Wie in den
meisten Beiträgen gab es ein Problem mit einem verteilten Dienst. Nennen wir diesen Dienst Alvin. Diesmal habe ich das Problem selbst nicht gefunden, informierten mich die Jungs vom Client-Teil.
Einmal bin ich aus einem verärgerten Brief aufgewacht, wegen der großen Verzögerungen von Alvin, den wir in naher Zukunft starten wollten. Insbesondere stieß der Kunde auf eine Verzögerung von 99. Perzentilen um 50 ms, die weit über unserem Verzögerungsbudget lag. Dies war überraschend, da ich den Service gründlich getestet habe, insbesondere auf Verzögerungen, da dies häufig beanstandet wird.
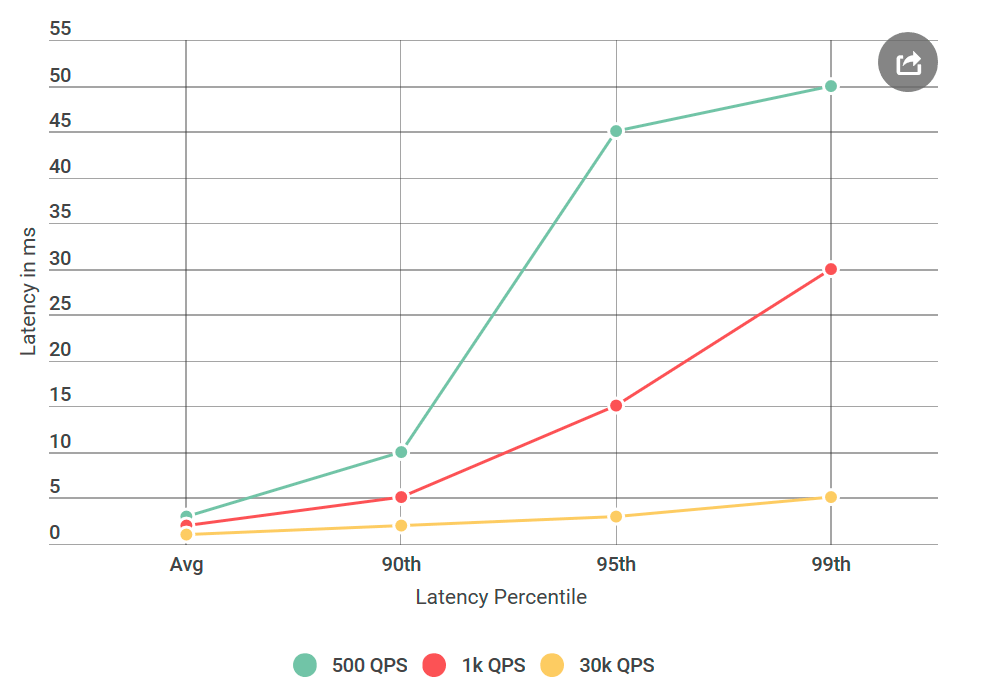
Bevor ich Alvin zum Testen gab, führte ich viele Experimente mit 40.000 Anfragen pro Sekunde (QPS) durch, die alle eine Verzögerung von weniger als 10 ms zeigten. Ich war bereit zu erklären, dass ich mit ihren Ergebnissen nicht einverstanden bin. Aber als ich den Brief noch einmal betrachtete, machte ich auf etwas Neues aufmerksam: Ich habe die genannten Bedingungen definitiv nicht getestet, ihr QPS war viel niedriger als meiner. Ich habe auf 40k QPS getestet, und sie nur auf 1k. Ich habe ein weiteres Experiment durchgeführt, diesmal mit niedrigerem QPS, nur um ihnen zu gefallen.
Da ich darüber in meinem Blog schreibe, haben Sie wahrscheinlich schon verstanden: Ihre Zahlen haben sich als richtig herausgestellt. Ich habe meinen virtuellen Client immer wieder getestet, alle mit dem gleichen Ergebnis: Eine geringe Anzahl von Anforderungen erhöht nicht nur die Verzögerung, sondern auch die Anzahl von Anforderungen mit einer Verzögerung von mehr als 10 ms. Mit anderen Worten, wenn bei 40k QPS etwa 50 Anforderungen pro Sekunde 50 ms überstiegen, dann gab es bei 1k QPS pro Sekunde 100 Anforderungen über 50 ms. Paradox!
Grenzen Sie Ihre Suche ein
Angesichts des Problems der Verzögerung in einem verteilten System mit vielen Komponenten müssen Sie zunächst eine kurze Liste der Verdächtigen erstellen. Wir gehen etwas tiefer in Alvins Architektur ein:
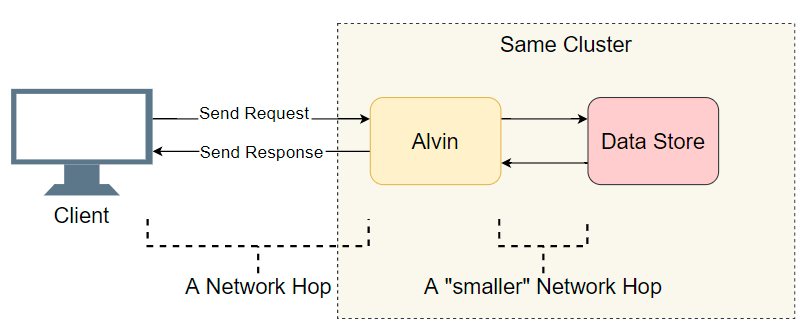
Ein guter Ausgangspunkt ist eine Liste abgeschlossener E / A-Übergänge (Netzwerkanrufe / Festplattensuchen usw.). Versuchen wir herauszufinden, wo die Verzögerung liegt. Neben der offensichtlichen E / A mit dem Kunden unternimmt Alvin einen weiteren Schritt: Er greift auf das Data Warehouse zu. Dieser Speicher funktioniert jedoch mit Alvin im selben Cluster, sodass weniger Verzögerungen auftreten sollten als mit dem Client. Also die Liste der Verdächtigen:
- Netzwerkanruf vom Client an Alvin.
- Netzwerkanruf von Alvin an das Data Warehouse.
- Suche auf Datenträger im Data Warehouse.
- Netzwerkanruf vom Data Warehouse an Alvin.
- Netzwerkanruf von Alvin an den Client.
Versuchen wir, einige Punkte zu streichen.
Data Warehouse
Als erstes habe ich Alvin in einen Ping-Ping-Server konvertiert, der keine Anforderungen verarbeitet. Nach Erhalt der Anfrage wird eine leere Antwort zurückgegeben. Wenn die Verzögerung abnimmt, ist ein Fehler bei der Implementierung von Alvin oder des Data Warehouse nichts Unbekanntes. Im ersten Experiment erhalten wir die folgende Grafik:
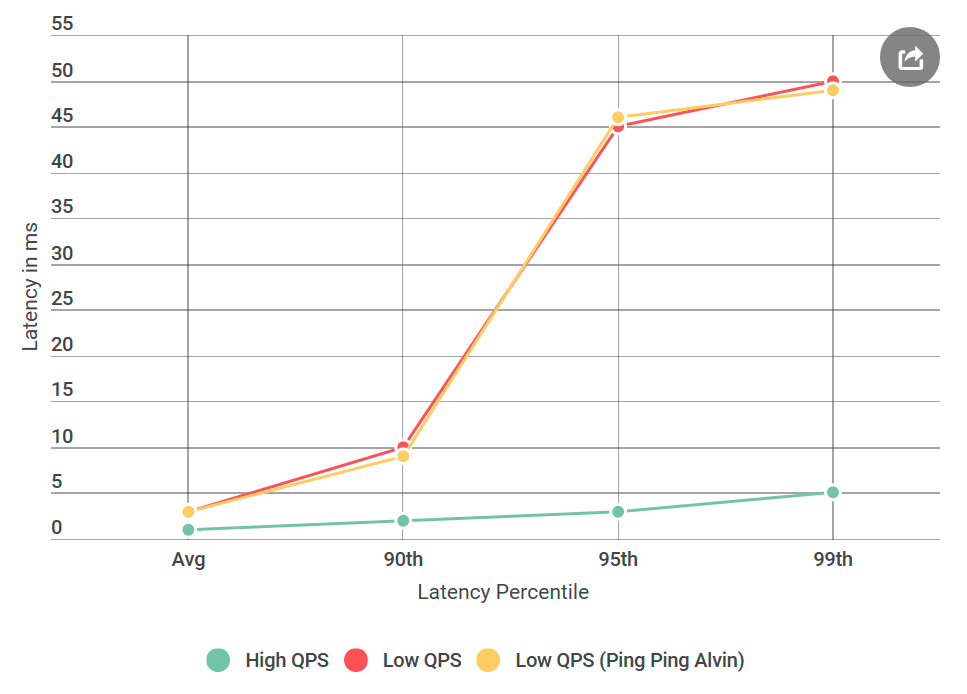
Wie Sie sehen, gibt es bei Verwendung des Ping-Ping-Servers keine Verbesserungen. Dies bedeutet, dass das Data Warehouse die Verzögerung nicht erhöht und die Liste der Verdächtigen halbiert wird:
- Netzwerkanruf vom Client an Alvin.
- Netzwerkanruf von Alvin an den Client.
Wow! Die Liste wird immer kleiner. Ich dachte, ich hätte fast den Grund herausgefunden.
gRPC
Jetzt ist es an der Zeit, Ihnen einen neuen Spieler vorzustellen:
gRPC . Dies ist eine Open Source-Bibliothek von Google für die In-Process-
RPC- Kommunikation. Obwohl
gRPC gut optimiert und weit verbreitet ist, habe ich es zum ersten Mal auf einem System dieser Größenordnung verwendet und erwartet, dass meine Implementierung - gelinde gesagt - nicht optimal ist.
Das Vorhandensein von
gRPC im Stapel warf eine neue Frage auf: Vielleicht ist dies meine Implementierung oder verursacht
gRPC selbst ein Verzögerungsproblem? Zur Liste des neuen Verdächtigen hinzufügen:
- Der Client ruft die
gRPC Bibliothek auf
- Die
gRPC Bibliothek auf dem Client ruft die gRPC Bibliothek auf dem Server im Netzwerk auf
gRPC Bibliothek greift auf Alvin zu (keine Operation bei Ping-Pong-Server)
Damit Sie verstehen, wie der Code aussieht, unterscheidet sich meine Client / Alvin-Implementierung nicht wesentlich von
asynchronen Client-Server-
Beispielen .
Hinweis: Die obige Liste ist etwas vereinfacht, da Sie mit gRPC Ihr eigenes (Vorlagen-?) Stream-Modell verwenden können, in dem der gRPC Ausführungsstapel und die Benutzerimplementierung miteinander verflochten sind. Der Einfachheit halber werden wir uns an dieses Modell halten.
Durch die Profilerstellung wird alles behoben
Als ich die Data Warehouses durchgestrichen hatte, dachte ich, ich wäre fast fertig: „Jetzt einfach! Wir werden das Profil anwenden und herausfinden, wo die Verzögerung auftritt. " Ich bin ein
großer Fan von genauem Profiling, weil die CPUs sehr schnell sind und meistens keinen Engpass darstellen. Die meisten Verzögerungen treten auf, wenn der Prozessor die Verarbeitung stoppen muss, um etwas anderes zu tun. Genau dafür wurde eine genaue Profilerstellung der CPU vorgenommen: Sie zeichnet alle
Kontextwechsel genau auf und macht deutlich, wo Verzögerungen auftreten.
Ich habe vier Profile erstellt: unter hohem QPS (niedrige Latenz) und mit einem Ping-Pong-Server mit niedrigem QPS (hohe Latenz), sowohl auf der Clientseite als auch auf der Serverseite. Und für alle Fälle habe ich auch ein Beispielprozessorprofil genommen. Beim Vergleichen von Profilen suche ich normalerweise nach einem abnormalen Aufrufstapel. Auf der schlechten Seite mit einer hohen Verzögerung gibt es beispielsweise viel mehr Kontextwechsel (10 oder mehr Mal). In meinem Fall stimmte die Anzahl der Kontextwechsel jedoch fast überein. Zu meinem Entsetzen gab es dort nichts Bedeutendes.
Zusätzliches Debugging
Ich war verzweifelt. Ich wusste nicht, welche anderen Werkzeuge verwendet werden könnten, und mein nächster Plan bestand im Wesentlichen darin, Experimente mit verschiedenen Variationen zu wiederholen und das Problem nicht eindeutig zu diagnostizieren.
Was wäre wenn
Ich war von Anfang an besorgt über die spezifische Verzögerungszeit von 50 ms. Dies ist eine sehr große Zeit. Ich beschloss, die Teile aus dem Code herauszuschneiden, bis ich genau herausfinden konnte, welcher Teil diesen Fehler verursachte. Dann folgte ein Experiment, das funktionierte.
Wie immer scheint im Hinterkopf alles offensichtlich zu sein. Ich habe den Client mit Alvin auf denselben Computer gestellt - und die Anfrage an
localhost gesendet. Und die Zunahme der Verzögerung ist verschwunden!
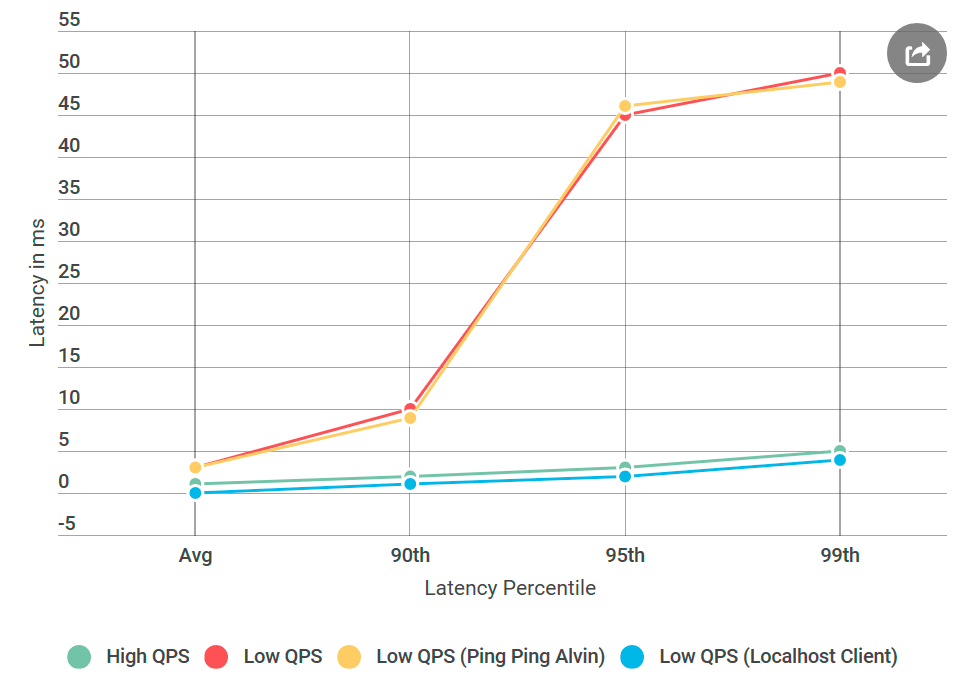
Mit dem Netzwerk stimmte etwas nicht.
Erlernen der Fähigkeiten eines Netzwerktechnikers
Ich muss zugeben: Mein Wissen über Netzwerktechnologien ist schrecklich, insbesondere angesichts der Tatsache, dass ich täglich mit ihnen arbeite. Aber das Netzwerk war der Hauptverdächtige, und ich musste lernen, wie man es debuggt.
Glücklicherweise liebt das Internet diejenigen, die lernen wollen. Die Kombination von Ping und Tracert schien ein guter Anfang zu sein, um Netzwerktransportprobleme zu beheben.
Zuerst habe ich
PsPing auf
Alvins TCP-Port ausgeführt. Ich habe die Standardoptionen verwendet - nichts Besonderes. Von den mehr als tausend Pings überschritt keiner 10 ms, mit Ausnahme des ersten zum Aufwärmen. Dies widerspricht dem beobachteten Anstieg der Verzögerung von 50 ms im 99. Perzentil: Dort sollten wir für jeweils 100 Anfragen etwa eine Anfrage mit einer Verzögerung von 50 ms sehen.
Dann habe ich es mit
Tracert versucht: Vielleicht liegt das Problem an einem der Knoten entlang der Route zwischen Alvin und dem Client. Aber der Tracer kam mit leeren Händen zurück.
Der Grund für die Verzögerung war also nicht mein Code, nicht die Implementierung von gRPC und nicht das Netzwerk. Ich habe bereits angefangen, mir Sorgen zu machen, dass ich das nie verstehen werde.
Auf welchem Betriebssystem sind wir jetzt?
gRPC unter Linux weit verbreitet, für Windows jedoch exotisch. Ich entschied mich für ein Experiment, das funktionierte: Ich erstellte eine virtuelle Linux-Maschine, kompilierte Alvin für Linux und stellte sie bereit.
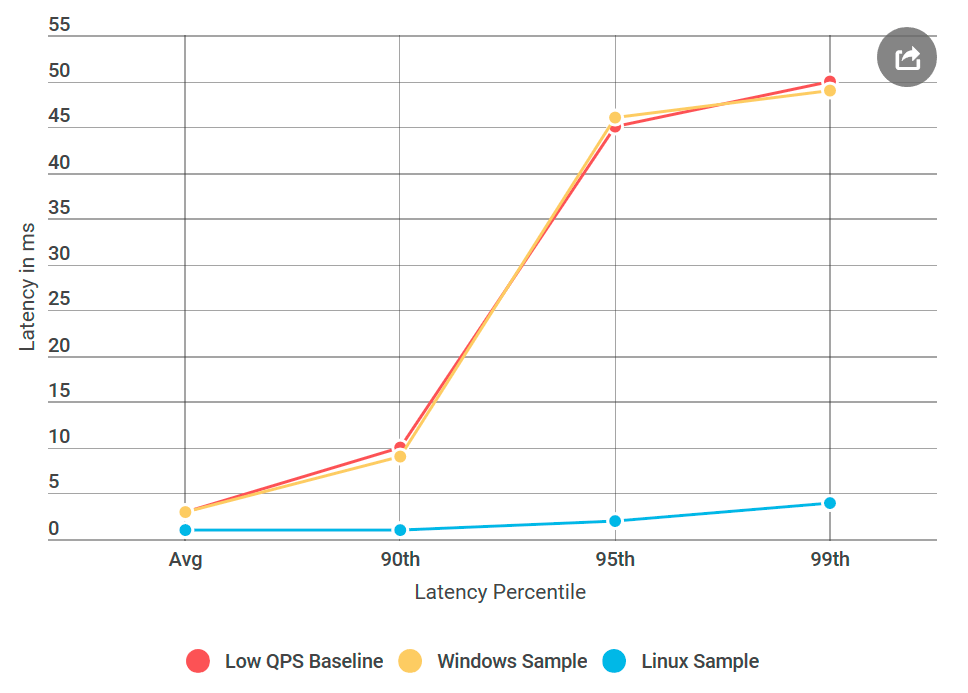
Und hier ist, was passiert ist: Der Ping-Pong-Linux-Server hatte keine Verzögerungen wie ein ähnlicher Windows-Knoten, obwohl sich die Datenquelle nicht unterschied. Es stellt sich heraus, dass das Problem in der Implementierung von gRPC für Windows liegt.
Nagle-Algorithmus
Die ganze Zeit dachte ich, ich hätte die
gRPC Flagge verpasst. Jetzt wurde mir klar, dass das Windows-Flag in
gRPC fehlt. Ich fand die interne RPC-Bibliothek, in der ich sicher war, dass sie für alle installierten
Winsock- Flags gut funktioniert. Dann fügte er all diese Flags zu gRPC hinzu und stellte Alvin für Windows auf dem festen Ping-Pong-Server für Windows bereit!
 Fast
Fast fertig: Ich fing an, die hinzugefügten Flags einzeln zu löschen, bis die Regression zurückkehrte, damit ich die Ursache ermitteln konnte. Es war der berüchtigte
TCP_NODELAY , ein Schalter des Nagle-Algorithmus.
Der Neigl-Algorithmus versucht, die Anzahl der über das Netzwerk gesendeten Pakete zu reduzieren, indem die Übertragung von Nachrichten verzögert wird, bis die Paketgröße eine bestimmte Anzahl von Bytes überschreitet. Obwohl dies für den durchschnittlichen Benutzer angenehm sein kann, ist es für Echtzeitserver destruktiv, da das Betriebssystem einige Nachrichten verzögert und Verzögerungen bei niedrigem QPS verursacht.
gRPC hatte dieses Flag in der Linux-Implementierung für TCP-Sockets gesetzt, jedoch nicht für Windows. Ich habe es
repariert .
Fazit
Eine große Verzögerung bei niedrigem QPS wurde durch die Betriebssystemoptimierung verursacht. Rückblickend hat die Profilerstellung keine Verzögerung festgestellt, da sie im Kernelmodus und nicht im
Benutzermodus ausgeführt wurde . Ich weiß nicht, ob es möglich ist, den Nagle-Algorithmus durch ETW-Captures zu beobachten, aber das wäre interessant.
Das localhost-Experiment hat wahrscheinlich den tatsächlichen Netzwerkcode nicht berührt, und der Neigl-Algorithmus wurde nicht gestartet, sodass die Verzögerungsprobleme verschwanden, als der Client Alvin über localhost kontaktierte.
Wenn Sie das nächste Mal eine Erhöhung der Latenz feststellen und gleichzeitig die Anzahl der Anforderungen pro Sekunde verringern, sollte der Neigl-Algorithmus auf Ihrer Liste der Verdächtigen stehen!