Wir haben bereits die PostgreSQL-
Indizierungs-Engine , die Schnittstelle von Zugriffsmethoden und Hauptzugriffsmethoden wie
Hash-Indizes ,
B-Bäume ,
GiST ,
SP-GiST und
GIN erörtert . In diesem Artikel werden wir sehen, wie aus Gin Rum wird.
RUM
Obwohl die Autoren behaupten, Gin sei ein mächtiger Geist, hat das Thema Getränke schließlich gewonnen: GIN der nächsten Generation wurde RUM genannt.
Diese Zugriffsmethode erweitert das Konzept, das GIN zugrunde liegt, und ermöglicht es uns, die Volltextsuche noch schneller durchzuführen. In dieser Artikelserie ist dies die einzige Methode, die nicht in einer Standard-PostgreSQL-Lieferung enthalten ist und eine externe Erweiterung darstellt. Hierfür stehen mehrere Installationsoptionen zur Verfügung:
- Nehmen Sie das Paket "yum" oder "apt" aus dem PGDG-Repository . Wenn Sie beispielsweise PostgreSQL aus dem Paket "postgresql-10" installiert haben, installieren Sie auch "postgresql-10-rum".
- Erstellen Sie aus dem Quellcode auf Github und installieren Sie es selbst (die Anweisung ist ebenfalls vorhanden).
- Verwenden Sie es als Teil von Postgres Pro Enterprise (oder lesen Sie zumindest die Dokumentation von dort).
Einschränkungen von Gin
Welche Einschränkungen von GIN können wir mit RUM überwinden?
Erstens enthält der Datentyp "tsvector" nicht nur Lexeme, sondern auch Informationen zu ihren Positionen innerhalb des Dokuments. Wie wir
letztes Mal festgestellt
haben , speichert der GIN-Index diese Informationen nicht. Aus diesem Grund werden Operationen zur Suche nach Phrasen, die in Version 9.6 enthalten waren, vom GIN-Index ineffizient unterstützt und müssen zur erneuten Überprüfung auf die Originaldaten zugreifen.
Zweitens geben Suchsysteme die Ergebnisse normalerweise sortiert nach Relevanz zurück (was auch immer das bedeutet). Zu diesem Zweck können wir die Ranking-Funktionen "ts_rank" und "ts_rank_cd" verwenden, aber sie müssen für jede Zeile des Ergebnisses berechnet werden, was sicherlich langsam ist.
In erster Näherung kann die RUM-Zugriffsmethode als GIN betrachtet werden, die zusätzlich Positionsinformationen speichert und die Ergebnisse in einer erforderlichen Reihenfolge
zurückgibt (wie
GiST die nächsten Nachbarn zurückgeben kann). Gehen wir Schritt für Schritt vor.
Nach Phrasen suchen
Eine Volltextsuchabfrage kann spezielle Operatoren enthalten, die den Abstand zwischen Lexemen berücksichtigen. Zum Beispiel können wir Dokumente finden, in denen "Hand" mit zwei weiteren Wörtern von "Oberschenkel" getrennt ist:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
Oder wir können angeben, dass die Wörter nacheinander stehen müssen:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
Der reguläre GIN-Index kann die Dokumente zurückgeben, die beide Lexeme enthalten, aber wir können den Abstand zwischen ihnen nur überprüfen, indem wir in tsvector schauen:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
Im RUM-Index verweist jedes Lexem nicht nur auf die Tabellenzeilen: Jede TID wird mit der Liste der Positionen geliefert, an denen das Lexem im Dokument vorkommt. So können wir uns den Index vorstellen, der für die "Slit-Sheet" -Tabelle erstellt wurde, die uns bereits bekannt ist (die Operatorklasse "rum_tsvector_ops" wird standardmäßig für tsvector verwendet):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
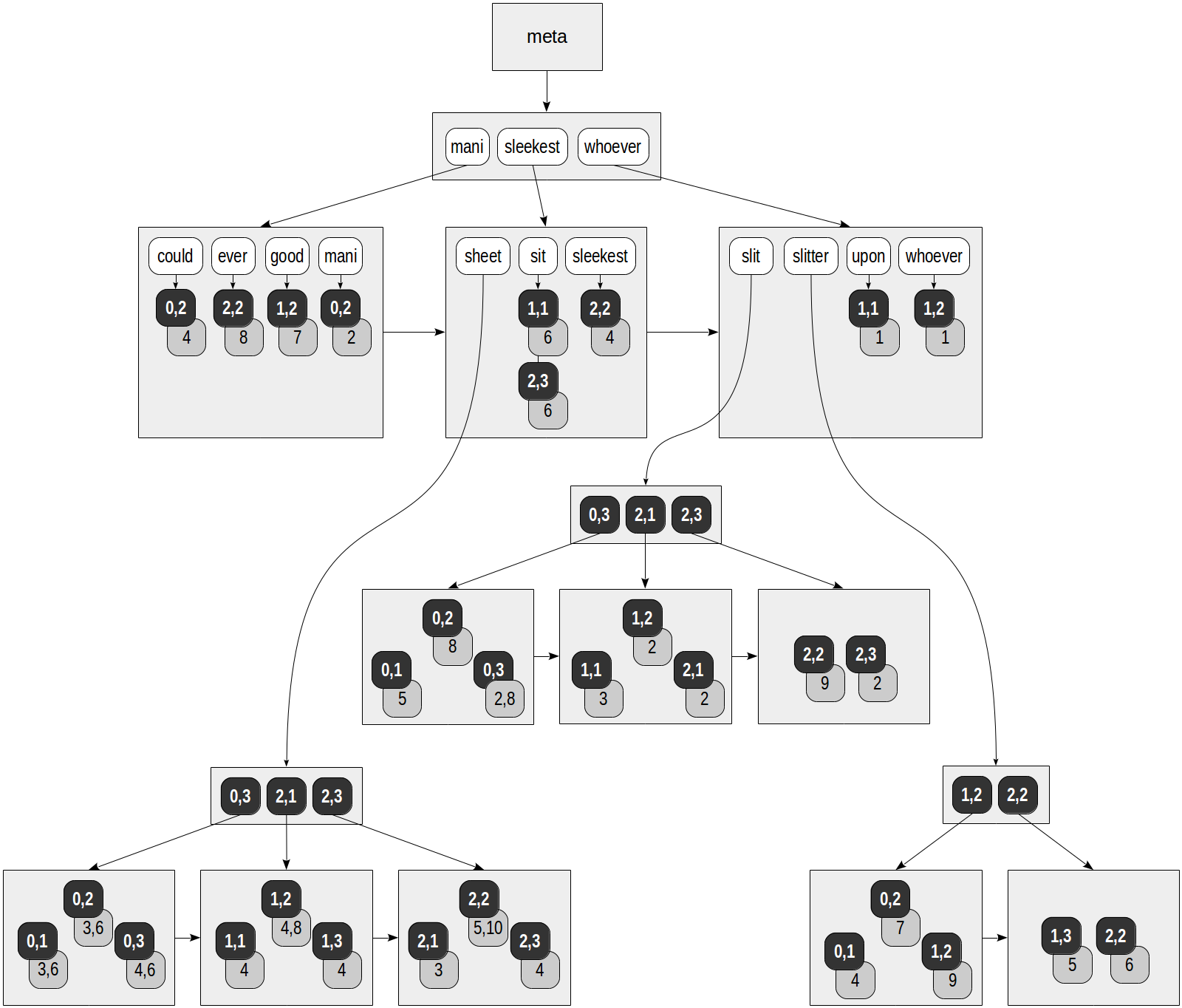
Graue Quadrate in der Abbildung enthalten die hinzugefügten Positionsinformationen:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
GIN bietet auch eine verschobene Einfügung, wenn der Parameter "fastupdate" angegeben ist. Diese Funktionalität wird aus RUM entfernt.
Um zu sehen, wie der Index für Live-Daten funktioniert, verwenden wir das vertraute
Archiv der Mailingliste von pgsql-hackers.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
So wird eine Abfrage ausgeführt, bei der nach Phrasen gesucht wird, mit dem GIN-Index:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
Wie aus dem Plan hervorgeht, wird der GIN-Index verwendet, der jedoch 1776 potenzielle Übereinstimmungen zurückgibt, von denen 259 übrig bleiben und 1517 bei der erneuten Überprüfung gelöscht werden.
Löschen wir den GIN-Index und erstellen RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
Der Index enthält jetzt alle erforderlichen Informationen, und die Suche wird genau durchgeführt:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
Sortieren nach Relevanz
Um Dokumente problemlos in der erforderlichen Reihenfolge zurückzugeben, unterstützt der RUM-Index
Bestelloperatoren , die wir in
einem Artikel zu
GiST besprochen
haben . Die RUM-Erweiterung definiert einen solchen Operator
<=> , der einen gewissen Abstand zwischen dem Dokument ("tsvector") und der Abfrage ("tsquery") zurückgibt. Zum Beispiel:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
Das Dokument schien für die erste Abfrage relevanter zu sein als für die zweite: Je öfter das Wort vorkommt, desto weniger "wertvoll" ist es.
Versuchen wir noch einmal, GIN und RUM bei einer relativ großen Datenmenge zu vergleichen: Wir werden zehn relevanteste Dokumente auswählen, die "Hallo" und "Hacker" enthalten.
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
Der GIN-Index gibt 1776 Übereinstimmungen zurück, die dann als separater Schritt sortiert werden, um die zehn besten Treffer auszuwählen.
Beim RUM-Index wird die Abfrage mithilfe eines einfachen Index-Scans ausgeführt: Es werden keine zusätzlichen Dokumente durchsucht und es ist keine separate Sortierung erforderlich:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
Zusätzliche Informationen
Der RUM-Index sowie GIN können auf mehreren Feldern erstellt werden. Während GIN Lexeme aus jeder Spalte unabhängig von denen aus einer anderen Spalte speichert, können wir mit RUM das Hauptfeld (in diesem Fall "tsvector") einem zusätzlichen Feld "zuordnen". Dazu benötigen wir eine spezielle Operatorklasse "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
Wir können diesen Index verwenden, um die nach dem zusätzlichen Feld sortierten Ergebnisse zurückzugeben:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
Hier suchen wir nach übereinstimmenden Zeilen, die dem angegebenen Datum so nahe wie möglich kommen, unabhängig davon, ob sie früher oder später vorliegen. Um die Ergebnisse zu erhalten, die genau vor (oder nach) dem angegebenen Datum liegen, müssen wir
<=| (oder
|=> ) Operator.
Wie erwartet wird die Abfrage nur durch einen einfachen Index-Scan ausgeführt:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
Wenn wir den Index ohne die zusätzlichen Informationen zur Feldzuordnung erstellen würden, müssten wir für eine ähnliche Abfrage alle Ergebnisse des Indexscans sortieren.
Zusätzlich zum Datum können wir dem RUM-Index sicherlich Felder anderer Datentypen hinzufügen. Nahezu alle Basistypen werden unterstützt. Beispielsweise kann ein Online-Shop Waren schnell nach Neuheit (Datum), Preis (numerisch) und Beliebtheit oder Rabattwert (Ganzzahl oder Gleitkomma) anzeigen.
Andere Operatorklassen
Um das Bild zu vervollständigen, sollten wir andere verfügbare Operatorklassen erwähnen.
Beginnen wir mit
"rum_tsvector_hash_ops" und
"rum_tsvector_hash_addon_ops" . Sie ähneln den bereits diskutierten "rum_tsvector_ops" und "rum_tsvector_addon_ops", aber der Index speichert den Hash-Code des Lexems und nicht des Lexems selbst. Dies kann die Indexgröße verringern, aber natürlich wird die Suche ungenauer und erfordert eine erneute Überprüfung. Außerdem unterstützt der Index die Suche nach einer Teilübereinstimmung nicht mehr.
Es ist interessant, sich die Operatorklasse
"rum_tsquery_ops" anzusehen . Es ermöglicht uns, ein "inverses" Problem zu lösen: Abfragen zu finden, die mit dem Dokument übereinstimmen. Warum könnte das nötig sein? Zum Beispiel, um einen Benutzer nach seinem Filter für neue Waren zu abonnieren oder neue Dokumente automatisch zu kategorisieren. Schauen Sie sich dieses einfache Beispiel an:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
Die verbleibenden Operatorklassen
"rum_anyarray_ops" und
"rum_anyarray_addon_ops" dienen zur Manipulation von Arrays anstelle von "tsvector". Dies wurde bereits beim
letzten Mal für GIN besprochen und muss nicht wiederholt werden.
Die Größe des Index und des Write-Ahead-Protokolls (WAL)
Es ist klar, dass RUM, da es mehr Informationen als GIN speichert, eine größere Größe haben muss. Wir haben beim letzten Mal die Größen verschiedener Indizes verglichen. Fügen wir dieser Tabelle RUM hinzu:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
Wie wir sehen können, ist die Größe erheblich gewachsen, was die Kosten für eine schnelle Suche sind.
Es lohnt sich, auf einen weiteren nicht offensichtlichen Punkt zu achten: RUM ist eine Erweiterung, dh sie kann ohne Änderungen am Systemkern installiert werden. Dies wurde in Version 9.6 dank eines Patches von
Alexander Korotkov ermöglicht . Eines der Probleme, die zu diesem Zweck gelöst werden mussten, war die Erstellung von Protokolldatensätzen. Eine Technik zur Protokollierung von Vorgängen muss absolut zuverlässig sein, daher kann eine Erweiterung nicht in diese Küche eingelassen werden. Anstatt der Erweiterung zu erlauben, ihre eigenen Arten von Protokolldatensätzen zu erstellen, ist Folgendes vorhanden: Der Code der Erweiterung teilt ihre Absicht mit, eine Seite zu ändern, nimmt Änderungen daran vor und signalisiert den Abschluss, und es ist der Systemkern. Hiermit werden die alten und neuen Versionen der Seite verglichen und die erforderlichen einheitlichen Protokolldatensätze generiert.
Der aktuelle Protokollgenerierungsalgorithmus vergleicht Seiten Byte für Byte, erkennt aktualisierte Fragmente und protokolliert jedes dieser Fragmente zusammen mit seinem Versatz vom Seitenanfang. Dies funktioniert gut, wenn nur einige Bytes oder die gesamte Seite aktualisiert werden. Wenn wir jedoch ein Fragment innerhalb einer Seite hinzufügen, den Rest des Inhalts nach unten verschieben (oder umgekehrt, ein Fragment entfernen, den Inhalt nach oben verschieben), ändern sich erheblich mehr Bytes als tatsächlich hinzugefügt oder entfernt wurden.
Aus diesem Grund können durch eine intensive Änderung des RUM-Index Protokolldatensätze mit einer erheblich größeren Größe als GIN generiert werden (das keine Erweiterung, sondern Teil des Kerns ist und das Protokoll selbst verwaltet). Das Ausmaß dieses störenden Effekts hängt stark von der tatsächlichen Arbeitsbelastung ab. Um jedoch einen Einblick in das Problem zu erhalten, versuchen wir, mehrere Zeilen mehrmals zu entfernen und hinzuzufügen, wobei diese Vorgänge mit „Vakuum“ verschachtelt werden. Wir können die Größe von Protokolldatensätzen wie folgt bewerten: Merken Sie sich am Anfang und am Ende die Position im Protokoll mit der Funktion "pg_current_wal_location" ("pg_current_xlog_location" in früheren Versionen als zehn) und sehen Sie sich dann den Unterschied an.
Aber natürlich sollten wir hier viele Aspekte berücksichtigen. Wir müssen sicherstellen, dass nur ein Benutzer mit dem System arbeitet (andernfalls werden "zusätzliche" Datensätze berücksichtigt). Selbst wenn dies der Fall ist, berücksichtigen wir nicht nur RUM, sondern auch Aktualisierungen der Tabelle selbst und des Index, der den Primärschlüssel unterstützt. Die Werte der Konfigurationsparameter wirken sich auch auf die Größe aus (hier wurde die Protokollstufe "Replikat" ohne Komprimierung verwendet). Aber lass es uns trotzdem versuchen.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
Wir bekommen also ungefähr 3 GB. Wenn wir jedoch dasselbe Experiment mit dem GIN-Index wiederholen, ergibt dies nur etwa 700 MB.
Daher ist es wünschenswert, einen anderen Algorithmus zu haben, der die minimale Anzahl von Einfüge- und Löschvorgängen findet, die einen Zustand der Seite in einen anderen umwandeln können. Das Dienstprogramm "Diff" funktioniert auf ähnliche Weise.
Oleg Ivanov hat einen solchen Algorithmus bereits implementiert und sein
Patch wird diskutiert. Im obigen Beispiel können wir mit diesem Patch die Größe von Protokolldatensätzen auf Kosten einer kleinen Verlangsamung um das 1,5-fache auf 1900 MB reduzieren.
Leider ist der Patch hängen geblieben und es gibt keine Aktivität um ihn herum.
Eigenschaften
Schauen wir uns wie üblich die Eigenschaften der RUM-Zugriffsmethode an und achten wir dabei auf die Unterschiede zu GIN (Abfragen
wurden bereits bereitgestellt ).
Im Folgenden sind die Eigenschaften der Zugriffsmethode aufgeführt:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
Die folgenden Indexschicht-Eigenschaften sind verfügbar:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
Beachten Sie, dass RUM im Gegensatz zu GIN den Index-Scan unterstützt. Andernfalls wäre es nicht möglich gewesen, bei Abfragen mit der "limit" -Klausel genau die erforderliche Anzahl von Ergebnissen zurückzugeben. Das Gegenstück zum Parameter "gin_fuzzy_search_limit" ist dementsprechend nicht erforderlich. Infolgedessen kann der Index zur Unterstützung von Ausschlussbeschränkungen verwendet werden.
Die folgenden Eigenschaften sind Spaltenebenen:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
Der Unterschied besteht darin, dass RUM Bestelloperatoren unterstützt. Dies gilt jedoch nicht für alle Operatorklassen. Dies gilt beispielsweise für "tsquery_ops".
Lesen Sie weiter .