
Wenn Sie eine virtuelle Infrastruktur verwalten, die auf VMware vSphere (oder einem anderen Technologie-Stack) basiert, hören Sie wahrscheinlich häufig Beschwerden von Benutzern: "Die virtuelle Maschine ist langsam!". In dieser Artikelserie werde ich Leistungsmetriken analysieren und erklären, was und warum es "langsamer" wird und wie sichergestellt werden kann, dass es nicht "langsamer" wird.
Ich werde die folgenden Leistungsaspekte von virtuellen Maschinen berücksichtigen:
Ich werde mit der CPU beginnen.
Für die Leistungsanalyse benötigen wir:
- vCenter-Leistungsindikatoren sind Leistungsindikatoren, deren Diagramme über den vSphere-Client angezeigt werden können. Informationen zu diesen Leistungsindikatoren sind in jeder Client-Version verfügbar ("dicker" Client in C #, Web-Client in Flex und Web-Client in HTML5). In diesen Artikeln werden wir Screenshots vom C # -Client verwenden, nur weil sie in Miniatur besser aussehen :)
- ESXTOP ist ein Dienstprogramm, das über die ESXi-Befehlszeile ausgeführt wird. Mit seiner Hilfe können Sie die Werte von Leistungsindikatoren in Echtzeit abrufen oder diese Werte für einen bestimmten Zeitraum zur weiteren Analyse in eine CSV-Datei hochladen. Als Nächstes werde ich Ihnen mehr über dieses Tool erzählen und einige nützliche Links zu Dokumentationen und verwandten Artikeln bereitstellen.
Ein bisschen Theorie
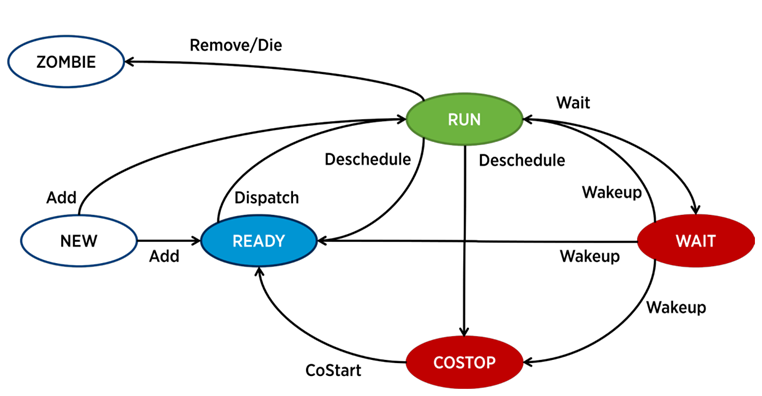
In ESXi ist ein separater Prozess für den Betrieb jeder vCPU (Virtual Machine Core) verantwortlich - der Welt in der VMware-Terminologie. Es gibt auch Serviceprozesse, die jedoch aus Sicht der VM-Leistungsanalyse weniger interessant sind.
Ein Prozess in ESXi kann sich in einem von vier Zuständen befinden:
- Ausführen - Der Prozess leistet nützliche Arbeit.
- Warten - Der Prozess erledigt keine Arbeit (Leerlauf) oder wartet auf Eingabe / Ausgabe.
- Costop ist eine Bedingung, die in virtuellen Multi-Core-Maschinen auftritt. Dies tritt auf, wenn der Hypervisor-CPU-Scheduler (ESXi CPU Scheduler) nicht alle aktiven Kerne der virtuellen Maschine so planen kann, dass sie gleichzeitig auf den physischen Serverkernen ausgeführt werden. In der physischen Welt arbeiten alle Prozessorkerne parallel, das Gastbetriebssystem in der VM erwartet ein ähnliches Verhalten, sodass der Hypervisor die VM-Kerne verlangsamen muss, die den Beat schneller beenden können. In modernen Versionen von ESXi verwendet der CPU-Scheduler einen Mechanismus, der als entspanntes Co-Scheduling bezeichnet wird: Der Hypervisor berücksichtigt die Lücke zwischen dem schnellsten und dem langsamsten Kern der virtuellen Maschine (Skew). Wenn die Lücke einen bestimmten Schwellenwert überschreitet, wechselt der schnelle Core in den Costop-Zustand Wenn VM-Kerne in diesem Zustand viel Zeit verbringen, kann dies zu Leistungsproblemen führen.
- Bereit - Der Prozess wird in diesen Zustand versetzt, wenn der Hypervisor nicht in der Lage ist, Ressourcen für seine Ausführung zuzuweisen. Hohe Bereitschaftswerte können zu VM-Leistungsproblemen führen.
Grundlegende CPU-Leistungsindikatoren einer virtuellen Maschine
CPU-Auslastung,%. Zeigt den Prozentsatz der CPU-Auslastung für einen bestimmten Zeitraum an.
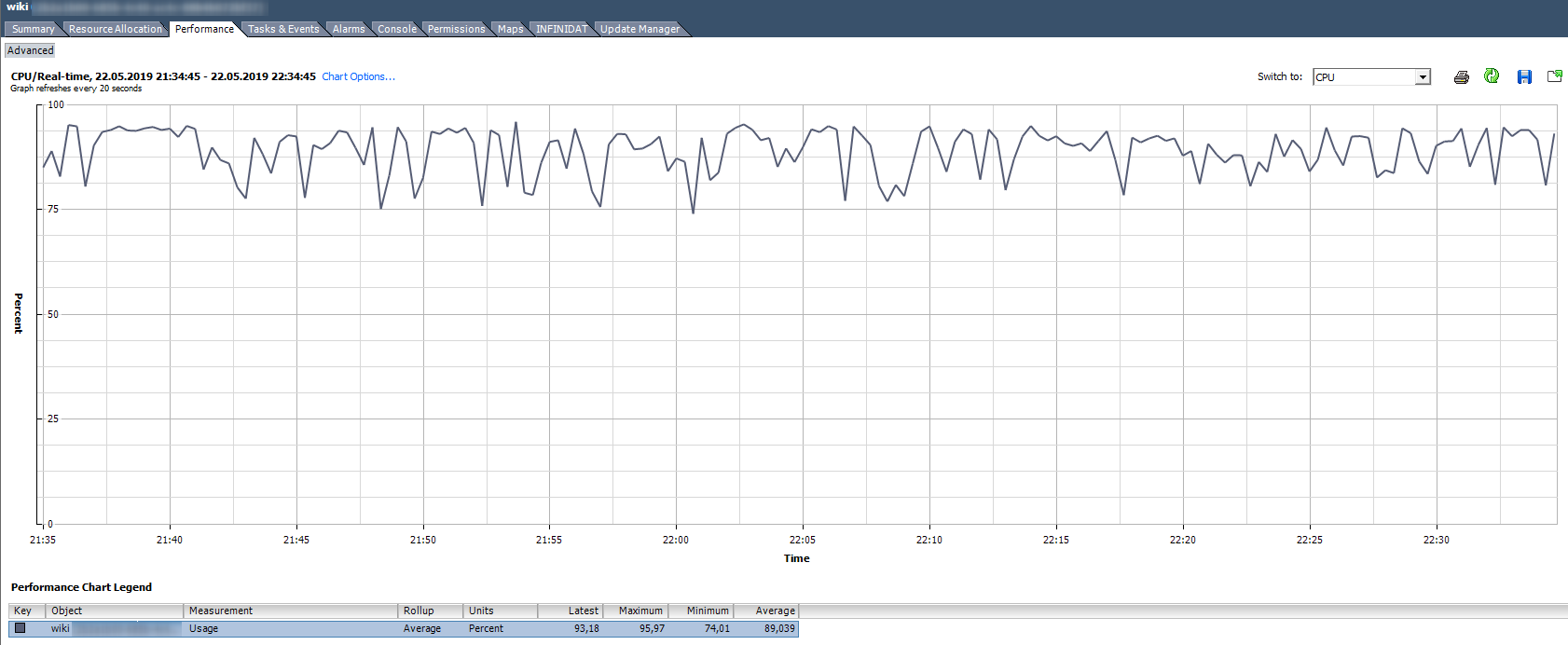 Wie zu analysieren?
Wie zu analysieren? Wenn die VM die CPU zu 90% stabil nutzt oder Spitzen von bis zu 100% auftreten, treten Probleme auf. Probleme können nicht nur im „langsamen“ Betrieb der Anwendung innerhalb der VM zum Ausdruck kommen, sondern auch in der Unzugänglichkeit der VM über das Netzwerk. Wenn das Überwachungssystem anzeigt, dass die VM regelmäßig abfällt, beachten Sie die Spitzen im Diagramm zur CPU-Auslastung.
Es gibt einen Standardalarm, der die CPU-Auslastung der virtuellen Maschine anzeigt:
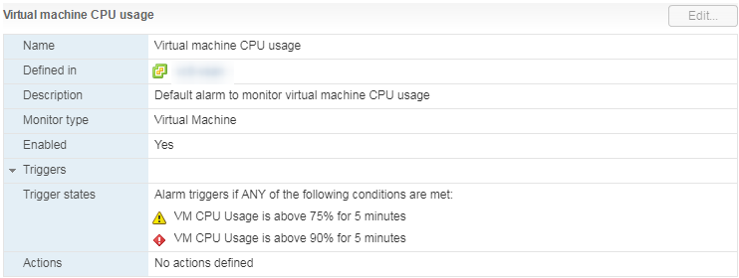 Was zu tun ist?
Was zu tun ist? Wenn die CPU-Auslastung die VM ständig überfordert, können Sie die Anzahl der vCPUs erhöhen (dies hilft leider nicht immer) oder die VMs auf einen Server mit effizienteren Prozessoren übertragen.
CPU-Auslastung in MHz
In vCenter-Verwendungsdiagrammen in% können Sie nur die gesamte virtuelle Maschine sehen. Es gibt keine Diagramme für einzelne Kerne (Esxtop hat Werte in% für Kerne). Für jeden Kern wird die Verwendung in MHz angezeigt.
Wie zu analysieren? Es kommt vor, dass die Anwendung nicht für die Mehrkernarchitektur optimiert ist: Sie verwendet zu 100% nur einen Kern, und der Rest ist ohne Last im Leerlauf. Mit den Standardeinstellungen für die Sicherung startet MS SQL den Prozess beispielsweise nur auf einem Kern. Infolgedessen wird die Sicherung nicht aufgrund der langsamen Festplattengeschwindigkeit (über die sich der Benutzer ursprünglich beschwert hat) verlangsamt, sondern weil der Prozessor nicht damit umgehen kann. Das Problem wurde durch Ändern der Parameter gelöst: Die Sicherung wurde in mehreren Dateien (bzw. in mehreren Prozessen) parallel ausgeführt.
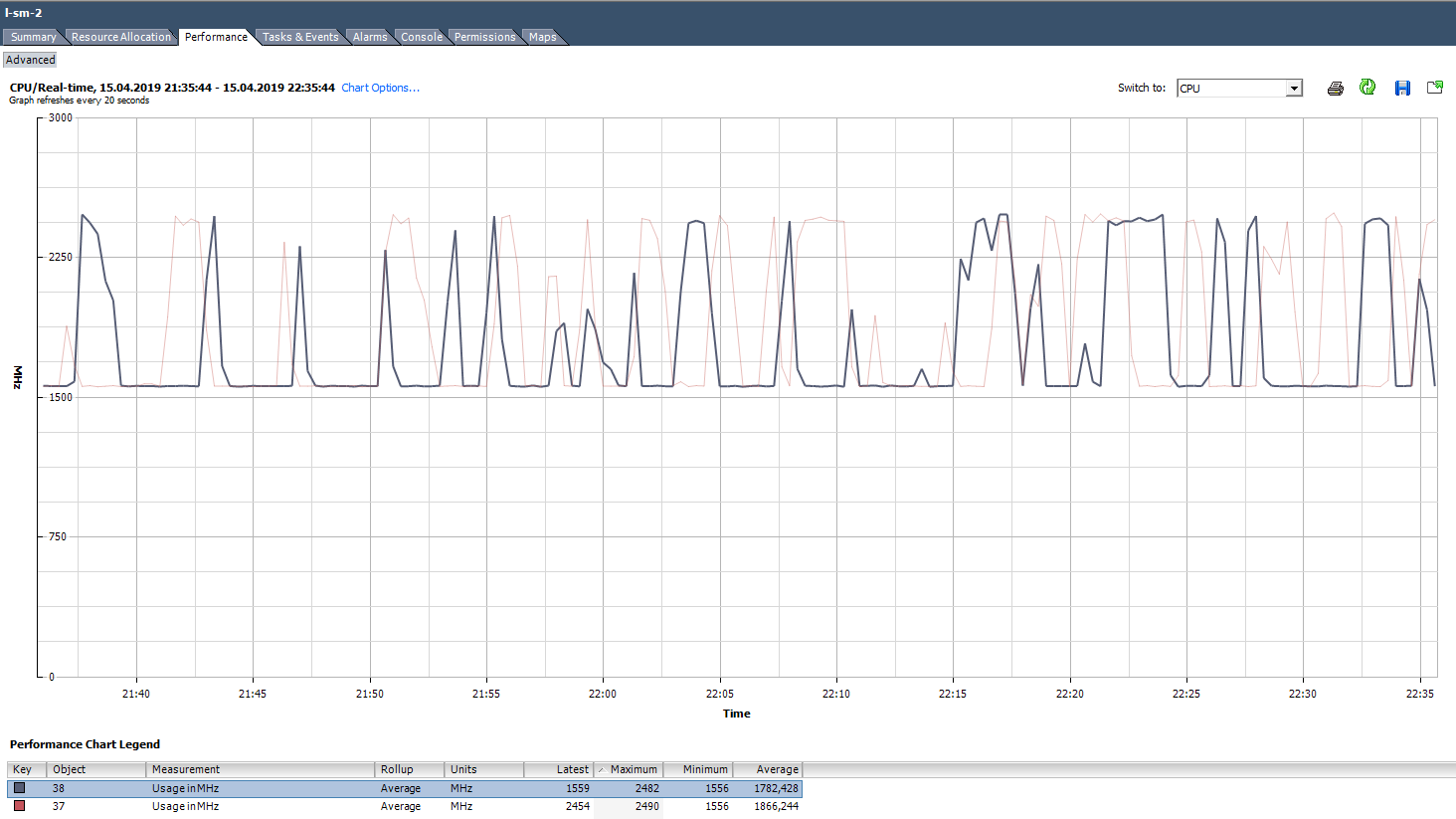 Ein Beispiel für eine ungleichmäßige Ladung von Kernen.
Ein Beispiel für eine ungleichmäßige Ladung von Kernen.Es gibt auch eine Situation (wie in der obigen Grafik), in der die Kerne ungleichmäßig belastet sind und einige von ihnen Spitzen von 100% aufweisen. Wie beim Laden nur eines Kerns funktioniert der Alarm bei der CPU-Auslastung nicht (auf der gesamten VM), es treten jedoch Leistungsprobleme auf.
Was zu tun ist? Wenn die Software in der virtuellen Maschine die Kernel ungleichmäßig lädt (verwendet nur einen Kern oder einen Teil der Kernel), macht es keinen Sinn, ihre Anzahl zu erhöhen. In diesem Fall ist es besser, die VM auf einen Server mit effizienteren Prozessoren zu verschieben.
Sie können auch versuchen, die Energieeinstellungen im Server-BIOS zu überprüfen. Viele Administratoren aktivieren den Hochleistungsmodus im BIOS und damit die Energiespartechnologien für C- und P-Zustände. Moderne Intel-Prozessoren verwenden die Turbo-Boost-Technologie, die die Frequenz einzelner Prozessorkerne aufgrund anderer Kerne erhöht. Es funktioniert jedoch nur mit den enthaltenen energiesparenden Technologien. Wenn wir sie ausschalten, kann der Prozessor den Stromverbrauch von nicht geladenen Kerneln nicht reduzieren.
VMware empfiehlt, keine Energiespartechnologien auf Servern auszuschalten, sondern Modi zu wählen, die das Energiemanagement für den Hypervisor maximieren. Gleichzeitig müssen Sie in den Energieeinstellungen des Hypervisors Hochleistung auswählen.
Wenn Ihre Infrastruktur separate VMs (oder VM-Kerne) enthält, die eine erhöhte CPU-Frequenz erfordern, kann die korrekte Konfiguration des Stromverbrauchs deren Leistung erheblich verbessern.
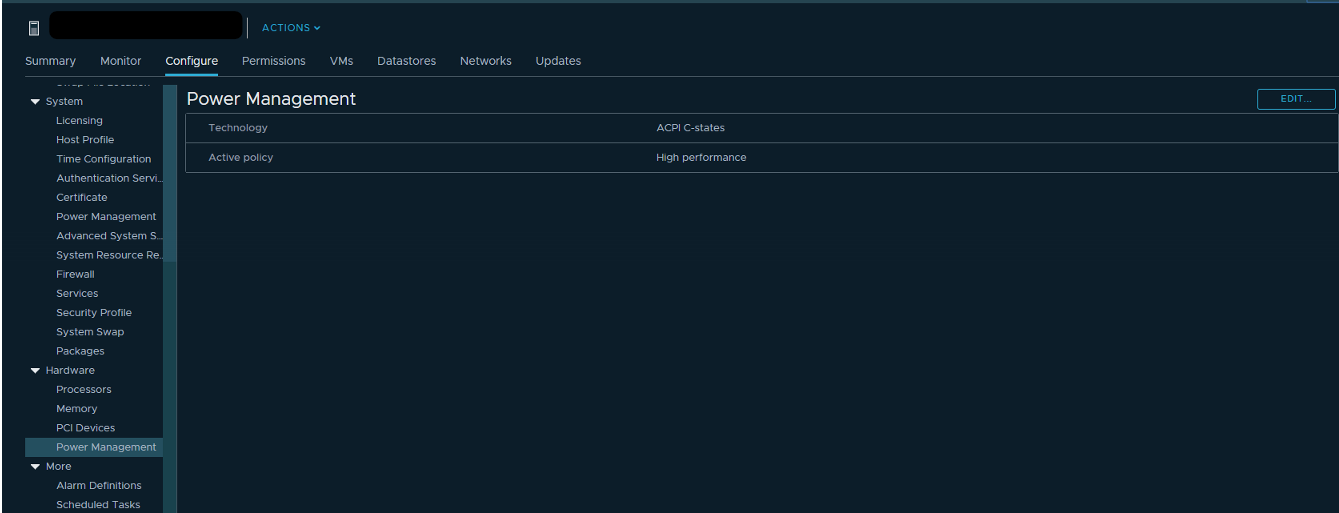
CPU bereit (Bereitschaft)
Wenn sich der VM-Kern (vCPU) im Bereitschaftszustand befindet, leistet er keine nützliche Arbeit. Diese Bedingung tritt auf, wenn der Hypervisor keinen freien physischen Kern findet, dem der vCPU-Prozess der virtuellen Maschine zugewiesen werden kann.
Wie zu analysieren? Wenn sich die Kerne der virtuellen Maschine mehr als 10% der Zeit im Bereitschaftszustand befinden, werden Sie normalerweise Leistungsprobleme feststellen. Einfach ausgedrückt, mehr als 10% der Zeit wartet eine VM auf die Verfügbarkeit physischer Ressourcen.
In vCenter werden 2 Zähler angezeigt, die der CPU-Bereitschaft zugeordnet sind:
Die Werte beider Zähler können sowohl über die gesamte VM als auch für einzelne Kernel angezeigt werden.
Die Bereitschaft zeigt den Wert sofort in Prozent, jedoch nur in Echtzeit (Daten für die letzte Stunde, Messintervall 20 Sekunden). Dieser Zähler wird am besten nur verwendet, um nach Problemen "bei der Verfolgung" zu suchen.
Bereitschaftszählerwerte können auch in historischer Perspektive betrachtet werden. Dies ist nützlich, um Muster zu erstellen und das Problem genauer zu analysieren. Wenn eine virtuelle Maschine beispielsweise zu einem bestimmten Zeitpunkt Leistungsprobleme aufweist, können Sie die Intervalle des Wertes für die CPU-Bereitschaft mit der Gesamtlast auf dem Server vergleichen, auf dem die VM ausgeführt wird, und Maßnahmen zur Reduzierung der Last ergreifen (wenn DRS dies nicht bewältigen konnte).
Ready wird im Gegensatz zu Readiness nicht in Prozent, sondern in Millisekunden angezeigt. Dies ist ein Zähler vom Typ Summation, dh er zeigt an, wie lange sich der VM-Kern während des Messzeitraums im Bereitschaftszustand befand. Sie können diesen Wert mit einer einfachen Formel in Prozent umrechnen:
(CPU-Ready-Summationswert / (Standard-Aktualisierungsintervall des Diagramms in Sekunden * 1000)) * 100 = CPU-Ready%
Für VMs in der folgenden Grafik lautet der Spitzenwert von Bereit für die gesamte virtuelle Maschine beispielsweise wie folgt:
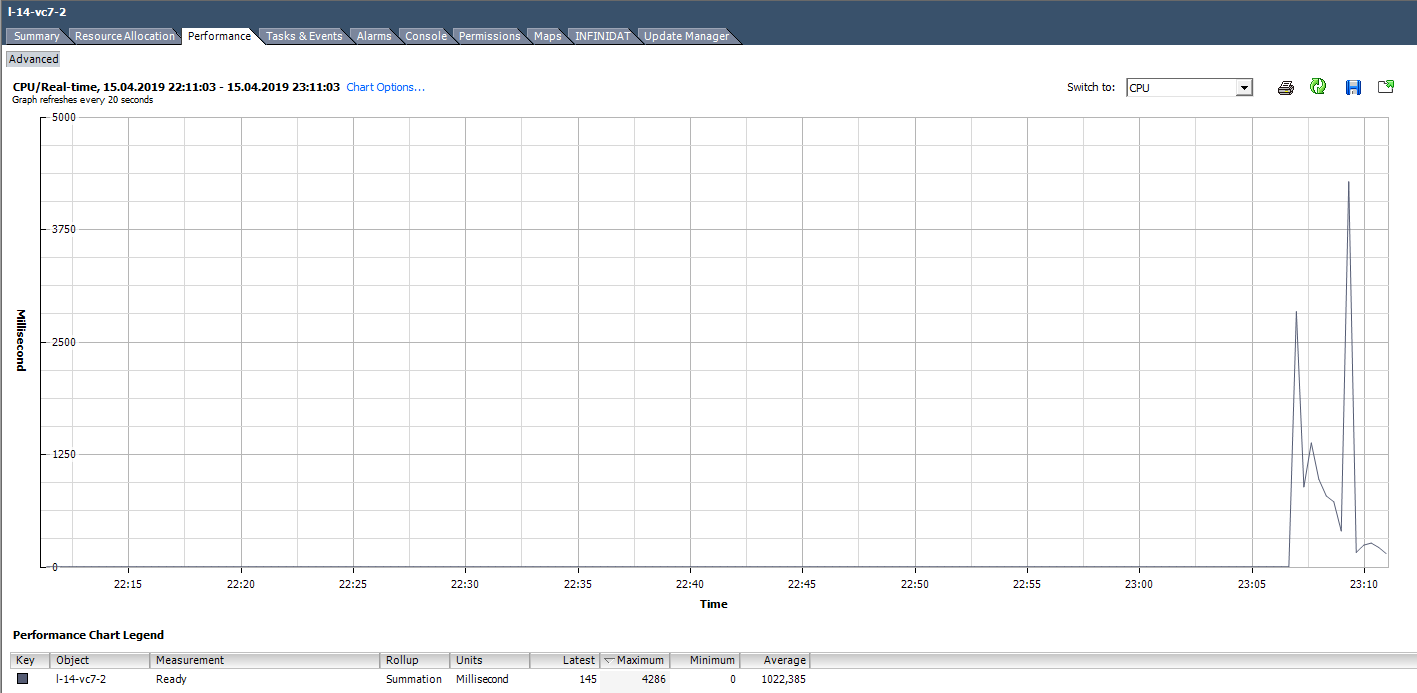
Bei der Berechnung des Bereitschaftswerts als Prozentsatz sollten Sie zwei Punkte beachten:
- Der Wert von Ready für die gesamte VM ist die Summe von Ready für alle Kerne.
- Messintervall. In Echtzeit sind dies 20 Sekunden und in Tages-Charts beispielsweise 300 Sekunden.
Bei aktiver Fehlerbehebung können diese einfachen Punkte leicht übersehen werden und wertvolle Zeit für die Lösung nicht vorhandener Probleme aufgewendet werden.
Wir berechnen Ready basierend auf den Daten aus der folgenden Grafik. (324474 / (20 * 1000)) * 100 = 1622% für die gesamte VM. Wenn Sie sich die Kerne ansehen, wird es nicht so beängstigend: 1622/64 = 25% pro Kern. In diesem Fall ist das Erkennen eines Tricks recht einfach: Der Ready-Wert ist unrealistisch. Wenn es sich jedoch um 10–20% für die gesamte VM mit mehreren Kernen handelt, kann der Wert für jeden Kern im normalen Bereich liegen.
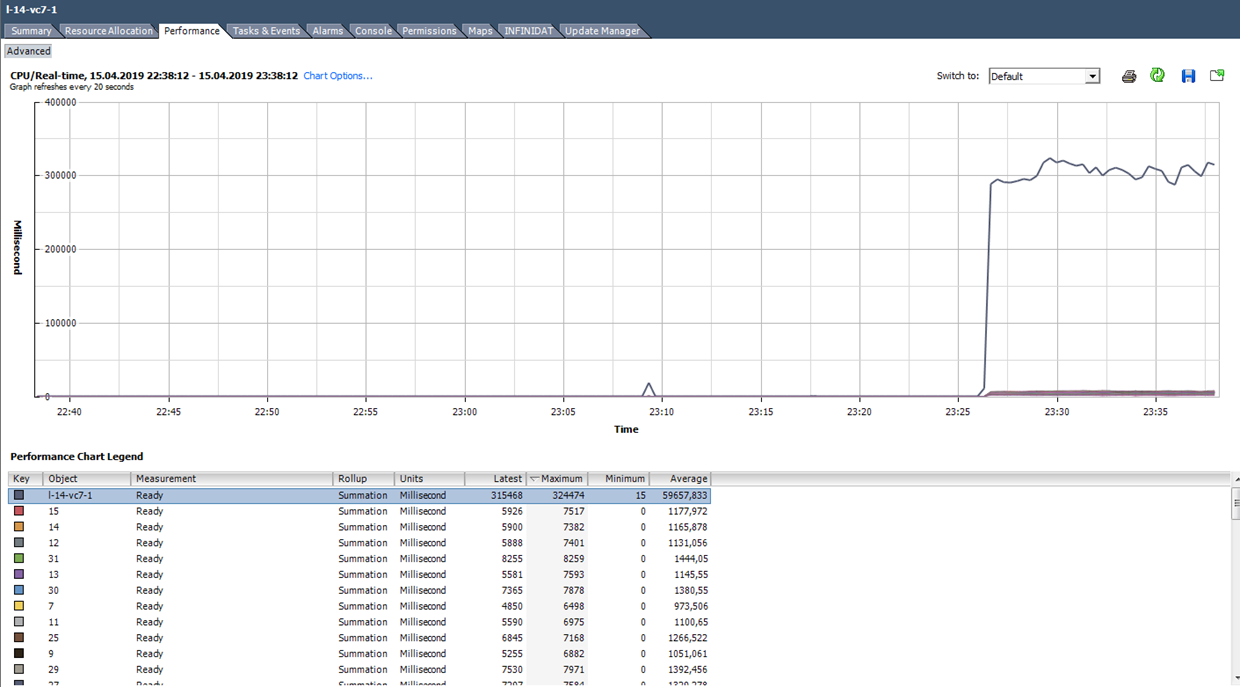 Was zu tun ist?
Was zu tun ist? Ein hoher Wert für Bereit zeigt an, dass der Server nicht über genügend Prozessorressourcen für den normalen Betrieb virtueller Maschinen verfügt. In dieser Situation bleibt nur die Überbelegung des Prozessors (vCPU: pCPU) zu reduzieren. Dies kann natürlich erreicht werden, indem die Parameter vorhandener VMs reduziert oder ein Teil der VM auf andere Server migriert wird.
Co-Stop
Wie zu analysieren? Dieser Zähler hat auch den Summationstyp und wird in Prozentsätze wie Bereit übersetzt:
(CPU-Co-Stop-Summierungswert / (Standard-Aktualisierungsintervall des Diagramms in Sekunden * 1000)) * 100 = CPU-Co-Stop%
Hier müssen Sie auch auf die Anzahl der Kerne pro VM und das Messintervall achten.
Im Costop-Status leistet der Kernel keine nützliche Arbeit. Bei korrekter Auswahl der VM-Größe und der normalen Auslastung des Servers sollte der Co-Stop-Zähler nahe Null liegen.
 In diesem Fall ist die Last eindeutig abnormal :)Was zu tun ist?
In diesem Fall ist die Last eindeutig abnormal :)Was zu tun ist? Wenn mehrere VMs mit einer großen Anzahl von Kernen auf demselben Hypervisor ausgeführt werden und die CPU überbelegt ist, kann der Co-Stop-Zähler wachsen, was zu Problemen mit der Leistung dieser VMs führt.
Außerdem erhöht sich der Co-Stop, wenn Threads für aktive Kernel einer VM auf demselben physischen Serverkern mit aktiviertem Hyper-Treading verwendet werden. Eine solche Situation kann beispielsweise auftreten, wenn die VM über mehr Kerne verfügt als physisch auf dem Server, auf dem sie arbeitet, oder wenn die Einstellung "PreferHT" für die VM aktiviert ist. Über diese Einstellung können Sie
hier lesen.
Um Probleme mit der VM-Leistung aufgrund eines hohen Co-Stopps zu vermeiden, wählen Sie die VM-Größe gemäß den Empfehlungen des Softwareherstellers, der auf dieser VM ausgeführt wird, und gemäß den Funktionen des physischen Servers, auf dem die VM ausgeführt wird.
Fügen Sie keine Kernel in Reserve hinzu. Dies kann nicht nur zu Leistungsproblemen der VM selbst, sondern auch der Servernachbarn führen.
Andere nützliche CPU-Metriken
Ausführen - Wie viel Zeit (ms) für die vCPU-Messperiode war im RUN-Status, dh tatsächlich geleistete nützliche Arbeit.
Leerlauf - Wie viel Zeit (ms) für den vCPU-Messzeitraum war inaktiv. Hohe Leerlaufwerte sind kein Problem, nur vCPU hatte "nichts zu tun".
Warten - Wie viel Zeit (ms) für die vCPU-Messperiode war im Wartezustand. Da IDLE in diesem Zähler enthalten ist, weisen hohe Wartewerte ebenfalls nicht auf ein Problem hin. Wenn jedoch bei hoher Wartezeit IDLE niedrig ist, hat die VM auf den Abschluss der E / A-Vorgänge gewartet, was wiederum auf ein Problem mit der Leistung der Festplatte oder einiger virtueller VM-Geräte hinweisen kann.
Max. Begrenzt - wie viel Zeit (ms) für die vCPU-Messperiode aufgrund des festgelegten Ressourcenlimits im Bereitschaftszustand war. Wenn die Leistung unerklärlich niedrig ist, ist es hilfreich, den Wert dieses Zählers und das CPU-Limit in den VM-Einstellungen zu überprüfen. VMs können tatsächlich Grenzen haben, die Sie nicht kennen. Dies ist beispielsweise der Fall, wenn die VM von der Vorlage abfällt, für die das CPU-Limit festgelegt wurde.
Swap-Wartezeit - Wie lange hat die vCPU während des Messzeitraums auf den Betrieb mit VMkernel Swap gewartet? Wenn die Werte dieses Zählers über Null liegen, hat die VM definitiv Leistungsprobleme. Wir werden mehr über SWAP im Artikel über RAM-Zähler sprechen.
ESXTOP
Wenn Leistungsindikatoren in vCenter für die Analyse historischer Daten geeignet sind, erfolgt die Online-Analyse des Problems am besten in ESXTOP. Hier werden alle Werte in fertiger Form dargestellt (es ist keine Übersetzung erforderlich), und die minimale Messdauer beträgt 2 Sekunden.
Der ESXTOP-Bildschirm auf der CPU wird mit der Taste „c“ aufgerufen und sieht folgendermaßen aus:

Der Einfachheit halber können Sie nur Prozesse der virtuellen Maschine verlassen, indem Sie Umschalt-V drücken.
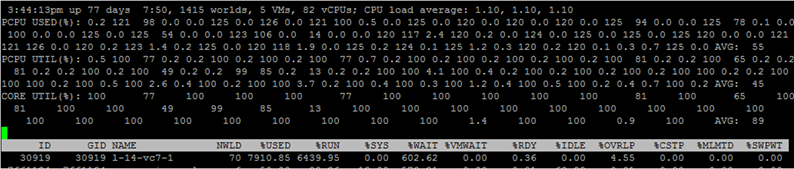
Um die Metriken für einzelne VM-Kerne anzuzeigen, drücken Sie "e" und geben Sie die GID der VM ein, an der Sie interessiert sind (30919 im folgenden Screenshot):

Gehen Sie kurz die Spalten durch, die standardmäßig angezeigt werden. Zusätzliche Spalten können durch Drücken von „f“ hinzugefügt werden.
NWLD (Anzahl der Welten) - Die Anzahl der Prozesse in der Gruppe. Drücken Sie "e", um die Gruppe zu erweitern und die Metriken für jeden Prozess anzuzeigen (z. B. für jeden Kern einer Multi-Core-VM). Wenn eine Gruppe mehr als einen Prozess hat, entsprechen die Werte der Metriken für die Gruppe der Summe der Metriken für die einzelnen Prozesse.
% USED - Wie viele Zyklen verwendet die CPU des Servers einen Prozess oder eine Gruppe von Prozessen.
% RUN - wie viel Zeit während des Messzeitraums der Prozess im RUN-Zustand war, d. H. nützliche Arbeit geleistet. Es unterscheidet sich von% USED darin, dass Hyper-Threading, Frequenzskalierung und Zeitaufwand für Systemaufgaben (% SYS) nicht berücksichtigt werden.
% SYS - Zeitaufwand für Systemaufgaben, z. B. Behandlung von Interrupts, Eingabe / Ausgabe, Netzwerkbetrieb usw. Der Wert kann hoch sein, wenn auf der VM viel Eingabe / Ausgabe vorhanden ist.
% OVRLP - Wie viel Zeit hat der physische Kern, auf dem der VM-Prozess ausgeführt wird, für Aufgaben anderer Prozesse aufgewendet
?Diese Metriken hängen wie folgt zusammen:
% USED =% RUN +% SYS -% OVRLP.
Normalerweise ist die% USED-Metrik informativer.
% WAIT - wie viel Zeit während des Messzeitraums der Prozess im Wartezustand war. Beinhaltet LEERLAUF.
% IDLE - wie lange sich der Prozess während des Messzeitraums im IDLE-Zustand befand.
% SWPWT - Wie lange hat vCPU während des Messzeitraums auf den Betrieb mit VMkernel Swap gewartet?
% VMWAIT - wie lange sich die vCPU während des Messzeitraums im Wartezustand eines Ereignisses (normalerweise E / A) befand. In vCenter gibt es keinen ähnlichen Zähler. Hohe Werte weisen auf Probleme mit der Eingabe / Ausgabe in die VM hin.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
Wenn die VM VMkernel Swap nicht verwendet, ist es ratsam, bei der Analyse von Leistungsproblemen% VMWAIT zu betrachten, da diese Metrik nicht die Zeit berücksichtigt, zu der die VM nichts getan hat (% IDLE).
% RDY - wie lange der Prozess während des Messzeitraums im Bereitschaftszustand war.
% CSTP - wie lange sich der Prozess während des Messzeitraums im Post-Zustand befand.
% MLMTD - Wie viel Zeit während des vCPU-Messzeitraums aufgrund des festgelegten Ressourcenlimits im Bereitschaftszustand war.
% WAIT +% RDY +% CSTP +% RUN = 100% - Der VM-Kern befindet sich immer in einem dieser vier Zustände.
CPU auf dem Hypervisor
Es gibt auch CPU-Leistungsindikatoren für den Hypervisor in vCenter, die jedoch nichts Interessantes darstellen - es ist nur die Summe der Leistungsindikatoren für alle VMs auf dem Server.
Der bequemste Weg, um den Status der CPU auf dem Server anzuzeigen, ist auf der Registerkarte Zusammenfassung:

Sowohl für den Server als auch für die virtuelle Maschine gibt es einen Standardalarm:
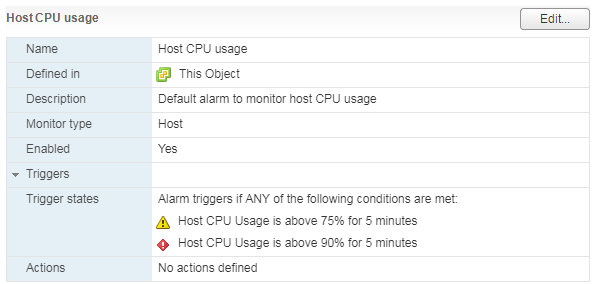
Bei einer hohen Auslastung der Server-CPU treten bei VMs, die darauf ausgeführt werden, Leistungsprobleme auf.
In ESXTOP werden die Daten zur Server-CPU-Auslastung oben auf dem Bildschirm angezeigt. Zusätzlich zur Standard-CPU-Auslastung, die für Hypervisoren nicht aussagekräftig ist, gibt es drei weitere Metriken:
CORE UTIL (%) - Laden des Kerns des physischen Servers. Dieser Zähler zeigt an, wie lange der Kernel die Arbeit während des Messzeitraums ausgeführt hat.
PCPU UTIL (%) - Wenn Hyper-Threading aktiviert ist, gibt es zwei Threads (PCPU) für jeden physischen Kern. Diese Metrik zeigt, wie viel Zeit jeder Thread für die Arbeit benötigt hat.
PCPU USED (%) ist dasselbe wie PCPU UTIL (%), berücksichtigt jedoch die Frequenzskalierung (entweder Verringern der Kernfrequenz zur Energieeinsparung oder Erhöhen der Kernfrequenz aufgrund der Turbo-Boost-Technologie) und Hyper-Threading.
PCPU_USED% = PCPU_UTIL% * effektive Kernfrequenz / nominale Kernfrequenz.
 In diesem Screenshot beträgt der USED-Wert für einige Kerne aufgrund des Betriebs von Turbo Boost mehr als 100%, da die Kernfrequenz höher als die Nennfrequenz ist.
In diesem Screenshot beträgt der USED-Wert für einige Kerne aufgrund des Betriebs von Turbo Boost mehr als 100%, da die Kernfrequenz höher als die Nennfrequenz ist.Ein paar Worte darüber, wie Hyper-Threading berücksichtigt wird. Wenn die Prozesse 100% der Zeit auf beiden Threads des physischen Kerns des Servers ausgeführt werden, während der Kern mit der Nennfrequenz ausgeführt wird, gilt Folgendes:
- CORE UTIL für den Kernel ist 100%,
- PCPU UTIL für beide Threads ist 100%,
- PCED USED für beide Threads beträgt 50%.
Wenn beide Threads während des Messzeitraums nicht 100% der Zeit funktionierten, wird in den Zeiträumen, in denen die Threads parallel arbeiteten, die USED PCPU für Kerne in zwei Hälften geteilt.
ESXTOP verfügt außerdem über einen Bildschirm mit den Stromverbrauchsparametern des CPU-Servers. Hier können Sie sehen, ob der Server energiesparende Technologien verwendet: C-Zustände und P-Zustände. Wird mit der Taste p aufgerufen:

Häufige Probleme mit der CPU-Leistung
Abschließend gehe ich auf typische Gründe für Probleme mit der Leistung der CPU-VM ein und gebe kurze Tipps zu deren Lösung:
Nicht genug Kerntaktrate. Wenn es keine Möglichkeit gibt, VMs auf effizientere Kernel zu übertragen, können Sie versuchen, die Energieeinstellungen zu ändern, damit Turbo Boost effizienter arbeitet.
Falsche Größe der VM (zu viele / wenige Kerne). Wenn Sie nur wenige Kerne einsetzen, wird die VM-CPU stark belastet. Wenn viel, fangen Sie einen hohen Co-Stop.
Große Überbelegung der CPU auf dem Server. Wenn die VM hoch bereit ist, reduzieren Sie die Überbelegung der CPU.
Falsche NUMA-Topologie auf großen VMs. Die von der VM angezeigte NUMA-Topologie (vNUMA) muss mit der NUMA-Servertopologie (pNUMA) übereinstimmen. Informationen zur Diagnose und möglichen Lösungen für dieses Problem finden Sie beispielsweise im Buch
"VMware vSphere 6.5 Host Resources Deep Dive" . Wenn Sie nicht tiefer gehen möchten und keine Lizenzbeschränkungen für das auf der VM installierte Betriebssystem haben, führen Sie viele virtuelle Sockets auf der VM auf einem Kern aus. Du wirst nicht viel verlieren :)
Das ist alles für die CPU. Fragen stellen. Im
nächsten Teil werde ich über RAM sprechen.