In den vorherigen Artikeln haben wir die PostgreSQL-
Indexierungs-Engine , die Schnittstelle der Zugriffsmethoden und die folgenden Methoden
erläutert :
Hash-Indizes ,
B-Bäume ,
GiST ,
SP-GiST ,
GIN und
RUM . Das Thema dieses Artikels sind BRIN-Indizes.
Brin
Allgemeines Konzept
Im Gegensatz zu Indizes, mit denen wir bereits Daten gesammelt haben, besteht die Idee von BRIN darin, das Durchsuchen definitiv ungeeigneter Zeilen zu vermeiden, anstatt schnell die passenden zu finden. Dies ist immer ein ungenauer Index: Er enthält überhaupt keine TIDs von Tabellenzeilen.
Vereinfacht gesagt funktioniert BRIN gut für Spalten, in denen Werte mit ihrer physischen Position in der Tabelle korrelieren. Mit anderen Worten, wenn eine Abfrage ohne ORDER BY-Klausel die Spaltenwerte virtuell in aufsteigender oder absteigender Reihenfolge zurückgibt (und es keine Indizes für diese Spalte gibt).
Diese Zugriffsmethode wurde im Rahmen von
Axle , dem europäischen Projekt für extrem große Analysedatenbanken, mit Blick auf Tabellen mit einer Größe von mehreren Terabyte oder Dutzenden von Terabyte erstellt. Ein wichtiges Merkmal von BRIN, mit dem wir Indizes für solche Tabellen erstellen können, ist die geringe Größe und die minimalen Wartungskosten.
Dies funktioniert wie folgt. Die Tabelle ist in
Bereiche unterteilt , die mehrere Seiten groß sind (oder mehrere Blöcke, die gleich sind) - daher der Name: Block Range Index, BRIN. Der Index speichert
zusammenfassende Informationen zu den Daten in jedem Bereich. In der Regel sind dies die minimalen und maximalen Werte, aber es ist zufällig anders, wie weiter unten gezeigt. Angenommen, es wird eine Abfrage ausgeführt, die die Bedingung für eine Spalte enthält. Wenn die gesuchten Werte nicht in das Intervall gelangen, kann der gesamte Bereich übersprungen werden. Wenn dies jedoch der Fall ist, müssen alle Zeilen in allen Blöcken durchgesehen werden, um die passenden unter ihnen auszuwählen.
Es ist kein Fehler, BRIN nicht als Index, sondern als Beschleuniger des sequentiellen Scans zu behandeln. Wir können BRIN als Alternative zur Partitionierung betrachten, wenn wir jeden Bereich als "virtuelle" Partition betrachten.
Lassen Sie uns nun die Struktur des Index genauer diskutieren.
Struktur
Die erste Seite (genauer gesagt Null) enthält die Metadaten.
Seiten mit den zusammenfassenden Informationen befinden sich in einem bestimmten Versatz zu den Metadaten. Jede Indexzeile auf diesen Seiten enthält zusammenfassende Informationen zu einem Bereich.
Zwischen der Metaseite und den Zusammenfassungsdaten befinden sich Seiten mit der Umkehrbereichskarte (abgekürzt als "revmap"). Tatsächlich ist dies ein Array von Zeigern (TIDs) auf die entsprechenden Indexzeilen.
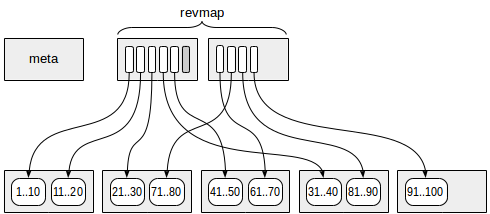
Für einige Bereiche kann der Zeiger in "revmap" zu keiner Indexzeile führen (eine ist in der Abbildung grau markiert). In einem solchen Fall wird davon ausgegangen, dass der Bereich noch keine zusammenfassenden Informationen enthält.
Index scannen
Wie wird der Index verwendet, wenn er keine Verweise auf Tabellenzeilen enthält? Diese Zugriffsmethode kann sicherlich keine Zeilen TID für TID zurückgeben, aber sie kann eine Bitmap erstellen. Es gibt zwei Arten von Bitmap-Seiten: genau auf die Zeile und ungenau auf die Seite. Es ist eine ungenaue Bitmap, die verwendet wird.
Der Algorithmus ist einfach. Die Karte der Bereiche wird nacheinander gescannt (dh die Bereiche werden in der Reihenfolge ihrer Position in der Tabelle durchlaufen). Die Zeiger werden verwendet, um Indexzeilen mit zusammenfassenden Informationen zu jedem Bereich zu bestimmen. Wenn ein Bereich nicht den gesuchten Wert enthält, wird er übersprungen. Wenn er den Wert enthalten kann (oder zusammenfassende Informationen nicht verfügbar sind), werden alle Seiten des Bereichs zur Bitmap hinzugefügt. Die resultierende Bitmap wird dann wie gewohnt verwendet.
Index aktualisieren
Interessanter ist, wie der Index aktualisiert wird, wenn die Tabelle geändert wird.
Wenn Sie einer Tabellenseite eine neue Version einer Zeile
hinzufügen , bestimmen wir, in welchem Bereich sie enthalten ist, und verwenden die Karte der Bereiche, um die Indexzeile mit den Zusammenfassungsinformationen zu finden. All dies sind einfache arithmetische Operationen. Die Größe eines Bereichs sei beispielsweise vier, und auf Seite 13 wird eine Zeilenversion mit dem Wert 42 angezeigt. Die Nummer des Bereichs (beginnend mit Null) ist 13/4 = 3, daher nehmen wir in "revmap" den Zeiger mit dem Offset von 3 (seine Bestellnummer ist vier).
Der minimale Wert für diesen Bereich ist 31 und der maximale Wert ist 40. Da der neue Wert von 42 außerhalb des Intervalls liegt, aktualisieren wir den maximalen Wert (siehe Abbildung). Befindet sich der neue Wert jedoch noch innerhalb der gespeicherten Grenzen, muss der Index nicht aktualisiert werden.

All dies bezieht sich auf die Situation, in der die neue Version der Seite in einem Bereich erscheint, für den die zusammenfassenden Informationen verfügbar sind. Wenn der Index erstellt wird, werden die Zusammenfassungsinformationen für alle verfügbaren Bereiche berechnet. Während die Tabelle jedoch weiter erweitert wird, können neue Seiten auftreten, die außerhalb der Grenzen liegen. Hier stehen zwei Optionen zur Verfügung:
- Normalerweise wird der Index nicht sofort aktualisiert. Dies ist keine große Sache: Wie bereits erwähnt, wird beim Scannen des Index der gesamte Bereich durchgesehen. Die eigentliche Aktualisierung erfolgt während des "Vakuums" oder manuell durch Aufrufen der Funktion "brin_summarize_new_values".
- Wenn wir den Index mit dem Parameter "autosummarize" erstellen, wird die Aktualisierung sofort durchgeführt. Wenn Seiten des Bereichs jedoch mit neuen Werten gefüllt werden, können Aktualisierungen zu häufig erfolgen. Daher ist dieser Parameter standardmäßig deaktiviert.
Wenn neue Bereiche auftreten, kann sich die Größe der "Revmap" erhöhen. Immer wenn die Karte zwischen der Metaseite und den Zusammenfassungsdaten um eine andere Seite erweitert werden muss, werden vorhandene Zeilenversionen auf einige andere Seiten verschoben. Die Karte der Bereiche befindet sich also immer zwischen der Metaseite und den Zusammenfassungsdaten.
Wenn eine Zeile
gelöscht wird , ... passiert nichts. Wir können feststellen, dass manchmal der minimale oder maximale Wert gelöscht wird. In diesem Fall könnte das Intervall reduziert werden. Um dies zu erkennen, müssten wir jedoch alle Werte im Bereich lesen, und dies ist kostspielig.
Die Richtigkeit des Index wird nicht beeinträchtigt. Bei der Suche müssen jedoch möglicherweise mehr Bereiche durchsucht werden, als tatsächlich benötigt werden. Im Allgemeinen können zusammenfassende Informationen für eine solche Zone manuell neu berechnet werden (durch Aufrufen der Funktionen "brin_desummarize_range" und "brin_summarize_new_values"). Wie können wir jedoch einen solchen Bedarf erkennen? Zu diesem Zweck steht jedoch kein herkömmliches Verfahren zur Verfügung.
Schließlich ist das
Aktualisieren einer Zeile nur das Löschen der veralteten Version und das Hinzufügen einer neuen.
Beispiel
Versuchen wir, ein eigenes Mini-Data-Warehouse für die Daten aus Tabellen der
Demo-Datenbank zu erstellen. Nehmen wir an, dass für die BI-Berichterstattung eine denormalisierte Tabelle erforderlich ist, um die Flüge, die von einem Flughafen abgeflogen oder auf dem Flughafen gelandet sind, mit der Genauigkeit eines Sitzplatzes in der Kabine wiederzugeben. Die Daten für jeden Flughafen werden einmal täglich zur Tabelle hinzugefügt, wenn es Mitternacht in der entsprechenden Zeitzone ist. Die Daten werden weder aktualisiert noch gelöscht.
Die Tabelle sieht wie folgt aus:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
Wir können den Vorgang des Ladens der Daten mithilfe verschachtelter Schleifen simulieren: eine externe - nach Tagen (wir betrachten
eine große Datenbank , also 365 Tage) und eine interne Schleife - nach Zeitzonen (von UTC + 02 bis UTC + 12) . Die Abfrage ist ziemlich lang und nicht von besonderem Interesse, daher werde ich sie unter dem Spoiler verstecken.
Simulation des Ladens der Daten in den Speicher DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
Wir bekommen 30 Millionen Zeilen und 4 GB. Nicht so groß, aber gut genug für einen Laptop: Der sequentielle Scan dauerte ungefähr 10 Sekunden.
Auf welchen Spalten sollen wir den Index erstellen?
Da BRIN-Indizes eine geringe Größe und moderate Gemeinkosten haben und Aktualisierungen nur selten auftreten, bietet sich die seltene Gelegenheit, viele Indizes „nur für den Fall“ zu erstellen, beispielsweise in allen Bereichen, in denen Analystenbenutzer ihre Ad-hoc-Abfragen erstellen können . Wird nicht nützlich sein - egal, aber selbst ein Index, der nicht sehr effizient ist, funktioniert mit Sicherheit besser als sequentieller Scan. Natürlich gibt es Felder, in denen es absolut nutzlos ist, einen Index zu erstellen. reiner gesunder Menschenverstand wird sie dazu veranlassen.
Es sollte jedoch seltsam sein, sich auf diesen Rat zu beschränken. Versuchen wir daher, ein genaueres Kriterium anzugeben.
Wir haben bereits erwähnt, dass die Daten in gewisser Weise mit ihrem physischen Standort korrelieren müssen. Hier ist es sinnvoll, sich daran zu erinnern, dass PostgreSQL Tabellenspaltenstatistiken sammelt, die den Korrelationswert enthalten. Der Planer verwendet diesen Wert, um zwischen einem regulären Index-Scan und einem Bitmap-Scan zu wählen, und wir können ihn verwenden, um die Anwendbarkeit des BRIN-Index abzuschätzen.
Im obigen Beispiel sind die Daten offensichtlich nach Tagen geordnet (nach "geplanter_Zeit" sowie nach "tatsächlicher_Zeit" - es gibt keinen großen Unterschied). Dies liegt daran, dass Zeilen, die der Tabelle hinzugefügt werden (ohne Löschungen und Aktualisierungen), nacheinander in der Datei angeordnet werden. Bei der Simulation des Datenladens haben wir nicht einmal die ORDER BY-Klausel verwendet, daher können Daten innerhalb eines Tages im Allgemeinen auf beliebige Weise verwechselt werden, aber die Reihenfolge muss vorhanden sein. Lassen Sie uns dies überprüfen:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
Der Wert, der nicht zu nahe bei Null liegt (idealerweise in der Nähe von Plus-Minus Eins, wie in diesem Fall), sagt uns, dass der BRIN-Index angemessen ist.
Die Reiseklasse "Tarifbedingung" (die Spalte enthält drei eindeutige Werte) und der Flugtyp "Flugtyp" (zwei eindeutige Werte) schienen unerwartet an zweiter und dritter Stelle zu stehen. Dies ist eine Illusion: Formal ist die Korrelation hoch, während tatsächlich auf mehreren aufeinanderfolgenden Seiten alle möglichen Werte mit Sicherheit angetroffen werden, was bedeutet, dass BRIN nichts Gutes bringt.
Als nächstes folgt die Zeitzone "Airport_utc_offset": Im betrachteten Beispiel werden Flughäfen innerhalb eines Tageszyklus nach Zeitzonen "nach Konstruktion" geordnet.
Es sind diese beiden Felder, Zeit und Zeitzone, mit denen wir weiter experimentieren werden.
Mögliche Schwächung der Korrelation
Die Korrelation, die "durch Konstruktion" entsteht, kann leicht geschwächt werden, wenn die Daten geändert werden. Dabei geht es nicht um eine Änderung eines bestimmten Werts, sondern um die Struktur der Multiversions-Parallelitätskontrolle: Die veraltete Zeilenversion wird auf einer Seite gelöscht, aber eine neue Version kann eingefügt werden, wo immer freier Speicherplatz verfügbar ist. Aus diesem Grund werden bei Aktualisierungen ganze Zeilen verwechselt.
Wir können diesen Effekt teilweise steuern, indem wir den Wert des Speicherparameters "fillfactor" reduzieren und auf diese Weise freien Speicherplatz auf einer Seite für zukünftige Aktualisierungen lassen. Aber wollen wir die Größe eines bereits riesigen Tisches erhöhen? Außerdem wird das Problem der Löschungen dadurch nicht behoben: Sie setzen auch "Traps" für neue Zeilen, indem sie den Speicherplatz irgendwo auf vorhandenen Seiten freigeben. Aus diesem Grund werden Zeilen, die sonst am Ende der Datei ankommen würden, an einer beliebigen Stelle eingefügt.
Das ist übrigens eine merkwürdige Tatsache. Da der BRIN-Index keine Verweise auf Tabellenzeilen enthält, sollte seine Verfügbarkeit HOT-Aktualisierungen überhaupt nicht behindern, dies ist jedoch der Fall.
Daher ist BRIN hauptsächlich für Tabellen mit großen und sogar großen Größen konzipiert, die entweder überhaupt nicht oder nur geringfügig aktualisiert werden. Es wird jedoch perfekt mit dem Hinzufügen neuer Zeilen (am Ende der Tabelle) fertig. Dies ist nicht überraschend, da diese Zugriffsmethode im Hinblick auf Data Warehouses und analytische Berichte erstellt wurde.
Welche Größe eines Bereichs müssen wir auswählen?
Wenn wir uns mit einer Terabyte-Tabelle befassen, besteht unser Hauptanliegen bei der Auswahl der Größe eines Bereichs wahrscheinlich darin, den BRIN-Index nicht zu groß zu machen. In unserer Situation können wir es uns jedoch leisten, Daten genauer zu analysieren.
Dazu können wir eindeutige Werte einer Spalte auswählen und sehen, auf wie vielen Seiten sie auftreten. Die Lokalisierung der Werte erhöht die Erfolgschancen bei der Anwendung des BRIN-Index. Darüber hinaus gibt die gefundene Anzahl von Seiten die Größe eines Bereichs an. Wenn der Wert jedoch über alle Seiten "verteilt" ist, ist BRIN nutzlos.
Natürlich sollten wir diese Technik verwenden, um die interne Struktur der Daten im Auge zu behalten. Zum Beispiel macht es keinen Sinn, jedes Datum (genauer gesagt einen Zeitstempel, einschließlich der Uhrzeit) als eindeutigen Wert zu betrachten - wir müssen ihn auf Tage runden.
Technisch kann diese Analyse durchgeführt werden, indem der Wert der ausgeblendeten Spalte "ctid" betrachtet wird, die den Zeiger auf eine Zeilenversion (TID) liefert: die Nummer der Seite und die Nummer der Zeile innerhalb der Seite. Leider gibt es keine konventionelle Technik, um TID in seine zwei Komponenten zu zerlegen. Daher müssen wir Typen durch die Textdarstellung gießen:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
Wir können sehen, dass jeder Tag ziemlich gleichmäßig auf die Seiten verteilt ist und die Tage leicht miteinander verwechselt sind (1500 & mal 365 = 547500, was nur wenig größer ist als die Anzahl der Seiten in der Tabelle 528172). Dies ist eigentlich "durch Konstruktion" sowieso klar.
Wertvolle Informationen sind hier eine bestimmte Anzahl von Seiten. Bei einer herkömmlichen Bereichsgröße von 128 Seiten werden pro Tag 9 bis 14 Bereiche ausgefüllt. Dies scheint realistisch: Bei einer Abfrage für einen bestimmten Tag können wir einen Fehler von etwa 10% erwarten.
Versuchen wir mal:
demo=# create index on flights_bi using brin(scheduled_time);
Die Größe des Index beträgt nur 184 KB:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
In diesem Fall ist es kaum sinnvoll, die Größe eines Bereichs auf Kosten des Genauigkeitsverlusts zu erhöhen. Bei Bedarf können wir jedoch die Größe reduzieren, und die Genauigkeit nimmt im Gegenteil zu (zusammen mit der Größe des Index).
Schauen wir uns nun die Zeitzonen an. Auch hier können wir keinen Brute-Force-Ansatz verwenden. Alle Werte sollten stattdessen durch die Anzahl der Tageszyklen geteilt werden, da die Verteilung innerhalb jedes Tages wiederholt wird. Da es nur wenige Zeitzonen gibt, können wir außerdem die gesamte Verteilung betrachten:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
Im Durchschnitt füllen die Daten für jede Zeitzone 133 Seiten pro Tag, aber die Verteilung ist sehr ungleichmäßig: Petropawlowsk-Kamtschatskiy und Anadyr haben nur sechs Seiten, während Moskau und seine Umgebung Hunderte davon benötigen. Die Standardgröße eines Bereichs ist hier nicht gut. Stellen wir es zum Beispiel auf vier Seiten ein.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
Ausführungsplan
Schauen wir uns an, wie unsere Indizes funktionieren. Wählen wir einen Tag aus, beispielsweise vor einer Woche (in der Demo-Datenbank wird "heute" durch die Funktion "booking.now" bestimmt):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
Wie wir sehen können, hat der Planer den erstellten Index verwendet. Wie genau ist es? Das Verhältnis der Anzahl der Zeilen, die die Abfragebedingungen erfüllen ("Zeilen" des Bitmap-Heap-Scan-Knotens), zur Gesamtzahl der Zeilen, die mit dem Index zurückgegeben wurden (der gleiche Wert plus durch Indexüberprüfung entfernte Zeilen), gibt Auskunft darüber. In diesem Fall 83954 / (83954 + 12045), was erwartungsgemäß ungefähr 90% entspricht (dieser Wert ändert sich von einem Tag zum anderen).
Woher stammt die 16640-Nummer in "tatsächlichen Zeilen" des Bitmap-Index-Scan-Knotens? Die Sache ist, dass dieser Knoten des Plans eine ungenaue (Seite für Seite) Bitmap erstellt und nicht weiß, wie viele Zeilen die Bitmap berühren wird, während etwas angezeigt werden muss. In der Verzweiflung wird daher angenommen, dass eine Seite 10 Zeilen enthält. Die Bitmap enthält insgesamt 1664 Seiten (dieser Wert wird in "Heap Blocks: lossy = 1664" angezeigt). Wir bekommen also nur 16640. Insgesamt ist dies eine sinnlose Zahl, auf die wir nicht achten sollten.
Wie wäre es mit Flughäfen? Nehmen wir zum Beispiel die Zeitzone von Wladiwostok, die 28 Seiten pro Tag umfasst:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
Der Planer verwendet erneut den erstellten BRIN-Index. Die Genauigkeit ist schlechter (in diesem Fall etwa 75%), dies wird jedoch erwartet, da die Korrelation geringer ist.
Auf BRMap-Ebene können sicherlich mehrere BRIN-Indizes (genau wie alle anderen) verknüpft werden. Das Folgende sind beispielsweise die Daten in der ausgewählten Zeitzone für einen Monat (Hinweis "BitmapAnd" -Knoten):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
Vergleich mit B-Baum
Was ist, wenn wir einen regulären B-Tree-Index für dasselbe Feld wie BRIN erstellen?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
Es schien
mehrere tausend Mal größer zu sein als unser BRIN! Die Abfrage wird jedoch etwas schneller ausgeführt: Der Planer verwendete Statistiken, um herauszufinden, dass die Daten physisch geordnet sind und keine Bitmap erstellt werden muss und dass die Indexbedingung hauptsächlich nicht erneut überprüft werden muss:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
Das ist das Wunderbare an BRIN: Wir opfern die Effizienz, gewinnen aber sehr viel Platz.
Operatorklassen
minmax
Bei Datentypen, deren Werte miteinander verglichen werden können, bestehen die zusammenfassenden Informationen aus
den Minimal- und Maximalwerten . Die Namen der entsprechenden Operatorklassen enthalten "minmax", z. B. "date_minmax_ops". Tatsächlich sind dies Datentypen, die wir bisher in Betracht gezogen haben, und die meisten Typen sind von dieser Art.
inklusive
Vergleichsoperatoren sind nicht für alle Datentypen definiert. Beispielsweise sind sie nicht für Punkte ("Punkt" -Typ) definiert, die die geografischen Koordinaten von Flughäfen darstellen. Aus diesem Grund zeigen die Statistiken übrigens nicht die Korrelation für diese Spalte.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
Viele solcher Typen ermöglichen es uns jedoch, ein Konzept eines "Begrenzungsbereichs" einzuführen, beispielsweise ein Begrenzungsrechteck für geometrische Formen. Wir haben ausführlich besprochen, wie der
GiST- Index diese Funktion verwendet. In ähnlicher Weise ermöglicht BRIN auch das Sammeln von Zusammenfassungsinformationen zu Spalten mit Datentypen wie diesen:
Der Begrenzungsbereich für alle Werte innerhalb eines Bereichs ist nur der Zusammenfassungswert.
Im Gegensatz zu GiST muss der Zusammenfassungswert für BRIN vom gleichen Typ sein wie die zu indizierenden Werte. Daher können wir den Index für Punkte nicht erstellen, obwohl klar ist, dass die Koordinaten in BRIN funktionieren könnten: Der Längengrad ist eng mit der Zeitzone verbunden. Glücklicherweise behindert nichts die Erstellung des Index für einen Ausdruck, nachdem Punkte in entartete Rechtecke umgewandelt wurden. Gleichzeitig setzen wir die Größe eines Bereichs auf eine Seite, um den Grenzfall anzuzeigen:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
Die Größe des Index beträgt selbst in solch extremen Situationen nur 30 MB:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
Jetzt können wir Anfragen stellen, die die Flughäfen durch Koordinaten einschränken. Zum Beispiel:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
Der Planer wird sich jedoch weigern, unseren Index zu verwenden.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Warum? Deaktivieren wir den sequentiellen Scan und sehen, was passiert:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Es scheint, dass der Index
verwendet werden kann, aber der Planer geht davon aus, dass die Bitmap auf der gesamten Tabelle erstellt werden muss (siehe "Zeilen" des Bitmap-Index-Scan-Knotens), und es ist kein Wunder, dass der Planer den sequentiellen Scan-In auswählt dieser Fall. Das Problem hierbei ist, dass PostgreSQL für geometrische Typen keine Statistiken sammelt und der Planer blind vorgehen muss:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
Leider. Es gibt jedoch keine Beschwerden über den Index - er funktioniert und funktioniert einwandfrei:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
Die Schlussfolgerung muss folgendermaßen lauten: PostGIS wird benötigt, wenn für die Geometrie etwas nicht Triviales erforderlich ist. Es kann sowieso Statistiken sammeln.
Interna
Die konventionelle Erweiterung "pageinspect" ermöglicht es uns, in den BRIN-Index zu schauen.
Zunächst werden wir anhand der Metainformation über die Größe eines Bereichs und die Anzahl der für "revmap" zugewiesenen Seiten informiert:
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
Die Seiten 1-3 sind hier für "revmap" reserviert, während der Rest zusammenfassende Daten enthält. Aus "revmap" können wir Verweise auf Zusammenfassungsdaten für jeden Bereich erhalten. Angenommen, die Informationen zum ersten Bereich, der die ersten 128 Seiten umfasst, befinden sich hier:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
Und das sind die zusammenfassenden Daten selbst:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
Nächster Bereich:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
Und so weiter.
Bei "Einschluss" -Klassen wird im Feld "Wert" so etwas wie angezeigt
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
Der erste Wert ist das Einbettungsrechteck, und "f" -Buchstaben am Ende bezeichnen fehlende leere Elemente (das erste) und fehlende nicht zusammenführbare Werte (das zweite). Tatsächlich sind die einzigen nicht zusammenlegbaren Werte die Adressen "IPv4" und "IPv6" (Datentyp "inet").
Eigenschaften
Erinnert Sie an die
bereits gestellten Fragen.
Im Folgenden sind die Eigenschaften der Zugriffsmethode aufgeführt:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
Indizes können für mehrere Spalten erstellt werden. In diesem Fall werden für jede Spalte eigene Zusammenfassungsstatistiken erfasst, die jedoch für jeden Bereich zusammen gespeichert werden. Dieser Index ist natürlich sinnvoll, wenn ein und dieselbe Größe eines Bereichs für alle Spalten geeignet ist.
Die folgenden Indexschicht-Eigenschaften sind verfügbar:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Offensichtlich wird nur der Bitmap-Scan unterstützt.
Das Fehlen von Clustering kann jedoch verwirrend erscheinen. Da der BRIN-Index empfindlich auf die physische Reihenfolge der Zeilen reagiert, wäre es logisch, Daten gemäß dem Index gruppieren zu können. Das ist aber nicht so. Wir können nur einen „regulären“ Index (B-Tree oder GiST, je nach Datentyp) erstellen und entsprechend gruppieren. Möchten Sie übrigens eine vermeintlich große Tabelle unter Berücksichtigung der exklusiven Sperren, der Ausführungszeit und des Speicherplatzverbrauchs beim Wiederherstellen gruppieren?
Im Folgenden sind die Eigenschaften der Spaltenschicht aufgeführt:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
Die einzige verfügbare Eigenschaft ist die Möglichkeit, NULL-Werte zu bearbeiten.
Lesen Sie weiter .