Hallo, liebe Leser von Habr. Mein Name ist Rustem und ich bin der Hauptentwickler des kasachischen IT-Unternehmens DAR. In diesem Artikel werde ich Ihnen erklären, was Sie wissen müssen, bevor Sie mit dem Akka-Toolkit zu Event Sourcing- und CQRS-Vorlagen übergehen.
Um 2015 haben wir begonnen, unser Ökosystem zu gestalten. Nach der Analyse und basierend auf den Erfahrungen mit Scala und Akka haben wir uns entschlossen, beim Akka-Toolkit anzuhalten. Wir hatten erfolgreiche Implementierungen von Event Sourcing-Vorlagen mit CQRS und nicht so. Die Anhäufung von Fachwissen in diesem Bereich, das ich mit den Lesern teilen möchte. Wir werden uns ansehen, wie Akka diese Muster implementiert und welche Tools verfügbar sind, und über Akka-Fallstricke sprechen. Ich hoffe, dass Sie nach dem Lesen dieses Artikels die Risiken eines Wechsels zum Akka-Toolkit besser verstehen.
Zu den Themen CQRS und Event Sourcing wurden viele Artikel über Habré und andere Ressourcen verfasst. Dieser Artikel richtet sich an Leser, die bereits verstehen, was CQRS und Event Sourcing sind. In dem Artikel möchte ich mich auf Akka konzentrieren.
Domänengesteuertes Design
Es wurde viel Material über Domain-Driven Design (DDD) geschrieben. Es gibt sowohl Gegner als auch Befürworter dieses Ansatzes. Ich möchte selbst hinzufügen, dass es nicht überflüssig ist, DDD zu studieren, wenn Sie sich für Event Sourcing und CQRS entscheiden. Darüber hinaus ist die DDD-Philosophie in allen Akka-Tools zu spüren.
Tatsächlich sind Event Sourcing und CQRS nur ein kleiner Teil des Gesamtbilds, das als domänengesteuertes Design bezeichnet wird. Beim Entwerfen und Entwickeln haben Sie möglicherweise viele Fragen dazu, wie Sie diese Muster richtig implementieren und in das Ökosystem integrieren können. Wenn Sie wissen, dass DDD Ihr Leben einfacher macht.
In diesem Artikel bezeichnet der Begriff Entität (Entität von DDD) einen Persistenzakteur mit einer eindeutigen Kennung.
Warum Scala?
Wir werden oft gefragt, warum Scala und nicht Java. Ein Grund ist Akka. Das Framework selbst, geschrieben in der Scala-Sprache mit Unterstützung für die Java-Sprache. Hier muss ich sagen, dass es auch eine Implementierung in .NET gibt , aber dies ist ein anderes Thema. Um keine Diskussion zu verursachen, werde ich nicht schreiben, warum Scala besser oder schlechter als Java ist. Ich möchte Ihnen nur einige Beispiele nennen, die meiner Meinung nach bei der Arbeit mit Akka einen Vorteil gegenüber Java haben:
- Unveränderliche Gegenstände. In Java müssen Sie unveränderliche Objekte selbst schreiben. Glauben Sie mir, es ist nicht einfach und nicht sehr bequem, ständig die endgültigen Parameter zu schreiben. In Scala
case class Fallklasse bereits mit der integrierten Kopierfunktion unveränderlich - Codierungsstil. Bei der Implementierung in Java schreiben Sie weiterhin im Scala-Stil, dh funktional.
Hier ist ein Beispiel für die Implementierung von Actor in Scala und Java:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Java:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(Beispiel von hier )
createReceive() auf die Implementierung der Methode createReceive() am Beispiel der Java-Sprache. Intern wird über die ReceiveBuilder Factory der Pattern-Matching implementiert. receiveBuilder() ist eine Methode von Akka zur Unterstützung von Lambda-Ausdrücken, nämlich Pattern-Matching in Java. In Scala wird dies nativ implementiert. Stimmen Sie zu, der Code in Scala ist kürzer und leichter zu lesen.
- Dokumentation und Beispiele. Trotz der Tatsache, dass es in der offiziellen Dokumentation Beispiele in Java gibt, befinden sich im Internet fast alle Beispiele in Scala. Außerdem können Sie leichter in den Quellen der Akka-Bibliothek navigieren.
In Bezug auf die Leistung wird es keinen Unterschied zwischen Scala und Java geben, da sich alles in der JVM dreht.
Lagerung
Bevor Sie Event Sourcing mit Akka Persistence implementieren, empfehlen wir Ihnen, eine Datenbank für die permanente Datenspeicherung vorzuwählen. Die Wahl der Basis hängt von den Anforderungen an das System, Ihren Wünschen und Vorlieben ab. Daten können sowohl in NoSQL und RDBMS als auch in einem Dateisystem, beispielsweise LevelDB von Google, gespeichert werden.
Es ist wichtig zu beachten, dass Akka Persistence nicht für das Schreiben und Lesen von Daten aus der Datenbank verantwortlich ist, sondern über ein Plug-In, das die Akka Persistence API implementieren sollte.
Nachdem Sie ein Tool zum Speichern von Daten ausgewählt haben, müssen Sie ein Plugin aus der Liste auswählen oder es selbst schreiben. Die zweite Option, ich empfehle nicht, warum das Rad neu erfinden.
Für die dauerhafte Datenspeicherung haben wir uns entschieden, bei Cassandra zu bleiben. Tatsache ist, dass wir eine zuverlässige, schnelle und verteilte Basis brauchten. Darüber hinaus begleitet Typesafe selbst das Plugin , das die Akka Persistence API vollständig implementiert. Es wird ständig aktualisiert und im Vergleich zu anderen hat das Cassandra-Plugin eine vollständigere Dokumentation geschrieben.
Es ist erwähnenswert, dass das Plugin auch einige Probleme hat. Zum Beispiel gibt es noch keine stabile Version (zum Zeitpunkt dieses Schreibens ist die neueste Version 0.97). Für uns war das größte Ärgernis bei der Verwendung dieses Plugins der Verlust von Ereignissen beim Lesen der persistenten Abfrage für einige Entitäten. Für ein vollständiges Bild sehen Sie unten das CQRS-Diagramm:
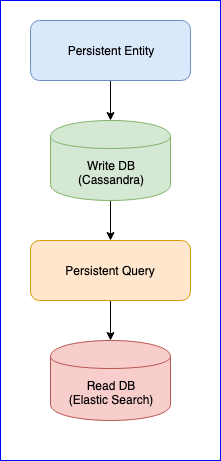
Persistente Entität verteilt Entitätsereignisse mithilfe des konsistenten Hash-Algorithmus (z. B. 10 Shards) in Tags:
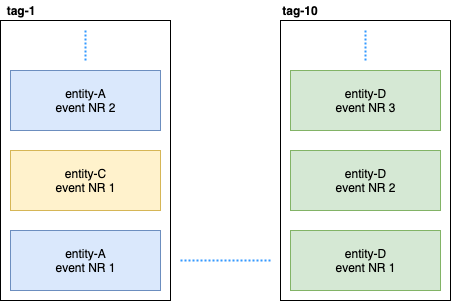
Anschließend abonniert Persistent Query diese Tags und startet einen Stream, der der elastischen Suche Daten hinzufügt. Da sich Cassandra in einem Cluster befindet, werden Ereignisse über Knoten verteilt. Einige Knoten können durchhängen und reagieren langsamer als andere. Es gibt keine Garantie dafür, dass Sie Veranstaltungen in strikter Reihenfolge erhalten. Um dieses Problem zu lösen, wird das Plugin so implementiert, dass es, wenn es ein ungeordnetes Ereignis empfängt, z. B. entity-A event NR 2 , eine bestimmte Zeit auf das erste Ereignis wartet und wenn es es nicht empfängt, einfach alle Ereignisse dieser Entität ignoriert. Auch darüber gab es Diskussionen über Gitter. Wenn jemand interessiert ist, können Sie die Korrespondenz zwischen @kotdv und den Entwicklern des Plugins lesen: Gitter
Wie kann dieses Missverständnis behoben werden:
- Sie müssen das Plugin auf die neueste Version aktualisieren. In neueren Versionen haben Typesafe-Entwickler viele Probleme im Zusammenhang mit der eventuellen Konsistenz gelöst. Wir warten aber immer noch auf eine stabile Version
- Für die Komponente, die für den Empfang von Ereignissen verantwortlich ist, wurden genauere Einstellungen hinzugefügt. Sie können versuchen, das Zeitlimit für ungeordnete Ereignisse zu erhöhen, um den Betrieb des Plugins zuverlässiger zu gestalten: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Konfigurieren Sie Cassandra wie von DataStax empfohlen. Setzen Sie den Garbage Collector G1 ein und weisen Sie Cassandra so viel Speicher wie möglich zu.
Am Ende haben wir das Problem mit den fehlenden Ereignissen gelöst, aber jetzt gibt es eine stabile Datenverzögerung auf der Seite der Persistenzabfrage (von fünf bis zehn Sekunden). Es wurde beschlossen, den Ansatz für Daten, die für die Analyse verwendet werden, beizubehalten. Wenn Geschwindigkeit wichtig ist, veröffentlichen wir Ereignisse manuell im Bus. Die Hauptsache ist, den geeigneten Mechanismus für die Verarbeitung oder Veröffentlichung von Daten zu wählen: mindestens einmal oder höchstens einmal. Eine gute Beschreibung von Akka finden Sie hier . Für uns war es wichtig, die Datenkonsistenz aufrechtzuerhalten. Daher haben wir nach dem erfolgreichen Schreiben von Daten in die Datenbank einen Übergangszustand eingeführt, der die erfolgreiche Veröffentlichung von Daten auf dem Bus steuert. Das Folgende ist ein Beispielcode:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
Wenn es aus irgendeinem Grund nicht möglich war, das Ereignis zu veröffentlichen, wird beim nächsten Start von SomeEntity , dass das DidSomething Ereignis den Bus nicht erreicht hat, und es wird versucht, die Daten erneut zu veröffentlichen.
Serializer
Die Serialisierung ist ein ebenso wichtiger Punkt bei der Verwendung von Akka. Er hat ein internes Modul - Akka Serialization . Dieses Modul wird verwendet, um Nachrichten beim Austausch zwischen Akteuren und beim Speichern über die Persistenz-API zu serialisieren. Standardmäßig wird der Java-Serializer verwendet, es wird jedoch empfohlen, einen anderen zu verwenden. Das Problem ist, dass der Java Serializer langsam ist und viel Platz beansprucht. Es gibt zwei beliebte Lösungen: JSON und Protobuf. JSON ist zwar langsam, aber einfacher zu implementieren und zu warten. Wenn Sie die Kosten für Serialisierung und Datenspeicherung minimieren müssen, können Sie bei Protobuf anhalten, aber dann wird der Entwicklungsprozess langsamer. Zusätzlich zum Domänenmodell müssen Sie ein weiteres Datenmodell schreiben. Vergessen Sie nicht die Datenversionierung. Seien Sie darauf vorbereitet, ständig eine Zuordnung zwischen dem Domänenmodell und dem Datenmodell zu schreiben.
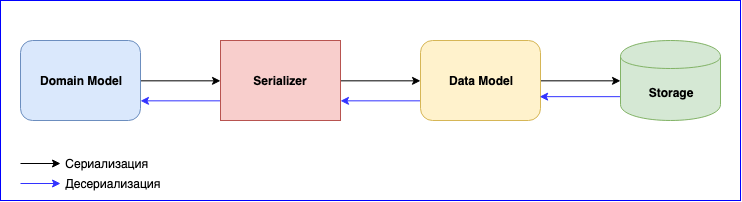
Neues Ereignis hinzugefügt - Zuordnung schreiben. Datenstruktur geändert - Schreiben Sie eine neue Version des Datenmodells und ändern Sie die Zuordnungsfunktion. Vergessen Sie nicht die Tests für Serializer. Im Allgemeinen wird es viel Arbeit geben, aber am Ende erhalten Sie lose gekoppelte Komponenten.
Schlussfolgerungen
- Studieren Sie sorgfältig und wählen Sie eine geeignete Basis und ein Plugin für sich. Ich empfehle, ein Plugin zu wählen, das gut gepflegt ist und nicht aufhört, sich zu entwickeln. Das Gebiet ist relativ neu, es gibt noch eine Reihe von Mängeln, die noch behoben werden müssen
- Wenn Sie verteilten Speicher auswählen, müssen Sie das Problem mit einer Verzögerung von bis zu 10 Sekunden selbst lösen oder in Kauf nehmen
- Die Komplexität der Serialisierung. Sie können Geschwindigkeit opfern und auf JSON anhalten oder Protobuf wählen und viele Adapter schreiben und diese unterstützen.
- Diese Vorlage hat Vorteile: Es handelt sich um lose gekoppelte Komponenten und unabhängige Entwicklungsteams, die ein großes System bilden.