Die biometrische Identifizierung einer Person ist eine der ältesten Ideen zur Erkennung von Personen, die sie im Allgemeinen technisch umzusetzen versuchten. Passwörter können gestohlen, ausspioniert, vergessen, Schlüssel gefälscht werden. Aber die einzigartigen Eigenschaften der Person selbst sind viel schwieriger zu fälschen und zu verlieren. Dies können Fingerabdrücke, Stimme, Zeichnen der Gefäße der Netzhaut, Gang und mehr sein.

Natürlich versuchen biometrische Systeme zu täuschen! Darüber werden wir heute sprechen. Wie Angreifer versuchen, Gesichtserkennungssysteme zu umgehen, indem sie sich als eine andere Person ausgeben, und wie dies erkannt werden kann.
Sie können hier eine Videoversion dieser Geschichte ansehen, und diejenigen, die lieber lesen als ansehen, laden Sie ein, fortzufahren
Nach den Vorstellungen von Hollywood-Regisseuren und Science-Fiction-Autoren ist es recht einfach, die biometrische Identifizierung zu täuschen. Es ist nur notwendig, dem System die „erforderlichen Teile“ des realen Benutzers entweder einzeln oder als Geisel zu präsentieren. Oder Sie können die Maske einer anderen Person auf sich selbst setzen, z. B. mit einer physischen Transplantationsmaske oder im Allgemeinen mit falschen genetischen Zeichen
Im wirklichen Leben versuchen Angreifer auch, sich als jemand anderes vorzustellen. Rauben Sie beispielsweise eine Bank aus, indem Sie eine schwarze Männermaske tragen, wie im Bild unten dargestellt.

Die Gesichtserkennung scheint ein vielversprechender Bereich für den Einsatz im Mobilbereich zu sein. Wenn jeder schon lange daran gewöhnt ist, Fingerabdrücke zu verwenden, und sich die Sprachtechnologie allmählich und ziemlich vorhersehbar entwickelt, hat sich die Situation mit der Identifizierung anhand des Gesichts eher ungewöhnlich entwickelt und verdient einen kleinen Exkurs in die Geschichte des Problems.
Wie alles begann oder von der Fiktion zur Realität
Die heutigen Erkennungssysteme weisen eine enorme Genauigkeit auf. Mit dem Aufkommen großer Datenmengen und komplexer Architekturen wurde es möglich, eine Gesichtserkennungsgenauigkeit von bis zu 0,000001 (ein Fehler pro Million!) Zu erreichen. Sie sind jetzt für die Übertragung auf mobile Plattformen geeignet. Der Engpass war ihre Verwundbarkeit.
Um sich in unserer technischen Realität und nicht im Film als eine andere Person auszugeben, werden am häufigsten Masken verwendet. Sie versuchen auch, das Computersystem zu täuschen, indem sie jemand anderem anstelle ihres Gesichts präsentieren. Masken können von völlig anderer Qualität sein, vom Foto einer anderen Person, die vor dem auf dem Drucker gedruckten Gesicht gedruckt wird, bis zu sehr komplexen dreidimensionalen Masken mit Erwärmung. Masken können separat in Form eines Blattes oder Bildschirms präsentiert oder am Kopf getragen werden.
Viel Aufmerksamkeit wurde auf das Thema gelenkt, als erfolgreich versucht wurde, das Face ID-System auf dem iPhone X mit einer ziemlich komplizierten Maske aus Steinpulver mit speziellen Einsätzen um die Augen zu täuschen, die die Wärme eines lebenden Gesichts mithilfe von Infrarotstrahlung imitieren.
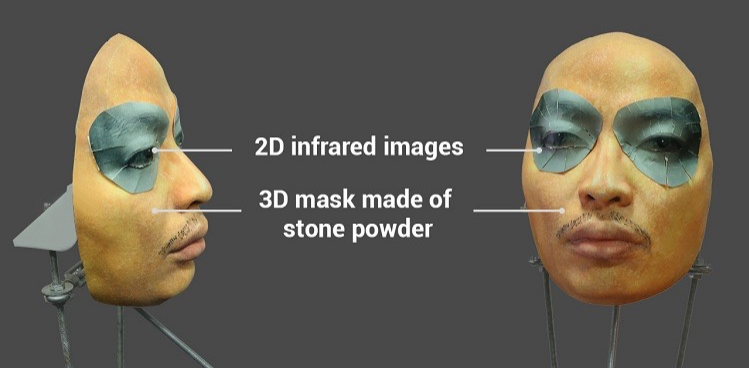
Es wird vermutet, dass mit einer solchen Maske die Gesichtserkennung auf dem iPhone X getäuscht werden konnte. Video und Text finden Sie hier
Das Vorhandensein solcher Sicherheitslücken ist für Banken oder staatliche Systeme sehr gefährlich, um einen Benutzer von Angesicht zu Angesicht zu authentifizieren, wenn das Eindringen eines Angreifers erhebliche Verluste mit sich bringt.
Terminologie
Das Forschungsgebiet des Gesichts-Anti-Spoofing ist recht neu und kann sich noch nicht einmal der vorherrschenden Terminologie rühmen.
Lassen Sie uns zustimmen, einen Versuch zu nennen, das Identifikationssystem zu täuschen, indem wir ihm einen gefälschten biometrischen Parameter (in diesem Fall eine Person) als Spoofing-Angriff präsentieren .
Dementsprechend wird eine Reihe von Schutzmaßnahmen zur Bekämpfung einer solchen Täuschung als Anti-Spoofing bezeichnet . Es kann in Form einer Vielzahl von Technologien und Algorithmen implementiert werden, die in den Förderer eines Identifikationssystems eingebaut sind.
Die ISO bietet eine leicht erweiterte Terminologie mit Begriffen wie Präsentationsangriff - Versuche, das System dazu zu bringen, den Benutzer falsch zu identifizieren oder ihm zu ermöglichen, die Identifizierung durch Demonstration eines Bildes, eines aufgezeichneten Videos usw. zu vermeiden. Normal (Bona Fide) - entspricht dem üblichen Algorithmus des Systems, dh alles, was KEIN Angriff ist. Präsentationsangriffsinstrument bedeutet ein Angriffsmittel, zum Beispiel einen künstlich hergestellten Körperteil. Und schließlich die Erkennung von Präsentationsangriffen - automatisierte Mittel zur Erkennung solcher Angriffe. Die Standards selbst befinden sich jedoch noch in der Entwicklung, sodass es unmöglich ist, über etablierte Konzepte zu sprechen. Die russische Terminologie fehlt fast vollständig.
Um die Qualität der Arbeit zu bestimmen, verwenden Systeme häufig die HTER- Metrik (Half-Total Error Rate - die Hälfte des Gesamtfehlers), die als Summe der Koeffizienten von fälschlicherweise zulässigen Identifikationen (FAR - False Acceptance Rate) und irrtümlich verbotenen Identifikationen (FRR - False Rejection Rate) berechnet wird in zwei Hälften.
HTER = (FAR + FRR) / 2
Es ist erwähnenswert, dass in biometrischen Systemen FAR normalerweise die größte Aufmerksamkeit geschenkt wird, um alles zu tun, um zu verhindern, dass ein Angreifer in das System eindringt. Und sie machen hier gute Fortschritte (erinnern Sie sich an das Millionstel vom Anfang des Artikels?). Die Kehrseite ist die unvermeidliche Zunahme der FRR - die Anzahl der normalen Benutzer, die fälschlicherweise als Eindringlinge eingestuft werden. Wenn dies für Staat, Verteidigung und andere ähnliche Systeme geopfert werden kann, reagieren mobile Technologien, die mit ihrer enormen Größe, einer Vielzahl von Teilnehmergeräten und im Allgemeinen auf Benutzerperspektiven ausgerichteten Geräten arbeiten, sehr empfindlich auf Faktoren, die dazu führen können, dass Benutzer Dienste ablehnen. Wenn Sie die Anzahl der nach der zehnten Verweigerung der Identifizierung in Folge gegen die Wand geschlagenen Telefone verringern möchten, sollten Sie auf FRR achten!
Arten von Angriffen. Cheat-System

Lassen Sie uns endlich genau herausfinden, wie die Angreifer das Erkennungssystem betrügen und wie dies bekämpft werden kann.
Die beliebtesten Mittel zum Betrügen sind Masken. Es gibt nichts Offensichtlicheres, als die Maske einer anderen Person aufzusetzen und Ihr Gesicht einem Identifikationssystem zu präsentieren (oft als Maskenangriff bezeichnet).
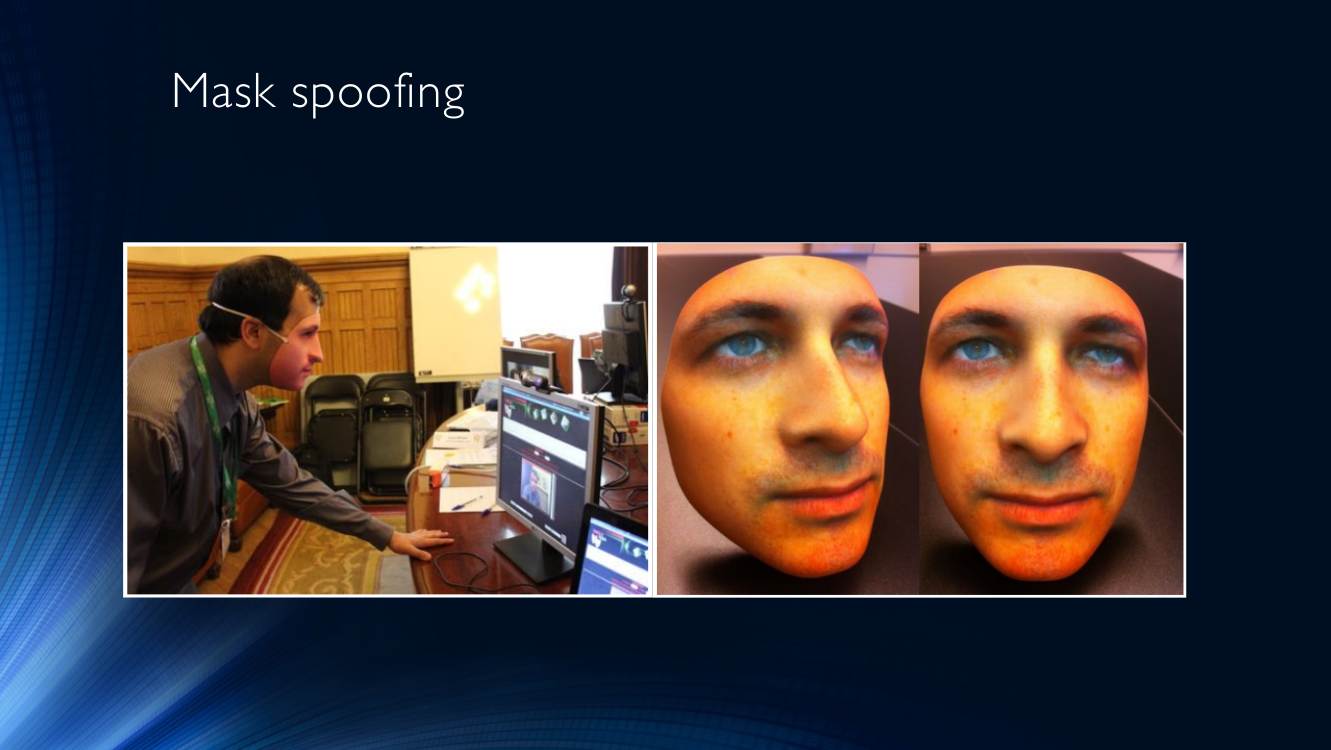
Sie können auch ein Foto von sich selbst oder einer anderen Person auf ein Blatt Papier drucken und zur Kamera bringen (nennen wir diese Art von Angriff Gedruckte Attacke).

Etwas komplizierter ist der Wiederholungsangriff, wenn dem System der Bildschirm eines anderen Geräts angezeigt wird, auf dem ein zuvor aufgenommenes Video mit einer anderen Person abgespielt wird. Die Komplexität der Ausführung wird durch die hohe Effizienz eines solchen Angriffs kompensiert, da Steuerungssysteme häufig Zeichen verwenden, die auf der Analyse von Zeitsequenzen basieren, z. B. Verfolgen von Blinzeln, Mikrobewegungen des Kopfes, Vorhandensein von Gesichtsausdrücken, Atmung usw. All dies kann leicht auf Video reproduziert werden.

Beide Arten von Angriffen weisen eine Reihe charakteristischer Merkmale auf, die es ermöglichen, sie zu erkennen und so einen Tablet-Bildschirm oder ein Blatt Papier von einer realen Person zu unterscheiden.
Wir fassen die charakteristischen Merkmale, mit denen wir diese beiden Arten von Angriffen identifizieren können, in einer Tabelle zusammen:
Angriffserkennungsalgorithmen. Guter alter Klassiker

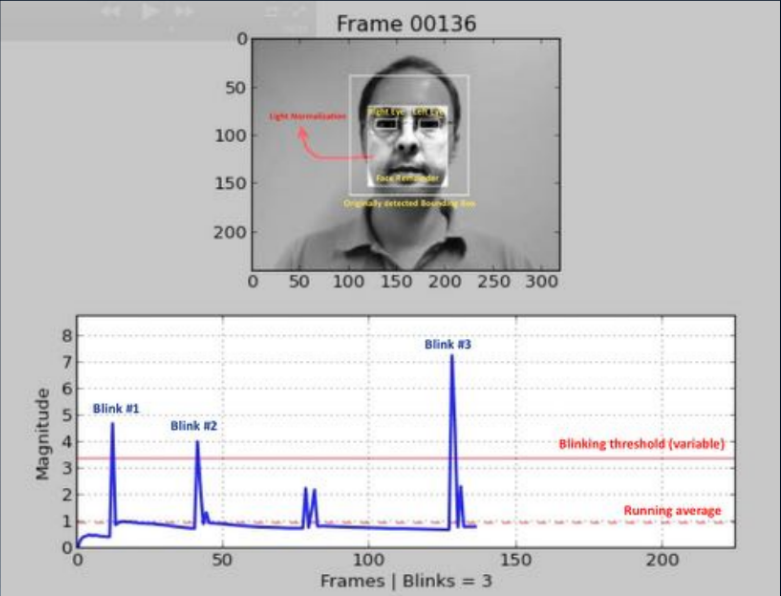
Einer der ältesten Ansätze (2007, 2008) basiert auf der Erkennung menschlicher Blinzel durch Analyse des Bildes mit einer Maske. Der Punkt ist, eine Art binären Klassifikator zu erstellen, mit dem Sie Bilder mit offenen und geschlossenen Augen in einer Folge von Frames auswählen können. Dies kann eine Analyse des Videostreams unter Verwendung der Identifizierung von Gesichtsteilen (Landmark Detection) oder die Verwendung eines einfachen neuronalen Netzwerks sein. Und heute wird diese Methode am häufigsten angewendet; Der Benutzer wird aufgefordert, eine Reihe von Aktionen auszuführen: Kopf drehen, zwinkern, lächeln und mehr. Wenn die Sequenz zufällig ist, ist es für einen Angreifer nicht einfach, sich im Voraus darauf vorzubereiten. Leider ist diese Suche für einen ehrlichen Benutzer auch nicht immer überwindbar, und das Engagement nimmt stark ab.
Sie können auch die Merkmale einer Verschlechterung der Bildqualität beim Drucken oder Abspielen auf dem Bildschirm verwenden. Höchstwahrscheinlich werden sogar einige lokale Muster, die für das Auge schwer zu erkennen sind, im Bild erkannt. Dies kann beispielsweise durch Zählen lokaler Binärmuster (LBP, lokales Binärmuster) für verschiedene Bereiche des Gesichts nach Auswahl aus dem Rahmen ( PDF ) erfolgen. Das beschriebene System kann als Begründer der auf Bildanalyse basierenden Anti-Spoofing-Algorithmen für die gesamte Richtung des Gesichts angesehen werden. Kurz gesagt, bei der Berechnung des LBP werden für jedes Pixel im Bild acht seiner Nachbarn nacheinander aufgenommen und ihre Intensität verglichen. Wenn die Intensität größer als auf dem zentralen Pixel ist, wird eins, wenn weniger, Null zugewiesen. Somit wird für jedes Pixel eine 8-Bit-Sequenz erhalten. Basierend auf den erhaltenen Sequenzen wird ein Histogramm pro Pixel erstellt, das dem Eingang des SVM-Klassifikators zugeführt wird.
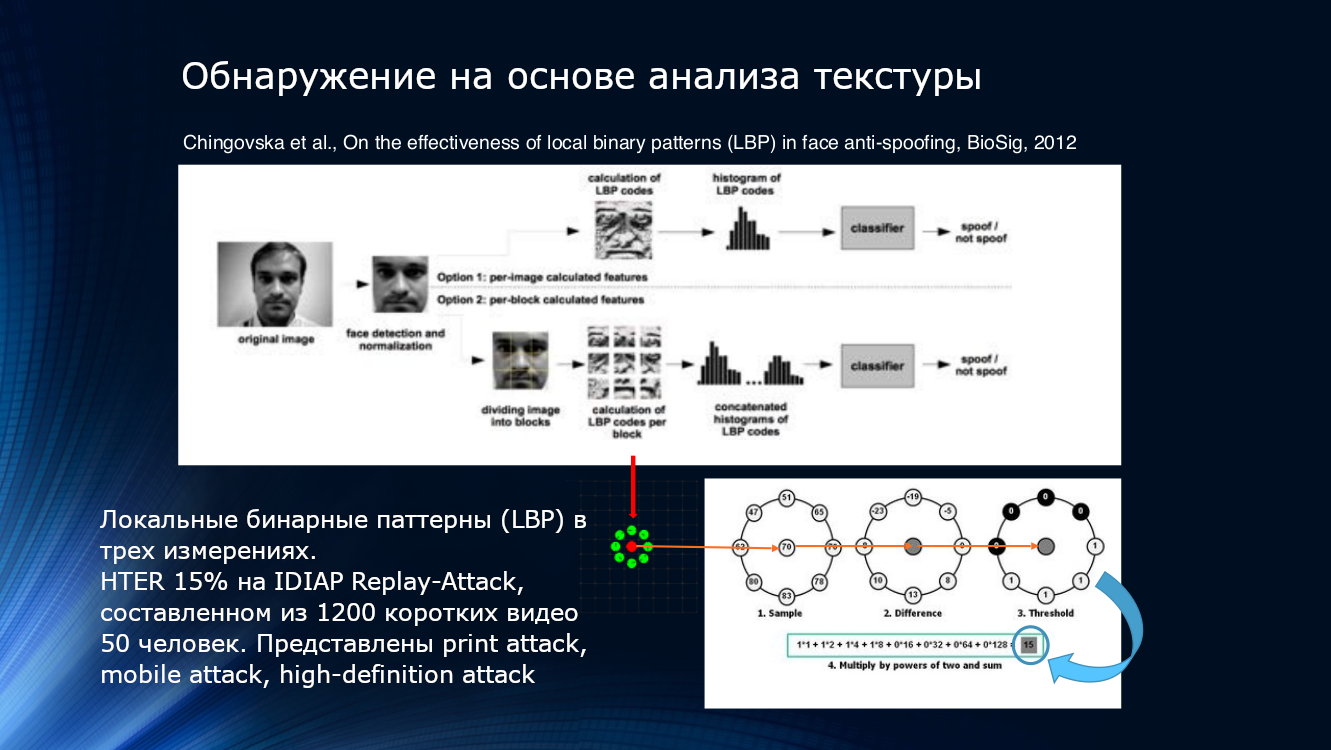
Lokale binäre Muster, Histogramm und SVM. Hier können Sie sich den zeitlosen Klassikern anschließen
Der HTER-Effizienzindikator beträgt „bis zu“ 15% und bedeutet, dass ein erheblicher Teil der Angreifer den Schutz ohne großen Aufwand überwindet, obwohl anerkannt werden sollte, dass viel beseitigt wird. Der Algorithmus wurde am IDIAP Replay-Attack- Datensatz getestet, der aus 1200 kurzen Videos von 50 Befragten und drei Arten von Angriffen besteht - gedruckte Angriffe, mobile Angriffe, hochauflösende Angriffe.
Ideen zur Analyse der Bildtextur wurden fortgesetzt. Im Jahr 2015 entwickelte Bukinafit einen Algorithmus zum alternativen Aufteilen des Bildes in Kanäle zusätzlich zu herkömmlichem RGB, für dessen Ergebnisse erneut lokale Binärmuster berechnet wurden, die wie bei der vorherigen Methode dem Eingang des SVN-Klassifikators zugeführt wurden. Die HTER-Genauigkeit, berechnet anhand der CASIA- und Replay-Attack-Datensätze, war zu diesem Zeitpunkt beeindruckend 3%.
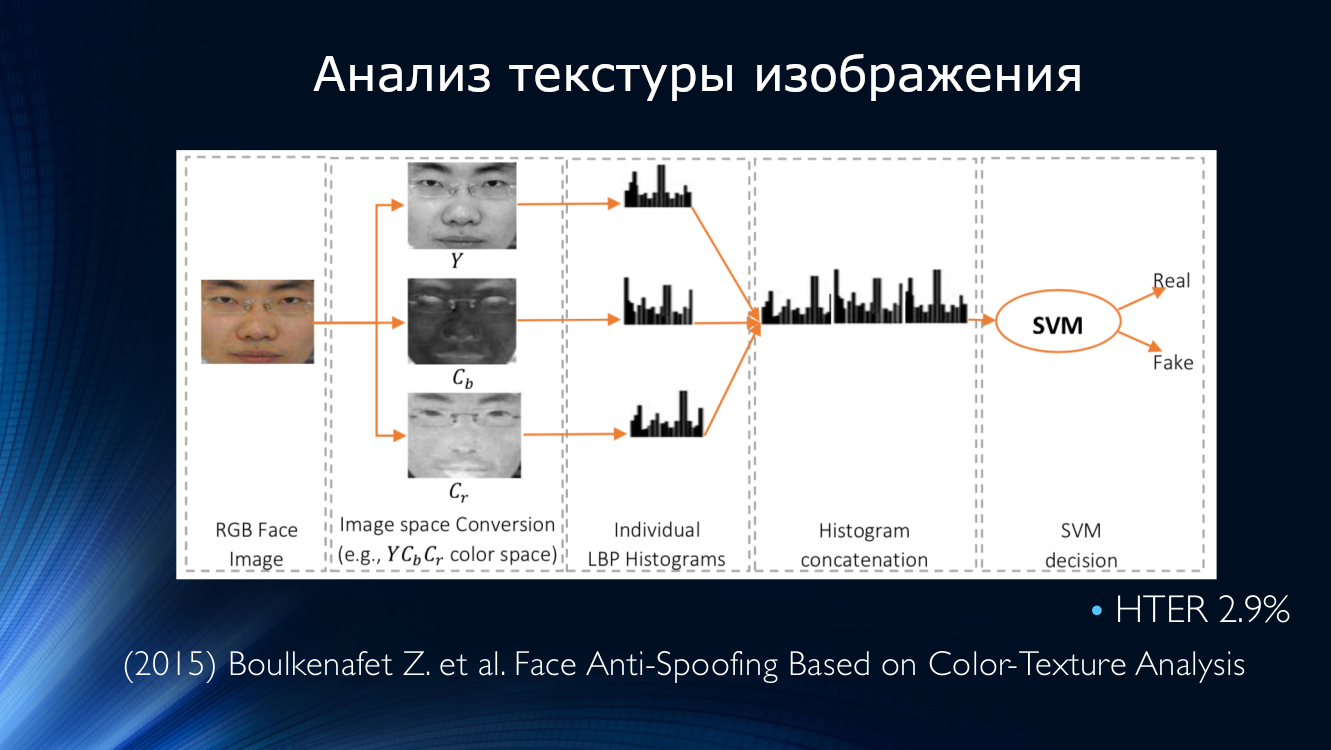
Gleichzeitig wurde an der Entdeckung von Moiré gearbeitet. Patel veröffentlichte einen Artikel, in dem er vorschlug, nach Bildartefakten in Form eines periodischen Musters zu suchen, das durch die Überlappung zweier Scans verursacht wird. Der Ansatz erwies sich als praktikabel und zeigte, dass HTER in den IDIAP-, CASIA- und RAFS-Datensätzen etwa 6% beträgt. Es war auch der erste Versuch, die Leistung eines Algorithmus für verschiedene Datensätze zu vergleichen.

Periodisches Muster im Bild, das durch Overlay-Sweeps verursacht wird
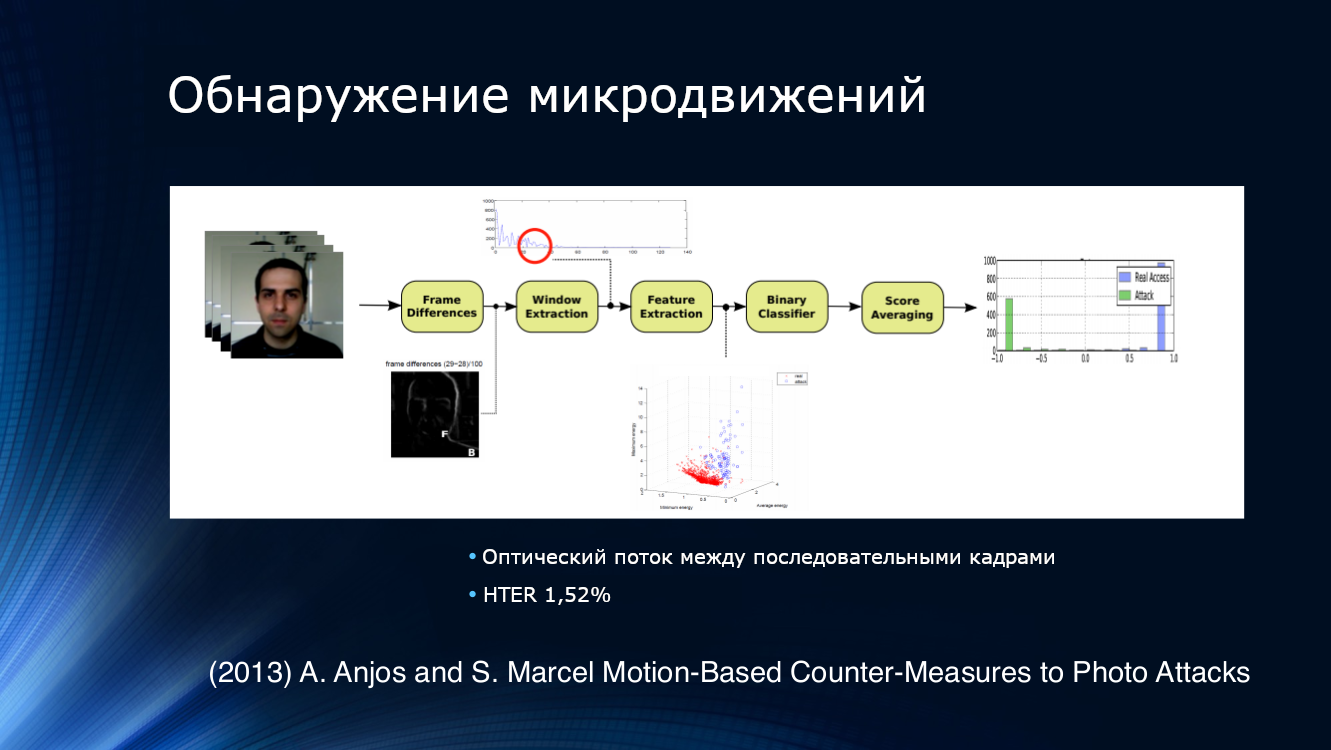
Um Versuche zu erkennen, Fotos zu präsentieren, bestand die logische Lösung darin, nicht ein Bild, sondern deren Sequenz aus dem Videostream zu analysieren. Zum Beispiel schlugen Anjos und Kollegen vor, Merkmale aus dem optischen Strom in benachbarten Rahmenpaaren zu isolieren, den binären Klassifikator der Eingabe zuzuführen und die Ergebnisse zu mitteln. Der Ansatz erwies sich als recht effektiv und zeigte einen HTER von 1,52% für den eigenen Datensatz.
Eine interessante Methode zur Verfolgung von Bewegungen, die sich von herkömmlichen Ansätzen etwas unterscheidet. Da 2013 das Prinzip „Anwenden eines Rohbildes auf die Eingabe des Faltungsnetzwerks und Anpassen der Gitterschichten, um das Ergebnis zu erhalten“ für moderne Projekte im Bereich des tiefen Lernens nicht üblich war, wandte Bharadzha konsequent komplexere vorläufige Transformationen an. Insbesondere verwendete er den Eulerschen Videovergrößerungsalgorithmus , der für die Arbeit von Wissenschaftlern des MIT bekannt ist und der erfolgreich zur Analyse von Farbveränderungen in der Haut in Abhängigkeit vom Puls eingesetzt wurde. Ich habe LBP durch HOOF (Histogramme der optischen Flussrichtungen) ersetzt, nachdem ich richtig festgestellt habe, dass wir, da wir Bewegungen verfolgen möchten, die entsprechenden Zeichen und nicht nur die Texturanalyse benötigen. Trotzdem wurde die damals traditionelle SVM als Klassifikator verwendet. Der Algorithmus zeigte äußerst beeindruckende Ergebnisse bei Print Attack- (0%) und Replay Attack- (1,25%) Datensätzen.

Lass uns schon das Gitter lernen!

Irgendwann wurde klar, dass der Übergang zum tiefen Lernen gereift war. Die berüchtigte „Deep Learning Revolution“ überholte das Anti-Spoofing.
Die „erste Schwalbe“ kann als Methode zur Analyse von Tiefenkarten in einzelnen Abschnitten („Patches“) des Bildes angesehen werden. Offensichtlich ist eine Tiefenkarte ein sehr gutes Zeichen für die Bestimmung der Ebene, in der sich das Bild befindet. Schon allein deshalb, weil das Bild auf dem Blatt Papier per Definition keine „Tiefe“ hat. In Ataums Arbeit im Jahr 2017 wurden viele separate kleine Abschnitte aus dem Bild extrahiert, für die Tiefenkarten berechnet wurden, die dann mit der Tiefenkarte des Hauptbildes zusammengeführt wurden. Es wurde darauf hingewiesen, dass zehn zufällige Gesichtsbild-Patches ausreichen, um Printed Attack zuverlässig zu identifizieren. Darüber hinaus haben die Autoren die Ergebnisse zweier Faltungsnetzwerke zusammengestellt, von denen das erste Tiefenkarten für Patches und das zweite für das gesamte Bild berechnet hat. Beim Training von Datensätzen wurde die Printed Attack-Klasse einer Tiefenkarte von Null und einem dreidimensionalen Modell des Gesichts sowie einer Reihe zufällig ausgewählter Abschnitte zugeordnet. Im Großen und Ganzen war die Tiefenkarte selbst nicht so wichtig, es wurde nur eine bestimmte Indikatorfunktion verwendet, die die „Tiefe des Abschnitts“ kennzeichnet. Der Algorithmus zeigte einen HTER-Wert von 3,78%. Für das Training wurden drei öffentliche Datensätze verwendet - CASIA-MFSD, MSU-USSA und Replay-Attack.

Leider hat die Verfügbarkeit einer großen Anzahl exzellenter Frameworks für Deep Learning zur Entstehung einer großen Anzahl von Entwicklern geführt, die "frontal" versuchen, das Problem des Antispoofing von Gesichtern auf eine bekannte Art und Weise beim Aufbau neuronaler Netze zu lösen. Normalerweise sieht es aus wie ein Stapel von Feature-Maps an den Ausgängen mehrerer Netzwerke, die auf einem weit verbreiteten Datensatz vorab trainiert wurden, der einem binären Klassifikator zugeführt wird.
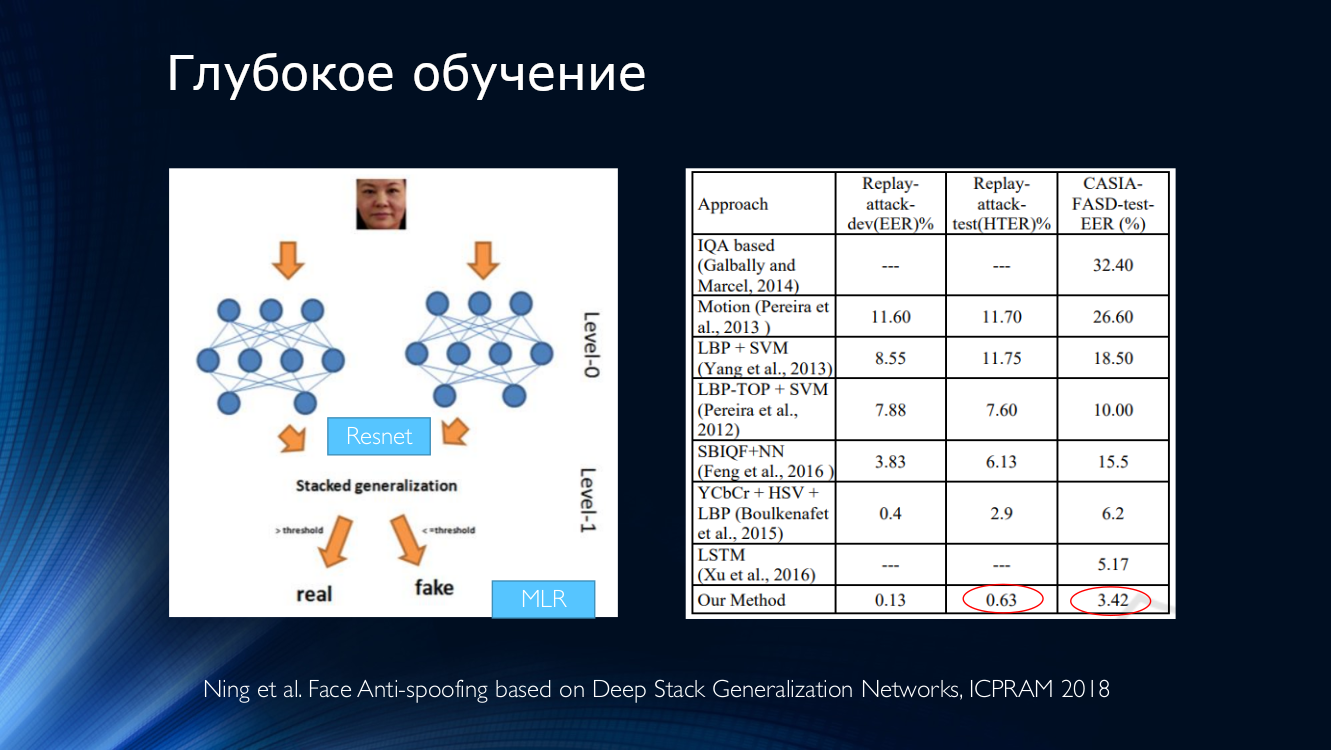
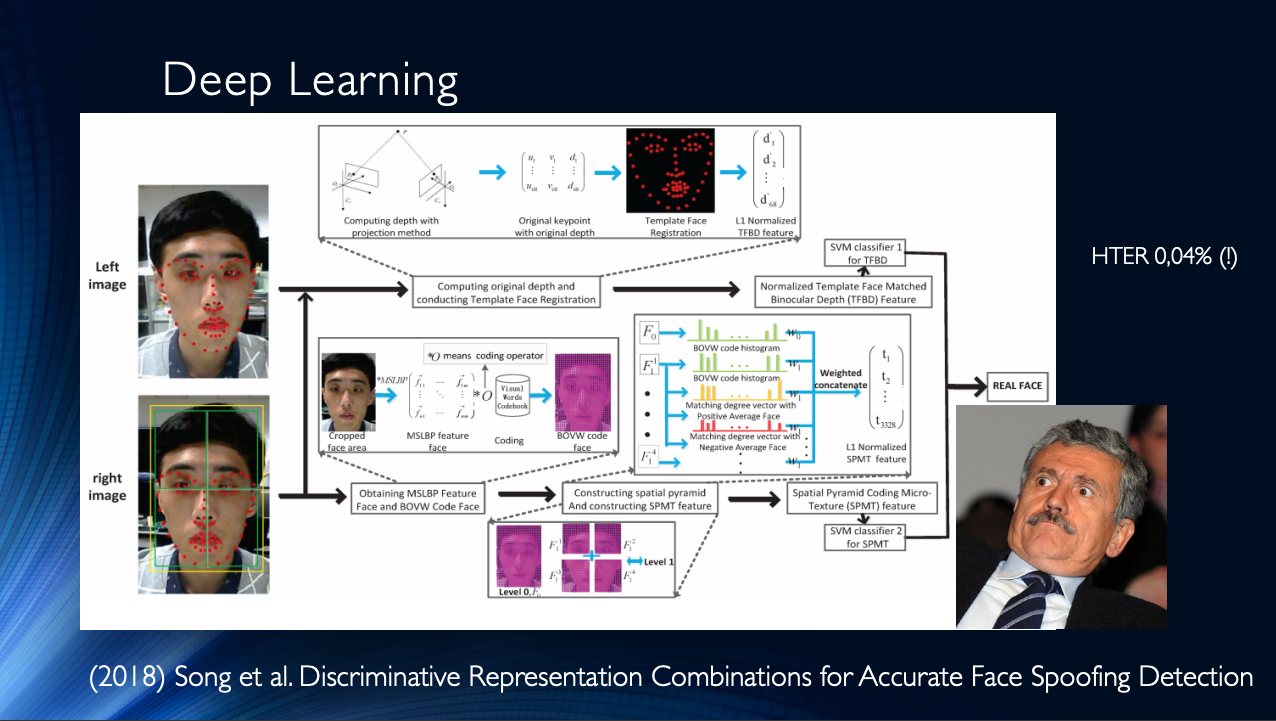
Generell ist der Schluss zu ziehen, dass bis heute einige Werke veröffentlicht wurden, die im Allgemeinen gute Ergebnisse zeigen und nur ein kleines „Aber“ vereinen. Alle diese Ergebnisse werden in einem bestimmten Datensatz demonstriert! Die Situation wird durch die begrenzte Verfügbarkeit von Datensätzen verschärft, und zum Beispiel beim berüchtigten Replay-Attack ist es für HTER 0% keine Überraschung. All dies führt zur Entstehung sehr komplexer Architekturen wie dieser , die verschiedene ausgeklügelte Merkmale, auf dem Stapel zusammengestellte Hilfsalgorithmen mit mehreren Klassifizierern, deren Ergebnisse gemittelt werden, usw. verwenden. Die Autoren erhalten HTER = 0,04% am Ausgang!
Dies deutet darauf hin, dass das Anti-Spoofing-Problem im Gesicht innerhalb eines bestimmten Datensatzes gelöst wurde. Lassen Sie uns verschiedene moderne Methoden auf den Tisch bringen, die auf neuronalen Netzen basieren. Es ist leicht zu erkennen, dass die "Referenzergebnisse" mit sehr unterschiedlichen Methoden erzielt wurden, die nur in den fragenden Köpfen der Entwickler entstanden sind.
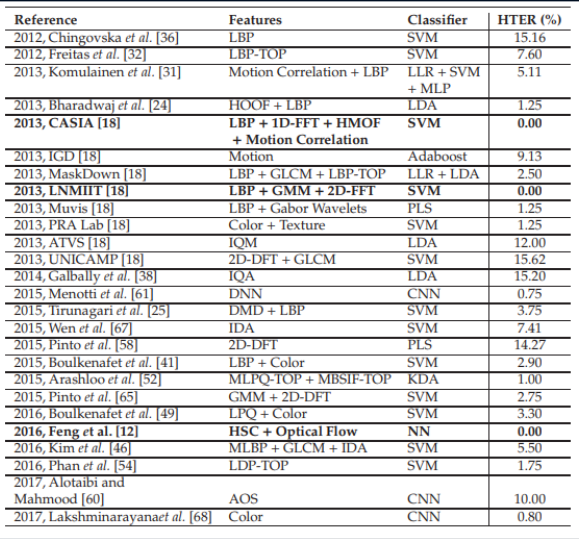
Vergleichsergebnisse verschiedener Algorithmen. Der Tisch ist von hier genommen .
Leider verletzt der gleiche „kleine“ Faktor das gute Bild des Kampfes um Zehntel Prozent. Wenn Sie versuchen, das neuronale Netzwerk auf einen Datensatz zu trainieren und auf einen anderen anzuwenden, sind die Ergebnisse ... nicht so optimistisch. Schlimmer noch, Versuche, Klassifikatoren im wirklichen Leben anzuwenden, lassen überhaupt keine Hoffnung.
Als Beispiel nehmen wir die Daten aus dem Jahr 2015, bei denen eine Metrik ihrer Qualität verwendet wurde, um die Authentizität des dargestellten Bildes zu bestimmen. Überzeugen Sie sich selbst:
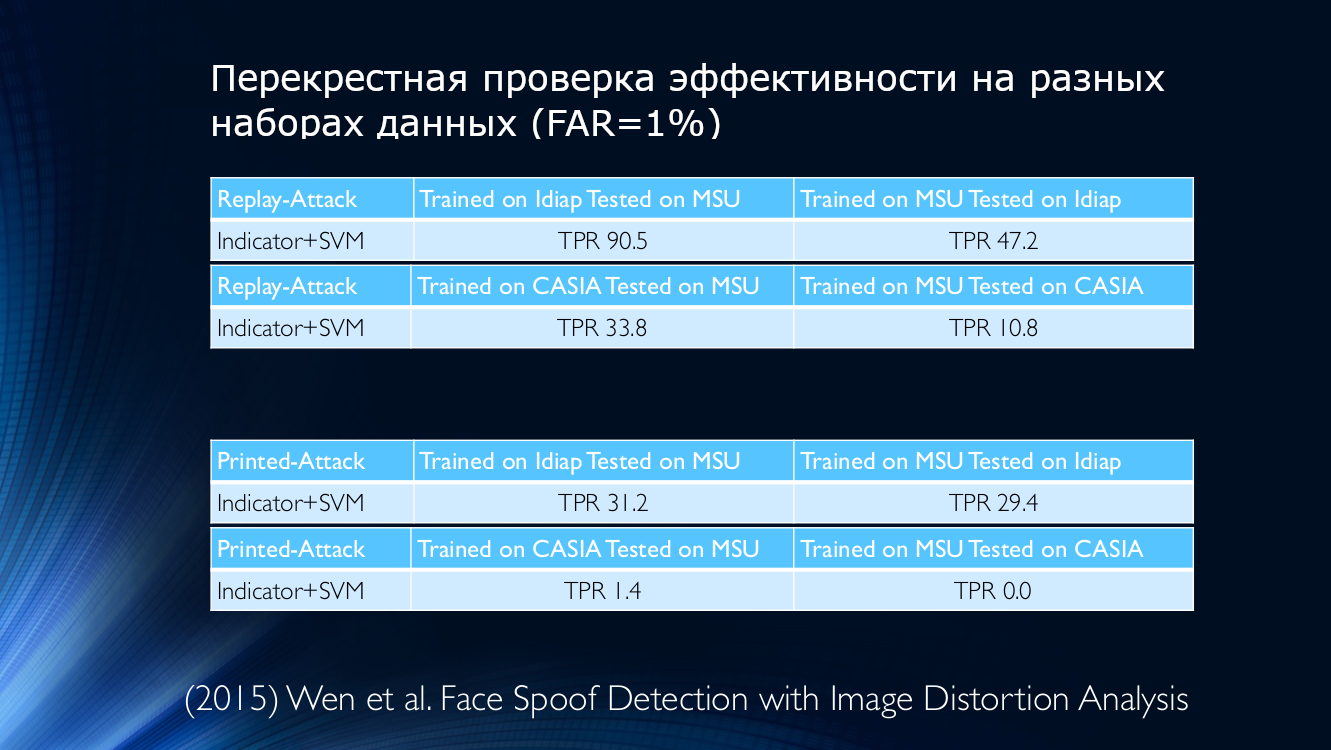
Mit anderen Worten, ein Algorithmus, der auf Idiap-Daten trainiert, aber auf MSU angewendet wird, ergibt eine wirklich positive Erkennungsrate von 90,5%. Wenn Sie das Gegenteil tun (auf MSU trainieren und auf Idiap testen), können nur 47,2 korrekt bestimmt werden % (!) Bei anderen Kombinationen verschlechtert sich die Situation noch mehr. Wenn Sie beispielsweise den Algorithmus auf MSU trainieren und auf CASIA überprüfen, beträgt der TPR 10,8%! Dies bedeutet, dass den Angreifern fälschlicherweise eine große Anzahl ehrlicher Benutzer zugewiesen wurde, was nur bedrückend sein kann. Selbst datenbankübergreifendes Training konnte die Situation nicht umkehren, was ein durchaus vernünftiger Ausweg zu sein scheint.
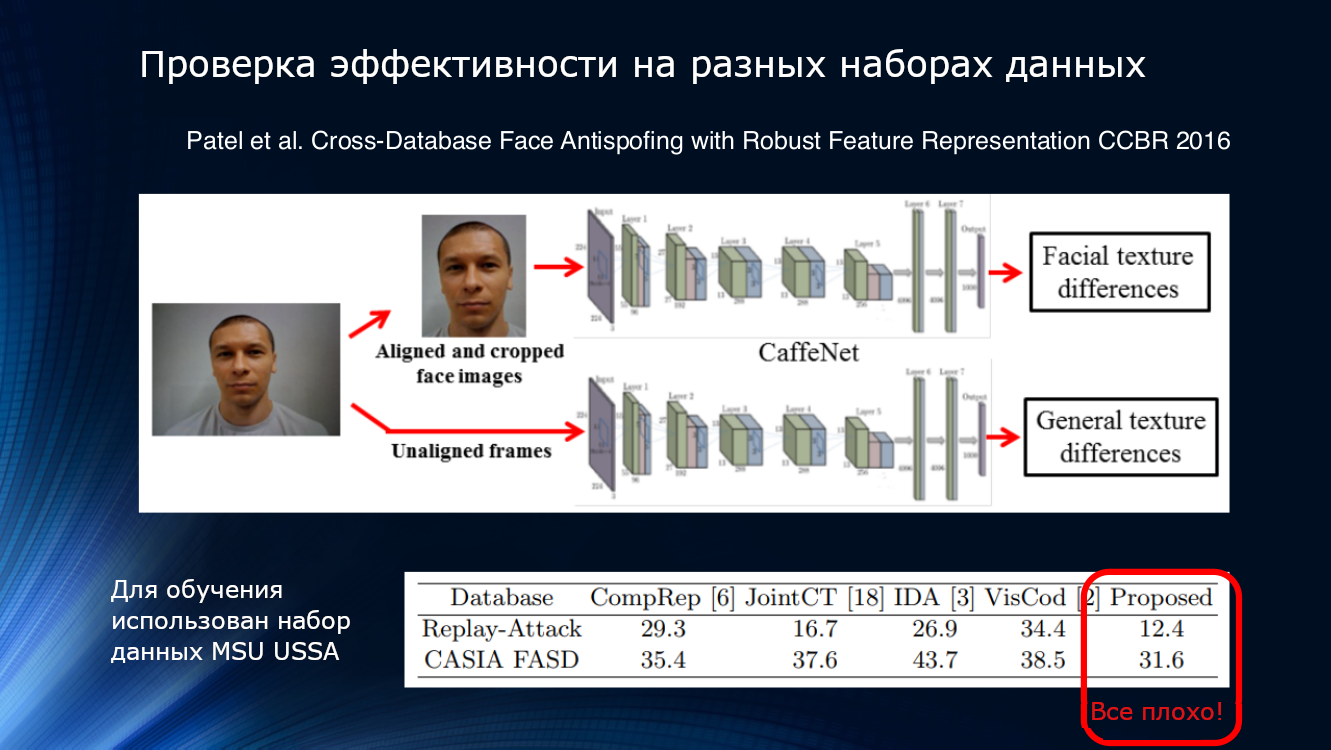
Mal sehen mehr. Die im Artikel von Patel 2016 vorgestellten Ergebnisse zeigen, dass selbst bei ausreichend komplexen Verarbeitungspipelines und der Auswahl zuverlässiger Merkmale wie Blinken und Textur die Ergebnisse unbekannter Datensätze nicht als zufriedenstellend angesehen werden können. Irgendwann wurde klar, dass die vorgeschlagenen Methoden nicht ausreichten, um die Ergebnisse zusammenzufassen.
Und wenn Sie einen Wettbewerb arrangieren ...
Natürlich war Anti-Spoofing auf dem Gebiet des Gesichts nicht ohne Konkurrenz. Im Jahr 2017 fand an der Universität von Oulu in Finnland ein Wettbewerb zu einem eigenen neuen Datensatz mit interessanten Protokollen statt, der speziell auf den Einsatz im Bereich mobiler Anwendungen ausgerichtet war.
- Protokoll 1: Es gibt einen Unterschied in Beleuchtung und Hintergrund. Datensätze werden an verschiedenen Orten aufgezeichnet und unterscheiden sich in Hintergrund und Beleuchtung.
-Protokoll 2: Verschiedene Modelle von Druckern und Bildschirmen wurden für Angriffe verwendet. Daher wird im Verifizierungsdatensatz eine Technik verwendet, die im Trainingssatz nicht enthalten ist
Protokoll 3: Austauschbarkeit von Sensoren. Echte Benutzervideos und Angriffe werden auf fünf verschiedenen Smartphones aufgezeichnet und in einem Trainingsdatensatz verwendet. , .
- 4: .
. , , , - . , , 10%. :
GRADIENT
- ( HSV YCbCr), .
- .
- HSV YCbCr, . ROI (region-of-interest) 160×160 ..
- ROI 3×3 5×5 , LBP , 6018.
- (Recursive Feature Elimination) 6018 1000.
- SVM .|
SZCVI
Recod
- SqueezeNet Imagenet
- Transfer learning : CASIA UVAD
- 224×224 pixels. , , , CNN.
- .
CPqD
- Inception-v3, ImageNet
- C
- , , 224×224 RGB |
, . LBP, , , .. GRADIANT , , , . .
. , . -, ( 15 NUAA 1140 MSU-USSA) , , , , . , , , , . -, . , CASIA , . , , , , … , , , .
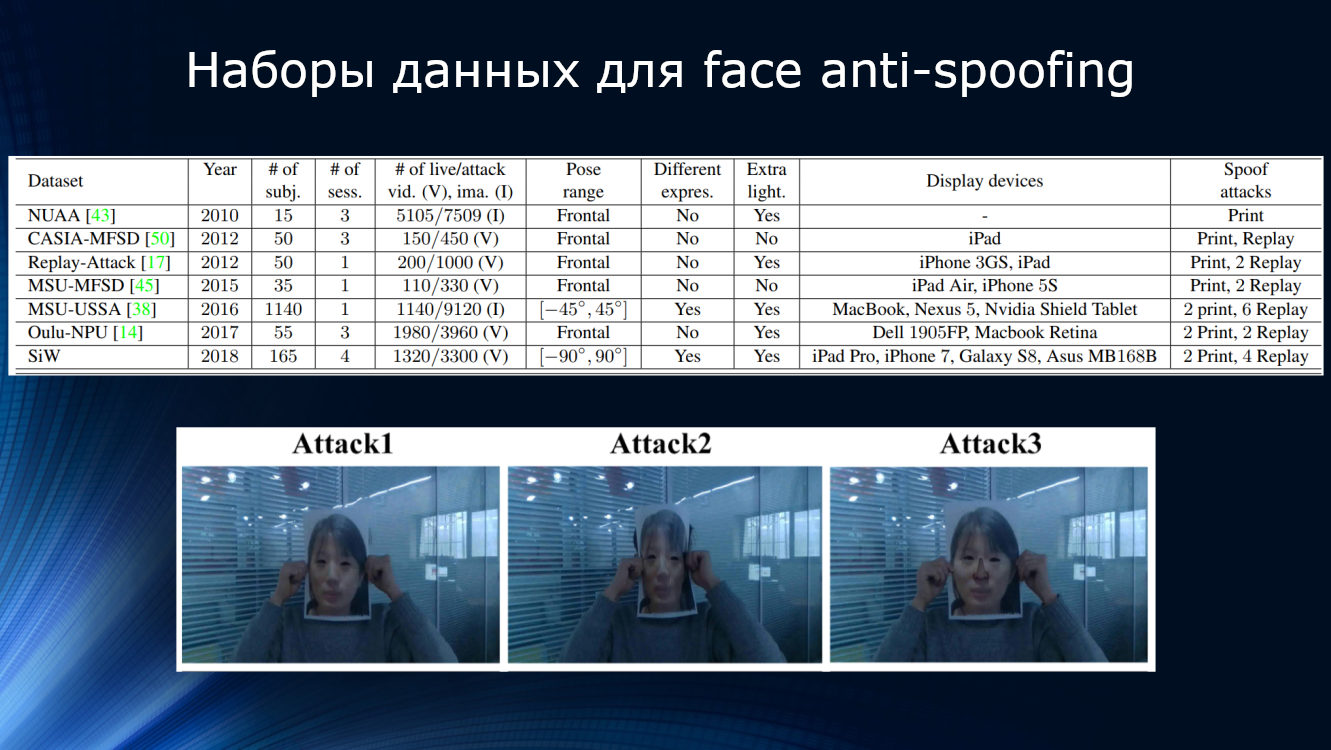
30 . , , . , .
, , « ». . , (rPPG – remote photoplethysmography), . , , -, – . . , , , . , , . , , , .


Die Arbeit zeigte einen HTER-Wert von etwa 10%, was die grundsätzliche Anwendbarkeit der Methode bestätigt. Es gibt mehrere Arbeiten, die die Aussichten dieses Ansatzes bestätigen.
(CVPR 2018) JH-Ortega et al. Zeitanalyse von pulsbasiertem Gesichts-Anti-Spoofing in Visible und NIR
(2016) X. Li. et al. Allgemeines Gesichts-Anti-Spoofing durch Erkennen von Impulsen aus Gesichtsvideos
(2016) J. Chen et al. Realsense = echte Herzfrequenz: Beleuchtungsinvariante Herzfrequenzschätzung aus Videos
(2014) HE Tasli et al. Remote PPG-basierte Vitalzeichenmessung mit adaptiven Gesichtsregionen
Im Jahr 2018 schlugen Liu und Kollegen von der University of Michigan vor , die binäre Klassifikation zugunsten des von ihnen als „binäre Überwachung“ bezeichneten Ansatzes aufzugeben , dh eine komplexere Schätzung auf der Grundlage von Tiefenkarten und Entfernungsphotoplethysmographie zu verwenden. Für jedes dieser Gesichtsbilder wurde ein dreidimensionales Modell unter Verwendung eines neuronalen Netzwerks rekonstruiert und mit einer Tiefenkarte benannt. Gefälschten Bildern wurde eine Tiefenkarte zugewiesen, die aus Nullen besteht. Am Ende ist es nur ein Stück Papier oder ein Gerätebildschirm! Diese Eigenschaften wurden als „Wahrheit“ angesehen, neuronale Netze wurden auf ihrem eigenen SiW-Datensatz trainiert. Dann wurde dem Eingabebild eine dreidimensionale Gesichtsmaske überlagert, eine Tiefenkarte und ein Impuls wurden dafür berechnet, und all dies wurde in einem ziemlich komplizierten Förderer zusammengebunden. Infolgedessen zeigte die Methode eine Genauigkeit von etwa 10 Prozent im OULU-Wettbewerbsdatensatz. Interessanterweise baute der Gewinner des von der Universität von Oulu organisierten Wettbewerbs den Algorithmus auf binären Klassifizierungsmustern, blinkendem Tracking und anderen von Hand entworfenen Zeichen auf, und seine Lösung hatte auch eine Genauigkeit von etwa 10%. Der Gewinn betrug nur etwa ein halbes Prozent! Die neue kombinierte Technologie wird durch die Tatsache unterstützt, dass der Algorithmus auf seinem eigenen Datensatz trainiert und auf OULU getestet wurde, um das Ergebnis des Gewinners zu verbessern. Dies weist auf eine gewisse Portabilität der Ergebnisse vom Datensatz zum Datensatz hin, und was zum Teufel nicht scherzt, ist für das wirkliche Leben möglich. Beim Versuch, ein Training für andere Datensätze durchzuführen - CASIA und ReplayAttack - lag das Ergebnis jedoch erneut bei etwa 28%. Dies übertrifft natürlich die Leistung anderer Algorithmen beim Training mit verschiedenen Datensätzen, aber bei solchen Genauigkeitswerten kann von keiner industriellen Verwendung gesprochen werden!
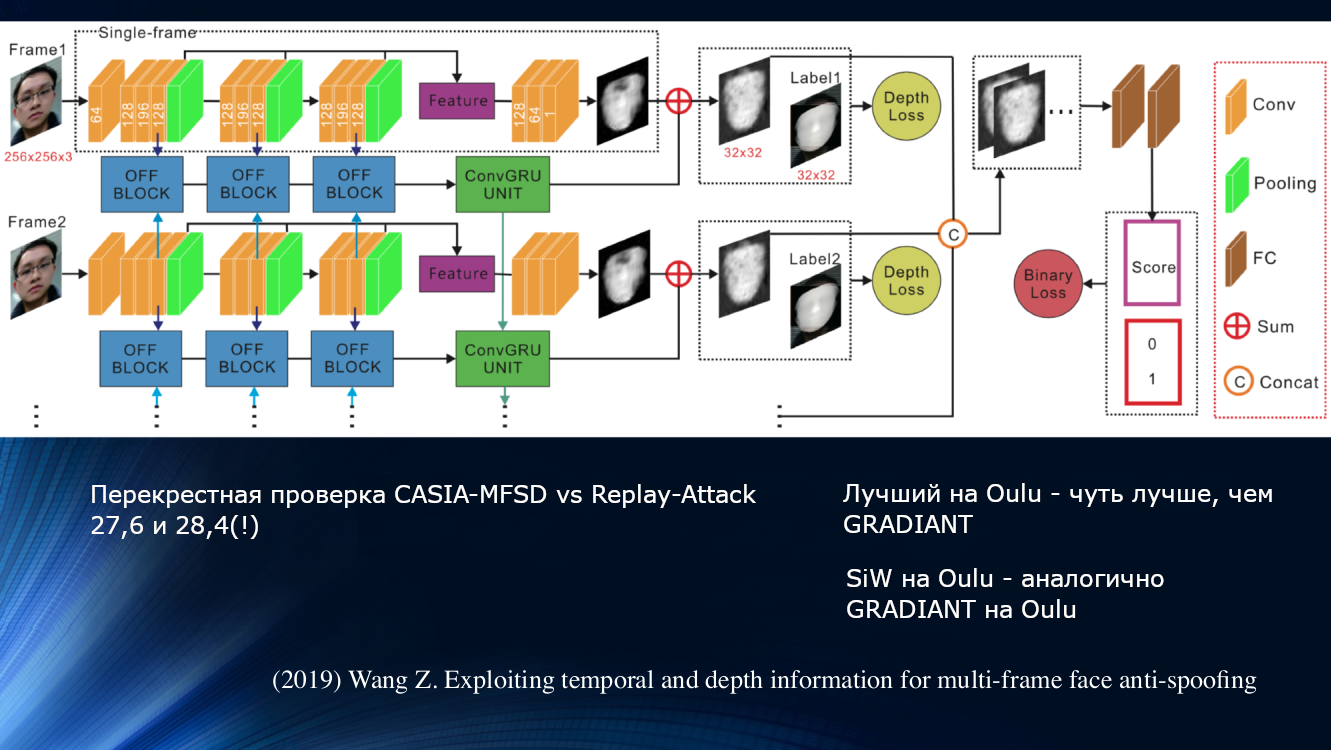
Ein anderer Ansatz wurde von Wang und Kollegen in einer kürzlich erschienenen Arbeit von 2019 vorgeschlagen. Es wurde festgestellt, dass bei der Analyse der Mikrobewegung im Gesicht Rotationen und Verschiebungen des Kopfes erkennbar sind, was zu einer charakteristischen Änderung der Winkel und relativen Abstände zwischen den Zeichen im Gesicht führt. Wenn das Gesicht horizontal verschoben wird, vergrößert sich der Winkel zwischen Nase und Ohr. Wenn Sie jedoch ein Blatt Papier mit einem Bild auf die gleiche Weise verschieben, verringert sich der Winkel! Zur Veranschaulichung lohnt es sich, eine Zeichnung aus der Arbeit zu zitieren.
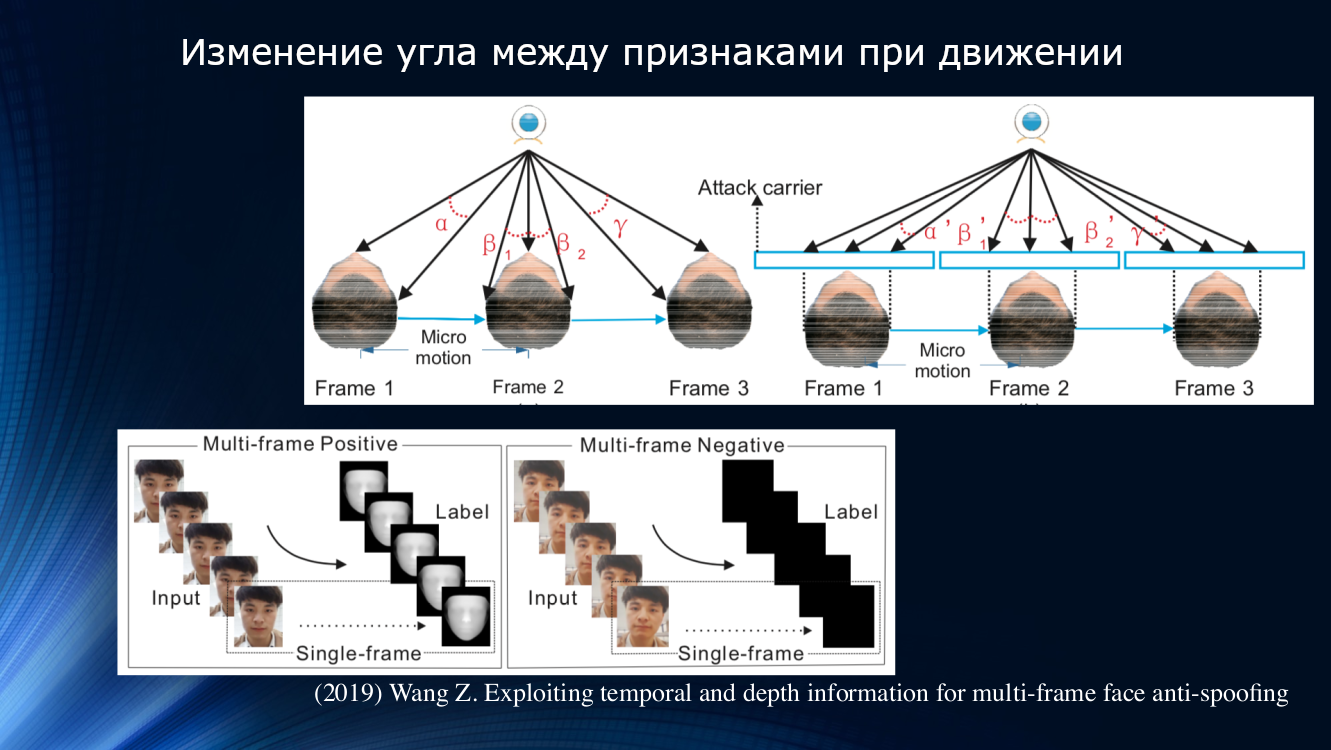
Nach diesem Prinzip bauten die Autoren eine ganze Lerneinheit zum Übertragen von Daten zwischen Schichten eines neuronalen Netzwerks auf. Dabei wurden „falsche Offsets“ für jeden Frame in einer Folge von zwei Frames berücksichtigt, sodass die Ergebnisse im nächsten Block der Langzeitabhängigkeitsanalyse auf der Grundlage der GRU Gated Recurrent Unit verwendet werden konnten . Dann wurden alle Zeichen verkettet, die Verlustfunktion berechnet und die endgültige Klassifizierung durchgeführt. Dies ermöglichte es uns, das Ergebnis des OULU-Datensatzes leicht zu verbessern, aber das Problem der Abhängigkeit von den Trainingsdaten blieb bestehen, da die Indikatoren für das CASIA-MFSD- und das Replay-Attack-Paar 17,5 bzw. 24 Prozent betrugen.
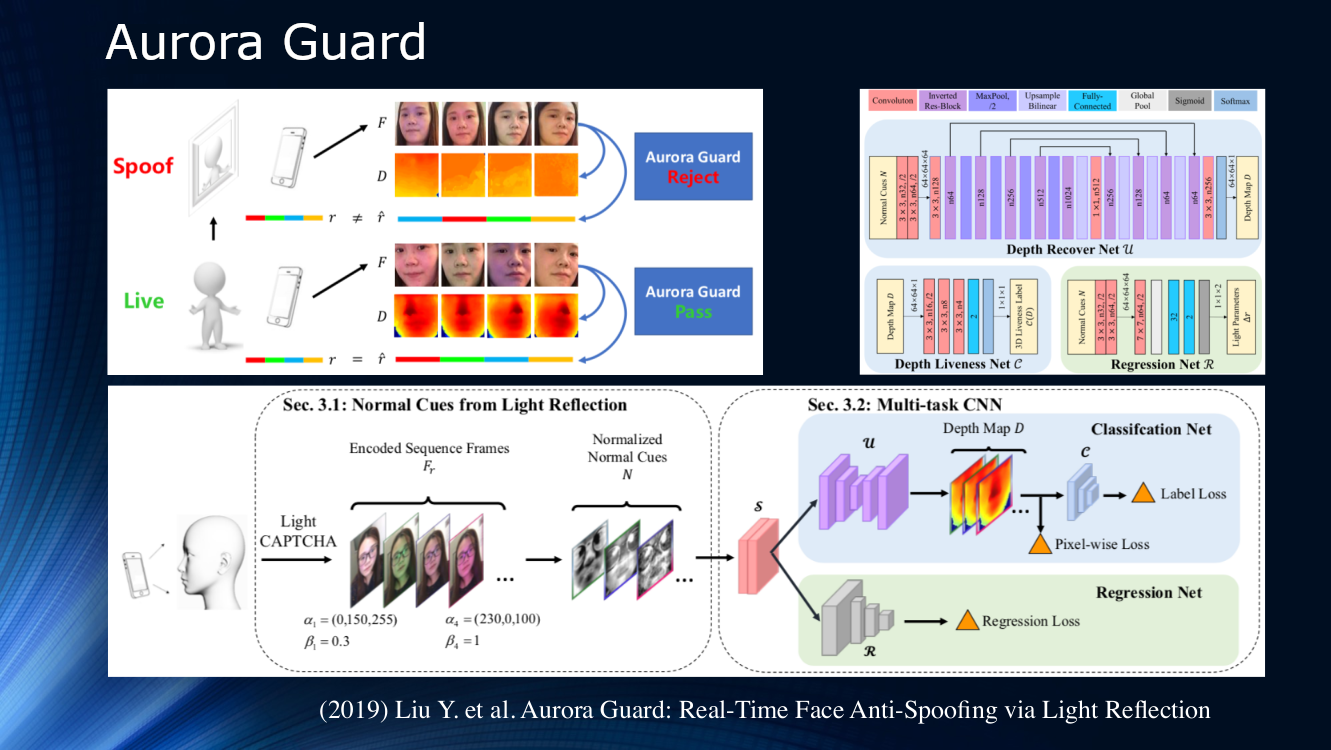
Gegen Ende ist die Arbeit von Tencent-Experten erwähnenswert, die vorgeschlagen haben, die Art und Weise zu ändern, in der das Quellvideobild empfangen wird. Anstatt die Szene passiv zu beobachten, schlugen sie vor, das Gesicht dynamisch zu beleuchten und Reflexionen zu lesen. Das Prinzip der aktiven Bestrahlung eines Objekts wird seit langem in Ortungssystemen verschiedener Art angewendet, daher erscheint seine Verwendung zur Untersuchung des Gesichts sehr logisch. Offensichtlich gibt es für eine zuverlässige Identifizierung im Bild selbst nicht genügend Zeichen, und das Beleuchten des Telefon- oder Tablet-Bildschirms mit einer Folge von Lichtsymbolen (Licht CAPTCHA gemäß der Terminologie der Autoren) kann sehr hilfreich sein. Als nächstes wird der Unterschied in Streuung und Reflexion über ein Rahmenpaar bestimmt, und die Ergebnisse werden einem neuronalen Multitask-Netzwerk zur weiteren Verarbeitung auf der Tiefenkarte und zur Berechnung verschiedener Verlustfunktionen zugeführt. Am Ende wird eine Regression der normalisierten Lichtrahmen durchgeführt. Die Autoren analysierten nicht die Generalisierungsfähigkeit ihres Algorithmus für andere Datensätze und trainierten ihn für ihren eigenen privaten Datensatz. Das Ergebnis liegt bei etwa 1% und es wird berichtet, dass das Modell bereits für den tatsächlichen Gebrauch bereitgestellt wurde.
Bis 2017 war der Gesichts-Anti-Spoofing-Bereich nicht sehr aktiv. Aber 2019 hat bereits eine ganze Reihe von Arbeiten vorgestellt, die mit der aggressiven Förderung mobiler Gesichtsidentifikationstechnologien, vor allem von Apple, verbunden sind. Darüber hinaus interessieren sich Banken für Gesichtserkennungstechnologien. Viele neue Leute sind in die Branche gekommen, was uns erlaubt, auf schnelle Fortschritte zu hoffen. Trotz der schönen Titel von Veröffentlichungen bleibt die Verallgemeinerungsfähigkeit der Algorithmen bislang sehr schwach und erlaubt es uns nicht, über eine Eignung für den praktischen Gebrauch zu sprechen.
Fazit Und zum Schluss sage ich das ...
- Lokale binäre Muster, Verfolgung von Blinken, Atmung, Bewegungen und andere manuell gestaltete Zeichen haben ihre Bedeutung überhaupt nicht verloren. Dies liegt vor allem daran, dass tiefes Training im Bereich Gesichts-Anti-Spoofing noch sehr naiv ist.
- Es ist klar, dass in der „gleichen“ Lösung mehrere Methoden zusammengeführt werden. Die Analyse von Reflexions-, Streu- und Tiefenkarten sollte zusammen verwendet werden. Höchstwahrscheinlich hilft das Hinzufügen eines zusätzlichen Datenkanals beispielsweise bei der Sprachaufzeichnung und bei einigen Systemansätzen, mit denen Sie mehrere Technologien in einem einzigen System sammeln können
- Fast alle für die Gesichtserkennung verwendeten Technologien finden Anwendung beim Gesichts-Anti-Spoofing (Cap!). Alles, was in der einen oder anderen Form für die Gesichtserkennung entwickelt wurde, hat Anwendung für die Angriffsanalyse gefunden
- Bestehende Datensätze haben die Sättigung erreicht. Von zehn Basisdatensätzen in fünf wurde ein Fehler von Null erreicht. Dies spricht zum Beispiel bereits für die Effizienz von Methoden, die auf Tiefenkarten basieren, erlaubt jedoch keine Verbesserung der Generalisierungsfähigkeit. Wir brauchen neue Daten und neue Experimente dazu
- Es besteht ein deutliches Ungleichgewicht zwischen dem Grad der Entwicklung der Gesichtserkennung und dem Antispoofing des Gesichts. Erkennungstechnologien sind Schutzsystemen deutlich voraus. Darüber hinaus ist es das Fehlen zuverlässiger Schutzsysteme, das den praktischen Einsatz von Gesichtserkennungssystemen behindert. Es kam vor, dass das Hauptaugenmerk speziell auf die Gesichtserkennung gelegt wurde und die Angriffserkennungssysteme etwas zurückhaltend blieben
- Es besteht ein starker Bedarf an einem systematischen Ansatz im Bereich des Gesichts-Anti-Spoofing. Der vergangene Wettbewerb der Universität von Oulu hat gezeigt, dass es bei Verwendung eines nicht repräsentativen Datensatzes durchaus möglich ist, die etablierten Lösungen mit einer einfachen kompetenten Anpassung zu besiegen, ohne neue zu entwickeln. Vielleicht kann ein neuer Wettbewerb das Blatt wenden
- Mit zunehmendem Interesse an dem Thema und der Einführung von Gesichtserkennungstechnologien durch große Akteure ergaben sich für neue ehrgeizige Teams „Zeitfenster“, da auf architektonischer Ebene ein ernsthafter Bedarf an einer neuen Lösung besteht