
Die Technologie von Harry Potter hat bis heute überlebt. Um ein vollwertiges Video einer Person zu erstellen, reicht nur eines ihrer Bilder oder Fotografien aus. Forscher des maschinellen Lernens aus Skolkovo und dem Samsung AI Center in Moskau veröffentlichten ihre Arbeiten zur Schaffung eines solchen Systems sowie eine Reihe von Videos von Prominenten und Kunstobjekten, die ein neues Leben erhalten haben.

Der Text der wissenschaftlichen Arbeit kann hier gelesen werden . Dort ist alles sehr interessant, mit vielen Formeln, aber die Bedeutung ist einfach: Ihr System wird von "Orientierungspunkten", Gesichtern wie einer Nase, zwei Augen, zwei Augenbrauen und der Kinnlinie geleitet. So fängt sie sofort ein, was eine Person ist. Und dann kann alles andere (Farbe, Textur des Gesichts, Schnurrbart, Stoppeln usw.) auf das Video einer anderen Person übertragen werden. Das alte Gesicht an neue Situationen anpassen.
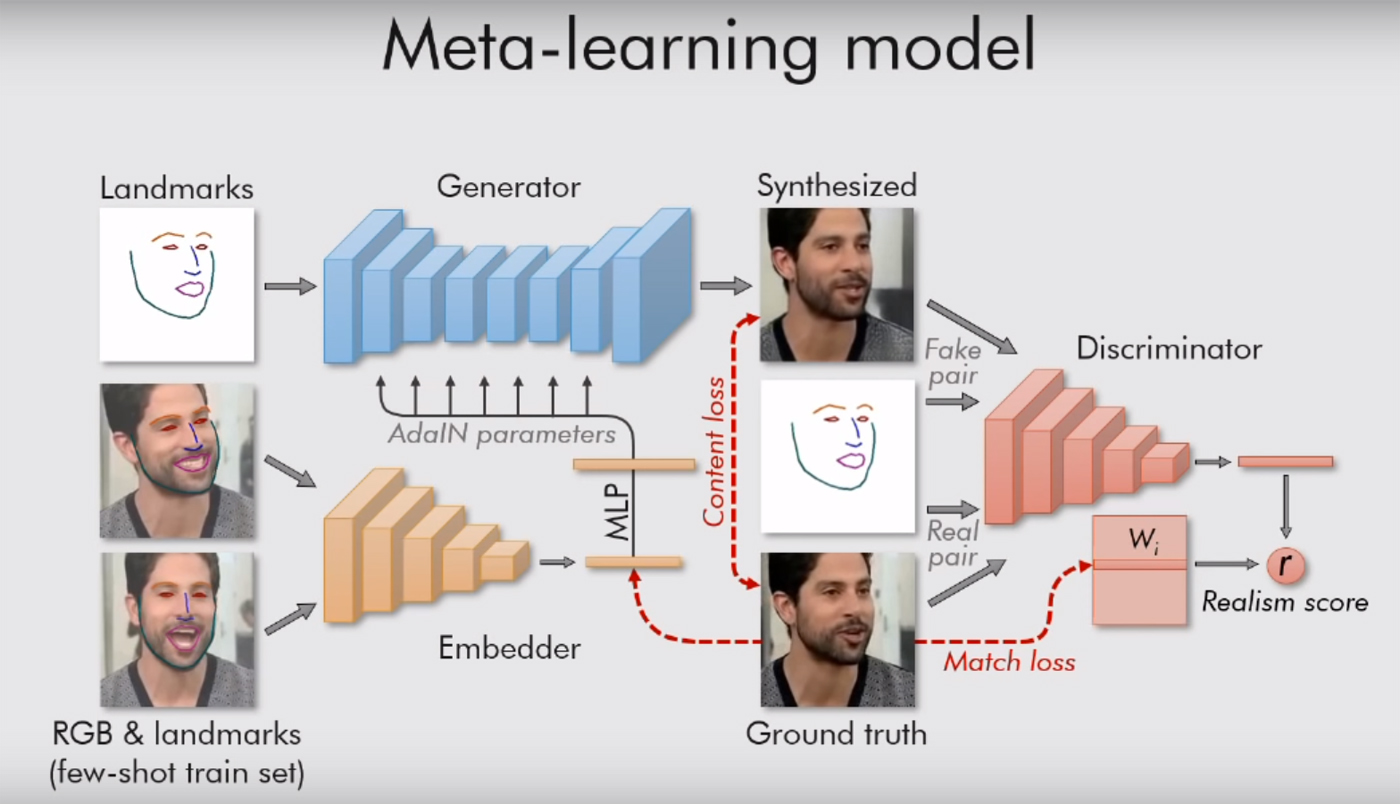
Dies funktioniert natürlich nur bei Porträts. Das Modell braucht nur eine Person mit einem uns zugewandten Gesicht, damit es zumindest beide Augen sehen kann. Dann kann das System alles damit machen und Gesichtsausdrücke an es übertragen. Es reicht aus, ihr ein passendes Video zu geben (mit einer anderen Person, deren Kopf sich ungefähr in derselben Position befindet).
Zuvor hatte AI bereits gelernt, wie man Diphakes macht, und Internetnutzer verspotteten Prominente, indem sie ihre Gesichter in Pornos einfügten und mit Nicholas Cage Memes machten. Dafür mussten sie die Algorithmen in Megabyte (oder besser - Gigabyte) Daten trainieren, um so viele Bilder und Videos mit Promi-Gesichtern wie möglich zu finden, um ein mehr oder weniger anständiges Ergebnis zu erzielen. Der Schöpfer von Deepfakes selbst sagte, dass es 8-12 Stunden dauert, um ein kurzes Video zu kompilieren. Das neue System generiert das Ergebnis sofort und benötigt bei der Eingabe nur ein Bild.
Mit dem vorherigen System könnten wir die lebende Mona Lisa niemals betrachten, wir haben nur einen Winkel. Mit Benchmarking-Algorithmen wird dies nun möglich. Das Ideal wird nicht erreicht, aber etwas ist schon nah.

Moskauer Forscher nutzen auch ein generativ-kontroverses Netzwerk. Zwei Modelle des Algorithmus kämpfen gegeneinander. Jeder versucht, den Gegner zu täuschen und ihm zu beweisen, dass das von ihm erstellte Video echt ist. Auf diese Weise wird ein gewisses Maß an Realismus erreicht: Ein Bild eines menschlichen Gesichts wird nicht „ins Licht“ gerückt, wenn das Kritikermodell nicht mehr als 90% seiner Echtheit sicher ist. Wie die Autoren in ihrer Arbeit sagen, werden zig Millionen Parameter in den Bildern reguliert, aber aufgrund eines solchen Systems kocht die Arbeit sehr schnell.

Wenn mehrere Bilder vorhanden sind, verbessert sich das Ergebnis. Auch hier ist es am einfachsten, mit Prominenten zu arbeiten, die bereits aus allen möglichen Blickwinkeln aufgenommen wurden. Um einen „idealen Realismus“ zu erreichen, werden 32 Aufnahmen benötigt. In diesem Fall sind die erzeugten KI-Fotos in niedriger Auflösung nicht von echten menschlichen Fotos zu unterscheiden. Ungeschulte Menschen sind zu diesem Zeitpunkt nicht mehr in der Lage, eine Fälschung zu identifizieren - vielleicht bleiben die Chancen bei Experten oder nahen Verwandten des „Experimentellen“ aus all diesen Bildern bestehen.
Wenn es nur ein Foto oder Bild gibt, ist das Ergebnis nicht immer das beste. Sie können Artefakte im Video sehen, wenn der Kopf ohne Probleme in Bewegung ist. Die Forscher selbst sagen, dass ihr schwächster Punkt der Blick ist. Das Modell, das auf den Orientierungspunkten des Gesichts basiert, versteht noch nicht immer, wie und wo eine Person aussehen sollte.
