Hallo Habr! Ich präsentiere Ihnen die Übersetzung des Artikels " Landbedeckungsklassifizierung mit eo-learn: Teil 1 " von Matic Lubej.
Teil 2
Teil 3
Vorwort
Vor ungefähr sechs Monaten wurde das erste Commit für das eo-learn- Repository auf GitHub vorgenommen. Heute hat sich eo-learn zu einer wunderbaren Open-Source-Bibliothek entwickelt, die von jedem genutzt werden kann, der sich für EO-Daten (Earth Observation - etc. Trans.) Interessiert. Alle Mitglieder des Sinergise- Teams warteten auf den Moment des Übergangs von der Phase des Aufbaus der erforderlichen Werkzeuge zur Phase ihres Einsatzes für maschinelles Lernen. Es ist Zeit, Ihnen eine Reihe von Artikeln zur Klassifizierung der Landbedeckung mithilfe von eo-learn vorzustellen
eo-learn ist eine Open-Source-Python-Bibliothek, die als Brücke zwischen Erdbeobachtung / Fernerkundung und dem Ökosystem der Python-Bibliotheken für maschinelles Lernen fungiert. Wir haben bereits einen separaten Beitrag in unserem Blog geschrieben , mit dem Sie sich vertraut machen sollten. Die Bibliothek verwendet numpy aus den numpy und numpy Bibliotheken, um Daten von Satelliten zu speichern und zu numpy . Derzeit ist es im GitHub-Repository verfügbar, und die Dokumentation finden Sie unter dem entsprechenden Link zu ReadTheDocs .

Sentinel-2-Satellitenbild und NDVI-Maske eines kleinen Gebiets in Slowenien im Winter
Um die Möglichkeiten von eo-learn zu demonstrieren, haben wir uns entschlossen, mithilfe unseres Multi-Temporal-Förderers die Abdeckung des Territoriums der Republik Slowenien (dem Land, in dem wir leben) anhand von Daten für 2017 zu klassifizieren. Da das gesamte Verfahren für einen Artikel möglicherweise zu kompliziert ist, haben wir beschlossen, es in drei Teile zu unterteilen. Dank dessen müssen Sie die Schritte nicht überspringen und sofort mit dem maschinellen Lernen fortfahren. Zuerst müssen wir die Daten, mit denen wir arbeiten, wirklich verstehen. Jeder Artikel wird von einem Jupyter Notebook-Beispiel begleitet. Für Interessenten haben wir bereits ein vollständiges Beispiel für alle Phasen vorbereitet.
- Im ersten Artikel werden wir Sie durch das Verfahren zum Auswählen / Aufteilen eines interessierenden Bereichs (im Folgenden - AOI, interessierender Bereich) und zum Abrufen der erforderlichen Informationen wie Daten von Satellitensensoren und Wolkenmasken führen. Wir zeigen auch ein Beispiel für das Erstellen einer Rastermaske von Daten zur tatsächlichen Abdeckung eines Gebiets aus Vektordaten. All dies sind notwendige Schritte, um ein zuverlässiges Ergebnis zu erzielen.
- Im zweiten Teil beschäftigen wir uns intensiv mit der Vorbereitung von Daten für das maschinelle Lernen. Dieser Prozess umfasst das Entnehmen von Zufallsstichproben zum Trainieren / Validieren von Pixeln, Entfernen von Wolkenbildern, Interpolieren von Zeitdaten zum Ausfüllen von „Löchern“ usw.
- Im dritten Teil werden wir das Training und die Validierung des Klassifikators sowie natürlich schöne Grafiken betrachten!

Sentinel-2-Satellitenbild und NDVI-Maske eines kleinen Gebiets in Slowenien im Sommer
Interessensgebiet? Wählen Sie!
Mit der eo-learn Bibliothek können Sie AOI in kleine Fragmente aufteilen, die unter Bedingungen begrenzter Rechenressourcen verarbeitet werden können. In diesem Beispiel wurde die slowenische Grenze von Natural Earth übernommen. Sie können jedoch eine Zone beliebiger Größe auswählen. Wir haben auch einen Puffer an der Grenze hinzugefügt, wonach die AOI-Dimension ungefähr 250 x 170 km betrug. Mit der Magie von geopandas und shapely Bibliotheken haben wir ein Werkzeug entwickelt, um AOI zu brechen. In diesem Fall haben wir das Gebiet in 25 x 17 Quadrate gleicher Größe unterteilt, wodurch wir ~ 300 Fragmente mit 1000 x 1000 Pixel in einer Auflösung von 10 m erhalten haben. Die Entscheidung über die Aufteilung in Fragmente hängt von der verfügbaren Rechenleistung ab. Als Ergebnis dieses Schritts erhalten wir eine Liste von Quadraten, die den AOI abdecken.

AOI (Territorium Sloweniens) ist in kleine Quadrate mit einer Größe von ungefähr 1000 x 1000 Pixel und einer Auflösung von 10 m unterteilt.
Empfangen von Daten von Sentinel-Satelliten
Nach dem Bestimmen der Quadrate können Sie mit eo-learn automatisch Daten von Sentinel-Satelliten herunterladen. In diesem Beispiel erhalten wir alle Sentinel-2 L1C-Bilder, die 2017 aufgenommen wurden. Es ist erwähnenswert, dass Sentinel-2 L2A-Produkte sowie zusätzliche Datenquellen (Landsat-8, Sentinel-1) auf ähnliche Weise zur Pipeline hinzugefügt werden können. Es ist auch erwähnenswert, dass die Verwendung von L2A-Produkten die Klassifizierungsergebnisse verbessern kann. Wir haben uns jedoch für die Verwendung von L1C entschieden, um die Vielseitigkeit der Lösung zu gewährleisten. Dies wurde mit sentinelhub-py , einer Bibliothek, die wie ein Wrapper für Sentinel-Hub-Dienste funktioniert. Die Nutzung dieser Dienste ist für Forschungsinstitute und Start-ups kostenlos, in anderen Fällen ist jedoch eine Anmeldung erforderlich.

Farbbilder eines Fragments an verschiedenen Tagen. Einige Bilder sind bewölkt, was bedeutet, dass ein Wolkendetektor benötigt wird.
Zusätzlich zu den Sentinel-Daten können Sie mit eo-learn dank der s2cloudless Bibliothek transparent auf Cloud- und Cloud-Wahrscheinlichkeitsdaten s2cloudless . Diese Bibliothek bietet Tools zum automatischen Erkennen von Wolken Pixel für Pixel . Details können hier gelesen werden .
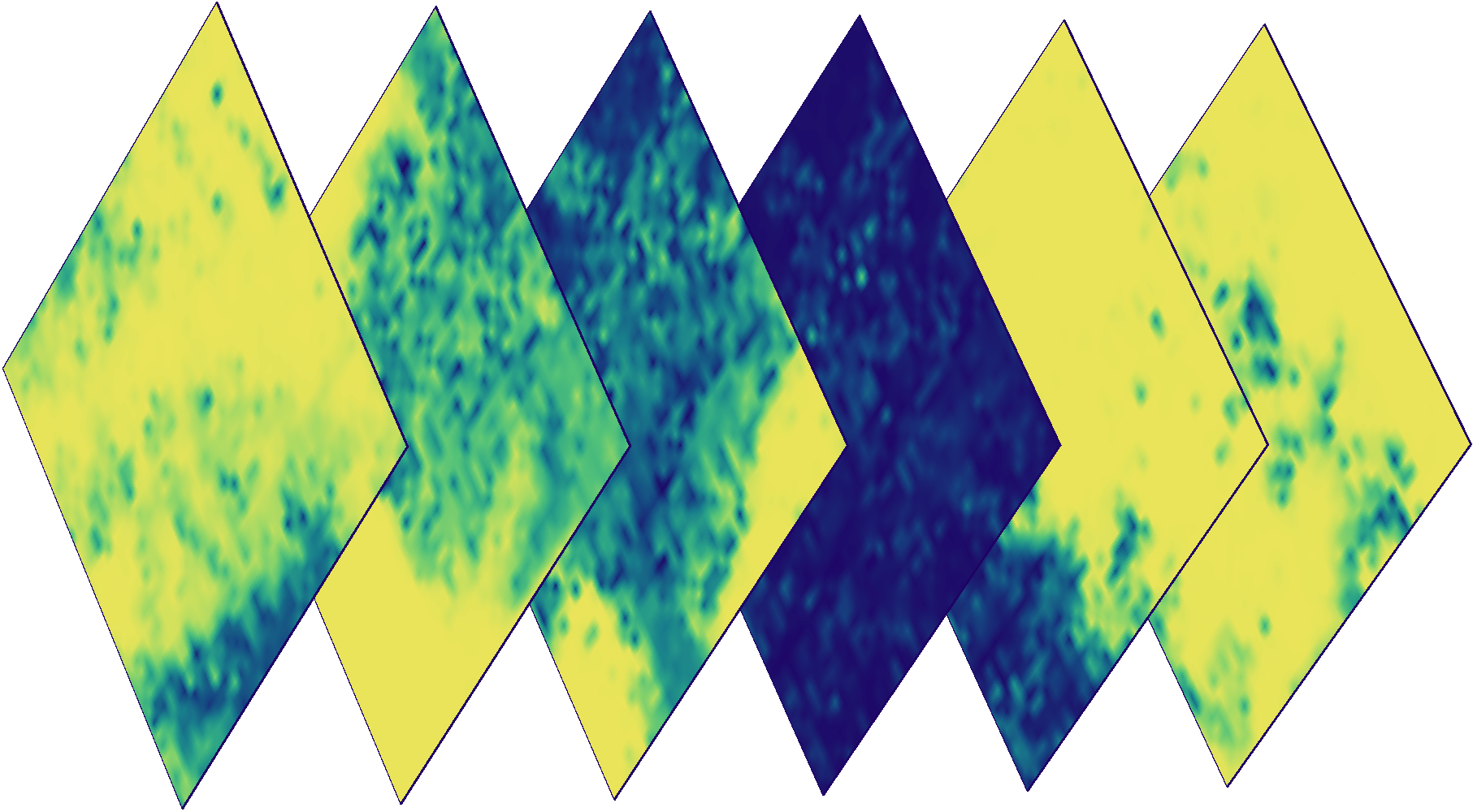
Wolkenmasken für die Bilder oben. Die Farbe gibt die Wahrscheinlichkeit einer Trübung eines bestimmten Pixels an (blau - niedrige Wahrscheinlichkeit, gelb - hoch).
Reale Daten hinzufügen
Das Unterrichten mit einem Lehrer erfordert eine Karte mit echten Daten oder Wahrheit . Der letzte Begriff sollte nicht wörtlich genommen werden, da Daten in Wirklichkeit nur eine Annäherung an das sind, was sich an der Oberfläche befindet. Leider hängt das Verhalten des Klassifikators stark von der Qualität dieser Karte ab ( wie bei den meisten anderen Aufgaben beim maschinellen Lernen ). Beschriftete Karten sind meistens als Vektordaten im shapefile Format verfügbar (z. B. vom Staat oder der Gemeinde bereitgestellt). eo-learn enthält Tools zum Rasterisieren von Vektordaten in Form einer Rastermaske.

Der Prozess des Rasterisierens von Daten in Masken am Beispiel eines Quadrats. Polygone in einer Vektordatei werden auf dem linken Bild angezeigt, Rastermasken für jedes Etikett werden in der Mitte angezeigt - schwarze und weiße Farben zeigen das Vorhandensein bzw. Fehlen eines bestimmten Attributs an. Das rechte Bild zeigt eine kombinierte Rastermaske, in der unterschiedliche Farben unterschiedliche Beschriftungen anzeigen.
Alles zusammenfügen
Alle diese Aufgaben verhalten sich wie Bausteine, die zu einer praktischen Abfolge von Aktionen kombiniert werden können, die für jedes Quadrat ausgeführt werden. Aufgrund der möglicherweise extrem großen Anzahl solcher Fragmente ist eine Pipeline-Automatisierung unbedingt erforderlich
Das Kennenlernen der tatsächlichen Daten ist der erste Schritt bei der Arbeit mit Aufgaben dieser Art. Mithilfe von Wolkenmasken, die mit Daten von Sentinel-2 gepaart sind, können Sie die Anzahl der Qualitätsbeobachtungen aller Pixel sowie die durchschnittliche Wahrscheinlichkeit von Wolken in einem bestimmten Bereich bestimmen. Dank dessen können Sie die vorhandenen Daten besser verstehen und diese beim Debuggen weiterer Probleme verwenden.

Farbbild (links), Maske der Anzahl der Qualitätsmessungen für 2017 (Mitte) und durchschnittliche Wolkenbedeckungswahrscheinlichkeit für 2017 (rechts) für ein zufälliges Fragment von AOI.
Jemand könnte an dem durchschnittlichen NDVI für eine beliebige Zone interessiert sein und die Wolken ignorieren. Mithilfe von Cloud-Masken können Sie den Durchschnittswert eines Features berechnen und Pixel ohne Daten ignorieren. Dank der Masken können wir für nahezu alle Funktionen in unseren Daten Bilder aus dem Rauschen entfernen.
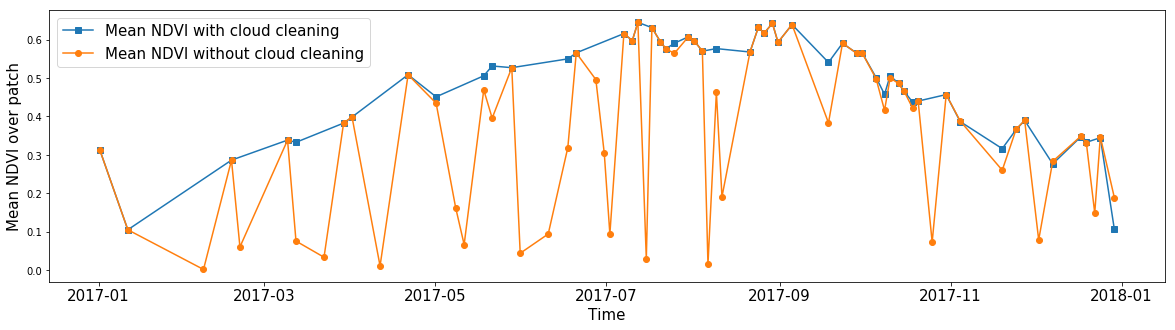
Der durchschnittliche NDVI aller Pixel in einem zufälligen AOI-Fragment während des ganzen Jahres. Die blaue Linie zeigt das Berechnungsergebnis, das erhalten wird, wenn die Werte innerhalb der Wolken ignoriert werden. Die orange Linie zeigt den Durchschnittswert, wenn alle Pixel berücksichtigt werden.
"Aber was ist mit Skalierung?"
Nachdem wir unseren Förderer am Beispiel eines Fragments eingerichtet haben, müssen Sie nur noch automatisch ein ähnliches Verfahren für alle Fragmente starten (parallel, sofern die Ressourcen dies zulassen), während Sie sich bei einer Tasse Kaffee entspannen und darüber nachdenken, wie groß der Chef angenehm überrascht sein wird die Ergebnisse Ihrer Arbeit. Nach dem Ende der Pipeline können Sie die Daten, an denen Sie interessiert sind, in ein einzelnes Bild im GeoTIFF-Format exportieren. Das Skript gdal_merge.py empfängt die Bilder und kombiniert sie, sodass ein Bild entsteht, das das ganze Land abdeckt.
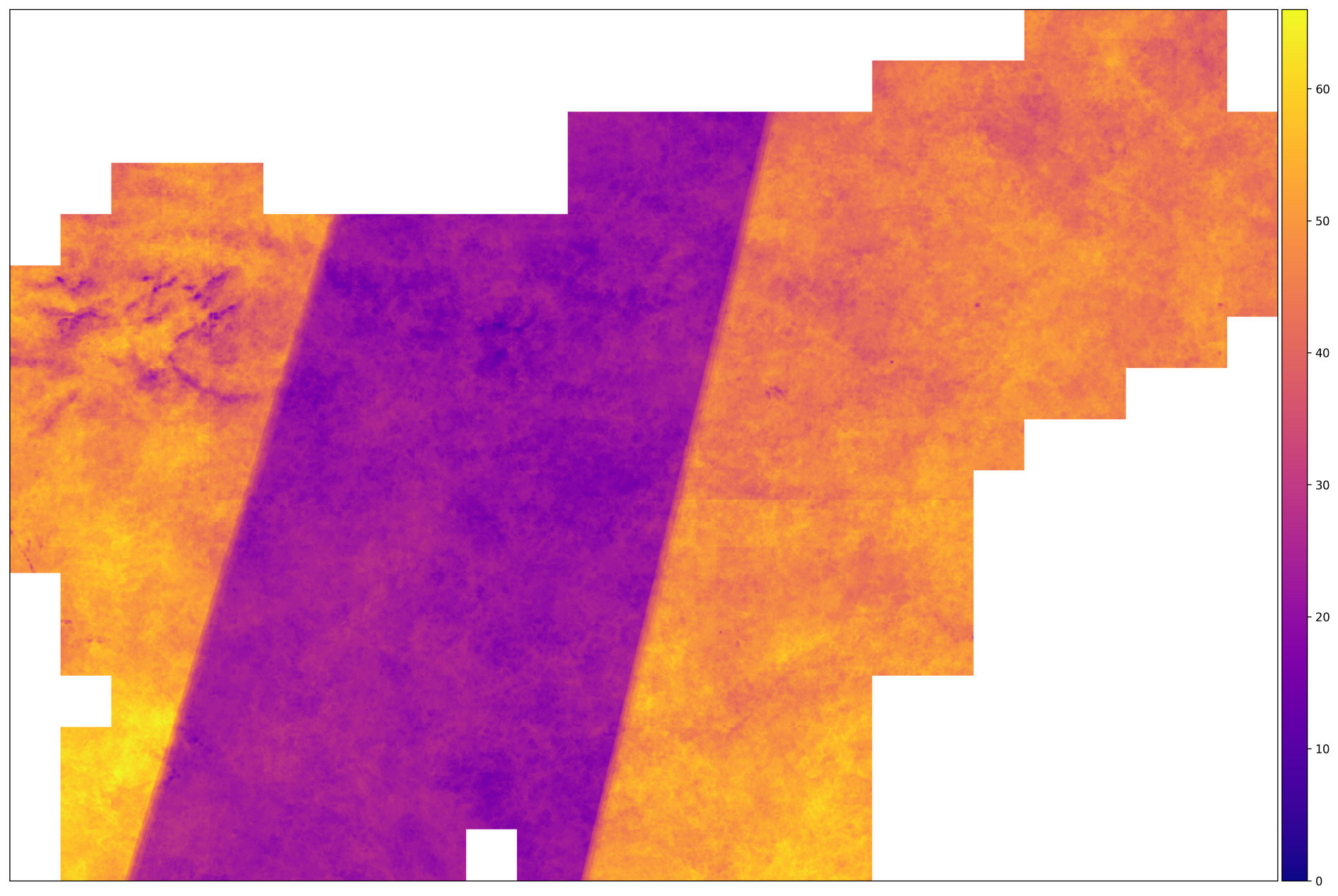
Die Anzahl der richtigen Aufnahmen für AOI im Jahr 2017. Regionen mit einer großen Anzahl von Bildern befinden sich auf dem Gebiet, auf dem sich die Flugbahn der Satelliten Sentinel-2A und Sentinel-2B schneidet. In der Mitte passiert das nicht.
Aus dem obigen Bild können wir schließen, dass die Eingabedaten heterogen sind - für einige Fragmente ist die Anzahl der Bilder doppelt so hoch wie für andere. Dies bedeutet, dass wir Maßnahmen ergreifen müssen, um die Daten zu normalisieren - beispielsweise die Interpolation entlang der Zeitachse.
Die Ausführung der angegebenen Pipeline dauert ungefähr 140 Sekunden für ein Fragment, was insgesamt ~ 12 Stunden ergibt, wenn der Prozess während des gesamten AOI gestartet wird. Die meiste Zeit werden Satellitendaten heruntergeladen. Das durchschnittliche unkomprimierte Fragment mit der beschriebenen Konfiguration benötigt ungefähr 3 GB, was insgesamt ~ 1 TB Speicherplatz für den gesamten AOI ergibt.
Beispiel in einem Jupyter-Notizbuch
Zur leichteren Einführung in den eo-learn Code haben wir ein Beispiel für die in diesem Beitrag behandelten Themen vorbereitet. Das Beispiel ist als Jupyter-Notizbuch konzipiert und befindet sich im Beispielverzeichnis des eo-learn Pakets.