
Vor einiger Zeit passierte mir eine unangenehme Geschichte, die als Auslöser für ein kleines Projekt auf dem Github diente und zu diesem Artikel führte.
Ein typischer Tag, eine normale Freigabe: Alle Aufgaben werden von unserem QS-Ingenieur auf und ab überprüft, sodass wir mit der Ruhe der heiligen Kuh auf die Bühne „rollen“. Die Anwendung verhält sich in den Protokollen gut - Stille. Wir entscheiden uns für einen Wechsel (Stage <-> Prod). Wir wechseln, schauen uns die Geräte an ...
Es dauert ein paar Minuten, der Flug ist stabil. Der QS-Techniker führt einen Rauchtest durch und stellt fest, dass die Anwendung auf unnatürliche Weise langsamer wird. Wir schreiben ab, um die Caches aufzuwärmen.
Ein paar Minuten vergehen, die erste Beschwerde aus der ersten Zeile: Die Daten werden sehr lange von den Clients heruntergeladen, die Anwendung wird langsamer, die Antwort dauert lange usw. Wir machen uns langsam Sorgen ... wir schauen uns die Protokolle an, wir suchen nach möglichen Gründen.
Ein paar Minuten später kommt ein Brief von DB-Administratoren. Sie schreiben, dass die Ausführungszeit von Abfragen an die Datenbank (im Folgenden als Datenbank bezeichnet) alle möglichen Grenzen überschritten hat und gegen unendlich tendiert.
Ich öffne die Überwachung (ich benutze
JavaMelody ) und finde diese Anfragen. Ich starte PGAdmin, ich reproduziere. Wirklich lang. Ich füge "EXPLAIN" hinzu, ich schaue mir den Ausführungsplan an ... wir haben die Indizes vergessen.
Warum reicht die Codeüberprüfung nicht aus?
Dieser Vorfall hat mich viel gelehrt. Ja, ich habe das Feuer für eine Stunde „gelöscht“ und auf irgendeine Weise den richtigen Index direkt auf dem Produkt erstellt (vergessen Sie nicht die Option CONCURRENTLY):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
Stimmen Sie zu, dies war gleichbedeutend mit einer Bereitstellung mit Ausfallzeiten. Für die Anwendung, an der ich arbeite, ist dies nicht akzeptabel.
Ich habe Schlussfolgerungen gezogen und der Checkliste einen besonderen Fettdruck für die Codeüberprüfung hinzugefügt: Wenn ich sehe, dass während des Entwicklungsprozesses eine der Repository-Klassen hinzugefügt / geändert wurde, überprüfe ich SQL-Migrationen auf das Vorhandensein eines Skripts, das den Index dort erstellt und ändert. Wenn er nicht da ist, schreibe ich dem Autor eine Frage: Ist er sicher, dass der Index hier nicht benötigt wird?
Es ist wahrscheinlich, dass ein Index nicht benötigt wird, wenn nur wenige Daten vorhanden sind. Wenn wir jedoch mit einer Tabelle arbeiten, in der die Anzahl der Zeilen in Millionen gezählt wird, kann ein Indexfehler schwerwiegend werden und zu der am Anfang des Artikels beschriebenen Geschichte führen.
In diesem Fall bitte ich den Autor der Pull-Anfrage (im Folgenden: PR), 100% sicher zu sein, dass die von ihm in HQL geschriebene Abfrage zumindest teilweise vom Index abgedeckt wird (Index-Scan wird verwendet). Dafür hat der Entwickler:
- Startet die Anwendung
- Suche nach konvertierten (HQL -> SQL) Abfragen in den Protokollen
- öffnet PGAdmin oder ein anderes Datenbankverwaltungstool
- generiert in der lokalen Datenbank eine Datenmenge, die für Tests akzeptabel ist (mindestens 10K - 20K Datensätze), um niemanden bei ihren Experimenten zu stören
- erfüllt die Anfrage
- fordert Ausführungsplan an
- studiert es sorgfältig und zieht entsprechende Schlussfolgerungen
- Fügt den Index hinzu / ändert ihn, um sicherzustellen, dass der Ausführungsplan dazu passt
- meldet sich in PR ab, dass die Anforderungsabdeckung überprüft wurde
- Wenn ich die Risiken und die Schwere der Anfrage fachmännisch einschätze, kann ich ihre Maßnahmen überprüfen
Viele Routinemaßnahmen und der menschliche Faktor, aber für einige Zeit war ich zufrieden und habe damit gelebt.
Auf dem Weg nach Hause
Sie sagen, es sei zumindest manchmal sehr nützlich, von der Arbeit zu gehen, ohne unterwegs Musik / Podcasts zu hören. Wenn Sie zu diesem Zeitpunkt nur an das Leben denken, können Sie zu interessanten Schlussfolgerungen und Ideen kommen.
Eines Tages ging ich nach Hause und dachte darüber nach, was an diesem Tag passiert war. Es gab einige Überprüfungen, ich überprüfte jede mit einer Checkliste und führte eine Reihe von oben beschriebenen Aktionen durch. Ich wurde damals so müde, dachte ich, was zur Hölle? Ist es unmöglich, dies automatisch zu tun? .. Ich machte einen schnellen Schritt und wollte diese Idee schnell „abschneiden“.
Erklärung des Problems
Was ist für den Entwickler im Ausführungsplan am wichtigsten?
Natürlich scannen Sie große Datenmengen, die durch das Fehlen eines Index verursacht werden.
Daher war es notwendig, einen Test durchzuführen, der:
- Wird in einer Datenbank mit einer ähnlichen Konfiguration wie das Produkt ausgeführt
- Fängt eine Datenbankabfrage ab, die von einem JPA-Repository (Ruhezustand) erstellt wurde.
- Ruft den Ausführungsplan ab
- Parsit-Ausführungsplan, der in einer für Überprüfungen geeigneten Datenstruktur angeordnet ist
- Überprüft die Erwartungen mithilfe einer praktischen Reihe von Assert-Methoden. Zum Beispiel wird dieser seq-Scan nicht verwendet.
Es war notwendig, diese Hypothese schnell zu testen, indem ein Prototyp erstellt wurde.
Lösungsarchitektur
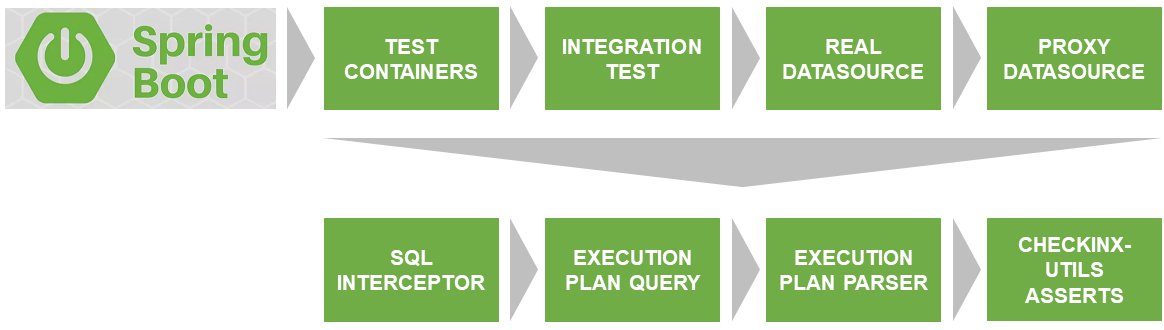
Das erste Problem, das gelöst werden sollte, war der Start des Tests in einer realen Datenbank, die der Version und den Einstellungen mit der auf dem Produkt verwendeten entspricht.
Dank
Docker & TestContainers lösen sie dieses Problem.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse und AssertService sind die Schnittstellen, die ich derzeit für Postgres implementiert habe. Es ist geplant, für andere Datenbanken zu implementieren. Wenn Sie teilnehmen möchten - willkommen. Der Code ist in Kotlin geschrieben.
All dies zusammen habe ich auf GitHub gepostet und
checkinx-utils aufgerufen. Sie müssen dies nicht wiederholen. Verbinden Sie einfach die Abhängigkeit mit checkinx in maven / gradle und verwenden Sie praktische Asserts. Wie das geht, werde ich weiter unten näher beschreiben.
Beschreibung der Interaktion von CheckInx-Komponenten
ProxyDataSource
Das erste Problem, das gelöst werden sollte, war das Abfangen von Datenbankabfragen, die zur Ausführung bereit waren. Bereits mit den festgelegten Parametern, ohne Fragen usw.
Dazu müssen Sie die reale dataSource in einen bestimmten Proxy einbinden, damit Sie sie in die Pipeline für die Ausführung von Abfragen integrieren und entsprechend abfangen können.
Eine solche ProxyDataSource wurde bereits von vielen implementiert. Ich habe die vorgefertigte
ttddyy- Lösung verwendet, mit der ich meinen Listener installieren kann, um die von mir benötigte Anforderung abzufangen.
Ich ersetze die Quell-DataSource durch die DataSourceWrapper-Klasse (BeanPostProcessor).
SqlInterceptor
Tatsächlich legt die Methode start () den Listener in proxyDataSource fest und fängt ab, Anforderungen abzufangen und in der Liste der internen Anweisungen zu speichern. Die stop () -Methode entfernt jeweils den installierten Listener.
ExecutionPlanQuery
Hier wird die ursprüngliche Anforderung in eine Anforderung für einen Ausführungsplan umgewandelt. Im Fall von Postgres ist dies eine Ergänzung zum Abfrage-Schlüsselwort "EXPLAIN".
Ferner wird diese Abfrage von Testcontainern in derselben Datenbank ausgeführt und ein "roher" Ausführungsplan (Liste der Zeilen) zurückgegeben.
ExecutionPlanParser
Es ist unpraktisch, mit einem rohen Ausführungsplan zu arbeiten. Deshalb analysiere ich es in einen Baum, der aus Knoten besteht (PlanNode).
Lassen Sie uns die PlanNode-Felder anhand eines Beispiels eines echten ExecutionPlan analysieren:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
Es ist bereits möglich, normal mit der vom Parser zurückgegebenen Datenstruktur zu arbeiten. CheckInxAssertService ist eine Reihe von Überprüfungen des oben beschriebenen PlanNode-Baums. Es ermöglicht Ihnen, Ihre eigenen Lambdas von Schecks zu setzen oder die meiner Meinung nach vordefinierten, die beliebtesten zu verwenden. Zum Beispiel, damit Ihre Abfrage keinen Seq-Scan enthält oder Sie sicherstellen möchten, dass ein bestimmter Index verwendet / nicht verwendet wird.
Coveragelevel
Sehr wichtige Aufzählung, ich werde es separat beschreiben:
Als nächstes sehen wir uns einige Anwendungsbeispiele an.
Testbeispiele mit CheckInx
Ich habe ein separates Projekt für die GitHub-
Checkinx-Demo durchgeführt , in dem ich ein JPA-Repository für die Haustier-Tabelle implementiert und Tests für dieses Repository durchgeführt habe, um die Abdeckung, Indizes usw. zu überprüfen. Es wird nützlich sein, dort als Ausgangspunkt zu betrachten.
Sie könnten einen Test wie diesen haben:
@Test fun testFindByLocation() {
Der Umsetzungsplan könnte wie folgt aussehen:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
... oder so, wenn wir den Index vergessen haben (Tests werden rot):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
In meinem Projekt verwende ich meistens die einfachste Behauptung, die besagt, dass der Ausführungsplan keinen Seq-Scan enthält:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
Das Vorhandensein eines solchen Tests legt nahe, dass ich zumindest den Umsetzungsplan studiert habe.
Außerdem wird das Projektmanagement expliziter und die Dokumentierbarkeit und Vorhersagbarkeit des Codes erhöht.
Erfahrener ModusIch empfehle die Verwendung von CheckInxAssertService, aber bei Bedarf können Sie den analysierten Baum (ExecutionPlanParser) selbst umgehen oder im Allgemeinen den rohen Ausführungsplan (das Ergebnis der Ausführung von ExecutionPlanQuery) analysieren.
@Test fun testFindByLocation() {
Verbindung zum Projekt
In meinem Projekt habe ich solche Tests einer separaten Gruppe zugeordnet und sie als intensive Integrationstests bezeichnet.
Das Anschließen und Starten von checkinx-utils ist einfach genug. Beginnen wir mit dem Build-Skript.
Verbinden Sie zuerst das Repository. Eines Tages werde ich checkinx auf maven hochladen, aber jetzt kannst du Artefakte nur von GitHub über jitpack herunterladen.
repositories { // ... maven { url 'https://jitpack.io' } }
Fügen Sie als Nächstes die Abhängigkeit hinzu:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
Wir vervollständigen die Verbindung durch Hinzufügen der Konfiguration. Derzeit wird nur Postgres unterstützt.
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
Achten Sie auf das Testprofil. Andernfalls finden Sie ProxyDataSource in Ihrem Produkt.
PostgresConfig verbindet mehrere Beans:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
Wenn Sie eine Anpassung benötigen, die die aktuelle API nicht bietet, können Sie jederzeit eine der Beans durch Ihre Implementierung ersetzen.
Bekannte Probleme
Manchmal kann ein DataSourceWrapper die ursprüngliche dataSource aufgrund des Spring CGLIB-Proxys nicht ersetzen. In diesem Fall kommt keine DataSource zu BeanPostProcessor, sondern zu ScopedProxyFactoryBean, und es gibt Probleme bei der Typprüfung.
Die einfachste Lösung wäre, HikariDataSource manuell für Tests zu erstellen. Dann wird Ihre Konfiguration wie folgt sein:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
Entwicklungspläne
- Ich würde gerne verstehen, ob jemand anders als ich das braucht? Erstellen Sie dazu eine Umfrage. Ich werde gerne ehrlich antworten.
- Sehen Sie, was Sie wirklich brauchen, und erweitern Sie die Standardliste der Assert-Methoden.
- Schreiben Sie Implementierungen für andere Datenbanken.
- Die Konstruktion von sqlInterceptor.statements [0] sieht nicht sehr offensichtlich aus, ich möchte sie verbessern.
Ich würde mich freuen, wenn jemand mitmachen und durch das Üben in Kotlin etwas Anerkennung gewinnen möchte.
Fazit
Ich bin mir sicher, dass es Kommentare geben wird:
Es ist unmöglich vorherzusagen, wie sich der Abfrageplaner auf dem Produkt verhält, alles hängt von den gesammelten Statistiken ab .
In der Tat ein Planer. Mithilfe der zuvor gesammelten Statistiken kann ein anderer Plan als der getestete erstellt werden. Die Bedeutung ist etwas anders.
Die Aufgabe des Planers ist es, die Anfrage zu verbessern, nicht zu verschlechtern. Daher wird er ohne ersichtlichen Grund Seq Scan nicht plötzlich verwenden, aber Sie können es unwissentlich.
Sie benötigen CheckInx, damit Sie beim Schreiben eines Tests nicht vergessen, den Ausführungsplan für Abfragen zu studieren und die Möglichkeit der Erstellung eines Index in Betracht zu ziehen, oder umgekehrt. Zeigen Sie mit einem Test deutlich, dass hier keine Indizes benötigt werden und Sie mit Seq Scan zufrieden sind. Dies würde Ihnen unnötige Fragen bei der Codeüberprüfung ersparen.
Referenzen
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki