In einem früheren Artikel haben wir den Ansatz untersucht, den wir auf das Problem der rechnergestützten (aggregierten) Datenverarbeitung zur Visualisierung auf interaktiven Dashboards angewendet haben. Der Artikel ging auf die Phase der Bereitstellung von Informationen aus Primärquellen an Benutzer im Kontext von Analysefällen ein, die es ermöglichen, den Informationswürfel zu drehen. Das vorgestellte Datenkonvertierungsmodell im laufenden Betrieb erstellt eine Abstraktion und bietet ein einziges Abfrageformat und einen Konstruktor zur Beschreibung der Berechnungen, Aggregation und Integration aller verbundenen Quellentypen - Datenbanktabellen, Dienste und Dateien .
Bei den aufgelisteten Quellen handelt es sich eher um strukturierte Quellen, was die Vorhersagbarkeit des Datenformats und die Eindeutigkeit der Verfahren für ihre Verarbeitung und Visualisierung impliziert. Für den Analysten sind unstrukturierte Daten jedoch nicht weniger interessant. Wenn die ersten Ergebnisse vorliegen, werden die Erwartungen an solche Systeme manchmal überschätzt. Appetit kommt mit Essen, und der Verlust der Vorsicht kann die Geschichte genau wiederholen ...
- Noch! Mehr Gold!
Aber sein Keuchen war kaum hörbar und Entsetzen erschien in seinen Augen
(Märchen "Goldene Antilope")

In diesem Artikel werden die wichtigsten Funktionen und das Design eines Mehrrollenclusters und eines Verhaltens- Crawlers von virtuellen Benutzern beschrieben, die die Routine zum Sammeln von Informationen aus komplexen Internetressourcen automatisieren. Und nur die Frage nach der Grenze solcher Systeme wird aufgeworfen.
Bei der Betrachtung von Crawling-Methoden kann jede hypothetische Internet-Ressource, aus der Informationen extrahiert werden müssen, auf einer Skala mit zwei Extremen platziert werden - von einfachen statischen Ressourcen und APIs bis hin zu dynamischen interaktiven Websites, die eine hohe Benutzerbeteiligung erfordern. Ersteres umfasst die alte Generation von Suchrobotern ( zumindest moderne haben gelernt, JavaScript zu verarbeiten ), letzteres umfasst Systeme mit Browserfarmen und Algorithmen, die die Arbeit des Benutzers simulieren oder ihn beim Sammeln von Informationen anziehen.
Mit anderen Worten, Crawling-Technologien können auf einer Komplexitätsskala platziert werden:

Einerseits kann die Komplexität der Quelle als eine Kette von Maßnahmen verstanden werden, die erforderlich sind, um Primärinformationen zu erhalten, und andererseits als Technologien, die angewendet werden müssen, um maschinenlesbare Daten zu erhalten, die für die Analyse geeignet sind.
Selbst das scheinbar einfache Extrahieren von Texten aus statischen Seiten ist in der Praxis nicht immer trivial - es ist entweder erforderlich, HTML-Planarisierungsregeln für alle Seitentypen zu entwickeln und zu pflegen oder Heuristiken und komplexe Lösungen zu automatisieren und zu erfinden. Bis zu einem gewissen Grad wird die Strukturierung durch die Entwicklung von Mikro-Markups ( insbesondere Schema.org , RDFa , verknüpfte Daten ) vereinfacht, jedoch nur in engen Sonderfällen zum Herunterladen von Firmenkarten, Produkten, Visitenkarten und anderen Produkten zur Suchmaschinenoptimierung sowie offenen Daten.
Im Folgenden werden wir den Umfang bewusst einschränken und uns auf die technologische Komponente einer Teilmenge von Browser-Crawlern konzentrieren, die zum Herunterladen von Informationen von komplexen Websites, insbesondere sozialen Netzwerken, entwickelt wurden. Dies ist genau dann der Fall, wenn andere einfache Crawler-Methoden nicht funktionieren.
Stellen Sie sich einen Ansatz vor, der die Aufgabe des Sammelns von Informationen aus sozialen Netzwerken auf die Bildung eines Informationszeitleistenbands reduziert - eine aktualisierte Sammlung oder einen aktualisierten Strom von Objekten mit Attributen und Zeitstempeln. Die Liste der Objekttypen und ihrer Attribute ist unterschiedlich, änderbar und erweiterbar, z. B. Posts, Likes, Kommentare, Reposts und andere Entitäten, die von Entwicklern und Analyseoperatoren zum System hinzugefügt und von Crawlern geladen werden.
Da das Band ein Strom strukturierter Objekte ist, stellt sich die Frage nach seiner Füllung. Wir haben zwei Arten von Bändern unterstützt:
- ein einfaches Band, das mit Inhalten aus festen Quellen gefüllt ist;
- Ein Themen-Feed, der mit Inhalten nach Schlüsselwörtern, Phrasen und Suchbegriffen gefüllt ist.
Ein Beispiel für einen einfachen Feed mit festen Quellen ( Listen von URLs für Profile und Seiten werden festgelegt ):

Ein einfacher Bandtyp umfasst das regelmäßige Crawlen dieser Profile und Seiten in verschiedenen sozialen Netzwerken mit einer bestimmten Crawltiefe und das Laden von vom Benutzer ausgewählten Objekten. Beim Auffüllen steht das Band zum Anzeigen, Analysieren und Hochladen von Daten zur Verfügung:

Das Themenband ist eine einfache Erweiterung und bietet Volltextsuche und Filterung von Objekten, die auf das Band geladen wurden. Das System steuert automatisch den Satz von Bandquellen und die Tiefe ihres Bypasses und analysiert die Relevanz und die Beziehungen der Quellen. Diese Funktion der Implementierung ist auf das Fehlen oder die "seltsame" Arbeit der integrierten Suche nach Schlüsselwörtern in sozialen Netzwerken zurückzuführen. Selbst wenn eine solche Funktion verfügbar ist, werden die Ergebnisse meistens nicht vollständig generiert und entsprechen einem internen Algorithmus, der mit den Anforderungen für den Crawler nicht kompatibel ist.
Ein spezieller Mechanismus mit einer bestimmten Heuristik ist für die Verwaltung des Bandes im System verantwortlich. Er analysiert Daten und Verlauf, fügt relevante Quellen (Profil- und Community-Feeds) hinzu, auf denen entweder bestimmte Ausdrücke erwähnt werden oder die in irgendeiner Weise mit ihnen zusammenhängen, und entfernt irrelevante.
Ein Beispiel für ein thematisches Band:

In Zukunft werden Bänder als Quelle für analytische Transformationen mit anschließender Visualisierung der Ergebnisse verwendet, beispielsweise in Form eines Diagramms:

In einigen Fällen wird die Streaming-Verarbeitung eingehender Objekte mit Speichern in spezialisierten Zielsammlungen oder Hochladen über die REST-API durchgeführt, um den gesammelten Inhalt in Systemen von Drittanbietern zu verwenden ( Beispiel ). In anderen Fällen wird die Blockverarbeitung durch einen Zeitgeber durchgeführt. Der Operator beschreibt das Verarbeitungsskript mit einem Skript oder erstellt einen Prozess mit Steuersignalen und Funktionsblöcken, zum Beispiel:

Aufgabenpool
Aktive Bänder definieren den primären Aufgabenpool, von denen jeder verwandte Aufgaben bildet. Beispielsweise kann eine einzelne Profildurchlaufaufgabe viele verwandte Unteraufgaben generieren - Umgehen von Freunden, Abonnenten oder Herunterladen neuer Beiträge und detaillierter Informationen usw. Es gibt auch eine Phase der Vorverarbeitung neuer Objekte des thematischen Bandes, die auch Aufgaben im Zusammenhang mit neuen relevanten Quellen bildet.
Infolgedessen erhalten wir eine große Anzahl verschiedener Arten von Aufgaben, die miteinander in Beziehung stehen und Prioritäten, Zeit und Ausführungsbedingungen haben. All dieser Zoo muss korrekt verwaltet werden, damit es keine Situationen gibt, in denen einige Aufgaben alle Clusterressourcen zum Nachteil von Aufgaben von anderen Bändern auf sich ziehen würden .
Um die Inkonsistenzen zu beheben, implementiert das System gemeinsam genutzte virtuelle Ressourcen und einen Mechanismus zur dynamischen Priorisierung, der die Aufgabentypen, die aktuelle Zeit und die Wahrscheinlichkeit des Starts in Form einer "Kuppel" berücksichtigt. Im Allgemeinen - die Priorität an einem bestimmten Punkt wird maximal, verschwindet aber bald, die Aufgabe "sauer", aber unter bestimmten Umständen kann sie wieder wachsen.
Die Formel für eine solche Kuppel berücksichtigt mehrere Faktoren, insbesondere die Priorität der übergeordneten Aufgaben, die Relevanz der zugehörigen Quelle und den Zeitpunkt des letzten Versuchs (mit wiederholten Crawls zur Verfolgung von Änderungen oder wenn ein Fehler auftritt).
Virtuelle Benutzer
Im weitesten Sinne kann ein virtueller Benutzer praktisch als die maximale Nachahmung menschlicher Handlungen verstanden werden - eine Reihe von Eigenschaften, die ein Crawler haben sollte:
- Führen Sie den Seitencode mit denselben Tools wie der Benutzer aus - Betriebssystem, Browser, UserAgent, Plugins, Schriftarten und mehr.
- mit der Seite interagieren, die Arbeit einer Person mit Tastatur und Maus simulieren - den Cursor auf der Seite bewegen, zufällige Bewegungen ausführen, Pausen einlegen, beim Drucken von Text Tasten drücken und vieles mehr ( mobile Geräte nicht vergessen );
- Interagieren Sie mit einem Entscheidungszentrum, das den Kontext und den Inhalt der Seite berücksichtigt:
- Berücksichtigen Sie Duplikate, die Relevanz von Objekten auf der Seite, die Durchforstungstiefe, Zeitrahmen und mehr.
- auf ungewöhnliche Situationen reagieren - im Falle von Captcha oder Fehlern eine Anfrage stellen und auf eine Lösung warten, entweder über einen Drittanbieter oder unter Einbeziehung eines Systembetreibers;
- Haben Sie eine glaubwürdige Legende - speichern Sie Ihren Browserverlauf und Ihre Cookies (Browserprofil), verwenden Sie bestimmte IP-Adressen, berücksichtigen Sie Zeiträume mit den meisten Aktivitäten (z. B. morgens-abends oder mittags-abends).
In einer idealisierten Ansicht kann ein virtueller Benutzer mehrere Konten haben, mehrere Browser zu unterschiedlichen Zeitpunkten verwenden und mit anderen virtuellen Benutzern verbunden sein sowie das Verhalten und die Gewohnheiten des Surfens im Internet besitzen, die für eine Person charakteristisch sind.
Stellen Sie sich zum Beispiel eine solche Situation vor: Virtuell verwendet man einen Browser und eine IP wie bei der Arbeit (dieselbe IP kann von "Kollegen" verwendet werden), einen anderen Browser und eine IP wie zu Hause ("Nachbarn" verwenden sie) und von Zeit zu Zeit Handy. Angesichts dieser Sichtweise des Problems scheint es eine nicht triviale und möglicherweise unpraktische Aufgabe zu sein, der automatisierten Erfassung durch Internetdienste entgegenzuwirken.
In der Praxis ist alles viel einfacher - der Kampf gegen Crawler ist wellenartig und umfasst eine kleine Reihe von Techniken: manuelle Moderation, Analyse des Benutzerverhaltens (Häufigkeit und Einheitlichkeit von Aktionen) und Anzeigen von Captcha. Claruler, der zumindest teilweise die Eigenschaften aus der obigen Liste besitzt, implementiert das Konzept der virtuellen Benutzer vollständig und kann mit der gebotenen Aufmerksamkeit des Bedieners seine Funktion für eine lange Zeit erfüllen und bleibt " schwer fassbarer Joe ".
Aber was ist mit der ethischen und rechtlichen Seite der Verwendung virtueller Benutzer?
Um nicht mit den Konzepten öffentlicher und personenbezogener Daten zu spielen, hat jede der Parteien ihre eigenen gewichtigen Argumente, wir werden nur auf die grundlegenden Punkte eingehen.
Die automatische Veröffentlichung von Inhalten, das Versenden von Spam, die Registrierung von Konten und andere "aktive" Aktivitäten virtueller Benutzer können leicht als illegal angesehen werden oder die Interessen Dritter beeinträchtigen. In dieser Hinsicht implementiert das System einen Ansatz, bei dem virtuelle Benutzer nur neugierige Beobachter sind, die den Benutzer (ihren Bediener) repräsentieren und stattdessen eine Routine zum Sammeln von Informationen ausführen.
Gemeinsame Verwaltung virtueller Ressourcen
Wie oben beschrieben, ist ein virtueller Benutzer eine kollektive Entität, die dabei mehrere System- und virtuelle Ressourcen verwendet. Einige Ressourcen werden alleine verwendet, während andere von mehreren virtuellen Benutzern gemeinsam genutzt werden. Beispiel:
- Ausgabeknotenadresse (externe IP) - einem oder mehreren virtuellen Benutzern zugeordnet;
- Browserprofil - einem einzelnen virtuellen Benutzer zugeordnet;
- Computerressource - mit dem Server verbunden, legt die Einschränkungen des Servers als Ganzes und für jeden Aufgabentyp fest;
- Virtueller Bildschirm - Legt Servereinschränkungen fest, wird jedoch vom virtuellen Benutzer verwendet.
Jede virtuelle Ressource verfügt über einen Typ und eine Gruppe von Instanzen, die als Slots bezeichnet werden. Auf jedem Knoten des Clusters wird die Konfiguration von virtuellen Ressourcen und Slots definiert, die dem Pool virtueller Ressourcen hinzugefügt werden und auf die alle Knoten des Clusters zugreifen können. Darüber hinaus können für einen Typ einer virtuellen Ressource sowohl eine feste als auch eine variable Anzahl von Steckplätzen hinzugefügt werden.
Jeder Slot kann Attribute haben, die als Bedingungen beim Verknüpfen und Zuweisen von Ressourcen verwendet werden. Beispielsweise können wir jeden virtuellen Benutzer bestimmten Arten von Aufgaben, Servern, IP-Adressen, Konten, Zeiträumen mit der größten Crawling-Aktivität und anderen beliebigen Attributen zuordnen.
Im allgemeinen Fall besteht der Lebenszyklus einer Ressource aus bestimmten Phasen:
- Wenn ein Clusterknoten im gemeinsam genutzten Pool virtueller Ressourcen gestartet wird, werden zusätzliche offene Slots sowie Verknüpfungen zwischen Ressourcen registriert.
- Wenn eine Aufgabe von einem Dispatcher aus einem Pool virtueller Ressourcen gestartet wird, wird ein geeigneter freier Steckplatz ausgewählt und blockiert. Das Blockieren der übergeordneten Ressource führt wiederum zum Blockieren verwandter Ressourcen, und wenn keine freien Slots vorhanden sind, wird ein Fehler generiert.
- Nach Abschluss der Aufgabe werden der Hauptressourcensteckplatz und die zugehörigen Steckplätze freigegeben.
Zusätzlich zu den in der Knotenkonfiguration angegebenen gibt es auch virtuelle Benutzerressourcen - Entitäten, mit denen der Systembetreiber arbeitet. Insbesondere verwendet der Bediener die virtuelle Benutzerregistrierungsschnittstelle, die mehrere nützliche Funktionen gleichzeitig unterstützt:
- Verwaltung von Details und zusätzlichen Attributen, die die Besonderheiten der Verwendung angeben, insbesondere können virtuelle Benutzer in Gruppen unterteilt und für verschiedene Zwecke verwendet werden;
- Verfolgung des Status und der Statistiken virtueller Benutzer;
- Verbindung zum virtuellen Bildschirm - Echtzeit-Verfolgung der Arbeit, Ausführen von Aktionen im Browser anstelle des virtuellen Benutzers (Remotedesktop-Widget).
Beispielregistrierung virtueller Benutzerressourcen:

Cooler Fall, der keine Wurzeln geschlagen hat
Zusätzlich zu Informationsbändern als „Killer Fitchi“ haben wir ein Prototyp-Suchdiagramm entwickelt, um komplexe Suchvorgänge durchzuführen und Online-Untersuchungen durchzuführen. Die Hauptidee besteht darin, ein visuelles Diagramm zu erstellen, in dem die Knoten die Vorlagen von Objekten (Personen, Organisationen, Gruppen, Veröffentlichungen, Likes usw.) und die Verknüpfungen die Verbindungsmuster zwischen den gefundenen Objekten sind.
Ein Beispiel für ein einfaches Suchdiagramm von Personen und deren Beziehungen:

Bei diesem Ansatz wird davon ausgegangen, dass die Suche mit einem Minimum an bekannten Informationen beginnt. Nach der ersten Suche überprüft der Benutzer die Ergebnisse und fügt dem Suchdiagramm schrittweise zusätzliche Bedingungen hinzu, wodurch die Auswahl eingegrenzt und die Durchforstungstiefe und Genauigkeit des Ergebnisses erhöht wird. Letztendlich hat der Graph die Form, in der jeder der Knoten ein separater Informationsfeed mit den Ergebnissen ist. Dieses Band kann auch als Quelle für die weitere Analyse und Visualisierung auf Dashboards und Widgets verwendet werden.

Zum Beispiel ...Als Beispiel können wir einige einfache Fälle betrachten:
- finde alle Freunde der Person mit dem Vornamen;
- Finde alle Beiträge von Freunden einer Person mit einem bestimmten Namen und anderen Attributen.
- Finden Sie alle Abonnenten der Seiten, auf denen die angegebenen Schlüsselbegriffe erwähnt werden, oder sammeln Sie die Umgebung um bestimmte Beiträge oder Autoren.
- oder Überschneidungen finden - Autoren von Kommentaren zu allen Posts von Autoren, die einmal Posts zu bestimmten Themen veröffentlicht haben.
Als wir die Entwicklung einer solchen Passform ankündigten, unterstützten unsere Kunden und Partner diese Idee nachdrücklich. Es schien genau das zu sein, was bei bestehenden ähnlichen Lösungen sehr fehlte. Nach Fertigstellung des funktionierenden Prototyps stellte sich jedoch in der Praxis heraus, dass die Kunden nicht bereit waren, ihre internen Prozesse zu ändern, und Internetuntersuchungen wurden eher als nützlich angesehen, wenn sie plötzlich benötigt wurden. Gleichzeitig ist die Funktionalität von technologischer Seite ernst und erfordert eine weitere Verfeinerung und Unterstützung. Aufgrund der mangelnden Nachfrage und des praktischen Interesses unserer Partner musste dieser Fitch vorübergehend bis zu besseren Zeiten eingefroren werden.
Reinkarnation
Angesichts des aktuellen Entwicklungsvektors unserer Lösungen scheint dieses Merkmal immer noch relevant zu sein, aber aus technischer Sicht wird es bereits anders gesehen. Es handelt sich vielmehr um eine Erweiterung der Funktionalität von Cubisio, nämlich des Editors des Domänenmodells und des Editors von Datenverarbeitungsprozessen, die bisher als Prototyp implementiert wurden, jedoch einen ähnlichen Ansatz in verallgemeinerter Form vorsehen.
Ein Beispiel für das ontologische Modell des Themenbereichs "Soziale Netzwerke" (Klicken auf das Bild des Editors öffnet sich):

Ein Beispiel für ein suchanalytisches Diagramm, das auf der obigen Ontologie basiert (durch Klicken auf das Bild wird der Editor geöffnet):

Cluster-Technologie-Stack

Das beschriebene System wurde vor einigen Jahren in Verbindung mit der Plattform (wir nennen es dWires) entwickelt. Es funktioniert und wird noch verwendet. Die wichtigsten erfolgreichen Lösungen sind natürlich auf unsere neuen Entwicklungen übergegangen. Insbesondere stellt die beschriebene Plattform die erste Generation des Entwicklers von Informationsanalysesystemen dar, aus der die jsBeans-Plattform und unsere anderen Entwicklungen hervorgegangen sind.
Kurz gesagt, das System basiert auf dem Akka-Cluster, dem Rhino-Interpreter und dem eingebetteten Jetty-Webserver. Einige nützliche architektonische Merkmale sind in der obigen Abbildung dargestellt. , , , JavaScript- , jsBeans .
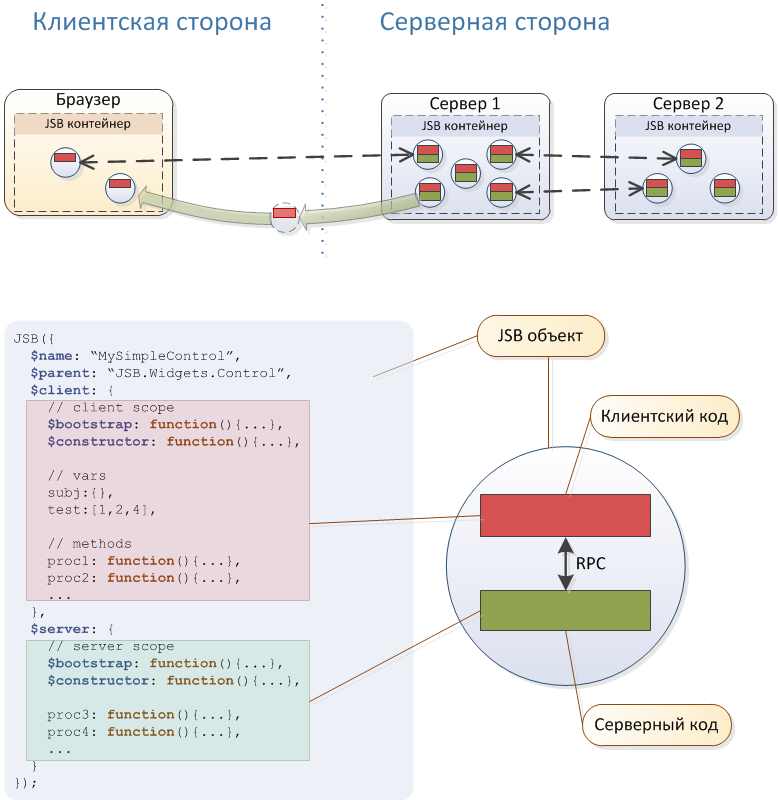
, – .
Java. , , – - JavaScript. JavaScript ( ), , , . – , , , , , - .
Akka - . - Akka Cluster , . , " " ( ) .
Selenium WebDriver , : , , API . WebDriver ( , IP ).
( ):
- , , Xvfb;
- VNC , , x11vnc;
- VNC Web Viewer , , noVNC -.
MongoDB, – . Elasticsearch, MongoDB. (H2, EhCache, Db4o).
Verwaltung
" ", , bash , ( ). . , .
, .
. – . , " ".
, .
,
( « »)