Hallo.
Wussten Sie, dass Anzeigenplattformen häufig Inhalte von Wettbewerbern kopieren, um die Anzahl der von ihnen gehosteten Anzeigen zu erhöhen? Sie machen es so: Sie rufen Verkäufer an und bieten ihnen an, sich auf ihrer Plattform niederzulassen. Und manchmal kopieren sie Anzeigen vollständig ohne Benutzererlaubnis. Avito ist ein beliebter Veranstaltungsort, und wir stoßen häufig auf solch unlauteren Wettbewerb. Lesen Sie, wie wir dieses Phänomen bekämpfen, lesen Sie unter dem Schnitt.

Das Problem
Das Kopieren von Inhalten von Avito auf andere Plattformen erfolgt in verschiedenen Kategorien von Waren und Dienstleistungen. Dieser Artikel konzentriert sich nur auf Autos. In einem früheren Beitrag habe ich darüber gesprochen, wie wir automatische Nummern versteckt haben, die sich auf Autos verstecken.

Es stellte sich jedoch heraus (gemessen an den Suchergebnissen anderer Plattformen), dass wir diese Funktion sofort auf drei Ankündigungsseiten gestartet haben.

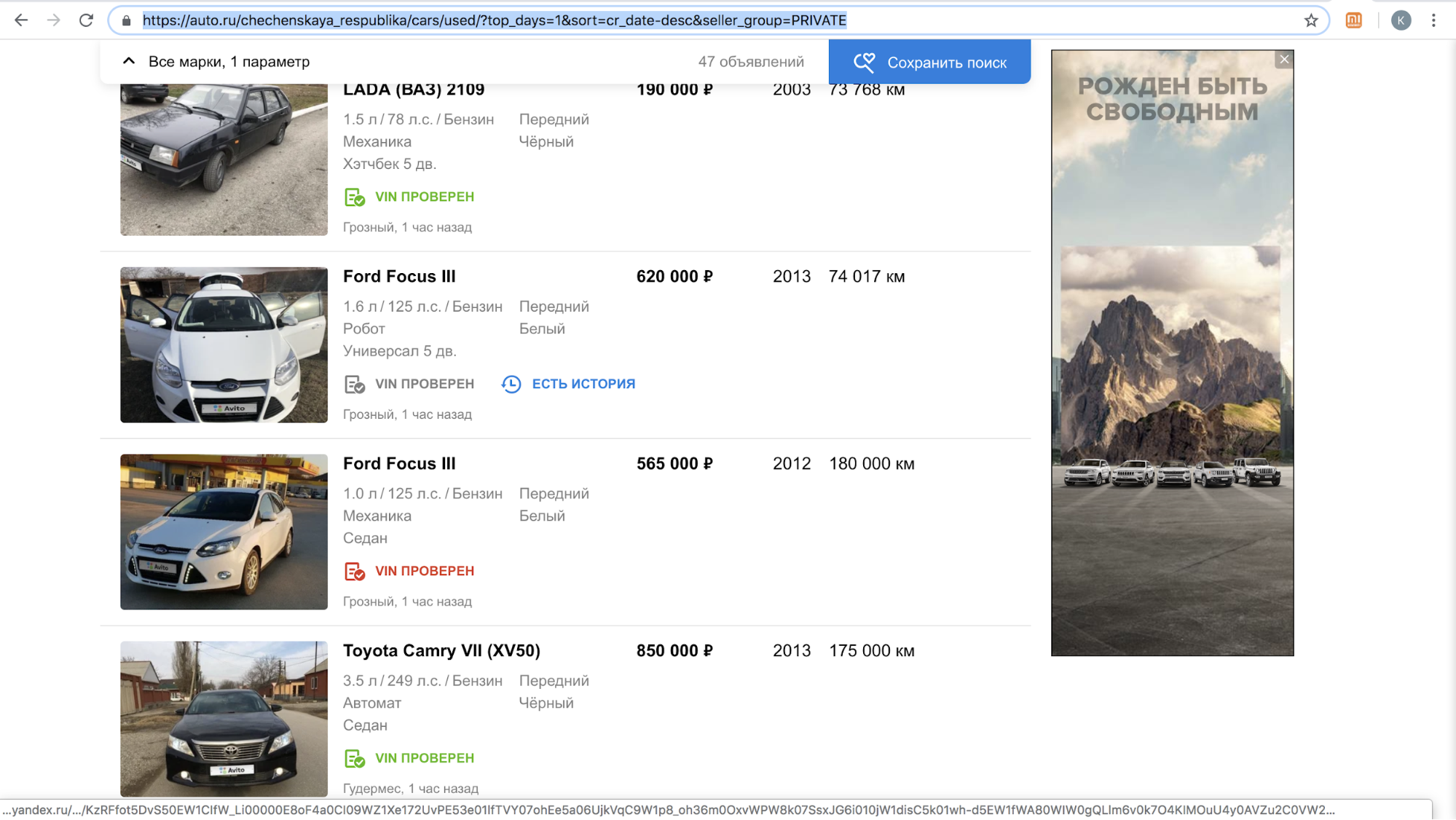
Nach dem Start einer Funktion wurde eine dieser Websites vorübergehend eingestellt, um unsere Benutzer mit Angeboten zum Kopieren der Ankündigung auf ihrer Plattform anzurufen: Es gab zu viel Inhalt mit dem Avito-Logo auf ihrer Website, allein im November 2018 gab es mehr als 70.000 Anzeigen. So sahen beispielsweise die Suchergebnisse pro Tag in der Tschetschenischen Republik aus.
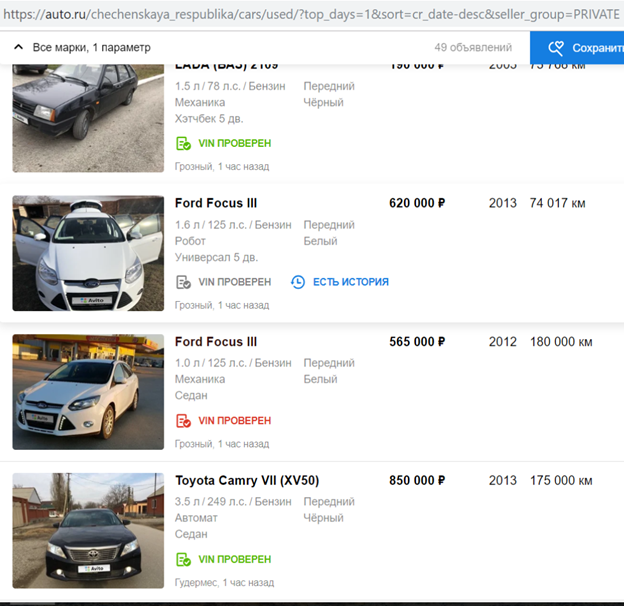
Nachdem sie ihren Algorithmus zum Ausblenden von Nummernschildern abgeschlossen hatten, damit das Avito-Logo automatisch erkannt und geschlossen wird, setzten sie den Vorgang fort.

Aus unserer Sicht ist es unethisch und inakzeptabel, Inhalte von Wettbewerbern zu kopieren und für kommerzielle Zwecke zu verwenden. Wir erhalten Beschwerden von unseren Nutzern, die damit unzufrieden sind, in unserer Unterstützung. Und hier ist ein Beispiel für eine Reaktion in einer der Geschichten.
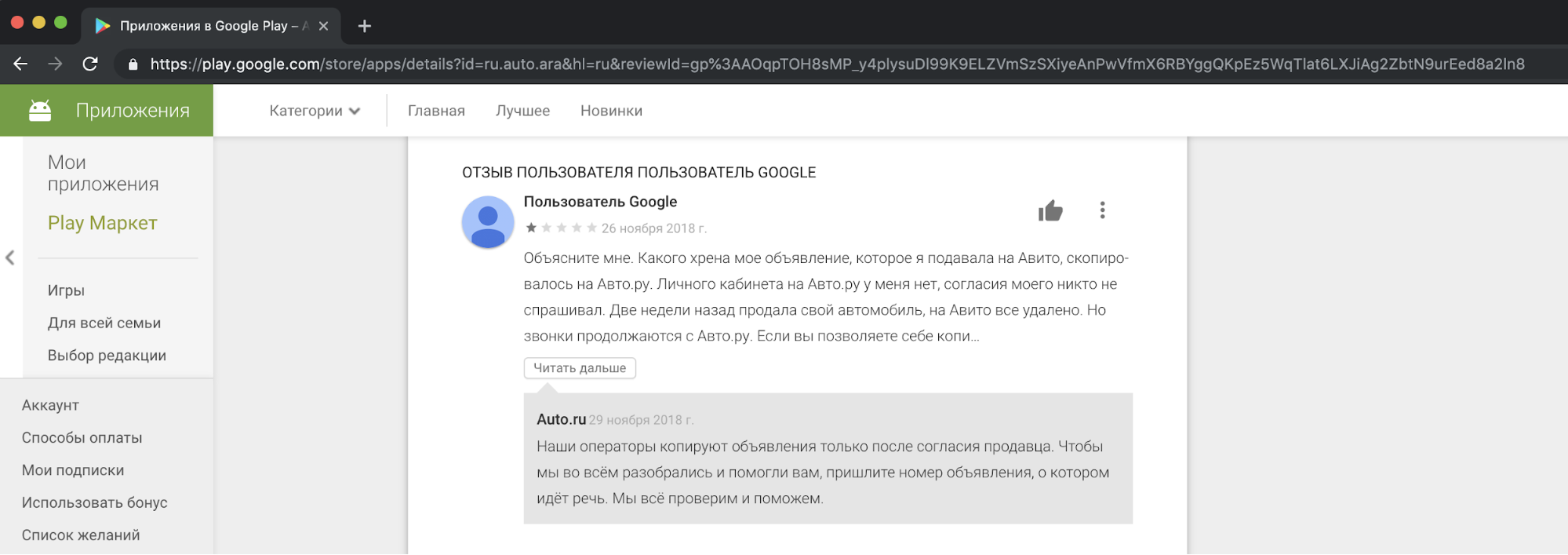
Ich muss sagen, dass die Bitte um Zustimmung von Personen zum Kopieren von Anzeigen solche Handlungen nicht rechtfertigt. Dies ist ein Verstoß gegen die Gesetze "Über Werbung" und "Über personenbezogene Daten", die Avito-Regeln, Markenrechte und die Datenbank mit Anzeigen.
Wir konnten uns nicht friedlich mit einem Konkurrenten einigen, aber wir wollten die Situation nicht so lassen, wie sie ist.
Möglichkeiten, das Problem zu lösen
Die erste Methode ist legal. Ähnliche Präzedenzfälle gab es bereits in anderen Ländern. Zum Beispiel hat der bekannte amerikanische Klassifikator Craigslist große Geldbeträge von Websites beschlagnahmt, die Inhalte von ihm kopieren.
Die zweite Möglichkeit, das Kopierproblem zu lösen, besteht darin, dem Bild ein großes Wasserzeichen hinzuzufügen, damit es nicht zugeschnitten werden kann.
Die dritte Methode ist technologisch. Wir können das Kopieren unserer Inhalte erschweren. Es ist logisch anzunehmen, dass ein Modell das Avito-Logo vor Wettbewerbern versteckt. Es ist auch bekannt, dass viele Modelle zu „Angriffen“ neigen, die ihre ordnungsgemäße Funktion beeinträchtigen. In diesem Artikel geht es nur um sie.
Gegnerischer Angriff

Im Idealfall sieht das gegnerische Beispiel für das Netzwerk wie Rauschen aus, das vom menschlichen Auge nicht zu unterscheiden ist, aber für den Klassifizierer fügt es der Klasse, die nicht im Bild enthalten ist, ein ausreichendes Signal hinzu. Infolgedessen wird ein Bild, beispielsweise mit einem Panda, mit hoher Sicherheit als Gibbon eingestuft. Das Erzeugen von kontroversem Rauschen ist nicht nur für Bildklassifizierungsnetzwerke möglich, sondern auch für die Segmentierung und Erkennung. Ein interessantes Beispiel ist eine kürzlich von Keen Labs durchgeführte Arbeit: Sie haben einen Tesla-Autopiloten mit Punkten auf dem Bürgersteig und einen Regendetektor ausgetrickst, indem sie genau solche Gegengeräusche angezeigt haben . Es gibt auch Angriffe für andere Domänen, zum Beispiel Sound: Der bekannte Angriff auf Amazon Alexa und andere Sprachassistenten bestand darin, Teams zu spielen, die vom menschlichen Ohr nicht zu unterscheiden sind (Cracker boten an, etwas bei Amazon zu kaufen).
Das Erzeugen von kontroversem Rauschen für Modelle, die Bilder analysieren, ist aufgrund der nicht standardmäßigen Verwendung des Gradienten möglich, der zum Trainieren des Modells erforderlich ist. Normalerweise werden bei der Methode der Rückausbreitung von Fehlern unter Verwendung des berechneten Gradienten der Zielfunktion nur die Gewichte der Netzwerkschichten geändert, so dass sie im Trainingsdatensatz weniger falsch sind. Genau wie bei Netzwerkebenen können Sie den Gradienten der Zielfunktion aus dem Eingabebild berechnen und ändern. Das Ändern des Eingabebildes unter Verwendung eines Gradienten wurde für verschiedene bekannte Algorithmen verwendet. Erinnerst du dich an Deepdream ?

Wenn wir den Gradienten der Zielfunktion iterativ aus dem Eingabebild berechnen und diesen Gradienten hinzufügen, werden im Bild weitere Informationen zur vorherrschenden Klasse aus ImageNet angezeigt: Es erscheinen mehr Gesichter von Hunden, wodurch der Wert der Verlustfunktion abnimmt und das Modell in der Klasse „Hund“ sicherer wird. Warum ist der Hund im Beispiel? Nur in ImageNet aus 1000 Klassen - 120 Klassen von Hunden . Ein ähnlicher Ansatz zur Bildmodifikation wurde im Style Transfer-Algorithmus verwendet, der hauptsächlich aufgrund der Prisma-Anwendung bekannt ist.
Um ein konträres Beispiel zu erstellen, können Sie auch die iterative Methode zum Ändern des Eingabebilds verwenden.
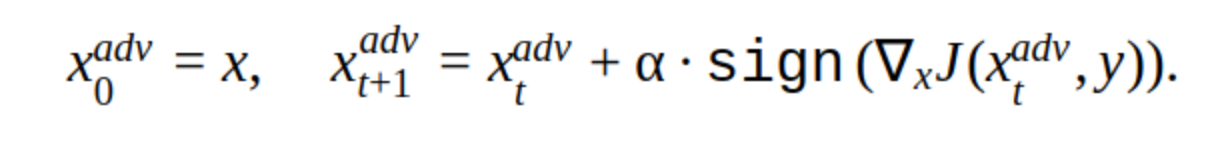
Es gibt verschiedene Modifikationen dieser Methode, aber die Grundidee ist einfach: Das Originalbild wird mit Schritt α iterativ in Richtung des Gradienten des Verlusts der Klassifikatorfunktion J (weil nur das Vorzeichen verwendet wird) verschoben. 'y' ist die Klasse, die im Bild dargestellt wird, um das Vertrauen des Netzwerks in die richtige Antwort zu verringern. Ein solcher Angriff wird als nicht zielgerichtet bezeichnet. Sie können den optimalen Schritt und die optimale Anzahl von Iterationen auswählen, sodass die Änderung im Eingabebild nicht von der für eine Person üblichen Änderung zu unterscheiden ist. Aus zeitlicher Sicht passt ein solcher Angriff jedoch nicht zu uns. 5-10 Iterationen für ein Bild im Produkt sind eine lange Zeit.
Eine Alternative zu iterativen Methoden ist die FGSM-Methode.

Dies ist eine Einzelschussmethode, d.h. Um es zu verwenden, müssen Sie den Gradienten der Verlustfunktion für das Eingabebild einmal berechnen, und das gegnerische Rauschen kann dem Bild hinzugefügt werden. Diese Methode ist offensichtlich produktiver. Es kann in der Produktion eingesetzt werden.
Widersprüchliche Beispiele erstellen
Wir haben uns entschlossen, zunächst unser eigenes Modell zu hacken.
Dies ist das Bild, das die Wahrscheinlichkeit verringert, ein Nummernschild für unser Modell zu finden.

Es ist offensichtlich, dass diese Methode einen Nachteil hat: Die Änderungen, die sie dem Bild hinzufügt, sind für das Auge sichtbar. Auch diese Methode ist nicht zielgerichtet, kann aber geändert werden, um einen gerichteten Angriff auszuführen. Dann sagt das Modell den Platz für das Nummernschild an einem anderen Ort voraus. Dies ist die T-FGSM-Methode.
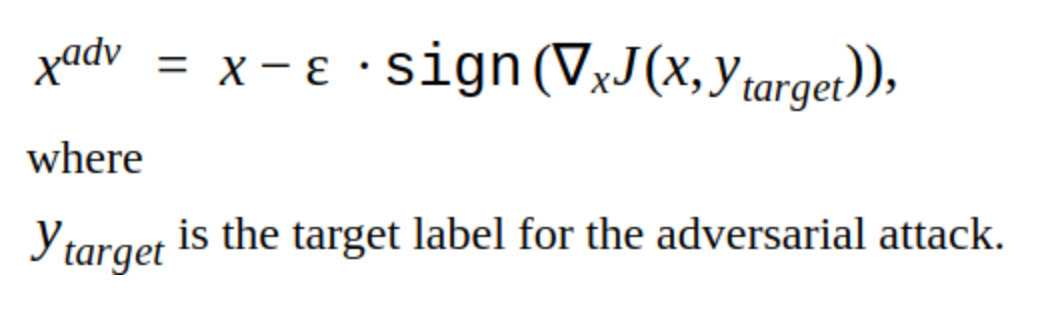
Um unser Modell mit dieser Methode zu brechen, müssen Sie das Eingabebild etwas deutlicher ändern.

Es ist noch nicht möglich zu sagen, dass die Ergebnisse ideal sind, aber zumindest die Effizienz der Methoden wurde überprüft. Wir haben auch vorgefertigte Bibliotheken zum Hacken von Foolbox-, CleverHans- und ART-IBM-Netzwerken ausprobiert, aber mit ihrer Hilfe war es nicht möglich, unser Netzwerk zur Erkennung zu unterbrechen. Die dort angegebenen Methoden eignen sich besser für Klassifizierungsnetzwerke. Dies ist ein allgemeiner Trend beim Netzwerk-Hacking: Für die Objekterkennung ist es schwieriger, einen Angriff auszuführen, insbesondere bei komplexen Modellen, z. B. Mask RCNN.
Angriffstests
Alles, was bisher beschrieben wurde, ging nicht über unsere internen Experimente hinaus, aber es musste herausgefunden werden, wie Angriffe auf die Detektoren anderer Anzeigenplattformen getestet werden können.
Es stellt sich heraus, dass bei der Beantragung einer der Plattformen das Nummernschild automatisch erkannt wird, sodass Sie Fotos viele Male hochladen und überprüfen können, wie der Erkennungsalgorithmus mit dem neuen gegnerischen Beispiel umgeht.
Es ist ausgezeichnet! Aber ...
Keiner der Angriffe, die auf unser Modell angewendet wurden, funktionierte beim Testen auf einer anderen Plattform. Warum ist das passiert? Dies ist eine Folge der unterschiedlichen Modelle und der allgemeinen Verallgemeinerung von Angriffen auf verschiedene Netzwerkarchitekturen. Aufgrund der Komplexität der Reproduktion von Angriffen werden sie in zwei Gruppen unterteilt: White Box und Black Box.

Diese Angriffe, die wir auf unser Modell gemacht haben - es war eine weiße Kiste. Was wir brauchen, ist eine Black Box mit zusätzlichen Inferenzbeschränkungen: Es gibt keine API. Sie können lediglich Fotos manuell hochladen und Angriffe überprüfen. Wenn es eine API gäbe, könnten Sie ein Ersatzmodell erstellen.

Die Idee ist, einen Datensatz mit Eingabebildern und Antworten des Black-Box-Modells zu erstellen, auf dem Sie mehrere Modelle unterschiedlicher Architekturen trainieren können, um das Black-Box-Modell zu approximieren. Dann können Sie einen White-Box-Angriff auf diese Modelle ausführen, und es ist wahrscheinlicher, dass sie auf einer Black-Box funktionieren. In unserem Fall bedeutet dies viel manuelle Arbeit, sodass diese Option nicht zu uns passte.
Den Stillstand überwinden
Auf der Suche nach interessanten Arbeiten zum Thema Black-Box-Angriffe wurde ein Artikel ShapeShifter: Robust Physical Adversarial Attack auf Faster R-CNN Object Detector gefunden
Die Autoren des Artikels griffen die Objekterkennung eines Netzwerks selbstfahrender Maschinen an, indem sie dem Hintergrund des Stoppschilds iterativ andere Bilder als die wahre Klasse hinzufügten.


Ein solcher Angriff ist für das menschliche Auge deutlich sichtbar, unterbricht jedoch erfolgreich die Arbeit des Objekterkennungsnetzwerks, was wir brauchen. Aus diesem Grund haben wir beschlossen, die gewünschte Unsichtbarkeit des Angriffs aus Gründen der Arbeitsfähigkeit zu vernachlässigen.
Wir wollten überprüfen, inwieweit das Erkennungsmodell umgeschult wurde, verwendet es Informationen über das Auto oder wird nur die Avito-Platte benötigt?
Erstellen Sie dazu das folgende Bild:

Wir haben es als Maschine auf eine Anzeigenplattform mit einem Black-Box-Modell hochgeladen. Erhalten:

Dies bedeutet, dass Sie nur die Avito-Platte ändern können. Der Rest der Informationen im Eingabebild ist für die Erkennung des Black-Box-Modells nicht erforderlich.
Nach mehreren Versuchen entstand die Idee, das durch die FGSM-Methode erhaltene gegnerische Rauschen der Avito-Platte zu addieren, wodurch unser eigenes Modell gebrochen wurde, jedoch mit einem ziemlich großen Koeffizienten ε. Es stellte sich so heraus:

Mit dem Auto sieht es so aus:

Wir haben ein Foto mit einem Black-Box-Modell auf die Plattform hochgeladen. Das Ergebnis war erfolgreich.

Bei Anwendung dieser Methode auf mehrere andere Fotos haben wir festgestellt, dass sie nicht oft funktioniert. Nach mehreren Versuchen haben wir uns dann entschlossen, uns auf den anderen auffälligsten Teil des Problems zu konzentrieren - die Grenze. Es ist bekannt, dass die anfänglichen Faltungsschichten des Netzwerks Aktivierungen an einfachen Objekten wie Linien, Winkeln aufweisen. Indem wir die Grenzlinie „durchbrechen“, können wir verhindern, dass das Netzwerk den Bereich der Nummer korrekt erkennt. Dies kann beispielsweise durch Hinzufügen von Rauschen in Form von weißen Quadraten zufälliger Größe über den gesamten Raumrand erfolgen.

Durch das Hochladen eines solchen Bildes auf eine Plattform mit einem Black-Box-Modell haben wir ein erfolgreiches gegnerisches Beispiel erhalten.

Nachdem wir diesen Ansatz an einer Reihe anderer Bilder ausprobiert hatten, stellten wir fest, dass das Black-Box-Modell die Avito-Platte nicht mehr erkennen kann (die Reihe wurde manuell zusammengesetzt, es gibt weniger als hundert Bilder und sie ist natürlich nicht repräsentativ, aber es dauert viel Zeit, um mehr zu machen). Eine interessante Beobachtung: Der Angriff ist nur dann erfolgreich, wenn Rauschen in den Avito-Buchstaben und zufällige weiße Quadrate in einem Frame kombiniert werden. Wenn Sie diese Methoden separat verwenden, erhalten Sie kein erfolgreiches Ergebnis.
Infolgedessen haben wir diesen Algorithmus im Produkt eingeführt, und hier ist, was dabei herausgekommen ist :)
Mehrere Anzeigen gefunden


Etwas Frischeres:
Wir sind sogar auf die Werbeplattform gekommen:
Insgesamt
Infolgedessen ist es uns gelungen, einen gegnerischen Angriff durchzuführen, der in unserer Implementierung die Bildverarbeitungszeit nicht verlängert. Die Zeit, die wir für die Erstellung des Angriffs aufgewendet haben, liegt zwei Wochen vor dem neuen Jahr. Wenn es in dieser Zeit nicht möglich gewesen wäre, hätten sie ein Wasserzeichen gesetzt. Jetzt ist das gegnerische Nummernschild deaktiviert, da jetzt ein Konkurrent Benutzer anruft, ihnen anbietet, Fotos selbst in die Anzeige hochzuladen oder Fotos des Autos durch Standardfotos aus dem Internet zu ersetzen.