
Viele Menschen sind es gewohnt, einen Film nach dem Anschauen bei KinoPoisk oder imdb zu bewerten, und die Abschnitte „Auch mit diesem Produkt gekauft“ und „Beliebte Produkte“ befinden sich in jedem Online-Shop. Es gibt jedoch weniger bekannte Arten von Empfehlungen. In diesem Artikel werde ich darüber sprechen, welche Aufgaben von Empfehlungssystemen empfohlen werden, wo sie ausgeführt werden sollen und was googeln soll.
Was empfehlen wir?
Was ist, wenn wir eine
Route empfehlen möchten, die
für den Benutzer angenehm ist? Verschiedene Aspekte der Reise sind für verschiedene Benutzer wichtig: Verfügbarkeit von Sitzplätzen, Reisezeit, Verkehr, Klimaanlage, eine schöne Aussicht aus dem Fenster. Eine ungewöhnliche Aufgabe, aber es ist ziemlich klar, wie man ein solches System baut.
Was ist, wenn wir die
Nachrichten empfehlen? Nachrichten werden schnell veraltet - Sie müssen den Benutzern die neuesten Artikel anzeigen, solange sie noch relevant sind. Es ist notwendig, den Inhalt des Artikels zu verstehen. Schon schwieriger.
Und wenn wir
Restaurants empfehlen, die auf Bewertungen basieren? Wir empfehlen aber nicht nur das Restaurant, sondern auch spezielle Gerichte, die einen Versuch wert sind. Sie können Restaurants auch Empfehlungen geben, was es wert ist, verbessert zu werden.
Was ist, wenn wir
die Aufgabe erweitern und versuchen, die Frage zu beantworten: "Welches Produkt wird für die größte Gruppe von Menschen von Interesse sein?" Es wird sehr ungewöhnlich und es ist nicht sofort klar, wie dies gelöst werden kann.
Tatsächlich gibt es viele Variationen der Empfehlungsaufgabe und jede hat ihre eigenen Nuancen. Sie können völlig unerwartete Dinge empfehlen. Mein Lieblingsbeispiel ist die Empfehlung von
Vorschauen auf Netflix .

Engere Aufgabe
Nehmen Sie die vertraute und vertraute Aufgabe an, Musik zu empfehlen. Was genau möchten wir empfehlen?

Auf dieser Collage finden Sie Beispiele für verschiedene Empfehlungen von Spotify, Google und Yandex.
- Hervorheben homogener Interessen im Daily Mix
- Personalisierte Pressemitteilung Radar, Empfohlene Neuerscheinungen, Premiere
- Persönliche Auswahl dessen, was Ihnen gefällt - Playlist des Tages
- Persönliche Auswahl von Titeln, die der Benutzer noch nicht gehört hat - Discover Weekly, Dejavu
- Eine Kombination der beiden vorherigen Punkte mit einer Tendenz in neuen Tracks - I'm Feeling Lucky
- Befindet sich in der Bibliothek, aber noch nicht gehört - Cache
- Deine Top Songs 2018
- Die Tracks, die Sie im Alter von 14 Jahren gehört haben und die Ihren Geschmack geprägt haben - Your Time Capsule
- Tracks, die Ihnen gefallen könnten, sich aber von denen unterscheiden, die der Benutzer normalerweise hört - Taste Breaker
- Tracks von Künstlern, die in Ihrer Stadt auftreten
- Stilsammlungen
- Aktivitäts- und Stimmungsauswahl
Und sicher können Sie sich etwas anderes einfallen lassen. Auch wenn wir absolut vorhersagen können, welche Tracks dem Benutzer gefallen, bleibt die Frage, in welcher Form und in welchem Layout sie ausgegeben werden sollen.
Klassische Inszenierung
In der klassischen Problemstellung haben wir lediglich eine Bewertungsmatrix für Benutzerelemente. Es ist sehr spärlich und unsere Aufgabe ist es, die fehlenden Werte auszufüllen. Normalerweise wird der RMSE der vorhergesagten Bewertung als Metrik verwendet. Es besteht jedoch die
Ansicht, dass dies nicht vollständig korrekt ist und die Merkmale der Empfehlung als Ganzes berücksichtigt werden sollten und nicht die Genauigkeit der Vorhersage einer bestimmten Zahl.
Wie bewerte ich die Qualität?
Online-Bewertung
Die am besten geeignete Methode zur Bewertung der Systemqualität ist die direkte Überprüfung der Benutzer im Kontext von Geschäftsmetriken. Dies kann die Klickrate, die im System verbrachte Zeit oder die Anzahl der Einkäufe sein. Experimente mit Benutzern sind jedoch teuer, und ich möchte selbst einer kleinen Gruppe von Benutzern keinen schlechten Algorithmus zur Verfügung stellen. Daher verwenden sie vor dem Online-Test Offline-Qualitätsmetriken.
Offline-Bewertung
Ranking-Metriken wie MAP @ k und nDCG @ k werden normalerweise als Qualitätsmetriken verwendet.
Relevance im Kontext von
MAP@k ist ein Binärwert, und im Kontext von
nDCG@k kann es eine Bewertungsskala geben.
Zusätzlich zur Genauigkeit der Vorhersage könnten wir aber auch an anderen Dingen interessiert sein:
- overage - der Anteil der Waren, der vom Empfehlungsgeber ausgegeben wird,
- Personalisierung - wie unterschiedlich sind Empfehlungen zwischen Benutzern,
- Vielfalt - wie vielfältig die Produkte innerhalb der Empfehlung sind.
Im Allgemeinen gibt es eine gute Überprüfung der Metriken.
Wie gut ist Ihr Empfehlungssystem? Eine Umfrage zu Bewertungen in Empfehlung . Ein Beispiel für die Formalisierung von Neuheitsmetriken finden Sie unter
Rang und Relevanz in Neuheits- und Diversitätsmetriken für Empfehlungssysteme .
Daten
Explizites Feedback
Die Bewertungsmatrix ist ein Beispiel für explizite Daten. Wie, nicht wie, Bewertung - der Benutzer selbst hat den Grad seines Interesses an dem Artikel klar zum Ausdruck gebracht. Solche Daten sind normalerweise knapp. Beispielsweise haben bei der
Rekko-Herausforderung in den Testdaten nur 34% der Benutzer mindestens eine Note.
Implizites Feedback
Es gibt viel mehr Informationen über implizite Einstellungen - Ansichten, Klicks, Lesezeichen, Einrichten von Benachrichtigungen. Aber wenn der Benutzer den Film gesehen hat, bedeutet dies nur, dass ihm der Film vor dem Anschauen interessant genug erschien. Wir können keine direkten Schlussfolgerungen darüber ziehen, ob der Film gefallen hat oder nicht.
Verlustfunktionen zum Lernen
Um implizites Feedback zu nutzen, haben wir geeignete Lehrmethoden entwickelt.
Bayesianisches personalisiertes Ranking
Originalartikel .
Es ist bekannt, mit welchen Elementen der Benutzer interagiert hat. Wir gehen davon aus, dass dies positive Beispiele sind, die ihm gefallen haben. Es gibt noch viele Elemente, mit denen der Benutzer nicht interagiert hat. Wir wissen nicht, welche davon für den Benutzer von Interesse sind und welche nicht, aber wir wissen sicherlich, dass sich nicht alle dieser Beispiele als positiv herausstellen werden. Wir machen eine grobe Verallgemeinerung und betrachten das Fehlen von Interaktion als negatives Beispiel.
Wir werden Tripel {Benutzer, positiver Gegenstand, negativer Gegenstand} abtasten und das Modell in Ordnung bringen, wenn ein negatives Beispiel höher als ein positives bewertet wird.
Paarweise gewichteter ungefährer Rang
Fügen Sie der vorherigen Idee eine adaptive Lernrate hinzu. Wir werden das Training des Systems anhand der Anzahl der Stichproben bewerten, die wir durchsehen mussten, um ein negatives Beispiel für das gegebene Paar {Benutzer, positives Beispiel} zu finden, das das System höher als positiv bewertet hat.
Wenn wir ein solches Beispiel zum ersten Mal gefunden haben, sollte die Geldstrafe hoch sein. Wenn Sie lange suchen mussten, dann funktioniert das System bereits gut und Sie müssen nicht so viel Geld verdienen.
Woran sollte man noch denken?
Kaltstart
Sobald wir gelernt haben, Vorhersagen für bestehende Benutzer und Produkte zu treffen, stellen sich zwei Fragen: „Wie kann man ein Produkt empfehlen, das noch niemand gesehen hat?“ und "Was soll ich einem Benutzer empfehlen, der noch keine einzige Bewertung hat?". Um dieses Problem zu lösen, versuchen sie, Informationen aus anderen Quellen zu extrahieren. Dies können Daten über einen Benutzer aus anderen Diensten, ein Fragebogen während der Registrierung oder Informationen zu einem Artikel aus dessen Inhalten sein.
In diesem Fall gibt es Aufgaben, bei denen der Zustand eines Kaltstarts konstant ist. In sitzungsbasierten Empfehlern müssen Sie Zeit haben, um während der Zeit, in der er sich auf der Site befindet, etwas über den Benutzer zu verstehen. In den Empfehlungen von Nachrichten oder Modeprodukten erscheinen ständig neue Artikel, während alte Artikel schnell veraltet sind.
Langer Schwanz
Wenn wir für jedes Element seine Beliebtheit in Form der Anzahl der Benutzer berechnen, die mit ihm interagiert oder eine positive Bewertung abgegeben haben, erhalten wir sehr oft eine Grafik wie im Bild:
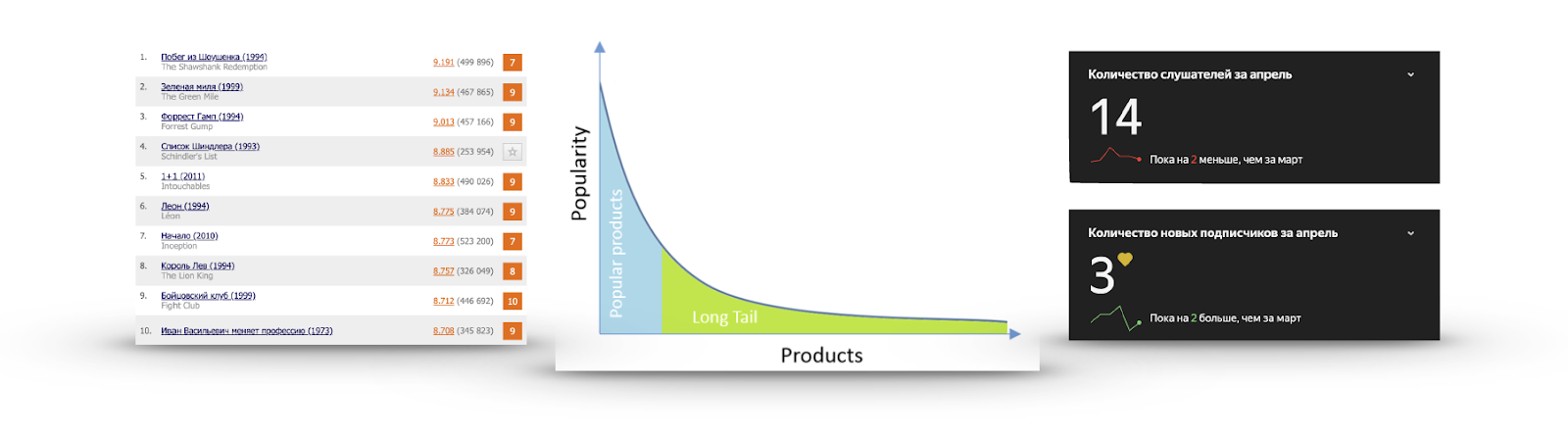
Es gibt eine sehr kleine Anzahl von Gegenständen, die jeder kennt. Es macht keinen Sinn, sie zu empfehlen, da der Benutzer sie höchstwahrscheinlich bereits gesehen und einfach keine Bewertung abgegeben hat, entweder über sie Bescheid weiß und sie sehen wird oder fest entschlossen ist, sie überhaupt nicht anzusehen. Ich habe den Trailer von Schindlers Liste mehr als einmal gesehen, aber ich wollte ihn nicht sehen.
Andererseits nimmt die Popularität sehr schnell ab, und fast niemand hat die überwiegende Mehrheit der Artikel gesehen. Empfehlungen aus diesem Teil sind nützlicher: Es gibt interessante Inhalte, die der Benutzer wahrscheinlich nicht selbst findet. Auf der rechten Seite sehen Sie beispielsweise die Hörstatistik einer meiner Lieblingsgruppen auf Yandex.Music.
Exploration vs Exploitation
Nehmen wir an, wir wissen genau, was der Benutzer mag. Bedeutet dies, dass wir dasselbe empfehlen sollten? Es besteht das Gefühl, dass solche Empfehlungen schnell langweilig werden und es sich manchmal lohnt, etwas Neues zu zeigen. Wenn wir empfehlen, was genau gefallen soll, ist Ausbeutung. Wenn wir versuchen, den Empfehlungen etwas weniger Populäres hinzuzufügen oder sie irgendwie zu diversifizieren, ist dies eine Erkundung. Ich möchte diese Dinge ausbalancieren.
Nicht personalisierte Empfehlungen
Am einfachsten ist es, jedem das Gleiche zu empfehlen.
Nach Beliebtheit sortieren
Punktzahl = (Positive Bewertungen) - (Negative Bewertungen)
Sie können Abneigungen von Likes subtrahieren und sie sortieren. In diesem Fall berücksichtigen wir jedoch nicht deren prozentuales Verhältnis. Es besteht das Gefühl, dass 200 Likes von 50 Abneigungen nicht mit 1200 Likes und 1050 Abneigungen identisch sind.
Punktzahl = (Positive Bewertungen) / (Gesamtbewertung)
Sie können die Anzahl der Likes durch die Anzahl der Abneigungen teilen. In diesem Fall berücksichtigen wir jedoch nicht die Anzahl der Bewertungen. Ein Produkt mit einer Bewertung von 5 Punkten wird höher eingestuft als ein sehr beliebtes Produkt mit einer durchschnittlichen Bewertung von 4,8.
Wie kann man
nicht nach der Durchschnittsbewertung sortieren und die Anzahl der Bewertungen berücksichtigen? Berechnen Sie das Konfidenzintervall: "Ist die Wahrscheinlichkeit einer 95% igen Wahrscheinlichkeit des tatsächlichen Anteils positiver Bewertungen auf der Grundlage der verfügbaren Schätzungen mindestens was?" Die Antwort auf diese Frage gab Edwin Wilson 1927.
- beobachteter Anteil positiver Bewertungen
- 1-Alpha-Quantil der Normalverteilung
Kompatibilität
Die Auswahl häufig vorkommender Produktgruppen umfasst eine ganze Gruppe von Pattern-Mining-Aufgaben:
periodisches Pattern-Mining ,
sequentielles Rule-Mining ,
sequentielles Pattern-Mining ,
High-Utility-Item-Set-Mining ,
häufiges Item-Set-Mining (Warenkorbanalyse) . Jede spezifische Aufgabe hat ihre eigenen
Methoden , aber wenn sie grob verallgemeinert sind, führen Algorithmen zum Finden häufiger Mengen eine verkürzte Breitensuche durch, um offensichtlich schlechte Optionen nicht zu sortieren.
Seltene Mengen werden an der angegebenen Grenzunterstützung abgeschnitten - der Anzahl oder Häufigkeit des Auftretens der Menge in den Daten.
Nach dem Hervorheben der häufigen Elementmenge wird die Qualität ihrer Abhängigkeit anhand der Metriken Lift oder Confindence (a, b) / Confidence (! A, b) bewertet. Sie zielen darauf ab, falsche Abhängigkeiten zu beseitigen.
Zum Beispiel finden sich Bananen oft zusammen mit Konserven im Einkaufskorb. Der Punkt liegt jedoch nicht in einem besonderen Zusammenhang, sondern in der Tatsache, dass Bananen an sich beliebt sind, und dies sollte bei der Suche nach Streichhölzern berücksichtigt werden.
Personalisierte Empfehlungen
Inhaltsbasiert
Die Idee eines inhaltsbasierten Ansatzes besteht darin, für ihn einen Vektor seiner Präferenzen im Raum von Objekten basierend auf der Historie der Benutzeraktionen zu erstellen und Produkte zu empfehlen, die diesem Vektor nahe kommen.
Das heißt, der Artikel sollte eine charakteristische Beschreibung haben. Dies können beispielsweise Genres von Filmen sein. Die Geschichte der Vorlieben und Abneigungen von Filmen bildet einen Vektor der Präferenz,
einige Genres hervorheben und andere vermeiden. Durch Vergleichen des Benutzervektors und des Artikelvektors können Sie ein Ranking erstellen und Empfehlungen erhalten.
Kollaboratives Filtern

Die kollaborative Filterung setzt eine Bewertungsmatrix für Benutzerelemente voraus. Die Idee ist, für jeden Benutzer die ähnlichsten „Nachbarn“ zu finden und die Lücken eines bestimmten Benutzers zu füllen, indem die Bewertungen der „Nachbarn“ gemittelt werden.
In ähnlicher Weise können Sie die Ähnlichkeit von Elementen betrachten und glauben, dass ähnliche Elemente von ähnlichen Personen gemocht werden. Technisch gesehen ist dies lediglich eine Betrachtung der transponierten Schätzmatrix.
Benutzer verwenden die Bewertungsskala anders - jemand setzt sie nie über acht und jemand verwendet die gesamte Skala. Dies ist nützlich, um dies zu berücksichtigen, und daher ist es möglich, nicht die Bewertung selbst vorherzusagen, sondern eine Abweichung von der durchschnittlichen Bewertung.
Oder Sie können die Schätzungen im Voraus normalisieren.
Matrixfaktorisierung
Aus der Mathematik
wissen wir, dass jede Matrix in das Produkt von drei Matrizen zerlegt werden kann. Die Bewertungsmatrix ist jedoch sehr spärlich, 99% sind an der Tagesordnung. Und SVD weiß nicht, was Lücken sind. Es ist nicht sehr wünschenswert, sie mit einem Durchschnittswert zu füllen. Und im Allgemeinen sind wir nicht sehr an der Matrix singulärer Werte interessiert - wir möchten nur eine versteckte Ansicht von Benutzern und Objekten erhalten, die sich bei Multiplikation der tatsächlichen Bewertung annähert. Sie können sofort in zwei Matrizen zerlegen.
Was tun mit Pässen? Hammer auf sie. Es stellte sich heraus, dass Sie mithilfe von SGD oder ALS auf ungefähre Bewertungen anhand der RMSE-Metrik trainieren können, wobei Auslassungen insgesamt ignoriert werden. Der erste derartige Algorithmus ist
Funk SVD , der 2006 im Zuge der Lösung der Konkurrenz durch Netflix erfunden wurde.
Netflix-Preis
Netflix-Preis - eine bedeutende Veranstaltung, die der Entwicklung von Empfehlungssystemen starke Impulse verlieh. Ziel des Wettbewerbs ist es, das bestehende Cinematch RMSE-Empfehlungssystem um 10% zu überholen. Zu diesem Zweck wurde zu diesem Zeitpunkt ein großer Datensatz mit 100 Millionen Bewertungen bereitgestellt. Die Aufgabe mag nicht so schwierig erscheinen, aber um die erforderliche Qualität zu erreichen, musste der Wettbewerb zweimal neu entdeckt werden - eine Lösung wurde nur für drei Jahre des Wettbewerbs erhalten. Wenn es notwendig wäre, eine Verbesserung von 15% zu erzielen, wäre dies mit den bereitgestellten Daten möglicherweise nicht möglich gewesen.
Während des Wettbewerbs wurden
einige interessante Merkmale in den Daten gefunden. Die Grafik zeigt die durchschnittliche Bewertung von Filmen in Abhängigkeit vom Datum, an dem sie im Netflix-Katalog erscheinen. Die offensichtliche Lücke hängt mit der Tatsache zusammen, dass Netflix zu diesem Zeitpunkt von einer objektiven Skala (ein schlechter Film, ein guter Film) zu einer subjektiven Skala wechselte (es hat mir nicht gefallen, es hat mir sehr gut gefallen). Menschen sind weniger kritisch, wenn sie ihre Einschätzung ausdrücken, als ein Objekt zu charakterisieren.
Diese Grafik zeigt, wie sich die durchschnittliche Filmbewertung nach der Veröffentlichung ändert. Es ist ersichtlich, dass über 2000 Tage die Punktzahl um 0,2 steigt. Das heißt, nachdem der Film nicht mehr neu ist, beginnen diejenigen, die ziemlich zuversichtlich sind, dass er den Film mögen wird, was die Bewertung erhöht, ihn anzuschauen.
Der erste Zwischenpreis wurde von einem Team von Spezialisten von AT & T - Korbell vergeben. Nach 2000 Stunden Arbeit und der Zusammenstellung eines Ensembles von 107 Algorithmen gelang es ihnen, eine Verbesserung von 8,43% zu erzielen.
Unter den Modellen befand sich eine Variation von SVD und RBM, die an sich den größten Teil des Inputs lieferten. Die verbleibenden 105 Algorithmen verbesserten nur ein Hundertstel der Metrik. Netflix hat diese beiden Algorithmen an seine Datenmengen angepasst und verwendet sie weiterhin als Teil des Systems.
Im zweiten Jahr des Wettbewerbs schlossen sich die beiden Teams zusammen und nun wurde der Preis von Bellkor in BigChaos entgegengenommen. Sie griffen insgesamt 207 Algorithmen an und verbesserten die Genauigkeit um ein Hundertstel und erreichten einen Wert von 0,8616. Die geforderte Qualität wird immer noch nicht erreicht, aber es ist bereits klar, dass nächstes Jahr alles klappen sollte.
Drittes Jahr. Kombiniere dich mit einem weiteren Team, benenne Bellkors Pragmatic Chaos um und erreiche die erforderliche Qualität, die dem Ensemble etwas unterlegen ist. Dies ist jedoch nur der öffentliche Teil des Datensatzes.
Auf der versteckten Seite stellte sich heraus, dass die Genauigkeit dieser Teams mit der vierten Dezimalstelle übereinstimmt, sodass der Gewinner durch eine Differenz von 20 Minuten ermittelt wurde.
Netflix zahlte die versprochene Million an die Gewinner,
nutzte die daraus resultierende Lösung jedoch nie. Die Implementierung des Ensembles erwies sich als zu teuer, und es hat keinen großen Nutzen daraus - schließlich bieten bereits zwei Algorithmen den größten Teil der Genauigkeitssteigerung. Und vor allem: Zum Zeitpunkt des Wettbewerbsendes im Jahr 2009 hatte Netflix bereits begonnen, seinen Streaming-Service zu nutzen und zusätzlich eine DVD für zwei Jahre auszuleihen. Sie hatten viele andere Aufgaben und Daten, die sie in ihrem System verwenden konnten. Der DVD-Mail-Verleih bedient jedoch immer
noch 2,7 Millionen zufriedene Abonnenten .
Neuronale Netze
In modernen Empfehlungssystemen stellt sich häufig die Frage, wie verschiedene explizite und implizite Informationsquellen berücksichtigt werden können. Oft gibt es zusätzliche Daten über den Benutzer oder das Element, die Sie verwenden möchten. Neuronale Netze sind eine gute Möglichkeit, solche Informationen zu berücksichtigen.
Bei der Verwendung von Netzwerken für Empfehlungen sollten Sie auf die Überprüfung des auf
Deep Learning basierenden Empfehlungssystems achten
: Eine Umfrage und neue Perspektiven . Es werden Beispiele für die Verwendung einer großen Anzahl von Architekturen für verschiedene Aufgaben beschrieben.
Es gibt viele Architekturen und Ansätze. Einer der wiederholten Namen ist
DSSM . Ich möchte auch
Attentive Collaborative Filtering erwähnen.
ACF schlägt vor, zwei Dämpfungsstufen einzuführen:
- Selbst bei gleichen Bewertungen tragen einige Elemente mehr zu Ihren Vorlieben bei als andere.
- Elemente sind nicht atomar, sondern bestehen aus Komponenten. Einige haben einen größeren Einfluss auf die Bewertung als andere. Der Film kann nur aufgrund der Anwesenheit eines Lieblingsschauspielers interessant sein.
Mehrarmige Banditen sind eines der beliebtesten Themen der letzten Zeit. Was mehrarmige Banditen sind, kann in einem Artikel über
Habré oder über das
Medium gelesen werden.
Bei Anwendung auf Empfehlungen klingt die Aufgabe "Kontext-Bandit" ungefähr so: "Wir geben die Benutzer- und Elementkontextvektoren an die Eingabe des Systems weiter. Wir möchten die Wahrscheinlichkeit einer Interaktion (Klicks, Käufe) für alle Benutzer im Laufe der Zeit maximieren und die Empfehlungsrichtlinie regelmäßig aktualisieren." Diese Formulierung löst natürlich das Problem der Exploration und Ausbeutung und ermöglicht es Ihnen, schnell optimale Strategien für alle Benutzer zu entwickeln.
Im Zuge der Popularität der Transformatorarchitektur gibt es auch Versuche, sie in Empfehlungen zu verwenden.
Nächste Artikelempfehlung mit Selbstaufmerksamkeit versucht, langfristige und aktuelle Benutzerpräferenzen zu kombinieren, um die Empfehlungen zu verbessern.
Die Werkzeuge
Empfehlungen sind kein so beliebtes Thema wie CV oder NLP. Um die neuesten Grid-Architekturen zu verwenden, müssen Sie sie entweder selbst implementieren oder hoffen, dass die Implementierung des Autors recht bequem und verständlich ist. Einige grundlegende Tools sind jedoch noch vorhanden:
Fazit
Die Empfehlungssysteme sind weit von der Standardaussage zum Ausfüllen der Bewertungsmatrix entfernt, und jeder spezifische Bereich wird seine eigenen Nuancen haben. Dies führt zu Schwierigkeiten, erhöht aber auch das Interesse. Darüber hinaus kann es schwierig sein, das Empfehlungssystem vom gesamten Produkt zu trennen. In der Tat ist nicht nur die Liste der Elemente wichtig, sondern auch die Methode und der Kontext der Einreichung. Was, wie, wem und wann zu empfehlen. All dies bestimmt den Eindruck der Interaktion mit dem Dienst.