
Heutzutage ist immer und überall eine hohe Verfügbarkeit von Diensten erforderlich, nicht nur bei großen, teuren Projekten. Vorübergehend nicht verfügbare Websites mit der Meldung "Entschuldigung, Wartung wird durchgeführt" treten weiterhin auf, verursachen jedoch normalerweise ein herablassendes Lächeln. Fügen Sie dazu das Leben in den Clouds hinzu. Wenn Sie einen zusätzlichen Server starten möchten, benötigen Sie nur einen Aufruf der API, und Sie müssen nicht über den "Eisen" -Betrieb nachdenken. Und es gibt keine Entschuldigung mehr, warum das kritische System nicht zuverlässig mithilfe von Clustertechnologien und Redundanz erstellt wurde.
Wir werden Ihnen sagen, welche Lösungen wir in Betracht gezogen haben, um die Zuverlässigkeit der Datenbanken in unseren Diensten sicherzustellen, und worauf wir gekommen sind. Plus eine Demo mit weitreichenden Schlussfolgerungen.
Vermächtnis in der Hochverfügbarkeitsarchitektur
Dies zeigt sich noch besser im Zusammenhang mit der Entwicklung verschiedener OpenSource-Systeme. Alte Lösungen mussten bei steigender Nachfrage Hochverfügbarkeitstechnologien hinzufügen. Und ihre Qualität war anders. Lösungen der nächsten Generation stellen die hohe Verfügbarkeit in den Mittelpunkt ihrer Architektur. Beispielsweise positioniert MongoDB den Cluster als Hauptanwendungsfall. Der Cluster wird horizontal skaliert, was ein starker Wettbewerbsvorteil dieses DBMS ist.
Zurück zu PostgreSQL. Dies ist eines der ältesten beliebten OpenSource-Projekte, dessen erste Veröffentlichung im 95. Jahr des letzten Jahrhunderts erfolgte. Das Projektteam betrachtete Hochverfügbarkeit lange Zeit nicht als eine Aufgabe, die vom System angegangen werden muss. Daher wurde die Replikationstechnologie zum Erstellen von Datenkopien erst 2006 in Version 8.2 integriert, aber abgelegt (Protokollversand). Im Jahr 2010 wurde die Streaming-Replikation in Version 9.0 veröffentlicht und ist die Grundlage für die Erstellung einer Vielzahl von Clustern. Dies ist in der Tat sehr überraschend für Leute, die PostgreSQL nach Enterprise SQL oder modernem NoSQL kennenlernen - die Standardlösung aus der Community besteht nur aus ein paar Master-Replikaten mit synchroner oder asynchroner Replikation. Gleichzeitig wird der Assistent manuell im Drain umgeschaltet, und es wird auch vorgeschlagen, das Problem des Clientwechsels unabhängig zu lösen.
Wie wir uns entschieden haben, zuverlässiges PostgreSQL zu machen und was wir dafür gewählt haben
PostgreSQL wäre jedoch nicht so beliebt geworden, wenn es nicht eine große Anzahl von Projekten und Tools gegeben hätte, mit denen eine fehlertolerante Lösung erstellt werden kann, die keine ständige Aufmerksamkeit erfordert. Seit dem Start von DBaaS sind in
Mail.ru Cloud Solutions (MCS) einzelne PostgreSQL-Server und Master-Replikatpaare mit asynchroner Replikation verfügbar.
Natürlich wollten wir das Leben aller vereinfachen und die PostgreSQL-Installation verfügbar machen, die als Grundlage für leicht zugängliche Dienste dienen kann, die Sie nachts nicht ständig überwachen und aufwachen müssen, um den Wechsel vorzunehmen. In diesem Segment gibt es sowohl alte bewährte Lösungen als auch eine Generation neuer Dienstprogramme, die die neuesten Entwicklungen nutzen.
Das Problem der Hochverfügbarkeit beruht heute nicht mehr auf Redundanz (selbstverständlich), sondern auf Konsens - einem Algorithmus zur Auswahl eines Führers (Wahl des Führers). Meistens ereignen sich schwere Unfälle nicht aufgrund fehlender Server, sondern aufgrund von Konsensproblemen: Ein neuer Leiter stieg nicht aus, zwei Leiter erschienen in verschiedenen Rechenzentren usw. Ein Beispiel ist ein Absturz im Github MySQL-Cluster - sie haben ein
detailliertes Post-Mortem geschrieben .
Die mathematische Grundlage in dieser Angelegenheit ist sehr ernst. Einerseits gibt es einen
CAP-Satz , der die Möglichkeit der Konstruktion von HA-Lösungen theoretisch einschränkt, andererseits mathematisch erprobte Algorithmen zur Konsensbestimmung wie
Paxos und
Raft . Auf dieser Basis gibt es sehr beliebte DCS (dezentrale Konsenssysteme) - Zookeeper, etcd, Consul. Wenn das Entscheidungssystem mit einem eigenen Algorithmus arbeitet, der unabhängig geschrieben wurde, sollten Sie daher äußerst vorsichtig sein. Nachdem wir eine Vielzahl von Systemen analysiert hatten, entschieden wir uns für Patroni - ein Open-Source-System, das hauptsächlich von Zalando entwickelt wurde.
Als lyrischen Exkurs möchte ich sagen, dass wir auch Multi-Master-Lösungen in Betracht gezogen haben, dh Cluster, die horizontal auf die Aufnahme skaliert werden können. Aus zwei Hauptgründen entschieden sie sich jedoch, keinen solchen Cluster zu erstellen. Erstens weisen solche Lösungen eine hohe Komplexität und dementsprechend mehr Schwachstellen auf. Es wird schwierig sein, in allen Fällen eine stabile Entscheidung zu treffen. Zweitens ist PostgreSQL in diesem Fall nicht mehr rein (nativ), einige Funktionen sind nicht verfügbar, und bei einigen Anwendungen können beim Arbeiten versteckte Fehler auftreten.
Patroni
Wie funktioniert Patroni? Die Entwickler haben das Rad nicht neu erfunden und vorgeschlagen, eine der bewährten DCS-Lösungen als Grundlage zu verwenden. Alle Probleme mit der Synchronisierung von Konfigurationen, der Wahl eines Leiters und dem Quorum werden ihm gegeben. Wir haben etcd dafür gewählt.
Darüber hinaus befasst sich Patroni mit der korrekten Anwendung aller Einstellungen in PostgreSQL und den Replikationseinstellungen sowie mit der Ausführung von Befehlen bei Umschaltung und Failover (dh regulären und nicht standardmäßigen Vermittlungsassistenten). Insbesondere können Sie in der MCS-Cloud einen Cluster aus einem Assistenten, einem synchronen Replikat und einem oder mehreren asynchronen Replikaten erstellen. Das Vorhandensein eines synchronen Replikats gewährleistet die Sicherheit von Daten auf mindestens 2 Servern, und dieses Replikat ist der Hauptkandidat für den Master.
Da etcd auf denselben Servern bereitgestellt wird, wird empfohlen, dass die Anzahl der Server 3 oder 5 beträgt, um den optimalen Quorumwert zu erzielen. Ein solcher Cluster wird zum Lesen horizontal skaliert (ich habe oben über das Skalieren zum Schreiben geschrieben). Es sollte jedoch berücksichtigt werden, dass asynchrone Replikate insbesondere bei hohen Lasten hinterherhinken.
Die Verwendung solcher Read-Standby-Replikate ist für Berichts- oder Analyseaufgaben gerechtfertigt und entlastet den Master-Server.
Wenn Sie einen solchen Cluster selbst erstellen möchten, benötigen Sie:
- Bereiten Sie 3 oder mehr Server vor, konfigurieren Sie die IP-Adressierung und die Firewall-Regeln zwischen ihnen.
- Installieren Sie Pakete für Dienste etcd, Patroni, PostgreSQL;
- etcd cluster konfigurieren;
- Konfigurieren Sie den Patroni-Dienst für die Arbeit mit PostgreSQL.
Das heißt, insgesamt müssen Sie ein Dutzend Konfigurationsdateien korrekt zusammenstellen und dürfen nirgendwo einen Fehler machen. Zu diesem Zweck lohnt es sich auf jeden Fall, ein Konfigurationsmanagement-Tool wie beispielsweise Ansible zu verwenden. Es gibt jedoch noch keinen hochverfügbaren TCP-Balancer. Es ist eine separate Arbeit.
Für diejenigen, die einen vorgefertigten Cluster benötigen, aber nicht mit all dem herumstöbern möchten, haben wir versucht, unser Leben zu vereinfachen und einen vorgefertigten Cluster auf Patroni in unserer Cloud erstellt. Er kann kostenlos getestet werden. Zusätzlich zum Cluster selbst haben wir Folgendes getan:
- TCP-Balancer An verschiedenen Ports zeigt es immer auf das aktuelle Master-, synchrone bzw. asynchrone Replikat.
- API zum Wechseln des aktiven Patroni-Assistenten.
Sie können sowohl über die MCS-Cloud-API als auch über die Webkonsole verbunden werden.
Demo
Um die Funktionen des PostgreSQL-Clusters in der MCS-Cloud zu testen, sehen wir uns an, wie sich eine Live-Anwendung bei Problemen mit dem DBMS verhält.
Das Folgende ist der Code für eine Anwendung, die künstliche Ereignisse protokolliert und dies dem Bildschirm meldet. Im Fehlerfall meldet es dies und setzt seine Arbeit in einem Zyklus fort, bis wir es mit der Kombination Strg + C stoppen.
from __future__ import print_function from datetime import datetime from random import randint from time import sleep import psycopg2 def main(): try: connection = psycopg2.connect(user = "admin", password = "P@ssw0rd", host = "89.208.87.38", port = "5432", database = "myproddb") cursor = connection.cursor() cursor.execute("SELECT version();") record = cursor.fetchone() print("Connection opened to", record[0]) cursor.execute( "INSERT INTO log VALUES ({});".format(randint(1, 10000))) connection.commit() cursor.execute("SELECT COUNT(event_id) from log;") record = cursor.fetchone() print("Logged a value, overall count: {}".format(record[0])) except Exception as error: print ("Error while connecting to PostgreSQL", error) finally: if connection: cursor.close() connection.close() print("Connection closed") if __name__ == '__main__': try: while True: try: print(datetime.now()) main() sleep(3) except Exception as e: print("Caught error:\n", e) sleep(1) except KeyboardInterrupt: print("exit")
Eine Anwendung benötigt PostgreSQL, um zu funktionieren. Erstellen Sie mithilfe der API einen Cluster in der MCS-Cloud. In einem regulären Terminal, in dem die Variable OS_TOKEN ein Token für den Zugriff auf die API enthält (Sie können es mit dem Befehl openstack token issue abrufen), geben wir die folgenden Befehle ein:
Erstellen Sie einen Cluster:
cat <<EF > pgc10.json {"cluster":{"name":"postgres10","allow_remote_access":true,"datastore":{"type":"postgresql","version":"10"},"databases":[{"name":"myproddb"}],"users":[{"databases":[{"name":"myproddb"}],"name":"admin","password":"P@ssw0rd"}],"instances":[{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}},{"key_name":"shared","availability_zone":"DP1","flavorRef":"d659fa16-c7fb-42cf-8a5e-9bcbe80a7538","nics":[{"net-id":"b91eafed-12b1-4a46-b000-3984c7e01599"}],"volume":{"size":50,"type":"DP1"}}]}} EOF curl -s -H "X-Auth-Token: $OS_TOKEN" \ -H 'Accept: application/json' \ -H 'Content-Type: application/json' \ -d @pgc10.json https://infra.mail.ru:8779/v1.0/ce2a41bbd1434013b85bdf0ba07c770f/clusters
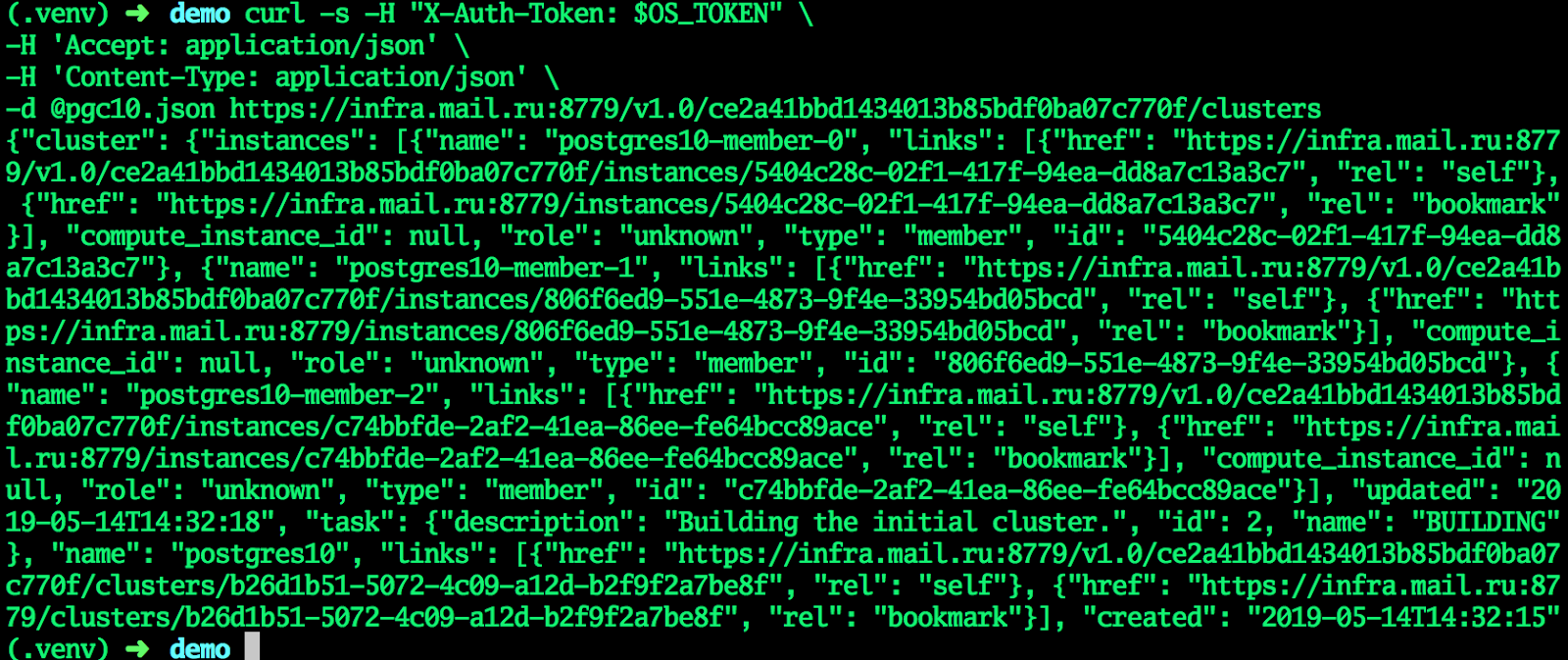
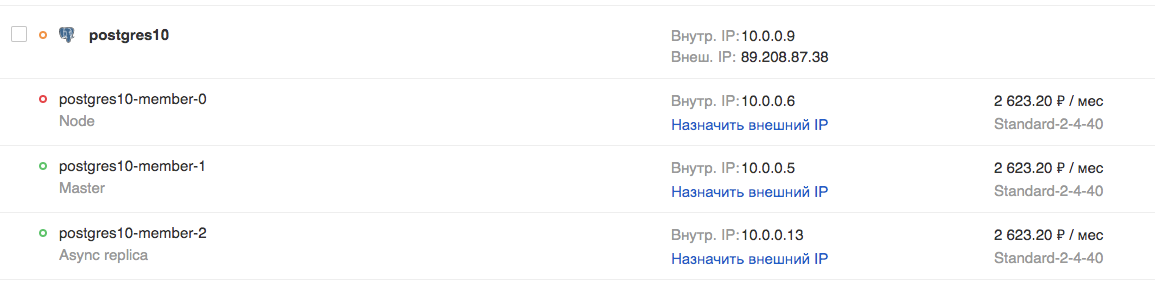
Wenn der Cluster in den Status AKTIV wechselt, erhalten alle Felder die aktuellen Werte - der Cluster ist bereit.
In der GUI:
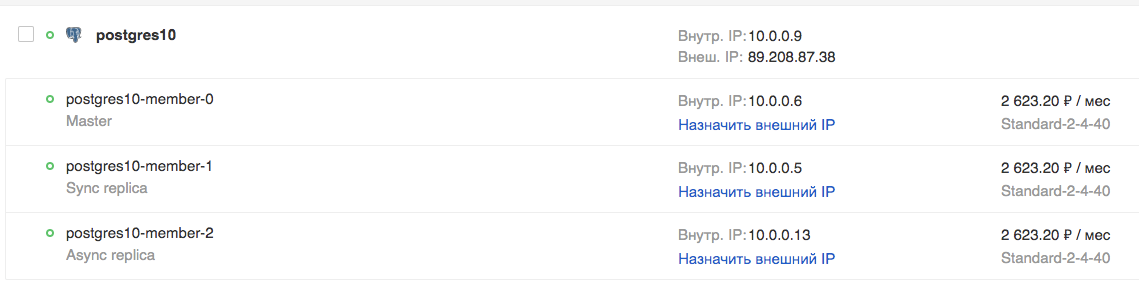
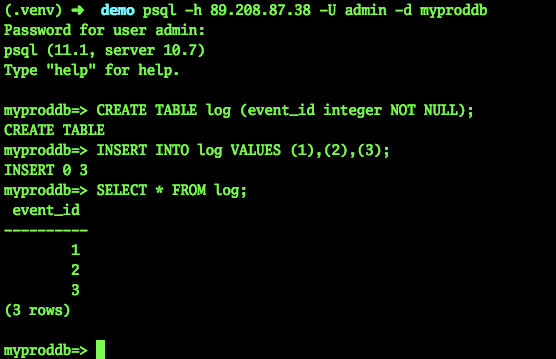
Versuchen wir, eine Verbindung herzustellen und eine Tabelle zu erstellen:
psql -h 89.208.87.38 -U admin -d myproddb Password for user admin: psql (11.1, server 10.7) Type "help" for help. myproddb=> CREATE TABLE log (event_id integer NOT NULL); CREATE TABLE myproddb=> INSERT INTO log VALUES (1),(2),(3); INSERT 0 3 myproddb=> SELECT * FROM log; event_id ---------- 1 2 3 (3 rows) myproddb=>
In der Anwendung geben wir die aktuellen Einstellungen für die Verbindung zu PostgreSQL an. Wir werden die Adresse des TCP-Balancers angeben, wodurch das manuelle Umschalten auf die Adresse des Assistenten entfällt. Führen Sie es aus. Wie Sie sehen können, werden die Ereignisse erfolgreich in der Datenbank protokolliert.

Geplanter Hauptschalter
Jetzt werden wir den Betrieb unserer Anwendung während des geplanten Wechsels des Assistenten testen:
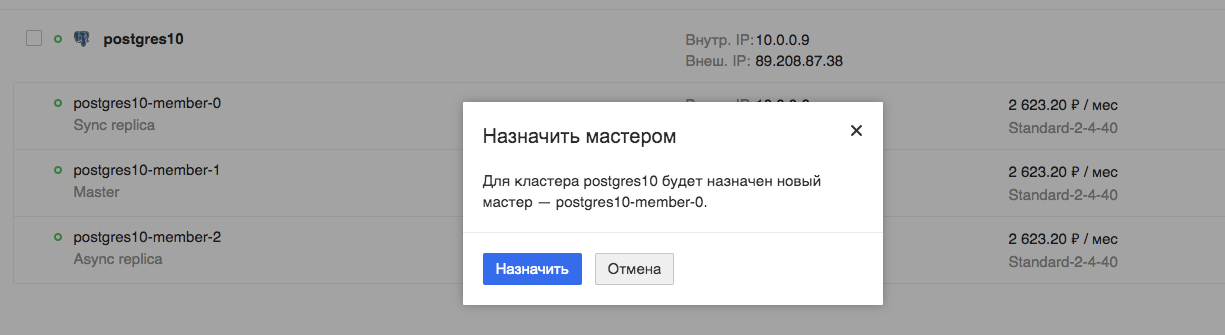
Wir beobachten die Anwendung. Wir sehen, dass die Anwendung wirklich unterbrochen ist, aber es dauert nur wenige Sekunden, in diesem speziellen Fall maximal 9.
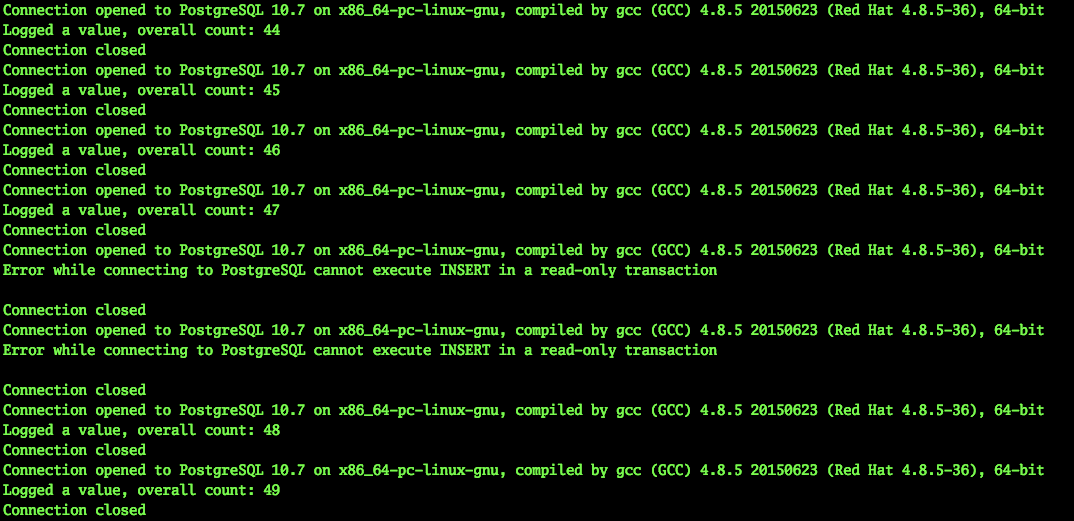
Auto fallen
Versuchen wir nun, den Fall einer virtuellen Maschine, des aktuellen Masters, zu simulieren. Es wäre möglich, die virtuelle Maschine einfach über die Horizon-Schnittstelle auszuschalten, nur wird sie regelmäßig heruntergefahren. Ein solcher Wechsel wird von allen Diensten, einschließlich Patroni, verarbeitet.
Wir brauchen ein unvorhersehbares Herunterfahren. Aus diesem Grund habe ich unsere Administratoren zu Testzwecken gebeten, die virtuelle Maschine - den aktuellen Master - auf ungewöhnliche Weise auszuschalten.
Gleichzeitig funktionierte unsere Anwendung weiter. Natürlich kann ein solcher Notschalter des Masters nicht unbemerkt bleiben.
2019-03-29 10:45:56.071234 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 453 Connection closed 2019-03-29 10:45:59.205463 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 454 Connection closed 2019-03-29 10:46:02.661440 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment ……………………………………………………….. - - 2019-03-29 10:46:30.930445 Error while connecting to PostgreSQL server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. Caught error: local variable 'connection' referenced before assignment 2019-03-29 10:46:31.954399 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 455 Connection closed 2019-03-29 10:46:35.409800 Connection opened to PostgreSQL 10.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit Logged a value, overall count: 456 Connection closed ^Cexit
Wie Sie sehen, konnte die Anwendung ihre Arbeit in weniger als 30 Sekunden fortsetzen. Ja, eine bestimmte Anzahl von Dienstbenutzern hat Zeit, Probleme zu bemerken. Dies ist jedoch ein schwerwiegender Serverfehler, der nicht so häufig auftritt. Gleichzeitig hätte es die Person (Administrator) kaum geschafft, so schnell zu reagieren, wenn sie nicht mit einem Umschaltskript in der Konsole gesessen hätte.
Fazit
Es scheint mir, dass ein solcher Cluster einen enormen Vorteil für Administratoren bietet. Tatsächlich sind schwerwiegende Ausfälle und Ausfälle der Datenbankserver für die Anwendung und dementsprechend für den Benutzer nicht erkennbar. Sie müssen nicht schnell etwas reparieren und zu temporären Konfigurationen, Servern usw. wechseln. Wenn Sie diese Lösung in Form eines vorgefertigten Dienstes in der Cloud verwenden, müssen Sie keine Zeit mit der Vorbereitung verschwenden. Es wird möglich sein, etwas interessanteres zu tun.