Teil 1
Teil 3
Wechseln von Daten zu Ergebnissen, ohne Ihren Computer zu verlassen

Ein Stapel von Bildern einer kleinen Zone in Slowenien und eine Karte mit einer klassifizierten Landbedeckung, die mit den im Artikel beschriebenen Methoden erhalten wurde.
Vorwort
Der zweite Teil einer Reihe von Artikeln zur Klassifizierung der Landbedeckung mithilfe der Eo-Learn-Bibliothek. Wir erinnern Sie daran, dass der erste Artikel Folgendes demonstrierte:
- Teilen von AOI (Area of Interest) in Fragmente namens EOPatch
- Empfangen von Bildern und Wolkenmasken von Sentinel-2-Satelliten
- Berechnung zusätzlicher Informationen wie NDWI , NDVI
- Erstellen einer Referenzmaske und Hinzufügen zu den Quelldaten
Darüber hinaus haben wir eine Oberflächenstudie der Daten durchgeführt. Dies ist ein äußerst wichtiger Schritt, bevor wir mit dem maschinellen Lernen beginnen. Die obigen Aufgaben wurden durch ein Beispiel in Form eines Jupyter-Notizbuchs ergänzt , das nun Material aus diesem Artikel enthält.
In diesem Artikel werden wir die Aufbereitung der Daten abschließen und 2017 das erste Modell für die Erstellung von Landbedeckungskarten für Slowenien erstellen.
Datenaufbereitung
Die Menge an Code, die sich direkt auf maschinelles Lernen bezieht, ist im Vergleich zum vollständigen Programm recht gering. Der Löwenanteil der Aufgabe besteht darin, die Daten zu löschen und die Daten so zu manipulieren, dass eine nahtlose Verwendung mit dem Klassifikator gewährleistet ist. Dieser Teil der Arbeit wird unten beschrieben.

Ein Pipeline-Diagramm für maschinelles Lernen, das zeigt, dass der Code selbst, der ML verwendet, einen kleinen Bruchteil des gesamten Prozesses ausmacht. Quelle
Cloud-Bildfilterung
Wolken sind Entitäten, die normalerweise auf einer Skala erscheinen, die unseren durchschnittlichen EOPatch überschreitet (1000 x 1000 Pixel, Auflösung 10 m). Dies bedeutet, dass jede Site an zufälligen Daten vollständig von Wolken bedeckt sein kann. Solche Bilder enthalten keine nützlichen Informationen und verbrauchen nur Ressourcen. Daher überspringen wir sie basierend auf dem Verhältnis der gültigen Pixel zur Gesamtzahl und legen einen Schwellenwert fest. Wir können alle Pixel als gültig bezeichnen, die nicht als Wolken klassifiziert sind und sich in einem Satellitenbild befinden. Beachten Sie auch, dass wir die mit den Sentinel-2-Bildern gelieferten Masken nicht verwenden, da sie auf der Ebene der Vollbilder berechnet werden (die Größe des vollständigen S2-Bilds beträgt 10980 × 10980 Pixel, ungefähr 110 × 110 km), was bedeutet, dass es für unseren AOI größtenteils nicht benötigt wird. Um die Wolken zu bestimmen, verwenden wir den Algorithmus aus dem s2cloudless- Paket, um eine Maske aus Wolkenpixeln zu erhalten.
In unserem Notizbuch ist der Schwellenwert auf 0,8 eingestellt, sodass wir nur Bilder auswählen, die zu 80% mit normalen Daten gefüllt sind. Dies mag nach einem ziemlich hohen Wert klingen, aber da Wolken für unsere AOI kein allzu großes Problem darstellen, können wir es uns leisten. Es ist zu bedenken, dass dieser Ansatz nicht gedankenlos auf irgendeinen Punkt auf dem Planeten angewendet werden kann, da das von Ihnen ausgewählte Gebiet für einen bedeutenden Teil des Jahres mit Wolken bedeckt sein kann.
Zeitliche Interpolation
Aufgrund der Tatsache, dass Bilder an bestimmten Daten übersprungen werden können, sowie aufgrund inkonsistenter AOI-Erfassungsdaten kommt es im Bereich der Erdbeobachtung häufig zu Datenmangel. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, eine Maske mit Pixelgültigkeit (aus dem vorherigen Schritt) aufzuerlegen und die Werte zu interpolieren, um "Löcher zu füllen". Als Ergebnis des Interpolationsprozesses können fehlende Pixelwerte berechnet werden, um ein EOPatch zu erstellen, das Schnappschüsse an gleichmäßig verteilten Tagen enthält. In diesem Beispiel haben wir die lineare Interpolation verwendet, es gibt jedoch auch andere Methoden, von denen einige bereits in eo-learn implementiert sind.

Auf der linken Seite befindet sich ein Stapel von Sentinel-2-Bildern einer zufällig ausgewählten AOI. Transparente Pixel bedeuten fehlende Daten aufgrund von Wolken. Das Bild rechts zeigt den Stapel nach der Interpolation unter Berücksichtigung von Wolkenmasken.
Zeitliche Informationen sind äußerst wichtig für die Klassifizierung der Deckung und noch wichtiger für die Identifizierung einer Keimkultur. Dies alles ist auf die Tatsache zurückzuführen, dass eine große Menge an Informationen über die Landbedeckung darin verborgen ist, wie sich das Grundstück im Laufe des Jahres ändert. Wenn Sie beispielsweise die interpolierten NDVI-Werte anzeigen, können Sie feststellen, dass die Werte in den Wäldern und Feldern im Frühjahr / Sommer ihre Höchstwerte erreichen und im Herbst / Winter stark abfallen, während das Wasser und die künstlichen Oberflächen diese Werte das ganze Jahr über ungefähr konstant halten. Künstliche Oberflächen haben im Vergleich zu Wasser etwas höhere NDVI-Werte und wiederholen teilweise die Entwicklung von Wäldern und Feldern, da in Städten häufig Parks und andere Vegetation zu finden sind. Sie sollten auch die Einschränkungen berücksichtigen, die mit der Auflösung von Bildern verbunden sind. Oft können Sie in dem von einem Pixel abgedeckten Bereich mehrere Arten der Abdeckung gleichzeitig beobachten.
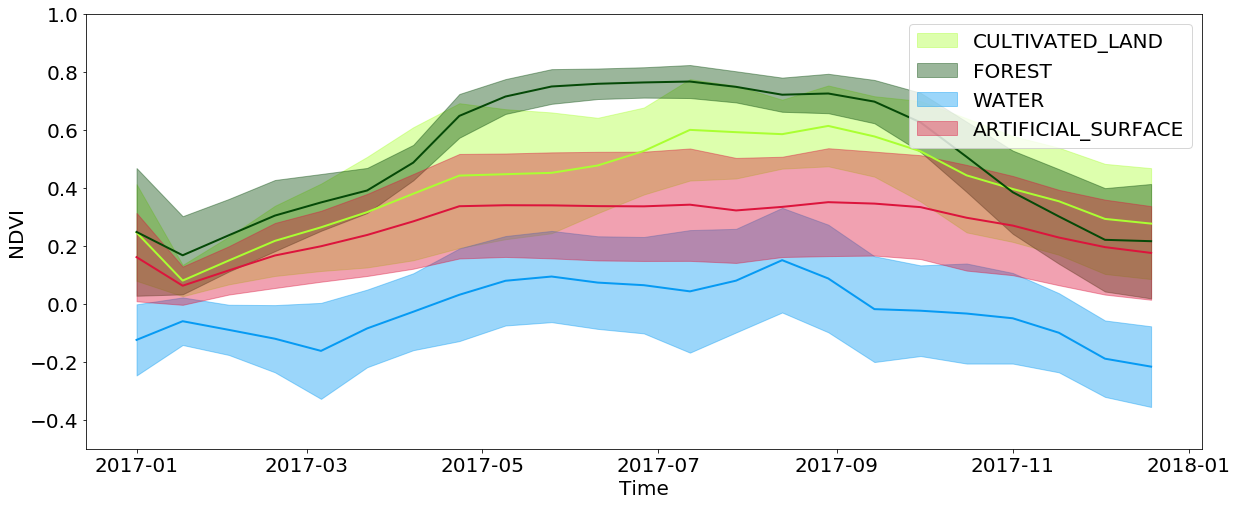
Zeitliche Entwicklung der NDVI-Werte für Pixel aus bestimmten Arten der Landbedeckung im Laufe des Jahres
Negative Pufferung
Obwohl eine Bildauflösung von 10 m für eine Vielzahl von Aufgaben ausreicht, sind die Nebenwirkungen kleiner Objekte erheblich. Solche Objekte befinden sich an der Grenze zwischen verschiedenen Deckungstypen, und diesen Pixeln werden nur die Werte eines der Typen zugewiesen. Aus diesem Grund ist beim Training des Klassifikators ein übermäßiges Rauschen in den Eingabedaten vorhanden, was das Ergebnis verschlechtert. Außerdem sind Straßen und andere Objekte mit einer Breite von 1 Pixel auf der Originalkarte vorhanden, obwohl sie anhand der Bilder äußerst schwer zu identifizieren sind. Wir wenden eine negative 1-Pixel-Pufferung auf die Referenzkarte an und entfernen fast alle Problembereiche aus der Eingabe.
AOI-Referenzkarte vor (links) und nach (rechts) negativer Pufferung
Zufällige Datenauswahl
Wie in einem früheren Artikel erwähnt, ist der gesamte AOI in ungefähr 300 Fragmente unterteilt, von denen jedes aus ~ 1 Million Pixel besteht. Dies ist eine ziemlich beeindruckende Menge dieser Pixel. Daher benötigen wir für jedes EOPatch gleichmäßig etwa 40.000 Pixel, um einen Datensatz von 12 Millionen Kopien zu erhalten. Da die Pixel gleichmäßig aufgenommen werden, spielt eine große Anzahl auf der Referenzkarte keine Rolle, da diese Daten unbekannt sind (oder nach dem vorherigen Schritt verloren gegangen sind). Es ist sinnvoll, solche Daten herauszufiltern, um das Training des Klassifikators zu vereinfachen, da wir ihm nicht beibringen müssen, das Etikett „Keine Daten“ zu definieren. Das gleiche Verfahren wird für den Testsatz wiederholt, da solche Daten die Qualitätsindikatoren von Klassifikatorvorhersagen künstlich verschlechtern.
Wir haben die Eingabedaten in Trainings- / Testsätze mit einem Verhältnis von 80/20% auf EOPatch-Ebene unterteilt, was uns garantiert, dass sich diese Sätze nicht überschneiden. Auf die gleiche Weise teilen wir auch die Pixel aus dem Satz für das Training in Sätze für das Testen und die Kreuzvalidierung auf. Nach der Trennung erhalten wir ein numpy.ndarray Array mit Dimensionen (p,t,w,h,d) , wobei:
p ist die Anzahl der EOPatch im Datensatz
t - die Anzahl der interpolierten Bilder für jedes EOPatch
* w, h, d - Breite, Höhe und Anzahl der Ebenen in den Bildern.
Nach Auswahl der Teilmengen entspricht die Breite w der Anzahl der ausgewählten Pixel (z. B. 40.000), während die Dimension h beträgt. Der Unterschied in der Form des Arrays ändert nichts. Dieses Verfahren ist nur erforderlich, um die Arbeit mit Bildern zu vereinfachen.
Die Daten von den Sensoren und der Maske d in einem beliebigen Bild t bestimmen die Eingabedaten für das Training, wobei solche Fälle insgesamt p*w*h . Um die Daten in ein für den Klassifizierer verdauliches Formular zu konvertieren, müssen wir die Dimension des Arrays von 5 auf die Matrix des Formulars (p*w*h, d*t) reduzieren. Dies ist mit dem folgenden Code einfach zu bewerkstelligen:
import numpy as np p, t, w, h, d = features_array.shape
Ein solches Verfahren ermöglicht es, neue Daten derselben Form vorherzusagen, sie dann zurück zu konvertieren und mit Standardmitteln zu visualisieren.
Erstellen eines maschinellen Lernmodells
Die optimale Auswahl des Klassifikators hängt stark von der spezifischen Aufgabe ab, und selbst bei der richtigen Wahl sollten wir die Parameter eines bestimmten Modells nicht vergessen, die von Aufgabe zu Aufgabe geändert werden müssen. In der Regel müssen viele Experimente mit unterschiedlichen Parametersätzen durchgeführt werden, um genau zu sagen, was in einer bestimmten Situation erforderlich ist.
In dieser Artikelserie verwenden wir das LightGBM- Paket, da es ein intuitives, schnelles, verteiltes und produktives Framework zum Erstellen von Modellen ist, die auf Entscheidungsbäumen basieren. Zur Auswahl von Klassifikator-Hyperparametern können verschiedene Ansätze verwendet werden, z. B. die Rastersuche , die an einem Testsatz getestet werden sollte. Der Einfachheit halber überspringen wir diesen Schritt und verwenden die Standardparameter.
Das Arbeitsschema von Entscheidungsbäumen in LightGBM. Quelle
Die Implementierung des Modells ist recht einfach. Da die Daten bereits in Form einer Matrix vorliegen, geben wir diese Daten einfach an die Eingabe des Modells weiter und warten. Glückwunsch! Jetzt können Sie jedem sagen, dass Sie sich mit maschinellem Lernen beschäftigen und der modischste Typ auf einer Party sein werden, während Ihre Mutter wegen der Rebellion von Robotern und dem Tod der Menschheit nervös sein wird.
Modellvalidierung
Trainingsmodelle für maschinelles Lernen sind einfach. Die Schwierigkeit besteht darin, sie gut zu trainieren. Dafür benötigen wir einen geeigneten Algorithmus, eine zuverlässige Referenzkarte und eine ausreichende Menge an Rechenressourcen. Aber selbst in diesem Fall sind die Ergebnisse möglicherweise nicht das, was Sie wollten. Daher ist es unbedingt erforderlich, den Klassifikator mit Fehlermatrizen und anderen Metriken zu überprüfen, um zumindest ein gewisses Vertrauen in die Ergebnisse Ihrer Arbeit zu haben.
Fehlermatrix
Fehlermatrizen sind die ersten Dinge, die bei der Bewertung der Qualität von Klassifizierern berücksichtigt werden müssen. Sie zeigen die Anzahl der korrekt und falsch vorhergesagten Tags für jedes Tag auf der Referenzkarte und umgekehrt. Normalerweise wird eine normalisierte Matrix verwendet, bei der alle Werte in den Zeilen durch den Gesamtbetrag geteilt werden. Dies zeigt, ob der Klassifikator keine Tendenz zu einer bestimmten Art von Deckung im Verhältnis zu einer anderen hat
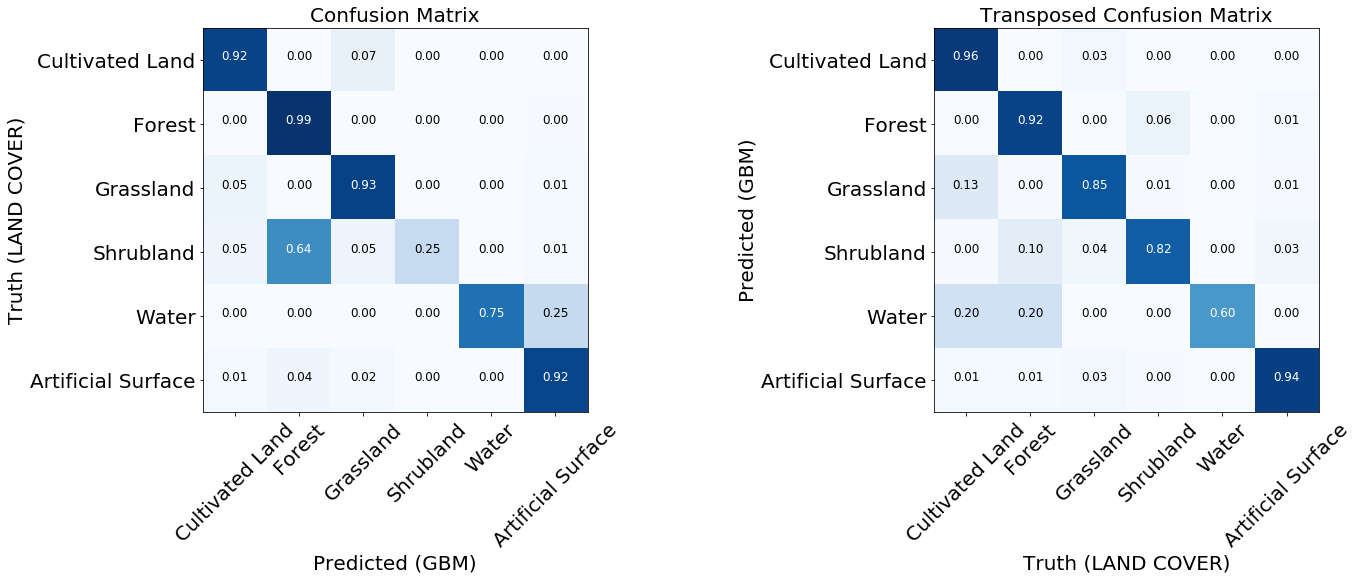
Zwei normalisierte Fehlermatrizen des trainierten Modells.
Für die meisten Klassen zeigt das Modell gute Ergebnisse. Bei einigen Klassen treten Fehler aufgrund eines Ungleichgewichts in den Eingabedaten auf. Wir sehen, dass das Problem beispielsweise Büsche und Wasser sind, bei denen das Modell Pixelbeschriftungen häufig verwechselt und falsch identifiziert. Andererseits korreliert das, was als Busch oder Wasser markiert ist, recht gut mit der Referenzkarte. Aus dem folgenden Bild können wir ersehen, dass Probleme für Klassen mit einer geringen Anzahl von Trainingsinstanzen auftreten - dies ist hauptsächlich auf die geringe Datenmenge in unserem Beispiel zurückzuführen, aber dieses Problem kann bei jeder realen Aufgabe auftreten.
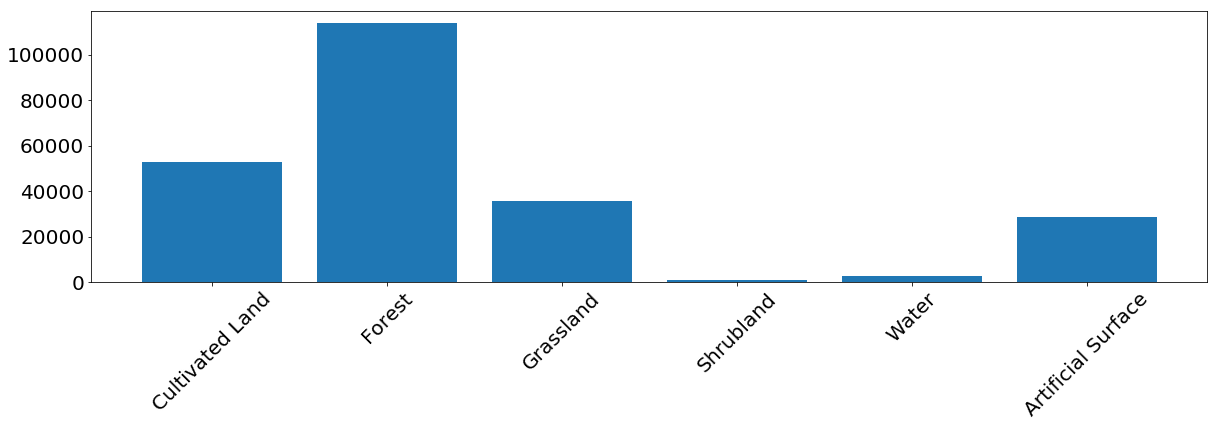
Die Häufigkeit des Auftretens von Pixeln jeder Klasse im Trainingssatz.
Betriebscharakteristik des Empfängers - ROC-Kurve
Klassifizierer sagen Etiketten mit einer bestimmten Sicherheit voraus, aber dieser Schwellenwert für ein bestimmtes Etikett kann geändert werden. Die ROC-Kurve zeigt die Fähigkeit des Klassifikators, beim Ändern der Empfindlichkeitsschwelle korrekte Vorhersagen zu treffen. Normalerweise wird dieser Graph für binäre Systeme verwendet, aber er kann in unserem Fall verwendet werden, wenn wir für jede Klasse das Merkmal „Label gegen alle anderen“ berechnen. Die x-Achse zeigt falsch positive Ergebnisse (wir müssen ihre Anzahl minimieren) und die y-Achse zeigt wahr-positive Ergebnisse (wir müssen ihre Anzahl erhöhen) bei verschiedenen Schwellenwerten. Ein guter Klassifikator kann durch eine Kurve beschrieben werden, unter der die Fläche der Kurve maximal ist. Dieser Indikator wird auch als Fläche unter der Kurve (AUC) bezeichnet. Aus den Diagrammen der ROC-Kurven kann man die gleichen Schlussfolgerungen über eine unzureichende Anzahl von Beispielen der „Busch“ -Klasse ziehen, obwohl die Kurve für Wasser viel besser aussieht - dies liegt an der Tatsache, dass sich das Wasser optisch stark von anderen Klassen unterscheidet, selbst wenn die Anzahl der Beispiele in den Daten nicht ausreicht.

ROC-Kurven des Klassifikators in Form von "Eins gegen Alle" für jede Klasse. Zahlen in Klammern sind AUC-Werte.
Die Bedeutung der Symptome
Wenn Sie sich eingehender mit den Feinheiten des Klassifikators befassen möchten, können Sie sich das Feature-Wichtigkeitsdiagramm ansehen, in dem angegeben ist, welche der Zeichen das Endergebnis stärker beeinflusst haben. Einige Algorithmen für maschinelles Lernen, wie der in diesem Artikel verwendete, geben diese Werte zurück. Bei anderen Modellen muss diese Metrik von uns selbst berücksichtigt werden.

Die Matrix der Wichtigkeit von Merkmalen für den Klassifikator aus dem Beispiel
Obwohl andere Zeichen im Frühjahr (NDVI) im Allgemeinen wichtiger sind, sehen wir, dass es ein genaues Datum gibt, an dem eines der Zeichen (B2 - blau) das wichtigste ist. Wenn Sie sich die Bilder ansehen, stellt sich heraus, dass der AOI in dieser Zeit mit Schnee bedeckt war. Es kann gefolgert werden, dass Schnee Informationen über die darunter liegende Abdeckung preisgibt, was dem Klassifizierer bei der Bestimmung der Art der Oberfläche sehr hilft. Es sei daran erinnert, dass ein solches Phänomen spezifisch für den beobachteten AOI ist und im Allgemeinen nicht als verlässlich angesehen werden kann.

Schneebedecktes 3x3 EOPatch AOI Teil
Vorhersageergebnisse
Nach der Validierung verstehen wir die Stärken und Schwächen unseres Modells besser. Wenn wir mit dem aktuellen Stand der Dinge nicht zufrieden sind, können Sie Änderungen an der Pipeline vornehmen und es erneut versuchen. Nach der Optimierung des Modells definieren wir eine einfache EOTask, die EOPatch und das Klassifikatormodell akzeptiert, eine Vorhersage erstellt und auf das Fragment anwendet.
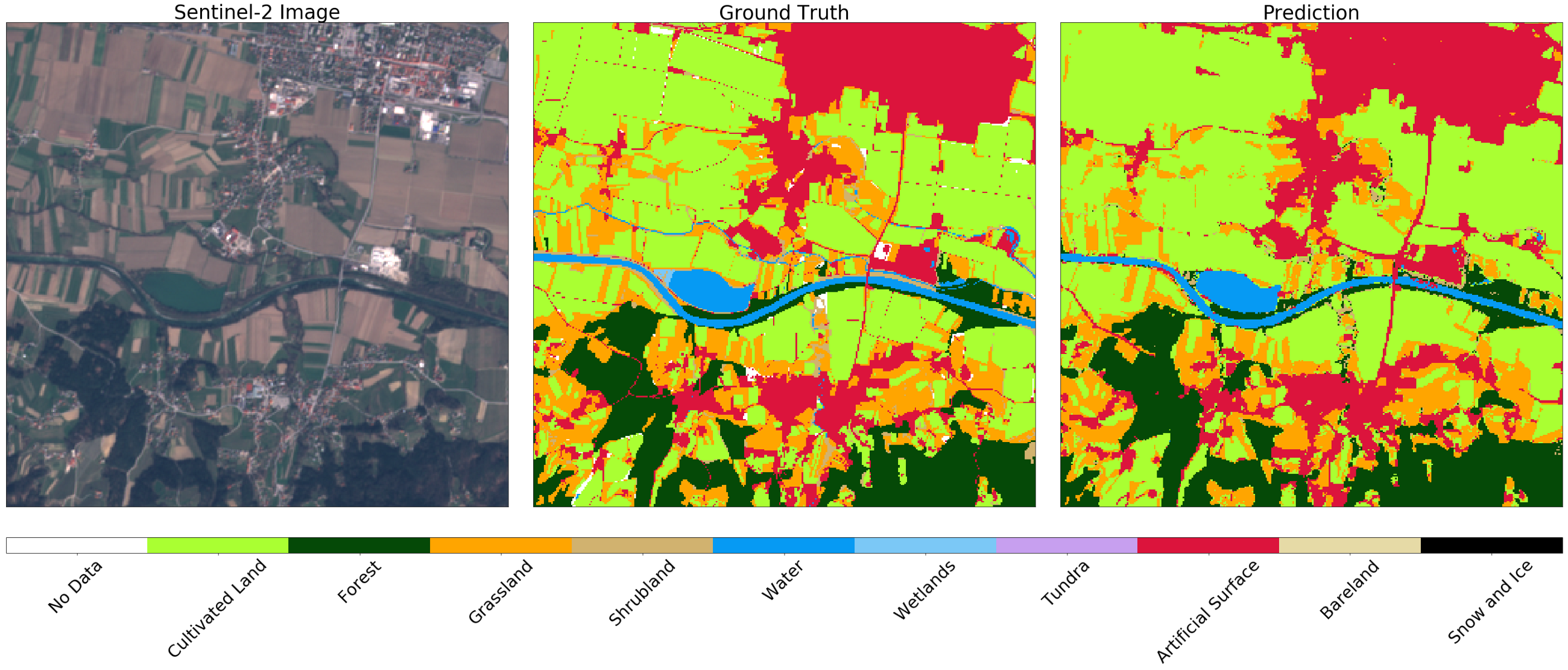
Bild von Sentinel-2 (links), Wahrheit (Mitte) und Vorhersage (rechts) für ein zufälliges Fragment von AOI. Möglicherweise stellen Sie einige Unterschiede in den Bildern fest, die durch die Verwendung einer negativen Pufferung auf der Originalkarte erklärt werden können. Im Allgemeinen ist das Ergebnis für dieses Beispiel zufriedenstellend.
Der weitere Weg ist frei. Der Vorgang muss für alle Fragmente wiederholt werden. Sie können sie sogar im GeoTIFF-Format exportieren und mit gdal_merge.py kleben .
Wir haben geklebtes GeoTIFF in unser GeoPedia-Portal hochgeladen. Die Ergebnisse finden Sie hier im Detail
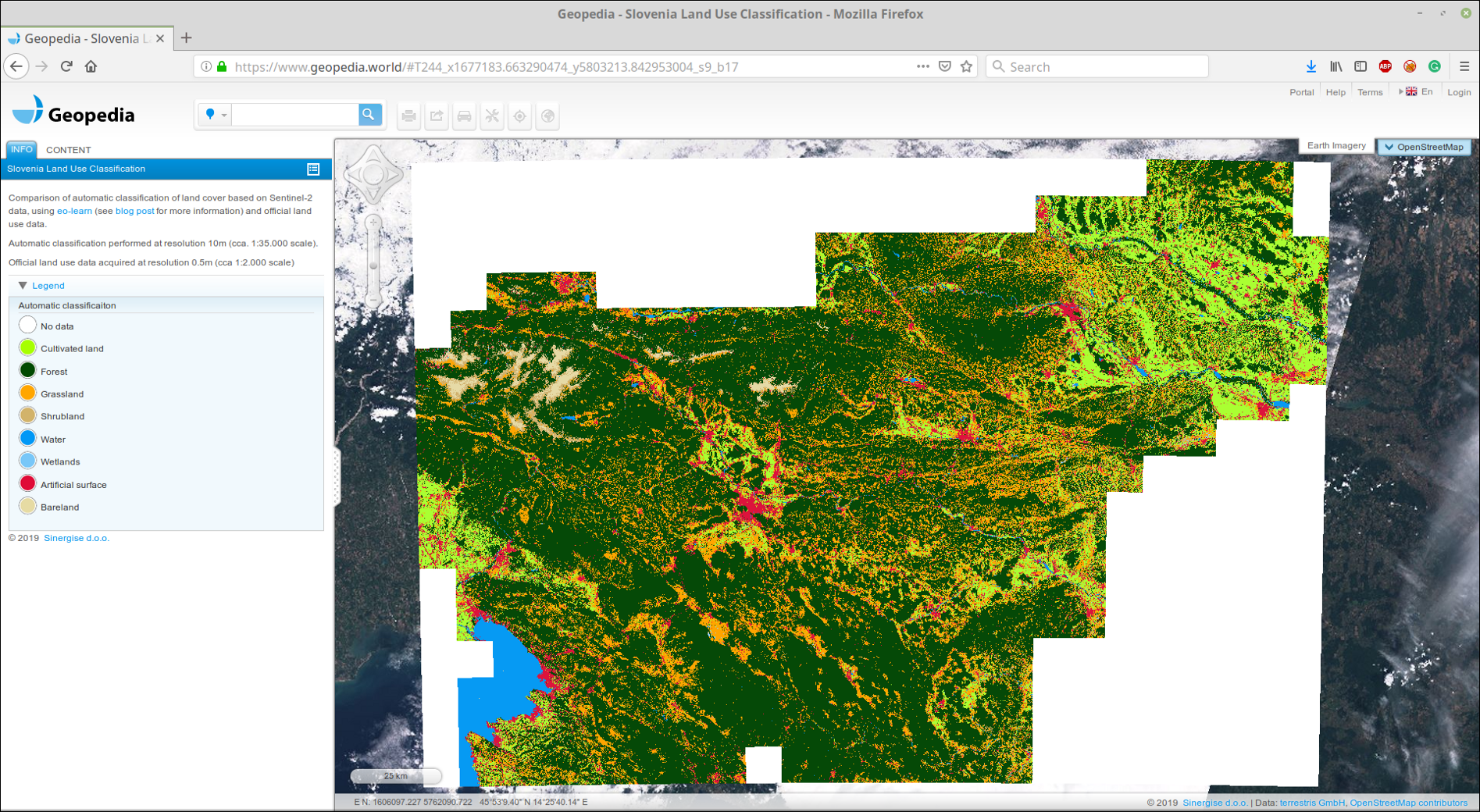
Screenshot der Vorhersage der Landbedeckung Slowenien 2017 unter Verwendung des Ansatzes aus diesem Beitrag. Verfügbar in einem interaktiven Format unter dem obigen Link
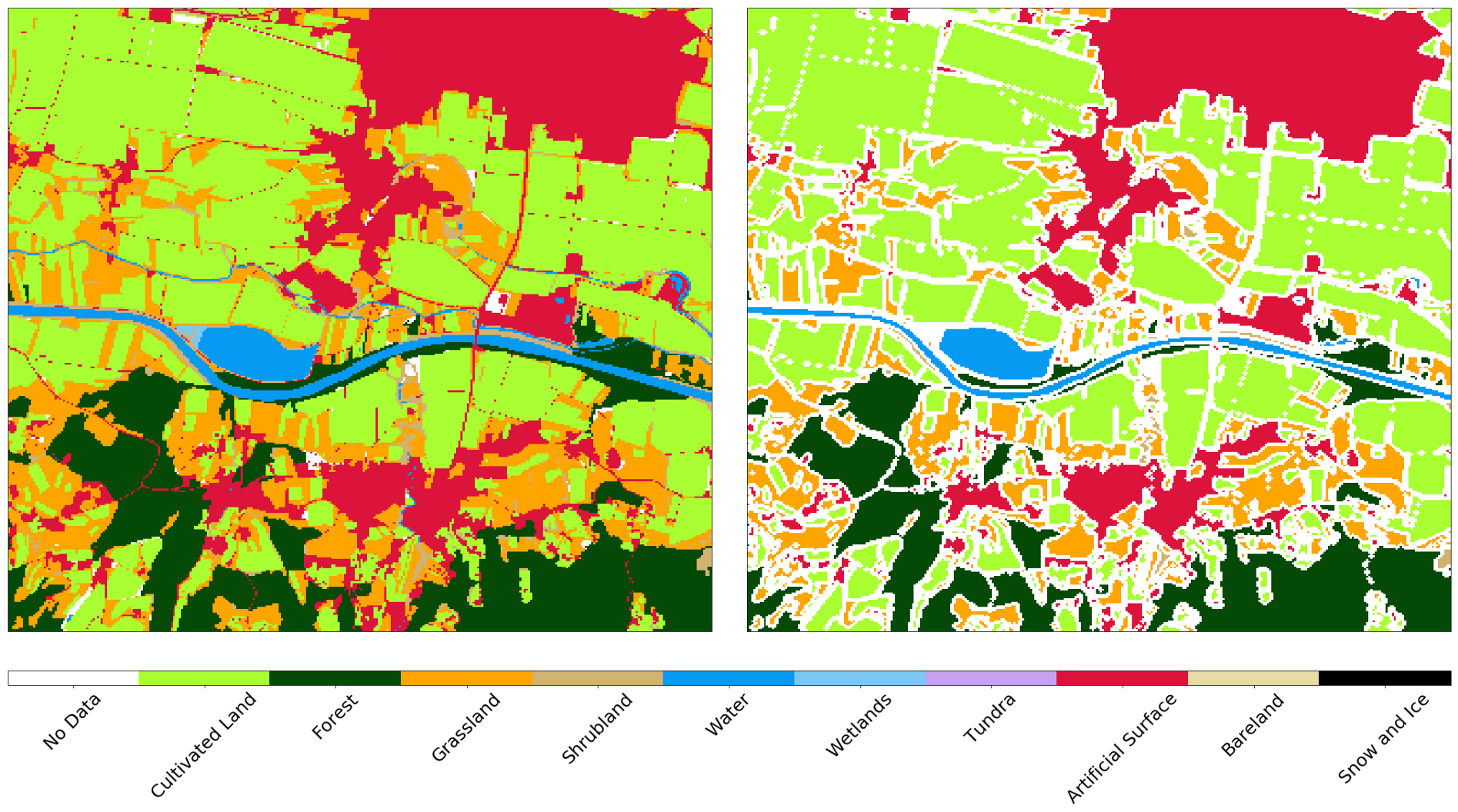
Sie können auch offizielle Daten mit dem Ergebnis des Klassifikators vergleichen. Achten Sie auf den Unterschied zwischen den Konzepten der Landnutzung und der Landbedeckung , der häufig bei maschinellen Lernaufgaben auftritt. Es ist nicht immer einfach, Daten aus offiziellen Registern Klassen in der Natur zuzuordnen. Als Beispiel zeigen wir zwei Flughäfen in Slowenien. Der erste ist Levets in der Nähe der Stadt Celje . Dieser Flughafen ist klein, wird hauptsächlich für Privatjets genutzt und ist mit Gras bedeckt. Offiziell ist das Gebiet als künstliche Oberfläche gekennzeichnet, obwohl der Klassifizierer das Gebiet korrekt als Gras identifizieren kann (siehe unten).

Bild von Sentinel-2 (links), wahr (Mitte) und Vorhersage (rechts) für das Gebiet um den kleinen Sportflughafen. Der Klassifikator definiert die Landebahn als Gras, obwohl sie in den vorliegenden Daten als künstliche Oberfläche markiert ist.
Auf dem größten Flughafen Sloweniens, Ljubljana , sind Zonen, die auf der Karte als künstliche Oberfläche markiert sind, Straßen. In diesem Fall unterscheidet der Klassifikator zwischen Strukturen, während Gras und Felder im Nachbargebiet korrekt unterschieden werden.
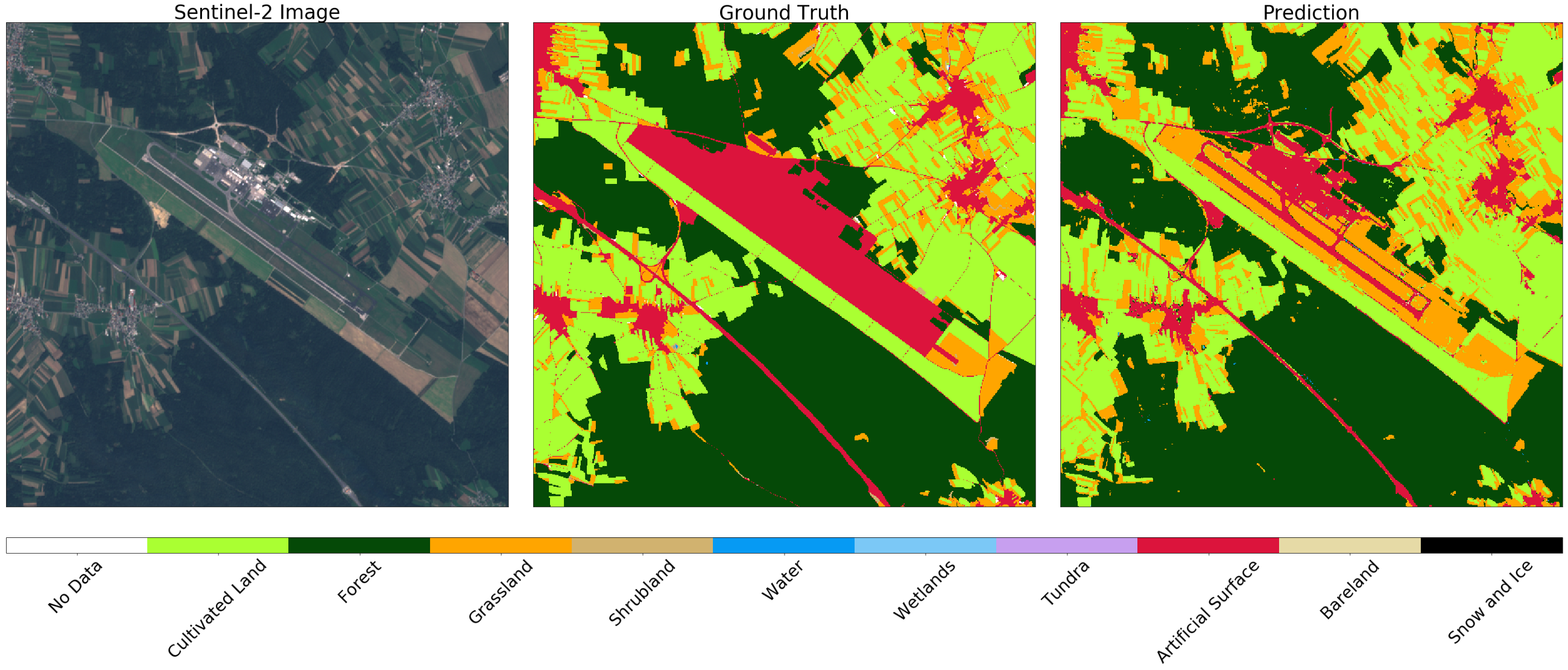
Bild von Sentinel-2 (links), Wahrheit (Mitte) und Vorhersage (rechts) für das Gebiet um Ljubljana. Der Klassifikator bestimmt die Landebahn und die Straßen und unterscheidet Gras und Felder in der Nachbarschaft korrekt
Voila!
Jetzt wissen Sie, wie Sie ein zuverlässiges Modell auf nationaler Ebene erstellen können! Denken Sie daran, dies Ihrem Lebenslauf hinzuzufügen.