
Einführung
Ich habe diesen Bericht auf Englisch auf der GopherCon Russia 2019-Konferenz in Moskau und auf Russisch auf dem Treffen in Nischni Nowgorod verfasst. Es geht um einen Bitmap-Index - weniger verbreitet als B-Tree, aber nicht weniger interessant. Ich teile die
Aufzeichnung der Rede auf der Konferenz auf Englisch und das Textprotokoll auf Russisch.
Wir werden untersuchen, wie der Bitmap-Index funktioniert, wann er besser ist, wann er schlechter als andere Indizes ist und in welchen Fällen er viel schneller als diese ist. Wir werden sehen, welche gängigen DBMS bereits Bitmap-Indizes haben. versuche deine eigenen auf Go zu schreiben. Und zum Nachtisch werden wir vorgefertigte Bibliotheken verwenden, um unsere eigene superschnelle spezialisierte Datenbank zu erstellen.
Ich hoffe wirklich, dass meine Arbeit für Sie nützlich und interessant sein wird. Lass uns gehen!
Einführung
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Hallo an alle! Es ist sechs Uhr abends, wir sind alle super müde. Gute Zeit, um über die langweilige Theorie der Datenbankindizes zu sprechen, oder? Keine Sorge, ich werde hier und da ein paar Zeilen Quellcode haben. :-)
Wenn ohne Witze, dann ist der Bericht voller Informationen, und wir haben nicht viel Zeit. Also fangen wir an.

Heute werde ich über Folgendes sprechen:
- Was sind Indizes?
- Was ist ein Bitmap-Index?
- wo es verwendet wird und wo es NICHT verwendet wird und warum;
- einfache Implementierung auf Go und ein wenig Kampf mit dem Compiler;
- etwas weniger einfache, aber viel produktivere Implementierung in Go-Assembler;
- "Probleme" von Bitmap-Indizes;
- bestehende Implementierungen.
Was sind Indizes?
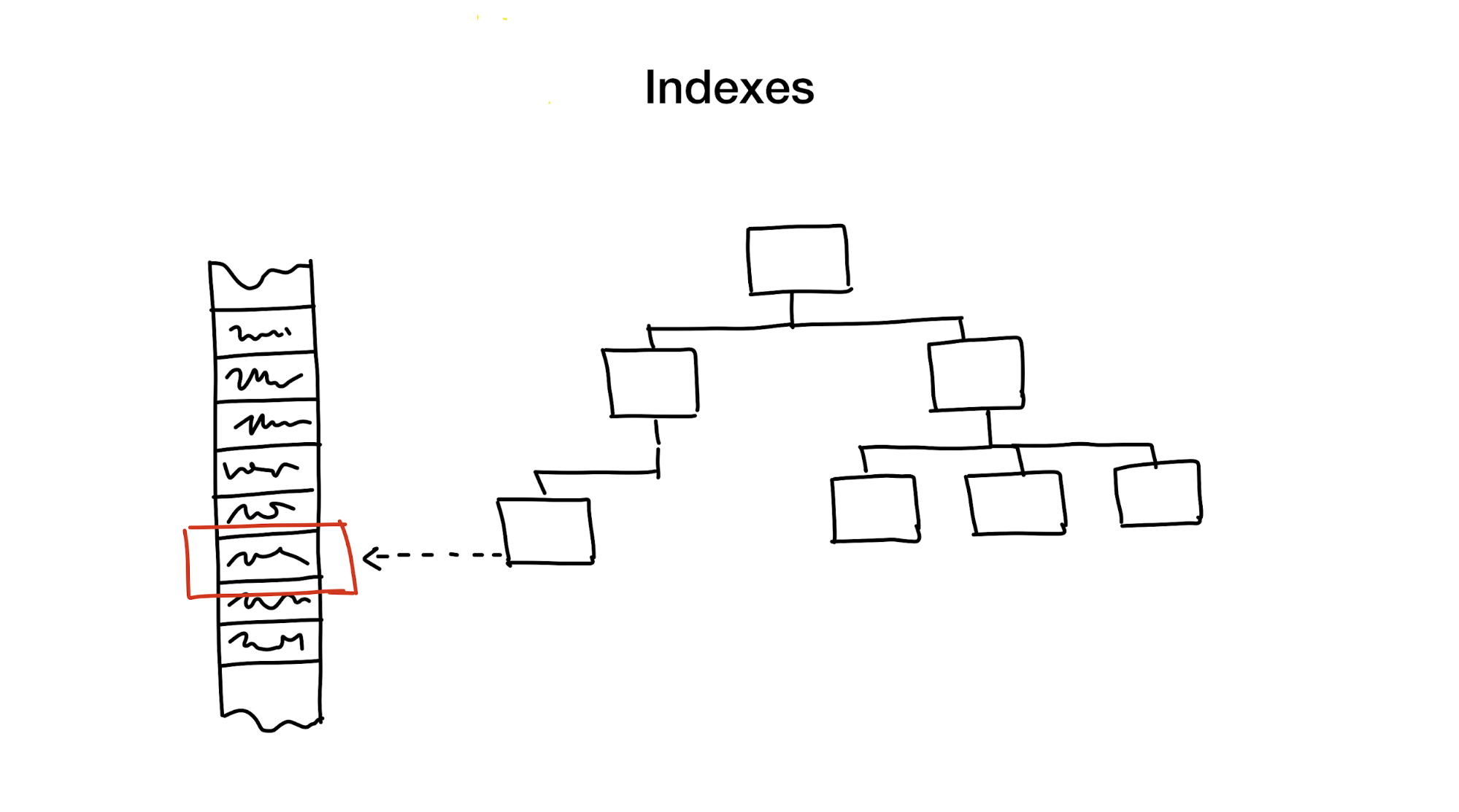
Ein Index ist eine separate Datenstruktur, die wir zusätzlich zu den Hauptdaten speichern und aktualisieren. Es wird verwendet, um die Suche zu beschleunigen. Ohne Indizes würde eine Suche einen vollständigen Durchlauf der Daten erfordern (ein Prozess, der als vollständiger Scan bezeichnet wird), und dieser Prozess weist eine lineare algorithmische Komplexität auf. Datenbanken enthalten jedoch normalerweise eine große Datenmenge und die lineare Komplexität ist zu langsam. Idealerweise würden wir einen Logarithmus oder eine Konstante erhalten.
Dies ist ein riesiges komplexes Thema, das mit Feinheiten und Kompromissen überfordert ist. Nach jahrzehntelanger Entwicklung und Forschung verschiedener Datenbanken bin ich jedoch bereit zu argumentieren, dass es nur wenige weit verbreitete Ansätze zur Erstellung von Datenbankindizes gibt.

Der erste Ansatz besteht darin, den Suchbereich hierarchisch zu verkleinern und den Suchbereich in kleinere Teile zu unterteilen.
Normalerweise machen wir das mit allen Arten von Bäumen. Ein Beispiel ist eine große Schachtel mit Materialien in Ihrem Schrank, in der sich kleinere Schachteln mit Materialien befinden, die nach verschiedenen Themen unterteilt sind. Wenn Sie Materialien benötigen, werden Sie diese wahrscheinlich in einer Box mit den Worten "Materialien" suchen und nicht in der mit "Cookies", oder?
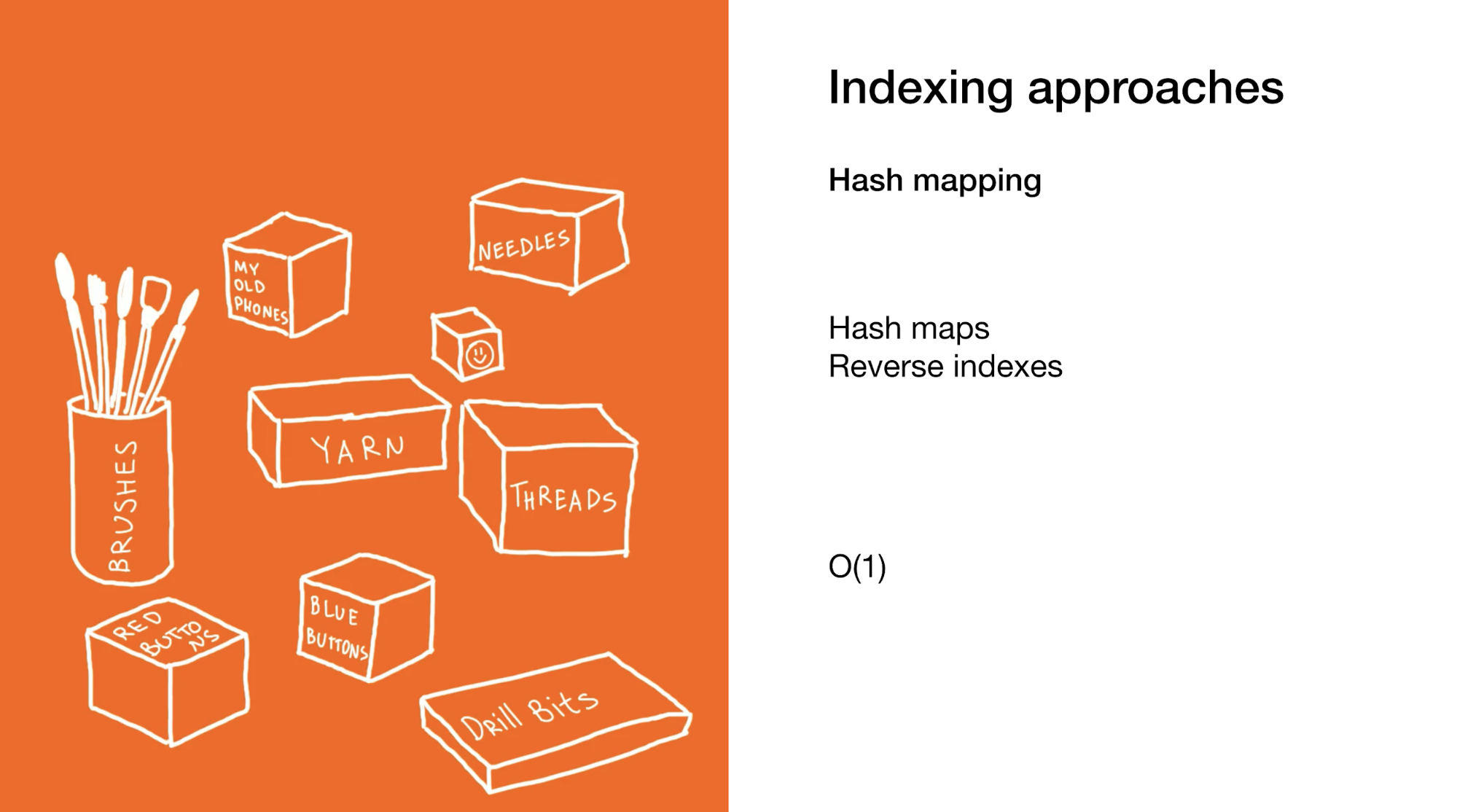
Der zweite Ansatz besteht darin, sofort das gewünschte Element oder die gewünschte Elementgruppe auszuwählen. Wir tun dies in Hash-Maps oder in umgekehrten Indizes. Die Verwendung von Hash-Maps ist dem vorherigen Beispiel sehr ähnlich. Nur anstelle einer Box mit Boxen in Ihrem Schrank gibt es viele kleine Boxen mit endgültigen Elementen.

Der dritte Ansatz besteht darin, die Notwendigkeit einer Suche zu beseitigen. Wir machen das mit Bloom-Filtern oder Kuckucksfiltern. Ersteres gibt sofort eine Antwort, sodass keine Suche erforderlich ist.
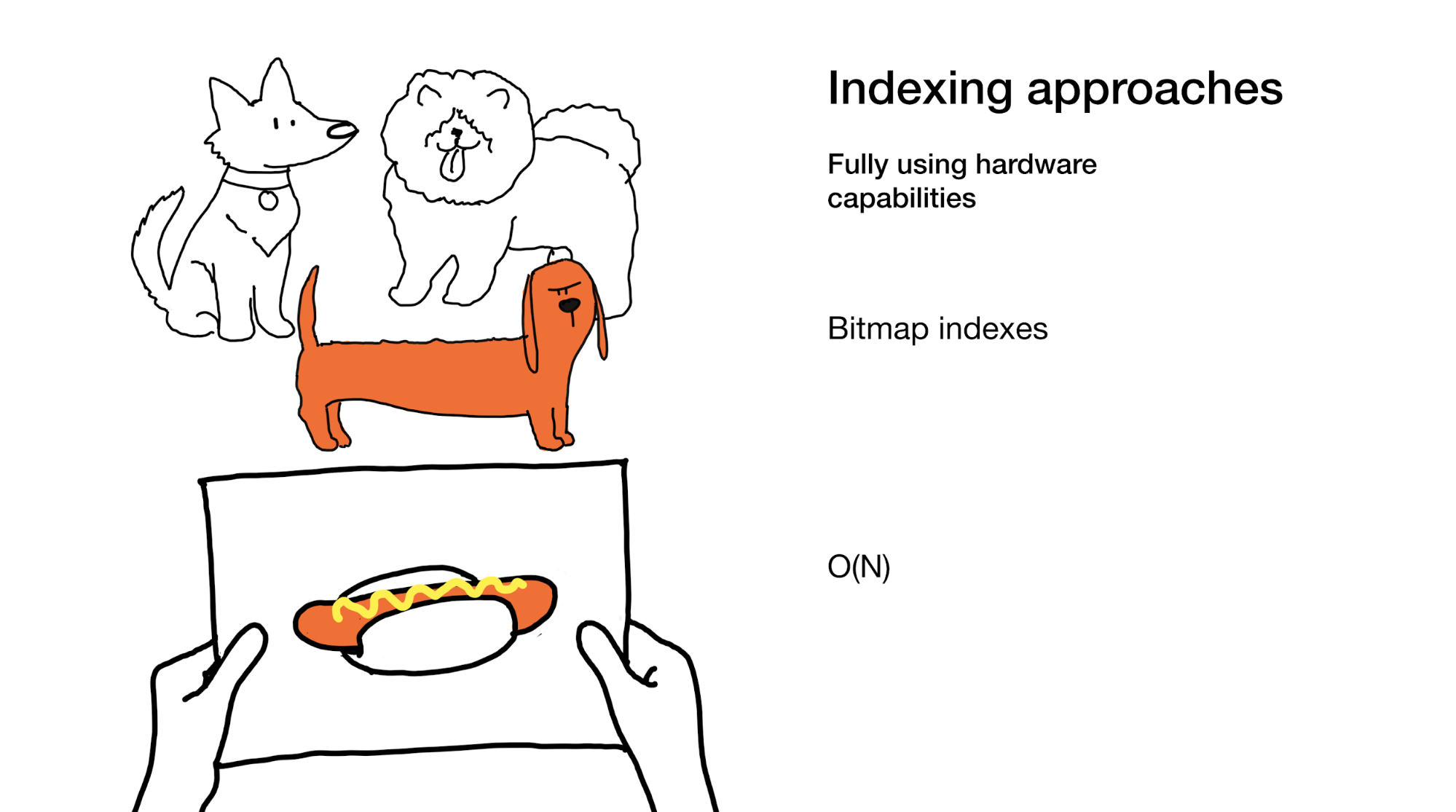
Der letzte Ansatz besteht darin, alle Kapazitäten, die uns modernes Eisen bietet, voll auszuschöpfen. Genau das machen wir in Bitmap-Indizes. Ja, wenn wir sie verwenden, müssen wir manchmal den gesamten Index durchgehen, aber wir machen das sehr effizient.
Wie gesagt, das Thema Datenbankindizes ist umfangreich und voller Kompromisse. Dies bedeutet, dass wir manchmal mehrere Ansätze gleichzeitig verwenden können: wenn wir die Suche noch weiter beschleunigen müssen oder wenn alle möglichen Suchtypen abgedeckt werden müssen.
Heute werde ich über den am wenigsten bekannten Ansatz sprechen - über Bitmap-Indizes.
Wer soll ich darüber reden?
Ich arbeite als Teamleiter in Badoo (vielleicht kennen Sie unser anderes Produkt, Bumble, besser). Wir haben bereits mehr als 400 Millionen Benutzer auf der ganzen Welt und viele Funktionen, die sich mit der Auswahl des besten Paares für sie befassen. Wir verwenden dazu benutzerdefinierte Dienste, die auch Bitmap-Indizes verwenden.
Was ist ein Bitmap-Index?
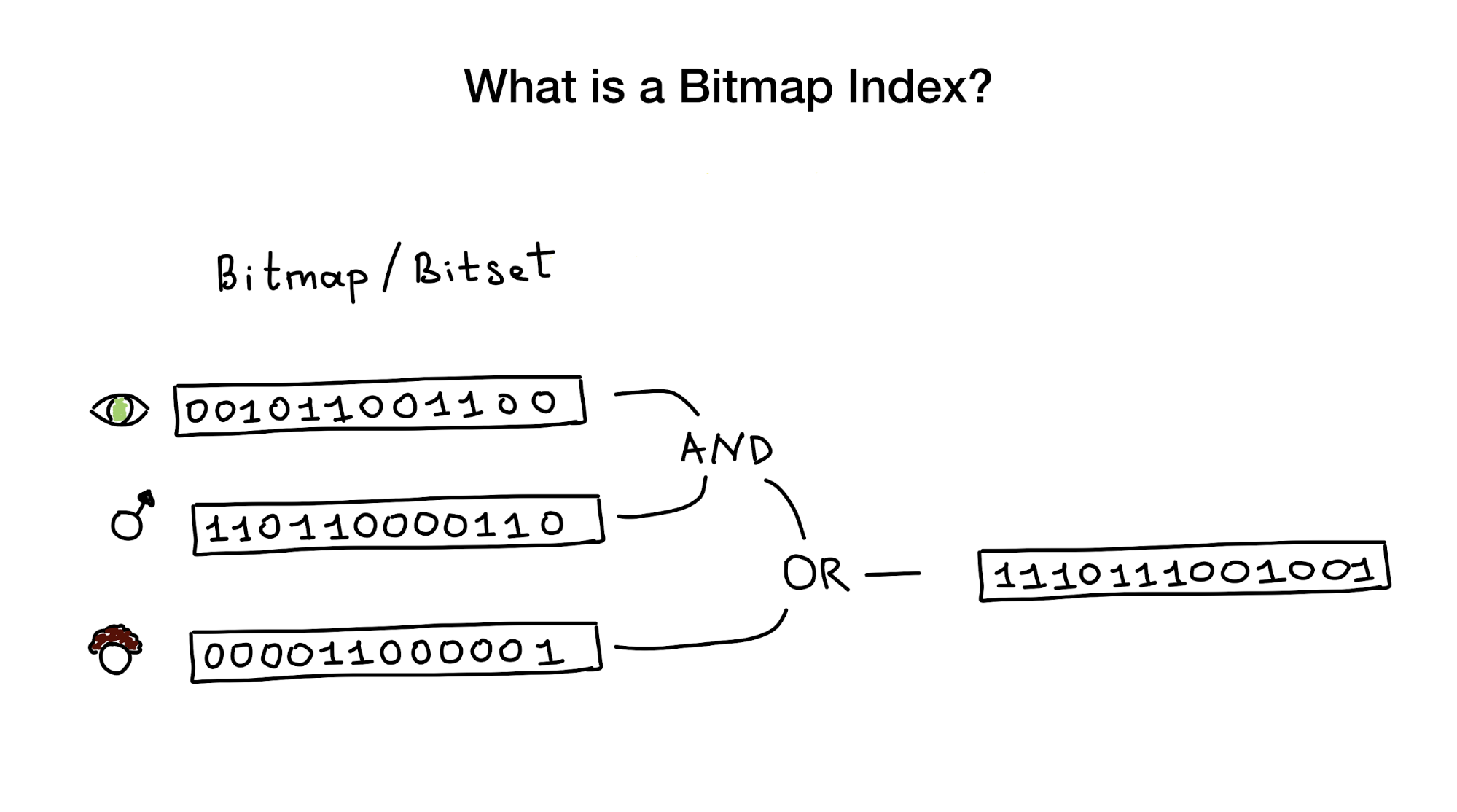
Bitmap-Indizes verwenden, wie der Name schon sagt, Bitmaps oder Bitsets, um einen Suchindex zu implementieren. Aus der Vogelperspektive besteht dieser Index aus einer oder mehreren solcher Bitmaps, die Entitäten (wie Personen) und deren Eigenschaften oder Parameter (Alter, Augenfarbe usw.) darstellen, sowie aus einem Algorithmus, der Bitoperationen verwendet (UND, ODER NICHT), um auf eine Suchanfrage zu antworten.

Uns wird gesagt, dass Bitmap-Indizes am besten geeignet und sehr produktiv sind für Fälle, in denen eine Suche Abfragen über viele Spalten hinweg mit geringer Kardinalität kombiniert (stellen Sie sich „Augenfarbe“ oder „Familienstand“ vor, etwa „Entfernung vom Stadtzentrum“). ) Aber später werde ich zeigen, dass sie bei Spalten mit hoher Kardinalität perfekt funktionieren.
Betrachten Sie das einfachste Beispiel eines Bitmap-Index.

Stellen Sie sich vor, wir haben eine Liste von Moskauer Restaurants mit binären Eigenschaften wie diesen:
- in der Nähe der U-Bahn (in der Nähe der U-Bahn);
- Es gibt einen privaten Parkplatz (hat einen privaten Parkplatz);
- es gibt eine Veranda (hat Terrasse);
- Sie können einen Tisch reservieren (akzeptiert Reservierungen);
- geeignet für Vegetarier (vegan freundlich);
- teuer (teuer).
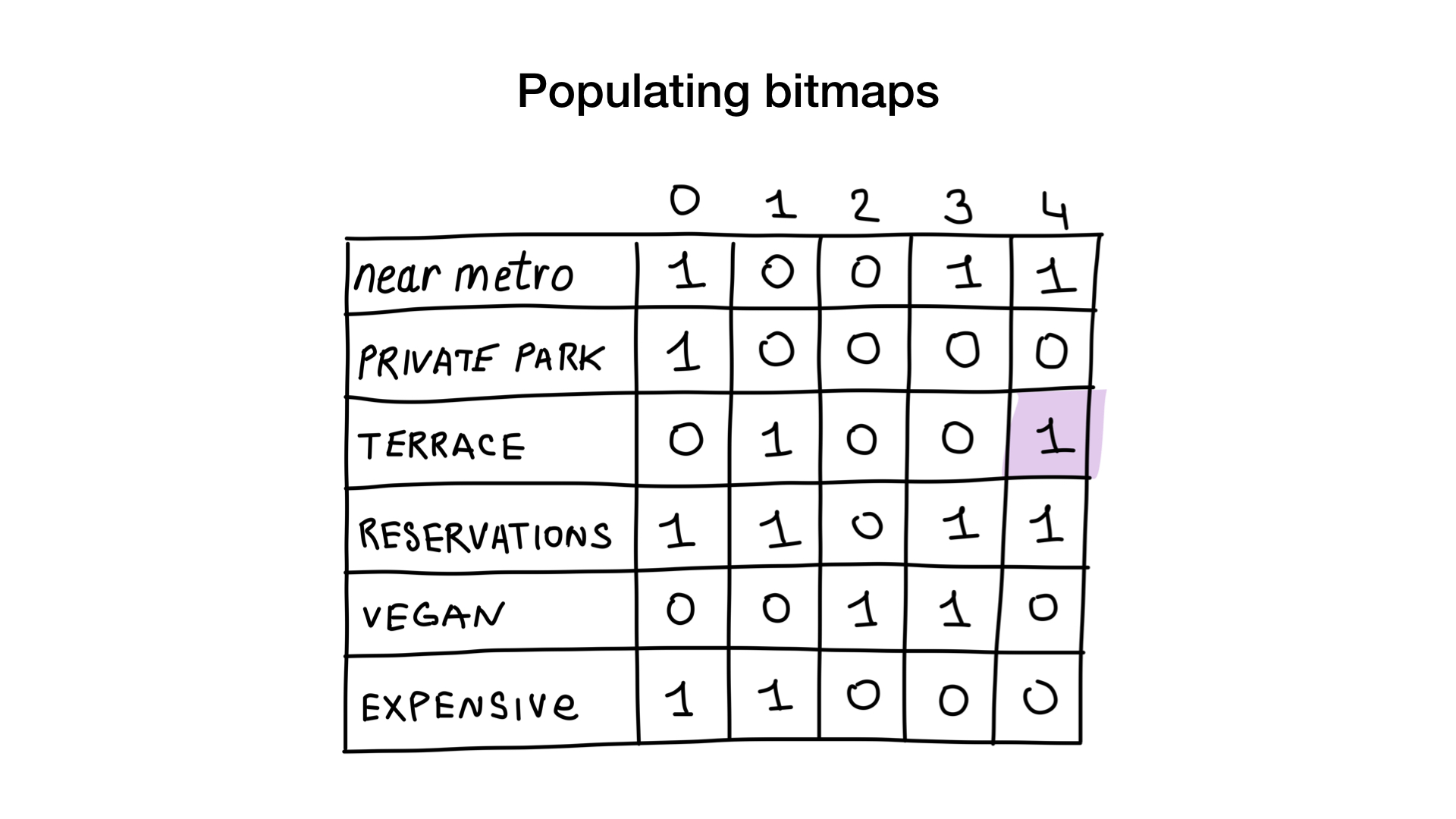
Geben Sie jedem Restaurant eine Seriennummer ab 0 und weisen Sie Speicher für 6 Bitmaps zu (eine für jedes Merkmal). Dann füllen wir diese Bitmaps aus, je nachdem, ob das Restaurant diese Eigenschaft hat oder nicht. Wenn Restaurant 4 eine Veranda hat, wird Bit Nr. 4 in der Bitmap „Es gibt eine Veranda“ auf 1 gesetzt (wenn es keine Veranda gibt, dann auf 0).

Jetzt haben wir den einfachsten möglichen Bitmap-Index und können damit Fragen beantworten wie:
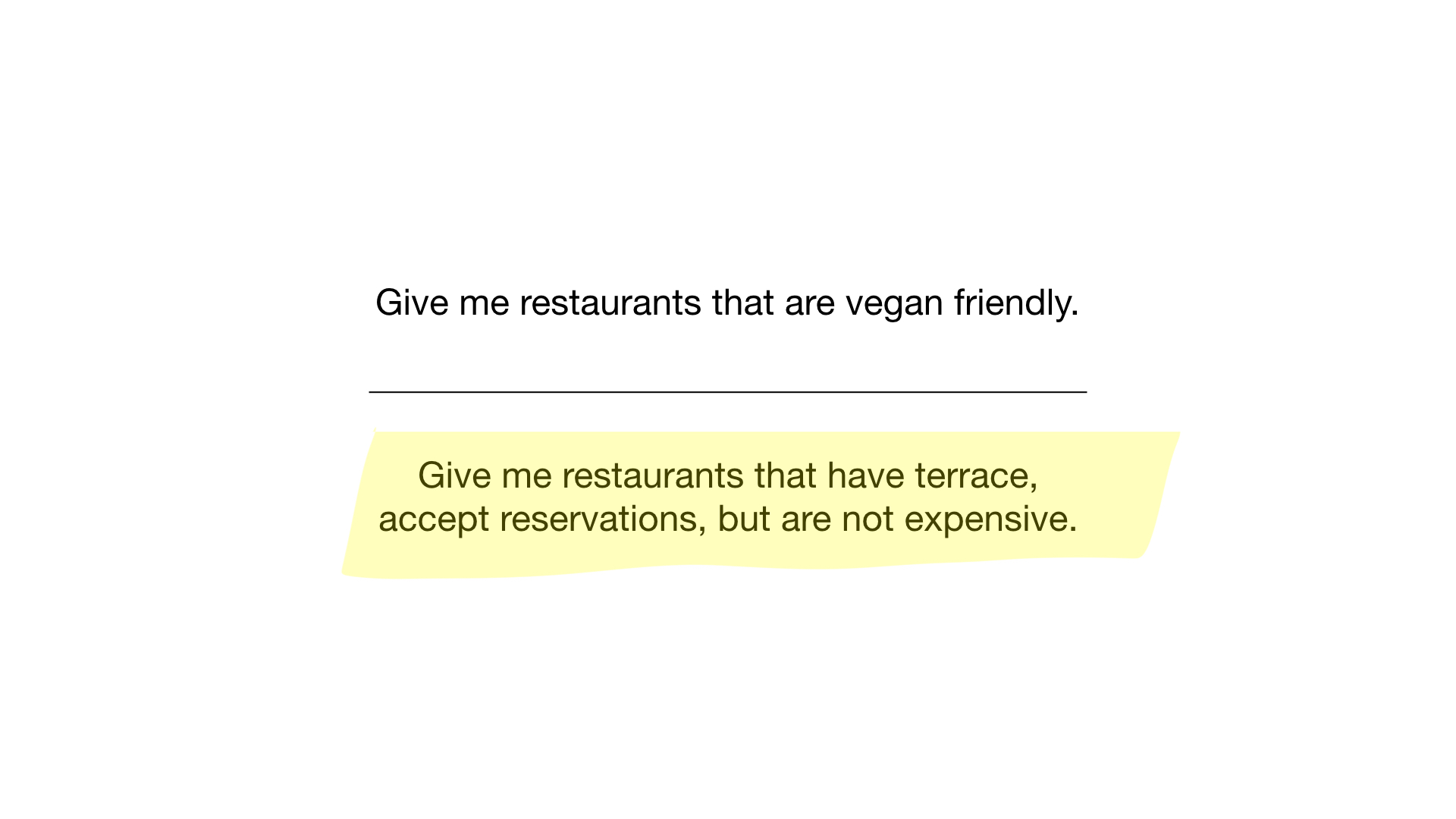
- "Zeigen Sie mir Restaurants für Vegetarier geeignet";
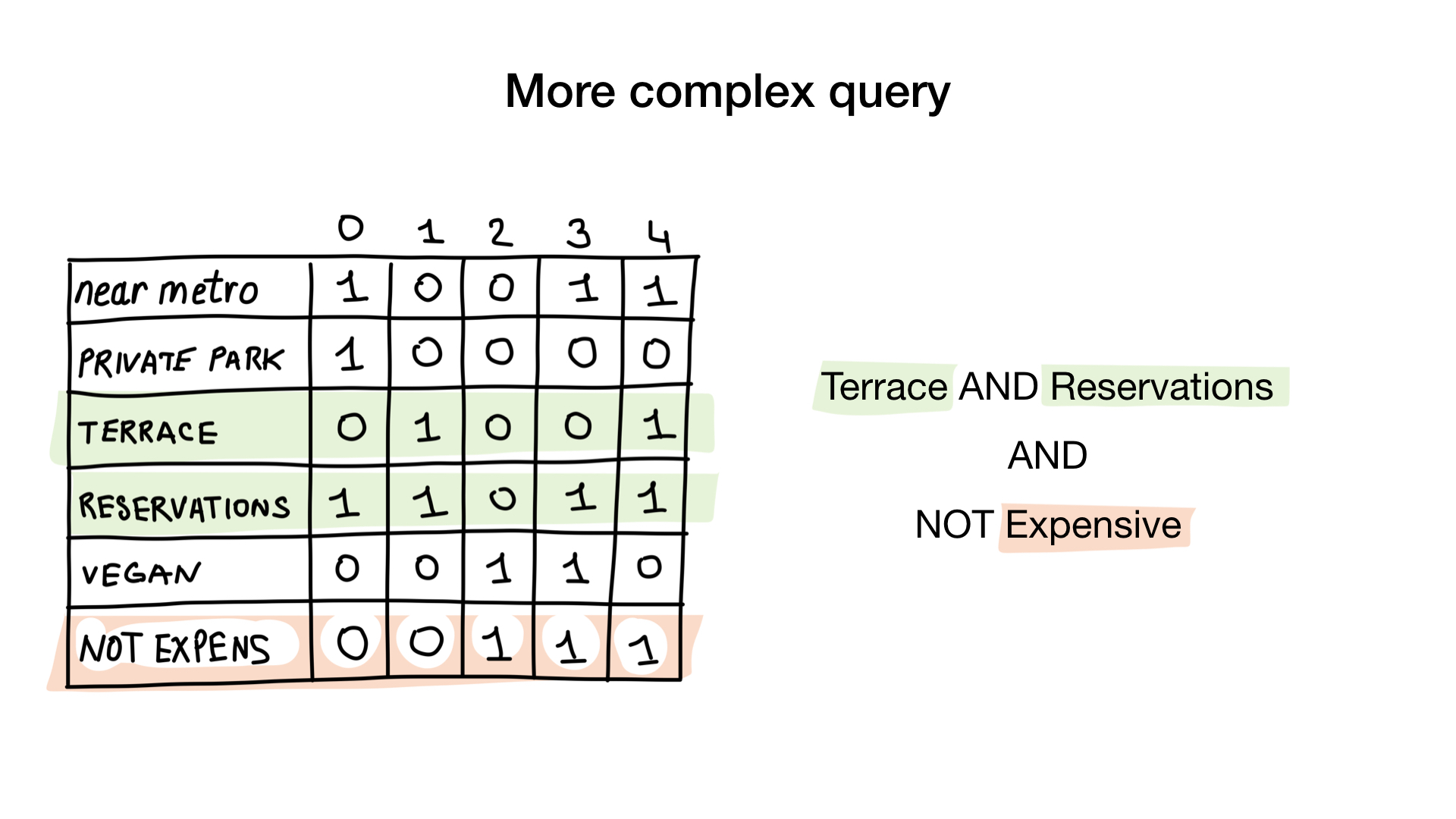
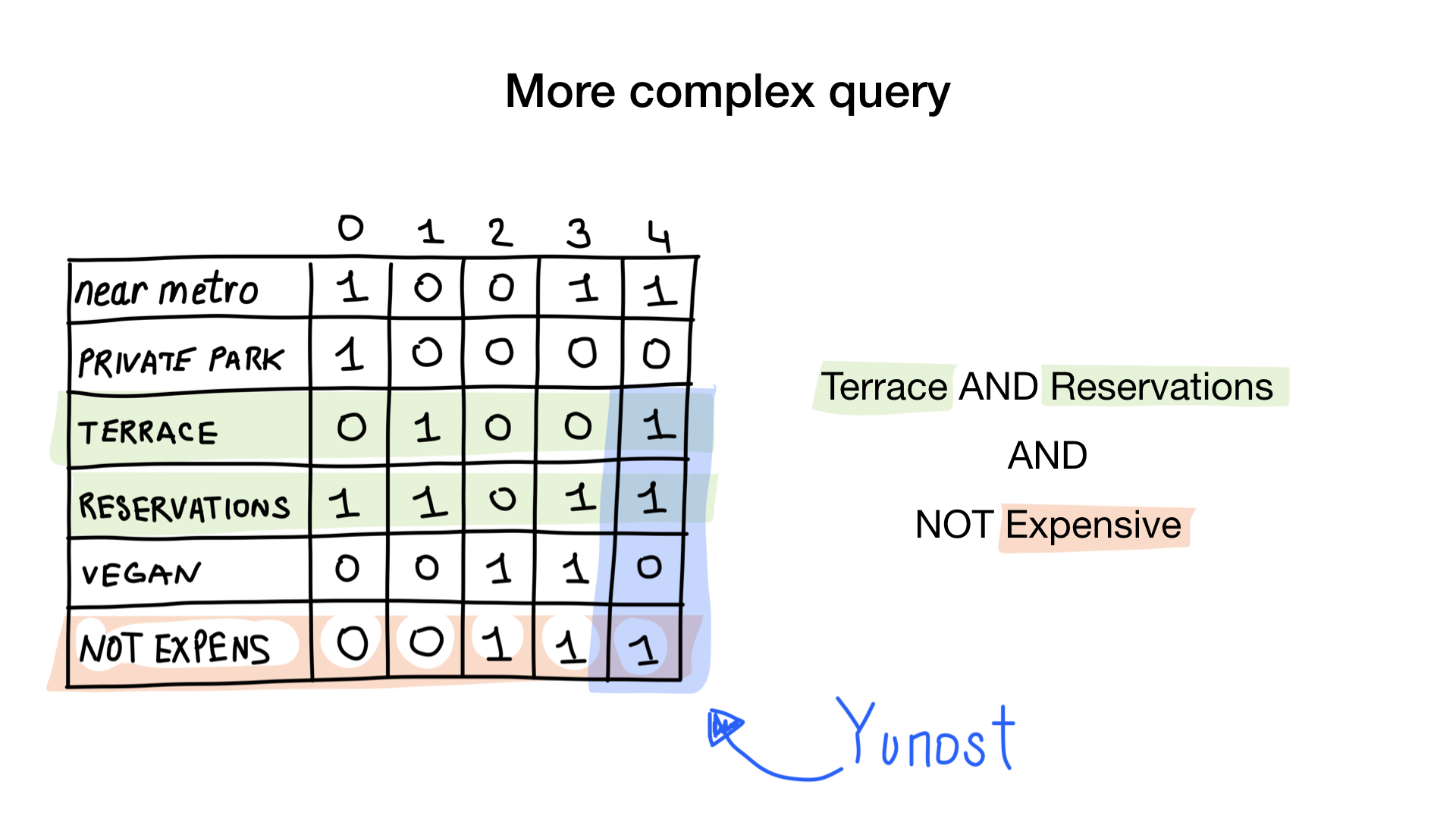
- "Zeigen Sie mir preiswerte Restaurants mit einer Veranda, auf der Sie einen Tisch reservieren können."
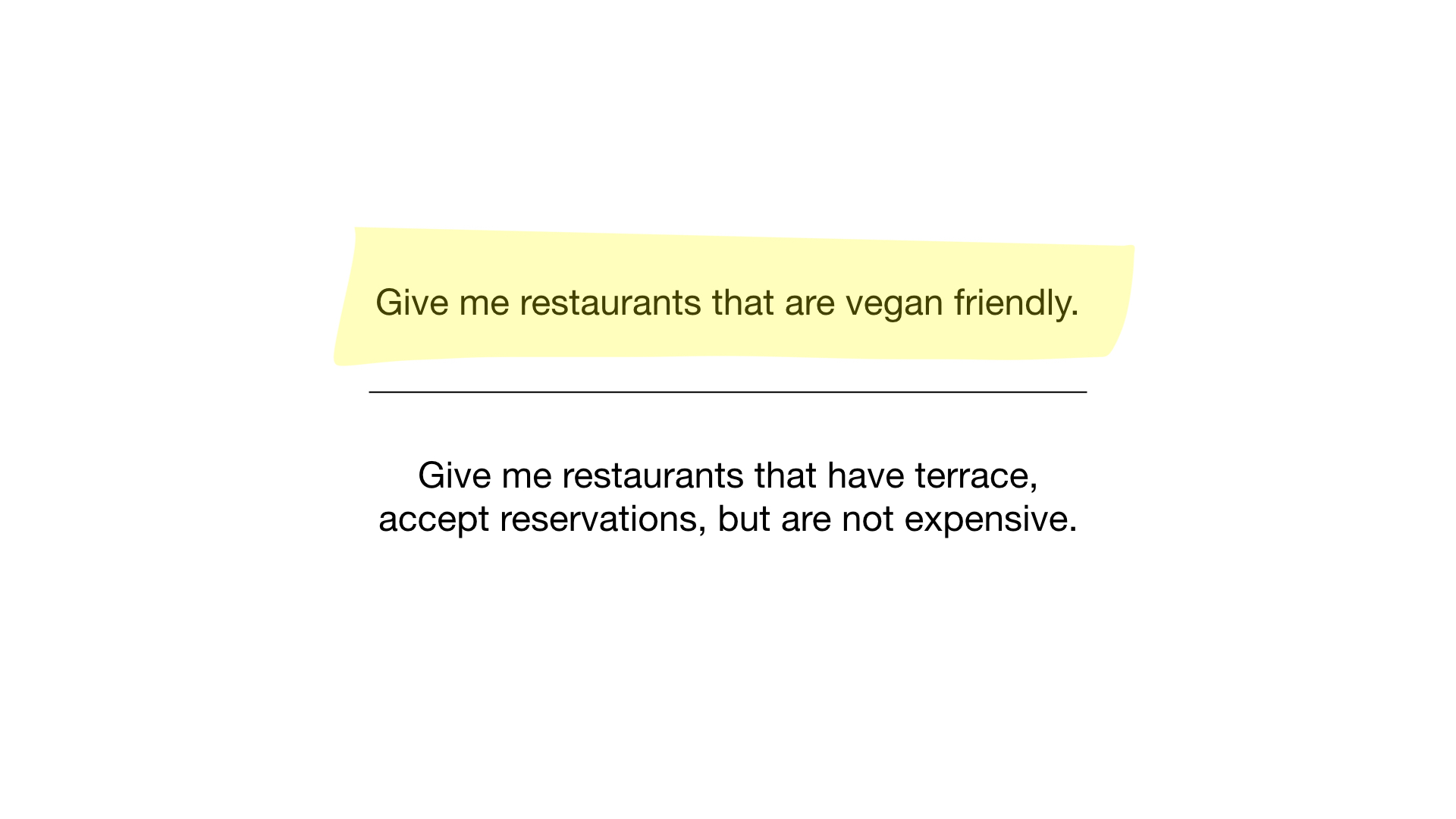
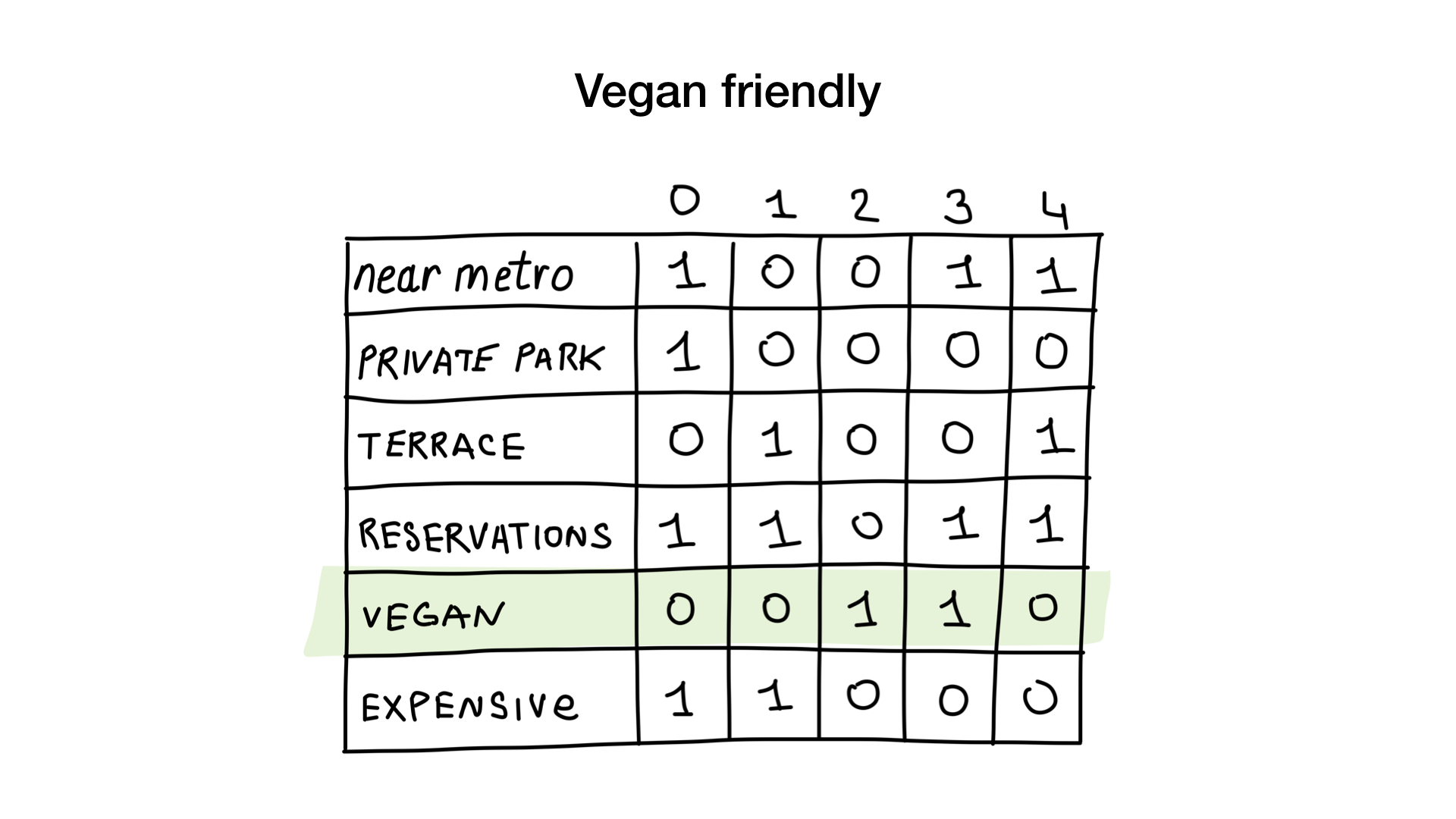
Wie? Mal sehen. Die erste Anfrage ist sehr einfach. Alles, was wir tun müssen, ist, die Bitmap „Für Vegetarier geeignet“ zu nehmen und daraus eine Liste von Restaurants zu machen, deren Teile ausgestellt sind.

Die zweite Abfrage ist etwas komplizierter. Wir müssen die NOT-Bit-Operation für die "teure" Bitmap verwenden, um eine Liste kostengünstiger Restaurants zu erhalten. Stellen Sie sie dann mit der Bitmap "Sie können eine Tabelle reservieren" ein und setzen Sie das Ergebnis mit der Bitmap "Es gibt eine Veranda". Die resultierende Bitmap enthält eine Liste der Einrichtungen, die alle unsere Kriterien erfüllen. In diesem Beispiel ist dies nur das Yunost-Restaurant.
Es gibt viel Theorie, aber keine Sorge, wir werden den Code sehr bald sehen.
Wo werden Bitmap-Indizes verwendet?

Wenn Sie Bitmap-Indizes „googeln“, beziehen sich 90% der Antworten auf Oracle DB. Aber der Rest des DBMS unterstützt wahrscheinlich auch so eine coole Sache, oder? Nicht wirklich.
Lassen Sie uns die Liste der Hauptverdächtigen durchgehen.

MySQL unterstützt noch keine Bitmap-Indizes, es gibt jedoch einen Vorschlag mit einem Vorschlag zum Hinzufügen dieser Option (
https://dev.mysql.com/worklog/task/?id=1524 ).
PostgreSQL unterstützt keine Bitmap-Indizes, verwendet jedoch einfache Bitmaps und Bitoperationen, um Suchergebnisse über mehrere andere Indizes hinweg zu kombinieren.
Tarantool verfügt über Bitset-Indizes und unterstützt eine einfache Suche.
Redis verfügt über einfache Bitfelder
(https://redis.io/commands/bitfield ), die nicht durchsucht werden können.
MongoDB unterstützt noch keine Bitmap-Indizes, es gibt jedoch auch einen Vorschlag mit einem Vorschlag zum Hinzufügen dieser Option
https://jira.mongodb.org/browse/SERVER-1723Elasticsearch verwendet darin Bitmaps
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- Aber ein neuer Nachbar erschien in unserem Haus: Pilosa. Dies ist eine neue nicht relationale Datenbank, die in Go geschrieben wurde. Es enthält nur Bitmap-Indizes und basiert alles darauf. Wir werden etwas später über sie sprechen.
Gehen Sie zur Implementierung
Aber warum werden Bitmap-Indizes so selten verwendet? Bevor ich diese Frage beantworte, möchte ich Ihnen die Implementierung eines sehr einfachen Bitmap-Index für Go demonstrieren.

Bitmaps sind im Wesentlichen nur Daten. Verwenden Sie in Go dafür Byte-Slices.
Wir haben eine Bitmap pro Restaurantmerkmal, und jedes Bit in der Bitmap gibt an, ob ein bestimmtes Restaurant über diese Eigenschaft verfügt oder nicht.

Wir brauchen zwei Hilfsfunktionen. Eine wird verwendet, um unsere Bitmaps mit zufälligen Daten zu füllen. Zufällig, aber mit einer gewissen Wahrscheinlichkeit, dass das Restaurant jede Eigenschaft hat. Ich glaube zum Beispiel, dass es in Moskau nur sehr wenige Restaurants gibt, in denen Sie keinen Tisch reservieren können, und es scheint mir, dass ungefähr 20% der Einrichtungen für Vegetarier geeignet sind.
Die zweite Funktion konvertiert die Bitmap in eine Liste von Restaurants.


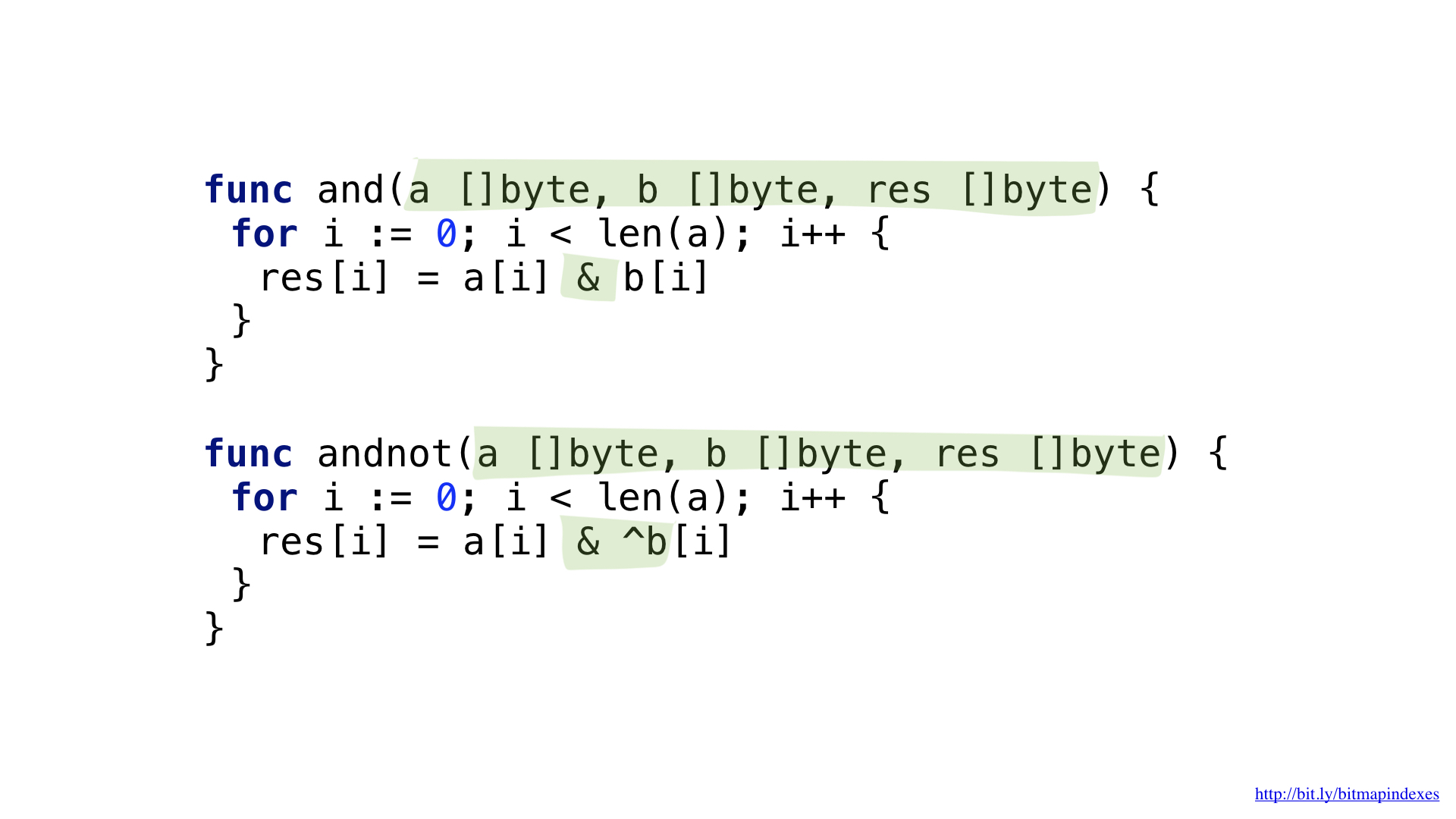
Um die Anfrage „Zeigen Sie mir preiswerte Restaurants mit einer Veranda und wo Sie einen Tisch reservieren können“ zu beantworten, benötigen wir zwei Bit-Operationen: NOT und AND.
Wir können unseren Code ein wenig vereinfachen, indem wir die komplexere AND NOT-Operation verwenden.
Wir haben Funktionen für jede dieser Operationen. Beide gehen die Slices durch, nehmen die entsprechenden Elemente von jedem, kombinieren sie mit einer Bitoperation und fügen das Ergebnis in das resultierende Slice ein.
Und jetzt können wir unsere Bitmaps und Funktionen verwenden, um auf eine Suchanfrage zu antworten.

Die Leistung ist nicht so hoch, obwohl die Funktionen sehr einfach sind und wir anständig gespart haben, dass wir nicht jedes Mal, wenn die Funktion aufgerufen wurde, ein neues resultierendes Slice zurückgegeben haben.
Nachdem ich ein wenig mit pprof profiliert hatte, bemerkte ich, dass der Go-Compiler eine sehr einfache, aber sehr wichtige Optimierung verpasste: das Inlining von Funktionen.
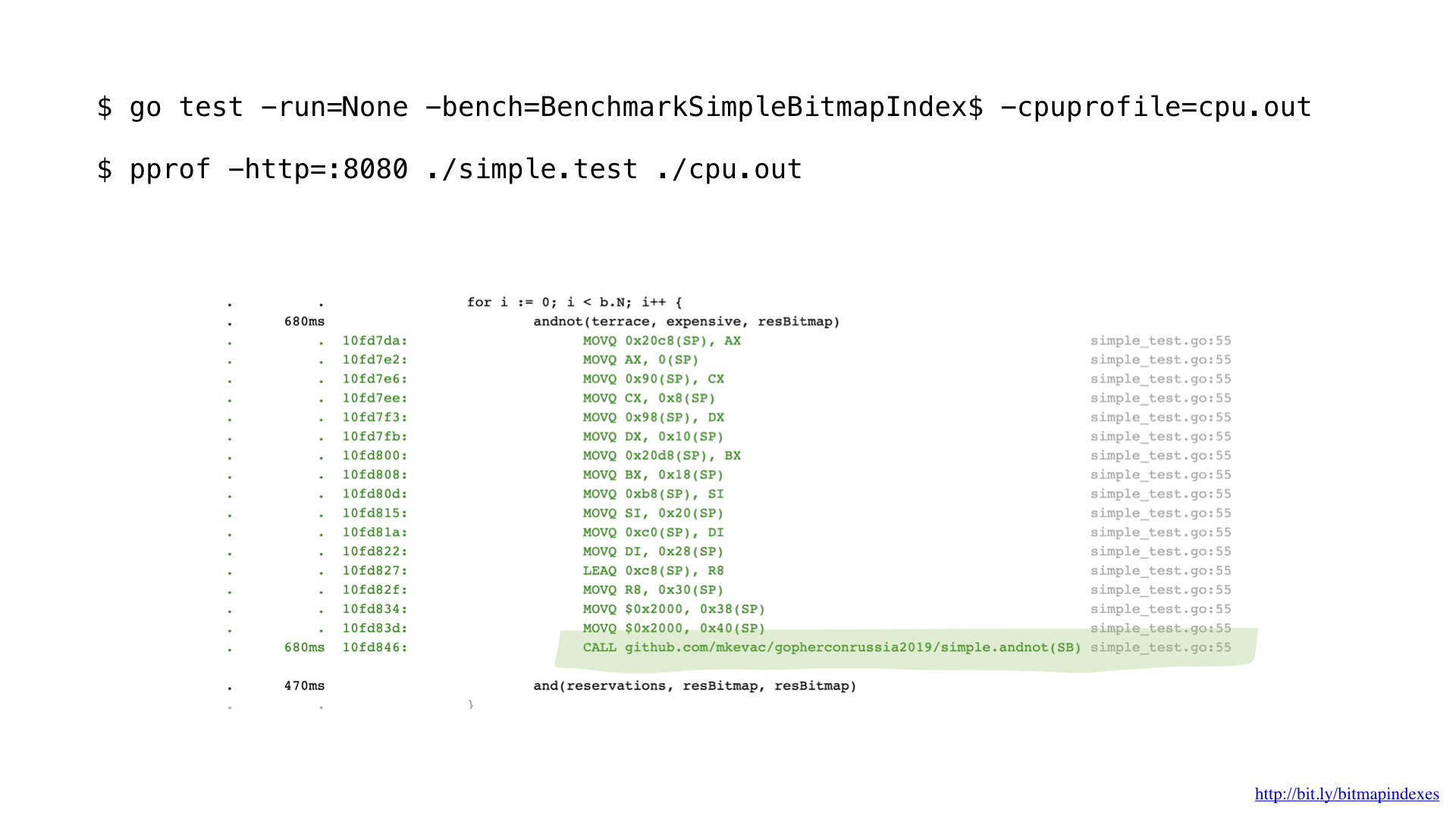
Tatsache ist, dass der Go-Compiler schreckliche Angst vor Schleifen hat, die Slices durchlaufen, und sich kategorisch weigert, Inline-Funktionen zu verwenden, die Schleifen enthalten.
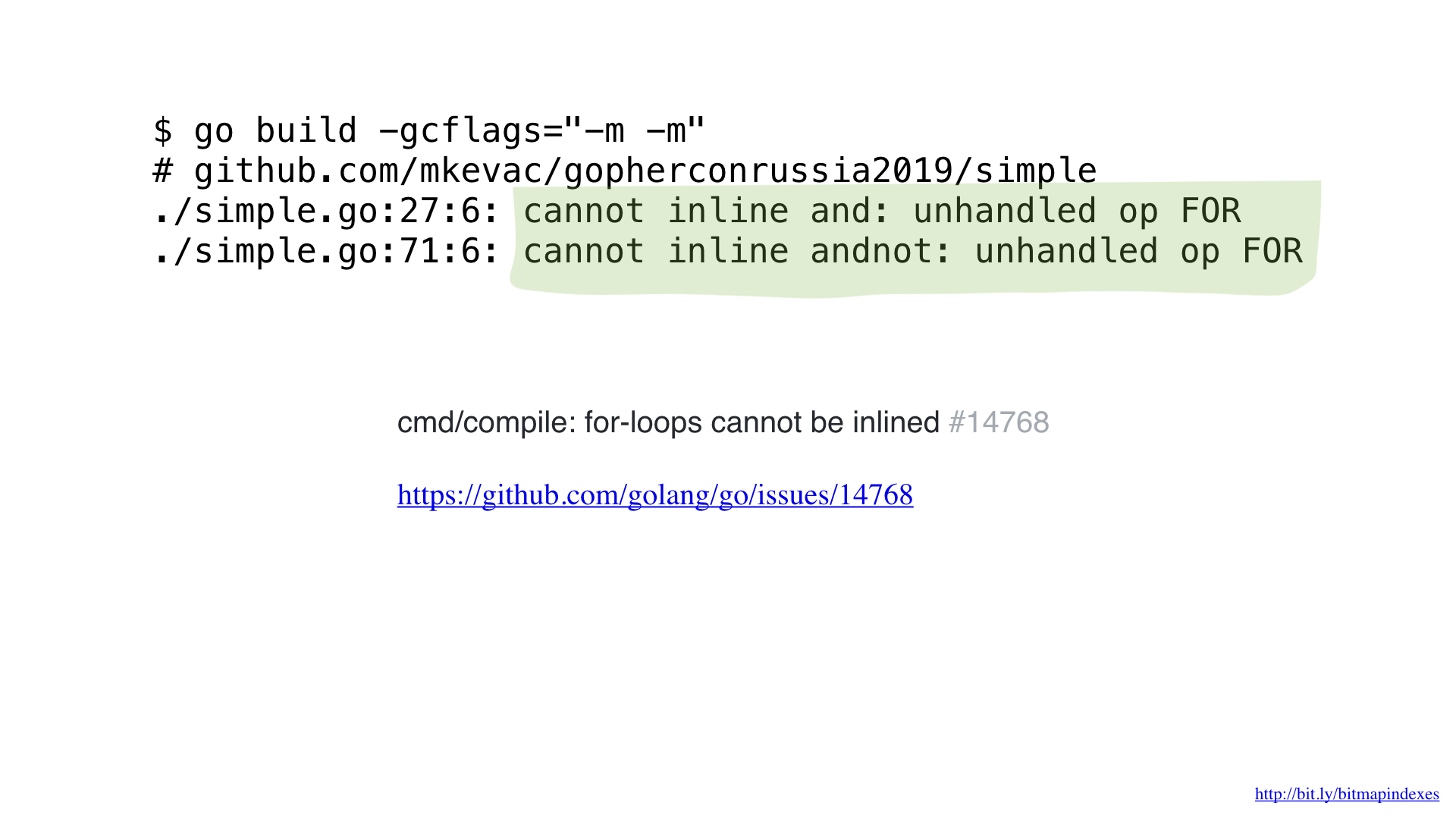
Aber ich habe keine Angst, und ich kann den Compiler täuschen, indem ich goto anstelle einer Schleife verwende, wie in den guten alten Zeiten.


Und wie Sie sehen, erweitert der Compiler unsere Funktion jetzt glücklich! Dadurch sparen wir ca. 2 Mikrosekunden. Nicht schlecht!

Der zweite Engpass ist leicht zu erkennen, wenn Sie sich die Assembler-Ausgabe genau ansehen. Der Compiler hat direkt in unserer heißesten Schleife eine Slice-gebundene Prüfung hinzugefügt. Tatsache ist, dass Go eine sichere Sprache ist. Der Compiler befürchtet, dass meine drei Argumente (drei Slices) unterschiedliche Größen haben. Schließlich besteht dann theoretisch die Möglichkeit, dass der sogenannte Pufferüberlauf auftritt.
Lassen Sie uns den Compiler beruhigen, indem wir ihm zeigen, dass alle Slices dieselbe Größe haben. Wir können dies tun, indem wir zu Beginn unserer Funktion eine einfache Prüfung hinzufügen.
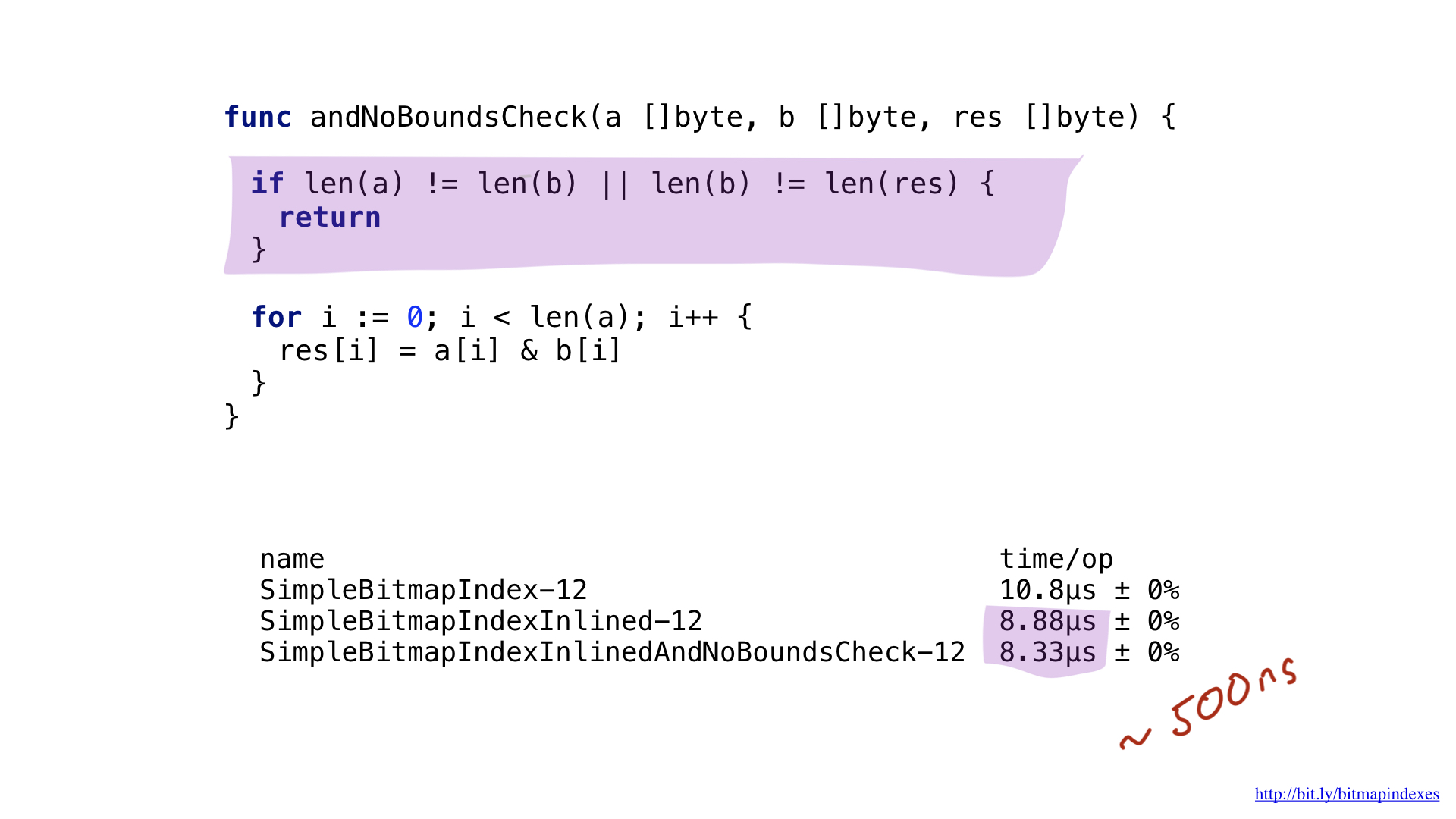
Wenn der Compiler dies sieht, überspringt er den Test gerne und wir sparen am Ende weitere 500 Nanosekunden.
Große Mengen
Okay, wir haben es geschafft, etwas Leistung aus unserer einfachen Implementierung herauszuholen, aber dieses Ergebnis ist mit der aktuellen Hardware tatsächlich viel schlechter als möglich.
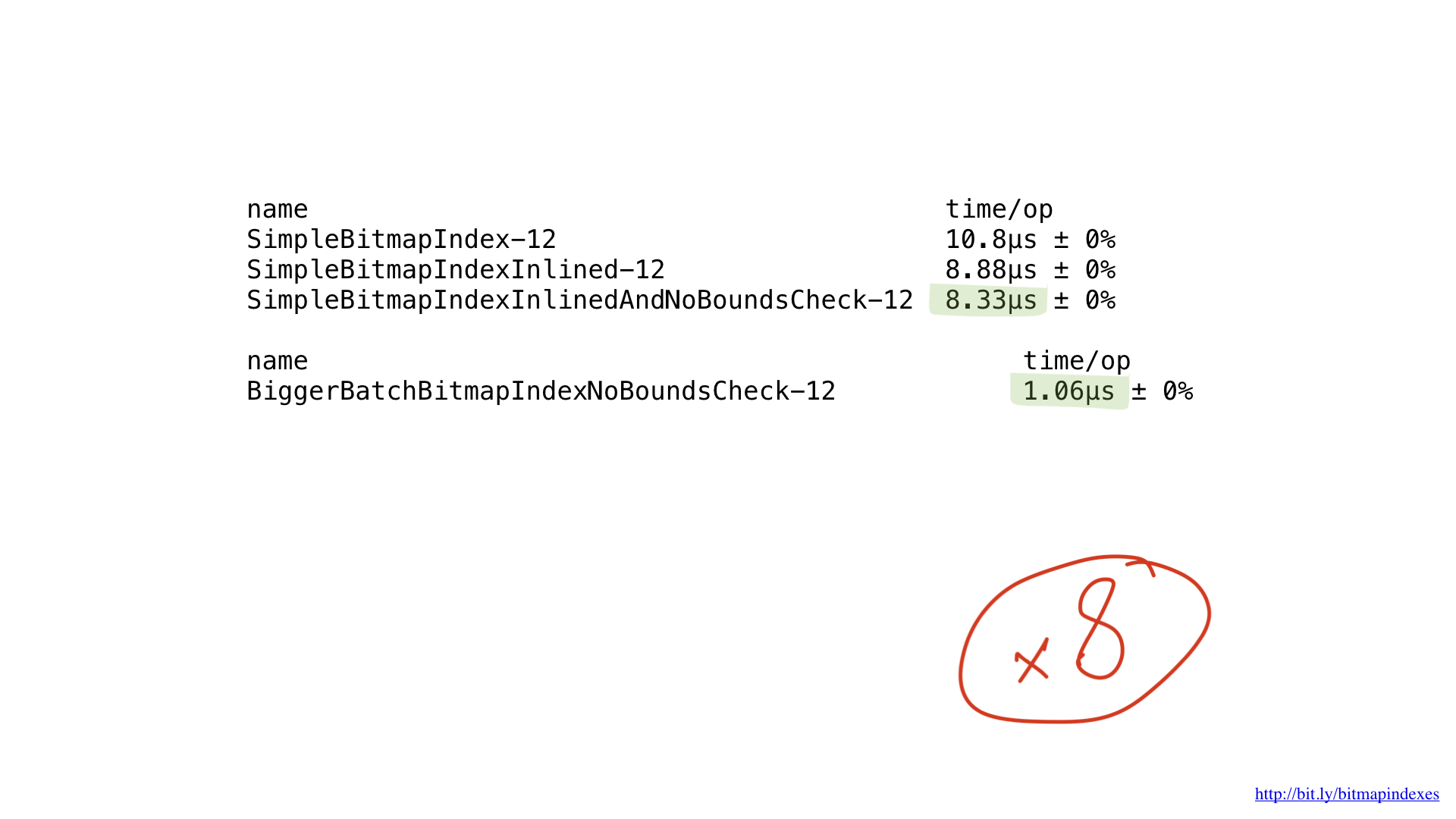
Alles, was wir tun, sind grundlegende Bitoperationen, und unsere Prozessoren führen sie sehr effizient aus. Leider „füttern“ wir unseren Prozessor mit sehr kleinen Arbeiten. Unsere Funktionen führen Operationen byteweise aus. Wir können unseren Code sehr einfach so optimieren, dass er mit 8-Byte-Chunks unter Verwendung von UInt64-Slices funktioniert.

Wie Sie sehen können, hat diese kleine Änderung unser Programm um das Achtfache beschleunigt, da die Charge um das Achtfache erhöht wurde. Die Verstärkung kann als linear bezeichnet werden.
Assembler-Implementierung

Dies ist jedoch nicht das Ende. Unsere Prozessoren können mit Teilen von 16, 32 und sogar 64 Bytes arbeiten. Solche "breiten" Operationen werden als Einzelbefehls-Mehrfachdaten (SIMD; ein Befehl, viele Daten) bezeichnet, und der Prozess der Transformation des Codes, so dass er solche Operationen verwendet, wird als Vektorisierung bezeichnet.
Leider ist der Go-Compiler kein ausgezeichneter Schüler in der Vektorisierung. Derzeit besteht die einzige Möglichkeit, Code auf Go zu vektorisieren, darin, diese Vorgänge manuell mit dem Go-Assembler auszuführen.

Assembler Go ist ein seltsames Tier. Sie wissen wahrscheinlich, dass Assembler stark an die Architektur des Computers gebunden ist, für den Sie schreiben, aber dies ist bei Go nicht der Fall. Der Go-Assembler ähnelt eher einer IRL (Intermediate Representation Language) oder einer Intermediate Language: Er ist praktisch plattformunabhängig. Rob Pike hat vor einigen Jahren auf der GopherCon in Denver eine hervorragende
Präsentation zu diesem Thema gehalten.
Darüber hinaus verwendet Go das ungewöhnliche Plan 9-Format, das sich von den allgemein anerkannten Formaten AT & T und Intel unterscheidet.

Man kann mit Sicherheit sagen, dass das manuelle Schreiben von Go Assembler nicht die unterhaltsamste Aktivität ist.
Glücklicherweise gibt es bereits zwei übergeordnete Tools, mit denen wir Go Assembler schreiben können: PeachPy und Avo. Beide Dienstprogramme generieren Go-Assembler aus höherwertigem Code, der in Python bzw. Go geschrieben ist.

Diese Dienstprogramme vereinfachen Dinge wie die Registerzuweisung, Schreibzyklen und vereinfachen im Allgemeinen den Einstieg in die Welt der Assembler-Programmierung in Go.
Wir werden avo verwenden, daher werden unsere Programme fast normale Go-Programme sein.

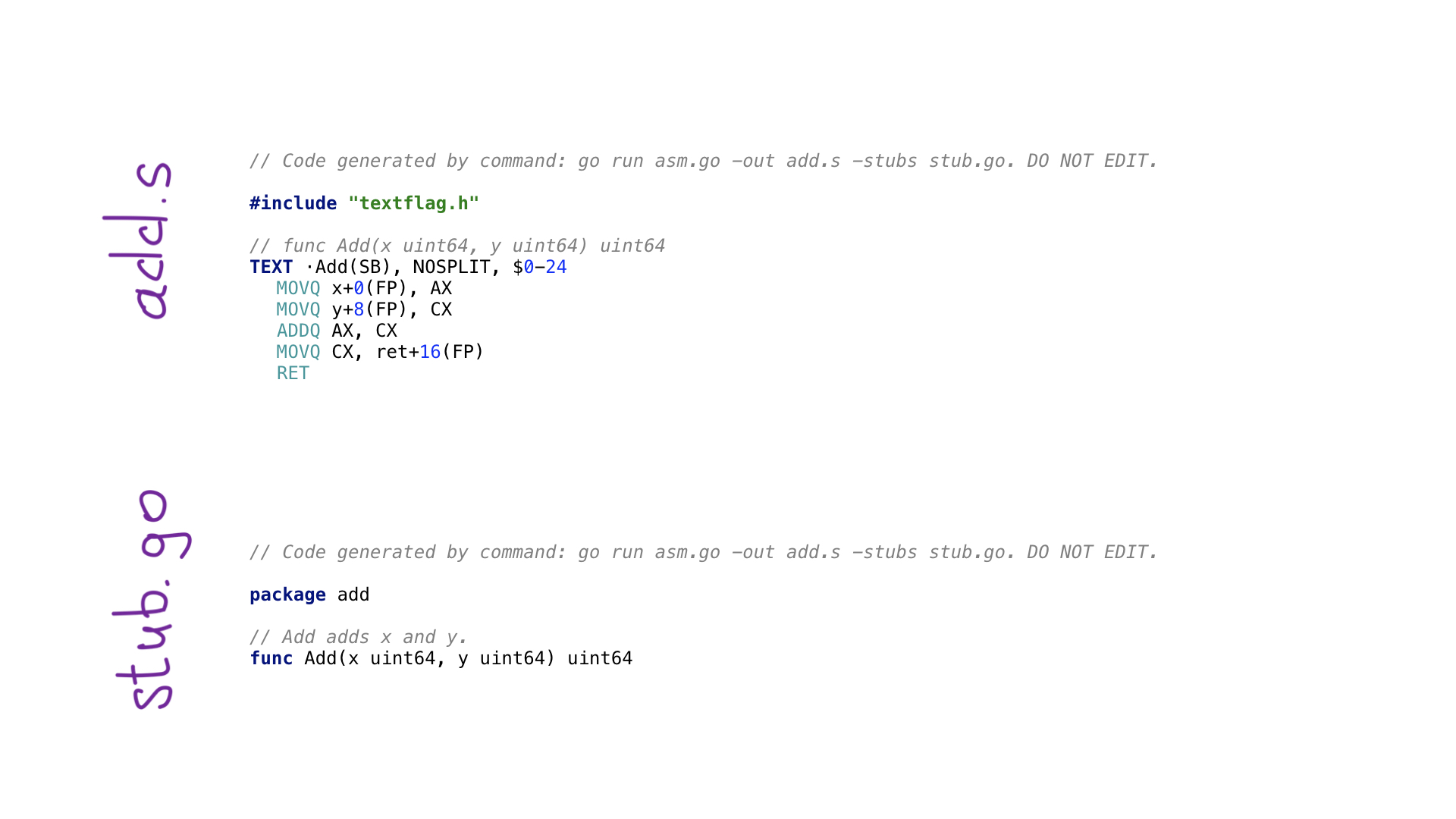
So sieht das einfachste Beispiel eines Avo-Programms aus. Wir haben eine main () - Funktion, die die Add () - Funktion in sich selbst definiert, deren Bedeutung darin besteht, zwei Zahlen hinzuzufügen. Es gibt Hilfsfunktionen zum Abrufen von Parametern nach Namen und zum Abrufen eines der freien und geeigneten Prozessorregister. Jede Prozessoroperation hat eine entsprechende Funktion auf avo, wie in ADDQ zu sehen. Schließlich sehen wir eine Hilfsfunktion zum Speichern des resultierenden Werts.

Durch den Aufruf von go generate führen wir das Programm auf avo aus und am Ende werden zwei Dateien generiert:
- add.s mit dem resultierenden Go-Assembler-Code;
- stub.go mit Funktionsheadern zum Verbinden zweier Welten: Go und Assembler.
Nachdem wir gesehen haben, was und wie Avo funktioniert, werfen wir einen Blick auf unsere Funktionen. Ich habe sowohl skalare als auch Vektorversionen (SIMD) von Funktionen implementiert.
Schauen Sie sich zunächst die skalaren Versionen an.

Wie im vorherigen Beispiel bitten wir Sie, uns ein kostenloses und korrektes Allzweckregister zur Verfügung zu stellen. Wir müssen die Offsets und Größen für die Argumente nicht berechnen. All das tut uns nichts.

Früher haben wir Labels und goto (oder Jumps) verwendet, um die Leistung zu verbessern und den Go-Compiler auszutricksen, aber jetzt machen wir das von Anfang an. Tatsache ist, dass Schleifen ein übergeordnetes Konzept sind. In Assembler haben wir nur Beschriftungen und Sprünge.

Der verbleibende Code sollte bereits bekannt und verständlich sein. Wir emulieren die Schleife mit Beschriftungen und Sprüngen, nehmen einen kleinen Teil der Daten aus unseren beiden Slices, kombinieren sie mit einer Bitoperation (UND in diesem Fall NICHT) und fügen das Ergebnis dann in das resultierende Slice ein. Das ist alles.

So sieht der endgültige Assembler-Code aus. Wir mussten weder die Offsets und Größen berechnen (grün hervorgehoben) noch die verwendeten Register verfolgen (rot hervorgehoben).
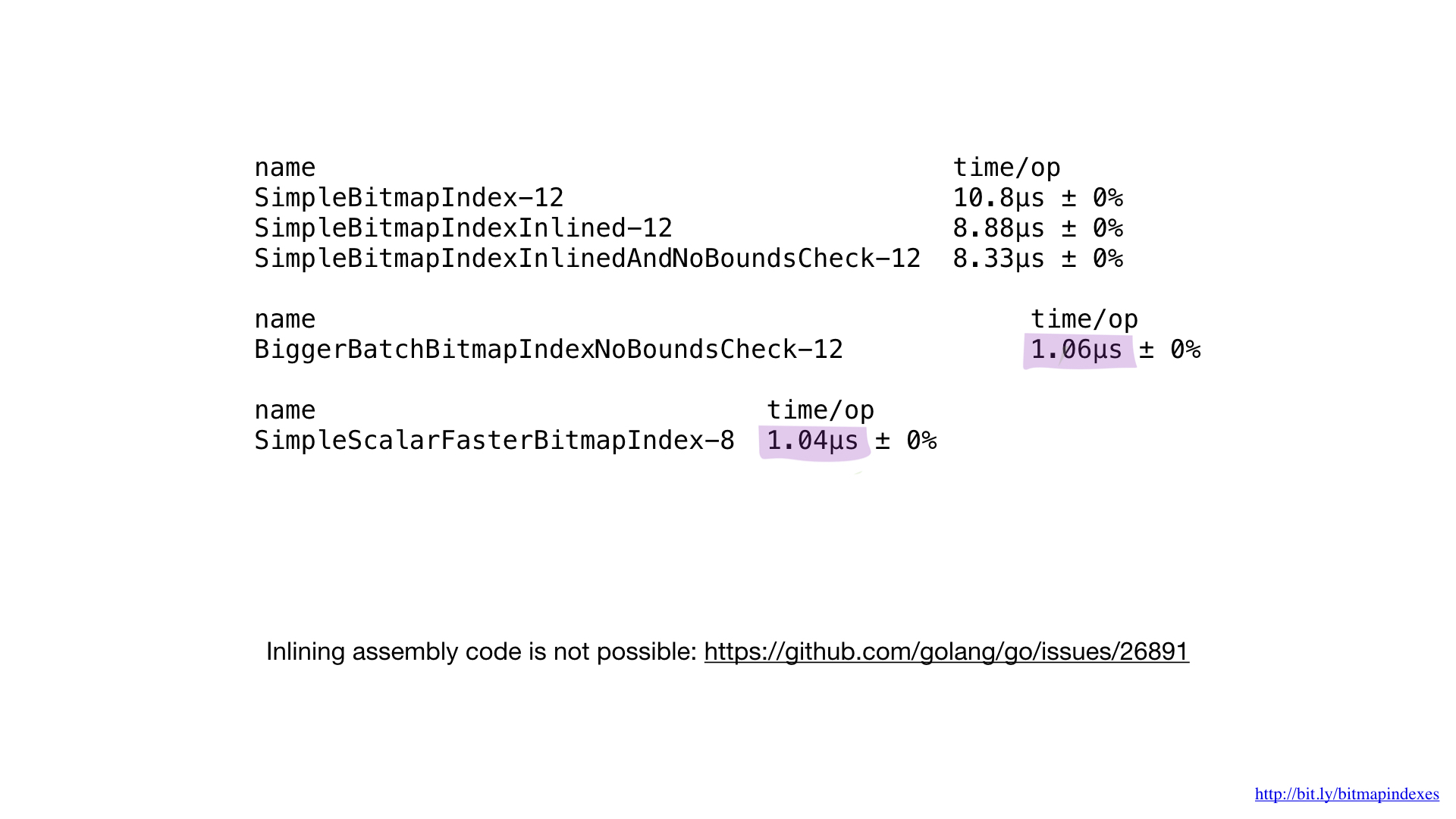
Wenn wir die Leistung der Implementierung in Assembler mit der Leistung der besten Implementierung in Go vergleichen, werden wir feststellen, dass es dieselbe ist. Und es wird erwartet. Schließlich haben wir nichts Besonderes gemacht - wir haben nur reproduziert, was der Go-Compiler tun würde.
Leider können wir den Compiler nicht zwingen, unsere in Assembler geschriebenen Funktionen zu integrieren. Der Go-Compiler verfügt heute nicht über diese Funktion, obwohl die Anforderung, sie hinzuzufügen, schon seit geraumer Zeit besteht.
Aus diesem Grund ist es unmöglich, kleine Assembler-Funktionen zu nutzen. Wir müssen entweder große Funktionen schreiben oder das neue math / bits-Paket verwenden oder die Assemblerseite umgehen.
Schauen wir uns nun die Vektorversionen unserer Funktionen an.

In diesem Beispiel habe ich mich für AVX2 entschieden, daher werden Operationen verwendet, die mit 32-Byte-Chunks arbeiten. Die Codestruktur ist der skalaren Option sehr ähnlich: Laden von Parametern, bitte stellen Sie uns ein kostenloses allgemeines Register usw. zur Verfügung.
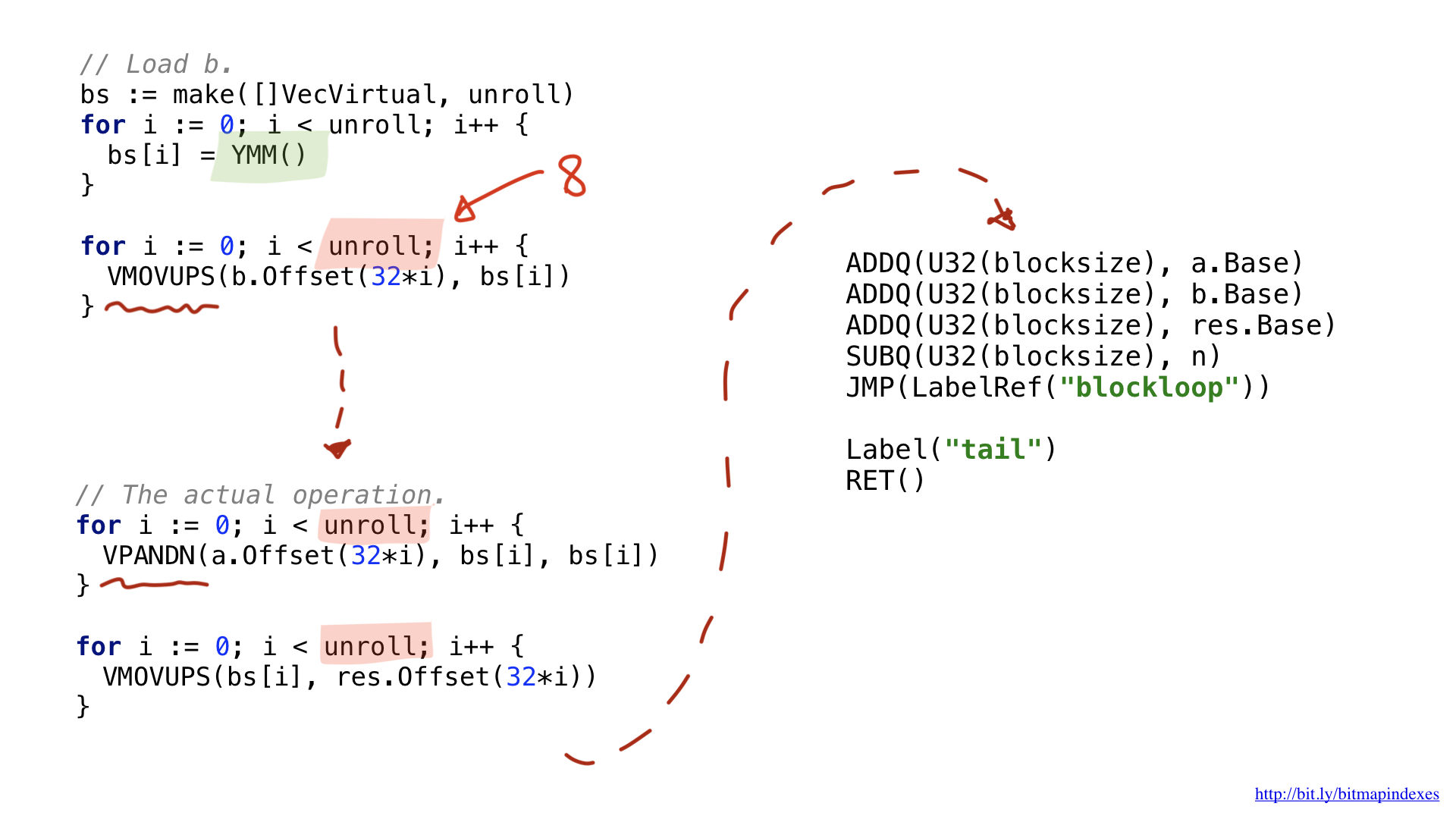
Eine der Neuerungen besteht darin, dass breitere Vektoroperationen spezielle breite Register verwenden. Bei 32-Byte-Chunks handelt es sich um Register mit dem Präfix Y. Aus diesem Grund wird im Code die Funktion YMM () angezeigt. Wenn ich den AVX-512 mit 64-Bit-Chunks verwenden würde, wäre das Präfix Z.
Die zweite Neuerung ist, dass ich mich für eine Optimierung namens Loop Unrolling entschieden habe, dh acht Loop-Operationen manuell durchzuführen, bevor ich zum Start der Loop springe. Diese Optimierung reduziert die Anzahl der Brunchs (Zweige) im Code und ist durch die Anzahl der verfügbaren freien Register begrenzt.
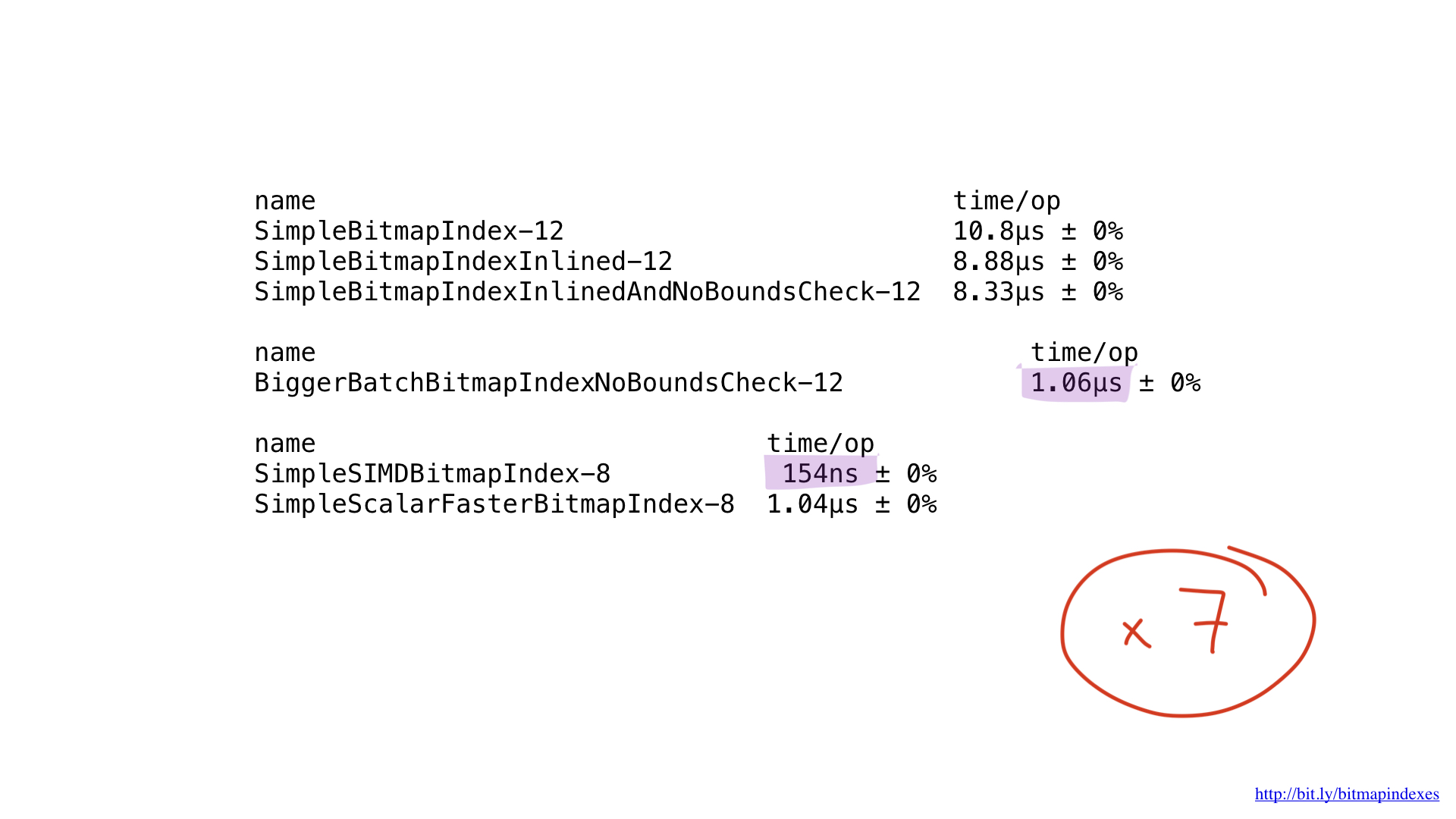
Was ist mit der Leistung? Sie ist schön! Wir haben ungefähr sieben Mal beschleunigt, verglichen mit der besten Lösung für unterwegs. Beeindruckend, oder?
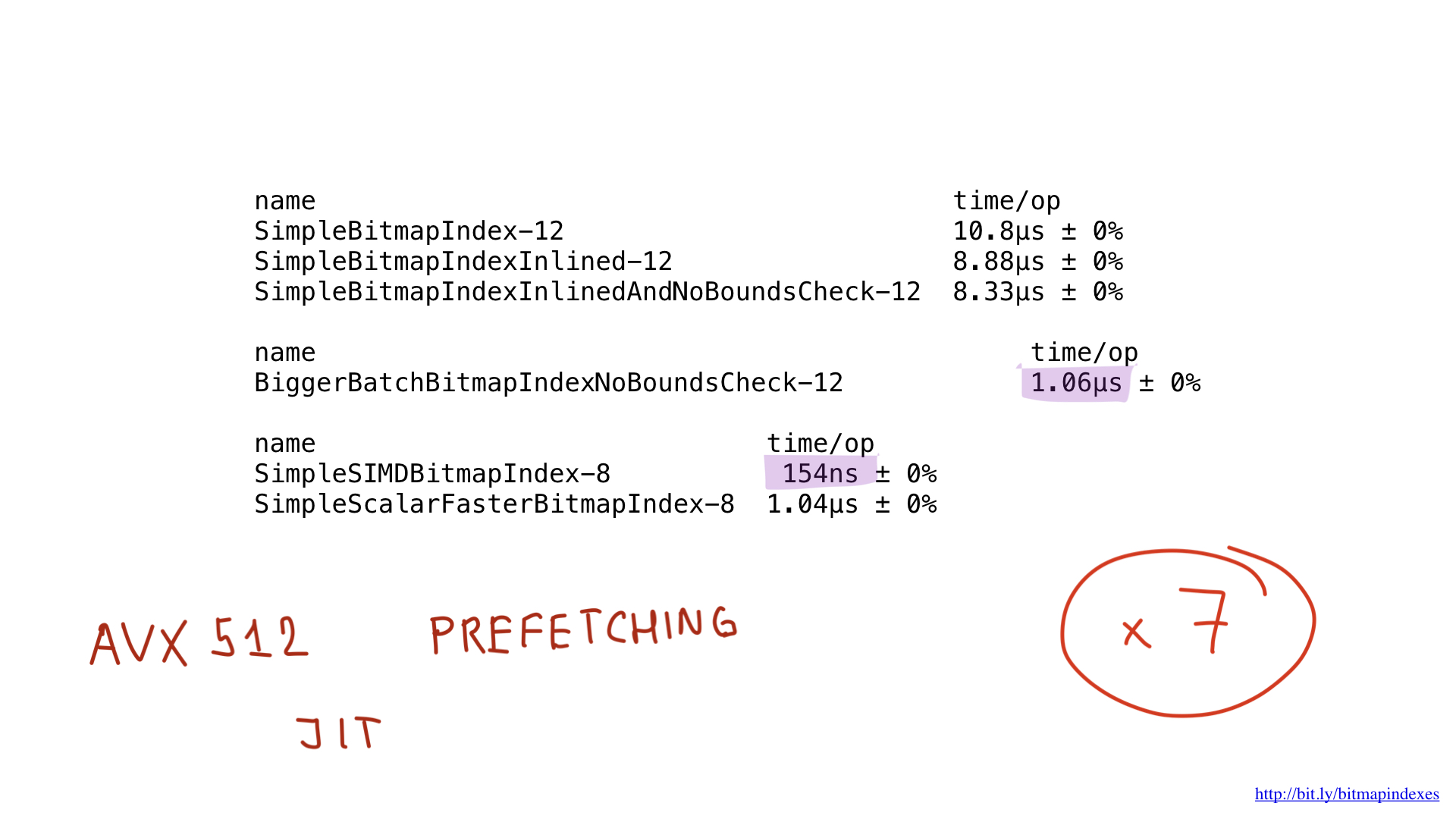
Aber auch diese Implementierung könnte möglicherweise durch die Verwendung von AVX-512, Prefetching oder JIT (Just-in-Time-Compiler) für den Abfrageplaner beschleunigt werden. Dies ist jedoch sicherlich ein Thema für einen separaten Bericht.
Probleme mit dem Bitmap-Index
Nachdem wir uns bereits eine einfache Implementierung des Go-Bitmap-Index und eine viel effizientere Assemblersprache angesehen haben, wollen wir abschließend darüber sprechen, warum Bitmap-Indizes so selten verwendet werden.

In den alten wissenschaftlichen Arbeiten werden drei Probleme von Bitmap-Indizes erwähnt, aber neuere wissenschaftliche Arbeiten und ich argumentieren, dass sie nicht mehr relevant sind. Wir werden uns nicht eingehend mit jedem dieser Probleme befassen, aber wir werden sie oberflächlich betrachten.
Das Problem der großen Kardinalität
Uns wird also gesagt, dass Bitmap-Indizes nur für Felder mit geringer Kardinalität geeignet sind, dh für Felder mit wenigen Werten (z. B. Geschlecht oder Augenfarbe), und der Grund dafür ist, dass die übliche Darstellung solcher Felder (ein Bit pro Wert) Im Falle einer großen Kardinalität nimmt es zu viel Platz ein und außerdem werden diese Bitmap-Indizes schwach (selten) gefüllt.
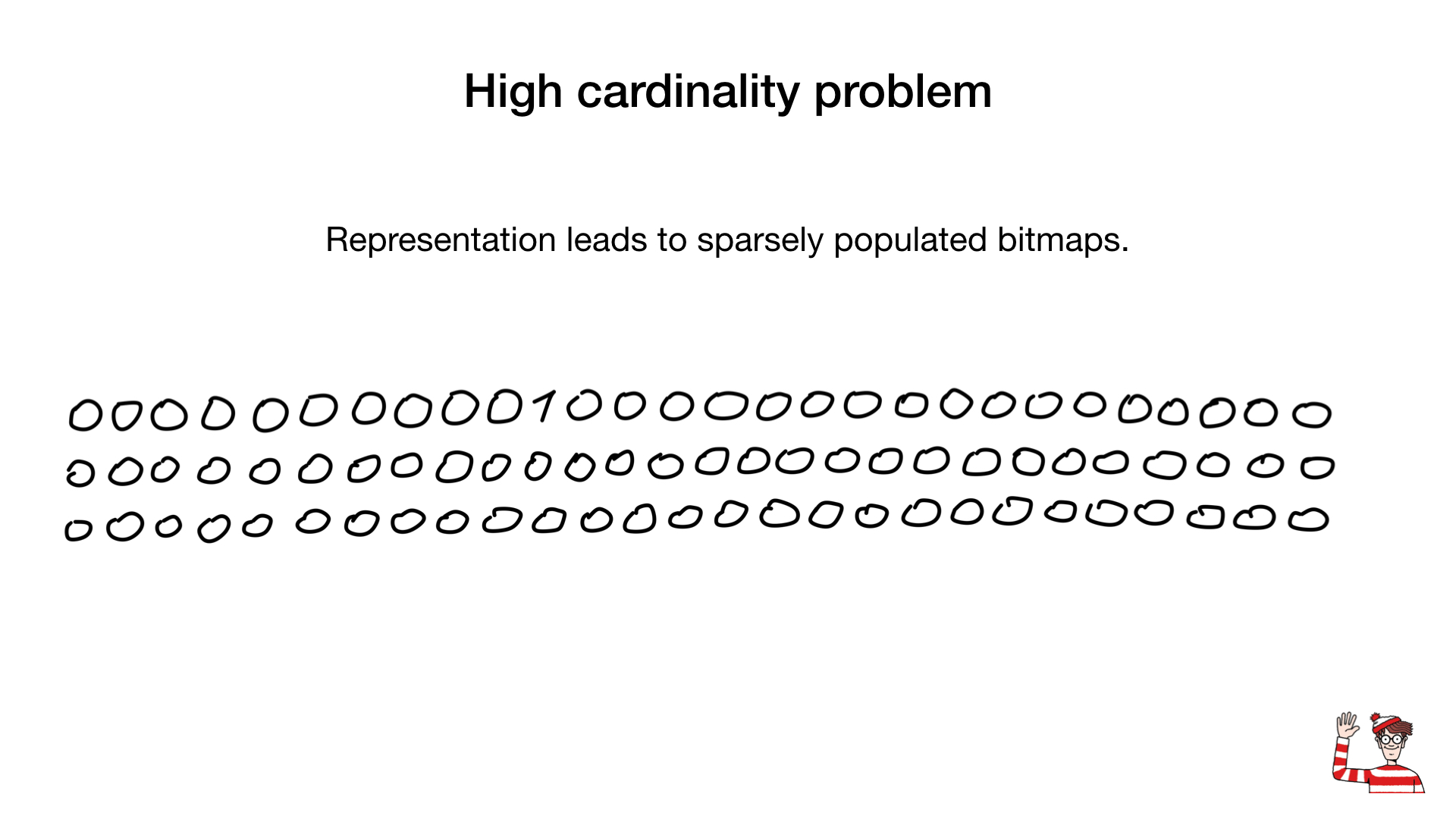
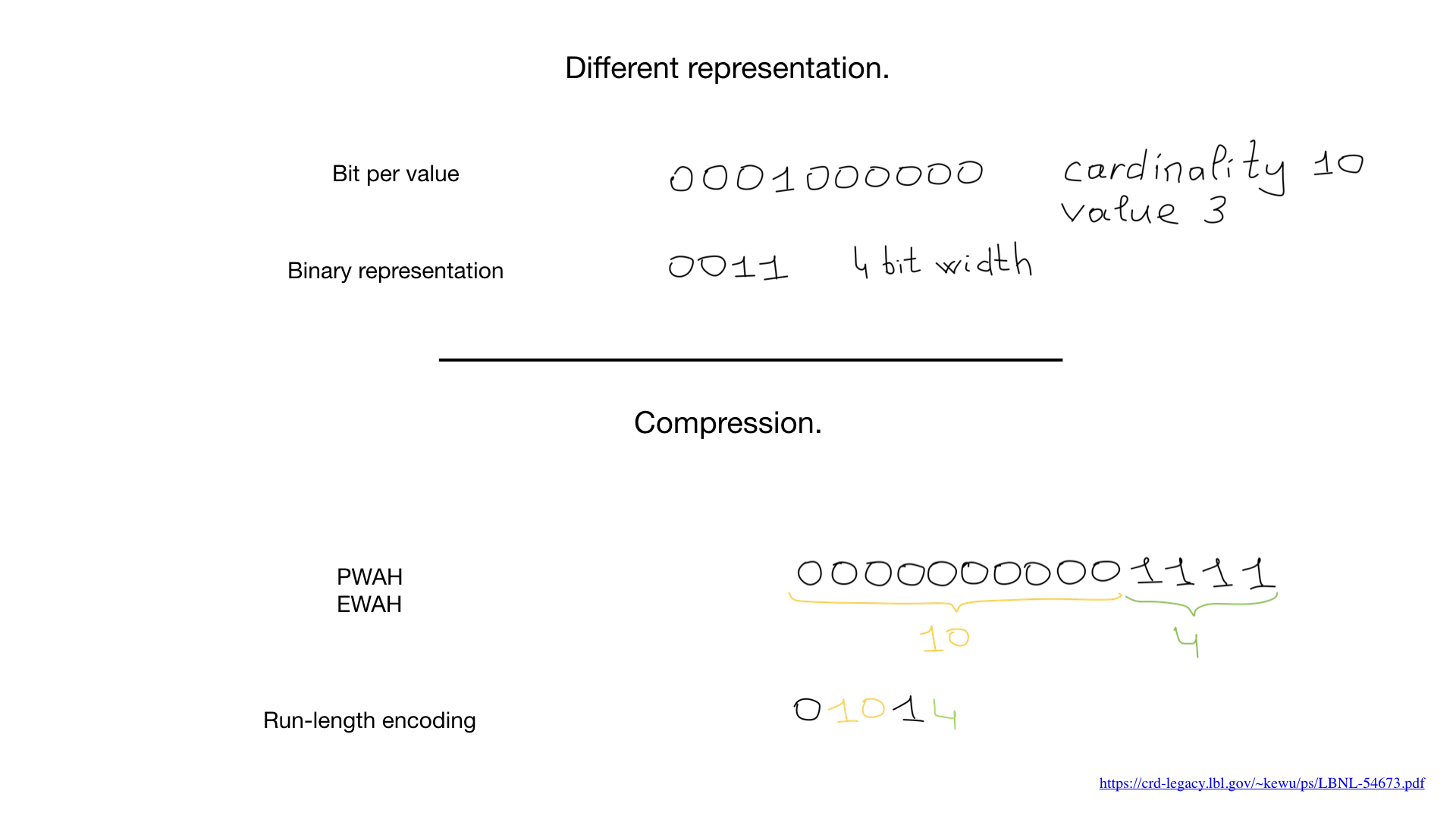 Manchmal können wir eine andere Darstellung verwenden, zum Beispiel die Standarddarstellung, mit der wir Zahlen darstellen. Aber es war das Aufkommen von Komprimierungsalgorithmen, die alles veränderten. In den letzten Jahrzehnten haben Wissenschaftler und Forscher eine Vielzahl von Komprimierungsalgorithmen für Bitmaps entwickelt. Ihr Hauptvorteil ist, dass Sie die Bitmaps für Bitoperationen nicht erweitern müssen - wir können Bitoperationen direkt auf den komprimierten Bitmaps ausführen.
Manchmal können wir eine andere Darstellung verwenden, zum Beispiel die Standarddarstellung, mit der wir Zahlen darstellen. Aber es war das Aufkommen von Komprimierungsalgorithmen, die alles veränderten. In den letzten Jahrzehnten haben Wissenschaftler und Forscher eine Vielzahl von Komprimierungsalgorithmen für Bitmaps entwickelt. Ihr Hauptvorteil ist, dass Sie die Bitmaps für Bitoperationen nicht erweitern müssen - wir können Bitoperationen direkt auf den komprimierten Bitmaps ausführen. In letzter Zeit tauchen hybride Ansätze auf, wie beispielsweise brüllende Bitmaps. Sie verwenden gleichzeitig drei verschiedene Darstellungen für Bitmaps - tatsächlich Bitmaps, Arrays und die sogenannten Bitläufe - und gleichen sie aus, um die Leistung zu maximieren und den Speicherverbrauch zu minimieren.
In letzter Zeit tauchen hybride Ansätze auf, wie beispielsweise brüllende Bitmaps. Sie verwenden gleichzeitig drei verschiedene Darstellungen für Bitmaps - tatsächlich Bitmaps, Arrays und die sogenannten Bitläufe - und gleichen sie aus, um die Leistung zu maximieren und den Speicherverbrauch zu minimieren.roaring . , Go.
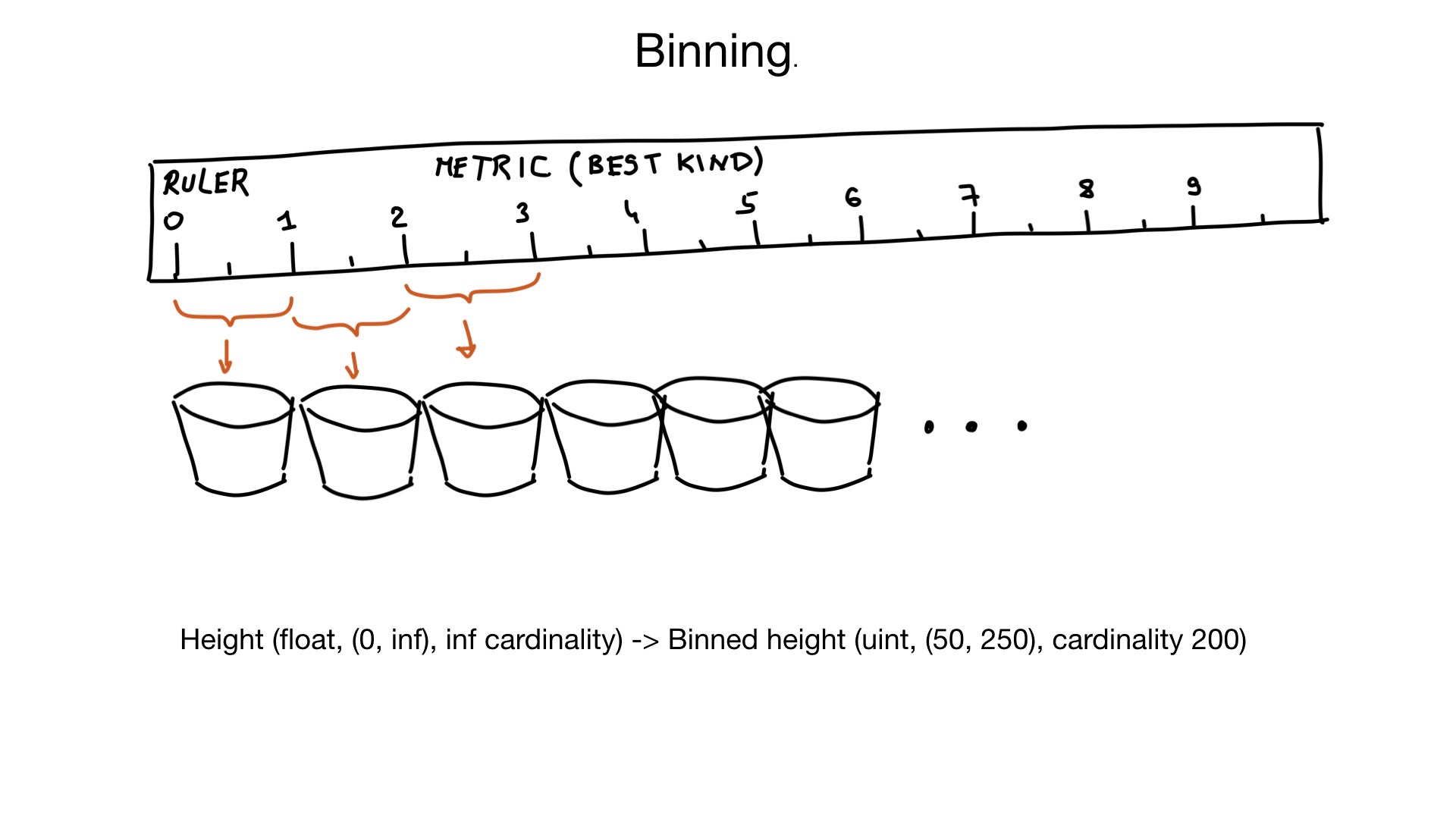
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
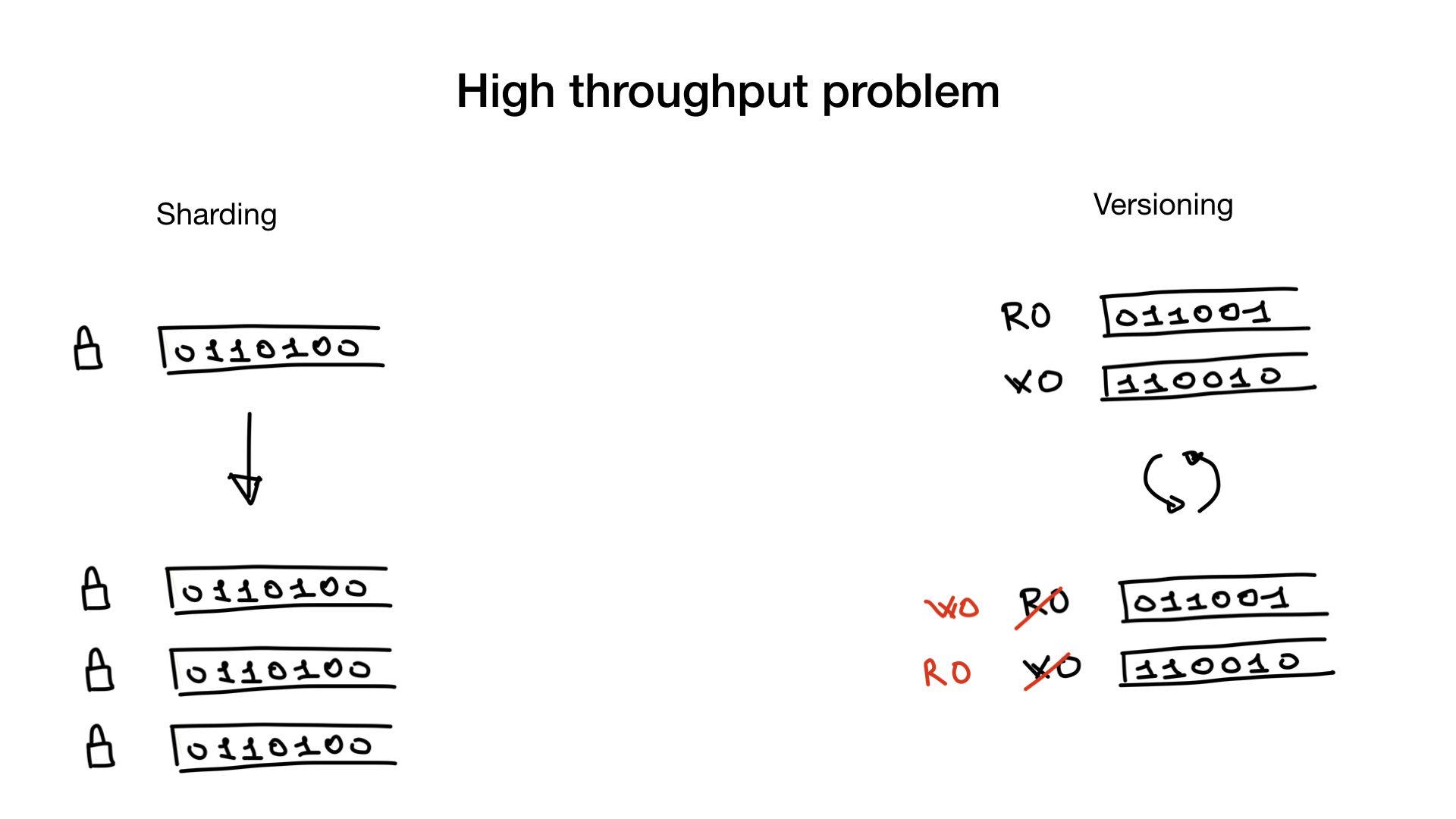
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . Usw.
, , . , 300 , , 199 . Fertig.

, bitmap-. , , . , S2 Google. , . « » ( ).
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
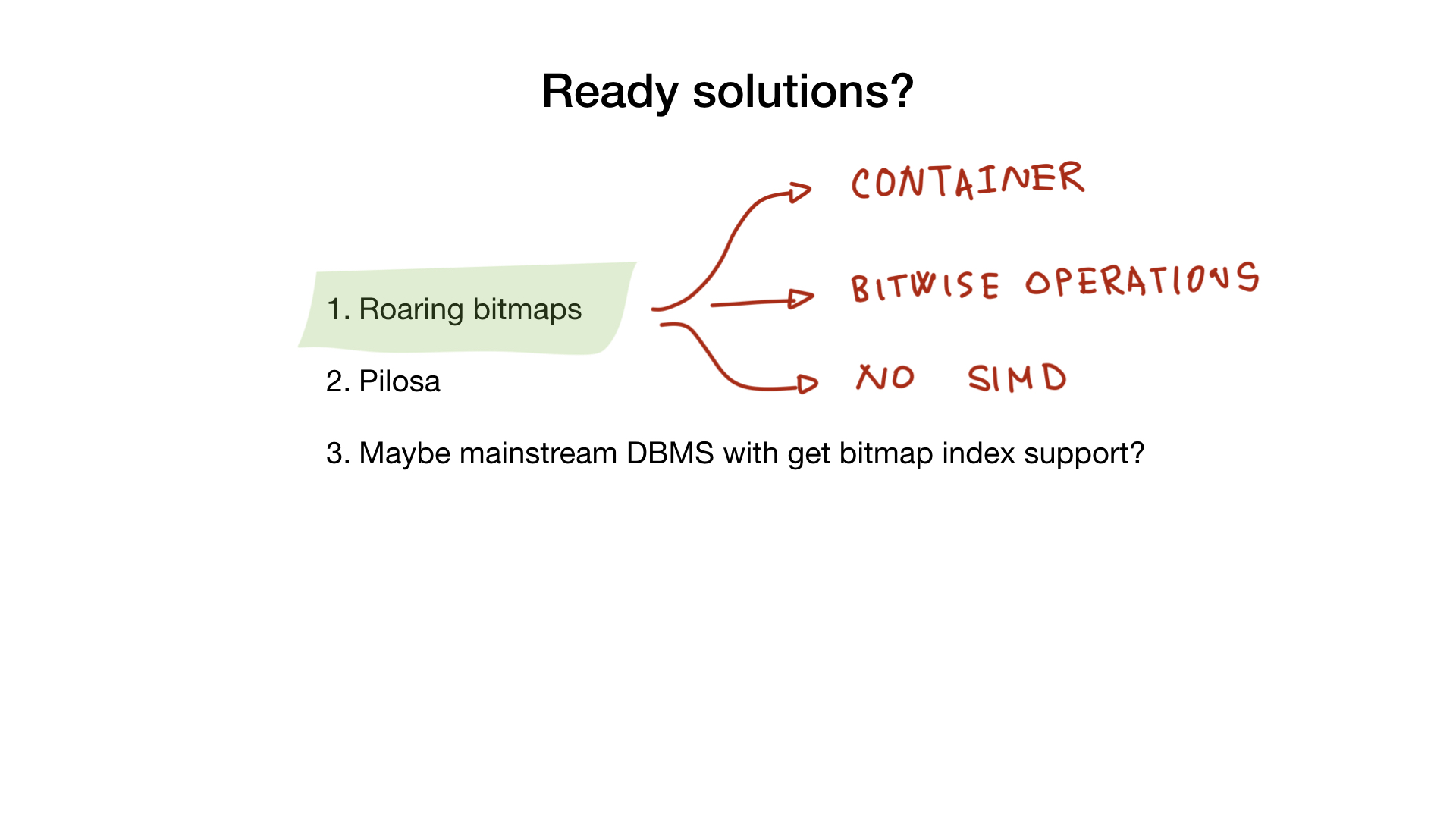
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
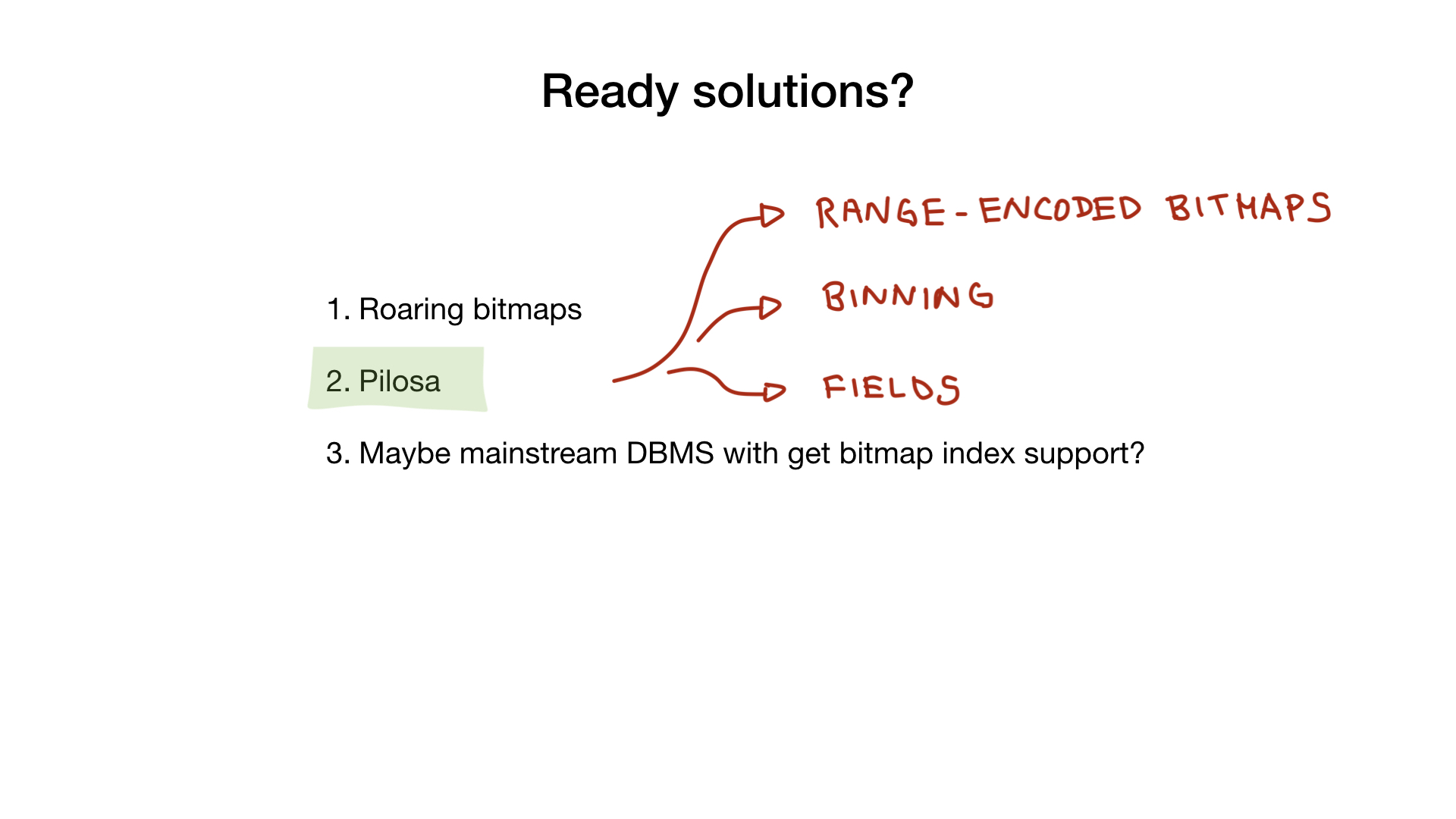
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
Danach verwenden wir NICHT auf dem "teuren" Feld und schneiden dann das Ergebnis (oder UND) mit dem Terrassenfeld und dem Reservierungsfeld. Und schließlich erhalten wir das Endergebnis. Ich hoffe wirklich, dass in absehbarer Zeit in DBMS wie MySQL und PostgreSQL auch diese neue Art von Indizes erscheinen wird - Bitmap-Indizes.
Ich hoffe wirklich, dass in absehbarer Zeit in DBMS wie MySQL und PostgreSQL auch diese neue Art von Indizes erscheinen wird - Bitmap-Indizes.
Fazit

Wenn Sie noch nicht eingeschlafen sind, danke. Ich musste wegen der begrenzten Zeit im Vorbeigehen auf viele Themen eingehen, aber ich hoffe, dass der Bericht nützlich und vielleicht sogar motivierend war.
Es ist gut, über Bitmap-Indizes Bescheid zu wissen, auch wenn Sie sie gerade nicht benötigen. Lassen Sie sie ein weiteres Werkzeug in Ihrer Schublade sein.
Wir haben verschiedene Performance-Tricks für Go und die Dinge behandelt, mit denen der Go-Compiler nicht sehr gut zurechtkommt. Aber es ist absolut nützlich, dass jeder Go-Programmierer es weiß.
Das ist alles was ich erzählen wollte. Vielen Dank!