Ein anderer Benutzer möchte ein neues Datenelement auf die Festplatte schreiben, hat jedoch nicht genügend freien Speicherplatz dafür. Ich möchte auch nichts löschen, da "alles sehr wichtig und notwendig ist". Und was sollen wir damit machen?
Er hat kein solches Problem. Terabyte an Informationen befinden sich auf unseren Festplatten, und diese Menge nimmt tendenziell nicht ab. Aber wie einzigartig ist es? Am Ende sind schließlich alle Dateien nur Sätze von Bits einer bestimmten Länge, und höchstwahrscheinlich unterscheidet sich die neue nicht wesentlich von der bereits gespeicherten.
Es ist klar, dass die Suche nach bereits gespeicherten Informationen auf der Festplatte eine Aufgabe ist, wenn nicht ein Fehler, dann zumindest keine effektive. Auf der anderen Seite, denn wenn der Unterschied gering ist, können Sie ein wenig passen ...

TL; DR - der zweite Versuch, über eine seltsame Methode zur Optimierung von Daten mithilfe von JPEG-Dateien zu sprechen, die jetzt verständlicher ist.
Über Bits und Unterschiede
Wenn wir zwei völlig zufällige Daten nehmen, fällt durchschnittlich die Hälfte der enthaltenen Bits in ihnen zusammen. In der Tat ist unter den möglichen Layouts für jedes Paar ('00, 01, 10, 11 ') genau die Hälfte die gleichen Werte, hier ist alles einfach.
Aber wenn wir nur zwei Dateien nehmen und eine unter die zweite passen, verlieren wir natürlich eine davon. Wenn wir die Änderungen beibehalten, werden wir einfach die Delta-Codierung neu erfinden, die auch ohne uns perfekt existiert, obwohl sie normalerweise nicht für den gleichen Zweck verwendet wird. Sie können versuchen, eine kleinere Sequenz in eine größere einzubetten. Trotzdem besteht die Gefahr, dass kritische Datensegmente verloren gehen, wenn sie vorschnell mit allem verwendet werden.
Zwischen was und was kann dann der Unterschied beseitigt werden? Das heißt, eine neue Datei, die vom Benutzer aufgezeichnet wurde, ist nur eine Folge von Bits, mit denen wir selbst nichts tun können. Dann müssen Sie nur noch solche Bits auf der Festplatte finden, damit sie geändert werden können, ohne den Unterschied speichern zu müssen, damit Sie ihren Verlust ohne schwerwiegende Konsequenzen überleben können. Ja, und es ist sinnvoll, nicht nur die Datei selbst auf dem FS zu ändern, sondern auch einige weniger vertrauliche Informationen darin. Aber welches und wie?
Anpassungsmethoden
Verlustbehaftete komprimierte Dateien helfen. Alle diese JPEG-, MP3- und anderen Dateien enthalten eine Reihe von Bits, die für eine sichere Änderung verfügbar sind, obwohl sie eine verlustbehaftete Komprimierung darstellen. Sie können fortschrittliche Techniken verwenden und deren Komponenten in verschiedenen Codierungsbereichen diskret ändern. Warte einen Moment. Fortgeschrittene Techniken ... unauffällige Modifikation ... einige Kleinigkeiten zu anderen ... ja, es ist fast Steganographie !
In der Tat ähnelt das Einbetten einer Information in eine andere ihren Methoden, egal was passiert. Es beeindruckt auch die Unsichtbarkeit der Veränderungen, die an den menschlichen Sinnen vorgenommen wurden. Hier gehen die Pfade auseinander - es ist ein Geheimnis: Unsere Aufgabe ist es, der Festplatte des Benutzers zusätzliche Informationen hinzuzufügen, die ihm nur schaden. Vergiss mehr.
Obwohl wir sie verwenden können, müssen wir daher einige Änderungen vornehmen. Und dann werde ich sie am Beispiel einer der vorhandenen Methoden und des gemeinsamen Dateiformats erzählen und zeigen.
Über die Schakale
Wenn Sie komprimieren, dann das komprimierbarste der Welt. Wir sprechen natürlich über JPEG-Dateien. Es gibt nicht nur eine Vielzahl von Tools und vorhandenen Methoden zum Einbetten von Daten, es ist auch das beliebteste Grafikformat auf diesem Planeten.

Um jedoch keine Hundezucht zu betreiben, müssen Sie Ihr Tätigkeitsfeld in Dateien dieses Formats einschränken. Niemand mag monochrome Quadrate, die durch übermäßige Komprimierung entstehen. Sie müssen sich daher darauf beschränken, mit einer bereits komprimierten Datei zu arbeiten, um eine Transcodierung zu vermeiden . Insbesondere mit ganzzahligen Koeffizienten, die nach den für den Datenverlust verantwortlichen Operationen verbleiben - DCT und Quantisierung, die im Codierungsschema perfekt angezeigt werden (dank des Wikis der Bauman-Nationalbibliothek):

Es gibt viele mögliche Optimierungsmethoden für JPEG-Dateien. Es gibt eine verlustfreie Optimierung (jpegtran), es gibt eine verlustfreie Optimierung, die zwar immer noch dazu beiträgt, uns aber nicht stört. Wenn ein Benutzer bereit ist, eine Information in eine andere einzubetten, um den freien Speicherplatz zu erhöhen, hat er seine Bilder entweder für lange Zeit optimiert oder möchte dies aus Angst vor Qualitätsverlust überhaupt nicht.
F5
Unter solchen Bedingungen ist eine ganze Familie von Algorithmen geeignet, die in dieser guten Darstellung zu finden sind . Am weitesten fortgeschritten ist der von Andreas Westfeld verfasste F5- Algorithmus, der mit den Koeffizienten der Helligkeitskomponente arbeitet, da das menschliche Auge am wenigsten empfindlich auf Änderungen reagiert. Darüber hinaus verwendet er eine auf Matrixcodierung basierende Einbettungstechnik, die es einem ermöglicht, die Größe des verwendeten Containers umso größer zu machen, je weniger Änderungen beim Einbetten derselben Informationsmenge vorgenommen werden.
Die Änderungen selbst führen unter bestimmten Bedingungen (dh nicht immer) zu einer Verringerung des Absolutwerts der Koeffizienten pro Einheit, wodurch F5 zur Optimierung der Datenspeicherung auf der Festplatte verwendet werden kann. Tatsache ist, dass der Koeffizient nach einer solchen Änderung aufgrund der statistischen Verteilung der Werte in JPEG wahrscheinlich eine geringere Anzahl von Bits nach der Huffman-Codierung einnimmt und neue Nullen von der Codierung mit RLE profitieren.
Die notwendigen Änderungen bestehen darin, den für die Geheimhaltung verantwortlichen Teil (Kennwortpermutation) zu eliminieren, wodurch Ressourcen und Ausführungszeit gespart werden können, und einen Mechanismus für die Arbeit mit vielen Dateien anstelle einer nach der anderen hinzuzufügen. Im Detail ist es unwahrscheinlich, dass der Prozess des Lesens des Lesers interessant ist, daher wenden wir uns der Beschreibung der Implementierung zu.
Hightech
Um die Arbeit dieses Ansatzes zu demonstrieren, habe ich die Methode in reinem C implementiert und eine Reihe von Optimierungen sowohl hinsichtlich der Geschwindigkeit als auch des Speichers durchgeführt (Sie können sich nicht vorstellen, wie viel diese Bilder ohne Komprimierung schon vor der DCT wiegen). Die plattformübergreifende Leistung wird durch eine Kombination der Bibliotheken libjpeg , pcre und tinydir erreicht , für die ich ihnen danke. All dies wird von make erledigt, daher möchten Windows-Benutzer Cygwin zur Evaluierung installieren oder sich selbst mit Visual Studio und Bibliotheken befassen.
Die Implementierung ist in Form eines Konsolendienstprogramms und einer Bibliothek verfügbar. Weitere Informationen zur Verwendung des letzteren finden Sie in der Readme-Datei im Repository auf dem Github, einem Link, den ich am Ende des Beitrags anhängen werde.
Wie benutzt man?
Mit Vorsicht. Die zum Verpacken verwendeten Bilder werden durch Suche nach regulären Ausdrücken im angegebenen Stammverzeichnis ausgewählt. Am Ende der Datei können Sie sie wie gewünscht verschieben, umbenennen und kopieren, die Datei und die Betriebssysteme ändern usw. Sie sollten jedoch äußerst vorsichtig sein und den unmittelbaren Inhalt nicht ändern. Der Verlust des Werts von nur einem Bit kann dazu führen, dass Informationen nicht wiederhergestellt werden können.
Nach Abschluss der Arbeiten hinterlässt das Dienstprogramm eine spezielle Archivdatei, die alle zum Entpacken erforderlichen Informationen enthält, einschließlich der Daten zu den verwendeten Bildern. An sich wiegt es in der Größenordnung von ein paar Kilobyte und hat keinen signifikanten Einfluss auf den belegten Speicherplatz.
Sie können die mögliche Kapazität mit dem Flag '-a' analysieren: './f5ar -a [Suchordner] [Perl-kompatibler regulärer Ausdruck]'. Das Packen erfolgt mit dem Befehl './f5ar -p [Suchordner] [Perl-kompatibler regulärer Ausdruck] [gepackte Datei] [Archivname]' und das Entpacken mit './f5ar -u [Archivdatei] [Name der wiederhergestellten Datei]'. .
Arbeitsdemonstration
Um die Wirksamkeit der Methode zu demonstrieren , habe ich eine Sammlung von 225 absolut kostenlosen Fotos von Hunden aus dem Unsplash- Dienst heruntergeladen und in den Dokumenten des zweiten Bandes der Knut- Programmierkunst ein großes PDF für 45 Meter ausgegraben.
Die Reihenfolge ist ziemlich einfach:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Screenshots für Fans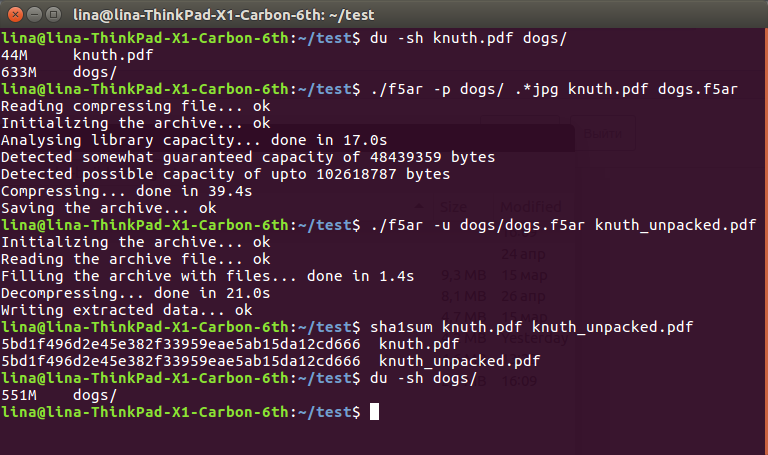
Die entpackte Datei ist weiterhin möglich und sollte gelesen werden:

Wie Sie sehen können, kamen wir von den ursprünglichen 633 + 36 == 669 Megabyte Daten auf der Festplatte zu einem angenehmeren 551. Dieser radikale Unterschied erklärt sich durch die Abnahme der Koeffizientenwerte, die ihre nachfolgende Komprimierung ohne Verlust beeinflussen: Eine Abnahme von nur einem nach dem anderen kann ruhig " Schneiden Sie "ein paar Bytes aus der resultierenden Datei. Dies ist jedoch immer noch ein Datenverlust, wenn auch äußerst gering, den Sie ertragen müssen.
Glücklicherweise sind sie für das Auge nicht vollständig sichtbar. Unter dem Spoiler (da habrastorage keine großen Dateien verarbeiten kann) kann der Leser den Unterschied sowohl nach Auge als auch nach Intensität bewerten, indem er die Werte der geänderten Komponente vom Original subtrahiert: das Original mit den darin enthaltenen Informationen den Unterschied (je dunkler die Farbe, desto kleiner der Unterschied im Block) )
Anstelle einer Schlussfolgerung
Angesichts all dieser Schwierigkeiten scheint der Kauf einer Festplatte oder das Hochladen aller Daten in die Cloud eine viel einfachere Lösung für das Problem zu sein. Aber obwohl wir jetzt in einer so wunderbaren Zeit leben, gibt es keine Garantie dafür, dass es morgen noch möglich sein wird, online zu gehen und all Ihre zusätzlichen Daten irgendwo hochzuladen. Oder kommen Sie in den Laden und kaufen Sie sich eine weitere Festplatte mit tausend Terabyte. Man kann aber immer schon liegende Häuser benutzen.
-> Github