Wir alle wissen, wie ein Hash aussieht, aber haben Sie sich jemals gefragt, wie oft ein bestimmter Charakter in einem Hash gefunden wird? Fragte ich mich. Und ich beschloss zu überprüfen. Skizzierte ein Python-Skript zum Zählen, und hier ist, was daraus wurde.
Zuerst habe ich eine zufällige Zeichenfolge generiert (Länge von 0 bis 1000).
def random_string(from_int, to_int): return str(''.join(random.SystemRandom().choice(string.ascii_letters + string.digits + string.punctuation) for _ in range(random.randint(from_int, to_int))))
Als nächstes nahm ich den MD5-Hash aus der Zeichenfolge.
def md5_from_string(string): return hashlib.md5(string.encode('utf-8')).hexdigest()
Nachher - Ich habe berechnet, wie viele Ziffern von 0 bis 9 im Hash sind. Bei einer Stichprobe von 1000 Hashes erhielt ich folgende Daten:
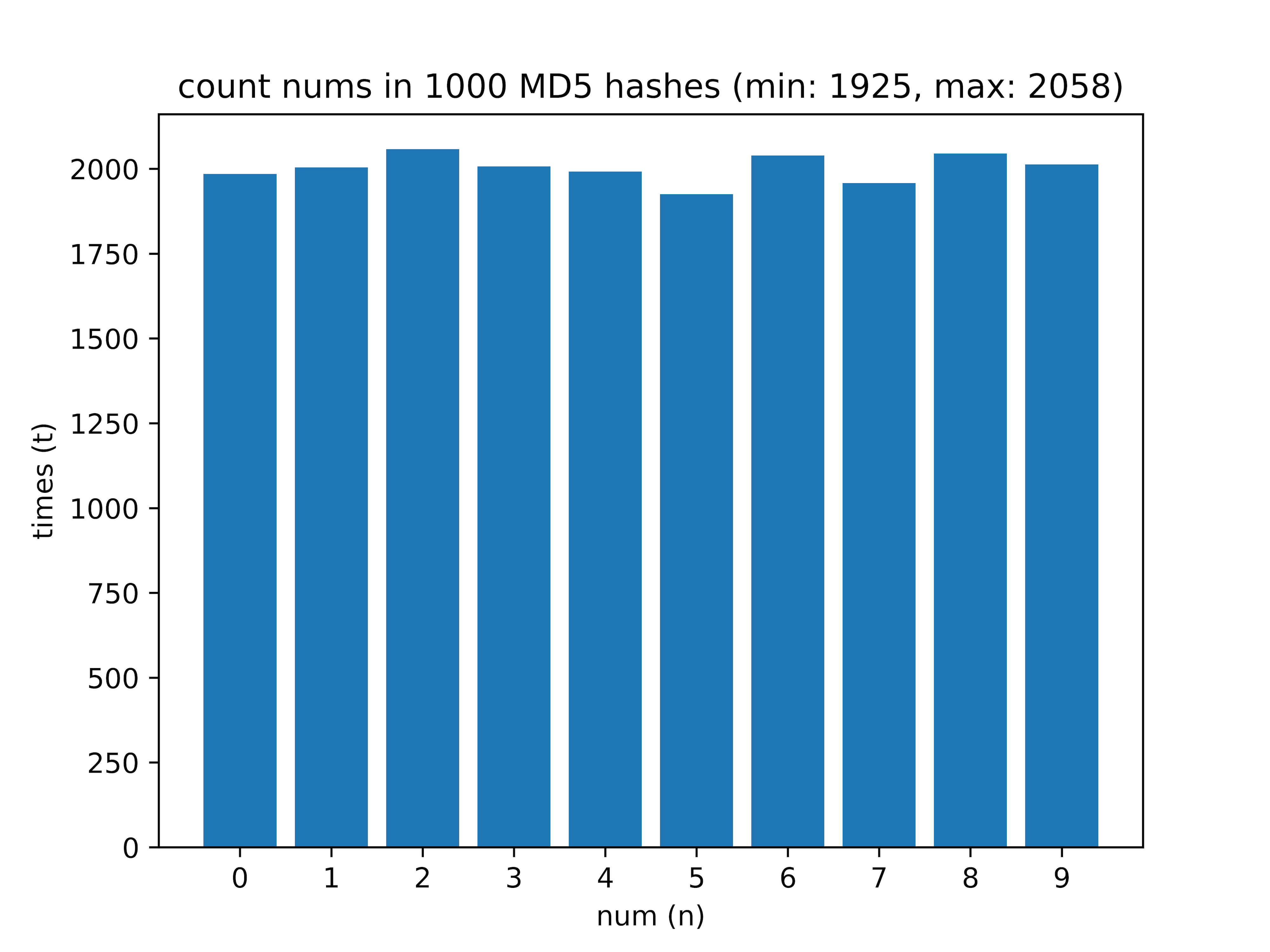
Hier ist der Unterschied zwischen der am häufigsten vorkommenden Ziffer und der seltensten (Delta-Wert) interessant.

Um die Änderung des Delta-Werts zu verfolgen, machte er Proben von 10.000, 100.000, 1.000.000, 10.000.000 Hashes.

Das Folgende ist eine Liste mit den Werten der minimalen und maximalen Anzahl und dem Delta-Wert für Proben mit unterschiedlicher Anzahl von MD5-Hashes:
- 100 - min: 179, max: 230, Delta: 22,17%
- 1000 - min: 1925, max: 2058, Delta: 6,46%
- 10000 - min: 19769, max: 20251, Delta: 2,38%
- 100000 - min: 199297, max: 200846, Delta: 0,77%
- 1.000.000 - min: 1997650, max: 2001690, Delta: 0,20%
- 10000000 - min: 19991830, max: 20004818, Delta: 0,06%
Was wir haben: Mit zunehmender Anzahl von Hashes im Array nimmt der Delta-Wert ab und jede Ziffer mit fast der gleichen Wahrscheinlichkeit fällt in das Array. Je größer die Stichprobe ist, desto geringer ist der Unterschied zwischen häufig vorkommenden und selten gesehenen Zahlen. Dementsprechend tendiert die Wahrscheinlichkeit, eine bestimmte Ziffer in einem Hash zu erhalten, zur Gleichförmigkeit.
Diese Informationen bildeten die Grundlage für den Algorithmus, den wir auf der Wettbewerbsplattform
bepeam.com implementiert haben