Der Titel des Artikels mag seltsam und aus gutem Grund erscheinen - er ist schön, gerade weil er nicht von mir geschrieben wurde, sondern vom neuronalen LSTM-Netzwerk (oder vielmehr seinem Teil vor dem „oder“).
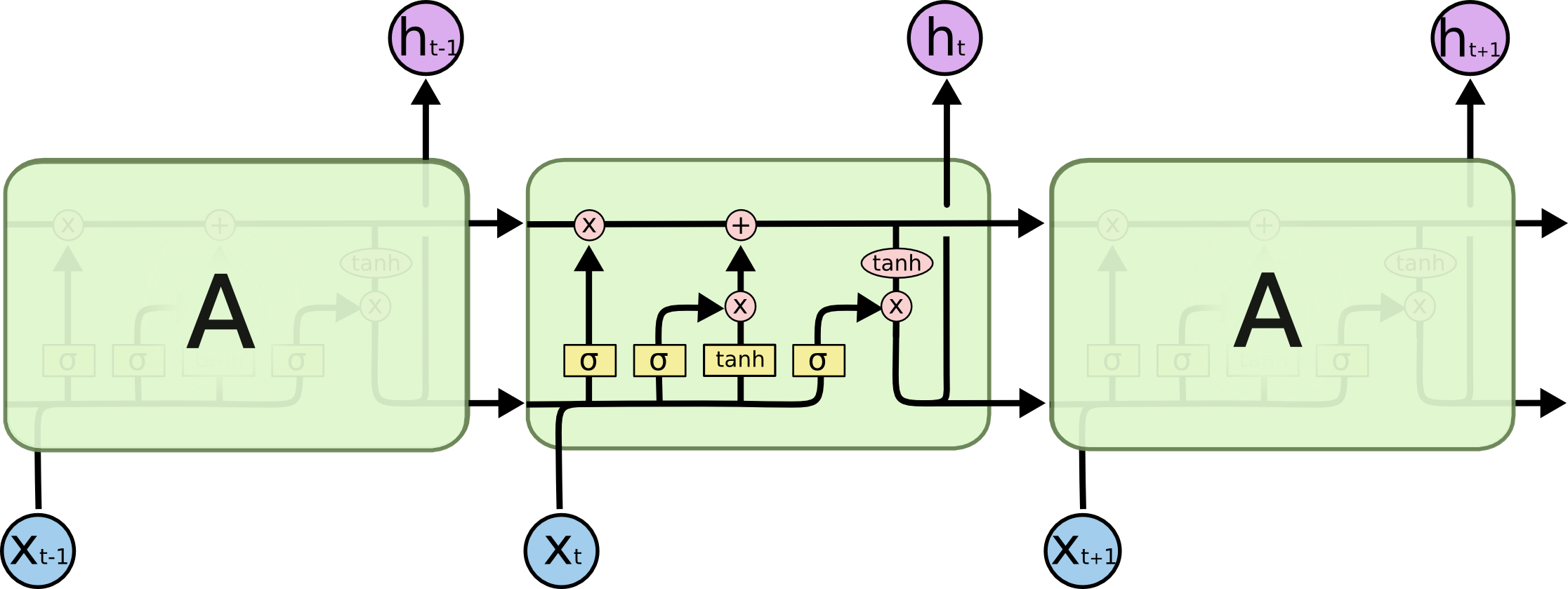
(LSTM-Schema aus dem Verständnis von LSTM-Netzwerken )
Und heute werden wir herausfinden, wie Sie die Überschriften von Habrs Artikeln generieren können (und im Prinzip kann der Text selbst von derselben Neuro-Architektur generiert werden). Der gesamte Code kann online in Notebooks von Google ausgeführt werden. Daten sind wie immer auf Github geöffnet.
Und hier können Sie das bereits trainierte Modell auf der GPU von Google (kostenlos und ohne SMS) ausführen und tatsächlich Header generieren.
Wichtige Links
Die Theorie und Beschreibung neuronaler Netze (insbesondere LSTM) in diesem Artikel basieren auf
Datenbeschreibung
Insgesamt wurden ca. 40.000 Artikeltitel gesammelt: Jeder Titel wurde am Anfang und Ende mit zwei Sonderzeichen <START_CHAR> und <END_CHAR> sowie <PADDING_CHAR> nach <END_CHAR> bis zur maximalen Größe des Titels ergänzt.
Ein Beispiel für die gesammelten Daten:
Google IT . Now it's official
LSTM-Theorie
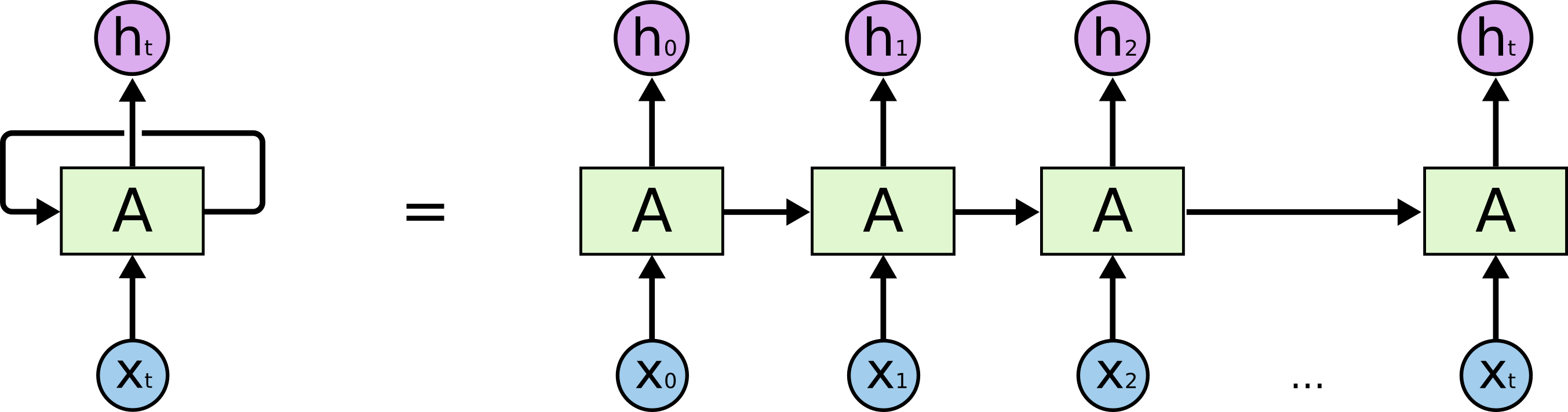
Beginnen wir mit der eigentlichen Aufgabe, die wir lösen: Wir möchten die (N + 1) -te Zeile in N Zeichen vorhersagen. Aus Sicht des LSTM-Modells sieht dies wie folgt aus: X unten - Eingabedaten; h i oben sind Wochenenden; zwischen ihnen ist der interne Zustand des Netzwerks. Etwas detaillierter - das Bild links mit einer Rückkopplungsschleife, die einer detaillierten Kette rechts entspricht.
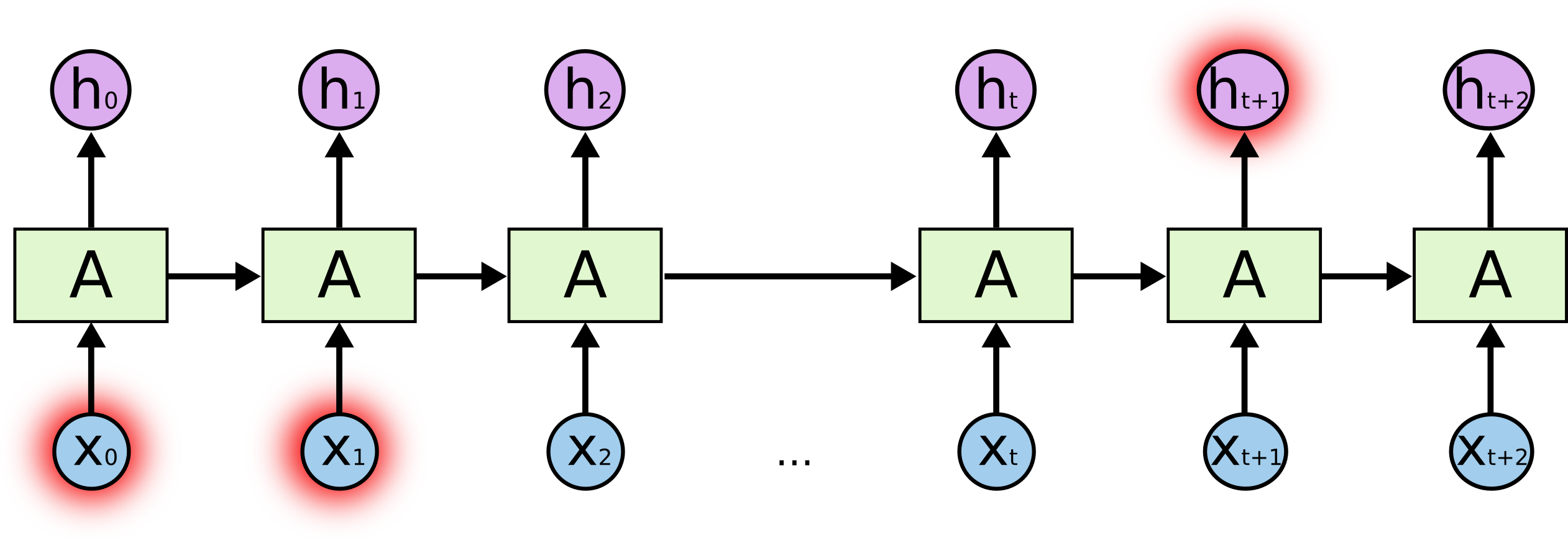
Was ist das Salz? Bei der Vorhersage eines hervorgehobenen Zeichens am Ende können am Anfang hervorgehobene Zeichen eine Schlüsselrolle spielen - daher der Begriff Langzeitabhängigkeiten. Es ist klar, dass häufig die unmittelbar neben ihnen stehenden Zeichen eine wichtige Rolle spielen - solche Abhängigkeiten werden als kurzfristige Abhängigkeiten bezeichnet.
Interne LSTM-Zellen:
Die gesamte Zelle enthält vier Grundelemente.
- Tore des Vergessens - ein Element entscheidet, dass es nicht mehr im Gedächtnis bleibt
- Eingehendes Gate - Es erstellt eine Reihe von "Kandidatenwerten", die wir zum Schreiben und Aktualisieren des Speichers verwenden können
- Speicher - ein Element entscheidet, was tatsächlich und wie wir speichern
- Ausgabeelement - Definiert die Ausgabe des Modells
Bezeichnungen:

Tor des Vergessens
Wenn wir versuchen, das Ende eines Wortes vorherzusagen - es ist wichtig, das Geschlecht des aktuellen Substantivs zu kennen, wenn wir ein neues Substantiv gesehen haben -, lohnt es sich, die vorherige Bedeutung zu vergessen:

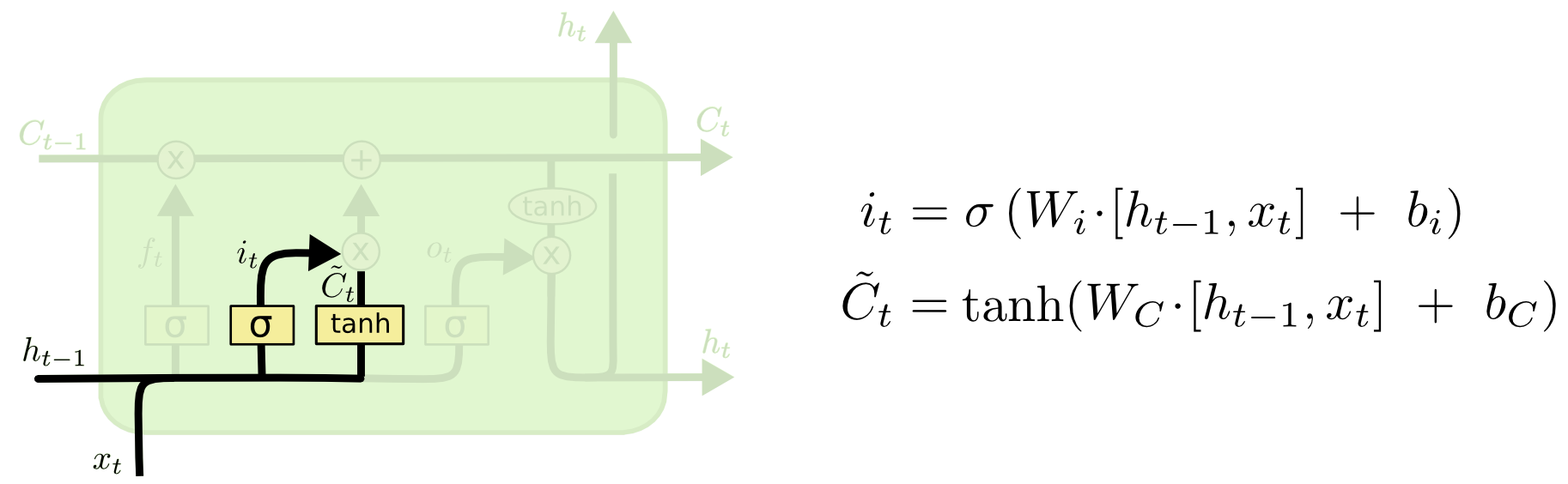
Eingehendes Tor
Als nächstes berechnen wir i t , wodurch bestimmt wird, welche Werte der Speicherzelle aktualisiert werden sollen, und
berechnet die Kandidatenwerte für die Aktualisierung.
Speicherzelle
Als nächstes sind die Speicherwerte eine Überlagerung dessen, was wir im aktuellen Zustand vergessen und was wir hinzugefügt haben

Modellausgabe
Was ist Modellinferenz - eine Kombination aus drei Dingen: dem aktuellen Eingabesymbol, der vorherigen Vorhersage und dem Modellspeicher

Code
Die Grundlogik des Modells wird in der Regel unten dargestellt: Dies sind etwa 5-10% des gesamten Codes. Der gesamte verbleibende Code bereinigt, bereitet und verarbeitet Daten und gibt sie in einer für Menschen lesbaren Form aus.
Hier können Sie den Code mit einem bereits trainierten Modell ausführen.
model = Sequential()
Beispiele für erstellte Header
Persönliche Probenahme:
python powershell
(Zufällige Modellverweise auf Dr. Strangelove sind besonders erfreulich)
Was ist Temperatur (im Kontext von DL)
Am Ausgang generiert das Modell die Gewichte x w der Wörter w - wir haben Optionen, wie diese Gewichte in Wahrscheinlichkeiten p (w) umgewandelt werden können, beispielsweise unter Verwendung der folgenden Formel:
Wenn T ein freier Parameter ist (in der Physik wird auf diese Weise die Temperatur statistisch bestimmt - daher der Name), wird der Exponent umso größer, je niedriger die Temperatur ist. Je höher die Gewichte sind, desto größer ist die Wahrscheinlichkeit, dass das Modell nur wenige Wörter mit Maximum vorhersagt Gewichte, wenn die Temperatur hoch ist, dann bewegt sich die Verteilung zu einer einheitlichen und "kreativeren". Dies gibt uns die Möglichkeit, das Gleichgewicht zwischen der genauen Verfolgung der verfügbaren Daten und der bedingten Kreativität des Modells zu steuern.
Beispiel für die Modellausgabe using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
Schlussfolgerungen
- Die LSTM-Architektur modelliert Sequenzen gut und klar
- Grammatik und Logik leiden häufig - höchstwahrscheinlich an zwei Stellen: Erstens ist das Speichergerät recht einfach und kann nicht alle Regeln und den Kontext erfassen. zweitens die Macht des Falles - der Datensatz ist ziemlich klein und nicht zu vielfältig
- Es wäre interessant, die Version von Better Language Models und ihre Implikationen im großen Fall der russischen Sprache zu betrachten, um zu verstehen, ob Architektur und ein leistungsfähigerer Fall diese Probleme lösen
- Einige der Schlagzeilen kamen unglaublich lächerlich und selbstironisch heraus, zum Beispiel "... und warum die Schuld dafür"
- Wir sehen bestimmte Muster in den Überschriften von Habr, zum Beispiel "Wir haben \ erstellt \ gebaut", ein klarer Indikator dafür, dass Menschen gerne persönliche Geschichten über Habr teilen