Hallo an alle. Mein Name ist Danila, ich arbeite in einem Team, das in Avito eine analytische Infrastruktur entwickelt. Im Zentrum dieser Infrastruktur stehen A / B-Tests.
A / B-Experimente sind ein wichtiges Entscheidungsinstrument in Avito. In unserem Produktentwicklungszyklus ist ein A / B-Test ein Muss. Wir testen jede Hypothese und führen nur positive Änderungen durch.
Wir erfassen Hunderte von Metriken und können diese auf Geschäftsbereiche aufteilen: Branchen, Regionen, autorisierte Benutzer usw. Wir verwenden dies automatisch auf einer einzigen Plattform für Experimente. In dem Artikel werde ich Ihnen ausführlich genug erklären, wie die Plattform angeordnet ist, und wir werden auf einige interessante technische Details eingehen.

Die Hauptfunktionen der A / B-Plattform sind wie folgt formuliert.
- Hilft Ihnen, schnell Experimente durchzuführen
- Steuert unerwünschte Experimentkreuzungen
- Zählt Metriken, stat. testet, visualisiert Ergebnisse
Mit anderen Worten, die Plattform hilft dabei, fehlerfreie Entscheidungen am schnellsten zu treffen.
Wenn wir den Prozess der Entwicklung von Features, die zum Testen gesendet werden, weglassen, sieht der gesamte Zyklus des Experiments folgendermaßen aus:

- Der Kunde (Analyst oder Produktmanager) konfiguriert die Experimentparameter über das Admin-Panel.
- Der Split-Service verteilt gemäß diesen Parametern die erforderliche A / B-Gruppe an das Client-Gerät.
- Benutzeraktionen werden in Rohprotokollen gesammelt, die aggregiert und in Metriken umgewandelt werden.
- Metriken werden durch statistische Tests geführt.
- Die Ergebnisse werden am Tag nach dem Start auf dem internen Portal angezeigt.
Der gesamte Datentransport in einem Zyklus dauert einen Tag. Experimente dauern in der Regel eine Woche, aber der Kunde erhält jeden Tag eine Reihe von Ergebnissen.
Lassen Sie uns nun auf die Details eingehen.
Versuchsmanagement
Das Admin-Panel verwendet das YAML-Format, um Experimente zu konfigurieren.

Dies ist eine bequeme Lösung für ein kleines Team: Die Fertigstellung der Funktionen der Konfiguration erfolgt ohne Front. Die Verwendung von Textkonfigurationen vereinfacht die Arbeit für den Benutzer: Sie müssen weniger Mausklicks ausführen. Eine ähnliche Lösung wird vom Airbnb A / B-Framework verwendet .
Um den Verkehr in Gruppen aufzuteilen, verwenden wir die Common Salt Hashing-Technik.
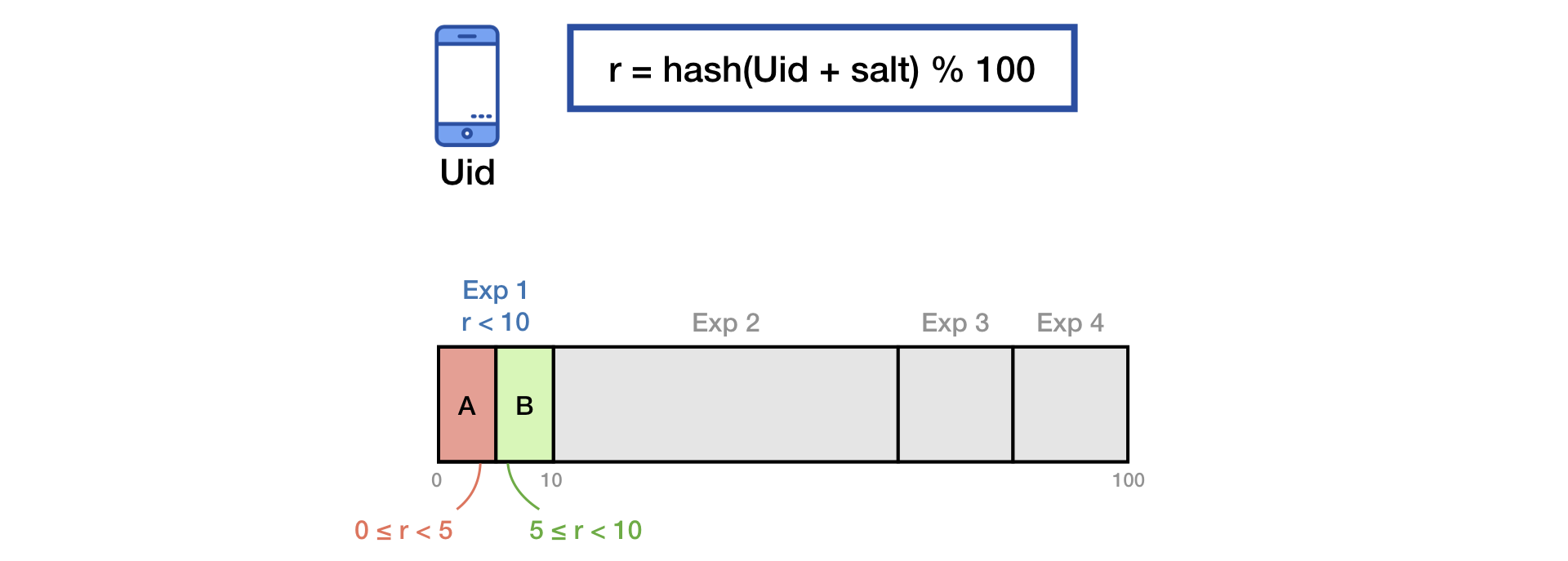
Um den Effekt des "Gedächtnisses" der Benutzer zu eliminieren, mischen wir zu Beginn eines neuen Experiments zusätzlich mit dem zweiten Salz:

Das gleiche Prinzip wird in der Präsentation von Yandex beschrieben .
Um potenziell gefährliche Überschneidungen von Experimenten zu vermeiden, verwenden wir eine Logik ähnlich der „Ebenen“ in Google .
Metriksammlung
Wir platzieren Rohprotokolle in Vertica und aggregieren sie zu Vorbereitungstabellen mit der Struktur:

Beobachtungen sind normalerweise einfache Ereigniszähler. Beobachtungen werden als Komponenten in der metrischen Berechnungsformel verwendet.
Die Formel zur Berechnung einer Metrik ist ein Bruch, dessen Zähler und Nenner die Summe der Beobachtungen ist:
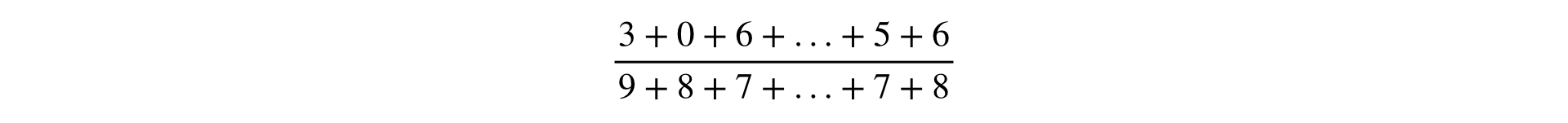
In einem der Berichte von Yandex wurden Metriken in zwei Typen unterteilt: nach Benutzern und Verhältnis. Dies ist geschäftlich sinnvoll, aber in der Infrastruktur ist es bequemer, alle Metriken auf dieselbe Weise wie das Verhältnis zu berücksichtigen. Diese Verallgemeinerung ist gültig, da die "posyuzerny" -Metrik offensichtlich als Bruch dargestellt werden kann:
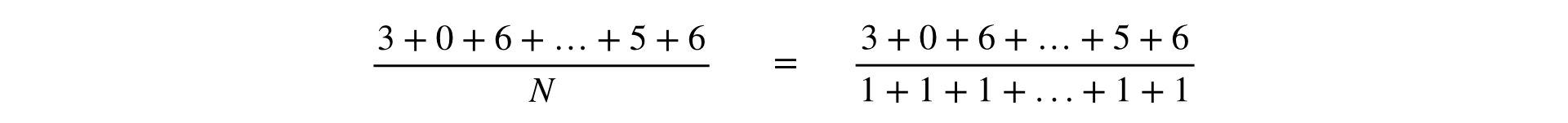
Wir fassen die Beobachtungen im Zähler und Nenner der Metrik auf zwei Arten zusammen.
Einfach:
Dies ist die übliche Menge aller Beobachtungen: die Anzahl der Suchanfragen, Klicks auf Anzeigen usw.
Und komplizierter:

Eine eindeutige Anzahl von Schlüsseln in der Gruppierung, um die die Gesamtzahl der Beobachtungen größer als ein bestimmter Schwellenwert ist.
Solche Formeln können einfach mit der YAML-Konfiguration festgelegt werden:

Die Groupby- und Schwellenwertparameter sind optional. Nur bestimmen sie die zweite Summierungsmethode.
Mit den beschriebenen Standards können Sie fast jede erdenkliche Online-Metrik konfigurieren. Gleichzeitig bleibt eine einfache Logik erhalten, die die Infrastruktur nicht übermäßig belastet.
Statistisches Kriterium
Wir messen die Signifikanz von Abweichungen anhand von Metriken mit den klassischen Methoden: T-Test , Mann-Whitney-U-Test . Die wichtigste notwendige Voraussetzung für die Anwendung dieser Kriterien ist, dass die Beobachtungen in der Stichprobe nicht voneinander abhängen. In fast allen unseren Experimenten glauben wir, dass Benutzer (Uid) diese Bedingung erfüllen.

Nun stellt sich die Frage: Wie werden T-Test und MW-Test für Verhältnismetriken durchgeführt? Für den T-Test müssen Sie in der Lage sein, die Varianz der Stichprobe zu lesen, und für MW sollte die Stichprobe „benutzerdefiniert“ sein.
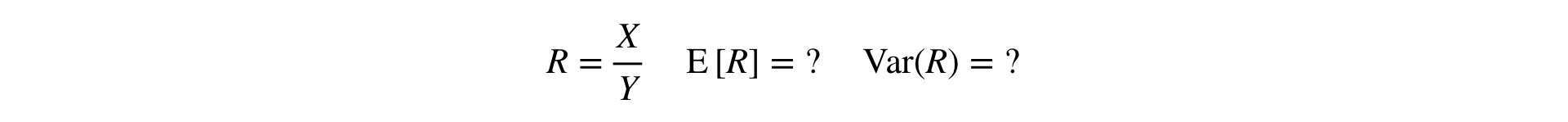
Antwort: Sie müssen das Verhältnis in einer Taylor-Reihe an einem Punkt auf die erste Ordnung erweitern ::
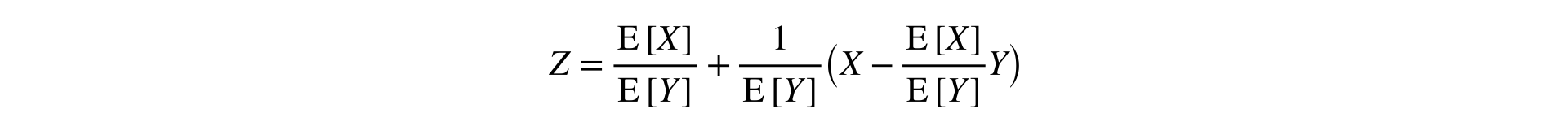
Diese Formel wandelt zwei Stichproben (Zähler und Nenner) in eine um, wobei der Mittelwert und die Varianz (asymptotisch) erhalten bleiben, was die Verwendung klassischer Statistiken ermöglicht. Tests.
Eine ähnliche Idee wird von Yandex-Kollegen als Verhältnislinearisierungsmethode ( einmaliges und zweimaliges Auftreten) bezeichnet.
Skalierungsleistung
Verwenden Sie schnell für die CPU-Statistik. Kriterien ermöglicht es, Millionen von Iterationen (Vergleiche von Behandlung und Kontrolle) in Minuten auf einem ganz normalen Server mit 56 Kernen durchzuführen. Bei großen Datenmengen hängt die Leistung jedoch in erster Linie von der Speicher- und Lesezeit von der Festplatte ab.
Die tägliche Berechnung von Uid-Metriken generiert Stichproben mit einer Gesamtgröße von Hunderten von Milliarden von Werten (aufgrund der großen Anzahl gleichzeitiger Experimente, Hunderten von Metriken und der kumulativen Akkumulation). Es ist zu problematisch, solche Volumes jeden Tag von der Festplatte zu entfernen (trotz des großen Clusters der Vertica-Spaltenbasis). Daher sind wir gezwungen, die Kardinalität von Daten zu reduzieren. Wir tun dies jedoch fast ohne Informationsverlust über die Varianz mit einer Technik namens "Bucket".
Die Idee ist einfach: Wir haben die Uids und "streuen" sie gemäß dem Rest der Division in eine Reihe von Eimern (wir bezeichnen ihre Anzahl mit B):
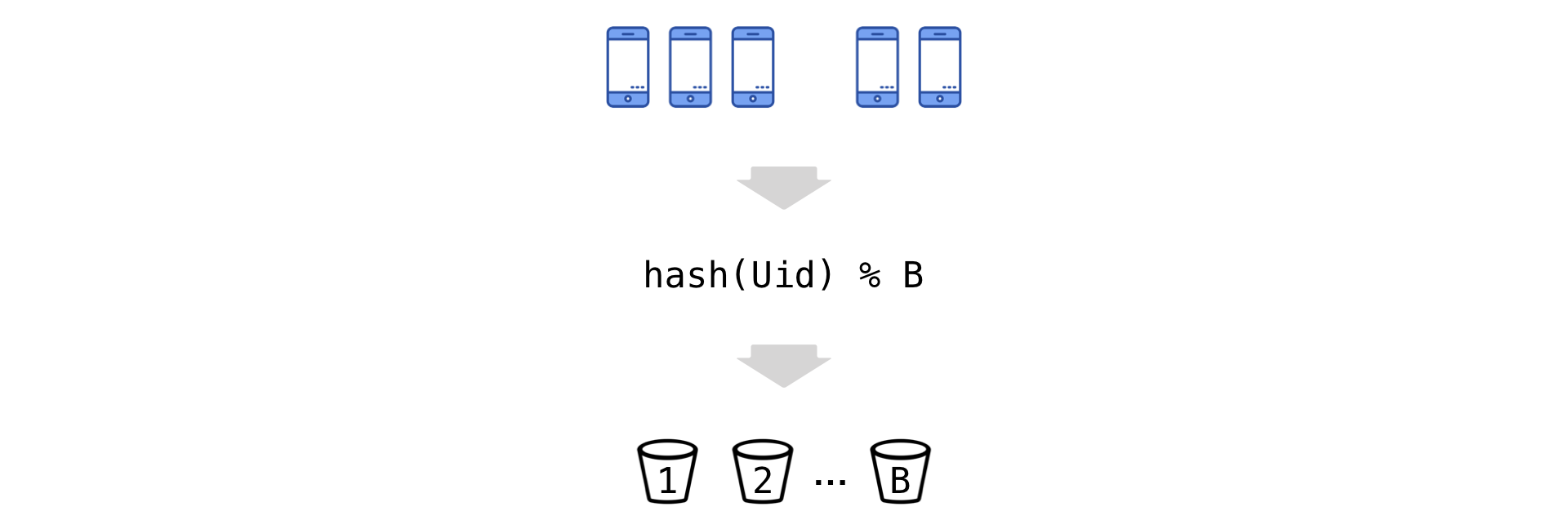
Jetzt gehen wir zur neuen experimentellen Einheit über - dem Eimer. Wir fassen die Beobachtungen im Eimer zusammen (Zähler und Nenner sind unabhängig voneinander):

Mit dieser Transformation wird die Bedingung für die Unabhängigkeit von Beobachtungen erfüllt, der Metrikwert ändert sich nicht und es ist leicht zu überprüfen, ob die Varianz der Metrik (Durchschnitt über die Stichprobe von Beobachtungen) erhalten bleibt:

Je mehr Bucket, desto weniger Informationen gehen verloren und desto kleiner ist der Gleichheitsfehler. In Avito nehmen wir B = 200.
Die metrische Verteilungsdichte nach der Bucket-Konvertierung wird immer ähnlich wie normal.
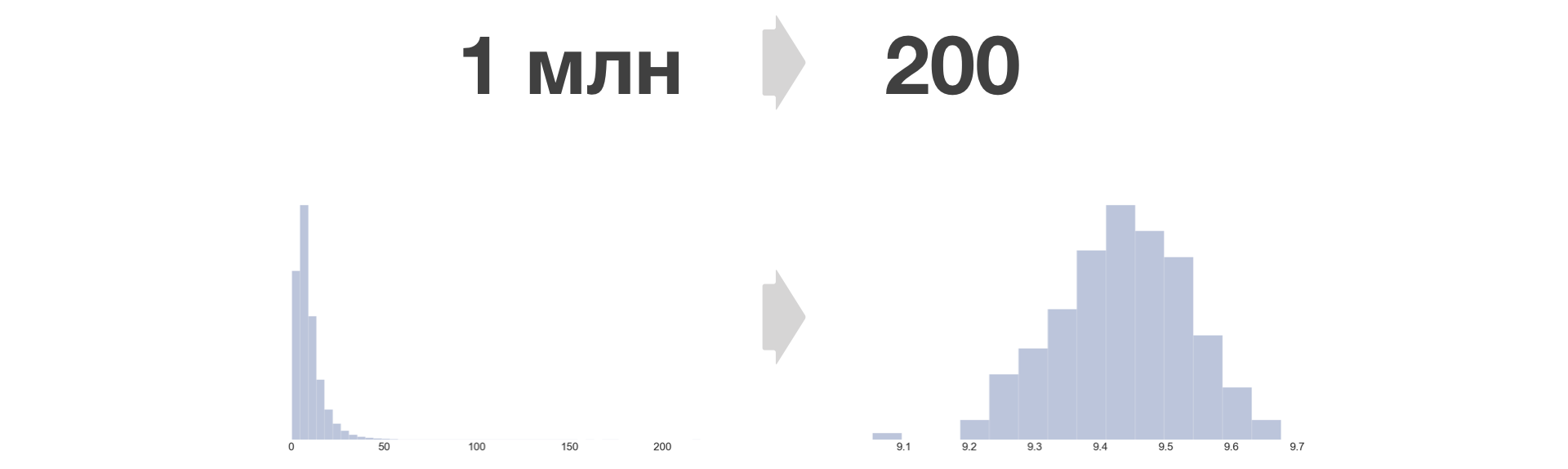
So viele große Proben können Sie auf eine feste Größe reduzieren. Das Wachstum der Menge der gespeicherten Daten hängt in diesem Fall nur linear von der Anzahl der Experimente und Metriken ab.
Ergebnisvisualisierung
Als Visualisierungstool verwenden wir Tableau und Webview auf Tableau Server. Jeder Avito-Mitarbeiter hat dort Zugriff. Es ist zu beachten, dass Tableau die Arbeit gut macht. Eine ähnliche Lösung mit einer vollständigen Back / Front-Entwicklung zu implementieren, wäre eine viel ressourcenintensivere Aufgabe.
Die Ergebnisse jedes Experiments sind ein Blatt mit mehreren tausend Zahlen. Die Visualisierung muss so beschaffen sein, dass falsche Schlussfolgerungen bei der Implementierung von Fehlern der ersten und zweiten Art minimiert werden und gleichzeitig die Änderungen in wichtigen Metriken und Abschnitten nicht „übersehen“ werden.
Zunächst überwachen wir die "Gesundheits" -Metriken der Experimente. Das heißt, wir beantworten die Fragen: "Stimmt es, dass die Teilnehmer in jede der Gruppen" eingegossen "wurden?", "Entspricht es den autorisierten oder neuen Benutzern?"
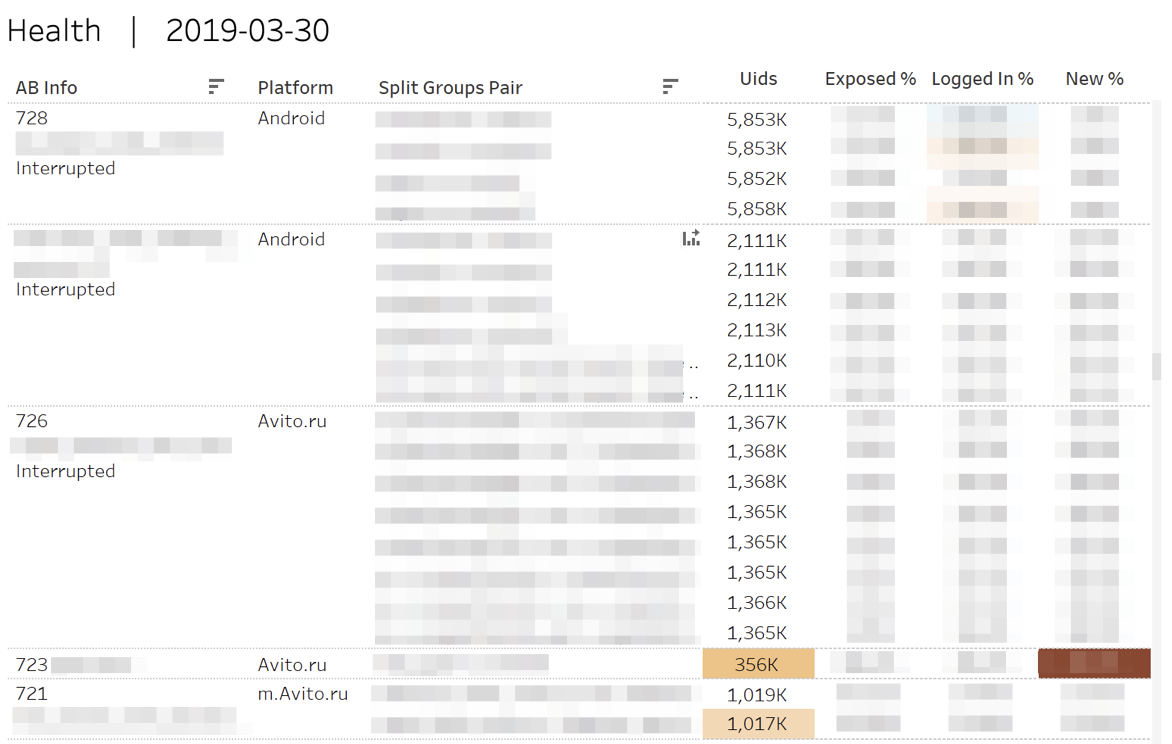
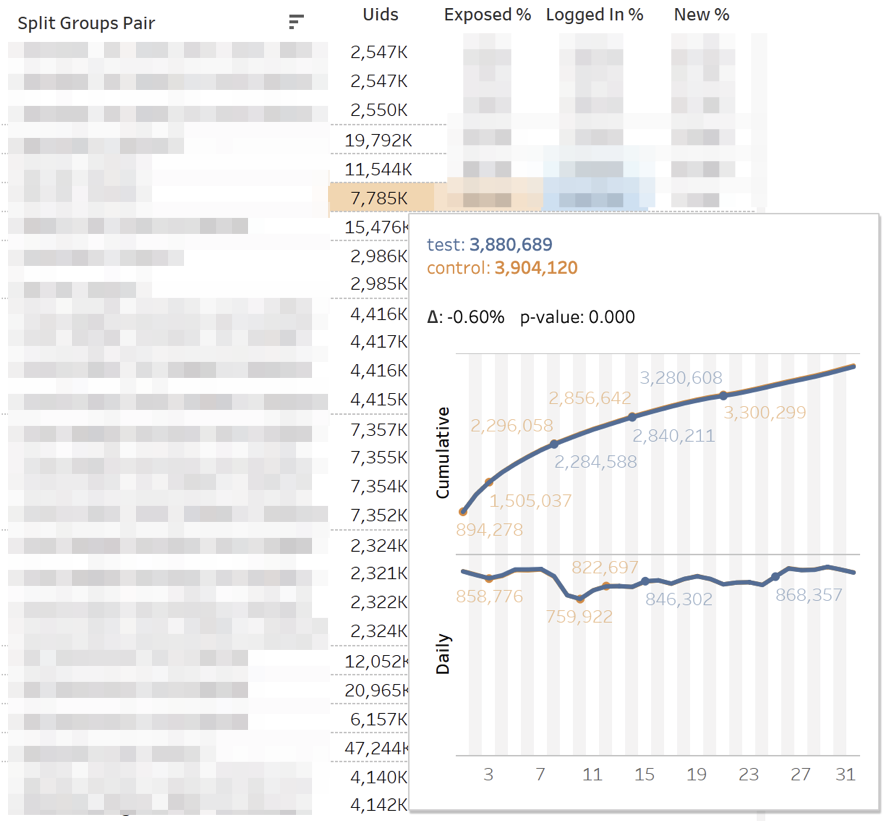
Bei statistisch signifikanten Abweichungen werden die entsprechenden Zellen hervorgehoben. Wenn Sie mit der Maus über eine beliebige Zahl fahren, wird die kumulative Dynamik des Tages angezeigt.
Das Haupt-Dashboard mit Metriken sieht folgendermaßen aus:
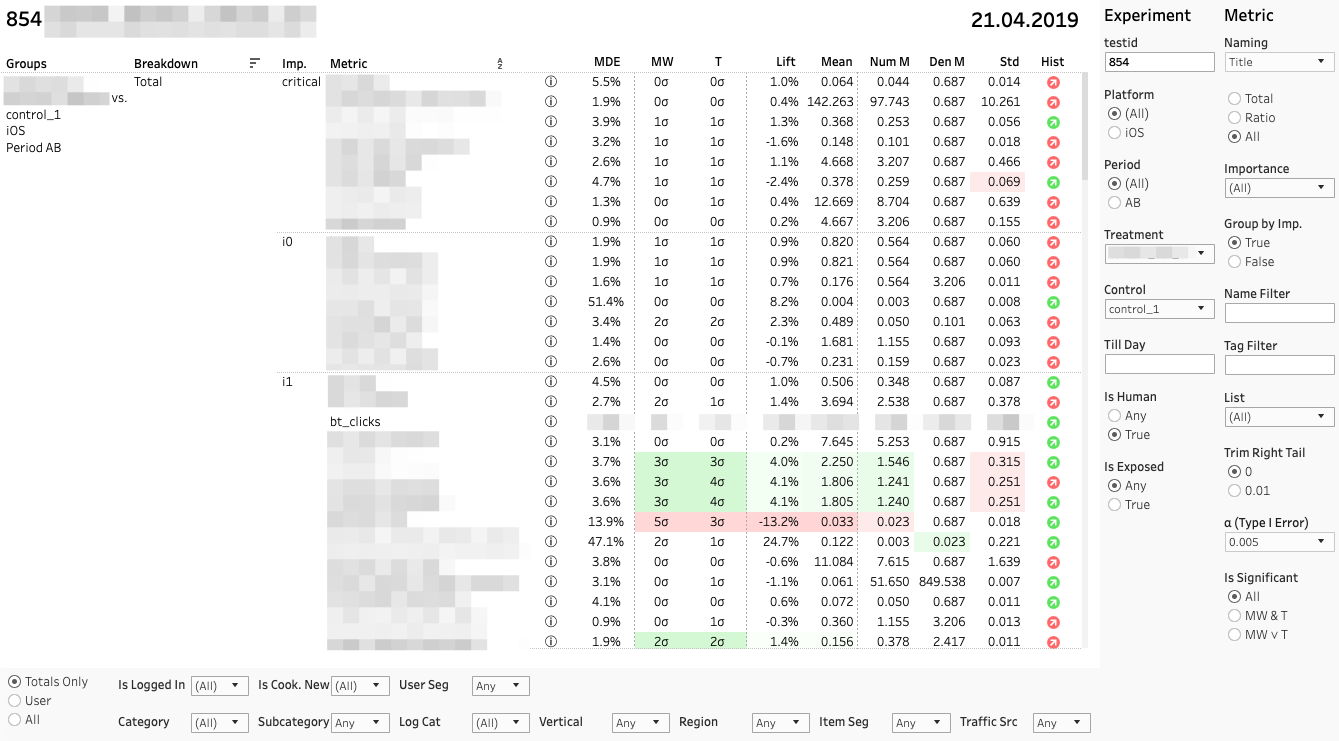
Jede Zeile ist ein Vergleich von Gruppen anhand einer bestimmten Metrik in einem bestimmten Abschnitt. Auf der rechten Seite befindet sich ein Feld mit Filtern für Experimente und Metriken. Filterplatte unten.
Jeder Metrikvergleich besteht aus mehreren Metriken. Lassen Sie uns ihre Werte von links nach rechts analysieren:
1. MDE. Minimaler nachweisbarer Effekt

⍺ und β sind vorgewählte Fehlerwahrscheinlichkeiten der ersten und zweiten Art. MDE ist sehr wichtig, wenn die Änderung statistisch nicht signifikant ist. Bei der Entscheidungsfindung muss der Kunde berücksichtigen, dass das Fehlen von stat. Bedeutung ist nicht gleichbedeutend mit keiner Wirkung. Zuverlässig können wir nur sagen, dass der mögliche Effekt nicht mehr als MDE ist.
2. MW | T. Mann-Whitney U- und T-Testergebnisse
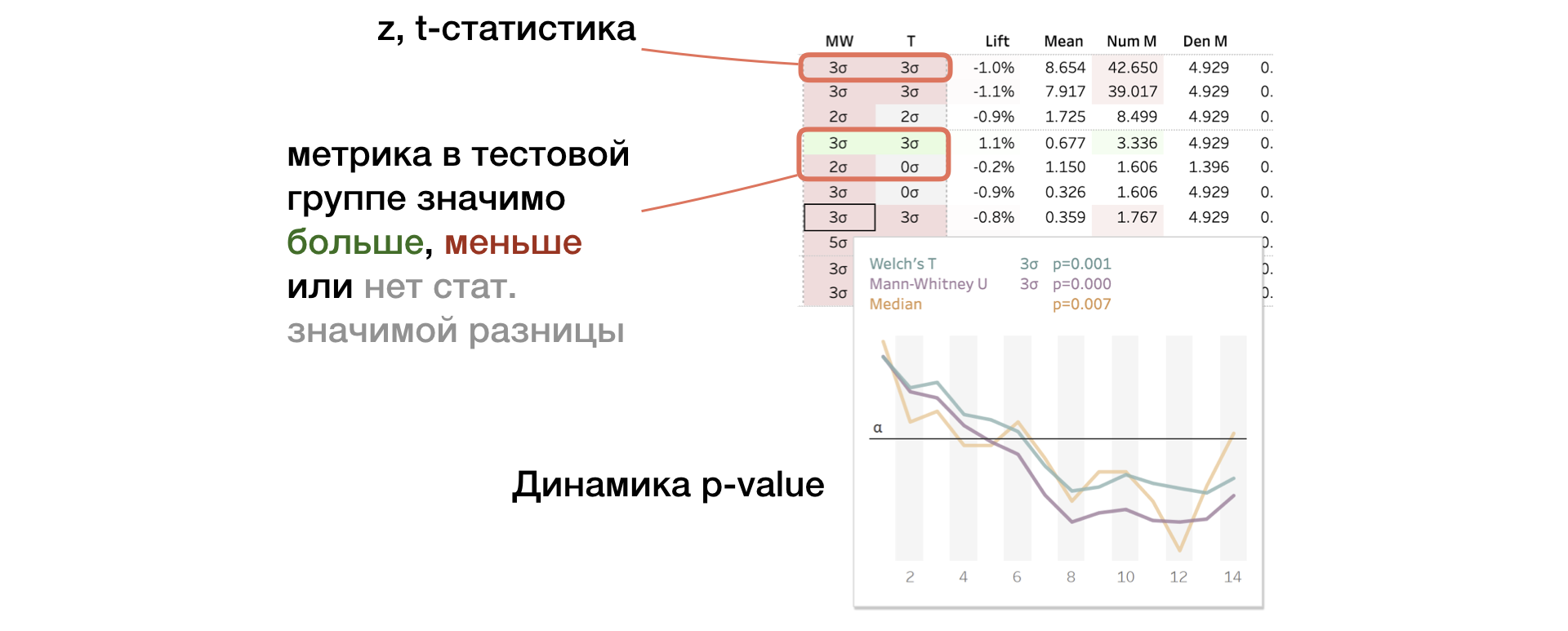
Das Feld zeigt den Wert der z- und t-Statistik an (für MW bzw. T). In einem Tooltip - p-Wert-Dynamik. Wenn die Änderung signifikant ist, wird die Zelle je nach Vorzeichen des Unterschieds zwischen den Gruppen rot oder grün hervorgehoben. In diesem Fall sagen wir, dass die Metrik "farbig" ist.
3. Heben. Prozentualer Unterschied zwischen Gruppen
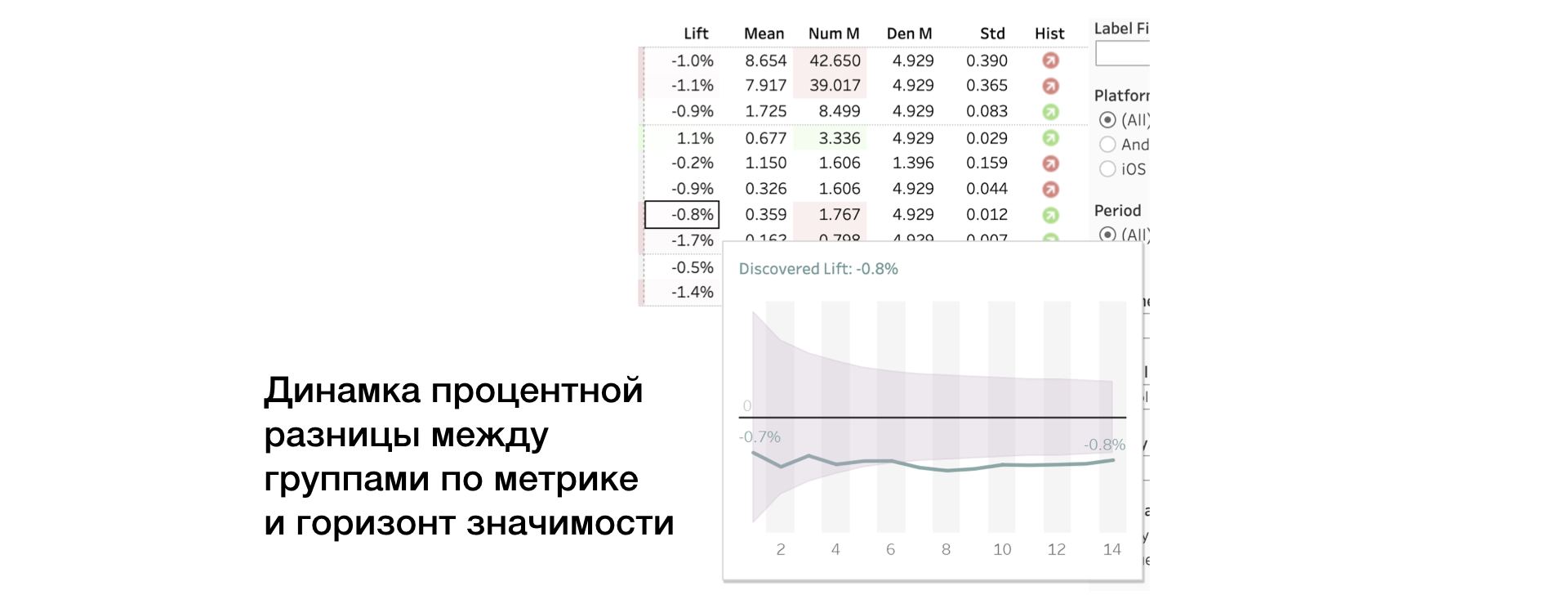
4. Mittelwert | Num | Den Metrikwert sowie Zähler und Nenner getrennt
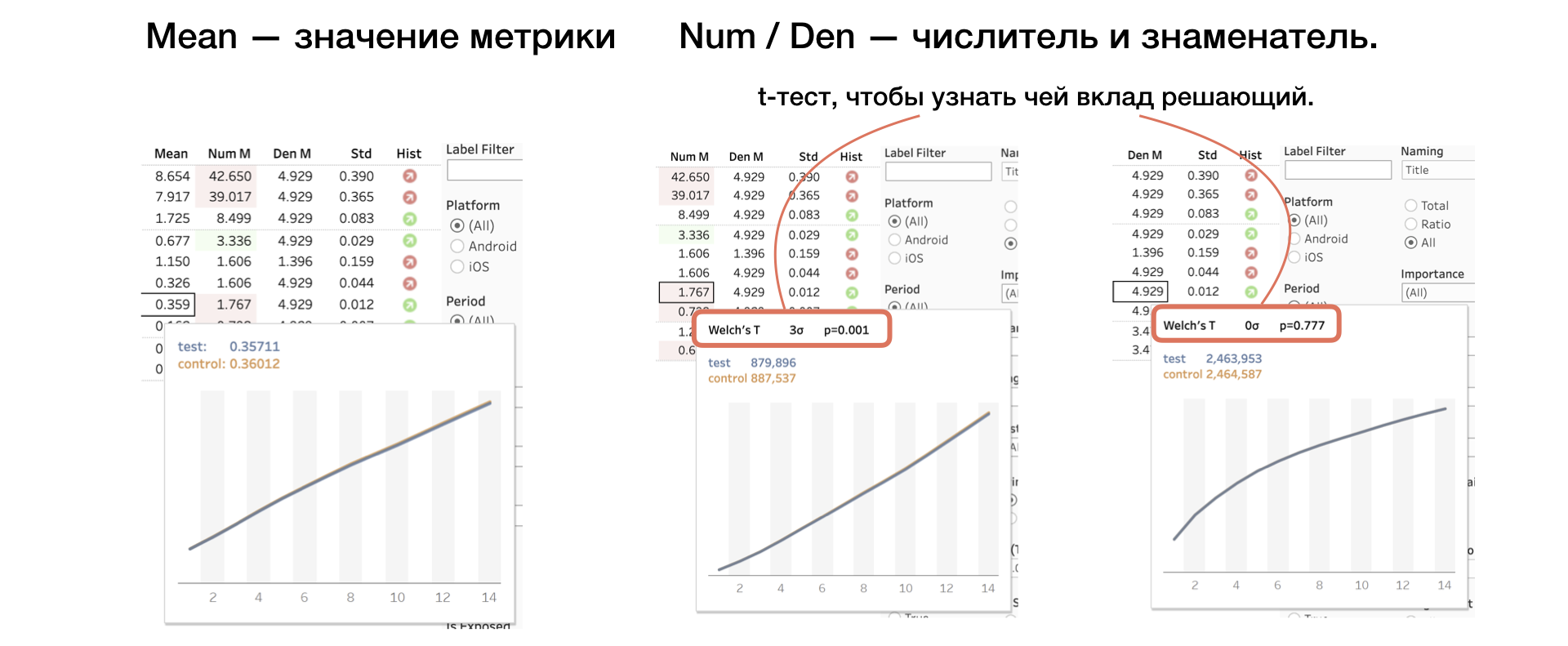
Wir wenden einen weiteren T-Test auf Zähler und Nenner an, um zu verstehen, wessen Beitrag entscheidend ist.
5. Std. Selektive Standardabweichung
6. Hist. Shapiro-Wilk-Test auf Normalität der "Bucket" -Verteilung.
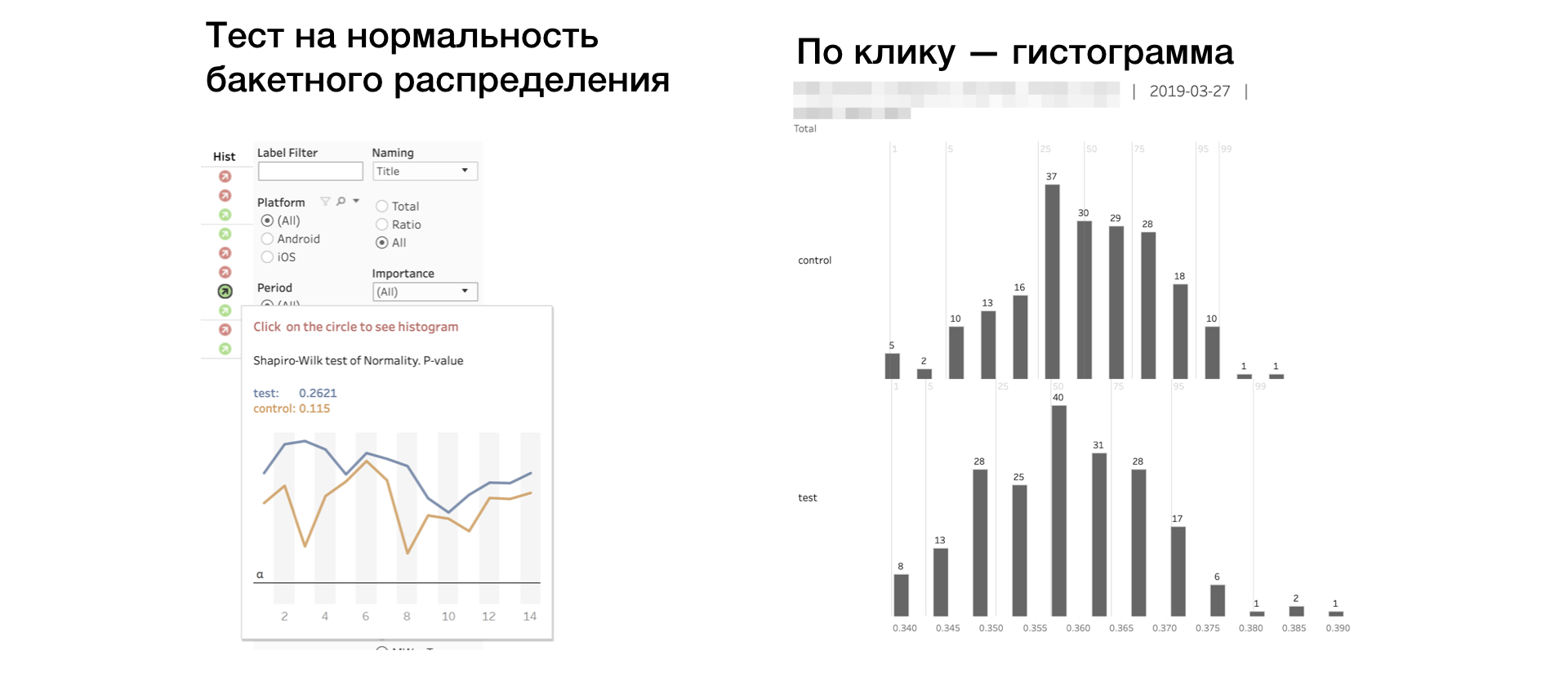
Wenn der Indikator rot ist, hat die Probe möglicherweise Ausreißer oder einen ungewöhnlich langen Schwanz. In diesem Fall müssen Sie das Ergebnis gemäß dieser Metrik sorgfältig oder gar nicht nehmen. Durch Klicken auf den Indikator wird das Histogramm der Metrik nach Gruppe geöffnet. Das Histogramm zeigt deutlich Anomalien - es ist einfacher, Schlussfolgerungen zu ziehen.
Fazit
Die Entstehung der A / B-Plattform in Avito ist ein Wendepunkt, als unser Produkt schneller zu wachsen begann. Jeden Tag machen wir grüne Experimente, die das Team belasten. und „Rotweine“, die gesunde Denkanstöße geben.
Es ist uns gelungen, ein effektives System von A / B-Tests und -Metriken aufzubauen. Oft haben wir komplexe Probleme mit einfachen Methoden gelöst. Aufgrund dieser Einfachheit verfügt die Infrastruktur über einen guten Sicherheitsspielraum.
Ich bin sicher, dass diejenigen, die die A / B-Plattform in ihrem Unternehmen aufbauen werden, in dem Artikel einige interessante Erkenntnisse gefunden haben. Ich freue mich, unsere Erfahrungen mit Ihnen zu teilen.
Schreiben Sie Fragen und Kommentare - wir werden versuchen, sie zu beantworten.