Täglich arbeiten Zehntausende von Mitarbeitern aus mehreren tausend Organisationen auf der ganzen Welt bei Pyrus. Wir betrachten die Reaktionsfähigkeit des Dienstes (die Geschwindigkeit der Bearbeitung von Anfragen) als einen wichtigen Wettbewerbsvorteil, da dies die Benutzererfahrung direkt beeinflusst. Die Schlüsselmetrik für uns ist der „Prozentsatz langsamer Abfragen“. Bei der Untersuchung des Verhaltens haben wir festgestellt, dass auf den Anwendungsservern einmal pro Minute Pausen von etwa 1000 ms Länge auftreten. In diesen Intervallen antwortet der Server nicht und es entsteht eine Warteschlange mit mehreren Dutzend Anforderungen. Die Suche nach den Ursachen und die Beseitigung von Engpässen, die durch die Speicherbereinigung in der Anwendung verursacht werden, werden in diesem Artikel erläutert.

Moderne Programmiersprachen können in zwei Gruppen unterteilt werden. In Sprachen wie C / C ++ oder Rust wird die manuelle Speicherverwaltung verwendet, sodass Programmierer mehr Zeit damit verbringen, Code zu schreiben, die Lebensdauer von Objekten zu verwalten und dann zu debuggen. Gleichzeitig sind Fehler aufgrund unsachgemäßer Speichernutzung einige der am schwierigsten zu debuggenden Fehler, sodass die modernste Entwicklung in Sprachen mit automatischer Speicherverwaltung durchgeführt wird. Dazu gehören beispielsweise Java, C #, Python, Ruby, Go, PHP, JavaScript usw. Programmierer sparen Entwicklungszeit, aber Sie müssen für die zusätzliche Ausführungszeit bezahlen, die das Programm regelmäßig für die Speicherbereinigung benötigt. Dadurch wird Speicherplatz frei, der von Objekten belegt wird, zu denen im Programm keine Links mehr vorhanden sind. In kleinen Programmen ist diese Zeit vernachlässigbar, aber mit zunehmender Anzahl von Objekten und der Intensität ihrer Erstellung leistet die Speicherbereinigung einen spürbaren Beitrag zur Gesamtausführungszeit des Programms.
Pyrus-Webserver werden auf der .NET-Plattform ausgeführt, die die automatische Speicherverwaltung verwendet. Die meisten Müllsammlungen sind "Stop the World", d. H. Zum Zeitpunkt ihrer Arbeit stoppen sie alle Threads der Anwendung. Nicht blockierende (Hintergrund-) Assemblys stoppen tatsächlich auch alle Threads, jedoch für einen sehr kurzen Zeitraum. Während der Thread-Blockierung verarbeitet der Server keine Anforderungen, vorhandene Anforderungen frieren ein, neue werden zur Warteschlange hinzugefügt. Infolgedessen werden Anforderungen, die zum Zeitpunkt der Speicherbereinigung verarbeitet wurden, direkt verlangsamt, und Anforderungen werden aufgrund der angesammelten Warteschlangen unmittelbar nach Abschluss der Speicherbereinigung langsamer verarbeitet. Dies verschlechtert die Metrik "Prozentsatz langsamer Abfragen".
Ausgerüstet mit dem kürzlich veröffentlichten Buch
Konrad Kokosa: Pro .NET Memory Management (darüber, wie wir sein erstes Exemplar in zwei Tagen nach Russland gebracht haben, können Sie einen separaten Beitrag schreiben), das sich ausschließlich dem Thema Speicherverwaltung in .NET widmet, haben wir begonnen, das Problem zu untersuchen.
Messung
Zum Profilieren des Pyrus-Webservers haben wir das PerfView-Dienstprogramm (
https://github.com/Microsoft/perfview ) verwendet, das für die Profilerstellung von .NET-Anwendungen geschärft wurde. Das Dienstprogramm basiert auf der ETW-Engine (Event Tracing for Windows) und hat nur minimale Auswirkungen auf die Leistung der Profilanwendung, sodass sie auf einem Kampfserver verwendet werden kann. Darüber hinaus hängt die Auswirkung auf die Leistung davon ab, welche Arten von Ereignissen und welche Informationen wir sammeln. Wir sammeln nichts - die Anwendung funktioniert wie gewohnt. Außerdem erfordert PerfView weder eine Neukompilierung noch einen Neustart der Anwendung.
Führen Sie den PerfView-Trace mit dem Parameter / GCCollectOnly aus (Trace-Zeit 1,5 Stunden). In diesem Modus werden nur Speicherbereinigungsereignisse erfasst und die Leistung wird nur minimal beeinträchtigt. Schauen wir uns den Speichergruppen- / GCStats-Ablaufverfolgungsbericht und darin eine Zusammenfassung der Garbage Collector-Ereignisse an:
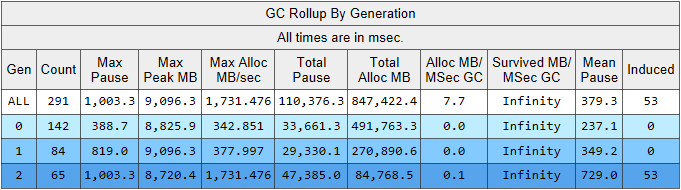
Hier sehen wir mehrere interessante Indikatoren gleichzeitig:
- Die durchschnittliche Erstellungspausenzeit in der 2. Generation beträgt 700 Millisekunden, und die maximale Pause beträgt etwa eine Sekunde. Diese Abbildung zeigt den Zeitpunkt, zu dem alle Threads in der .NET-Anwendung beendet werden. Insbesondere wird diese Pause allen verarbeiteten Anforderungen hinzugefügt.
- Die Anzahl der Baugruppen der 2. Generation ist vergleichbar mit der 1. Generation und liegt geringfügig unter der Anzahl der Baugruppen der 0. Generation.
- In der Spalte Induziert sind 53 Baugruppen der 2. Generation aufgeführt. Die induzierte Assemblierung ist das Ergebnis eines expliziten Aufrufs von GC.Collect (). In unserem Code haben wir keinen einzigen Aufruf dieser Methode gefunden, was bedeutet, dass einige der von unserer Anwendung verwendeten Bibliotheken schuld sind.
Lassen Sie uns die Beobachtung über die Anzahl der Speicherbereinigungen erklären. Die Idee, Objekte durch ihre Lebensdauer zu teilen, basiert auf der
Generationshypothese : Ein erheblicher Teil der erstellten Objekte stirbt schnell und die meisten anderen leben lange (mit anderen Worten, wenige Objekte mit einer „durchschnittlichen“ Lebensdauer). In diesem Modus ist der .NET-Garbage Collector inhaftiert, und in diesem Modus sollten die Assemblys der zweiten Generation viel kleiner sein als die der 0. Generation. Das heißt, für den optimalen Betrieb des Garbage Collectors müssen wir die Arbeit unserer Anwendung auf die Generationshypothese abstimmen. Formulieren wir die Regel wie folgt: Objekte müssen entweder schnell sterben, ohne für die ältere Generation zu überleben, oder danach leben und für immer dort leben. Diese Regel gilt auch für andere Plattformen, die eine automatische Speicherverwaltung mit Generationstrennung verwenden, z. B. Java.
Die für uns interessanten Daten können aus einer anderen Tabelle im GCStats-Bericht extrahiert werden:

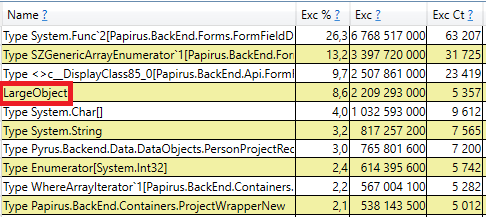
In einigen Fällen versucht eine Anwendung, ein großes Objekt zu erstellen (in .NET Framework werden Objekte mit einer Größe von> 85.000 Byte im LOH - Heap für große Objekte erstellt) und muss auf den Abschluss der Assembly der 2. Generation warten, die parallel im Hintergrund stattfindet. Diese Pausen des Allokators sind nicht so kritisch wie die Pausen des Garbage Collector, da sie nur einen Thread betreffen. Zuvor haben wir .NET Framework Version 4.6.1 verwendet. In Version 4.7.1 hat Microsoft den Garbage Collector fertiggestellt. Jetzt können Sie während der Hintergrundgenerierung der 2. Generation Speicher im Heap für große Objekte zuweisen:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # gemeinsame Sprache-Laufzeit-clrAus diesem Grund haben wir zu diesem Zeitpunkt ein Upgrade auf die neueste Version 4.7.2 durchgeführt.
Builds der 2. Generation
Warum haben wir so viele Builds der älteren Generation? Die erste Annahme ist, dass wir einen Speicherverlust haben. Um diese Hypothese zu testen, werfen wir einen Blick auf die Größe der zweiten Generation (wir haben die Überwachung der entsprechenden Leistungsindikatoren in Zabbix eingerichtet). Aus den Diagrammen der Größe der 2. Generation für 2 Pyrus-Server ist ersichtlich, dass ihre Größe zuerst zunimmt (hauptsächlich aufgrund des Füllens von Caches), sich dann aber stabilisiert (große Fehler im Diagramm - regelmäßiger Neustart des Webdienstes zur Aktualisierung der Version):
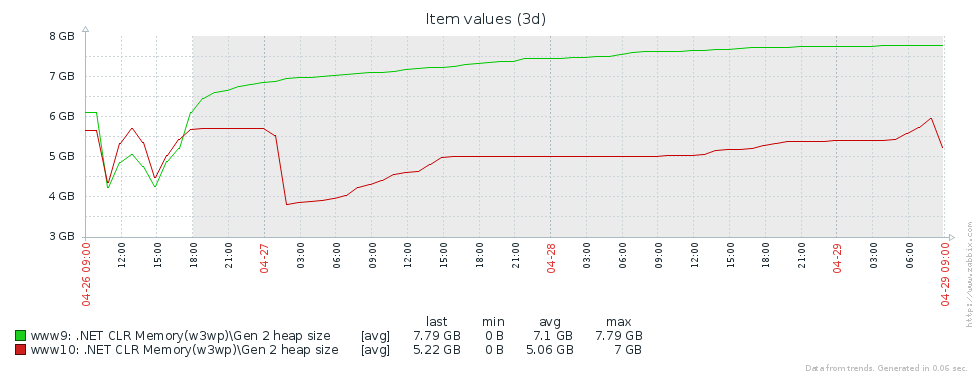
Dies bedeutet, dass keine merklichen Speicherverluste auftreten, dh eine große Anzahl von Baugruppen der 2. Generation tritt aus einem anderen Grund auf. Die nächste Hypothese ist, dass es viel Speicherverkehr gibt, d. H. Viele Objekte fallen in die 2. Generation und viele Objekte sterben dort ab. PerfView verfügt über einen / GCOnly-Modus, um solche Objekte zu finden. Beachten Sie in den Ablaufverfolgungsberichten die Stapel "Gen 2-Objekttod (Grobabtastung)", die eine Auswahl von Objekten enthalten, die in der 2. Generation sterben, sowie Aufrufstapel der Orte, an denen diese Objekte erstellt wurden. Hier sehen wir folgende Ergebnisse:
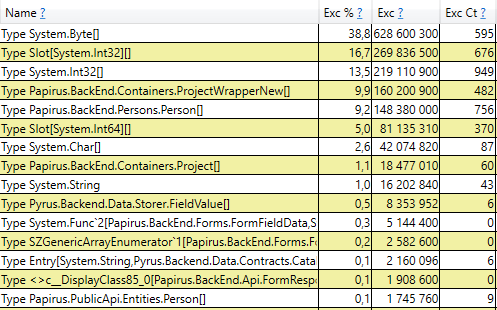
Nachdem wir die Zeile geöffnet haben, sehen wir im Inneren einen Aufrufstapel der Stellen im Code, die Objekte erstellen, die der 2. Generation gerecht werden. Unter ihnen:
- System.Byte [] Wenn Sie nach innen schauen, werden Sie feststellen, dass mehr als die Hälfte Puffer für die Serialisierung in JSON sind:
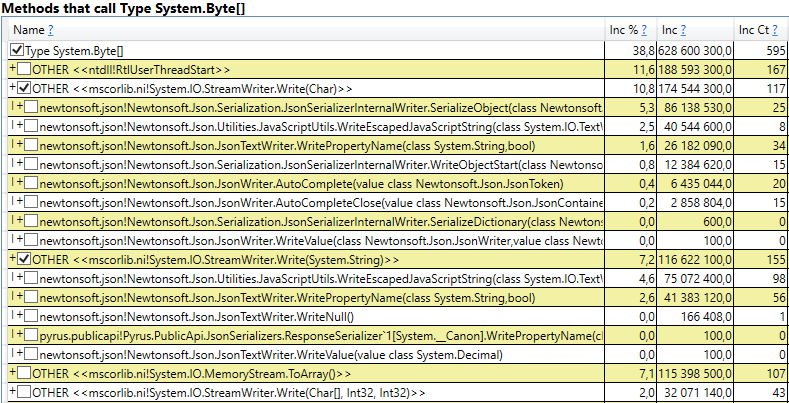
- Slot [System.Int32] [] (dies ist Teil der HashSet-Implementierung), System.Int32 [] usw. Dies ist unser Code, der Client-Caches berechnet - die Verzeichnisse, Formulare, Listen, Freunde usw., die dieser Benutzer sieht und die in seinem Browser oder seiner mobilen Anwendung zwischengespeichert werden:

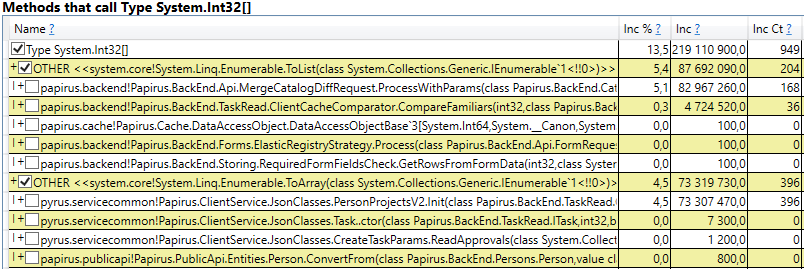
Interessanterweise sind die Puffer für JSON und für die Berechnung von Client-Caches alle temporäre Objekte, die auf derselben Anforderung leben. Warum werden sie der 2. Generation gerecht? Beachten Sie, dass alle diese Objekte Arrays von ziemlich großer Größe sind. Bei einer Größe> 85000 Byte wird der Speicher für sie im Large Object Heap zugewiesen, der nur zusammen mit der 2. Generation gesammelt wird.
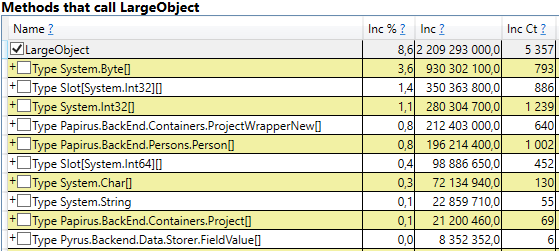
Öffnen Sie zur Überprüfung den Abschnitt 'GC Heap Alloc Ignore Free (Coarse Sampling) -Stapel' in den perfview / GCOnly-Ergebnissen. Dort sehen wir die LargeObject-Zeile, in der PerfView die Erstellung großer Objekte gruppiert, und im Inneren sehen wir dieselben Arrays, die wir in der vorherigen Analyse gesehen haben. Wir erkennen die Hauptursache für die Probleme mit dem Garbage Collector an: Wir erstellen viele temporäre große Objekte.
Änderungen im Pyrus-System
Basierend auf den Messergebnissen haben wir die Hauptbereiche weiterer Arbeiten identifiziert: den Kampf gegen große Objekte bei der Berechnung von Client-Caches und die Serialisierung in JSON. Es gibt verschiedene Lösungen für dieses Problem:
- Am einfachsten ist es, keine großen Objekte zu erstellen. Wenn beispielsweise der große Puffer B in sequentiellen Datentransformationen A-> B-> C verwendet wird, können diese Transformationen manchmal kombiniert werden, indem sie in A-> C umgewandelt werden und das Erstellen von Objekt B entfällt. Diese Option ist nicht immer anwendbar, aber sie ist anwendbar das einfachste und effektivste.
- Pool von Objekten. Anstatt ständig neue Objekte zu erstellen und sie wegzuwerfen und den Garbage Collector zu laden, können wir eine Sammlung freier Objekte speichern. Im einfachsten Fall, wenn wir ein neues Objekt benötigen, nehmen wir es aus dem Pool oder erstellen ein neues, wenn der Pool leer ist. Wenn wir das Objekt nicht mehr benötigen, geben wir es an den Pool zurück. Ein gutes Beispiel ist ArrayPool in .NET Core, das auch in .NET Framework als Teil des System.Buffers Nuget-Pakets verfügbar ist.
- Verwenden Sie kleine statt große Objekte.
Betrachten wir beide Fälle großer Objekte getrennt - das Berechnen von Client-Caches und das Serialisieren in JSON.
Client-Cache-Berechnung
Der Pyrus-Webclient und mobile Anwendungen speichern die dem Benutzer zur Verfügung stehenden Daten (Projekte, Formulare, Benutzer usw.) zwischen. Das Caching wird verwendet, um die Arbeit zu beschleunigen. Es ist auch für die Arbeit im Offline-Modus erforderlich. Caches werden auf dem Server berechnet und an den Client übertragen. Sie sind für jeden Benutzer individuell, da sie von ihren Zugriffsrechten abhängen, und werden häufig aktualisiert, beispielsweise wenn die Verzeichnisse geändert werden, auf die er Zugriff hat.
Daher werden regelmäßig viele Client-Cache-Berechnungen auf dem Server durchgeführt und viele temporäre kurzlebige Objekte erstellt. Wenn der Benutzer eine große Organisation ist, kann er auf viele Objekte zugreifen. Die Client-Caches für ihn sind groß. Aus diesem Grund haben wir die Zuweisung von Speicher für große temporäre Arrays im Heap für große Objekte gesehen.
Lassen Sie uns die vorgeschlagenen Optionen analysieren, um die Erstellung großer Objekte zu vermeiden:
- Vollständige Entsorgung großer Gegenstände. Dieser Ansatz ist nicht anwendbar, da Datenaufbereitungsalgorithmen unter anderem das Sortieren und Vereinigen von Mengen verwenden und temporäre Puffer erfordern.
- Verwenden eines Pools von Objekten. Dieser Ansatz hat Schwierigkeiten:
- Die Vielfalt der verwendeten Sammlungen und die Arten der darin enthaltenen Elemente: HashSet, List und Array werden verwendet (die beiden letzteren können kombiniert werden). Int32, Int64 sowie alle Arten von Datenklassen werden in Sammlungen gespeichert. Für jeden verwendeten Typ benötigen Sie einen eigenen Pool, in dem auch Sammlungen unterschiedlicher Größe gespeichert werden.
- Schwierige Lebensdauer von Sammlungen. Um die Vorteile des Pools nutzen zu können, müssen die darin enthaltenen Objekte nach der Verwendung zurückgegeben werden. Dies kann erfolgen, wenn das Objekt in einer Methode verwendet wird. In unserem Fall ist die Situation jedoch komplizierter, da viele große Objekte zwischen Methoden wechseln, in Datenstrukturen eingefügt, auf andere Strukturen übertragen werden usw.
- Implementierung. Es gibt ArrayPool von Microsoft, aber wir brauchen noch List und HashSet. Wir haben keine geeignete Bibliothek gefunden, daher müssten wir die Klassen selbst implementieren.
- Verwendung kleiner Gegenstände. Ein großes Array kann in mehrere kleine Teile unterteilt werden, von denen ich den Heap für große Objekte nicht lade, sondern in der 0. Generation erstelle und dann in der 1. und 2. Generation den Standardpfad entlang gehe. Wir hoffen, dass sie nicht der 2. gerecht werden, sondern in der 0. oder im Extremfall in der 1. Generation vom Müllsammler abgeholt werden. Der Vorteil dieses Ansatzes besteht darin, dass die Änderungen am vorhandenen Code minimal sind. Schwierigkeiten:
- Implementierung. Wir haben keine geeigneten Bibliotheken gefunden, daher müssten wir die Klassen selbst schreiben. Der Mangel an Bibliotheken ist verständlich, da das Szenario „Sammlungen, die den Heap für große Objekte nicht laden“ ein sehr enger Bereich ist.
Wir haben uns entschlossen, den dritten Weg zu gehen und
unser Fahrrad zu
erfinden , um List und HashSet zu schreiben, ohne den Heap für große Objekte zu laden.
Stückliste
Unsere ChunkedList <T> implementiert Standardschnittstellen, einschließlich IList <T>, für die nur minimale Änderungen am vorhandenen Code erforderlich sind. Ja, und die von uns verwendete Newtonsoft.Json-Bibliothek kann sie automatisch serialisieren, da sie IEnumerable <T> implementiert:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
Die Standardliste <T> enthält die folgenden Felder: Array für Elemente und Anzahl der gefüllten Elemente. In ChunkedList <T> gibt es ein Array von Arrays von Elementen, die Anzahl der vollständig gefüllten Arrays und die Anzahl der Elemente im letzten Array. Jedes der Arrays von Elementen mit weniger als 85.000 Bytes:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
Da die ChunkedList <T> ziemlich kompliziert ist, haben wir detaillierte Tests dazu geschrieben. Jede Operation muss in mindestens zwei Modi getestet werden: in "klein", wenn die gesamte Liste in ein Stück mit einer Größe von bis zu 85.000 Byte passt, und in "groß", wenn sie aus mehr als einem Stück besteht. Darüber hinaus sind die Methoden für Methoden, die die Größe ändern (z. B. Hinzufügen), noch größer: "klein" -> "klein", "klein" -> "groß", "groß" -> "groß", "groß" -> " klein. " Hier gibt es einige verwirrende Grenzfälle, die Unit-Tests gut machen.
Die Situation wird durch die Tatsache vereinfacht, dass einige der Methoden der IList-Schnittstelle nicht verwendet werden und weggelassen werden können (z. B. Einfügen, Entfernen). Ihre Implementierung und Prüfung wäre ziemlich aufwändig. Darüber hinaus wird das Schreiben von Komponententests durch die Tatsache vereinfacht, dass wir keine neuen Funktionen entwickeln müssen. ChunkedList <T> sollte sich genauso verhalten wie List <T>. Das heißt, alle Tests sind wie folgt organisiert: Erstellen Sie eine Liste <T> und eine ChunkedList <T>, führen Sie dieselben Vorgänge für sie aus und vergleichen Sie die Ergebnisse.
Wir haben die Leistung mithilfe der BenchmarkDotNet-Bibliothek gemessen, um sicherzustellen, dass wir unseren Code beim Wechsel von List <T> zu ChunkedList <T> nicht wesentlich verlangsamen. Testen wir zum Beispiel das Hinzufügen von Elementen zur Liste:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
Und der gleiche Test mit List <T> zum Vergleich. Ergebnisse beim Hinzufügen von 500 Elementen (alles passt in ein Array):
Ergebnisse beim Hinzufügen von 50.000 Elementen (aufgeteilt in mehrere Arrays):
Detaillierte Beschreibung der Spalten in den Ergebnissen BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
Wenn Sie sich die Spalte "Mittelwert" ansehen, in der die durchschnittliche Testausführungszeit angezeigt wird, sehen Sie, dass unsere Implementierung nur 2 bis 2,5 Mal langsamer als der Standard ist. Wenn man bedenkt, dass Operationen mit Listen im realen Code nur einen kleinen Teil aller ausgeführten Aktionen ausmachen, wird dieser Unterschied unbedeutend. Die Spalte 'Gen 2 / 1k op' (die Anzahl der Baugruppen der 2. Generation für 1000 Testläufe) zeigt jedoch, dass wir das Ziel erreicht haben: Mit einer großen Anzahl von Elementen erzeugt ChunkedList in der 2. Generation keinen Müll, was unsere Aufgabe war.
Stücksatz
In ähnlicher Weise implementiert ChunkedHashSet <T> die ISet <T> -Schnittstelle. Beim Schreiben des ChunkedHashSet <T> haben wir die bereits in der ChunkedList implementierte kleine Chunk-Logik wiederverwendet. Zu diesem Zweck haben wir eine vorgefertigte Implementierung von HashSet <T> aus der .NET-Referenzquelle übernommen, die unter der MIT-Lizenz verfügbar ist, und Arrays durch ChunkedLists ersetzt.
In Unit-Tests verwenden wir denselben Trick wie für Listen: Wir vergleichen das Verhalten von ChunkedHashSet <T> mit dem Referenz-HashSet <T>.
Zum Schluss Leistungstests. Die Hauptoperation, die wir verwenden, ist die Vereinigung von Mengen, weshalb wir sie testen:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
Und genau der gleiche Test für das Standard-HashSet. Erster Test für kleine Sets:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
Der zweite Test für große Mengen, der ein Problem mit einer Reihe großer Objekte verursachte:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
Die Ergebnisse ähneln den Auflistungen. ChunkedHashSet ist 2-2,5-mal langsamer, lädt aber gleichzeitig bei großen Sets die 2. Generation um 2 Größenordnungen weniger.
Serialisierung in JSON
Der Pyrus-Webserver bietet mehrere APIs, die unterschiedliche Serialisierungen verwenden. Wir haben die Erstellung großer Objekte in der von Bots verwendeten API und dem Synchronisierungsdienstprogramm (im Folgenden als öffentliche API bezeichnet) entdeckt. Beachten Sie, dass die API grundsätzlich eine eigene Serialisierung verwendet, die von diesem Problem nicht betroffen ist. Wir haben darüber im Artikel
https://habr.com/en/post/227595/ im Abschnitt "2. Sie wissen nicht, wo der Engpass Ihrer Anwendung liegt. " Das heißt, die Haupt-API funktioniert bereits gut, und das Problem trat in der öffentlichen API auf, als die Anzahl der Anforderungen und die Datenmenge in den Antworten zunahmen.
Lassen Sie uns die öffentliche API optimieren. Am Beispiel der Haupt-API wissen wir, dass Sie im Streaming-Modus eine Antwort an den Benutzer zurückgeben können. Das heißt, Sie müssen keine Zwischenpuffer erstellen, die die gesamte Antwort enthalten, sondern die Antwort sofort in den Stream schreiben.
Bei näherer Betrachtung haben wir festgestellt, dass wir beim Serialisieren der Antwort einen temporären Puffer für das Zwischenergebnis erstellen ('content' ist ein Array von Bytes, die JSON in UTF-8-Codierung enthalten):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
Mal sehen, wo Inhalte verwendet werden. Aus historischen Gründen basiert die öffentliche API auf WCF, für das XML das Standard-Anforderungs- und Antwortformat ist. In unserem Fall enthält die XML-Antwort ein einzelnes 'Binär'-Element, in das in Base64 codiertes JSON geschrieben ist:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
Beachten Sie, dass hier kein temporärer Puffer benötigt wird. JSON kann sofort in den von WCF bereitgestellten XmlWriter-Puffer geschrieben und im laufenden Betrieb in Base64 codiert werden. Wir werden also den ersten Weg gehen und die Speicherzuweisung loswerden:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
Hier ist Base64Writer ein einfacher Wrapper über XmlWriter, der die Stream-Schnittstelle implementiert, die als Base64 in XmlWriter schreibt. Gleichzeitig reicht es aus, von der gesamten Schnittstelle aus nur eine Write-Methode zu implementieren, die in StreamWriter aufgerufen wird:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
Induzierte gc
Versuchen wir, mit mysteriösen Müllsammlungen umzugehen. Wir haben unseren Code zehnmal auf GC.Collect-Aufrufe überprüft, dies ist jedoch fehlgeschlagen. Ich habe es geschafft, diese Ereignisse in PerfView abzufangen, aber der Aufrufstapel ist nicht sehr bezeichnend (DotNETRuntime / GC / Triggered-Ereignis):
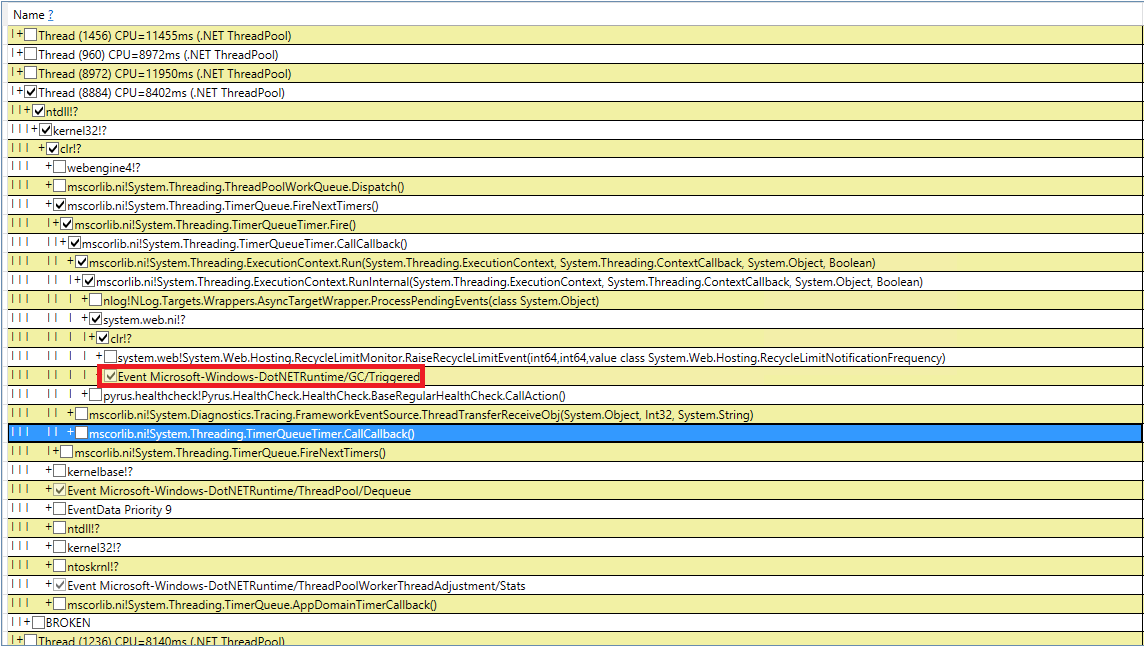
Es gibt einen kleinen Hinweis: RecycleLimitMonitor.RaiseRecycleLimitEvent vor der induzierten Garbage Collection aufrufen. Verfolgen wir den Aufrufstapel der RaiseRecycleLimitEvent-Methode:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
Die Namen der Methoden stimmen mit ihren Funktionen überein:
- Im Konstruktor von RecycleLimitMonitor.RecycleLimitMonitorSingleton wird ein Timer erstellt, der PBytesMonitorThread in einem bestimmten Intervall aufruft.
- PBytesMonitorThread sammelt Statistiken zur Speichernutzung und ruft unter bestimmten Umständen CollectInfrequently auf.
- CollectInfrequently ruft AlertProxyMonitors auf, ruft als Ergebnis einen Bool ab und ruft GC.Collect () auf, wenn es wahr wird. Er überwacht auch die Zeit, die seit dem letzten Anruf beim Garbage Collector vergangen ist, und ruft sie nicht zu oft auf.
- AlertProxyMonitors geht die Liste der ausgeführten IIS-Webanwendungen durch, löst für jede das entsprechende RecycleLimitMonitor-Objekt aus und ruft RaiseRecycleLimitEvent auf.
- RaiseRecycleLimitEvent löst die IObserver-Liste <RecycleLimitInfo> aus. Die Handler erhalten als Parameter RecycleLimitInfo, in dem sie das RequestGC-Flag setzen können, das häufig zu CollectInfre zurückkehrt und eine induzierte Garbage Collection verursacht.
Weitere Untersuchungen zeigen, dass IObserver <RecycleLimitInfo> -Handler in der RecycleLimitMonitor.Subscribe () -Methode hinzugefügt werden, die in der AspNetMemoryMonitor.Subscribe () -Methode aufgerufen wird. Außerdem ist der Standard-IObserver-Handler <RecycleLimitInfo> (die RecycleLimitObserver-Klasse) in der AspNetMemoryMonitor-Klasse hängen, die ASP.NET-Caches bereinigt und manchmal nach Garbage Collection fragt.
Das Rätsel der induzierten GC ist fast gelöst. Es bleibt die Frage, warum diese Garbage Collection aufgerufen wird. RecycleLimitMonitor überwacht die Verwendung des IIS-Speichers (genauer gesagt die Anzahl der privaten Bytes). Wenn sich die Verwendung einer bestimmten Grenze nähert, beginnt ein ziemlich verwirrender Algorithmus, um das RaiseRecycleLimitEvent-Ereignis auszulösen. Der Wert von AspNetMemoryMonitor.ProcessPrivateBytesLimit wird als Speicherlimit verwendet und enthält wiederum die folgende Logik:
- Wenn der Anwendungspool in IIS auf "Private Memory Limit (KB)" eingestellt ist, wird der Wert in Kilobyte von dort übernommen
- Andernfalls werden bei 64-Bit-Systemen 60% des physischen Speichers belegt (bei 32-Bit-Systemen ist die Logik komplizierter).
Das Ergebnis der Untersuchung lautet: ASP.NET nähert sich seinem Speicherlimit und ruft regelmäßig die Garbage Collection auf. Das 'Private Memory Limit (KB)' wurde nicht festgelegt, daher war ASP.NET auf 60% des physischen Speichers beschränkt. Das Problem wurde durch die Tatsache maskiert, dass auf dem Task-Manager-Server viel freier Speicher angezeigt wurde und es anscheinend fehlte. Wir haben den Wert für "Private Memory Limit (KB)" in den Anwendungspooleinstellungen in IIS auf 80% des physischen Speichers erhöht. Dies ermutigt ASP.NET, mehr verfügbaren Speicher zu verwenden. Wir haben auch die Überwachung des Leistungsindikators '.NET CLR Memory / # Induced GC' hinzugefügt, um das nächste Mal nicht zu verpassen, wenn ASP.NET entscheidet, dass es sich der Grenze der Speichernutzung nähert.
Wiederholte Messungen
Mal sehen, was nach all diesen Änderungen mit der Garbage Collection passiert ist. Beginnen wir mit perfview / GCCollectOnly (Trace-Zeit - 1 Stunde), GCStats-Bericht:
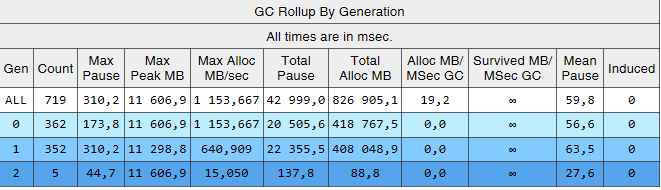
Es ist ersichtlich, dass die Baugruppen der 2. Generation jetzt 2 Größenordnungen kleiner sind als die 0. und 1 .. Auch die Zeit dieser Baugruppen nahm ab. Induzierte Baugruppen werden nicht mehr beobachtet. Schauen wir uns die Liste der Baugruppen der 2. Generation an:
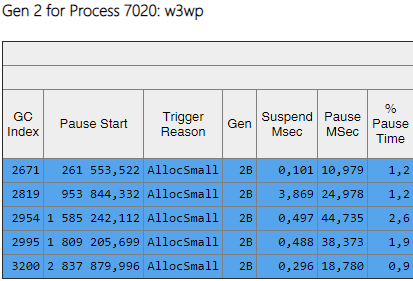
Die Spalte Gen zeigt, dass alle Baugruppen der 2. Generation zum Hintergrund geworden sind ('2B' bedeutet 2. Generation, Hintergrund). Das heißt, der größte Teil der Arbeit wird parallel zur Ausführung der Anwendung ausgeführt, und alle Threads werden für kurze Zeit blockiert (Spalte 'MSec anhalten'). Schauen wir uns die Pausen beim Erstellen großer Objekte an:

Es ist ersichtlich, dass die Anzahl solcher Pausen beim Erstellen großer Objekte erheblich gesunken ist.
Zusammenfassung
Dank der im Artikel beschriebenen Änderungen konnte die Anzahl und Dauer der Baugruppen der 2. Generation deutlich reduziert werden. Es gelang mir, die Ursache für die induzierten Baugruppen zu finden und sie loszuwerden. Die Anzahl der Baugruppen der 0. und 1. Generation nahm zu, ihre durchschnittliche Dauer nahm jedoch ab (von ~ 200 ms auf ~ 60 ms). Die maximale Montagedauer der 0. und 1. Generation hat sich verringert, jedoch nicht so deutlich. Baugruppen der 2. Generation wurden schneller, lange Pausen bis zu 1000 ms sind komplett weg.
Die Schlüsselmetrik „Prozentsatz langsamer Abfragen“ verringerte sich nach allen Änderungen um 40%.
Dank unserer Arbeit haben wir erkannt, welche Leistungsindikatoren erforderlich sind, um die Situation mit Speicher- und Speicherbereinigung zu bewerten, und sie zur kontinuierlichen Überwachung zu Zabbix hinzugefügt. Hier ist eine Liste der wichtigsten, auf die wir achten und deren Grund wir herausfinden (z. B. ein erhöhter Fluss von Anforderungen, eine große Menge übertragener Daten, ein Fehler in der Anwendung):