
In letzter Zeit gab es mehrere Artikel, in denen ImageNet kritisiert wurde, der vielleicht berühmteste Satz von Bildern, die zum Trainieren neuronaler Netze verwendet werden.
Im ersten Artikel funktioniert die Approximation von CNNs mit Modellen mit vielen lokalen Merkmalen in ImageNet überraschend gut. Die Autoren verwenden ein Modell, das dem Wort mit ähnlichen Wörtern ähnelt, und verwenden Fragmente aus dem Bild als „Wörter“. Diese Fragmente können bis zu 9 x 9 Pixel groß sein. Gleichzeitig erhalten die Autoren bei einem solchen Modell, bei dem Informationen über die räumliche Anordnung dieser Fragmente vollständig fehlen, eine Genauigkeit von 70 bis 86% (z. B. beträgt die Genauigkeit eines regulären ResNet-50 ~ 93%).
Im zweiten Artikel von ImageNet-trainierten CNNs sind die Autoren auf Textur ausgerichtet. Die Autoren kommen zu dem Schluss, dass der gesamte ImageNet-Datensatz und die Art und Weise, wie Menschen und neuronale Netze Bilder wahrnehmen, fehlerhaft sind, und schlagen die Verwendung eines neuen Datensatzes vor - Stylized-ImageNet.
Im Detail darüber, was Menschen in Bildern sehen und welche neuronalen Netze
ImageNet
Der ImageNet-Datensatz wurde 2006 von Professor Fei-Fei Li erstellt und entwickelt sich bis heute weiter. Derzeit enthält es etwa 14 Millionen Bilder, die zu mehr als 20.000 verschiedenen Kategorien gehören.
Seit 2010 wird eine Teilmenge dieses Datensatzes, bekannt als ImageNet 1K mit ~ 1 Million Bildern und Tausenden von Klassen, in der ImageNet Large Scale Visual Recognition Challenge (ILSVRC) verwendet. In diesem Wettbewerb schoss AlexNet, ein neuronales Faltungsnetzwerk, 2012 mit einer Top-1-Genauigkeit von 60% und einer Top-5-Genauigkeit von 80%.
In dieser Teilmenge des Datensatzes messen Personen aus dem akademischen Umfeld ihre SOTA, wenn sie neue Netzwerkarchitekturen anbieten.
Ein wenig über den Lernprozess in diesem Datensatz. Wir werden über das Trainingsprotokoll auf ImageNet im akademischen Umfeld sprechen. Das heißt, wenn uns die Ergebnisse eines SE-Block-, ResNeXt- oder DenseNet-Netzwerks im Artikel gezeigt werden, sieht der Prozess ungefähr so aus: Das Netzwerk lernt für 90 Epochen, die Lerngeschwindigkeit verringert sich als Optimierer alle 10 Mal um die 30. und 60. Epoche Es wird eine gewöhnliche SGD mit einem geringen Gewichtsabfall ausgewählt. Es werden nur RandomCrop und HorizontalFlip aus Erweiterungen verwendet. Die Bildgröße wird normalerweise auf 224 x 224 Pixel geändert.
Hier ist ein Beispiel für ein Pytorch-Skript für das Training in ImageNet.
BagNet
Kehren wir zu den zuvor erwähnten Artikeln zurück. Im ersten Fall wollten die Autoren ein Modell, das einfacher zu interpretieren ist als gewöhnliche tiefe Netzwerke. Inspiriert von der Idee der Bag-of-Feature-Modelle kreieren sie ihre eigene Modellfamilie - BagNets. Auf Basis des üblichen ResNet-50-Netzwerks.
Durch das Ersetzen einiger 3x3-Faltungen durch 1x1 in ResNet-50 wird sichergestellt, dass das Empfangsfeld von Neuronen auf der letzten Faltungsschicht bis zu 9x9 Pixel erheblich reduziert wird. Daher beschränken sie die Informationen, die einem einzelnen Neuron zur Verfügung stehen, auf ein sehr kleines Fragment des gesamten Bildes - einen Patch mit mehreren Pixeln. Es ist zu beachten, dass für das makellose ResNet-50 die Größe des Empfangsfelds mehr als 400 Pixel beträgt, wodurch das Bild vollständig abgedeckt wird, das normalerweise eine Größe von 224 x 224 Pixel hat.
Dieser Patch ist das maximale Fragment des Bildes, aus dem das Modell räumliche Daten extrahieren kann. Am Ende des Modells wurden alle Daten einfach zusammengefasst und das Modell konnte in keiner Weise wissen, wo sich die einzelnen Patches im Verhältnis zu anderen Patches befinden.
Insgesamt wurden drei Varianten von Netzwerken mit den Empfangsfeldern 9x9, 17x17 und 33x33 getestet. Und trotz des völligen Mangels an räumlichen Informationen konnten solche Modelle eine gute Genauigkeit bei der Klassifizierung in ImageNet erzielen. Die Top-5-Genauigkeit für Patches 9x9 betrug 70%, für 17x17 - 80%, für 33x33 - 86%. Zum Vergleich beträgt die ResNet-50 Top-5-Genauigkeit ungefähr 93%.

Die Struktur des Modells ist in der obigen Abbildung dargestellt. Jeder Patch aus qxqx3 Pixeln, der aus dem Bild ausgeschnitten wurde, wird vom Netzwerk in einen 2048-Vektor umgewandelt. Als nächstes wird dieser Vektor dem Eingang eines linearen Klassifikators zugeführt, der für jede der 1000 Klassen Punktzahlen erzeugt. Durch Sammeln der Ergebnisse jedes Patches in einem 2D-Array können Sie eine Heatmap für jede Klasse und jedes Pixel des Originalbilds erhalten. Die endgültigen Ergebnisse für das Bild wurden durch Summieren der Heatmap jeder Klasse erhalten.
Beispiele für Heatmaps für einige Klassen:

Wie Sie sehen können, leisten Patches an den Rändern von Objekten den größten Beitrag zum Nutzen einer bestimmten Klasse. Patches aus dem Hintergrund werden fast ignoriert. Bisher läuft alles gut.
Schauen wir uns die informativsten Patches an:

Zum Beispiel nahmen die Autoren vier Klassen. Für jeden von ihnen wurden 2x7 signifikanteste Patches ausgewählt (dh Patches, bei denen die Punktzahl dieser Klasse am höchsten war). Die obere Reihe von 7 Patches wird nur aus Bildern der entsprechenden Klasse entnommen, die untere aus dem gesamten Bildbeispiel.
Was auf diesen Bildern zu sehen ist, ist bemerkenswert. Beispielsweise sind für die Schleienklasse (Schleie, Fisch) Finger ein charakteristisches Merkmal. Ja, gewöhnliche menschliche Finger auf grünem Hintergrund. Und das alles, weil es in fast allen Bildern einen Fischer dieser Klasse gibt, der diesen Fisch tatsächlich in den Händen hält und eine Trophäe vorführt.
Ein charakteristisches Merkmal von Laptops sind die Buchstabentasten. Schreibmaschinentasten zählen auch für diese Klasse.
Ein charakteristisches Merkmal eines Buchumschlags sind Buchstaben auf farbigem Hintergrund. Lassen Sie es sogar eine Inschrift auf einem T-Shirt oder auf einer Tasche sein.
Es scheint, dass dieses Problem uns nicht stören sollte. Da es nur einer engen Klasse von Netzwerken mit einem sehr begrenzten Empfangsfeld inhärent ist. Darüber hinaus berechneten die Autoren die Korrelation zwischen Protokollen (Netzwerkausgaben vor dem endgültigen Softmax), die jeder BagNet-Klasse mit unterschiedlichem Empfangsfeld zugewiesen wurden, und Protokollen von VGG-16, das ein ziemlich großes Empfangsfeld aufweist. Und sie fanden sie ziemlich hoch.
Korrelation zwischen BagNets und VGG-16 Die Autoren fragten sich, ob BagNet Hinweise darauf enthält, wie andere Netzwerke Entscheidungen treffen.
Für einen der Tests verwendeten sie eine Technik wie Image Scrambling. Was darin bestand, einen Texturgenerator zu verwenden, der auf Gramm-Matrizen basiert , um ein Bild zu erstellen, in dem Texturen gespeichert werden, aber räumliche Informationen fehlen.

VGG-16, trainiert auf gewöhnlichen, vollwertigen Bildern, kam mit solchen durcheinandergemischten Bildern ziemlich gut zurecht. Die Top-5-Genauigkeit sank von 90% auf 80%. Das heißt, selbst Netzwerke mit einem ziemlich großen Empfangsfeld bevorzugen es immer noch, sich Texturen zu merken und räumliche Informationen zu ignorieren. Daher fiel ihre Genauigkeit bei verschlüsselten Bildern nicht stark ab.
Die Autoren führten eine Reihe von Experimenten durch, in denen sie verglichen, welche Teile der Bilder für BagNet und andere Netzwerke (VGG-16, ResNet-50, ResNet-152 und DenseNet-169) am wichtigsten sind. Alles deutete darauf hin, dass andere Netzwerke wie BagNet auf kleine Bildfragmente angewiesen sind und bei Entscheidungen etwa dieselben Fehler machen. Dies machte sich insbesondere bei nicht sehr tiefen Netzwerken wie VGG bemerkbar.
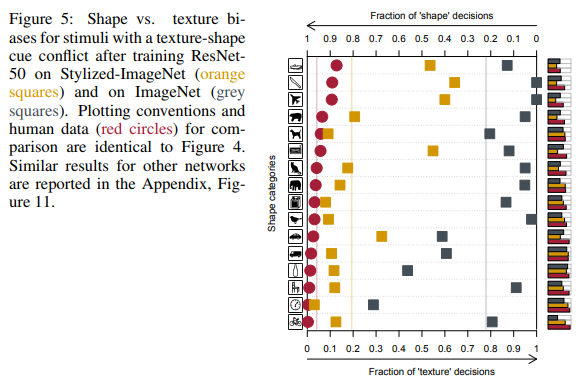
Diese Tendenz von Netzwerken, Entscheidungen auf der Grundlage von Texturen zu treffen, veranlasste im Gegensatz zu uns Menschen, die Form bevorzugen (siehe Abbildung unten), die Autoren des zweiten Artikels, einen neuen Datensatz auf der Basis von ImageNet zu erstellen.
Stilisiertes ImageNet
Zunächst erstellten die Autoren des Artikels mithilfe der Stilübertragung eine Reihe von Bildern, bei denen sich Form (räumliche Daten) und Texturen in einem Bild widersprachen. Und wir verglichen die Ergebnisse von Menschen und tiefen Faltungsnetzwerken verschiedener Architekturen mit einem synthetisierten Datensatz aus 16 Klassen.

Ganz rechts sehen die Menschen eine Katze, ein Netzwerk - einen Elefanten.

Vergleich der Ergebnisse von Menschen und neuronalen Netzen.
Wie Sie sehen können, stützten sich Personen beim Zuweisen eines Objekts zu einer bestimmten Klasse auf die Form von Objekten, neuronale Netze auf Texturen. In der Abbildung oben sahen die Menschen eine Katze, ein Netzwerk - einen Elefanten.
Ja, hier kann man daran bemängeln, dass die Netze auch etwas richtig sind und dies zum Beispiel ein Elefant sein könnte, der aus nächster Nähe mit einem Tattoo einer geliebten Katze fotografiert wurde. Aufgrund der Tatsache, dass sich die Netzwerke bei Entscheidungen anders verhalten als die Menschen, haben die Autoren das Problem in Betracht gezogen und nach Wegen gesucht, es zu lösen.
Wie oben erwähnt, kann das Netzwerk nur mit Texturen ein gutes Ergebnis bei einer Top-5-Genauigkeit von 86% erzielen. Dabei geht es nicht um mehrere Klassen, in denen Texturen helfen, Bilder korrekt zu klassifizieren, sondern um die meisten Klassen.
Das Problem liegt in ImageNet selbst, da später gezeigt wird, dass das Netzwerk die Form lernen kann, dies jedoch nicht, da Texturen für diesen Datensatz ausreichen und sich die für die Texturen verantwortlichen Neuronen auf flachen Schichten befinden. die sind viel einfacher zu trainieren.
Mit diesem etwas anderen AdaIN-Schnellübertragungsmechanismus erstellten die Autoren einen neuen Datensatz - Stylized ImageNet. Die Form der Objekte wurde aus ImageNet übernommen und die Texturen aus diesem Wettbewerb auf Kaggle . Das Skript zur Generierung ist unter dem Link verfügbar.

Der Kürze halber wird ImageNet als IN , Stylized ImageNet als SIN bezeichnet .
Die Autoren nahmen ResNet-50 und drei BagNet mit unterschiedlichem Empfangsfeld und trainierten für jeden Datensatz ein eigenes Modell.
Und hier ist, was sie getan haben:
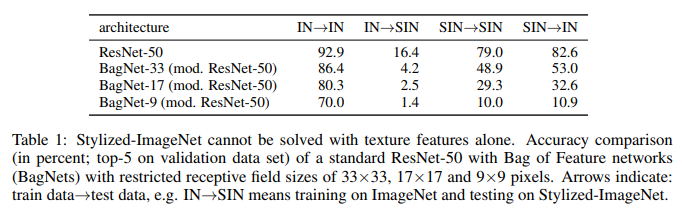
Was wir hier sehen. Auf IN trainiertes ResNet-50 ist auf SIN vollständig außer Gefecht gesetzt. Dies bestätigt teilweise, dass sich das Netzwerk beim Training auf IN an Texturen anpasst und die Form von Objekten ignoriert. Gleichzeitig kommt das auf SIN trainierte ResNet-50 sowohl mit SIN als auch mit IN perfekt zurecht. Das heißt, wenn ihm ein einfacher Pfad entzogen wird, folgt das Netzwerk einem schwierigen Pfad - es lehrt die Form von Objekten.
BagNet hat endlich begonnen, sich wie erwartet zu verhalten, insbesondere bei kleinen Patches, da es nichts zu klammern hat - Texturinformationen fehlen einfach in der SIN.
In diesen 16 Klassen, die zuvor erwähnt wurden, begann ResNet-50, das auf SIN geschult war, Antworten zu geben, die denen ähnlicher waren, die die Leute gaben:
Zusätzlich zum einfachen Training von ResNet-50 auf SIN versuchten die Autoren, das Netzwerk auf einem gemischten Satz von SIN und IN zu trainieren, einschließlich der separaten Feinabstimmung auf reinem IN.

Wie Sie sehen, haben sich bei Verwendung von SIN + IN für das Training die Ergebnisse nicht nur bei der Hauptaufgabe - der Bildklassifizierung in ImageNet - verbessert, sondern auch bei der Erkennung von Objekten im PASCAL VOC 2007-Dataset.
Darüber hinaus sind von SIN trainierte Netzwerke widerstandsfähiger gegen verschiedene Datenstörungen.
Fazit
Selbst jetzt, im Jahr 2019, nach sieben Jahren des Erfolgs mit AlexNet, als neuronale Netze in der Bildverarbeitung weit verbreitet sind und ImageNet 1K de facto zum Standard für die Bewertung der Leistung von Modellen im akademischen Umfeld wurde, ist der Mechanismus, wie neuronale Netze Entscheidungen treffen, nicht ganz klar . Und wie die Datensätze, auf denen diese Netzwerke trainiert wurden, dies beeinflussen.
Die Autoren des ersten Artikels versuchten zu beleuchten, wie solche Entscheidungen in Netzwerken mit einer Bag-of-Features-Architektur mit einem begrenzten Empfangsfeld getroffen werden, das leichter zu interpretieren ist. Beim Vergleich der Antworten von BagNet und den üblichen tiefen neuronalen Netzen kamen wir zu dem Schluss, dass die Entscheidungsprozesse in ihnen ziemlich ähnlich sind.
Die Autoren des zweiten Artikels verglichen, wie Menschen und neuronale Netze Bilder wahrnehmen, in denen sich Form und Textur widersprechen. Und sie schlugen vor, ein neues Dataset, Stylized ImageNet, zu verwenden, um Wahrnehmungsunterschiede zu verringern. Als Bonus eine Erhöhung der Genauigkeit der Klassifizierung in ImageNet und der Erkennung in Datensätzen von Drittanbietern erhalten.
Die Hauptschlussfolgerung kann wie folgt gezogen werden: Netzwerke, die aus Bildern lernen und sich an übergeordnete räumliche Eigenschaften von Objekten erinnern können, bevorzugen einen einfacheren Weg, um das Ziel zu erreichen - eine Überanpassung an Texturen. Wenn der Datensatz, auf dem sie trainieren, dies zulässt.
Neben dem akademischen Interesse ist das Problem der Texturüberanpassung für alle von uns wichtig, die vorgefertigte Modelle für das Transferlernen in ihren Aufgaben verwenden.
Eine wichtige Konsequenz all dessen ist für uns, dass Sie dem Gewicht von Modellen, die im Allgemeinen in ImageNet vorab trainiert wurden, nicht vertrauen sollten, da für die meisten von ihnen relativ einfache Erweiterungen verwendet wurden, die in keiner Weise dazu beitragen, Überanpassungen zu beseitigen. Und wenn möglich, ist es besser, Modelle mit ernsthafteren Erweiterungen oder stilisiertem ImageNet + ImageNet im Nest trainieren zu lassen. Um immer vergleichen zu können, welches für unsere aktuelle Aufgabe am besten geeignet ist.