
Hintergrund
So kam es, dass der Server von einem Ransomware-Virus angegriffen wurde, der durch einen "Zufall" .ibd-Dateien (innodb-Rohdatendateien), intakte, aber vollständig verschlüsselte .fpm-Dateien (Strukturdateien) teilweise beiseite legte. Gleichzeitig könnte .idb unterteilt werden in:
- vorbehaltlich der Wiederherstellung durch Standardwerkzeuge und -anleitungen. Für solche Fälle gibt es einen großartigen Artikel ;
- teilweise verschlüsselte Tabellen. Meist handelt es sich um große Tabellen, auf denen (wie ich verstanden habe) die Angreifer nicht über genügend RAM für eine vollständige Verschlüsselung verfügten.
- Nun, vollständig verschlüsselte Tabellen, die nicht wiederhergestellt werden können.
Es war möglich zu bestimmen, zu welcher Option die Tabellen gehören, indem man in einem beliebigen Texteditor unter der gewünschten Codierung (in meinem Fall UTF8) öffnete und einfach in der Datei nach Textfeldern suchte, zum Beispiel:
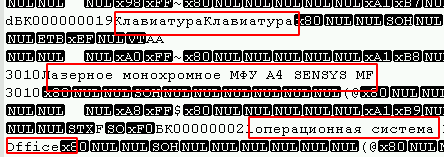
Außerdem können Sie am Anfang der Datei eine große Anzahl von 0-Bytes beobachten, und Viren, die den Blockverschlüsselungsalgorithmus (den häufigsten) verwenden, wirken sich normalerweise auf sie aus.

In meinem Fall haben die Angreifer am Ende jeder verschlüsselten Datei eine Zeichenfolge von 4 Byte (1, 0, 0, 0) hinterlassen, was die Aufgabe vereinfacht hat. Ein Skript reichte aus, um nach nicht infizierten Dateien zu suchen:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
So stellte sich heraus, dass Dateien des ersten Typs gefunden wurden. Das zweite impliziert ein langes Handbuch, aber bereits gefunden war genug. Alles wäre in Ordnung, aber es ist notwendig, die absolut genaue Struktur zu kennen , und (natürlich) es gab einen solchen Fall, dass ich mit einem häufig wechselnden Tisch arbeiten musste. Niemand erinnerte sich daran, ob sich der Feldtyp änderte oder eine neue Spalte hinzugefügt wurde.
Leider konnte Debri City in diesem Fall nicht helfen, daher wird dieser Artikel geschrieben.
Komm auf den Punkt
Es gibt eine Tabellenstruktur von vor 3 Monaten, die nicht mit der aktuellen übereinstimmt (vielleicht ein Feld, aber möglicherweise mehr). Tabellenstruktur:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
In diesem Fall müssen Sie extrahieren:
id_point INT (11);id_user INT (11);date_start DATETIME;date_finish DATETIME.
Zur Wiederherstellung wird eine Byteanalyse der .ibd-Datei verwendet, gefolgt von deren Übersetzung in eine besser lesbare Form. Da es ausreicht, um die erforderlichen Datentypen wie int und datatime zu analysieren, werden nur diese im Artikel beschrieben. Manchmal beziehen sie sich jedoch auch auf andere Datentypen, die bei ähnlichen Vorfällen hilfreich sein können.
Problem 1 : Felder mit den Typen DATETIME und TEXT hatten einen NULL-Wert und werden einfach in der Datei übersprungen. Aus diesem Grund war es in meinem Fall nicht möglich, die Struktur für die Wiederherstellung zu bestimmen. In den neuen Spalten war der Standardwert null, und einige der Transaktionen konnten aufgrund der Einstellung innodb_flush_log_at_trx_commit = 0 verloren gehen, sodass zusätzliche Zeit für die Bestimmung der Struktur aufgewendet werden musste.
Problem 2 : Es ist zu beachten, dass sich die durch DELETE gelöschten Zeilen alle genau in der ibd-Datei befinden, ihre Struktur jedoch nicht mit ALTER TABLE aktualisiert wird. Infolgedessen kann die Datenstruktur vom Anfang bis zum Ende der Datei variieren. Wenn Sie häufig OPTIMIZE TABLE verwenden, ist es unwahrscheinlich, dass Sie auf ein ähnliches Problem stoßen.
Beachten Sie, dass die DBMS-Version die Art und Weise beeinflusst, in der Daten gespeichert werden. Dieses Beispiel funktioniert möglicherweise nicht für andere Hauptversionen. In meinem Fall wurde die Windows-Version mariadb 10.1.24 verwendet. Auch wenn Sie in Mariadb mit InnoDB-Tabellen arbeiten, handelt es sich tatsächlich um XtraDB , was die Anwendbarkeit der Methode mit InnoDB- MySQL ausschließt.
Dateianalyse
In Python zeigt der Datentyp bytes () Daten in Unicode anstelle der üblichen Zahlen an. Sie können die Datei zwar in dieser Form betrachten, aber der Einfachheit halber können Sie Bytes in eine numerische Form übersetzen, indem Sie das Byte-Array in ein reguläres Array übersetzen (list (example_byte_array)). In jedem Fall sind beide Methoden für die Analyse nützlich.
Nachdem Sie sich mehrere ibd-Dateien angesehen haben, finden Sie Folgendes:
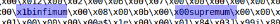
Wenn Sie die Datei durch diese Schlüsselwörter teilen, erhalten Sie außerdem meist flache Datenblöcke. Wir werden infimum als Teiler verwenden.
table = table.split("infimum".encode())
Eine interessante Beobachtung für Tabellen mit einer kleinen Datenmenge zwischen Infimum und Supremum ist ein Zeiger auf die Anzahl der Zeilen im Block.
 - Prüftisch mit 1. Reihe
- Prüftisch mit 1. Reihe
 - Testtabelle mit 2 Zeilen
- Testtabelle mit 2 Zeilen
Das Array der Zeilentabelle [0] kann übersprungen werden. Nachdem ich es mir angesehen hatte, konnte ich die Rohdaten der Tabellen immer noch nicht finden. Dieser Block wird höchstwahrscheinlich zum Speichern von Indizes und Schlüsseln verwendet.
Wenn Sie mit Tabelle [1] beginnen und diese in ein numerisches Array übersetzen, können Sie bereits einige Muster feststellen, nämlich:

Dies sind int-Werte, die in einer Zeichenfolge gespeichert sind. Das erste Byte gibt an, ob die Zahl positiv oder negativ ist. In meinem Fall sind alle Zahlen positiv. Aus den verbleibenden 3 Bytes können Sie die Anzahl mit der folgenden Funktion ermitteln. Skript:
def find_int(val: str):
Zum Beispiel 128, 0, 0, 1 = 1 oder 128, 0, 75, 108 = 19308 .
Die Tabelle hatte einen Primärschlüssel mit automatischer Inkrementierung, und hier finden Sie ihn auch

Beim Vergleich der Daten aus den Testtabellen wurde festgestellt, dass das DATETIME-Objekt aus 5 Bytes besteht, beginnend mit 153 (höchstwahrscheinlich unter Angabe von Jahresintervallen). Da der DATTIME-Bereich von '1000-01-01' bis '9999-12-31' reicht, kann die Anzahl der Bytes variieren. In meinem Fall fallen die Daten jedoch in den Zeitraum von 2016 bis 2019, sodass wir davon ausgehen, dass 5 Bytes ausreichen .
Um die Zeit ohne Sekunden zu bestimmen, wurden die folgenden Funktionen geschrieben. Skript:
day_ = lambda x: x % 64 // 2
Ein Jahr und einen Monat lang war es nicht möglich, eine gesunde Arbeitsfunktion zu schreiben, daher musste ich hart codieren. Skript:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
Ich bin sicher, dass dieses Missverständnis korrigiert werden kann, wenn Sie n die Zeit verbringen.
Als Nächstes gibt die Funktion ein Datum / Uhrzeit-Objekt aus einer Zeichenfolge zurück. Skript:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
Es war möglich, häufig wiederholte Werte aus int, int, datetime, datetime zu erkennen 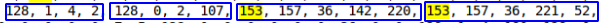 Es scheint, dass dies das ist, was Sie brauchen. Darüber hinaus wird eine solche Sequenz nicht zweimal pro Zeile wiederholt.
Es scheint, dass dies das ist, was Sie brauchen. Darüber hinaus wird eine solche Sequenz nicht zweimal pro Zeile wiederholt.
Mit einem regulären Ausdruck finden wir die notwendigen Daten:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
Bitte beachten Sie, dass bei der Suche nach diesem Ausdruck keine NULL-Werte in den erforderlichen Feldern ermittelt werden können. In meinem Fall ist dies jedoch nicht kritisch. Nachdem wir das gefundene durchlaufen haben. Skript:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
Eigentlich alles, Daten aus dem Ergebnisarray, das sind die Daten, die wir brauchen. ### PS. ###
Ich verstehe, dass diese Methode nicht für jeden geeignet ist, aber das Hauptziel des Artikels ist es, Maßnahmen zu veranlassen, anstatt alle Ihre Probleme zu lösen. Ich denke, die richtigste Lösung wäre, den Quellcode von Mariadb selbst zu studieren , aber aufgrund der begrenzten Zeit schien die aktuelle Methode die schnellste zu sein.
In einigen Fällen können Sie nach der Analyse der Datei die ungefähre Struktur ermitteln und eine der Standardmethoden über die obigen Links wiederherstellen. Es wird viel korrekter sein und weniger Probleme verursachen.