Hallo!
Mein Name ist Marat Gayanov. Ich möchte Ihnen meine Lösung für das Problem aus dem
Best Reverser-Wettbewerb mitteilen , um zu zeigen, wie Sie Keygen für diesen Fall
erstellen können.
Beschreibung
In diesem Wettbewerb erhalten die Teilnehmer ROM-Spiele für Sega Mega Drive (
best_reverser_phd9_rom_v4.bin ).
Aufgabe: einen solchen Schlüssel abholen, der zusammen mit der E-Mail-Adresse des Teilnehmers als gültig anerkannt wird.
Also die Lösung ...
Die Werkzeuge
Schlüssellänge prüfen
Das Programm akzeptiert nicht jeden Schlüssel: Sie müssen das gesamte Feld ausfüllen, dies sind 16 Zeichen. Wenn der Schlüssel kürzer ist, wird eine Meldung angezeigt: „Falsche Länge! Versuchen Sie es erneut ... ".
Versuchen wir, diese Zeile im Programm zu finden, für die wir die binäre Suche (Alt-B) verwenden. Was werden wir finden?
Wir finden nicht nur das, sondern auch die anderen Serviceleitungen in der Nähe: „Falscher Schlüssel! Versuchen Sie es erneut ... “und„ SIE SIND DER BESTE UMKEHRER! “.
Ich
WRONG_LENGTH_MSG YOU_ARE_THE_BEST_MSG WRONG_KEY_MSG WRONG_LENGTH_MSG ,
YOU_ARE_THE_BEST_MSG und
WRONG_KEY_MSG .
0x0000FDFA Sie eine Pause beim Lesen der Adresse
0x0000FDFA - finden Sie heraus, wer mit der Meldung "Falsche Länge! Versuchen Sie es erneut ... ". Führen Sie den Debugger aus (er stoppt mehrmals, bevor die Taste eingegeben werden kann. Drücken Sie bei jedem Stopp einfach F9). Geben Sie Ihre E-Mail-
ABCD geben Sie
ABCD .
Der Debugger führt zu
0x00006FF0 tst.b (a1)+ :
Es gibt nichts Interessantes im Block selbst. Es ist viel interessanter, wer hier die Kontrolle überträgt. Wir schauen uns den Call Stack an:
Klicken Sie und kommen Sie hierher - zur Anweisung
0x00001D2A jsr (sub_6FC0).l :
Wir sehen, dass alle möglichen Nachrichten an einem Ort gefunden wurden. Lassen Sie uns jedoch herausfinden, wohin die Steuerung im Block
WRONG_KEY_LEN_CASE_1D1C wird. Wir werden keine Pausen setzen, bewegen Sie einfach den Cursor über den Pfeil zum Block. Der Anrufer befindet sich unter
0x000017DE loc_17DE (die ich in
CHECK_KEY_LEN umbenennen
CHECK_KEY_LEN ):
Setzen Sie eine Pause auf die Adresse
0x000017EC cmpi.b 0x20 (a0, d0.l) (die Anweisung in diesem Kontext
0x000017EC cmpi.b 0x20 (a0, d0.l) , ob am Ende des Schlüsselzeichenarrays ein leeres Zeichen steht), starten Sie neu, geben Sie die E-Mail und den
ABCD Schlüssel erneut ein. Der Debugger stoppt und zeigt an, dass sich der eingegebene Schlüssel unter der Adresse
0x00FF01C7 (zu diesem Zeitpunkt in Register
a0 gespeichert):
Dies ist ein guter Fund, dadurch werden wir überhaupt alles packen. Markieren Sie jedoch zunächst die Bytes des Schlüssels, um die Benutzerfreundlichkeit zu verbessern:
Wenn wir von diesem Ort aus nach oben scrollen, sehen wir, dass die Mail neben dem Schlüssel gespeichert ist:
Wir tauchen immer tiefer und es ist Zeit, ein Kriterium für die Richtigkeit des Schlüssels zu finden. Eher die erste Hälfte des Schlüssels.
Das Korrektheitskriterium für die erste Hälfte des Schlüssels
Vorberechnungen
Es ist logisch anzunehmen, dass unmittelbar nach dem Überprüfen der Länge andere Operationen mit dem Schlüssel folgen. Betrachten Sie den Block unmittelbar nach der Prüfung:
Dieser Block befindet sich in der Vorarbeit. Die Funktion
get_hash_2b (im Original war
sub_1526 ) wird zweimal aufgerufen. Zuerst wird die Adresse des ersten Bytes des Schlüssels an ihn übertragen (Register
a0 enthält die Adresse
KEY_BYTE_0 ), das zweite Mal - das fünfte Mal (
KEY_BYTE_4 ).
Ich habe die Funktion so benannt, weil sie so etwas wie einen 2-Byte-Hash berücksichtigt. Dies ist der verständlichste Name, den ich aufgegriffen habe.
Ich werde die Funktion selbst nicht betrachten, aber ich werde sie sofort in Python schreiben. Sie macht einfache Dinge, aber ihre Beschreibung mit Screenshots wird viel Platz beanspruchen.
Das Wichtigste dazu: Die Eingabeadresse wird an den Eingang geliefert, und 4 Bytes von dieser Adresse werden bearbeitet. Das heißt, das erste Byte des Schlüssels wurde eingegeben, und die Funktion funktioniert mit dem 1,2,3,4. Als fünfte Datei arbeitet die Funktion mit der 5,6,7,8. Mit anderen Worten, in diesem Block gibt es Berechnungen über die erste Hälfte des Schlüssels. Das Ergebnis wird in das Register
d0 .
Also die Funktion
get_hash_2b :
Schreiben Sie sofort eine Hash-Dekodierungsfunktion:
Ich habe mir keine bessere Dekodierungsfunktion ausgedacht und sie ist nicht ganz richtig. Deshalb werde ich es so überprüfen (nicht jetzt, aber viel später):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
Überprüfen Sie die Funktion von
get_hash_2b . Wir interessieren uns für den Zustand des Registers
d0 nach Ausführung der Funktion. Wir
0x000017FE Pausen auf
0x000017FE ,
0x00001808 , den Schlüssel, den wir in
ABCDEFGHIJKLMNOP .
Die Werte
0xABCD ,
0xEF01 werden in das Register
d0 eingetragen. Und was wird
get_hash_2b geben?
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
Überprüfung bestanden.
Dann wird
xor eor.w d0, d5 erzeugt, das Ergebnis wird in
d5 eingegeben:
>>> hex(0xabcd ^ 0xef01) 0x44cc
Das Erhalten eines solchen
0x44CC ist
0x44CC und besteht aus vorläufigen Berechnungen. Außerdem wird alles nur noch komplizierter.
Wohin geht der Hash?
Wir können nicht weiter gehen, wenn wir nicht wissen, wie das Programm mit dem Hash funktioniert. Sicherlich bewegt es sich von
d5 in den Speicher, weil Das Register ist woanders nützlich. Wir können ein solches Ereignis über den Trace finden (
d5 beobachten), aber nicht manuell, sondern automatisch. Das folgende Skript hilft:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
Ich
0x00001808 eor.w d0, d5 erinnern, dass wir uns jetzt in der letzten Pause befinden.
0x00001808 eor.w d0, d5 . Fügen Sie das Skript ein (
Shift-F2 ) und klicken Sie auf
RunDas Skript stoppt bei der Anweisung
0x00001C94 move.b (a0, a1.l), d5 , aber zu diesem Zeitpunkt wurde
d5 bereits gelöscht. Wir sehen jedoch, dass der Wert von
d5 durch den Befehl
0x00001C56 move.w d5,a6 : Er wird unter der Adresse
0x00FF0D46 (2 Bytes) in den Speicher geschrieben.
Denken Sie daran: Der Hash wird bei 0x00FF0D46 gespeichert.Wir fangen die Anweisungen ab, die von
0x00FF0D46-0x00FF0D47 gelesen
0x00FF0D46-0x00FF0D47 (wir setzen eine
0x00FF0D46-0x00FF0D47 ). 4 Blöcke gefangen:




Wie wählt man die richtigen / richtigen aus?
Gehen Sie zurück zum Anfang:
Dieser Block bestimmt, ob das Programm zu
LOSER_CASE oder zu
WINNER_CASE :
Wir sehen, dass im Register
d1 Null sein muss, um zu gewinnen.
Wo ist Null gesetzt? Scrollen Sie einfach nach oben:
Wenn die
loc_1EEC im Block
loc_1EEC erfüllt ist:
*(a6 + 0x24) == *(a6 + 0x22)
dann bekommen wir null in
d5 .
Wenn wir den Befehl
0x00001F16 beq.w loc_20EA , sehen wir, dass
a6 + 0x24 = 0x00FF0D6A und der Wert
0x4840 dort gespeichert ist. Und in
a6 + 0x22 = 0x00FF0D68 gespeichert.
Wenn wir verschiedene Schlüssel und Mails eingeben, sehen wir, dass
0xCB4C - .
Die erste Hälfte des Schlüssels wird nur akzeptiert, wenn in 0x00FF0D6A auch 0xCB4C . Dies ist das Kriterium für die Richtigkeit der ersten Hälfte des Schlüssels.Wir finden heraus, welche Blöcke in
0x00FF0D6A geschrieben
0x00FF0D6A - setzen Sie eine Pause in den Datensatz, geben Sie die Mail ein und geben Sie den Schlüssel erneut ein.
Und wir werden diesen
loc_EAC Block finden (es gibt tatsächlich 3 davon, aber die ersten beiden sind nur null aus
0x00FF0D6A ):
Dieser Block gehört zur Funktion
sub_E3E .
Durch den Aufrufstapel erfahren wir, dass die Funktion
sub_E3E in den Blöcken
loc_1F94 ,
loc_203E :
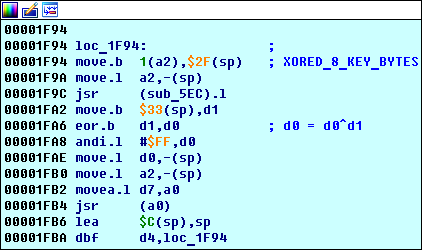

Erinnerst du dich, dass wir 4 Blocks früher gefunden haben?
loc_1F94 wir dort gesehen - dies ist der Beginn des Hauptschlüsselverarbeitungsalgorithmus.
Erste wichtige Schleife loc_1F94
Die Tatsache, dass
loc_1F94 ein Zyklus ist, ist aus dem Code ersichtlich: Er wird
d4 mal ausgeführt (siehe Anweisung
0x00001FBA d4,loc_1F94 ):
Worauf zu achten ist:
- Es gibt eine
sub_5EC Funktion. - Der Befehl 0x00001FB4 jsr (a0) ruft die Funktion sub_E3E auf (dies kann mit einer einfachen Ablaufverfolgung gesehen werden).
Was ist hier los:
- Die Funktion
sub_5EC schreibt das Ergebnis ihrer Ausführung in das Register d0 (ein separater Abschnitt ist diesem gewidmet). - Das Byte an der Adresse
sp+0x33 ( 0x00FFFF79 , sagt der Debugger) wird im Register d1 gespeichert und entspricht dem zweiten Byte der Schlüssel-Hash-Adresse ( 0x00FF0D47 ). Dies ist leicht zu beweisen, wenn Sie den Datensatz bei 0x00FFFF79 : Es funktioniert mit den Anweisungen 0x00001F94 move.b 1(a2), 0x2F(sp) . Das Register a2 speichert zu diesem Zeitpunkt die Adresse 0x00FF0D46 - die Hash-Adresse, 0x1(a2) = 0x00FF0D46 + 1 - die Adresse des zweiten Bytes des Hash. - Das Register
d0 ist geschrieben d0^d1 .
- Das resultierende xor'a-Ergebnis wird an die Funktion
sub_E3E , deren Verhalten von den vorherigen Berechnungen abhängt (siehe unten). - Wiederholen.
Wie oft läuft dieser Zyklus?
Finde das heraus. Führen Sie das folgende Skript aus:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4 - hier wird bestimmt, was in
d4 unmittelbar vor der Schleife passieren wird:
Wir beschäftigen uns mit der Funktion sub_5EC.
sub_5EC
Bedeutender Code:
Dabei ist
0x2c(a2) immer
0x00FF1D74 .
Dieses Stück kann wie folgt in Pseudocode umgeschrieben werden:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
Das heißt, 4 Bytes von
0x00FF1D74 sind die Adresse, weil Sie werden wie ein Zeiger behandelt.
Wie schreibe
sub_5EC die
sub_5EC Funktion in Python um?
- Oder machen Sie einen Speicherauszug und arbeiten Sie damit.
- Oder notieren Sie sich einfach alle zurückgegebenen Werte.
Die zweite Methode gefällt mir besser, aber was ist, wenn bei unterschiedlichen Berechtigungsdaten die zurückgegebenen Werte unterschiedlich sind? Überprüfen Sie dies heraus.
Das Skript hilft dabei:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
Ich habe gerade die Ausgänge mit der Konsole mit verschiedenen Schlüsseln, Mails verglichen.
Wenn Sie das Skript mehrmals mit verschiedenen Schlüsseln
sub_5EC , werden Sie
sub_5EC dass die Funktion
sub_5EC immer den nächsten Wert aus dem Array zurückgibt:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
sub_5EC ist also bereit.
sub_E3E folgt
sub_E3E .
sub_E3E
Bedeutender Code:
Entschlüsseln:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
Die Funktion
sub_E3E Schritten:
- Speichern Sie das Eingabeargument in einem Array.
- Berechnen Sie den Versatzversatz.
- Ziehen Sie 2 Bytes an der Adresse
0x00011FC0 + offset (ROM). - Ergebnis =
( >> 8) ^ (2 0x00011FC0 + offset) .
Stellen Sie sich die Funktion
sub_E3E in folgender Form vor:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0 ist nur eine Datei, in der ich 4096 Bytes von
[0x00011FC0:00011FC0+4096] .
Aktivität um 1FC4
Wir haben die Adresse
0x00001FC4 noch nicht gesehen, aber sie ist leicht zu finden, da der Block fast unmittelbar nach dem ersten Zyklus
0x00001FC4 .
Dieser Block ändert den Inhalt an der Adresse
0x00FF0D46 (Register
a2 ), und dort wird der Schlüssel-Hash gespeichert.
0x00FF0D46 wir jetzt diesen Block. Mal sehen, was hier passiert.
- Die Bedingung, die bestimmt, ob der linke oder der rechte Zweig ausgewählt ist, ist:
( ) & 0b1 != 0 . Das heißt, das erste Bit des Hash wird überprüft. - Wenn Sie sich beide Zweige ansehen, werden Sie sehen:
- In beiden Fällen tritt eine Verschiebung nach rechts um 1 Bit auf.
- Im linken Zweig wird die Hash-Operation
0x8000 . - In beiden Fällen wird der verarbeitete Hashwert in die Adresse
0x00FF0D46 geschrieben, 0x00FF0D46 der Hash wird durch einen neuen Wert ersetzt. - Weitere Berechnungen sind nicht kritisch, da es in
(a2) grob gesagt keine Schreiboperationen gibt (es gibt keine Anweisung, wo der zweite Operand (a2) ).
Stellen Sie sich einen Block wie diesen vor:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
Die zweite wichtige Schleife ist loc_203E
loc_203E - Schleife, weil
0x0000206C bne.s loc_203E .
Dieser Zyklus berechnet den Hash und hier ist sein Hauptmerkmal:
jsr (a0) ist ein Aufruf der Funktion
sub_E3E , die wir bereits untersucht haben - er stützt sich auf das vorherige Ergebnis seiner eigenen Arbeit und auf ein Eingabeargument (es wurde durch das Register
d2 oben und hier durch
d0 )
Lassen Sie uns herausfinden, was über das
d0 Register an sie weitergegeben wird.
Wir haben uns bereits mit der Konstruktion
0x34(a2) - die Funktion
sub_E3E speichert dort das übergebene Argument. Dies bedeutet, dass zuvor übergebene Argumente in dieser Schleife verwendet werden. Aber nicht alle.
Entschlüsseln Sie den Codeteil:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
Das
d0 ist eine einfache Aktion: Nehmen
d0 bei jeder Iteration
d0 gespeicherte Argument vom Ende des Arrays. Das heißt, wenn 4 in
d0 gespeichert
d0 , nehmen wir das vierte Element vom Ende.
Wenn ja, was genau braucht
d0 ? Hier habe ich auf Skripte verzichtet, sie aber einfach ausgeschrieben und am Anfang dieses Blocks eine Pause eingelegt. Hier sind sie:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .
Jetzt haben wir alles, um eine vollständige Schlüssel-Hash-Berechnungsfunktion zu schreiben.
Volle Hash-Berechnungsfunktion
def finish_hash(hash_2b):
Gesundheitscheck
- Im Debugger setzen wir eine Unterbrechung auf die Adresse
0x0000180A move.l 0x1000,(sp) (unmittelbar nach der Hash-Berechnung). 0x00001F16 beq.w loc_20EA Adresse 0x00001F16 beq.w loc_20EA (Vergleich des endgültigen Hash mit der Konstanten 0xCB4C ).Enter im Programm die Taste ABCDEFGHIJKLMNOP und drücken Sie die Enter .- Der Debugger stoppt bei
0x0000180A und wir sehen, dass 0x44CC d5 Register geschrieben wird, 0x44CC ist der erste Hash. - Wir starten den Debugger weiter.
- Wir halten bei
0x00001F16 und sehen, dass bei 0x00FF0D6A liegt - der letzte Hash
- Schauen Sie sich jetzt unsere Funktion finish_hash (hash_2b) an:
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
Wir suchen den richtigen Schlüssel 1
Der richtige Schlüssel ist dieser Schlüssel, dessen endgültiger Hash
0xCB4C (
0xCB4C oben). Daher die Frage: Was sollte der erste Hash sein, damit das Finale
0xCB4C ?
Jetzt ist es leicht herauszufinden:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
Die Ausgabe des Programms legt nahe, dass es nur eine Option gibt: Der erste Hash sollte
0xFEDC .
Welche Zeichen brauchen wir, damit ihr erster Hash
0xFEDC ?
Da
0xFEDC = __4_ ^ __4_ , müssen Sie nur den
__4_ , da der
__4_ = __4_ ^ 0xFEDC . Und dann beide Hashes dekodieren.
Der Algorithmus ist wie folgt:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Wählen Sie eine Reihe von Optionen aus.
Wir suchen den richtigen Schlüssel 2
Die erste Hälfte des Schlüssels ist fertig, was ist mit der zweiten?
Dies ist der einfachste Teil.
Der verantwortliche Code befindet sich unter
0x00FF2012 . Ich habe ihn durch manuelle Ablaufverfolgung erhalten, beginnend mit der Adresse
0x00001F16 beg.w loc_20EA (Validierung der ersten Hälfte des Schlüssels). Im Register ist
a0 die Mailadresse,
loc_FF2012 ist ein Zyklus, weil
bne.s loc_FF2012 . Es wird ausgeführt, solange
*(a0+d0) (das nächste
*(a0+d0) vorhanden ist.
Und der
jsr (a3) ruft die bereits bekannte Funktion
get_hash_2b , die jetzt mit der zweiten Hälfte des Schlüssels funktioniert.
Lassen Sie uns den Code klarer machen:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
Im Register
d2 -
( -1) << 8 . In
d3 die Summe der Bytes der E-Mail-Zeichen.
Das Korrektheitskriterium lautet wie folgt:
__ ^ d2 == ___2 ^ d3 .
Wir schreiben die Auswahlfunktion der zweiten Hälfte des Schlüssels:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Keygen
Mail muss eine Kapsel sein.
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
Vielen Dank für Ihre Aufmerksamkeit! Der gesamte Code ist
hier verfügbar.