SDSM ist vorbei, aber der unkontrollierte Wunsch zu schreiben bleibt bestehen.

Unser Bruder litt viele Jahre lang unter Routinearbeiten, drückte die Daumen, bevor er sich verpflichtete, und hatte aufgrund nächtlicher Rollbacks keinen Schlaf.
Aber die dunklen Zeiten gehen zu Ende.
Mit diesem Artikel beginne ich eine Reihe darüber, wie
ich Automatisierung sehe.
Dabei werden wir uns mit den Phasen der Automatisierung befassen, Variablen speichern, das Design formalisieren, mit RestAPI, NETCONF, YANG, YDK und viel programmieren.
Es bedeutet für
mich, dass a) dies keine objektive Wahrheit ist, b) nicht unbedingt der beste Ansatz ist, c) sich meine Meinung auch während des Übergangs vom ersten zum letzten Artikel ändern kann - um ehrlich zu sein, habe ich vom Entwurf bis zur Veröffentlichung alles zweimal komplett neu geschrieben.
Inhalt
- Ziele
- Das Netzwerk ist wie ein einzelner Organismus
- Konfigurationstest
- Versionierung
- Überwachungs- und Selbstheilungsdienste
- Mittel
- Inventarsystem
- IP Space Management System
- Netzwerkdienste Beschreibung System
- Geräteinitialisierungsmechanismus
- Herstellerunabhängiges Konfigurationsmodell
- Herstellerspezifischer Treiber
- Der Mechanismus zum Übermitteln der Konfiguration an das Gerät
- CI / CD
- Sicherungs- und Abweichungsmechanismus
- Überwachungssystem
- Fazit
Ich werde versuchen, den ADSM in einem Format zu halten, das sich geringfügig vom SDSM unterscheidet. Es werden weiterhin große, detailliert nummerierte Artikel erscheinen, und dazwischen werde ich kleine Notizen aus der täglichen Erfahrung veröffentlichen. Ich werde versuchen, den Perfektionismus hier zu bekämpfen und nicht jeden von ihnen zu lecken.
Wie lustig, dass du beim zweiten Mal den gleichen Weg gehen musst.
Zuerst musste ich Artikel über das Netzwerk selbst schreiben, da sie nicht in RuNet waren.
Jetzt konnte ich kein umfassendes Dokument finden, das Automatisierungsansätze systematisiert und einfache praktische Beispiele zur Analyse der oben genannten Technologien verwendet.
Vielleicht irre ich mich deshalb, Links zu geeigneten Ressourcen zu werfen. Dies ändert jedoch nichts an meiner Entschlossenheit zu schreiben, denn das Hauptziel ist es, selbst etwas zu lernen, und meinem Nachbarn das Leben zu erleichtern, ist ein angenehmer Bonus, der das Gen für die Verbreitung von Erfahrungen streichelt.
Wir werden versuchen, ein mittelgroßes LAN-DC-Rechenzentrum zu nutzen und das gesamte Automatisierungsschema zu erarbeiten.
Ich werde einige Dinge fast das erste Mal mit dir machen.
In den hier beschriebenen Ideen und Werkzeugen werde ich nicht originell sein. Dmitry Figol hat einen ausgezeichneten Kanal mit Streams zu diesem Thema .
Artikel in vielen Aspekten überschneiden sich mit ihnen.
Der LAN-DC verfügt über 4 DCs, etwa 250 Switches, ein halbes Dutzend Router und einige Firewalls.
Nicht Facebook, aber genug, um tief über Automatisierung nachzudenken.
Es besteht jedoch die Meinung, dass Sie bereits eine Automatisierung benötigen, wenn Sie mehr als ein Gerät haben.
Tatsächlich ist es schwer vorstellbar, dass jemand jetzt ohne mindestens ein paar kniehohe Skripte leben kann.
Obwohl ich gehört habe, dass es solche Büros gibt, in denen IP-Adressen in Excel gespeichert werden und jedes der Tausenden von Netzwerkgeräten manuell konfiguriert wird und eine eigene Konfiguration hat. Dies kann natürlich als zeitgenössische Kunst ausgegeben werden, aber die Gefühle des Ingenieurs werden sicherlich beleidigt sein.
Ziele
Jetzt werden wir die abstraktesten Ziele setzen:
- Das Netzwerk ist wie ein einzelner Organismus
- Konfigurationstest
- Versionierung des Netzwerkstatus
- Überwachungs- und Selbstheilungsdienste
Später in diesem Artikel werden wir analysieren, welche Mittel wir verwenden werden, und im Folgenden Ziele und Mittel im Detail.
Das Netzwerk ist wie ein einzelner Organismus
Die definierende Phrase des Zyklus, obwohl sie auf den ersten Blick nicht so wichtig erscheint:
Wir werden das Netzwerk konfigurieren, nicht einzelne Geräte .
In den letzten Jahren haben wir eine Verlagerung des Schwerpunkts hin zur Behandlung des Netzwerks als eine Einheit beobachtet, daher kommen die
softwaredefinierten Netzwerke ,
absichtsgesteuerten Netzwerke und
autonomen Netzwerke in unser Leben.
Was global von Anwendungen aus dem Netzwerk benötigt wird: Konnektivität zwischen den Punkten A und B (naja, manchmal + B-Z) und Isolation von anderen Anwendungen und Benutzern.

Daher besteht unsere Aufgabe in dieser Serie darin
, ein System zu
erstellen , das die aktuelle Konfiguration des
gesamten Netzwerks unterstützt , das bereits in die aktuelle Konfiguration auf jedem Gerät entsprechend seiner Rolle und Position zerlegt ist.
Das Netzwerkverwaltungssystem impliziert, dass wir Änderungen vornehmen, um Änderungen vorzunehmen, und es berechnet wiederum den gewünschten Status für jedes Gerät und konfiguriert es.
Daher minimieren wir die Verwendung von CLI in unseren Händen auf nahezu Null - Änderungen an den Geräteeinstellungen oder am Netzwerkdesign sollten formalisiert und dokumentiert werden - und erst dann auf die erforderlichen Netzwerkelemente übertragen.
Das heißt, wenn wir zum Beispiel beschlossen haben, dass die Rack-Switches in Kasan von nun an zwei Netzwerke anstelle von einem ankündigen sollen, wir
- Zunächst dokumentieren wir die Änderungen in den Systemen
- Wir generieren die Zielkonfiguration aller Netzwerkgeräte
- Wir starten das Programm zur Aktualisierung der Netzwerkkonfiguration, das berechnet, was auf jedem Knoten entfernt werden muss, was hinzugefügt werden muss, und die Knoten in den gewünschten Zustand versetzt.
Gleichzeitig nehmen wir mit unseren Händen erst im ersten Schritt Änderungen vor.
Konfigurationstest
Es ist bekannt, dass 80% der Probleme bei Konfigurationsänderungen auftreten - ein indirekter Beweis dafür ist, dass in den Neujahrsferien normalerweise alles ruhig ist.
Ich persönlich habe Dutzende globaler Ausfallzeiten aufgrund eines menschlichen Fehlers erlebt: Der falsche Befehl, die Konfiguration wurde im falschen Zweig ausgeführt, die Community hat vergessen, MPLS global auf dem Router zerstört, fünf Eisenstücke konfiguriert und den sechsten Fehler nicht bemerkt, die alten Änderungen, die von einer anderen Person vorgenommen wurden . Szenarien Dunkelheit ist dunkel.
Durch die Automatisierung können wir weniger Fehler machen, jedoch in größerem Maßstab. Sie können also nicht nur ein Gerät, sondern das gesamte Netzwerk gleichzeitig blockieren.
Seit jeher überprüften unsere Großväter die Richtigkeit der vorgenommenen Änderungen mit einem scharfen Auge, Stahleiern und der Effizienz des Netzwerks, nachdem sie sie ausgerollt hatten.
Diese Großväter, deren Arbeit zu Ausfallzeiten und katastrophalen Verlusten führte, hinterließen weniger Nachkommen und sollten im Laufe der Zeit aussterben. Die Evolution ist jedoch ein langsamer Prozess, und daher überprüft nicht jeder zuvor die Änderungen im Labor.
An der Spitze derjenigen, die den Testprozess der Konfiguration und ihre weitere Anwendung auf das Netzwerk automatisiert haben. Mit anderen Worten, ich habe das CI / CD-Verfahren (
Continuous Integration, Continuous Deployment ) von den Entwicklern ausgeliehen.
In einem Teil werden wir uns ansehen, wie dies mit einem Versionskontrollsystem, wahrscheinlich einem Github, implementiert werden kann.
Sobald Sie sich an die Idee des Netzwerk-CI / CD gewöhnt haben, wird Ihnen die Methode, die Konfiguration zu überprüfen, indem Sie sie auf das funktionierende Netzwerk anwenden, über Nacht als frühmittelalterliche Ignoranz erscheinen. Wie man einen Gefechtskopf mit einem Hammer hämmert.
Eine organische Fortsetzung der Ideen
zum Netzwerkmanagementsystem und zu CI / CD ist die vollständige Versionierung der Konfiguration.
Versionierung
Wir gehen davon aus, dass bei allen Änderungen, selbst bei geringfügigen Änderungen, selbst auf einem unauffälligen Gerät, das gesamte Netzwerk von einem Status in einen anderen wechselt.
Und wir führen den Befehl immer nicht auf dem Gerät aus, wir ändern den Status des Netzwerks.
Lassen Sie uns nun diese Zustände abrufen und sie Versionen nennen.
Angenommen, die aktuelle Version ist 1.0.0.
Hat sich die IP-Adresse der Loopback-Schnittstelle auf einem der ToRs geändert? Dies ist eine Nebenversion - erhalten Sie die Nummer 1.0.1.
Überprüfte Richtlinien für den Routenimport in BGP - etwas schwerwiegender - bereits 1.1.0
Wir haben beschlossen, IGP loszuwerden und nur auf BGP umzusteigen - dies ist eine radikale Designänderung - 2.0.0.
Gleichzeitig können verschiedene DCs unterschiedliche Versionen haben - das Netzwerk entwickelt sich, neue Geräte werden installiert, irgendwo werden neue Wirbelsäulenebenen hinzugefügt, irgendwo - nein usw.
Wir werden in einem separaten Artikel über
semantische Versionierung sprechen.
Ich wiederhole - jede Änderung (außer Debugging-Befehlen) ist ein Update der Version. Administratoren sollten über Abweichungen von der aktuellen Version informiert werden.
Gleiches gilt für das Rollback von Änderungen - dies ist nicht die Aufhebung der letzten Befehle, dies ist kein Rollback durch das Betriebssystem des Geräts - dies bringt das gesamte Netzwerk auf eine neue (alte) Version.
Überwachungs- und Selbstheilungsdienste
Diese selbstverständliche Aufgabe in modernen Netzwerken erreicht eine neue Ebene.
Oft praktizieren große Dienstleister den Ansatz, dass ein ausgefallener Dienst schnell beendet und ein neuer angehoben werden muss, anstatt herauszufinden, was passiert ist.
"Sehr" bedeutet, dass es von allen Seiten notwendig ist, die Überwachung stark zu verschmieren, wodurch innerhalb von Sekunden die geringsten Abweichungen von der Norm festgestellt werden.
Und hier gibt es nicht genug bekannte Metriken, wie das Laden einer Schnittstelle oder die Zugänglichkeit eines Knotens. Nicht genug und manuelle Verfolgung des Dienstoffiziers für sie.
Für viele Dinge sollte es im Allgemeinen
Selbstheilung geben - die Kontrollen leuchteten rot auf und gingen von der Wegerich selbst weg, wo es weh tut.
Und hier überwachen wir nicht nur einzelne Geräte, sondern auch den Zustand des gesamten Netzwerks, sowohl die Whitebox, die relativ klar ist, als auch die Blackbox, die bereits komplizierter ist.
Was brauchen wir, um solch ehrgeizige Pläne umzusetzen?
- Haben Sie eine Liste aller Geräte im Netzwerk, ihren Standort, Rollen, Modelle, Softwareversionen.
kazan-leaf-1.lmu.net, Kasan, Blatt, Juniper QFX 5120, R18.3.
- Haben Sie ein System zur Beschreibung von Netzwerkdiensten.
IGP, BGP, L2 / 3VPN, Richtlinie, ACL, NTP, SSH. - Sie können das Gerät initialisieren.
Hostname, Mgmt IP, Mgmt Route, Benutzer, RSA-Schlüssel, LLDP, NETCONF - Konfigurieren Sie das Gerät und bringen Sie die Konfiguration auf die gewünschte (einschließlich der alten) Version.
- Testkonfiguration
- Überprüfen Sie regelmäßig den Status aller Geräte auf Abweichungen vom aktuellen und sagen Sie, wer dies tun soll.
Nachts fügte jemand der ACL leise eine Regel hinzu . - Überwachen Sie die Leistung.
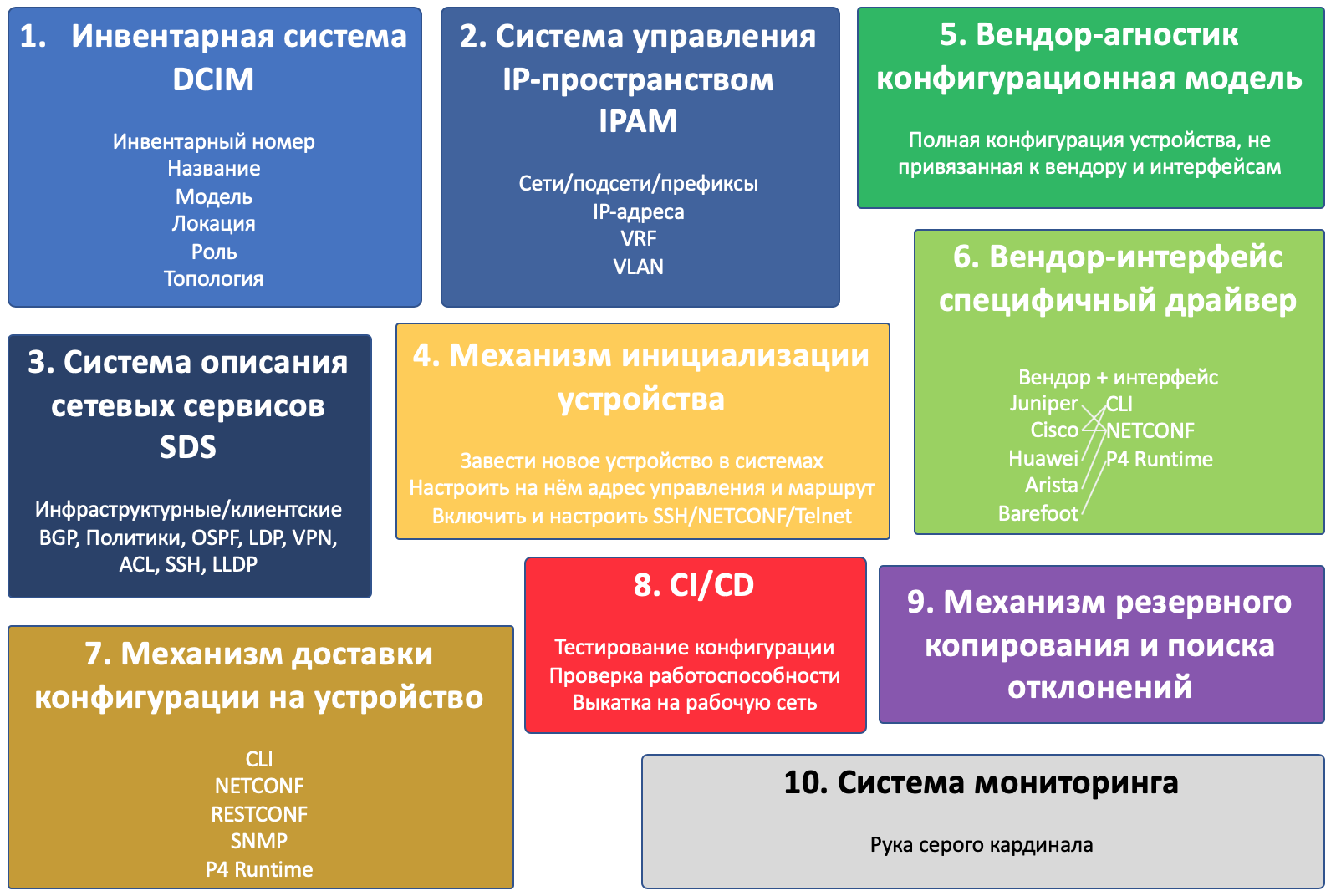
Mittel
Klingt kompliziert genug, um ein Projekt in Komponenten zu zerlegen.
Und es werden zehn sein:
- Inventarsystem
- IP Space Management System
- Netzwerkdienste Beschreibung System
- Geräteinitialisierungsmechanismus
- Herstellerunabhängiges Konfigurationsmodell
- Herstellerspezifischer Treiber
- Der Mechanismus zum Übermitteln der Konfiguration an das Gerät
- CI / CD
- Sicherungs- und Abweichungsmechanismus
- Überwachungssystem
Dies ist übrigens ein Beispiel dafür, wie sich die Sicht auf die Ziele des Zyklus geändert hat - die Entwurfskomponenten enthielten 4 Komponenten.

In der Abbildung habe ich alle Komponenten und das Gerät selbst dargestellt.
Sich überschneidende Komponenten interagieren miteinander.
Je größer der Block, desto mehr Aufmerksamkeit müssen Sie dieser Komponente widmen.
Komponente 1. Inventarsystem
Natürlich wollen wir wissen, mit welchen Geräten, wo sie stehen und woran sie angeschlossen sind.
Das Inventarsystem ist ein wesentlicher Bestandteil jedes Unternehmens.
In den meisten Fällen verfügt das Unternehmen für Netzwerkgeräte über ein separates Inventarsystem, das spezifischere Aufgaben löst.
Als Teil einer Artikelserie werden wir es DCIM - Data Center Infrastructure Management nennen. Obwohl der Begriff DCIM selbst streng genommen viel mehr beinhaltet.
Für unsere Aufgaben speichern wir die folgenden Informationen über das Gerät darin:
- Inventarnummer
- Titel / Beschreibung
- Modell ( Huawei CE12800, Juniper QFX5120 usw. )
- Typische Parameter ( Karten, Schnittstellen usw. )
- Rolle ( Blatt, Wirbelsäule, Border Router usw. )
- Standort ( Region, Stadt, Rechenzentrum, Rack, Einheit )
- Verbindungen zwischen Geräten
- Netzwerktopologie

Es ist völlig klar, dass wir das alles selbst wissen wollen.
Aber hilft es bei der Automatisierung?
Natürlich.
Wir wissen beispielsweise, dass in diesem Rechenzentrum auf Leaf-Switches, wenn es sich um Huawei handelt, ACLs zum Filtern bestimmten Datenverkehrs auf das VLAN angewendet werden sollten, und wenn es sich um Juniper handelt, auf Einheit 0 der physischen Schnittstelle.
Oder Sie müssen einen neuen Syslog-Server für alle Boarder in der Region bereitstellen.
Darin werden virtuelle Netzwerkgeräte wie virtuelle Router oder Root-Reflektoren gespeichert. Wir können einen DNS-Server, NTP, Syslog und im Allgemeinen alles hinzufügen, was irgendwie mit dem Netzwerk zusammenhängt.
Komponente 2. IP Space Management System
Ja, und in unserer Zeit gibt es Teams von Personen, die Präfixe und IP-Adressen in einer Excel-Datei verfolgen. Der moderne Ansatz ist jedoch immer noch eine Datenbank mit einem Frontend für Nginx / Apache, einer API und umfangreichen Funktionen zur Berücksichtigung von IP-Adressen und Netzwerken mit Trennung in VRF.
IPAM - IP-Adressverwaltung.
Für unsere Aufgaben speichern wir folgende Informationen darin:
- VLAN
- VRF
- Netzwerke / Subnetze
- IP-Adressen
- Bindungsadressen an Geräte, Netzwerke an Standorte und VLAN-Nummern

Auch hier ist klar, dass wir sicher sein möchten, dass wir durch die Zuweisung einer neuen IP-Adresse für den ToR-Loopback nicht auf die Tatsache stoßen, dass diese bereits jemandem zugewiesen wurde. Oder dass wir dasselbe Präfix zweimal an verschiedenen Enden des Netzwerks verwendet haben.
Aber wie hilft das bei der Automatisierung?
Einfach.
Wir fordern im System ein Präfix mit der Rolle "Loopbacks" an, in dem IP-Adressen für die Zuweisung verfügbar sind. Wenn dies der Fall ist, wählen Sie die Adresse aus. Wenn nicht, fordern wir die Erstellung eines neuen Präfix an.
Wenn wir eine Gerätekonfiguration erstellen, können wir vom selben System aus herausfinden, in welcher VRF sich die Schnittstelle befinden soll.
Und wenn Sie einen neuen Server starten, geht das Skript in das System und findet heraus, auf welchem Server sich der Switch befindet, an welchem Port und welches Subnetz der Schnittstelle zugewiesen ist - es wählt die Serveradresse aus.
Es weckt den Wunsch von DCIM und IPAM, sich zu einem System zusammenzuschließen, um Funktionen nicht zu duplizieren und nicht zwei ähnlichen Einheiten zu dienen.
Also werden wir es tun.
Komponente 3. Netzwerkdienste Beschreibung System
Wenn die ersten beiden Systeme Variablen speichern, die noch irgendwie verwendet werden müssen, beschreibt das dritte für jede Geräterolle, wie sie konfiguriert werden sollen.
Es lohnt sich, zwei verschiedene Arten von Netzwerkdiensten hervorzuheben:
Ersteres bietet grundlegende Konnektivität und Geräteverwaltung. Dazu gehören VTY, SNMP, NTP, Syslog, AAA, Routing-Protokolle, CoPP usw.
Die zweiten organisieren den Dienst für den Client: MPLS L2 / L3VPN, GRE, VXLAN, VLAN, L2TP usw.
Natürlich gibt es auch Grenzfälle - wo soll MPLS LDP, BGP eingeschlossen werden? Ja, und Routing-Protokolle können für Clients verwendet werden. Das ist aber nicht wichtig.
Beide Arten von Diensten werden in Konfigurationsprimitive zerlegt:
- physische und logische Schnittstellen (tag / anteg, mtu)
- IP-Adressen und VRF (IP, IPv6, VRF)
- ACLs und Richtlinien zur Verkehrsbehandlung
- Protokolle (IGP, BGP, MPLS)
- Routing-Richtlinien (Präfixlisten, Community, ASN-Filter).
- Servicedienste (SSH, NTP, LLDP, Syslog ...)
- Usw.
Wie genau wir das machen werden, werde ich mir noch nicht überlegen. Wir werden in einem separaten Artikel behandeln.

Wenn etwas näher am Leben, dann könnten wir das beschreiben
Ein Leaf-Switch muss BGP-Sitzungen mit allen verbundenen Spine-Switches haben, verbundene Netzwerke in den Prozess importieren und nur Netzwerke mit einem bestimmten Präfix von Spine-Switches akzeptieren. Begrenzen Sie CoPP IPv6 ND auf 10 pps usw.
Spins halten wiederum Sitzungen mit allen verbundenen Mieder ab, die als Wurzelreflektoren fungieren, und empfangen von ihnen nur Routen einer bestimmten Länge und mit einer bestimmten Community.
Komponente 4. Geräteinitialisierungsmechanismus
Unter dieser Überschrift kombiniere ich die vielen Aktionen, die ausgeführt werden müssen, damit das Gerät auf Radargeräten angezeigt wird und remote zugegriffen werden kann.
- Starten Sie das Gerät im Inventarsystem.
- Markieren Sie die Verwaltungs-IP-Adresse.
- Konfigurieren Sie den Basiszugriff darauf:
Hostname, Verwaltungs-IP-Adresse, Route zum Verwaltungsnetzwerk, Benutzer, SSH-Schlüssel, Protokolle - Telnet / SSH / NETCONF
Es gibt drei Ansätze:
- Alles ist komplett manuell. Das Gerät wird an einen Stand gebracht, an dem eine normale organische Person ihn in das System führt, eine Verbindung zur Konsole herstellt und konfiguriert. Kann in kleinen statischen Netzwerken funktionieren.
- ZTP - Zero Touch Provisioning. Iron kam, stand auf, erhielt eine Adresse über DHCP, ging zu einem speziellen Server und konfigurierte sich selbst.
- Die Infrastruktur von Konsolenservern, bei der die Erstkonfiguration über den Konsolenport im automatischen Modus erfolgt.
Wir werden über alle drei in einem separaten Artikel sprechen.

Komponente 5. Herstellerunabhängiges Konfigurationsmodell
Bis jetzt waren alle Systeme verstreut und enthielten Variablen und eine deklarative Beschreibung dessen, was wir im Netzwerk sehen möchten. Aber früher oder später müssen Sie sich mit Einzelheiten befassen.
Zu diesem Zeitpunkt werden für jedes bestimmte Gerät Grundelemente, Dienste und Variablen zu einem Konfigurationsmodell kombiniert, das die vollständige Konfiguration eines bestimmten Geräts nur herstellerunabhängig beschreibt.
Was gibt diesen Schritt? Warum nicht sofort das Gerät konfigurieren, das Sie einfach ausfüllen können?
Auf diese Weise können wir drei Probleme lösen:
- Passen Sie sich nicht an eine bestimmte Schnittstelle für die Interaktion mit dem Gerät an. Ob CLI, NETCONF, RESTCONF, SNMP - das Modell ist das gleiche.
- Behalten Sie die Anzahl der Vorlagen / Skripte nicht nach der Anzahl der Anbieter im Netzwerk bei und ändern Sie sie im Falle einer Designänderung an mehreren Stellen.
- Laden Sie die Konfiguration vom Gerät herunter (Backup), legen Sie sie in genau demselben Modell an und vergleichen Sie direkt die Zielkonfiguration mit der Konfiguration, die für die Berechnung des Deltas und die Vorbereitung des Konfigurationspatches verfügbar ist. Dadurch werden nur die erforderlichen Teile geändert oder Abweichungen festgestellt.

Als Ergebnis dieser Phase erhalten wir eine herstellerunabhängige Konfiguration.
Komponente 6. Herstellerschnittstellenspezifischer Treiber
Trösten Sie sich nicht mit der Hoffnung, dass ein Tsiska, sobald Sie ihn konfigurieren können, genauso wie ein Jumper möglich ist, indem Sie ihm genau dieselben Anrufe senden. Trotz der wachsenden Beliebtheit von Whiteboxen und der zunehmenden Unterstützung für NETCONF, RESTCONF und OpenConfig unterscheiden sich die spezifischen Inhalte dieser Protokolle von Anbieter zu Anbieter, und dies ist einer ihrer Wettbewerbsunterschiede, die sie einfach nicht aufgeben.
Dies entspricht in etwa dem von OpenContrail und OpenStack, deren NorthBound-Schnittstelle RestAPI ist, und erwartet völlig unterschiedliche Aufrufe.
Im fünften Schritt sollte das herstellerunabhängige Modell die Form annehmen, in der es zum Bügeleisen gelangt.
Und hier sind alle Mittel gut (nein): CLI, NETCONF, RESTCONF, SNMP in einem einfachen Fall.
Daher benötigen wir einen Treiber, der das Ergebnis des vorherigen Schritts in das gewünschte Format für einen bestimmten Anbieter übersetzt: eine Reihe von CLI-Befehlen, eine XML-Struktur.
Komponente 7. Der Mechanismus zum Übermitteln der Konfiguration an das Gerät
Wir haben die Konfiguration generiert, sie muss jedoch noch an die Geräte geliefert werden - und natürlich nicht von Hand.Erstens stehen wir vor der Frage, welche Art von Transport wir verwenden werden. Und die Auswahl ist heute nicht mehr klein:- CLI (Telnet, SSH)
SNMP- NETCONF
- RESTCONF
- REST-API
- OpenFlow (obwohl es aus der Liste gestrichen wurde, da dies eine Möglichkeit ist, FIB zu liefern, nicht Einstellungen)
Lassen Sie uns hier mit e punktieren. CLI ist Vermächtnis. SNMP ... hehe.RESTCONF ist immer noch ein unbekanntes Tier, die REST-API wird von fast niemandem unterstützt. Daher konzentrieren wir uns in einer Schleife auf NETCONF.Wie der Leser bereits verstanden hatte, hatten wir uns zu diesem Zeitpunkt bereits für die Schnittstelle entschieden - das Ergebnis des vorherigen Schritts wurde bereits im Format der ausgewählten Schnittstelle dargestellt.Zweitens , mit welchen Tools werden wir dies tun?Auch hier ist die Auswahl groß:- Selbstgeschriebenes Skript oder Plattform. Wir rüsten uns mit ncclient und asyncIO aus und machen alles selbst. Was kostet es uns, ein Bereitstellungssystem von Grund auf neu zu erstellen?
- Ansible mit seiner umfangreichen Bibliothek an Netzwerkmodulen.
- Salt mit seiner mageren Netzwerkarbeit und Bündel mit Napalm.
- Eigentlich Napalm, der ein paar Anbieter kennt und das ist alles, tschüss.
- Nornir ist ein weiteres Tier, das wir für die Zukunft vorbereiten.
Es ist noch kein Favorit ausgewählt - wir werden stampfen.Was ist hier noch wichtig? Die Konsequenzen der Anwendung der Konfiguration.Erfolgreich oder nicht. Verbleibender Zugriff auf die Hardware oder nicht.Es scheint, dass Commit hier bei der Bestätigung und Validierung dessen helfen wird, was auf das Gerät heruntergeladen wurde.Dies, zusammen mit der korrekten Implementierung von NETCONF, schränkt den Bereich geeigneter Geräte erheblich ein - nicht viele Hersteller unterstützen normale Commits. Dies ist jedoch nur eine der Voraussetzungen für RFP . Am Ende ist niemand besorgt, dass kein einziger russischer Anbieter unter der Bedingung einer 32 * 100GE-Schnittstelle bestehen wird. Oder Sorgen?
Komponente 8. CI / CD
Zu diesem Zeitpunkt sind wir bereits für alle Netzwerkgeräte bereit.Ich schreibe "für alles", weil wir über die Versionierung des Netzwerkstatus sprechen. Und selbst wenn Sie die Einstellungen nur eines Switches ändern müssen, werden die Änderungen für das gesamte Netzwerk berechnet. Offensichtlich können sie für die meisten Knoten Null sein.Aber wie oben bereits erwähnt, sind wir keine Barbaren, um alles auf einmal in den Stoß zu rollen.Die generierte Konfiguration muss zuerst das Pipeline-CI / CD durchlaufen.CI/CD Continuous Integration, Continuous Deployment. , , , (Deployment) , , (Integration).
, , , , , , — .
, CI/CD Pipeline — .

Komponente 9. Sicherungs- und Ablehnungssystem
Nun, ich muss nicht noch einmal über Backups sprechen.Wir werden sie einfach entsprechend der Krone oder aufgrund einer Konfigurationsänderung im Git hinzufügen.Aber der zweite Teil ist interessanter - jemand sollte diese Backups im Auge behalten. Und in einigen Fällen muss dieser jemand alles so drehen, wie es war, und in anderen miaut jemand die Störung.Wenn beispielsweise ein neuer Benutzer in den Variablen nicht registriert ist, müssen Sie ihn aus dem Hack entfernen. Und wenn es besser ist, die neue Firewall-Regel nicht zu berühren, hat sich vielleicht jemand gerade beim Debuggen eingeschaltet, oder vielleicht hat sich ein neuer Dienst, ein Durcheinander, nicht gemäß den Regeln registriert, aber die Leute sind bereits dazu gegangen.Wir werden trotz Automatisierungssystemen und einer stählernen Hand des Managements immer noch nicht von einem bestimmten kleinen Delta auf der Skala des gesamten Netzwerks wegkommen. Um Probleme trotzdem zu debuggen, bringt niemand die Konfiguration auf das System. Darüber hinaus werden sie möglicherweise nicht einmal vom Konfigurationsmodell bereitgestellt.Zum Beispiel eine Firewall-Regel zum Zählen der Anzahl von Paketen auf einer bestimmten IP, zum Lokalisieren des Problems - eine ganz normale temporäre Konfiguration.

Komponente 10. Überwachungssystem
— , . , . .
— CI/CD. , , .
, — , , BGP-, OSPF-, End-to-End .
Aber haben die Syslogs auf dem externen Server aufgehört zu klappen, ist der SFlow-Agent ausgefallen, sind die Tropfen in den Warteschlangen gewachsen und ist die Verbindung zwischen zwei Präfixpaaren unterbrochen worden?In einem separaten Artikel reflektieren wir dies.
Fazit
Als Basis habe ich mich für eines der modernen Netzwerkdesigns für Rechenzentren entschieden - L3 Clos Fabric mit BGP als Routing-Protokoll.Dieses Mal werden wir ein Netzwerk auf Juniper aufbauen, da die JunOs-Schnittstelle jetzt ein Vanlav ist.Lassen Sie uns unser Leben nur mit Open Source-Tools und einem Netzwerk von mehreren Anbietern komplizieren. Daher werde ich neben Juniper auf dem Weg einen anderen Glückspilz auswählen.Der Plan für kommende Veröffentlichungensieht ungefähr so aus: Zuerst werde ich über virtuelle Netzwerke sprechen. Erstens, weil ich möchte, und zweitens, weil ohne dies das Design des Infrastrukturnetzwerks nicht sehr klar sein wird.Dann über das Netzwerkdesign selbst: Topologie, Routing, Richtlinien.Lassen Sie uns den Laborständer zusammenbauen.Lassen Sie uns darüber nachdenken und vielleicht üben, das Gerät im Netzwerk zu initialisieren.Und dann über jede Komponente in intimen Details.Und ja, ich verspreche nicht, diesen Zyklus elegant mit einer vorgefertigten Lösung zu beenden. :) :)
Nützliche Links
- Bevor Sie sich mit der Serie befassen, sollten Sie das Buch von Natasha Samoilenko Python für Netzwerktechniker lesen . Und vielleicht einen Kurs belegen .
- Es wird auch nützlich sein, den RFC über das Design von Rechenzentrumsfabriken von Facebook für die Urheberschaft von Peter Lapukhov zu lesen.
- In der Dokumentation zur Tungsten Fabric- Architektur (ehemals Open Contrail) erhalten Sie eine Vorstellung davon, wie das Overlay-SDN funktioniert .
Danke
Römische Schlucht. Für Kommentare und Änderungen.Artyom Chernobay. Für KDPV.