Im „Black Mirror“ gab es eine Serie (S2E1), in der sie Roboter entwickelten, die toten Menschen ähnlich waren, wobei die Geschichte der Korrespondenz in sozialen Netzwerken für das Training verwendet wurde. Ich möchte Ihnen sagen, wie ich versucht habe, etwas Ähnliches zu tun, und was daraus entstanden ist. Es wird keine Theorie geben, nur Praxis.

Die Idee war einfach: Die Geschichte ihrer Chats aus dem Telegramm zu entnehmen und auf ihrer Grundlage das seq2seq-Netzwerk zu trainieren, das in der Lage ist, den Abschluss zu Beginn des Dialogs vorherzusagen. Ein solches Netzwerk kann in drei Modi betrieben werden:
- Prognostizieren Sie die Vervollständigung der Benutzerphrasen basierend auf dem Konversationsverlauf
- Arbeiten Sie im Chatbot-Modus
- Synthetisieren Sie ganze Konversationsprotokolle
Das habe ich bekommen
Bot bietet Phrasenvervollständigung
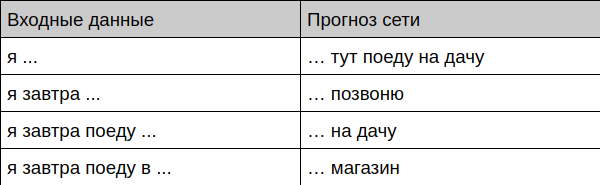
Bot bietet Abschluss des Dialogs
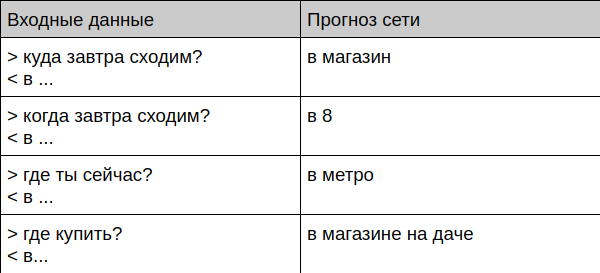
Bot kommuniziert mit einer lebenden Person
User: Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot:
Als nächstes werde ich Ihnen sagen, wie Sie die Daten vorbereiten und einen solchen Bot selbst trainieren können.
Wie man sich selbst beibringt
Datenaufbereitung
Zuallererst müssen Sie irgendwo viele Chats bekommen. Ich habe meine gesamte Korrespondenz in Telegramm aufgenommen, da der Client für den Desktop das Herunterladen des vollständigen Archivs im JSON-Format ermöglicht. Dann habe ich alle Nachrichten, die Anführungszeichen, Links und Dateien enthalten, weggeworfen, die verbleibenden Texte in Kleinbuchstaben übertragen und alle seltenen Zeichen von dort weggeworfen, wobei nur ein einfacher Satz von Buchstaben, Zahlen und Satzzeichen übrig blieb - es ist einfacher, das Netzwerk zu lernen.
Dann habe ich die Chats in diese Form gebracht:
=== > < > < ! === > ? <
Hier sind Nachrichten, die mit dem Symbol ">" beginnen, eine Frage für mich, das Symbol "<" markiert meine Antwort entsprechend und die Zeile "===" dient dazu, die Dialoge untereinander zu trennen. Die Tatsache, dass ein Dialog endete und der andere begann, wurde durch die Zeit bestimmt (wenn zwischen den Nachrichten mehr als 15 Minuten vergangen sind, denken wir, dass dies eine neue Konversation ist. Sie können das Skript zum Konvertieren der Geschichte auf Github sehen .
Da ich Telegramme schon lange aktiv benutze, gab es am Ende viele Nachrichten - die endgültige Datei enthielt 443.000 Zeilen.
Modellauswahl
Ich habe versprochen, dass es heute keine Theorie geben wird, deshalb werde ich versuchen, dies so kurz wie möglich an meinen Fingern zu erklären.
Ich habe mich für den klassischen seq2seq entschieden, der auf GRU basiert. Ein solches Eingabemodell empfängt den Text Buchstabe für Buchstabe und gibt auch jeweils einen Buchstaben aus. Der Lernprozess basiert auf der Tatsache, dass wir dem Netzwerk beibringen, den letzten Buchstaben des Textes vorherzusagen. Beispielsweise geben wir der Eingabe „Blei“ und warten, bis „Niet“ ausgegeben wird.
Um lange Texte zu generieren, wird ein einfacher Trick verwendet - das Ergebnis der vorherigen Vorhersage wird an das Netzwerk zurückgesendet usw., bis die erforderliche Textlänge generiert ist.
GRU-Module können als "gerissenes Perzeptron mit Gedächtnis und Aufmerksamkeit" sehr, sehr vereinfacht werden. Weitere Details dazu finden Sie beispielsweise hier .
Als Grundlage des Modells wurde ein bekanntes Beispiel für die Aufgabe der Erstellung von Shakespeares Texten gewählt.
Schulung
Jeder, der jemals auf neuronale Netze gestoßen ist, weiß wahrscheinlich, dass es sehr langweilig ist, sie auf der CPU zu lernen. Glücklicherweise hilft Google mit seinem Colab- Dienst - darin können Sie Ihren Code kostenlos in einem Jupyter-Notebook mit einer CPU, einer GPU und sogar einer TPU ausführen. In meinem Fall dauert das Training auf der Grafikkarte 30 Minuten, obwohl nach 10 Minuten vernünftige Ergebnisse vorliegen. Die Hauptsache ist, den Hardwaretyp zu wechseln (im Menü Laufzeit -> Laufzeittyp ändern).
Testen
Nach dem Training können Sie mit der Modellüberprüfung fortfahren. Ich habe mehrere Beispiele geschrieben, mit denen Sie in verschiedenen Modi auf das Modell zugreifen können - von der Texterstellung bis zum Live-Chat. Alle von ihnen sind auf Github .
Die Methode zum Generieren von Text hat einen Temperaturparameter - je höher dieser ist, desto vielfältiger wird der Text (und bedeutungslos) einen Bot erzeugen. Dieser Parameter ist sinnvoll, um Hände für eine bestimmte Aufgabe zu konfigurieren.
Weitere Verwendung
Warum kann ein solches Netzwerk verwendet werden? Am naheliegendsten ist es, einen Bot (oder eine intelligente Tastatur) zu entwickeln, der dem Benutzer vorgefertigte Antworten bietet, noch bevor er sie schreibt. Eine ähnliche Funktion gibt es in Google Mail und den meisten Tastaturen seit langem, sie berücksichtigt jedoch nicht den Kontext der Konversation und die Art und Weise, wie ein bestimmter Benutzer Korrespondenz führt. Sagen wir, die G-Tastatur bietet mir stabil völlig bedeutungslose Optionen, zum Beispiel "Ich gehe mit ... Respekt" an der Stelle, an der ich die Option "Ich gehe von der Datscha" erhalten möchte, die ich definitiv oft verwendet habe.
Hat der Chat-Bot eine Zukunft? In seiner reinen Form ist es definitiv nicht da, es hat zu viele persönliche Daten, niemand weiß, an welchem Punkt es dem Gesprächspartner die Nummer Ihrer Kreditkarte geben wird, die Sie einmal an einen Freund geworfen haben. Darüber hinaus ist ein solcher Bot überhaupt nicht abgestimmt, es ist sehr schwierig, ihn dazu zu bringen, bestimmte Aufgaben auszuführen oder eine bestimmte Frage richtig zu beantworten. Vielmehr könnte ein solcher Chatbot in Verbindung mit anderen Arten von Bots funktionieren und einen vernetzten Dialog "über nichts" bieten - er kommt damit gut zurecht. (Und doch sagte ein externer Experte in der Person seiner Frau, dass der Kommunikationsstil des Bots mir sehr ähnlich ist. Und die Themen, die ihn interessieren, sind eindeutig dieselben - Fehler, Korrekturen, Commits und andere Freuden und Sorgen des Entwicklers tauchen ständig in den Texten auf.)
Was raten Sie noch zu versuchen, wenn dieses Thema für Sie interessant ist?
- Übertragen Sie das Lernen (um eine große Anzahl von Dialogen anderer Menschen zu trainieren und dann selbstständig zu beenden)
- Modell ändern - erhöhen, Typ ändern (z. B. bei LSTM).
- Versuchen Sie, mit TPU zu arbeiten. In seiner reinen Form funktioniert dieses Modell nicht, kann aber angepasst werden. Die theoretische Beschleunigung des Lernens sollte das Zehnfache betragen.
- Portieren Sie auf eine mobile Plattform, z. B. mit Tensorflow Mobile.
PS Link zum Github