Jedes Jahr findet in Moskau die
Dialogkonferenz statt, an der Linguisten und Datenanalysespezialisten teilnehmen. Sie diskutieren, was natürliche Sprache ist, wie man einer Maschine beibringt, sie zu verstehen und zu verarbeiten. Die Konferenz veranstaltete traditionell Wettbewerbe (Tracks)
Dialogevaluation . An ihnen können Vertreter großer Unternehmen teilnehmen, die Lösungen im Bereich der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) entwickeln, sowie einzelne Forscher. Es mag den Anschein haben, als würden Sie als einfacher Student mit den Systemen konkurrieren, die große Spezialisten großer Unternehmen seit Jahren entwickeln. Dialogbewertung - Dies ist genau dann der Fall, wenn in der Endwertung ein einfacher Schüler höher sein kann als ein berühmtes Unternehmen.
Dieses Jahr ist das neunte in Folge, wenn die Dialogbewertung im Dialog stattfindet. Jedes Jahr ist die Anzahl der Wettbewerbe unterschiedlich. NLP-Aufgaben wie Stimmungsanalyse, Wortsinninduktion, automatische Rechtschreibkorrektur, Erkennung benannter Entitäten und andere sind bereits zu Themen für Titel geworden.

In diesem Jahr haben vier Gruppen von Veranstaltern solche Tracks vorbereitet:
- Generierung von Schlagzeilen für Nachrichtenartikel.
- Auflösung von Anaphora und Koreferenz.
- Morphologische Analyse des Materials ressourcenarmer Sprachen.
- Automatische Analyse einer der Ellipsenarten (Lücke).
Heute werden wir über die letzten sprechen: Was ist eine Ellipse und warum soll man dem Auto beibringen, wie man sie im Text wiederherstellt, wie wir ein neues Gebäude geschaffen haben, um dieses Problem zu lösen, wie die Wettbewerbe abgehalten wurden und welche Ergebnisse die Teilnehmer erzielen konnten.
AGRR-2019 (Automatische Lückenauflösung für Russisch)
Im Herbst 2018 standen wir vor einer Forschungsaufgabe im Zusammenhang mit einer Ellipse - einem absichtlichen Weglassen einer Wortkette in einem Text, der aus dem Kontext wiederhergestellt werden kann. Wie finde ich automatisch eine solche Lücke im Text und fülle sie richtig aus? Für einen Muttersprachler ist es einfach, aber dieses Auto zu unterrichten ist nicht einfach. Ziemlich schnell wurde klar, dass dies ein gutes Material für die Konkurrenz ist, und wir machten uns an die Arbeit.
Die Organisation von Wettbewerben zu einem neuen Thema hat ihre eigenen Merkmale, und für uns scheinen sie größtenteils Pluspunkte zu sein. Eines der wichtigsten Dinge ist die Erstellung des Korpus (viele Texte mit Markup, auf denen Sie lernen können). Wie soll es aussehen und wie viel soll es sein? Für viele Aufgaben gibt es Standards für die Darstellung von Daten, auf denen aufgebaut werden kann. Für die
Definition benannter Entitäten wurden beispielsweise IO / BIO / IOBES-Markup-Schemata entwickelt. Für die Aufgaben der syntaktischen und morphologischen Analyse wird traditionell das CONLL-Format verwendet. Es muss nichts erfunden werden, aber die Richtlinien müssen strikt befolgt werden.
In unserem Fall war es an uns, das Korps zusammenzustellen und die Aufgabe zu formulieren.
Hier ist so eine Aufgabe ...
Hier müssen wir unweigerlich eine populäre sprachliche Einführung darüber machen, was Ellipsen im Allgemeinen sind und welche Lücken sie haben.
Unabhängig davon, welche Vorstellungen Sie über die Sprache haben, ist es schwierig zu argumentieren, dass die oberflächliche Ausdrucksebene (Text oder Sprache) nicht die einzige ist. Der Satz ist die Spitze des Eisbergs. Der Eisberg selbst beinhaltet eine pragmatische Bewertung, die Konstruktion einer syntaktischen Struktur, die Auswahl von lexikalischem Material und so weiter. Ellipse ist ein Phänomen, das die Oberflächenebene wunderbar mit der Tiefe verbindet. Dies ist das Weglassen doppelter Syntaxelemente. Wenn wir die syntaktische Struktur eines Satzes in Form eines Baums darstellen und dieselben Teilbäume in diesem Baum ausgewählt werden können, werden häufig (aber nicht immer) doppelte Elemente gelöscht, damit der Satz natürlich ist. Eine solche Entfernung wird als Ellipse bezeichnet (Beispiel 1).
(1)
Sie haben mich nicht zurückgerufen, und ich verstehe nicht, warum sie mich nicht zurückgerufen haben .Die durch Auslassungspunkte erhaltenen Lücken können aus dem Sprachkontext eindeutig wiederhergestellt werden. Vergleichen Sie das erste Beispiel mit dem zweiten (2), bei dem es einen Durchgang gibt, aber was genau dort fehlt, ist nicht klar. Dieser Fall ist keine Ellipse.
(2)
Lücken sind eine der Frequenzarten der Ellipse. Betrachten Sie Beispiel (3) und verstehen Sie, wie es funktioniert.
(3)
Ich verwechselte sie mit einem Italiener und ihn mit einem Schweden.In allen Beispielen gibt es mehr als zwei Sätze (Klauseln), die untereinander zusammengesetzt sind. In der ersten Klausel gibt es ein Verb (Linguisten sagen eher „Prädikat“) und seine Teilnehmer
akzeptierten es:
Ich ,
sie und
Italienisch . In der zweiten Klausel gibt es kein ausgedrücktes Verb, es gibt nur "Überreste" (oder Überreste)
davon und
für den Schweden , die nicht syntaktisch verwandt sind, aber wir verstehen, wie der Pass wiederhergestellt wird.
Um den Pass wiederherzustellen, wenden wir uns der ersten Klausel zu und kopieren die gesamte Struktur daraus (Beispiel 4). Wir ersetzen nur diejenigen Teile, für die es in einer unvollständigen Klausel "parallele" Überreste gibt. Wir haben das Prädikat kopiert,
wir ersetzen es durch
es ,
für Italienisch ersetzen
wir es durch Reste
für den Schweden . Für
mich gab es keinen parallelen Rest, was bedeutet, dass wir ihn ersatzlos kopieren.
(4)
Ich verwechselte sie mit Italienisch und ich verwechselte sie mit einem Schweden.Es scheint, dass es zur Wiederherstellung der Lücke ausreicht, festzustellen, ob dieser Satz eine Lücke enthält, die unvollständige Klausel und die gesamte damit verbundene Klausel (aus der das Material für die Wiederherstellung entnommen wurde) zu finden und dann zu verstehen, welche „Überreste“ (Überreste) in der unvollständigen Klausel und enthalten sind was sie in vollem Umfang entsprechen. Es scheint, dass diese Bedingungen ausreichen, um die Lücke effektiv zu schließen. Daher versuchen wir, den Prozess im Kopf einer Person nachzuahmen, die einen Text liest oder hört, in dem es möglicherweise zu Auslassungen kommt.
Warum wird das benötigt?
Es ist klar, dass für eine Person, die zuerst von Auslassungspunkten und den damit verbundenen Verarbeitungsschwierigkeiten erfährt, die berechtigte Frage „Warum?“ Aufkommen kann. Skeptiker möchten
die Väter der Sprachwissenschaft zum
Lesen einladen ,
um zu erklären, dass wenn die Lösung eines angewandten Problems Material liefert, das für die theoretische Forschung nützlich sein kann, dies bereits eine ausreichende Antwort auf die Frage nach dem Zweck einer solchen Aktivität ist.
Theoretiker studieren seit etwa 50 Jahren Ellipsen in verschiedenen Sprachen, beschreiben die Einschränkungen und heben allgemeine Muster in verschiedenen Sprachen hervor. Gleichzeitig ist uns nicht bekannt, dass es einen Korpus gibt, der irgendeine Art von Ellipse mit mehr als einigen hundert Beispielen darstellt. Dies ist teilweise auf die Seltenheit des Phänomens zurückzuführen (nach unseren Daten wird die Einstufung beispielsweise in nicht mehr als 5 von 10 Sätzen gefunden). Die Schaffung eines solchen Korps ist also bereits ein wichtiges Ergebnis.
In Anwendungssystemen, die mit Textdaten arbeiten, können Sie diese aufgrund der Seltenheit des Phänomens einfach ignorieren. Die Unfähigkeit des syntaktischen Parsers, fehlende Lücken wiederherzustellen, bringt nicht gerade viele Fehler mit sich. Aus seltenen Ereignissen entsteht jedoch eine ausgedehnte und bunte sprachliche Peripherie. Es scheint, dass die Erfahrung, ein solches Problem an sich zu lösen, für diejenigen von Interesse sein sollte, die Systeme erstellen möchten, die nicht nur mit einfachen, kurzen, sauberen Texten mit gemeinsamem Vokabular arbeiten, dh mit sphärischen Texten in einem Vakuum, das in der Natur praktisch nicht vorkommt.
Nur wenige Parser verfügen über ein effektives System zum Erkennen und Auflösen von Ellipsen. Im internen Parser ABBYY gibt es jedoch ein Modul, das für die Wiederherstellung von Durchläufen verantwortlich ist und auf manuell geschriebenen Regeln basiert. Dank dieser Fähigkeit des Parsers konnten wir einen großen Körper für den Wettbewerb erstellen. Der potenzielle Vorteil des ursprünglichen Parsers besteht darin, ein langsam laufendes Modul zu ersetzen. Während der Arbeit an dem Fall haben wir außerdem eine detaillierte Analyse der Fehler des aktuellen Systems durchgeführt.
Wie wir den Körper geschaffen haben
Unser Gebäude ist in erster Linie für das Training von automatischen Systemen gedacht, was bedeutet, dass es äußerst wichtig ist, dass es voluminös und vielfältig ist. Aus diesem Grund haben wir die Arbeit der Datenerfassung wie folgt aufgebaut. Für das Korps haben wir Texte verschiedener Genres ausgewählt: von technischen Dokumentationen und Patenten bis hin zu Nachrichten und Posts aus sozialen Medien. Alle wurden vom ABBYY-Parser markiert. Innerhalb eines Monats verteilten wir Daten zwischen Linguisten und Schreibern. Die Marker wurden aufgefordert, ohne das Markup zu ändern, es auf einer Skala zu bewerten:
0 - Der Satz enthält keine Zuordnung, das Markup ist irrelevant.
1 - Es gibt eine Zuordnung und das Markup ist korrekt.
2 - Es gibt eine Lücke, aber mit dem Markup stimmt etwas nicht.
3 - ein kniffliger Fall, ist es überhaupt ein Mapping?
Infolgedessen war jede der Gruppen nützlich. Beispiele aus Kategorie 1 fielen in die positive Klasse unseres Datensatzes. Wir wollten die Beispiele aus den Kategorien 2 und 3 grundsätzlich nicht manuell neu abtasten, um Zeit zu sparen, aber diese Beispiele waren später für die Bewertung unseres resultierenden Korpus hilfreich. Anhand dieser kann man beurteilen, welche Fälle das System durchweg falsch markiert, was bedeutet, dass sie nicht in unser Korps fallen. Und schließlich haben wir den Systemen, einschließlich der Fallbeispiele, die von Markern der Kategorie 0 zugewiesen wurden, die Möglichkeit gegeben, „aus den Fehlern anderer zu lernen“, dh nicht nur das Verhalten des ursprünglichen Systems zu simulieren, sondern besser zu arbeiten.
Jedes Beispiel wurde mit zwei Markern bewertet. Danach gelangte etwas mehr als die Hälfte der Vorschläge aus den Quelldaten in das Korps. Die gesamte positive Klasse von Beispielen und ein Teil des Negativen besteht aus ihnen. Wir haben beschlossen, die negative Klasse doppelt so positiv zu machen, damit einerseits das Volumen der Klassen vergleichbar ist und andererseits das Übergewicht der in der Sprache vorhandenen negativen Klasse erhalten bleibt.
Um diesem Verhältnis zu entsprechen, mussten wir dem Fall zusätzlich zu den beschriebenen Beispielen der Kategorie 0 weitere negative Beispiele hinzufügen. Geben wir ein Beispiel (5) der Kategorie 0 an, das nicht nur das Auto, sondern auch die Person verwirren kann.
(5)
Aber bis dahin war Jack in Cindy Page verliebt, jetzt Mrs. Jack Svaytek.In der zweiten Klausel erholt sie sich nicht
in Liebe , weil ich meine, dass Cindy Page jetzt Frau Jack Svaytek geworden ist, weil sie ihn geheiratet hat.
Im Allgemeinen ist für ein so seltenes syntaktisches Phänomen wie Gapping ein negatives Beispiel fast jeder zufällige Satz der Sprache, da die Wahrscheinlichkeit, dass ein zufälliger Satz eine winzige Lücke aufweist. Die Verwendung solcher negativen Beispiele kann jedoch zu einer Umschulung von Satzzeichen führen. In unserem Fall wurden Beispiele für die negative Klasse nach einfachen Kriterien erhalten: das Vorhandensein eines Verbs, das Vorhandensein eines Kommas oder Strichs, die minimale Satzlänge beträgt nicht weniger als 6 Token.
Für den Wettbewerb haben wir aus dem Teil des Schulungsgebäudes (im Verhältnis 1: 5) ausgewählt, den die Teilnehmer zur Konfiguration ihrer Systeme verwenden sollten. Die endgültigen Versionen der Systeme wurden an den kombinierten Zug- und Entwicklungsteilen geschult. Wir haben den Testfall (Test) manuell selbst beschriftet. In Bezug auf das Volumen ist dies der 10. Teil von train + dev. Hier ist die genaue Anzahl der Klassenbeispiele:
Zusätzlich zu den manuell überprüften Trainingsdaten haben wir eine vom Quellsystem empfangene Roh-Markup-Datei hinzugefügt. Es enthält mehr als 100.000 Beispiele, und die Teilnehmer können diese Daten optional als Ergänzung zur Trainingsstichprobe verwenden. Mit Blick auf die Zukunft sagen wir, dass nur ein Teilnehmer herausgefunden hat, wie das Schulungsgebäude mithilfe schmutziger Daten signifikant vergrößert werden kann, ohne an Qualität zu verlieren.
Markup-Format
Wir haben uns bewusst geweigert, Parser von Drittanbietern zu verwenden, und ein Markup entwickelt, in dem alle für uns interessanten Elemente in der Textzeile linear markiert sind. Wir haben zwei Arten von Markups verwendet. Die erste, für Menschen lesbare Version ist für die Verwendung mit Markups ausgelegt und es ist praktisch, die Fehler der resultierenden Systeme zu analysieren. Bei dieser Methode werden alle Lückenelemente innerhalb des Satzes mit eckigen Klammern markiert. Jedes Klammerpaar ist mit dem Namen des entsprechenden Elements gekennzeichnet. Wir haben die folgende Notation verwendet:

Wir geben Beispiele für Sätze mit Lücken in Klammern.
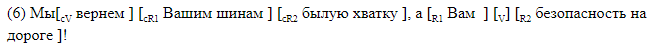
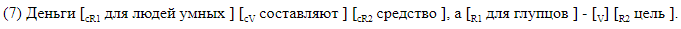

Die Klammermarkierung eignet sich für die Materialanalyse. In diesem Fall werden die Daten in einem anderen Format gespeichert, das bei Bedarf problemlos in Klammern konvertiert werden kann. Eine Zeile entspricht einem Satz. Die Spalten zeigen das Vorhandensein von Lücken im Satz an, und für jede mögliche Beschriftung in ihrer Spalte werden symbolische Versätze des Beginns und Endes des Segments angegeben, die dem Element entsprechen. So sieht das Offset-Markup aus, das dem Klammer-Markup in () entspricht.
Aufgaben für Teilnehmer
Die Teilnehmer der AGRR-2019 konnten eines von drei Problemen lösen:
- Binäre Klassifizierung Es muss festgestellt werden, ob der Satz eine Lücke enthält.
- Lückenerlaubnis. Es ist notwendig, die Position des Passes (V) und die Position des Verbcontrollers (cV) wiederherzustellen.
- Voller Aufschlag. Sie müssen Offsets für alle Elemente der Lücke definieren.
Jede nächste Aufgabe muss irgendwie die vorherige lösen. Es ist klar, dass jedes Markup nur in Sätzen möglich ist, in denen die binäre Klassifizierung eine positive Klasse zeigt (es gibt eine Zuordnung), und das vollständige Markup umfasst auch das Finden der Grenzen der fehlenden und kontrollierenden Prädikate.
Metriken
Für das Problem der binären Klassifizierung verwendeten wir Standardmetriken: Genauigkeit und Vollständigkeit, und die Ergebnisse der Teilnehmer wurden nach f-Maß eingestuft.
Für das Auflösen von Lücken und das vollständige Markup haben wir uns für ein symbolisches f-Maß entschieden, da die Ausgangstexte nicht mit Token versehen waren und wir nicht wollten, dass der Unterschied in den von den Teilnehmern verwendeten Tokenisierern die Ergebnisse beeinflusst. Richtig-negative Beispiele trugen nicht zum symbolischen f-Maß bei. Für jedes Markup-Element wurde ein eigenes f-Maß berücksichtigt. Das Endergebnis wurde durch Makro-Mittelung über den gesamten Körper erhalten. Dank einer solchen Berechnung der Metrik wurden falsch positive Fälle erheblich bestraft, was wichtig ist, wenn reale Daten um ein Vielfaches weniger positive Beispiele enthalten als negative.
Wettkampfkurs
Parallel zur Montage des Gebäudes haben wir Anträge auf Teilnahme am Wettbewerb angenommen. Infolgedessen haben wir mehr als 40 Teilnehmer registriert. Dann haben wir das Trainingsgebäude angelegt und den Wettbewerb gestartet. Die Teilnehmer hatten 4 Wochen Zeit, um ihre Modelle zu bauen.
Die Bewertung der Ergebnisse erfolgte wie folgt: Die Teilnehmer erhielten 20.000 Angebote ohne Aufschlag, an denen ein Testfall beteiligt war. Die Teams mussten diese Daten mit ihren Systemen markieren, woraufhin wir die Ergebnisse der Markierungen auf dem Testgebäude auswerteten. Das Mischen des Tests in eine große Datenmenge garantierte uns, dass der Fall mit all unseren Wünschen in den wenigen Tagen, die für den Lauf angegeben wurden, nicht manuell markiert werden konnte (automatische Markierung).
Wettbewerbsergebnisse
Neun Teams erreichten das Finale, darunter Vertreter von zwei IT-Unternehmen, Forscher der Moskauer Staatlichen Universität, des Moskauer Instituts für Physik und Technologie, HSE und IPPI RAS.
Alle bis auf eines der Teams nahmen an allen drei Wettbewerben teil. Gemäß den Bestimmungen von AGRR-2019 haben alle Teams einen Kodex für ihre Entscheidungen veröffentlicht. Eine Übersichtstabelle mit den Ergebnissen finden Sie in
unserem Repository . Dort finden Sie auch Links zu den übersichtlichen Lösungen von Teams mit kurzen Beschreibungen.
Fast alle zeigten gute Ergebnisse. Hier sind die Bewertungen der Entscheidungen der Gewinnerteams:
Eine detaillierte Beschreibung der Top-Lösungen wird in Kürze in den Artikeln der Teilnehmer der Dialogue-Sammlung verfügbar sein.
In diesem Artikel haben wir darüber gesprochen, wie man auf der Grundlage eines seltenen sprachlichen Phänomens eine Aufgabe formuliert, ein Korps vorbereitet und Wettbewerbe durchführt. Diese Arbeit ist auch für die NLP-Community von Vorteil, da Wettbewerbe dazu beitragen, verschiedene Architekturen und Ansätze in Bezug auf bestimmtes Material miteinander zu vergleichen, und Linguisten einen Fall eines seltenen Phänomens mit der Möglichkeit der Wiederauffüllung erhalten (unter Verwendung der Entscheidungen der Gewinner). Das versammelte Korps ist um ein Vielfaches größer als das Volumen des derzeit existierenden Korps (außerdem ist das Korpusvolumen für Lücken um eine Größenordnung größer als das Korpsvolumen nicht nur für Russisch, sondern für alle Sprachen im Allgemeinen). Alle Daten und Links zu Entscheidungen der Teilnehmer finden Sie in unserem Github.
Am 30. Mai werden auf der Sondersitzung des
Dialogs zur automatischen Analyse von Lückenwettbewerben die Ergebnisse der AGRR-2019 zusammengefasst. Wir werden über die Organisation des Wettbewerbs sprechen und uns mit dem Inhalt des erstellten Gebäudes befassen, und die Teilnehmer werden die ausgewählte Architektur vorstellen, mit der sie das Problem gelöst haben.
NLP Advanced Research Group