Den vollständigen Kurs in Russisch finden Sie unter
diesem Link .
Der ursprüngliche Englischkurs ist unter
diesem Link verfügbar.
 Alle 2-3 Tage sind neue Vorträge geplant.
Alle 2-3 Tage sind neue Vorträge geplant.Interview mit Sebastian Trun, CEO Udacity
"Also sind wir immer noch bei dir und bei uns, wie zuvor, Sebastian." Wir wollen nur vollständig verbundene Schichten diskutieren, dieselben dichten Schichten. Vorher möchte ich eine Frage stellen. Was sind die Grenzen und was sind die Haupthindernisse, die dem tiefen Lernen im Wege stehen und in den nächsten 10 Jahren den größten Einfluss darauf haben werden? Alles ändert sich so schnell! Was denkst du wird das nächste "große Ding" sein?
- Ich würde zwei Dinge sagen. Die erste ist die allgemeine KI für mehr als eine Aufgabe. Das ist großartig! Menschen können mehr als ein Problem lösen und sollten niemals dasselbe tun. Die zweite ist die Markteinführung von Technologie. Für mich ist die Besonderheit des maschinellen Lernens, dass es Computern die Möglichkeit bietet, Muster in Daten zu beobachten und zu finden, und Menschen dabei hilft, die besten auf dem Gebiet zu werden - auf Expertenebene! Maschinelles Lernen kann in Recht, Medizin und autonomen Autos eingesetzt werden. Entwickeln Sie solche Anwendungen, weil sie eine Menge Geld bringen können, aber vor allem haben Sie die Möglichkeit, die Welt zu einem viel besseren Ort zu machen.
- Ich mag die Art und Weise, wie Sie alles in einem einzigen Bild des tiefen Lernens und seiner Anwendung zusammenfassen. Dies ist nur ein Werkzeug, mit dem Sie ein bestimmtes Problem lösen können.
- Ja genau! Unglaubliches Werkzeug, richtig?
- Ja, ja, ich stimme dir vollkommen zu!
"Fast wie ein menschliches Gehirn!"
- Sie haben in unserem ersten Interview im ersten Teil des Videokurses medizinische Anwendungen erwähnt. In welchen Anwendungen sorgt Ihrer Meinung nach der Einsatz von Deep Learning für die größte Freude und Überraschung?
- Sehr viel! Sehr! Die Medizin steht auf der kurzen Liste der Bereiche, in denen Deep Learning aktiv eingesetzt wird. Ich habe meine Schwester vor ein paar Monaten verloren, sie war an Krebs erkrankt, was sehr traurig ist. Ich denke, es gibt viele Krankheiten, die früher erkannt werden könnten - in den frühen Stadien, die es ermöglichen, den Prozess ihrer Entwicklung zu heilen oder zu verlangsamen. Die Idee ist in der Tat, einige Werkzeuge in das Haus (Smart Home) zu übertragen, so dass es möglich ist, solche Gesundheitsabweichungen lange vor dem Moment zu erkennen, in dem die Person sie selbst sieht. Ich würde auch hinzufügen - alles wird wiederholt, jede Büroarbeit, bei der Sie immer wieder die gleichen Aktionen ausführen, zum Beispiel die Buchhaltung. Sogar ich als CEO mache viele sich wiederholende Aktionen. Es wäre großartig, sie zu automatisieren und sogar mit E-Mail-Korrespondenz zu arbeiten!
- Ich kann dir nicht widersprechen! In dieser Lektion werden wir den Schülern einen Kurs mit einer neuronalen Netzwerkschicht vorstellen, die als dichte Schicht bezeichnet wird. Können Sie uns genauer sagen, was Sie von vollständig verbundenen Schichten halten?
- Beginnen wir also damit, dass jedes Netzwerk auf unterschiedliche Weise verbunden werden kann. Einige von ihnen verfügen möglicherweise über eine sehr enge Konnektivität, wodurch Sie einige Vorteile bei der Skalierung erzielen und gegen große Netzwerke „gewinnen“ können. Manchmal wissen Sie nicht, wie viele Verbindungen Sie benötigen, also verbinden Sie alles mit allem - dies wird als vollständig verbundene Schicht bezeichnet. Ich füge hinzu, dass dieser Ansatz viel mehr Kraft und Potenzial hat als etwas strukturierteres.
- Ich stimme dir vollkommen zu! Vielen Dank, dass Sie uns dabei helfen, mehr über vollständig verbundene Ebenen zu erfahren. Ich freue mich auf den Moment, in dem wir endlich beginnen, sie zu implementieren und Code zu schreiben.
- Viel Spaß! Es wird wirklich Spaß machen!
Einführung
- Willkommen zurück! In der letzten Lektion haben Sie herausgefunden, wie Sie mit TensorFlow und Keras Ihr erstes neuronales Netzwerk aufbauen, wie neuronale Netzwerke funktionieren und wie der Trainingsprozess funktioniert. Insbesondere haben wir gesehen, wie das Modell trainiert wird, um Grad Celsius in Grad Fahrenheit umzurechnen.

- Wir haben auch das Konzept der vollständig verbundenen Schichten (dichten Schichten) kennengelernt, der wichtigsten Schicht in neuronalen Netzen. Aber in dieser Lektion werden wir viel coolere Dinge tun! In dieser Lektion werden wir ein neuronales Netzwerk entwickeln, das Kleidungselemente und Bilder erkennen kann. Wie bereits erwähnt, verwendet das maschinelle Lernen Eingaben, die als "Features" bezeichnet werden, und Ausgaben, die als "Labels" bezeichnet werden, anhand derer das Modell einen Transformationsalgorithmus lernt und findet. Daher werden wir zunächst viele Beispiele benötigen, um das neuronale Netzwerk zu trainieren, um verschiedene Elemente der Kleidung zu erkennen. Ich möchte Sie daran erinnern, dass ein Beispiel für das Training ein Wertepaar ist - eine Eingabefunktion und eine Ausgabebezeichnung, die der Eingabe eines neuronalen Netzwerks zugeführt werden. In unserem neuen Beispiel wird das Bild als Eingabe verwendet, und das Ausgabeetikett sollte die Kleidungskategorie sein, zu der das auf dem Bild gezeigte Kleidungsstück gehört. Glücklicherweise existiert ein solcher Datensatz bereits. Es heißt Fashion MNIST. Wir werden uns diesen Datensatz im nächsten Teil genauer ansehen.
Mode MNIST Datensatz
Willkommen in der Welt des MNIST-Datensatzes! Unser Set besteht also aus 28 x 28 Bildern, von denen jedes Pixel einen Grauton darstellt.

Der Datensatz enthält Bilder von T-Shirts, Tops, Sandalen und sogar Stiefeln. Hier ist eine vollständige Liste unserer MNIST-Datensätze:
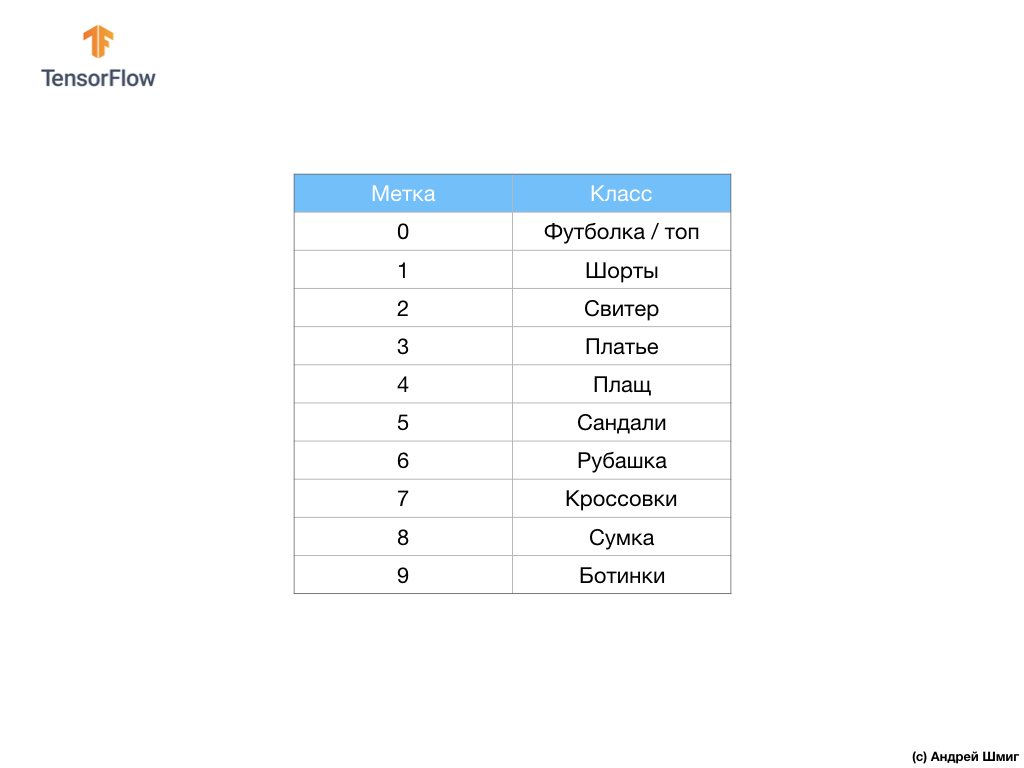
Jedes Eingabebild entspricht einer der obigen Beschriftungen. Der Fashion MNIST-Datensatz enthält 70.000 Bilder, sodass wir einen Ort haben, an dem wir beginnen und arbeiten können. Von diesen 70.000 werden wir 60.000 verwenden, um das neuronale Netzwerk zu trainieren.
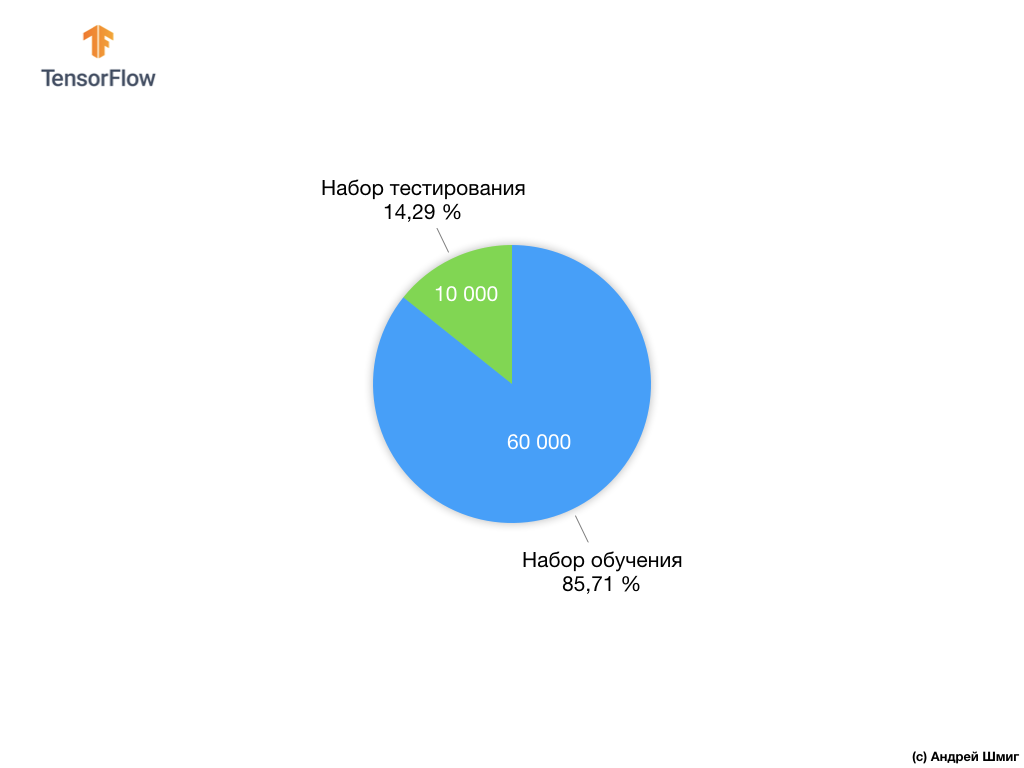
Und wir werden die verbleibenden 10.000 Elemente verwenden, um zu überprüfen, wie gut unser neuronales Netzwerk gelernt hat, Kleidungselemente zu erkennen. Später werden wir erklären, warum wir den Datensatz in einen Trainingssatz und einen Testsatz unterteilt haben.
Hier ist also unser Fashion MNIST-Datensatz.
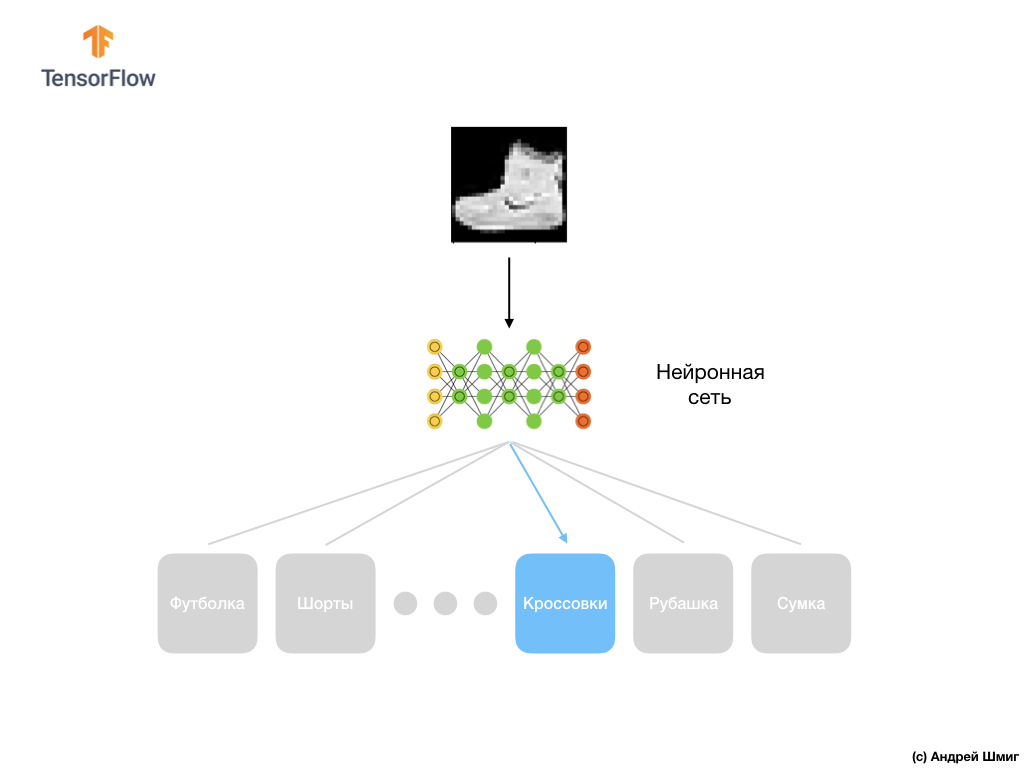
Denken Sie daran, dass jedes Bild im Datensatz ein Bild der Größe 28 x 28 in Graustufen ist. Dies bedeutet, dass jedes Bild eine Größe von 784 Byte hat. Unsere Aufgabe ist es, ein neuronales Netzwerk zu erstellen, das diese 784 Bytes am Eingang empfängt und am Ausgang zurückgibt, zu welcher von 10 verfügbaren Kleidungskategorien das am Eingang angewendete Element gehört.
Neuronales Netz
In dieser Lektion verwenden wir ein tiefes neuronales Netzwerk, das lernt, Bilder aus dem Fashion MNIST-Datensatz zu klassifizieren.
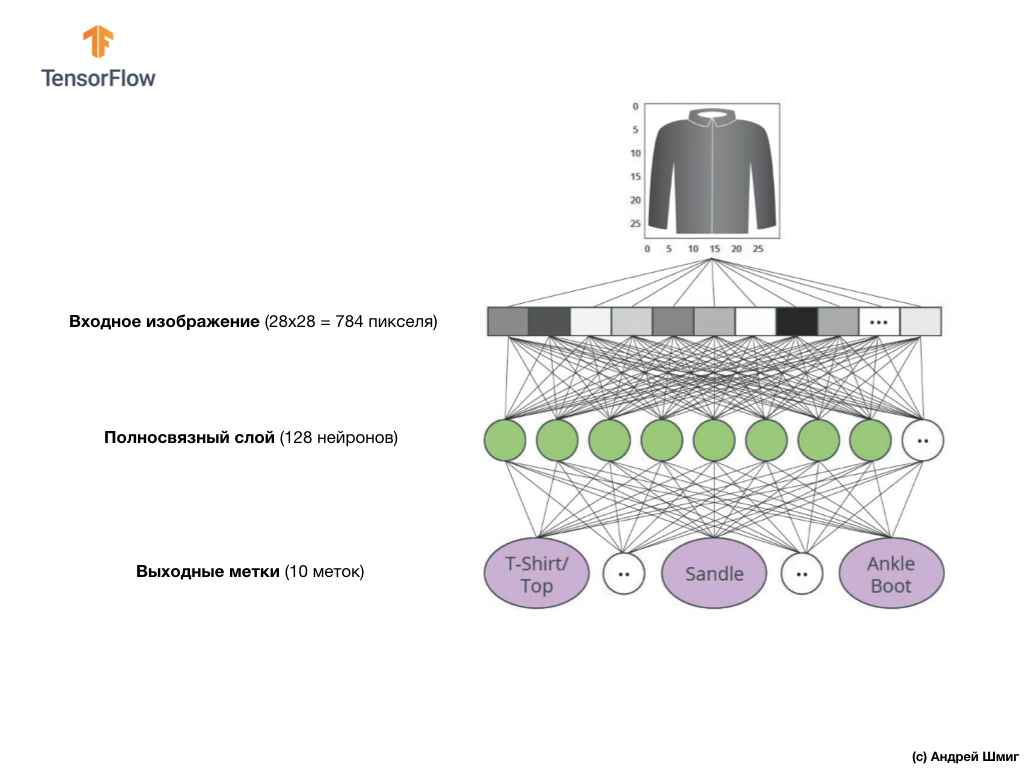
Das Bild oben zeigt, wie unser neuronales Netzwerk aussehen wird. Schauen wir uns das genauer an.
Der Eingabewert unseres neuronalen Netzwerks ist ein eindimensionales Array mit einer Länge von 784, ein Array mit genau dieser Länge, da jedes Bild 28 x 28 Pixel (= insgesamt 784 Pixel im Bild) beträgt, das wir in ein eindimensionales Array konvertieren. Das Konvertieren eines 2D-Bildes in einen Vektor wird als Abflachung bezeichnet und durch eine Glättungsschicht - eine Abflachungsebene - implementiert.
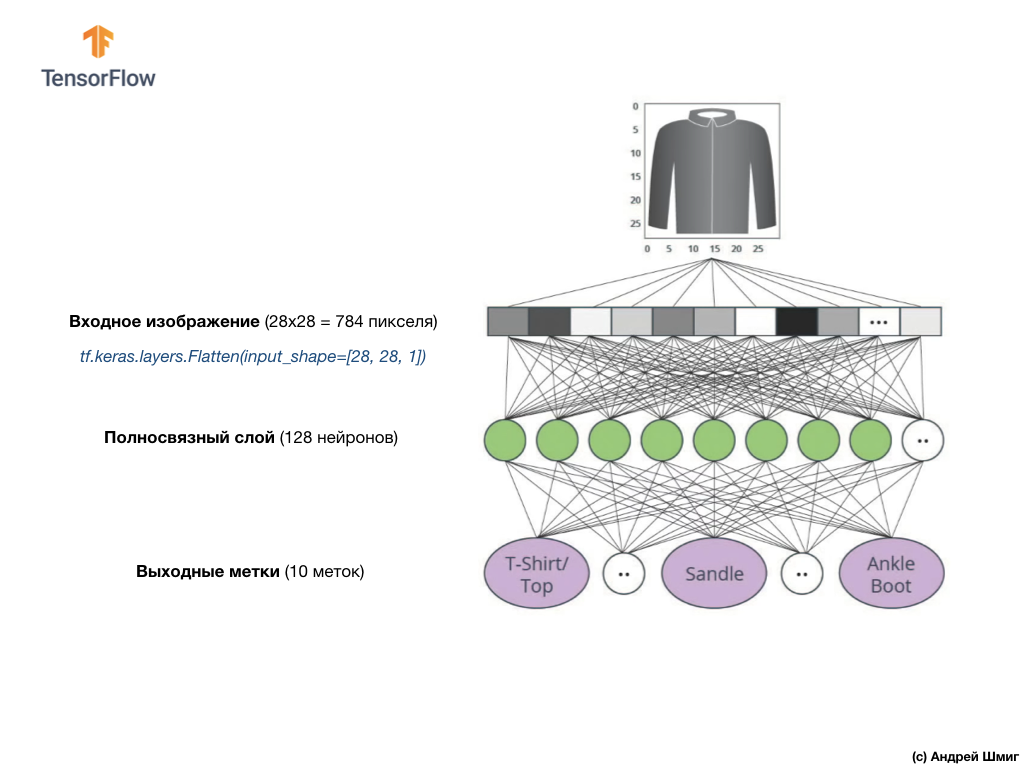
Sie können eine Glättung durchführen, indem Sie die entsprechende Ebene erstellen:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Diese Ebene konvertiert ein 2D-Bild mit 28 x 28 Pixeln (1 Byte für Graustufen für jedes Pixel) in ein 1D-Array mit 784 Pixeln.
Die Eingabewerte werden vollständig mit unserer ersten
dense Netzwerkschicht verknüpft, deren Größe wir gleich 128 Neuronen gewählt haben.
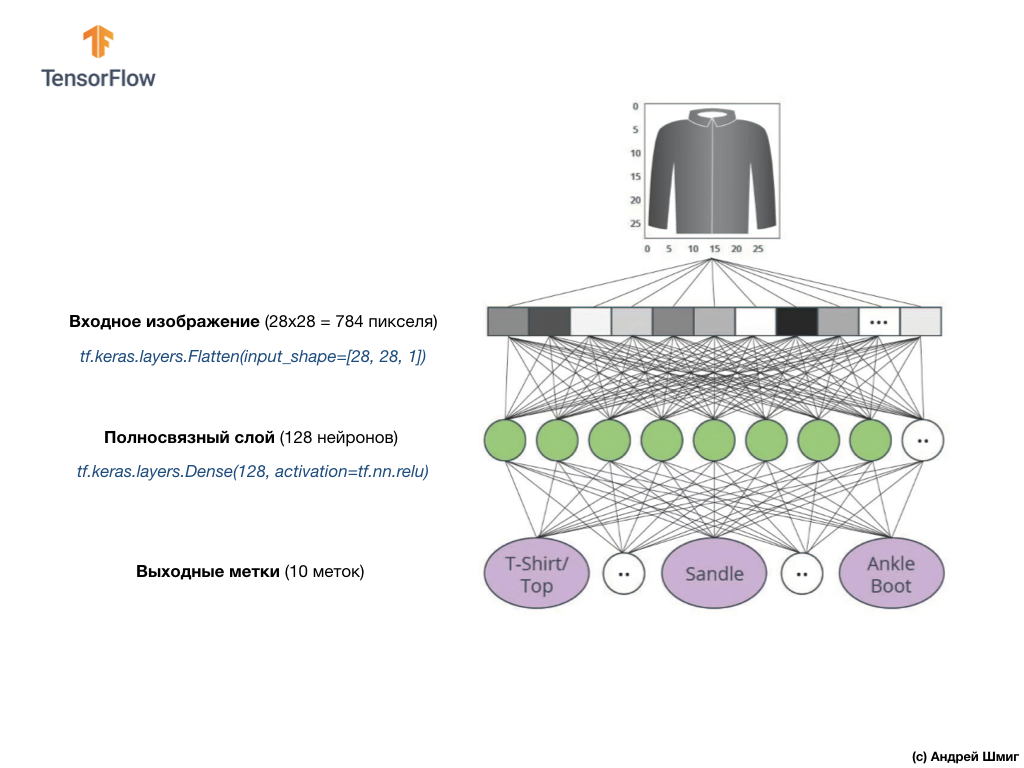
So sieht die Erstellung dieser Ebene im Code aus:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Hör auf! Was ist
tf.nn.relu ? Wir haben dies in unserem vorherigen Beispiel für ein neuronales Netzwerk nicht verwendet, als wir Grad Celsius in Grad Fahrenheit umgerechnet haben! Das Fazit ist, dass die aktuelle Aufgabe viel komplizierter ist als die, die als Beispiel für die Ermittlung von Fakten verwendet wurde - die Umrechnung von Grad Celsius in Grad Fahrenheit.
ReLU ist eine mathematische Funktion, die wir unserer vollständig verbundenen Schicht hinzufügen und die unserem Netzwerk mehr Leistung verleiht. Tatsächlich ist dies eine kleine Erweiterung für unsere vollständig verbundene Schicht, die es unserem neuronalen Netzwerk ermöglicht, komplexere Probleme zu lösen. Wir werden nicht auf Details eingehen, aber ein wenig detailliertere Informationen finden Sie unten.
Schließlich besteht unsere letzte Schicht, auch als Ausgangsschicht bekannt, aus 10 Neuronen. Es besteht aus 10 Neuronen, da unser Fashion MNIST-Datensatz 10 Kleidungskategorien enthält. Jeder dieser 10 Ausgabewerte repräsentiert die Wahrscheinlichkeit, dass sich das Eingabebild in dieser Kleidungskategorie befindet. Mit anderen Worten, diese Werte spiegeln das „Vertrauen“ des Modells in die Richtigkeit der Vorhersage und Korrelation des abgelegten Bildes mit einer bestimmten von 10 Kleidungskategorien am Ausgang wider. Wie hoch ist beispielsweise die Wahrscheinlichkeit, dass das Bild ein Kleid, Turnschuhe, Schuhe usw. zeigt?
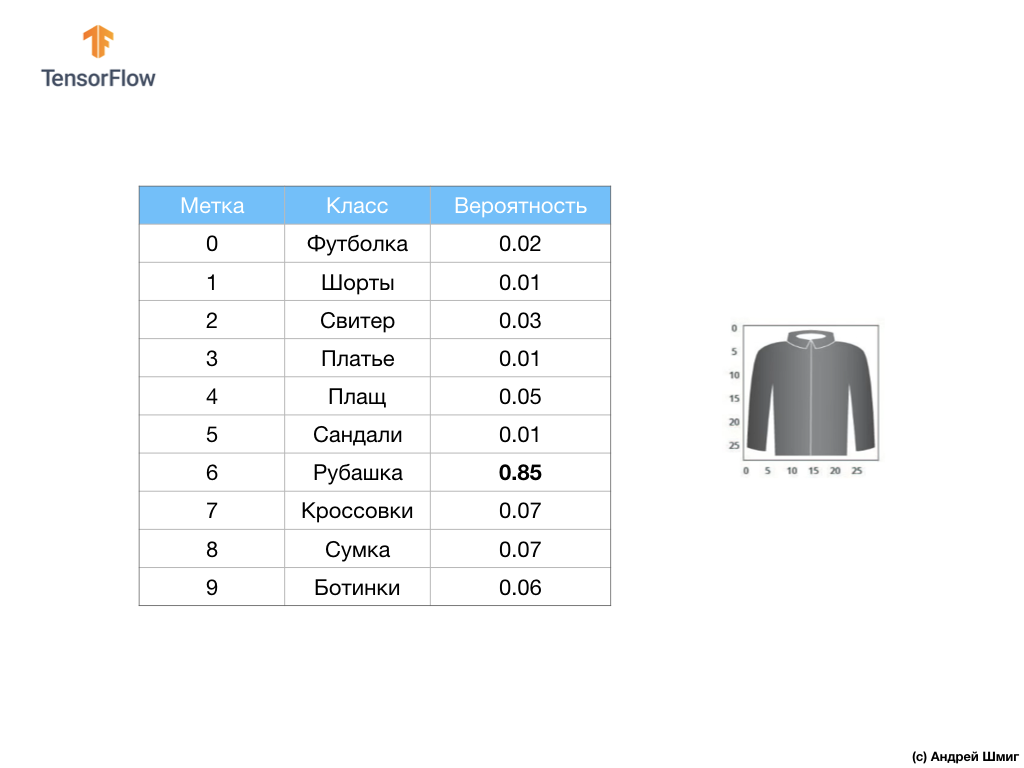
Wenn beispielsweise ein Hemdbild an die Eingabe unseres neuronalen Netzwerks gesendet wird, kann das Modell Ergebnisse liefern, wie Sie sie im obigen Bild sehen - die Wahrscheinlichkeit, dass das Eingabebild mit dem Ausgabeetikett übereinstimmt.
Wenn Sie darauf achten, werden Sie feststellen, dass sich die größte Wahrscheinlichkeit - 0,85 - auf Tag 6 bezieht, das dem Shirt entspricht. Das Modell ist zu 85% sicher, dass das Bild auf dem Shirt. Normalerweise haben Dinge, die wie Hemden aussehen, auch eine hohe Wahrscheinlichkeitsbewertung, und Dinge, die am wenigsten ähnlich sind, haben eine niedrigere Wahrscheinlichkeitsbewertung.
Da alle 10 Ausgabewerte Wahrscheinlichkeiten entsprechen, erhalten wir beim Summieren aller dieser Werte 1. Diese 10 Werte werden auch als Wahrscheinlichkeitsverteilung bezeichnet.
Jetzt benötigen wir eine Ausgabeebene, um die Wahrscheinlichkeiten für jedes Etikett zu berechnen.

Und wir werden dies mit dem folgenden Befehl tun:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
Tatsächlich verwenden wir immer dann, wenn wir neuronale Netze erstellen, die Klassifizierungsprobleme lösen, eine vollständig verbundene Schicht als letzte Schicht eines neuronalen Netzes. Die letzte Schicht des neuronalen Netzwerks sollte die Anzahl der Neuronen enthalten, die der Anzahl der Klassen entspricht, zu denen wir die
softmax bestimmen und die Softmax-Aktivierungsfunktion verwenden.
ReLU - Neuronenaktivierungsfunktion
In dieser Lektion haben wir über
ReLU als etwas gesprochen, das die Fähigkeiten unseres neuronalen Netzwerks erweitert und ihm zusätzliche Leistung verleiht.
ReLU ist eine mathematische Funktion, die folgendermaßen aussieht:
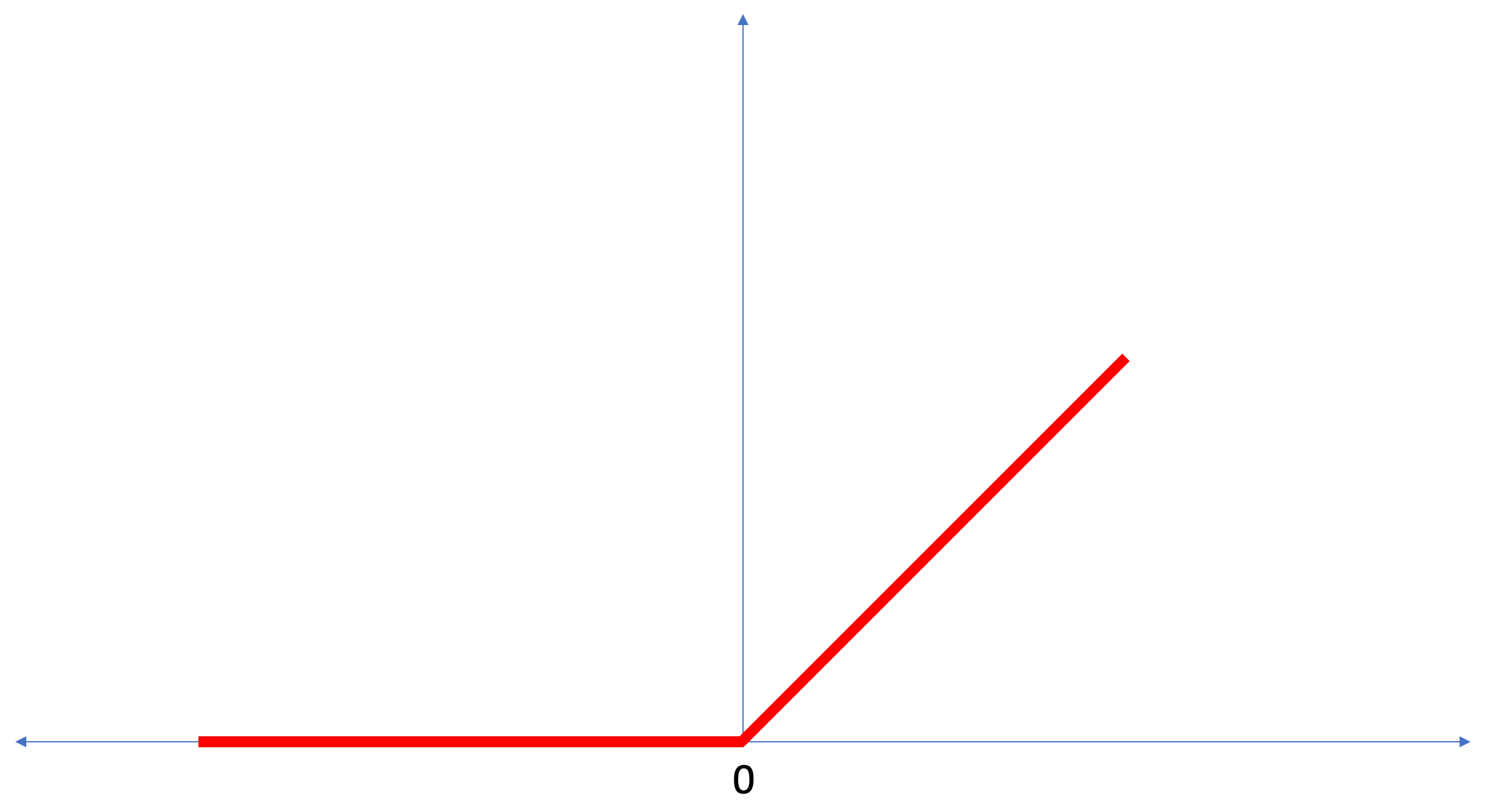
Die
ReLU Funktion gibt 0 zurück, wenn der Eingabewert ein negativer Wert oder Null war. In allen anderen Fällen gibt die Funktion den ursprünglichen Eingabewert zurück.
ReLU ermöglicht die Lösung nichtlinearer Probleme.
Die Umrechnung von Grad Celsius in Grad Fahrenheit ist eine lineare Aufgabe, da der Ausdruck
f = 1.8*c + 32 die Gleichung der Linie ist -
y = m*x + b . Die meisten Aufgaben, die wir lösen möchten, sind jedoch nicht linear. In solchen Fällen kann das Hinzufügen der ReLU-Aktivierungsfunktion zu unserer vollständig verbundenen Schicht bei dieser Art von Aufgabe hilfreich sein.
ReLU ist nur eine Art von Aktivierungsfunktion. Es gibt Aktivierungsfunktionen wie Sigmoid, ReLU, ELU,
ReLU Am häufigsten wird jedoch
ReLU als Standardaktivierungsfunktion verwendet. Um Modelle mit ReLU zu erstellen und zu verwenden, müssen Sie nicht verstehen, wie es intern funktioniert. Wenn Sie noch besser verstehen wollen, empfehlen wir
diesen Artikel .
Lassen Sie uns die neuen Begriffe in dieser Lektion durchgehen:
- Glätten - der Prozess des Konvertierens eines 2D-Bildes in einen 1D-Vektor;
- ReLU ist eine Aktivierungsfunktion, mit der das Modell nichtlineare Probleme lösen kann.
- Softmax - eine Funktion, die die Wahrscheinlichkeiten für jede mögliche Ausgabeklasse berechnet;
- Klassifizierung - Eine Klasse von maschinellen Lernaufgaben, mit denen die Unterschiede zwischen zwei oder mehr Kategorien (Klassen) ermittelt werden.
Schulung und Prüfung
Beim Training eines Modells, eines Modells für maschinelles Lernen, ist es immer erforderlich, den Datensatz in mindestens zwei verschiedene Sätze zu unterteilen - den für das Training verwendeten Datensatz und den zum Testen verwendeten Datensatz. In diesem Teil werden wir verstehen, warum es sich lohnt, dies zu tun.
Erinnern wir uns, wie wir unseren Datensatz von Fashion MNIST mit 70.000 Exemplaren verteilt haben.
Wir haben vorgeschlagen, 70.000 in zwei Teile zu teilen - im ersten Teil 60.000 für das Training und im zweiten Teil 10.000 für Tests. Die Notwendigkeit eines solchen Ansatzes wird durch die folgende Tatsache verursacht: Nachdem das Modell auf 60.000 Kopien trainiert wurde, müssen die Ergebnisse und die Wirksamkeit seiner Arbeit an Beispielen überprüft werden, die noch nicht in dem Datensatz enthalten waren, auf dem das Modell trainiert wurde.
Auf seine Weise ähnelt es dem Bestehen einer Prüfung in der Schule. Bevor Sie die Prüfung bestehen, sind Sie fleißig damit beschäftigt, Probleme einer bestimmten Klasse zu lösen. In der Prüfung stoßen Sie dann auf dieselbe Problemklasse, jedoch mit unterschiedlichen Eingabedaten. Es ist nicht sinnvoll, dieselben Daten wie während des Trainings zu übermitteln. Andernfalls wird die Aufgabe darauf reduziert, sich an Entscheidungen zu erinnern und nicht nach einem Lösungsmodell zu suchen. Deshalb stehen Sie bei Prüfungen vor Aufgaben, die zuvor nicht im Lehrplan enthalten waren. Nur so können wir überprüfen, ob das Modell die allgemeine Lösung gelernt hat oder nicht.
Das gleiche passiert beim maschinellen Lernen. Sie zeigen einige Daten an, die eine bestimmte Klasse von Aufgaben darstellen, deren Lösung Sie lernen möchten. In unserem Fall möchten wir, dass das neuronale Netzwerk mit einem Datensatz von Fashion MNIST die Kategorie bestimmen kann, zu der das Kleidungselement im Bild gehört. Deshalb trainieren wir unser Modell an 60.000 Beispielen, die alle Kategorien von Kleidungsstücken enthalten. Nach dem Training möchten wir die Wirksamkeit des Modells überprüfen, damit wir die verbleibenden 10.000 Kleidungsstücke füttern, die das Modell noch nicht „gesehen“ hat. Wenn wir uns entscheiden würden, dies nicht zu tun und nicht mit 10.000 Beispielen zu testen, könnten wir nicht mit Sicherheit sagen, ob unser Modell tatsächlich darauf trainiert wurde, die Klasse des Kleidungsstücks zu bestimmen, oder ob sie sich an alle Paare von Eingabe- / Ausgabewerten erinnerte.
Deshalb haben wir beim maschinellen Lernen immer einen Datensatz für das Training und einen Datensatz zum Testen.
TensorFlow ist eine Sammlung gebrauchsfertiger Trainingsdaten.
Datensätze werden normalerweise in mehrere Blöcke unterteilt, von denen jeder in einer bestimmten Phase des Trainings und Testens der Wirksamkeit des neuronalen Netzwerks verwendet wird. In diesem Teil sprechen wir über:
- Trainingsdatensatz : ein Datensatz zum Trainieren eines neuronalen Netzwerks;
- Testdatensatz : Ein Datensatz zur Überprüfung der Effizienz eines neuronalen Netzwerks.
Stellen Sie sich einen anderen Datensatz vor, den ich als Validierungsdatensatz bezeichne. Dieser Datensatz wird nicht
zum Trainieren des Modells verwendet, sondern nur
während des Trainings. Nachdem unser Modell mehrere Trainingszyklen durchlaufen hat, geben wir ihm unseren Testdatensatz und sehen uns die Ergebnisse an. Wenn beispielsweise während des Trainings der Wert der Verlustfunktion abnimmt und sich die Genauigkeit des Testdatensatzes verschlechtert, bedeutet dies, dass sich unser Modell einfach nur Paare von Eingabe-Ausgabe-Werten merkt.
Der Verifizierungsdatensatz wird am Ende des Trainings wiederverwendet, um die endgültige Genauigkeit der Modellvorhersagen zu messen.
Weitere
Informationen zu Trainings- und Testdatensätzen finden Sie im Google Crash-Kurs .
Praktischer Teil in CoLab
Link zum originalen CoLab in Englisch und ein
Link zum russischen CoLab .
Klassifizierung von Bildern von Kleidungsstücken
In diesem Teil der Lektion werden wir ein neuronales Netzwerk aufbauen und trainieren, um Bilder von Kleidungselementen wie Kleidern, Turnschuhen, Hemden, T-Shirts usw. zu klassifizieren.
Es ist in Ordnung, wenn einige Momente nicht klar sind. Der Zweck dieses Kurses ist es, Sie mit TensorFlow vertraut zu machen und gleichzeitig die Algorithmen seiner Arbeit zu erklären und ein gemeinsames Verständnis für Projekte mit TensorFlow zu entwickeln, anstatt sich mit den Details der Implementierung zu befassen.
In diesem Teil verwenden wir
tf.keras , eine
tf.keras API zum
tf.keras und Trainieren von Modellen in TensorFlow.
Abhängigkeiten installieren und importieren
Wir benötigen
ein TensorFlow-Dataset , eine API, die das Laden und Zugreifen auf Datasets vereinfacht, die von mehreren Diensten bereitgestellt werden. Wir werden auch einige Hilfsbibliotheken brauchen.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
Importieren Sie den Fashion MNIST-Datensatz
In diesem Beispiel wird der Fashion MNIST-Datensatz verwendet, der 70.000 Bilder von Kleidungsstücken in 10 Kategorien in Graustufen enthält. Die Bilder enthalten Kleidungsstücke in niedriger Auflösung (28 x 28 Pixel), wie unten gezeigt:

Fashion MNIST wird als Ersatz für den klassischen MNIST-Datensatz verwendet - am häufigsten als "Hallo Welt!" in maschinellem Lernen und Computer Vision. Der MNIST-Datensatz enthält Bilder von handgeschriebenen Zahlen (0, 1, 2 usw.) im gleichen Format wie die Kleidungsstücke in unserem Beispiel.
In unserem Beispiel verwenden wir Fashion MNIST aufgrund der Vielfalt und weil diese Aufgabe unter dem Gesichtspunkt der Implementierung interessanter ist als die Lösung eines typischen Problems im MNIST-Datensatz. Beide Datensätze sind klein genug, daher werden sie verwendet, um die korrekte Funktionsfähigkeit des Algorithmus zu überprüfen. Hervorragende Datensätze zum Erlernen des maschinellen Lernens, Testens und Debuggens von Code.
Wir werden 60.000 Bilder verwenden, um das Netzwerk zu trainieren, und 10.000 Bilder, um die Genauigkeit des Trainings und der Bildklassifizierung zu testen. Sie können über TensorFlow über die API direkt auf den Fashion MNIST-Datensatz zugreifen:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
Durch Laden eines Datensatzes erhalten wir Metadaten, einen Trainingsdatensatz und einen Testdatensatz.
- Das Modell wird an einem Datensatz aus "train_dataset" trainiert
- Das Modell wird an einem Datensatz aus `test_dataset` getestet
Bilder sind zweidimensionale
2828 Arrays, bei denen die Werte in jeder Zelle im Intervall
[0, 255] . Beschriftungen - ein Array von Ganzzahlen, wobei jeder Wert im Intervall
[0, 9] . Diese Beschriftungen entsprechen der Ausgabebildklasse wie folgt:
Jedes Bild gehört zu einem Tag. Da die Klassennamen nicht im Originaldatensatz enthalten sind, speichern wir sie für die zukünftige Verwendung, wenn wir die Bilder zeichnen:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
Wir recherchieren Daten
Lassen Sie uns das Format und die Struktur der im Trainingssatz dargestellten Daten untersuchen, bevor Sie das Modell trainieren. Der folgende Code zeigt, dass sich 60.000 Bilder im Trainingsdatensatz und 10.000 Bilder im Testdatensatz befinden:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
Datenvorverarbeitung
Der Wert jedes Pixels im Bild liegt im Bereich
[0,255] . Damit das Modell korrekt funktioniert, müssen diese Werte normalisiert und auf Werte im Intervall
[0,1] reduziert werden. Etwas niedriger deklarieren und implementieren wir daher die Normalisierungsfunktion und wenden sie dann auf jedes Bild in den Trainings- und Testdatensätzen an.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
Wir untersuchen die verarbeiteten Daten
Zeichnen wir ein Bild, um es uns anzusehen:
Wir zeigen die ersten 25 Bilder aus dem Trainingsdatensatz an und geben unter jedem Bild an, zu welcher Klasse es gehört.
Stellen Sie sicher, dass die Daten im richtigen Format vorliegen und wir mit der Erstellung und Schulung des Netzwerks beginnen können.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

Ein Modell bauen
Um ein neuronales Netzwerk aufzubauen, müssen Ebenen abgestimmt und anschließend ein Modell mit Optimierungs- und Verlustfunktionen zusammengestellt werden.
Passen Sie Ebenen an
Das Grundelement beim Aufbau eines neuronalen Netzwerks ist die Schicht. Die Ebene extrahiert die Ansicht aus den Daten, die in ihre Eingabe eingegangen sind. Als Ergebnis der Arbeit mehrerer miteinander verbundener Schichten erhalten wir eine Ansicht, die zur Lösung des Problems sinnvoll ist.
Die meiste Zeit, in der Sie tief lernen, werden Sie Verknüpfungen zwischen einfachen Ebenen herstellen. Die meisten Ebenen, z. B. tf.keras.layers.Dense, verfügen über eine Reihe von Parametern, die während des Lernprozesses „angepasst“ werden können.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
Das Netzwerk besteht aus drei Schichten:
- input
tf.keras.layers.Flatten - Diese Ebene konvertiert Bilder mit einer Größe von 28 x 28 Pixel in ein 1D-Array mit einer Größe von 784 (28 * 28). Auf dieser Ebene haben wir keine Parameter für das Training, da diese Ebene nur die Konvertierung von Eingabedaten behandelt. - versteckte Schicht
tf.keras.layers.Dense - eine eng verbundene Schicht von 128 Neuronen. Jedes Neuron (Knoten) nimmt alle 784 Werte aus der vorherigen Schicht als Eingabe, ändert die Eingabewerte entsprechend den internen Gewichten und Verschiebungen während des Trainings und gibt einen einzelnen Wert an die nächste Schicht zurück. - Ausgabeschicht
ts.keras.layers.Dense - softmax besteht aus 10 Neuronen, von denen jede eine bestimmte Klasse von Kleidungselementen darstellt. Wie in der vorherigen Schicht empfängt jedes Neuron die Eingabewerte aller 128 Neuronen der vorherigen Schicht. Die Gewichte und Verschiebungen jedes Neurons auf dieser Schicht ändern sich während des Trainings, so dass der resultierende Wert im Intervall [0,1] und die Wahrscheinlichkeit darstellt, dass das Bild zu dieser Klasse gehört. Die Summe aller Ausgangswerte von 10 Neuronen ist 1.
Kompilieren Sie das Modell
Bevor wir mit dem Training des Modells beginnen, sollten noch einige Einstellungen vorgenommen werden. Diese Einstellungen werden während der Modellzusammenstellung vorgenommen, wenn die Kompilierungsmethode aufgerufen wird:
- Verlustfunktion - Ein Algorithmus zum Messen, wie weit der gewünschte Wert vom vorhergesagten Wert entfernt ist.
- Optimierungsfunktion - ein Algorithmus zum „Anpassen“ der internen Parameter (Gewichte und Offsets) des Modells, um die Verlustfunktion zu minimieren;
- Metriken - werden verwendet, um den Trainingsprozess und die Tests zu überwachen. Im folgenden Beispiel werden Metriken wie
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Wir trainieren das Modell
Zunächst bestimmen wir die Reihenfolge der Aktionen während des Trainings anhand eines Trainingsdatensatzes:
- Wiederholen Sie den Satz von Eingabedaten mit der Methode
dataset.repeat() unendlich dataset.repeat() der unten beschriebene Parameter epochs bestimmt die Anzahl aller durchzuführenden Trainingsiterationen). - Die Methode
dataset.shuffle(60000) alle Bilder, sodass das Training unseres Modells nicht durch die Reihenfolge der Eingabedaten beeinflusst wird. - Die Methode
dataset.batch(32) weist die Trainingsmethode model.fit , bei model.fit Aktualisierung der internen Variablen des Modells Blöcke mit 32 Bildern und Beschriftungen model.fit verwenden.
Das Training erfolgt durch Aufrufen der
model.fit Methode:
- Sendet
train_dataset an die Modelleingabe. - Das Modell lernt, das Eingabebild mit dem Etikett abzugleichen.
- Der Parameter
epochs=5 begrenzt die Anzahl der Trainingseinheiten auf 5 vollständige Trainingsiterationen in einem Datensatz, wodurch wir letztendlich an 5 * 60.000 = 300.000 Beispielen trainieren können.
(Sie können den Parameter
steps_per_epoch ignorieren, bald wird dieser Parameter von der Methode ausgeschlossen.)
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
Und hier ist die Schlussfolgerung:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Während des Modelltrainings werden für jede Trainingsiteration der Wert der Verlustfunktion und die Genauigkeitsmetrik angezeigt. Dieses Modell erreicht eine Genauigkeit von ca. 0,88 (88%) bei Trainingsdaten.
Überprüfen Sie die Genauigkeit
Lassen Sie uns überprüfen, welche Genauigkeit das Modell mit Testdaten erzeugt. Wir werden alle Beispiele, die wir im Testdatensatz haben, zur Überprüfung der Genauigkeit verwenden.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
Fazit:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
Wie Sie sehen können, war die Genauigkeit des Testdatensatzes geringer als die Genauigkeit des Trainingsdatensatzes. Dies ist ganz normal, da das Modell auf train_dataset-Daten trainiert wurde. Wenn ein Modell Bilder entdeckt, die es noch nie zuvor gesehen hat (aus dem Dataset train_dataset), ist es offensichtlich, dass die Klassifizierungseffizienz abnimmt.
Vorhersagen und erforschen
Wir können das trainierte Modell verwenden, um Vorhersagen für einige Bilder zu erhalten.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
Schlussfolgerung: Im obigen Beispiel hat das Modell Beschriftungen für jedes Testeingabebild vorhergesagt. Schauen wir uns die erste Vorhersage an:(32, 10)
predictions[0]
Fazit: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
Denken Sie daran, dass Modellvorhersagen ein Array von 10 Werten sind. Diese Werte beschreiben das „Vertrauen“ des Modells, dass das Eingabebild zu einer bestimmten Klasse (Kleidungsstück) gehört. Wir können den Maximalwert wie folgt sehen: np.argmax(predictions[0])
Fazit: 6
Dies bedeutet, dass das Modell am sichersten war, dass dieses Bild zur Klasse mit der Bezeichnung 6 (class_names [6]) gehört. Wir können überprüfen und sicherstellen, dass das Ergebnis wahr und korrekt ist: test_labels[0]
6
Wir können alle Eingabebilder und die entsprechenden Modellvorhersagen für 10 Klassen anzeigen: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
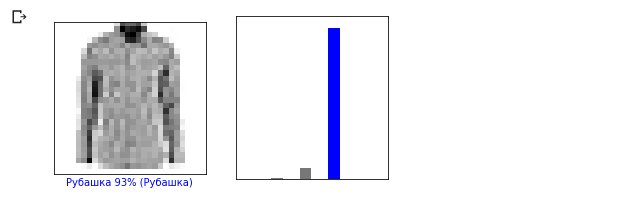
Schauen wir uns das 0. Bild an, das Ergebnis der Vorhersage des Modells und das Array von Vorhersagen. i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
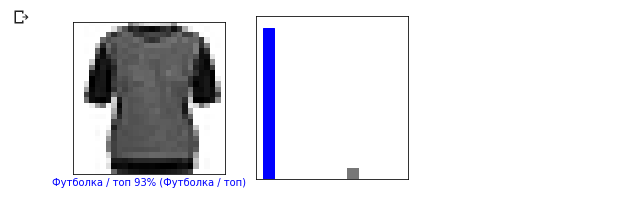 Lassen Sie uns nun einige Bilder mit ihren jeweiligen Vorhersagen anzeigen. Richtige Vorhersagen sind blau, falsche Vorhersagen sind rot. Der Wert unter dem Bild gibt den Prozentsatz der Sicherheit an, dass das Eingabebild dieser Klasse entspricht. Bitte beachten Sie, dass das Ergebnis möglicherweise falsch ist, auch wenn der Wert für „Vertrauen“ hoch ist.
Lassen Sie uns nun einige Bilder mit ihren jeweiligen Vorhersagen anzeigen. Richtige Vorhersagen sind blau, falsche Vorhersagen sind rot. Der Wert unter dem Bild gibt den Prozentsatz der Sicherheit an, dass das Eingabebild dieser Klasse entspricht. Bitte beachten Sie, dass das Ergebnis möglicherweise falsch ist, auch wenn der Wert für „Vertrauen“ hoch ist. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 Verwenden Sie das trainierte Modell, um die Beschriftung für ein einzelnes Bild vorherzusagen:
Verwenden Sie das trainierte Modell, um die Beschriftung für ein einzelnes Bild vorherzusagen: img = test_images[0] print(img.shape)
Fazit: (28, 28, 1)
Modelle in sind tf.kerasfür Vorhersagen durch Blöcke (Sammlungen) optimiert. Trotz der Tatsache, dass wir ein einzelnes Element verwenden, müssen Sie es der Liste hinzufügen: img = np.array([img]) print(img.shape)
Fazit:(1, 28, 28, 1)Jetzt werden wir das Ergebnis vorhersagen: predictions_single = model.predict(img) print(predictions_single)
Fazit: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
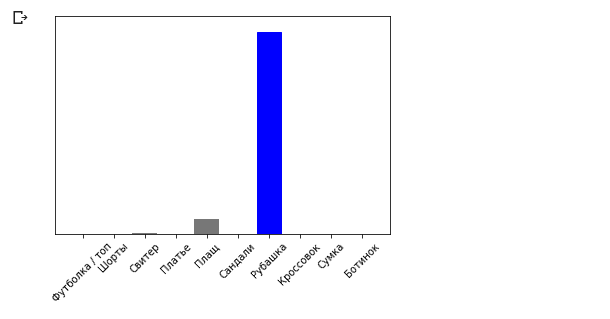 Die model.predict-Methode gibt eine Liste von Listen (ein Array von Arrays) zurück, jeweils für ein Bild aus einem Eingabeblock. Wir erhalten das einzige Ergebnis für unser einzelnes Eingabebild:
Die model.predict-Methode gibt eine Liste von Listen (ein Array von Arrays) zurück, jeweils für ein Bild aus einem Eingabeblock. Wir erhalten das einzige Ergebnis für unser einzelnes Eingabebild: np.argmax(predictions_single[0])
Fazit: 6
Wie zuvor sagte das Modell das Etikett 6 (Hemd) voraus.Übungen
Experimentieren Sie mit verschiedenen Modellen und sehen Sie, wie sich die Genauigkeit ändert. Versuchen Sie insbesondere, die folgenden Einstellungen zu ändern:- Setzen Sie den Parameter epochs auf 1;
- Ändern Sie beispielsweise die Anzahl der Neuronen in der verborgenen Schicht von einem niedrigen Wert von 10 auf 512 und sehen Sie, wie sich die Genauigkeit des Prognosemodells ändert.
- Fügen Sie zusätzliche Schichten zwischen der Abflachungsschicht (Glättungsschicht) und der letzten dichten Schicht hinzu. Experimentieren Sie mit der Anzahl der Neuronen auf dieser Schicht.
- Normalisieren Sie die Pixelwerte nicht und sehen Sie, was passiert.
Denken Sie daran, die GPU zu aktivieren, damit alle Berechnungen schneller sind ( Runtime -> Change runtime type -> Hardware accelertor -> GPU). Wenn Sie während des Vorgangs auf Probleme stoßen, versuchen Sie, die globalen Umgebungseinstellungen zurückzusetzen:Edit -> Clear all outputsRuntime -> Reset all runtimes
Grad Celsius VS MNIST
- Zu diesem Zeitpunkt sind wir bereits auf zwei Arten von neuronalen Netzen gestoßen. Unser erstes neuronales Netzwerk hat gelernt, wie man Grad Celsius in Grad Frenheit umwandelt, wobei ein einzelner Wert zurückgegeben wird, der in einem weiten Bereich numerischer Werte liegen kann.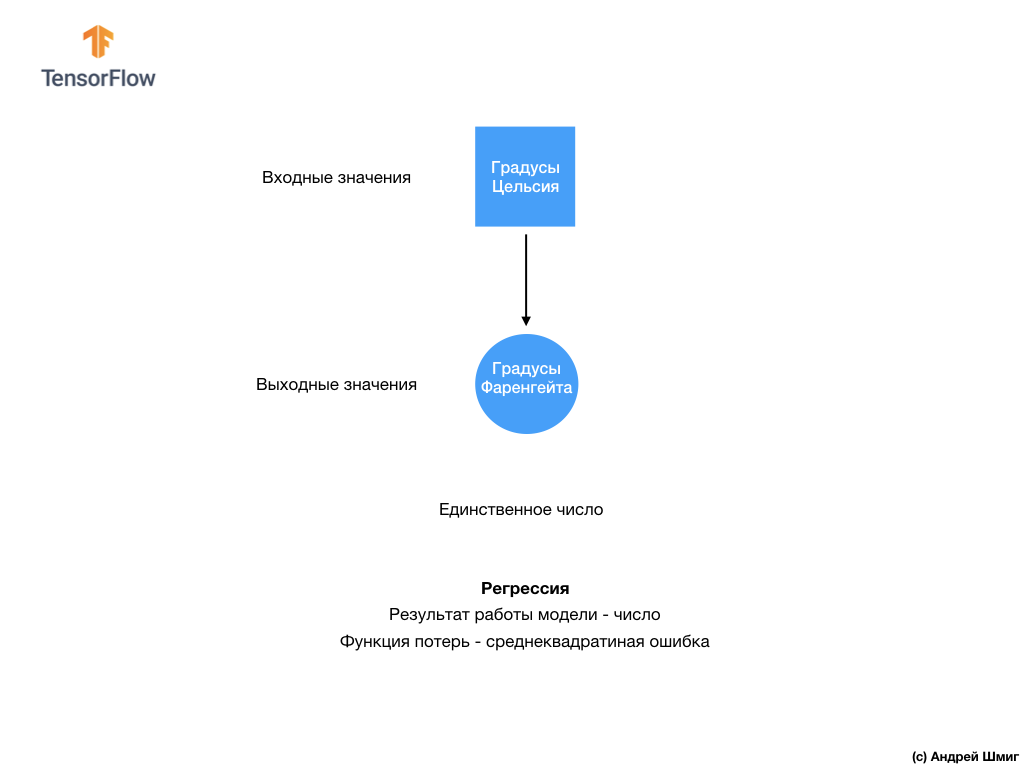 Unser zweites neuronales Netzwerk gibt 10 Wahrscheinlichkeitswerte zurück, die das Vertrauen des Netzwerks widerspiegeln, dass das Eingabebild einer bestimmten Klasse entspricht.Neuronale Netze können verwendet werden, um verschiedene Probleme zu lösen.
Unser zweites neuronales Netzwerk gibt 10 Wahrscheinlichkeitswerte zurück, die das Vertrauen des Netzwerks widerspiegeln, dass das Eingabebild einer bestimmten Klasse entspricht.Neuronale Netze können verwendet werden, um verschiedene Probleme zu lösen.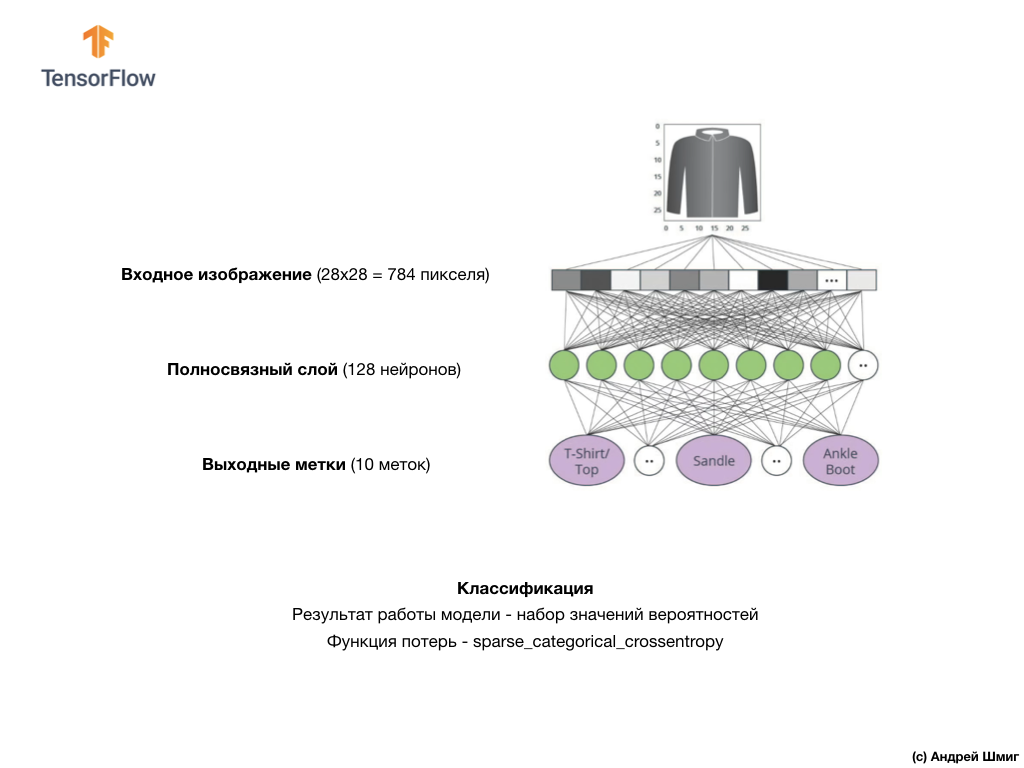 Die erste Klasse von Problemen, die wir mit der Vorhersage eines einzelnen Wertes gelöst haben, heißt Regression. Die Umrechnung von Grad Celsius in Grad Fahrenheit ist ein Beispiel für die Aufgabe dieser Klasse. Ein weiteres Beispiel für diese Aufgabenklasse kann die Aufgabe sein, den Wert eines Hauses anhand der Anzahl der Räume, der Gesamtfläche, des Standorts und anderer Merkmale zu bestimmen.Die zweite Klasse von Aufgaben, die wir in dieser Lektion untersucht haben, um Bilder in verfügbare Kategorien zu klassifizieren, wird als Klassifizierung bezeichnet . Gemäß den Eingabedaten gibt das Modell die Wahrscheinlichkeitsverteilung zurück (das „Vertrauen“ des Modells, dass der Eingabewert zu dieser Klasse gehört). In dieser Lektion haben wir ein neuronales Netzwerk entwickelt, das Kleidungselemente in 10 Kategorien klassifiziert. In der nächsten Lektion lernen wir zu bestimmen, wer auf dem Foto gezeigt wird - ein Hund oder eine Katze. Diese Aufgabe gehört auch zur Klassifizierungsaufgabe.Lassen Sie uns den Unterschied zwischen diesen beiden Problemklassen - Regression und Klassifizierung - zusammenfassen und feststellen .
Die erste Klasse von Problemen, die wir mit der Vorhersage eines einzelnen Wertes gelöst haben, heißt Regression. Die Umrechnung von Grad Celsius in Grad Fahrenheit ist ein Beispiel für die Aufgabe dieser Klasse. Ein weiteres Beispiel für diese Aufgabenklasse kann die Aufgabe sein, den Wert eines Hauses anhand der Anzahl der Räume, der Gesamtfläche, des Standorts und anderer Merkmale zu bestimmen.Die zweite Klasse von Aufgaben, die wir in dieser Lektion untersucht haben, um Bilder in verfügbare Kategorien zu klassifizieren, wird als Klassifizierung bezeichnet . Gemäß den Eingabedaten gibt das Modell die Wahrscheinlichkeitsverteilung zurück (das „Vertrauen“ des Modells, dass der Eingabewert zu dieser Klasse gehört). In dieser Lektion haben wir ein neuronales Netzwerk entwickelt, das Kleidungselemente in 10 Kategorien klassifiziert. In der nächsten Lektion lernen wir zu bestimmen, wer auf dem Foto gezeigt wird - ein Hund oder eine Katze. Diese Aufgabe gehört auch zur Klassifizierungsaufgabe.Lassen Sie uns den Unterschied zwischen diesen beiden Problemklassen - Regression und Klassifizierung - zusammenfassen und feststellen .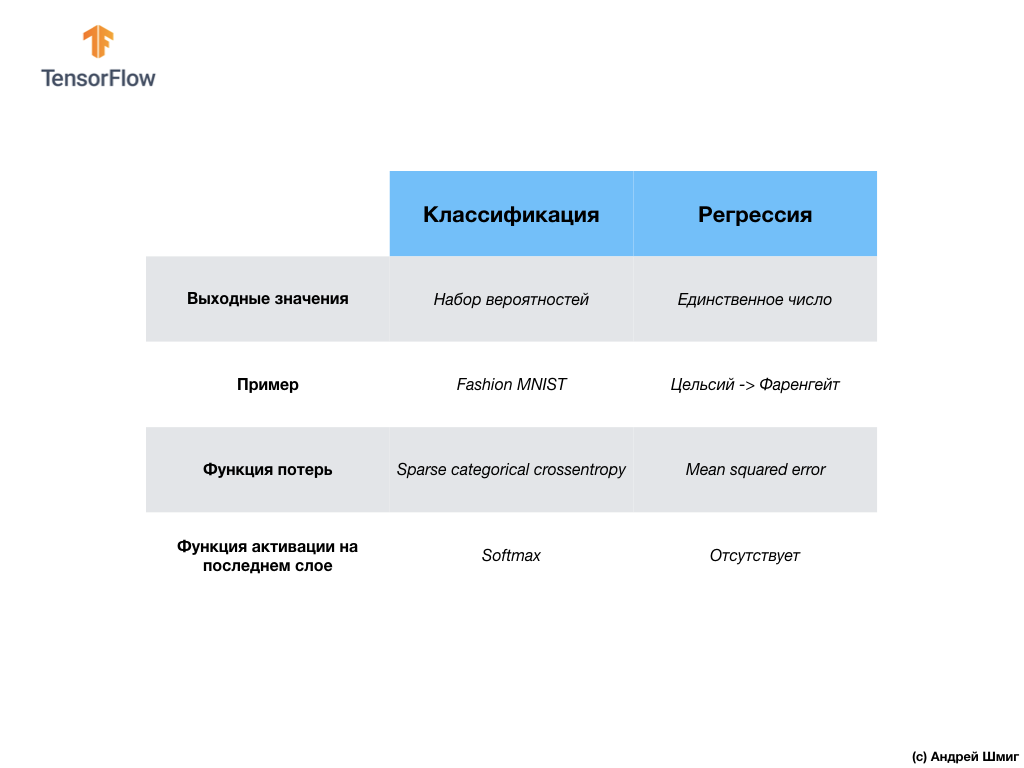 Herzlichen Glückwunsch, Sie haben zwei Arten von neuronalen Netzen untersucht! Machen Sie sich bereit für die nächste Vorlesung. Dort werden wir einen neuen Typ neuronaler Netze untersuchen - Convolutional Neural Networks (CNN).
Herzlichen Glückwunsch, Sie haben zwei Arten von neuronalen Netzen untersucht! Machen Sie sich bereit für die nächste Vorlesung. Dort werden wir einen neuen Typ neuronaler Netze untersuchen - Convolutional Neural Networks (CNN).Zusammenfassung
In dieser Lektion haben wir das neuronale Netzwerk trainiert, um Bilder mit Kleidungselementen zu klassifizieren. Zu diesem Zweck haben wir den Fashion MNIST-Datensatz verwendet, der 70.000 Bilder von Kleidungsstücken enthält. 60.000 davon haben wir verwendet, um das neuronale Netzwerk zu trainieren, und die restlichen 10.000, um die Wirksamkeit seiner Arbeit zu testen. Um diese Bilder an die Eingabe unseres neuronalen Netzwerks zu senden, mussten wir sie von einem 28x28 2D-Format in ein 1D-Format mit 784 Elementen konvertieren (glätten). Unser Netzwerk bestand aus einer vollständig verbundenen Schicht von 128 Neuronen und einer Ausgangsschicht von 10 Neuronen, entsprechend der Anzahl der Etiketten (Klassen, Kategorien von Kleidungsstücken). Diese 10 Ausgabewerte repräsentierten die Wahrscheinlichkeitsverteilung für jede Klasse. Softmax- Aktivierungsfunktionzählte die Wahrscheinlichkeitsverteilung.Wir haben auch die Unterschiede zwischen Regression und Klassifikation kennengelernt .- Regression : Ein Modell, das einen einzelnen Wert zurückgibt, z. B. den Wert eines Hauses.
- Klassifizierung : Ein Modell, das die Wahrscheinlichkeitsverteilung zwischen mehreren Kategorien zurückgibt. In unserer Aufgabe mit Fashion MNIST waren die Ausgabewerte beispielsweise 10 Wahrscheinlichkeitswerte, von denen jeder einer bestimmten Klasse (Kategorie von Kleidungsstücken) zugeordnet war. Ich erinnere Sie daran, dass wir die Softmax- Aktivierungsfunktion verwendet haben , um eine Wahrscheinlichkeitsverteilung auf der letzten Ebene zu erhalten.
Videoversion des ArtikelsDas Video erscheint einige Tage nach Veröffentlichung und wird dem Artikel hinzugefügt.
... und Standard-Handlungsaufforderung - anmelden, ein Plus setzen und teilen :)
YouTubeTelegrammVKontakte