Vor ungefähr einem Jahr wurde mir eine ziemlich ernste Aufgabe gestellt: In einem zweistündigen Vortrag für Manager die Geschichte von Agile und DevOps zu halten.
So begann meine Rückkehr von der Softskill-Ebene des Agile-Trainings zur IT. Und laut Veranstalter haben über 1000 Produktmanager diese Vorlesung durchlaufen, von denen ungefähr 48/50 zum ersten Mal in meiner Klasse das Wort „Load Balancer“ hörten.
Ich habe sogar eine Comic-Gottheit bekommen: "Ein großartiger Balancer, ein Meister der Updates ohne Ausfallzeiten, billig zu implementierende A / B-Tests ohne Programmierung und im Allgemeinen eine gute Nachtruhe eines Managers."
Natürlich können Kollegen aus der IT über diese Vereinfachung lachen und sich sogar darüber empören, dass sich die Welt nicht auf das Wort "Balancer" geeinigt hat und wie viel Aufmerksamkeit darauf verwendet werden kann.
Aber als in meinem Fitnessstudio 48 von 50 Menschen nichts von dem Phänomen des Lastausgleichs hörten, ist es ein wenig traurig. Ja, und die Entwickler der Backends einiger mobiler Anwendungen können selbst große Banken durch das Fehlen solcher Systeme sündigen.
Meine Lieblingsbank in Gelb aktualisiert beispielsweise den Backend-Server einer mobilen Anwendung etwa zweimal pro Woche um 5 Uhr morgens in Moskau. Warum weiß ich das? Denn in Nowosibirsk, wo ich 2016 für ein Jahr zurückkehrte, war es zu diesem Zeitpunkt bereits 9 Uhr morgens, und der Fehler 000 tauchte für mich auf. Es ist schrecklich, sich vorzustellen, dass dies bereits ein Mittagessen für Fernost ist.
Vielleicht haben wir die Chance, diese Welt ein wenig besser zu machen, wenn Manager zum Zeitpunkt der Budgetierung der Serverkapazitäten über Fehlertoleranz nachdenken und es nicht für alles einen Server gibt, sondern ein wirklich angemessenes Maß an Risiko und Systemlastkonfiguration.
Warum?
Die allererste Frage, die sich bei der Festlegung einer Aufgabe stellt, ist natürlich: Warum?
Es gibt einen solchen Rahmen:Warum brauchen wir es? | Warum brauchen sie es?
Warum brauchen wir es?
Wenn wir uns vorstellen, dass „wir“ viele IT-Mitarbeiter sind, nicht nur Entwickler und verwandte Spezialisten, sondern auch Technologieberater, HR- und Agile-Coaches, die täglich mit Managern in Kontakt stehen, die keinen IT-Hintergrund haben.
Für mich selbst habe ich die erste Frage ganz einfach beantwortet: Die Verbesserung der technischen Kenntnisse von Managern verringert die Wahrscheinlichkeit unzureichender Aufgaben erheblich und erhöht die Zufriedenheit der Entwickler.
Warum brauchen sie es?
Warum wissen Manager, die wirklich weit von der IT entfernt sind, davon?Wir sind alle Menschen und wollen alle friedlich schlafen. Manager übernehmen oft Verantwortung für etwas, das sie nicht wirklich beeinflussen können. Das Stressniveau ist in diesem Fall vergleichbar mit den Passagieren des Flugzeugs, die an Aerophobie leiden.
Und dies ist wahrscheinlich das einzige Argument, das nicht wie Snobismus sein wird: "Wie kann man solche offensichtlichen Dinge nicht wissen?" Oder "Jede Person muss nachts mit verbundenen Augen ein unbestimmtes Integral verbinden". Nach meiner Erfahrung, wenn eine Person "bis zum Ellbogen in der Konsole" ist, dann sogar unbewusst, aber er kann oft mit solchen Stempeln arbeiten.
Wie kann ich die komplexen einfachen Bilder erklären?
Die folgenden Abbildungen erheben keinen Anspruch auf absolute Wahrheit und haben keinen unabhängigen Wert, zumal diese Vereinfachungen beim Erstellen fehlertoleranter Architekturen nicht als Leitfaden für Maßnahmen verwendet werden sollten, da ich nicht beabsichtigte, dort verschiedene subtile Punkte wie das Caching zu zeichnen. Dies ist nur ein vereinfachtes Modell.
In der Erwachsenenbildung und bei der Aufnahme neuer Informationen in das Lernen ist es wichtig zu verstehen, dass Informationen mindestens dreimal wiederholt werden müssen, um die Wahrscheinlichkeit zu erhöhen, dass sie tatsächlich erfasst werden.
Zum Beispiel wird ein solches Schema höchstwahrscheinlich mit dem Mem "Versuchen Sie nicht, Omsk zu verlassen" verknüpft und bestätigen Sie nur die Person in dem Gedanken, dass "alles kompliziert ist, aber sie auch viele Server wollen".
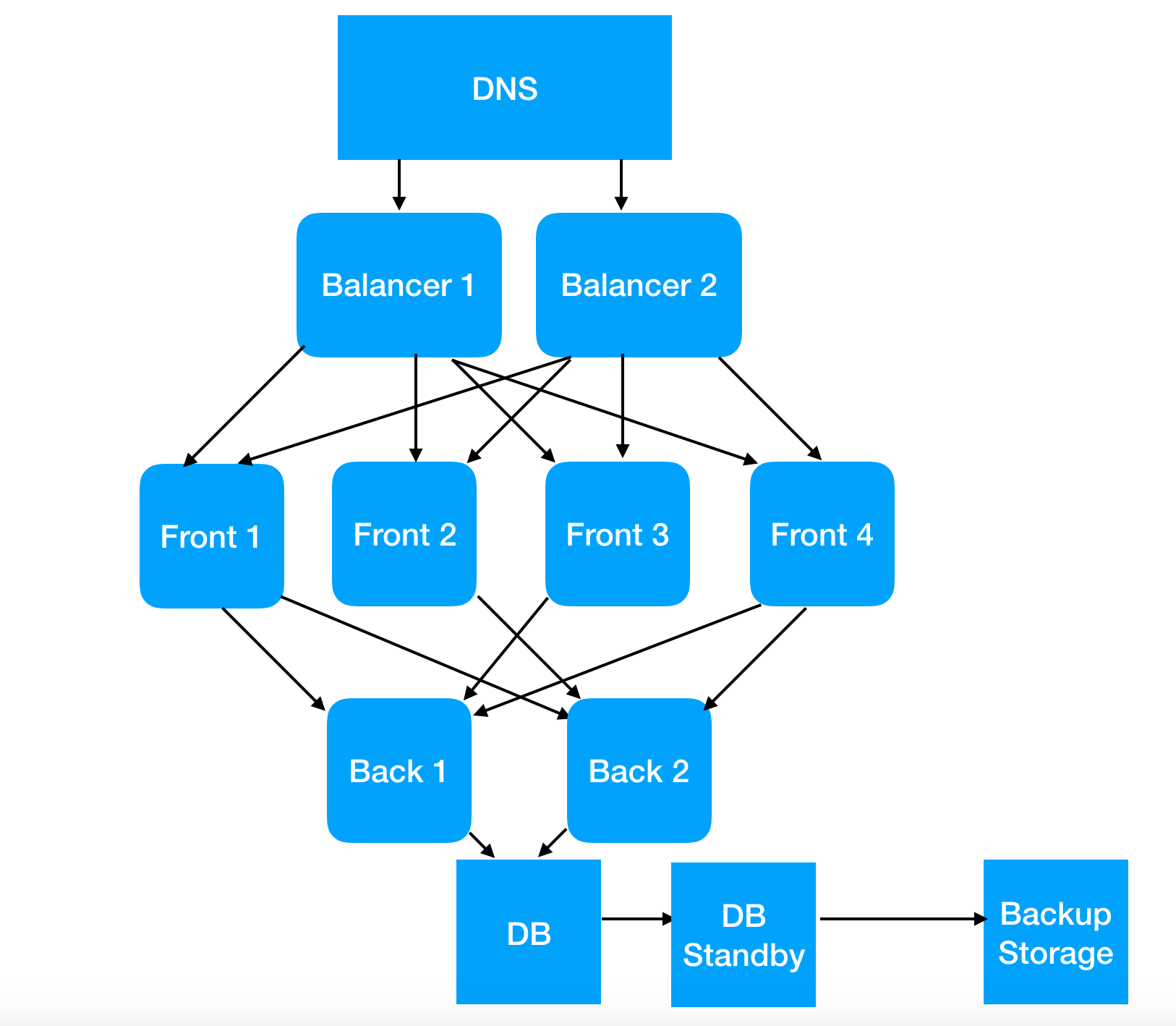
Dieses zunächst gezeigte Schema kann jedoch dazu führen, dass eine Person das Wort "Balancer" mit dem Phänomen des Lastausgleichs auf dem Server in Verbindung bringt. Ohne Garantie für ein korrektes Verständnis dieses Prozesses, aber mit dem sicheren Wissen, dass er existiert und warum er benötigt wird.
Lassen Sie uns ein paar Punkte des
Agilen Manifests an dieser Stelle verderben und sagen: "Das heißt, ohne den Wert dessen, was rechts ist, zu mindern, schätzen wir mehr auf das, was links ist."
Zum Beispiel, weil Sie mit diesem Schema verstehen können, wie Sie das A / B-Testsystem konfigurieren, ohne Tonnen von Quellcode zu schreiben, und wie Sie den Server aktualisieren, ohne vorher Mut zu haben (gegenüber dem Manager, nicht gegenüber dem Administrator).
Was weiter?
Und genau dieses Verständnis eröffnet dem Manager den Weg in die schöne Welt von CI / CD, denn wenn wir bereits wissen, wie viel Arbeit erforderlich ist, um die Infrastruktur teilweise fehlertolerant zu machen, haben wir weniger Angst vor häufigen Veröffentlichungen. Dies ändert grundlegend den Ansatz zur Aktualisierung von Richtlinien im Allgemeinen.
Nun, ich kann Ihnen nicht sagen, dass kleinere Änderungen bei 1/10 der Kapazität liegen (selbst wenn es sich um 1 von 3 Servern handelt, aber nur 10% des Datenverkehrs dafür bereitgestellt werden). Dies ist ein starker Rückgang der Leidenschaften während des Upgrades. Auch wenn die Server die Verarbeitung jeder 10. Anfrage vollständig einstellen.
Wir hatten einmal einen Rückgang von 20% bei RPS 600 und es wurde schnell beseitigt, es scheint sogar ohne die Beteiligung von Menschen. Zu diesem Zeitpunkt begann ich als technischer Premierminister, der für alle Backends der Richtung verantwortlich war, praktisch, das Wort „Balancer“ gegenüber anderen Managern zu wiederholen.
Wie meine Erfahrung zeigt, ist dieses Wissen äußerst nützlich, damit Manager verstehen, wie sie die Risiken aus der Veröffentlichung minimieren und sich für CI / CD und verschiedene technologische Experimente interessieren können.
Vor ungefähr 4 Jahren erzählte ungefähr die gleiche Geschichte in meiner Praxis Entwicklern von GitFlow-ähnlichen „Brunching“ -Systemen, um Releases und Moratorien für Commits in der Release-Branche zu stabilisieren, die auf Hook-Ebene unterstützt werden. In letzter Zeit ist sie jedoch immer weniger geworden und weniger erforderlich.
Meiner Meinung nach ist es jetzt wirklich wichtig, die technische Kompetenz nichttechnischer Manager zu verbessern. Natürlich nicht unbedingt so.