
Kennen Sie eine Situation, in der Sie viel Zeit damit verbringen, einen Film auszuwählen, der mit der Zeit vergleichbar ist, in der Sie ihn gesehen haben? Für Benutzer von Online-Kinos ist dies ein häufiges Problem, und für Kinos selbst - entgangene Gewinne.
Glücklicherweise haben wir Rekko - ein System persönlicher Empfehlungen, das Okko-Benutzern seit einem Jahr erfolgreich hilft, Filme und Serien aus mehr als zehntausend Inhaltseinheiten auszuwählen. In dem Artikel werde ich Ihnen erzählen, wie es unter algorithmischen und technischen Gesichtspunkten angeordnet ist, wie wir uns seiner Entwicklung nähern und wie wir die Ergebnisse bewerten. Nun, ich erzähle Ihnen auch von den Ergebnissen des jährlichen A / B-Tests.
Zunächst ein wenig Geschichte. Okko begann seine Existenz im Jahr 2011 als Teil von Iota, beginnend unter dem Namen Yota Play.
Bereits 2011 haben die Nutzer die Idee, einen Film legal im Internet zu sehen, mit Begeisterung angenommen Yota Play war für seine Zeit ein einzigartiger Dienst: Es war eng in soziale Netzwerke integriert und verwendete Informationen zu Filmen, die von Freunden in vielen Teilen des Dienstes angesehen und bewertet wurden, einschließlich Empfehlungen.

2012 wurde beschlossen, soziale Empfehlungen durch algorithmische zu ergänzen. So entstand „Oracle“ - das erste Empfehlungssystem des Online-Kinos Okko. Hier einige Auszüge aus seinem Designdokument:
Ein ähnlicher Ansatz wurde im implementierten System persönlicher Empfehlungen verwendet. Die Skala der Ebenen wird von „nichts“ (Leere, Abwesenheit) bis „alles“ (vollständig, maximal) verwendet. Im Bereich [127 .. + 127] 0 - ist die Mitte oder "Norm". Auf dieser Skala werden auch der Grad der Sympathie für die Hauptfigur und der subjektive Preis des Produkts sowie der Grad der „roten“ Farbe bewertet. Beispielsweise wird die Größe des Universums auf +127 (auf der Skala der Dimensionen) und die Dunkelheit auf 127 (auf der Skala der Lichtintensität) geschätzt.
Bei der Abgabe von Empfehlungen ist nicht nur der Hintergrund wichtig, sondern auch die Art des jeweiligen Benutzers. Das persönliche Profil enthält auch 4 Skalen von Charaktertypen (laut K. Leonhard - demonstrativ, pedantisch, festgefahren, erregbar).
Die physiologischen Grenzen des Gehirns hängen nicht von den Eigenschaften des Charakters einer Person und davon ab, wie freundlich und gesellig sie ist. Nach Angaben des Professors bestehen Einschränkungen im Neokortex, der Abteilung, die für bewusstes Denken und Sprechen zuständig ist. Diese Einschränkung wird auch im implementierten System berücksichtigt, insbesondere bei der Entwicklung von Empfehlungen für einen pedantischen Charaktertyp und bei der Bildung einer Stichprobe solcher Benutzer unter sozialen Verbindungen.

Wie Sie bereits verstanden haben, waren die Zeiten wild, die physiologischen Grenzen des Gehirns waren auf nichts beschränkt, und der übertaktete Neokortex selbst konnte mit Lichtgeschwindigkeit persönliche Empfehlungen abgeben. Daher wurde beschlossen, das Modell sofort in Produktion zu bringen.
Soweit man anhand der erhaltenen Artefakte der alten Zivilisation beurteilen kann, war "Oracle" eine wilde Mischung aus kollaborativen Filteralgorithmen, die großzügig mit Geschäftsregeln gewürzt waren.

Mitte 2013 begannen alle, ein wenig loszulassen, und es wurde schließlich beschlossen, die Qualität der Empfehlungsmaschine zu überprüfen. Zu diesem Zweck füllte ein speziell geschulter Editor die Hauptabschnitte der Anwendung aus und startete den A / B-Test: Die Hälfte der Benutzer sah die Ausgabe des Algorithmus, die andere Hälfte die Wahl des Editors.
Jetzt lesen wir Artikel über die nächsten Siege der künstlichen Intelligenz und stellen uns mit Entsetzen den Tag vor, an dem er unsere Arbeit verlieren wird. 2013 war die Situation anders: Eine Person besiegte das Auto heldenhaft und schuf noch mehr Arbeitsplätze in der Inhaltsabteilung. Das Orakel wurde ausgeschaltet und nie wieder eingeschaltet. Bald verschwanden alle sozialen Chips und Yota Play wurde zu Okko.
Der Zeitraum von 2013 bis 2016 war geprägt vom „Winter“ der künstlichen Intelligenz und der totalitären Herrschaft der Inhaltsabteilung: Es gab keine persönlichen Empfehlungen im Dienst.
Mitte 2017 wurde klar, dass man so nicht mehr leben kann. Die Erfolge von Netflix waren allen bekannt und die gesamte Branche bewegte sich rasant in Richtung Personalisierung. Die Benutzer waren nicht mehr an „dummen“ statischen Diensten interessiert, sondern gewöhnten sich bereits an „intelligente“ Schnittstellen, verstanden sie perfekt und sagten alle ihre Wünsche voraus.
Als erste Iteration haben wir uns entschlossen, zwei große russische Anbieter von Empfehlungen zu integrieren. Einmal am Tag nahmen beide Dienste die erforderlichen Daten von Okko, raschelten mit ihren Blackboxen auf entfernten Servern und luden die Ergebnisse hoch.
Nach den Ergebnissen des sechsmonatigen A / B-Tests wurden keine statistisch signifikanten Unterschiede in der Kontroll- und Testgruppe gefunden.
Kurz am Ende dieses A / B-Tests kam ich nach Okko, um den Service mit dem Leiter der Analytik, Mikhail Alekseev ( malekseev ), wirklich persönlich zu gestalten . Weniger als ein Jahr später schloss sich Danil Kazakov ( xaph ) uns an und bildete schließlich das aktuelle Team.
Allgemeine Überlegungen
Wenn ein Geschäftsproblem vor Ihnen auftritt, das seit langem von der internationalen Gemeinschaft untersucht wurde und das außerdem schnell gelöst werden muss, ist es verlockend, die erste beliebte Lösung für tiefe neuronale Netze zu verwenden, die Daten mit einer Schaufel hineinzuschieben, zu rammen und in das Produkt zu werfen.

Die Hauptsache ist, dieser Versuchung nicht zu erliegen. Die Aufgabe der wissenschaftlichen Gemeinschaft, maximale Geschwindigkeit für faule und synthetische Datensätze zu erreichen, fällt oft nicht mit der Geschäftsaufgabe zusammen, mehr Geld zu verdienen und gleichzeitig weniger Ressourcen auszugeben.

Nein, dies bedeutet nicht, dass Sie keine wiederkehrenden Netzwerke benötigen und Milliarden mit der Methode der k nächsten Nachbarn harken können. Es kann sich herausstellen, dass Sie mit der klassischen Matrixzerlegung zusätzliche bedingte 100 Millionen pro Jahr und wiederkehrende Netzwerke verdienen können - 105 Millionen pro Jahr. Gleichzeitig kostet die Wartung eines Server-Racks mit Grafikkarten für dieselben Netzwerke 10 Millionen pro Jahr und erfordert mehrere zusätzliche Monate für die Entwicklung und Implementierung. Die einfache Integration einer vorgefertigten Matrixzerlegung in einen anderen Abschnitt der Service- und Mailingliste erfordert einen Monat Verbesserungen und weitere 100 bedingte Millionen Im Jahr.
Daher ist es wichtig, mit den Grundlagen zu beginnen - bewährten Grundmethoden - und sich immer moderneren Ansätzen zuzuwenden. Achten Sie darauf, zu messen und vorherzusagen, welche Auswirkungen jede neue Methode auf das Unternehmen hat, wie viel sie kostet und wie viel Sie damit verdienen können.
Okko kann gut messen. Buchstäblich jede neue Funktion, jede Innovation, die wir durchlaufen haben, wird im Kontext einer Vielzahl von Benutzergruppen untersucht, die Auswirkungen werden auf statistische Signifikanz überprüft und erst danach wird entschieden, ob die neue Funktionalität akzeptiert oder abgelehnt wird.

Das aktuelle Rekko-Dashboard vergleicht beispielsweise die Kontroll- und Testgruppen für mehr als 50 Metriken, einschließlich Umsatz, Zeitaufwand für den Dienst, Zeit für die Auswahl eines Films, Anzahl der Aufrufe nach Abonnement, Umstellung auf Kauf und automatische Verlängerung und viele andere. Und ja, wir haben immer noch eine kleine Gruppe von Benutzern, die noch nie personalisierte Empfehlungen erhalten haben (sorry).

Über Empfehlungssysteme
Zunächst eine kleine Einführung in Empfehlungssysteme.
Das Ziel des Empfehlungssystems ist das für jeden Benutzer über seine Geschichte der Interaktion mit Elementen eine Ordnungsbeziehung auf der Menge aller Elemente aufzubauen. Dies bedeutet Folgendes: Unabhängig davon, welche zwei willkürlichen Elemente wir verwenden, können wir immer sagen, welches für den Benutzer vorzuziehen ist und welches weniger.
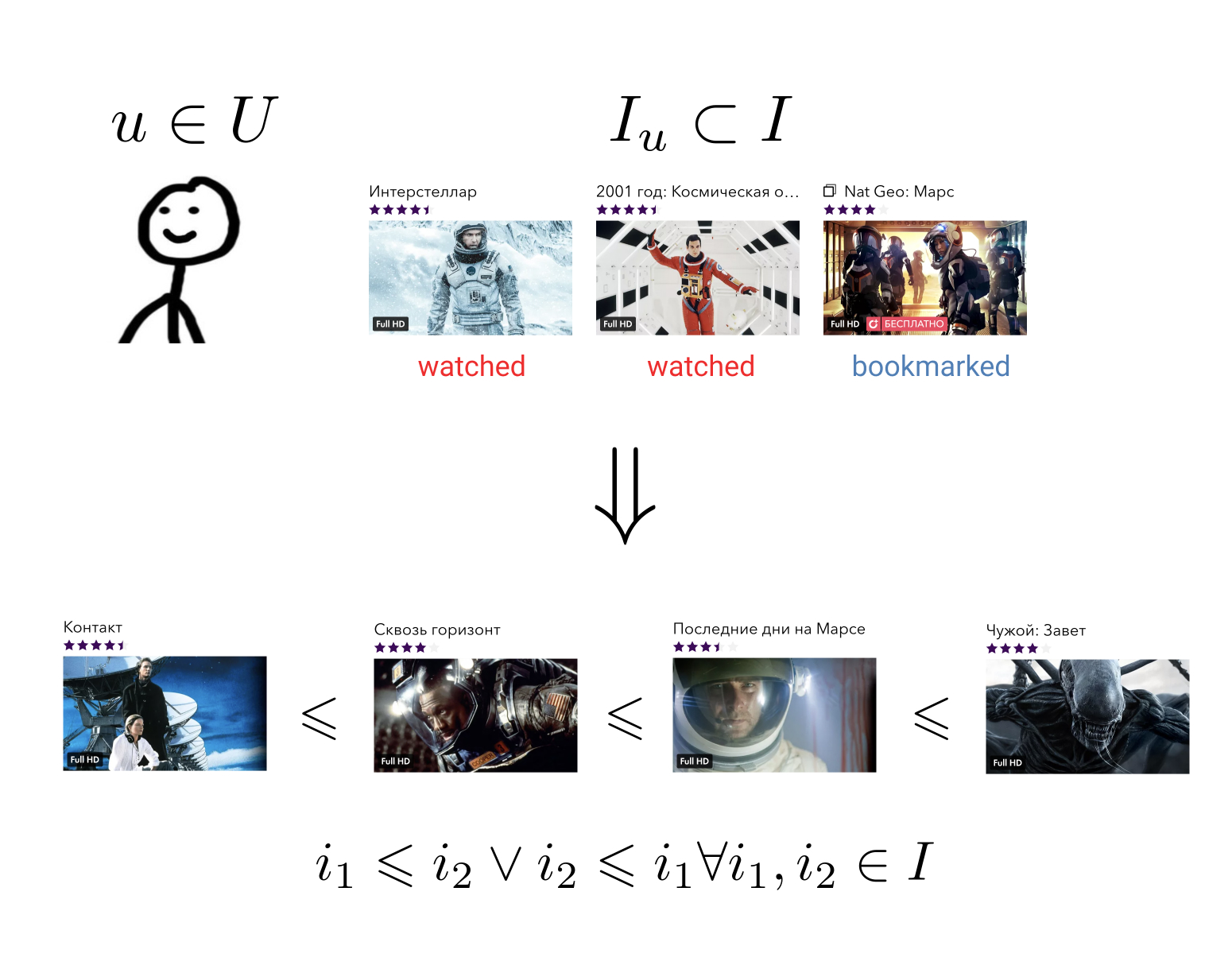
Diese eher allgemeine Aufgabe kann auf eine einfachere reduziert werden: Elemente einer Menge zuordnen, für die bereits eine Ordnungsbeziehung definiert ist. Zum Beispiel auf einer Reihe von reellen Zahlen. In diesem Fall muss jeder Benutzer und jedes Element einen bestimmten Wert vorhersagen können - wie sehr bevorzugt dieser Benutzer dieses Element.

Mit einer Auftragsbeziehung zu unseren Elementen können wir viele geschäftliche Probleme lösen. Wählen Sie beispielsweise aus allen Elementen N die für den Benutzer relevantesten aus oder sortieren Sie die Suchergebnisse nach seinen Vorlieben.
Idealerweise brauchen wir eine ganze Familie kontextsensitiver Ordnungsbeziehungen. Wenn der Benutzer die Sammlung "Action" betreten hat, wird er höchstwahrscheinlich den Film "Destroyer" dem Film "Oscar" vorziehen, aber in der Sammlung "Films with Sylvester Stallone" kann die Präferenz durchaus umgekehrt sein. Ähnliche Beispiele können für den Wochentag, die Tageszeit oder das Gerät angegeben werden, von dem aus der Benutzer den Dienst betreten hat.

Traditionell werden alle Methoden zur Erstellung persönlicher Empfehlungen in drei große Gruppen unterteilt: Collaborative Filtering (CF), Inhaltsmodelle (Inhaltsmodelle, CM) und Hybridmodelle, die die ersten beiden Ansätze kombinieren.
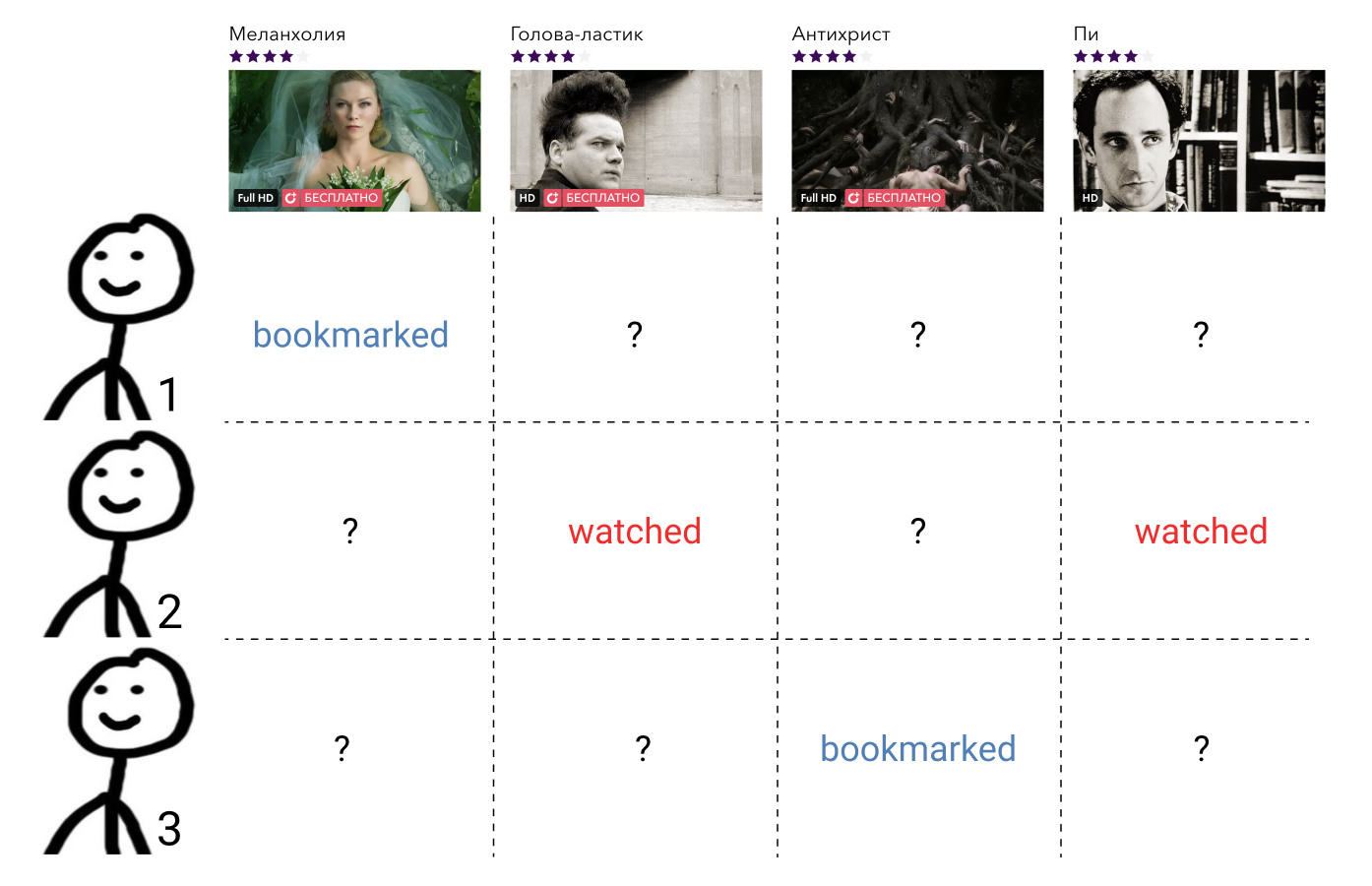
Kollaborative Filtermethoden verwenden Informationen über die Interaktionen aller Benutzer und aller Elemente. Solche Informationen werden in der Regel in Form einer spärlichen Matrix dargestellt, in der die Zeilen den Benutzern entsprechen, die Spalten den Elementen, und der Benutzer und das Element den Wert enthalten, der die Interaktion zwischen ihnen kennzeichnet, oder eine Lücke, wenn es keine solche Interaktion gab. Die Aufgabe, hier eine Ordnungsbeziehung aufzubauen, reduziert sich auf die Aufgabe, die fehlenden Matrixelemente auszufüllen.
Diese Methoden sind in der Regel schnell zu verstehen und zu implementieren, zeigen jedoch nicht das beste Ergebnis.
Inhaltsmodelle - beliebige Methoden des maschinellen Lernens zur Lösung von Klassifizierungs- oder Regressionsproblemen, die durch einen bestimmten Parametersatz parametrisiert werden . Am Eingang akzeptieren sie die Attribute des Benutzers und die Attribute des Elements, und die Ausgabe ist der Grad der Relevanz des angegebenen Elements für diesen Benutzer. Solche Modelle werden nicht über die Interaktionen aller Benutzer und aller Elemente, wie z. B. kollaborative Filtermethoden, unterrichtet, sondern nur über einzelne Präzedenzfälle.

Solche Modelle sind in der Regel viel genauer als kollaborative Filtermethoden, aber viel langsamer. Stellen Sie sich vor, wenn wir eine Funktion allgemeiner Form haben, die Zeichen von Benutzern und Elementen als Eingabe akzeptiert, muss sie für jedes Paar aufgerufen werden . Bei tausend Benutzern und zehntausend Elementen sind dies eine Million Anrufe.
Hybridmodelle kombinieren die Stärken beider Ansätze und bieten Qualitätsempfehlungen in angemessener Zeit.
Der derzeit beliebteste Hybridansatz ist eine zweistufige Architektur, bei der das kollaborative Filtermodell eine kleine Anzahl (100 - 1000) von Kandidaten aus allen möglichen Elementen auswählt, die dann nach einem viel leistungsfähigeren Inhaltsmodell eingestuft werden. Manchmal kann es mehrere solcher Stufen der Auswahl von Kandidaten geben, und auf jeder neuen Ebene wird ein zunehmend komplexeres Modell verwendet.

Eine solche Architektur hat viele Vorteile:
- Kollaborative und inhaltliche Teile sind nicht miteinander verbunden und können separat mit unterschiedlichen Frequenzen trainiert werden.
- Qualität ist immer besser als die eines kollaborativen Modells.
- Die Geschwindigkeit ist viel höher als die des Inhaltsmodells separat;
- "Frei" erhalten wir Vektoren aus einem kollaborativen Modell, die dann zur Lösung verwandter Probleme verwendet werden können.
Wenn wir über bestimmte Technologien sprechen, gibt es viele mögliche Kombinationen.
Als kollaborativer Teil können Sie Benutzerabonnements, beliebte Inhalte und beliebte Inhalte unter den Freunden des Benutzers aufnehmen, eine Matrix- oder Tensorfaktorisierung anwenden, DSSM oder eine andere Methode mit relativ schneller Vorhersage trainieren.
Als Inhaltsmodell kann im Allgemeinen jeder Ansatz verwendet werden, von der linearen Regression bis zu tiefen Gittern.
Bei Okko konzentrieren wir uns derzeit auf eine Kombination aus Matrixfaktorisierung mit WARP-Verlust und Gradientenverstärkung über Bäumen, auf die ich jetzt ausführlich eingehen werde.
Stufe eins: Auswahl der Kandidaten
Ich glaube, ich lüge nicht, wenn ich sage, dass Matrixfaktorisierungsalgorithmen bei weitem die beliebtesten Methoden der kollaborativen Filterung sind. Das Wesentliche der Methode ergibt sich aus dem Namen: Wir versuchen, die bereits erwähnte Matrix von Benutzerinteraktionen mit Inhalten durch das Produkt zweier Matrizen mit niedrigerem Rang darzustellen, von denen eine eine „Benutzermatrix“ und die andere eine „Matrix von Elementen“ sein wird. Mit dieser Zerlegung können wir die ursprüngliche Matrix zusammen mit allen fehlenden Werten wiederherstellen.

In diesem Fall können wir natürlich ein Kriterium für die Ähnlichkeit der verfügbaren und wiederhergestellten Matrizen wählen. Das einfachste Kriterium ist die Standardabweichung.
Lass - Benutzermatrixzeile, die dem Benutzer entspricht und - Spalte der Elementmatrix, die dem Element entspricht . Dann, wenn Matrizen multipliziert werden, ihr Produkt bedeutet die Größe der beabsichtigten Interaktion zwischen dem angegebenen Benutzer und dem Element. Berechnen Sie nun die Standardabweichung zwischen dieser Größe und dem a priori bekannten Wert der Wechselwirkung für alle Paare interagierender Benutzer und Elemente erhalten wir eine Verlustfunktion, die minimiert werden kann.
In der Regel wird noch eine Regularisierung hinzugefügt.
Ein solches Problem ist nicht konvex und NP-komplex. Es ist jedoch leicht zu bemerken, dass beim Fixieren einer der Matrizen die Aufgabe in eine lineare Regression relativ zur zweiten Matrix umgewandelt wird, was bedeutet, dass wir iterativ nach einer Lösung suchen können, indem wir entweder die Benutzermatrix oder die Matrix der Elemente abwechselnd einfrieren. Dieser Ansatz wird als Alternating Least Squares (ALS) bezeichnet.

Das Hauptplus von ALS ist die Geschwindigkeit und die Fähigkeit zur einfachen Parallelisierung. Dafür ist er in Yandex.Zen und Vkontakte so beliebt, wo sowohl Benutzer als auch Elemente im zweistelligen Millionenbereich liegen.
Wenn es sich jedoch um die Datenmenge handelt, die auf einen Computer passt, hält ALS Kritik nicht stand. Sein Hauptproblem ist, dass er die falsche Verlustfunktion optimiert. Denken Sie an die Formulierung der Aufgabe, ein Empfehlungssystem aufzubauen. Wir wollen die Ordnungsrelation auf der Menge erhalten und stattdessen die Standardabweichung optimieren.
Es ist leicht, ein Beispiel für eine Matrix zu nennen, für die die Standardabweichung minimal ist, aber die Reihenfolge der Elemente wird hoffnungslos zerstört.
Mal sehen, was wir dagegen tun können. Im Kopf des Benutzers sind alle Elemente, mit denen er interagiert hat, in einer bestimmten Reihenfolge angeordnet. Zum Beispiel weiß er sicher, dass Interstellar besser ist als Gravity, Gravity und Alien sind gleich gute Filme und sie sind alle etwas schlechter als Terminator. Gleichzeitig erlebt er eine gewisse Einstellung zu Filmen, die der Benutzer noch nicht gesehen hat, und das gilt für alle. Er könnte glauben, dass solche Filme a priori schlechter sind als die Filme, die er gesehen hat. Oder er könnte zum Beispiel annehmen, dass Prometheus ein schlechter Film ist und jeder Film, den er noch nicht gesehen hat, besser ist als er.
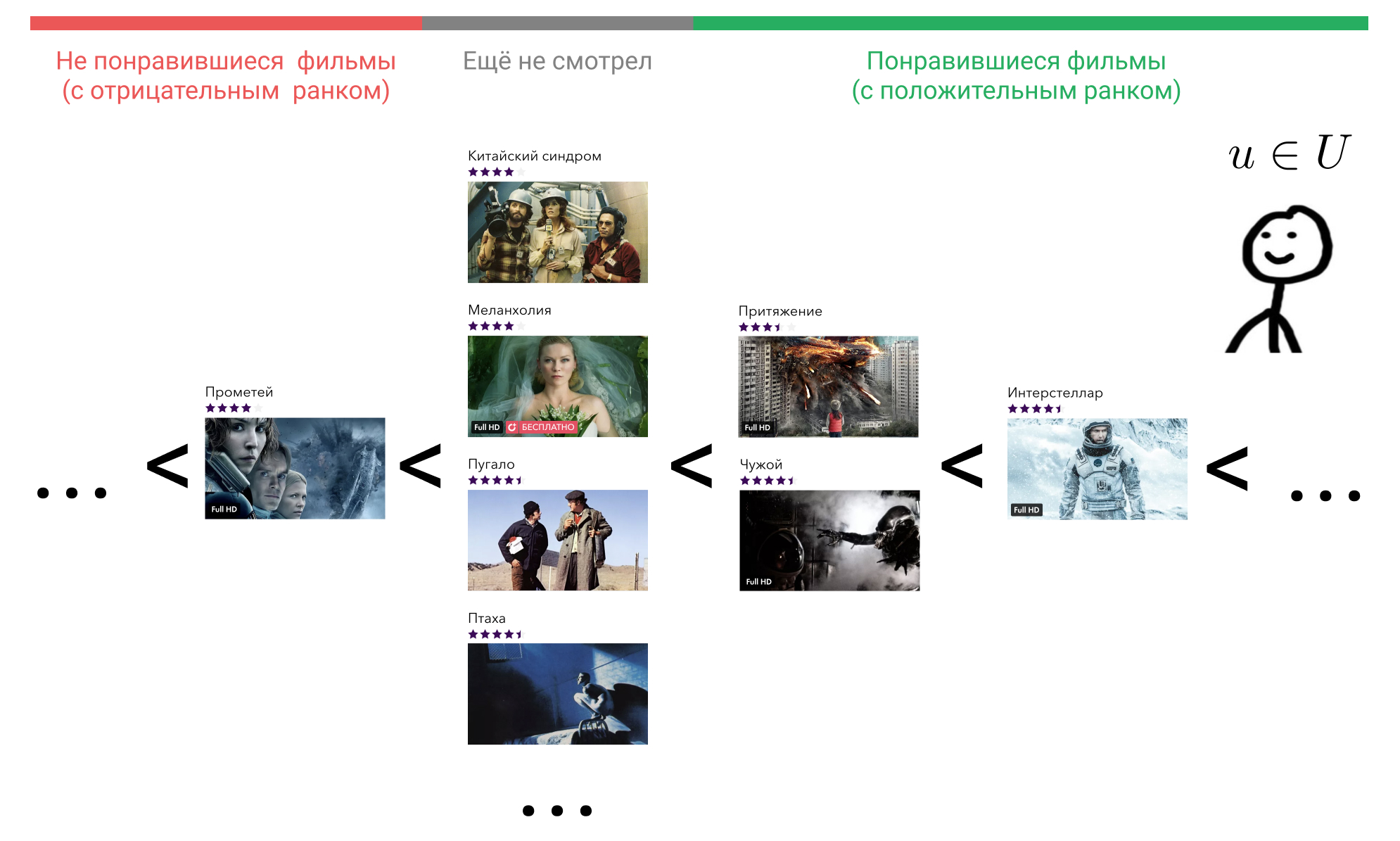
Stellen Sie sich vor, dass wir diese Reihenfolge gemäß einigen Anzeichen von Benutzerverhalten im Dienst wiederherstellen können, indem wir das Element, mit dem es interagiert hat, mithilfe der Funktion in einer Ganzzahl anzeigen . Viele der Filme, mit denen der Benutzer interagiert, bezeichnen als . Wir sind uns einig wenn der Benutzer nicht mit dem Film interagiert hat , also . Wenn der Benutzer den Film als schlecht ansieht, dann und wenn gut, dann .

Jetzt können wir den Rang eingeben .
hier bezeichnet die Indikatorfunktion und ist gleich Eins, wenn wahr und sonst Null.
Lassen Sie uns eine Minute innehalten und überlegen, was ein solcher Rang bedeutet.
Wir reparieren den Benutzer Dies ist ein bestimmter Benutzer, an dem wir nicht interessiert sind. Dementsprechend ist sein Vektor wird behoben.
Nehmen Sie jetzt jeden Film, den er gesehen hat, zum Beispiel Interstellar. In der Formel ist dies . Als nächstes finden wir einen Film, den der Benutzer für schlechter hält als Interstellar. Wir können zwischen "Attraction", "Alien", "Prometheus" oder jedem Film wählen, den er noch nicht gesehen hat.

Nimm die "Attraktion". In der Formel ist dies . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
wo — .
, , , .
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
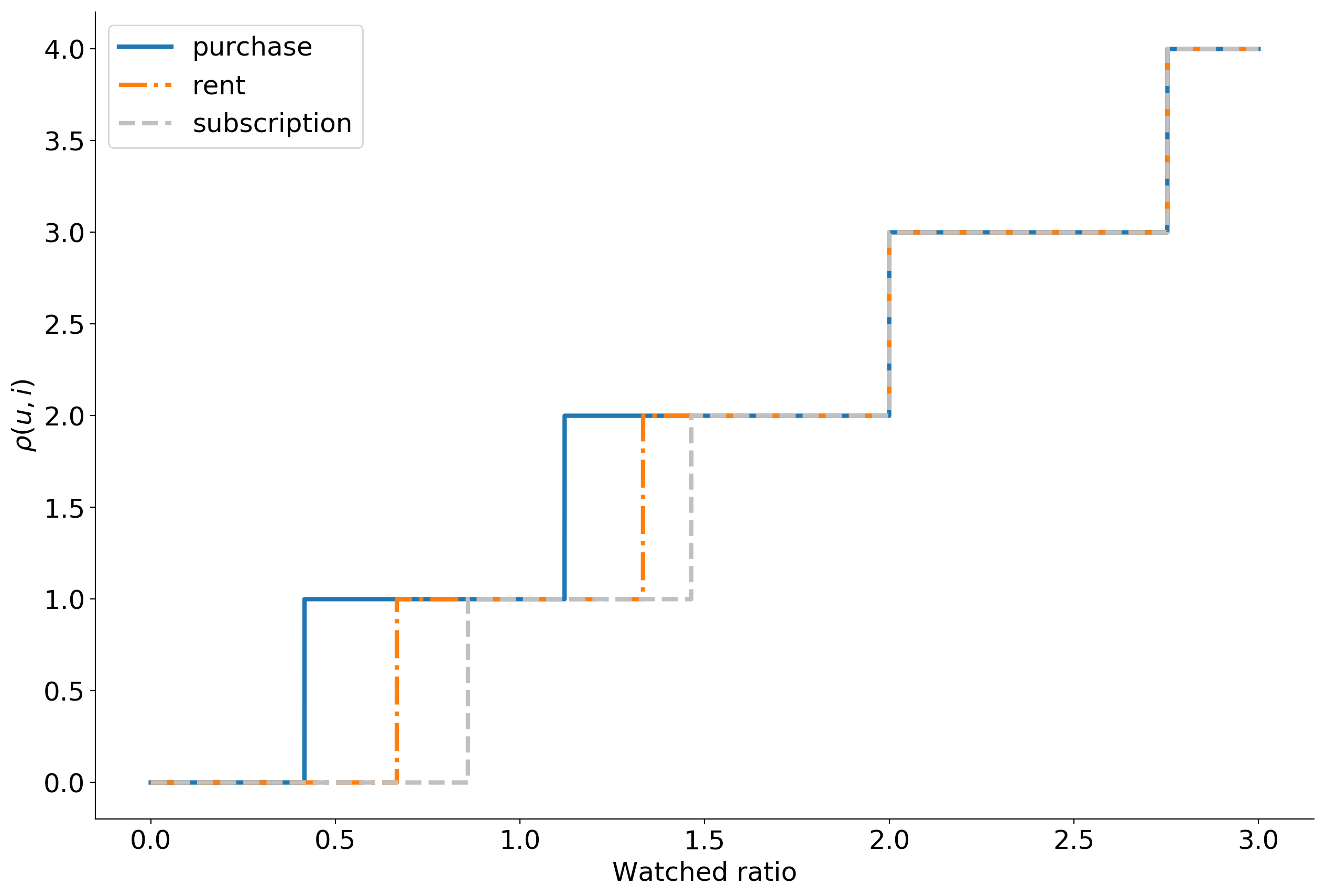
Dabei , , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
Diese Probleme werden durch Inhaltsmodelle vermieden. Sie sind kraftvoll, ausdrucksstark und Sie können alle Zeichen in sie stecken, aber sie sind extrem langsam. Die Lösung besteht darin, das Inhaltsmodell nicht für alle Elemente auszuführen, sondern für Kandidaten, die aus der Matrixzerlegung erhalten wurden. Es können so viele Kandidaten vorhanden sein, wie Sie bearbeiten können, vorzugsweise jedoch mindestens doppelt so viele, wie Sie den Benutzern anzeigen. In unserem Fall bestand die beste Lösung für die 100 empfohlenen Filme darin, 400 Kandidaten zu verwenden.

Die Attribute, die wir an das Inhaltsmodell senden, können in drei Gruppen unterteilt werden: Benutzerattribute, Elementattribute und Interaktionszeichen. Insgesamt werden ca. 50 Zeichen erhalten.
Als Zeichen für Benutzer verwenden wir aggregierte Statistiken über ihr Verhalten im Dienst, zum Beispiel:
- Prozentsatz der Abonnementansicht
- Verteilung von Geräten, von denen sich der Benutzer bei der Anwendung anmeldet,
- Lebenszeit im Dienst,
- usw.
Für Filme verwenden wir fast alle verfügbaren Metainformationen: Genre, Erscheinungsjahr, Land, Schauspieler, Regisseur, Altersgrenze usw. Aggregierte Geschäftsmetriken helfen ebenfalls: Prozentsatz der Besuche auf der Karte, Anzahl der Aufrufe, Ergänzungen zu Favoriten, Verteilung nach Anzeigemethoden, Geräten usw.
Anzeichen für eine Interaktion sind die Geschwindigkeit ab der Auswahl der Kandidaten und aggregierte Statistiken für alle vorherigen Benutzer- und Filminteraktionen unter Beteiligung derselben Schauspieler, Regisseure und Drehbuchautoren wie der betreffende Film.
Die häufigste Frage, die sich bei der Einstufung von Kandidaten mit einem Modell der zweiten Ebene stellt, ist, wie dieses Modell trainiert werden soll. Allein bei der Matrixfaktorisierung benötigten wir zwei Sätze, die durch Zeit getrennt waren - Training und Test. Bei einem zweistufigen System benötigen wir drei davon - zwei Schulungen und einen Test.
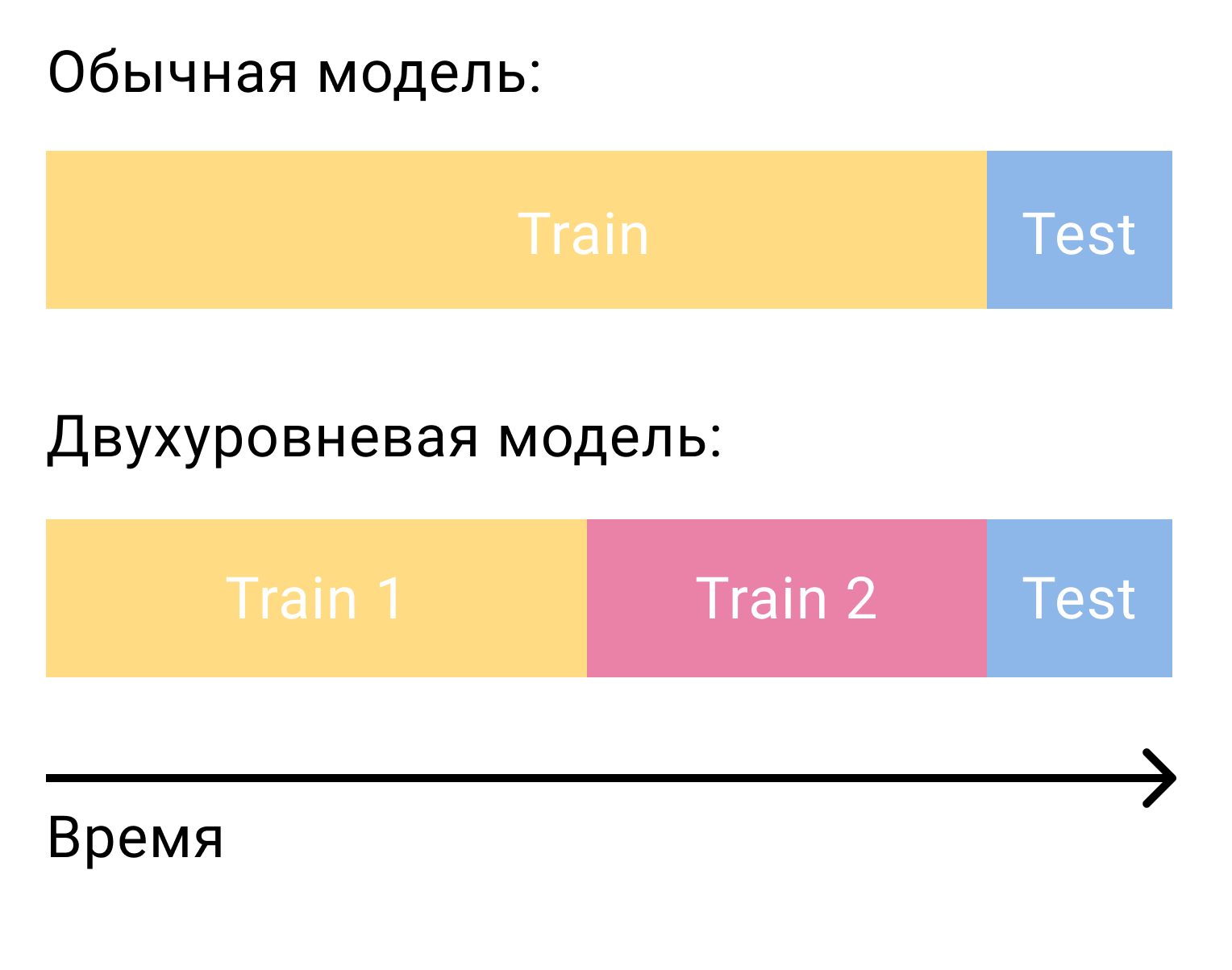
Beim ersten Trainingsset werden wir das Modell der ersten Stufe trainieren und Kandidaten erstellen. Von den Kandidaten ist es wichtig, diejenigen Elemente auszuschließen, mit denen der Benutzer in diesem Satz interagiert hat. Dann werden wir sehen, mit welchem der Kandidaten der Benutzer im zweiten Trainingssatz interagiert hat. Wir nennen sie positiv und die übrigen Kandidaten negativ. Dies wird unser Trainingsset für das Inhaltsmodell sein.
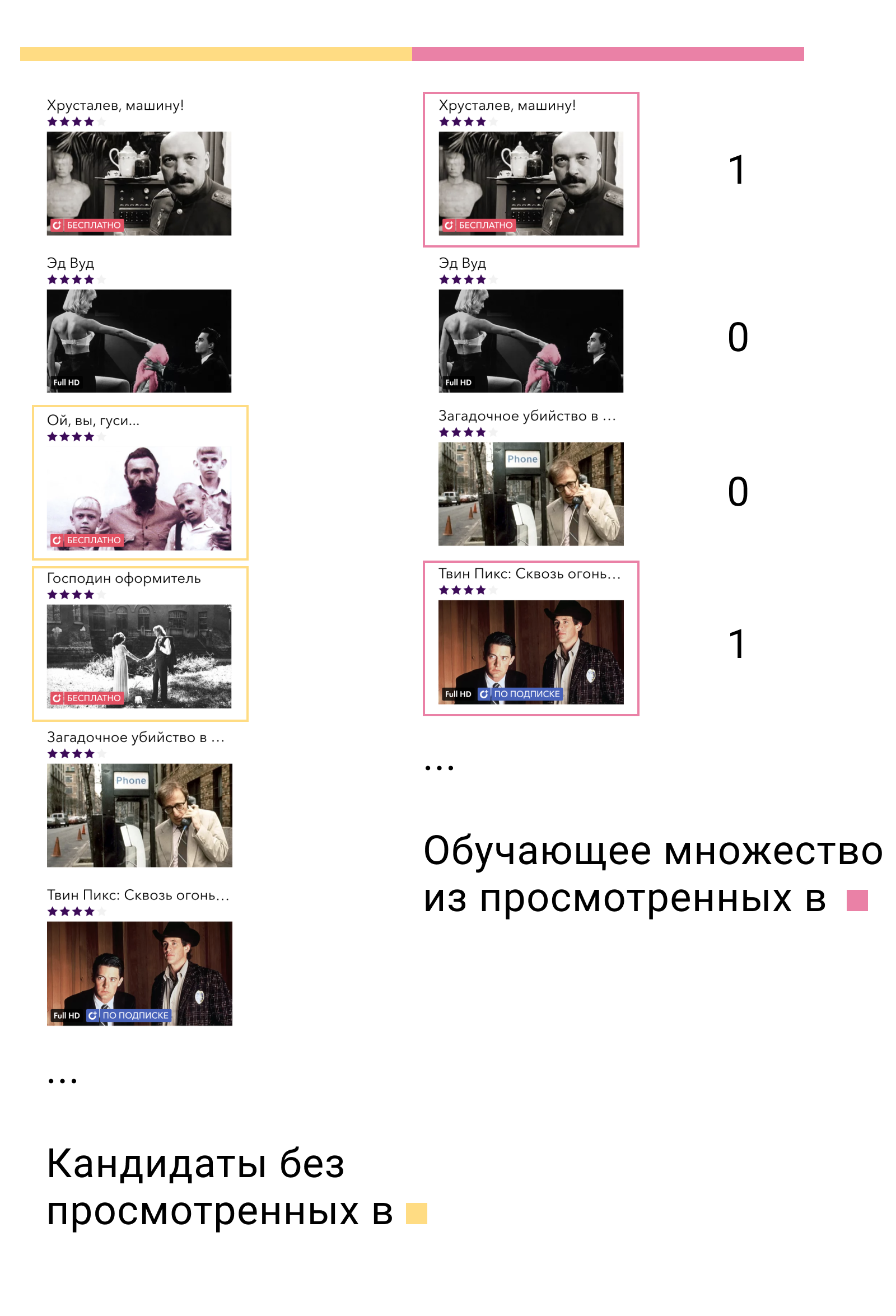
Warum funktioniert es? Zunächst trainieren wir das Modell genau anhand der Daten, für die es verwendet wird - der Ausgabe des Modells der ersten Ebene. Zweitens nehmen wir unter allen möglichen negativen Beispielen die komplexesten - diejenigen, die das Modell der ersten Ebene für den Benutzer relevant nennt, aber nicht.
Was weiter? Die einfachste und naheliegendste Lösung besteht darin, das Problem der binären Klassifizierung zu lösen und die Elemente dann in absteigender Reihenfolge der Wahrscheinlichkeit zu sortieren, um ein positives Beispiel zu erhalten. Aber wir können uns wieder an die Aussage über das Problem des Aufbaus eines Empfehlungssystems erinnern, verstehen, dass die binäre Klassifizierung nicht das Problem ist, das wir lösen, und wieder zum Ranking-Problem übergehen.
In XGBoost und LightGBM ist LambdaMART die primäre Verlustfunktion für Ranking-Aufgaben. Wenn Sie nicht auf Details eingehen, ist die Intuition dahinter recht einfach. Wenn - Modellausgabe zum Beispiel , dann die Wahrscheinlichkeit, dass das Element wird einen höheren Rang als das Element haben wird gleich sein
Die Verlustfunktion kann dann wie folgt geschrieben werden.
Hier ist die wahre Wahrscheinlichkeit des Rankings. Wir werden es als 1 definieren, wenn , 0 wenn und 0,5 in dem Fall .
Ein zweistufiges Modell erhöht die Metrik um 50% im Vergleich zu einem einstufigen Modell. Die Ranking-Loss-Funktion fügt weitere 10% hinzu.
Bonus: verwandte Filme
Denken Sie daran, dass ich in den Vorteilen unseres Ansatzes die „freien“ Vektoren aus der Matrixfaktorisierung erwähnt habe, die zur Lösung verwandter Probleme verwendet werden können. Eine dieser Aufgaben - die Suche nach ähnlichen Filmen - haben wir uns entschieden.
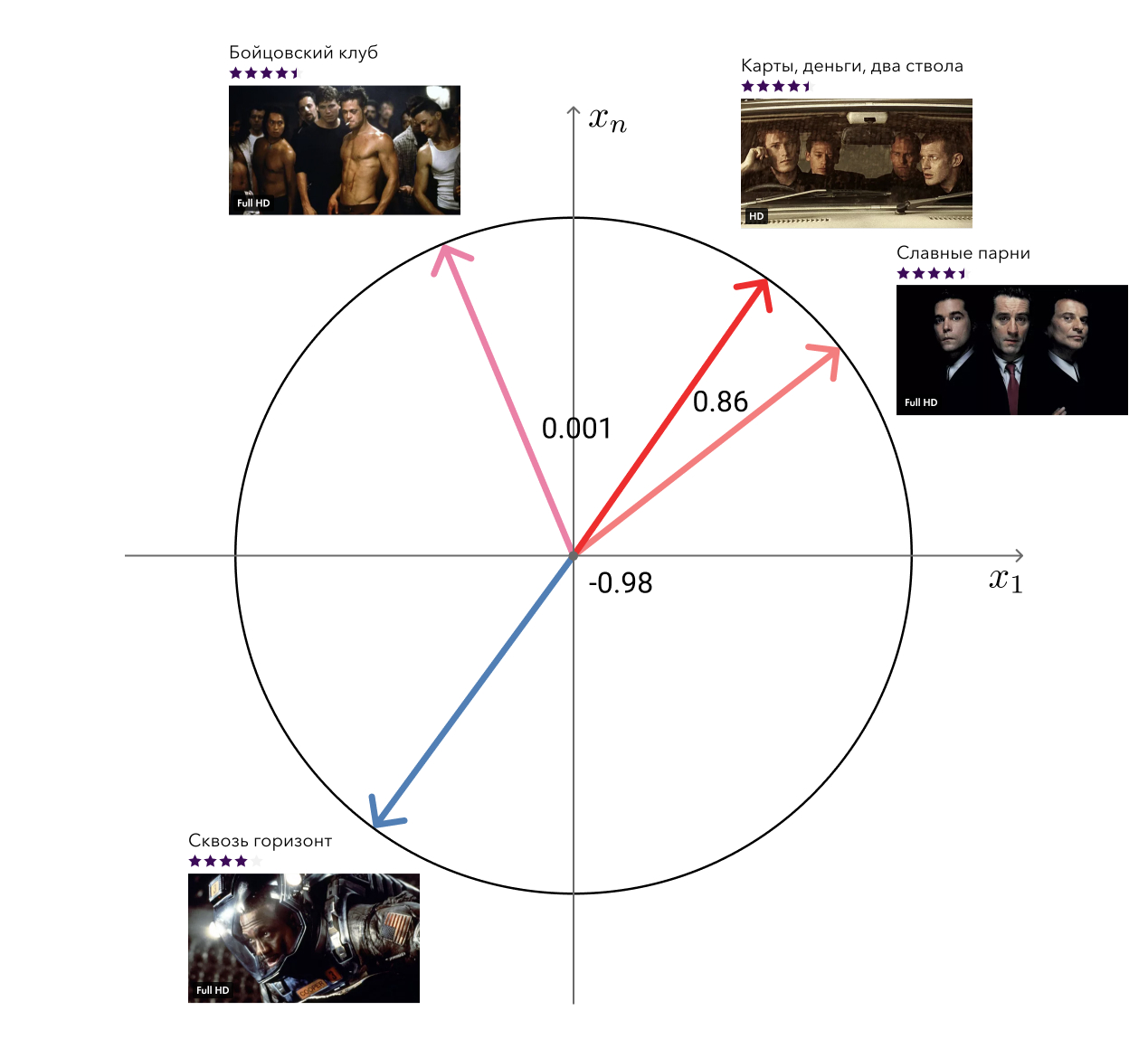
Die Lösung für die Schande ist einfach: Für jeden Film nehmen wir seinen Vektor und suchen diejenigen, die im Kosinusabstand am nächsten sind. Für das Auge sieht es völlig ausreichend aus. Die nächste Ebene besteht darin, Metainformationen hinzuzufügen und Diagrammalgorithmen zu verwenden.

Technische Umsetzung
Neben dem algorithmischen Teil möchte ich ein wenig über die Implementierung sprechen. Rekko besteht aus drei Komponenten: Lynch, Rekko-Tasks und Rekko-Service.
Lynch läuft auf einem leistungsstarken Computer, wacht regelmäßig auf, bereitet Daten für den Microservice vor und legt sie in S3 ab.
Die Rekko-Tasks für Microservices und der Rekko-Service befinden sich zusammen mit allen anderen Microservices und Datenbanken in der Okko-Produktumgebung. Der erste von ihnen überwacht S3 ständig auf Änderungen, lädt sie herunter und legt sie in Lebensmittelgeschäften ab. Der zweite Mikroservice verwendet diese berechneten Ergebnisse, um in Echtzeit auf Benutzeranfragen zu reagieren und deren Empfehlungen zu berechnen.

Microservices werden in Python mit Falcon, Gunicorn und Gevent geschrieben und stellen außer der Geschäftslogik nichts Interessantes dar. Wie alle anderen Microservices der Okko-Produktumgebung werden sie vom Balancer geschlossen.
Lynch ist viel interessanter.
Was muss getan werden, um den nächsten Teil der Empfehlungen für Benutzer zu berechnen? Zumindest:
- Laden Sie neue Daten herunter, die seit der letzten Nachzählung erschienen sind.
- Verarbeiten Sie sie;
- Zugmatrixfaktorisierung;
- Kandidaten bauen
- Kandidaten neu ordnen;
- Geschäftsregeln anwenden
- Entladen.
Es scheint nicht beängstigend zu klingen. Sie können jedes Teil in eine separate Funktion einfügen und sie einfach nacheinander aufrufen:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
Nun, alles hat einen tollen Job gemacht, sind wir uns nicht einig? Nicht wirklich. Aber was ist, wenn das ganze Blatt irgendwo hinfällt? Zum Beispiel wegen Speichermangels. Wir müssen alles neu starten, auch wenn wir bereits ein paar Stunden damit verbracht haben, das Modell zu trainieren und Kandidaten zu bauen.
Nun, dann speichern wir alle Zwischenergebnisse in Dateien und überprüfen nach dem Fall, welche bereits vorhanden sind, stellen den Status wieder her und starten die Berechnungen ab dem richtigen Zeitpunkt. In der Tat ist diese Idee noch schlimmer als die vorherige. Ein Programm wird möglicherweise während des Schreibens in eine Datei unterbrochen, und obwohl es vorhanden ist, befindet es sich in einem falschen Zustand. Im besten Fall fällt die gesamte Berechnung, im schlimmsten Fall endet sie mit dem falschen Ergebnis.
Ok, lass uns in die Atomdatei schreiben. Und wir nehmen jede Funktion in einer separaten Entität heraus und geben die Abhängigkeiten zwischen ihnen an. Das Ergebnis ist eine Kette von Berechnungen, von denen jedes Element entweder ausgeführt werden kann oder nicht.

Schon nicht schlecht. In der Realität werden jedoch alle notwendigen Berechnungen kaum durch eine Liste beschrieben. Das Erlernen der Matrixfaktorisierung erfordert nicht nur Transaktionsdaten, sondern auch Benutzerbewertungen. Für die Erstellung von Kandidaten ist eine Liste der gespeicherten Filme erforderlich, um sie auszuschließen. Für die Berechnung ähnlicher Filme sind eine geschulte Matrixfaktorisierung und Metainformationen aus dem Katalog erforderlich. Unsere Aufgaben sind nicht mehr in einer einfach verbundenen Liste aufgebaut, sondern in einem gerichteten Graphen ohne Zyklen (Directed Acyclic Graph, DAG).

Die DAG ist eine äußerst beliebte Computerorganisation. Es gibt zwei Hauptrahmen für den Aufbau einer DAG: Airflow und Luigi . Wir bei Okko haben uns für Letzteres entschieden. Luigi wurde bei Spotify entwickelt, entwickelt sich aktiv, ist vollständig in Python geschrieben, leicht erweiterbar und ermöglicht es Ihnen, Berechnungen sehr flexibel zu organisieren.
Eine Aufgabe in Luigi wird durch eine Klasse definiert, die von luigi.Task erbt und drei erforderliche Methoden implementiert: luigi.Task , output und run . So sieht eine typische Aufgabe aus:
Luigi wird sicherstellen, dass die Aufgaben in der richtigen Reihenfolge ausgeführt werden, ohne den Verbrauch der verfügbaren Ressourcen zu überschreiten. Wenn Aufgaben parallel ausgeführt werden können, werden sie parallel ausgeführt, wodurch die CPU-Auslastung maximiert und die Gesamtausführungszeit minimiert wird. Wenn eine Aufgabe fehlschlägt, startet er sie mehrmals neu und informiert uns im Fehlerfall. In diesem Fall werden alle Aufgaben ausgeführt, die ausgeführt werden können. Dies bedeutet zum Beispiel, dass ein Fehler bei der Rangfolge der Kandidaten das Zählen und Hochladen einer Liste ähnlicher Filme nicht behindert.
Derzeit besteht Lynch aus 47 einzigartigen Aufgaben, von denen etwa 100 Exemplare produziert werden. Einige von ihnen sind mit direkter Arbeit beschäftigt, andere zählen Metriken und senden sie an unser Splunk BI-Tool. Lynch sendet uns auch regelmäßig grundlegende Statistiken und Berichte über seine Arbeit per Telegramm. Er schreibt auch über Fehler, aber in PM.
Überwachung, Aufteilung und Ergebnisse

Die erste Regel von Data Science: Erzählen Sie niemandem von Gehältern in Data Science. Die zweite Regel von Data Science: Was nicht gemessen werden kann, kann nicht verbessert werden.
Wir versuchen alles im Auge zu behalten. Zuallererst ist dies natürlich eine Rangfolge von Metriken für historische Daten. Sie helfen bereits in der Forschungsphase, das beste Modell aus mehreren auszuwählen und Hyperparameter dafür auszuwählen.
Bei Modellen, die in der Produktion arbeiten, berücksichtigen wir auch Metriken, jedoch bereits im Alltag. Solche Metriken sind ziemlich volatil, aber es kann von ihnen gesagt werden, wenn sich das Modell aus irgendeinem Grund plötzlich verschlechtert. Wenn ein neues Modell im Produkt gestartet wird, können Sie es eine Woche lang im Leerlauf lassen und sicherstellen, dass die Metriken nicht durchhängen. Danach können Sie es für einige Benutzer aktivieren, den A / B-Test ausführen und bereits Geschäftsmetriken überwachen.

Darüber hinaus berücksichtigen wir die Verteilung der Empfehlungen nach Genre, Land, Jahr, Typ usw. Dies ermöglicht es uns, die aktuelle Art der Benutzerpräferenzen zu verstehen, sie mit tatsächlichen Anzeigedaten zu vergleichen und Fehler in Geschäftsregeln zu erkennen.

Es ist auch wichtig, die Verteilung aller verwendeten Merkmale zu verfolgen. Eine starke Änderung kann durch einen Fehler in der Datenquelle verursacht werden und zu unvorhersehbaren Ergebnissen führen.
Aber das Wichtigste, was besondere Aufmerksamkeit erfordert, sind natürlich die Geschäftsmetriken. Als Teil des Empfehlungssystems sind die wichtigsten Geschäftsmetriken für uns:
- Einnahmen aus Transaktions- und Abonnementverbrauchsmodellen (TVOD / SVOD-Einnahmen);
- Durchschnittlicher Umsatz pro Besucher (durchschnittlicher Umsatz pro Besucher, ARPV);
- Der durchschnittliche Scheck (Durchschnittspreis pro Kauf, APPP);
- Durchschnittliche Einkäufe pro Benutzer (APPU);
- Umwandlung in Kauf (CR in Kauf);
- Konvertierung zur Ansicht per Abonnement (CR zum Ansehen);
- Umwandlung während des Versuchszeitraums (CR zu Versuch).
Gleichzeitig betrachten wir die Metriken aus den Abschnitten „Empfehlungen“ und „Ähnliche“ sowie die Metriken des gesamten Dienstes als Ganzes, um den Umverteilungseffekt zu berücksichtigen und die Situation aus verschiedenen Blickwinkeln zu betrachten.
Dies kann wie ein Dashboard aussehen, in dem mehrere Modelle verglichen werden:

Wie eingangs erwähnt, vergleichen wir nicht nur Modelle miteinander, sondern auch eine Gruppe von Benutzern mit Empfehlungen mit einer Gruppe von Benutzern ohne Empfehlungen. Auf diese Weise können wir den Nettoeffekt der Implementierung von Rekko bewerten und verstehen, wo wir uns gerade befinden und welcher Verbesserungsspielraum noch besteht. Nach diesem A / B-Test haben wir derzeit:
- ARPV + 3,5%
- ARPV mit Marge + 5%
- APPU + 4,3%
- CR zum Versuch + 2,6%
- CR zu sehen + 2,5%
- APPP -1%
Filme in einem Online-Kino können in zwei Gruppen unterteilt werden: neue Elemente und alte Inhalte. Wir wissen bereits, wie man gute Nachrichten verkauft. Der Hauptzweck persönlicher Empfehlungen besteht darin, alte, für Benutzer relevante Inhalte aus dem Katalog abzurufen. Dies führt zu einer Erhöhung der Anzahl der Käufe und zum Absinken des durchschnittlichen Schecks, da solche Inhalte natürlich billiger sind. Solche Inhalte haben aber auch eine hohe Marge, die das Absinken des Schecks kompensiert und zu einer Steigerung der Einnahmen führt.
Relevantere Abonnementinhalte haben zu einer erhöhten Conversion während des Testzeitraums und zur Anzeige nach Abonnement geführt.
Rekko Herausforderung
Vom 18. Februar bis 18. April 2019 veranstalteten wir zusammen mit der Boosters-Plattform die Rekko Challenge, bei der wir die Teilnehmer einluden, ein Empfehlungssystem auf der Grundlage anonymisierter Produktdaten aufzubauen.

Es wird erwartet, dass die Teilnehmer, die ein zweistufiges System ähnlich unserem aufgebaut haben, an der Spitze standen. Gewinner, die den ersten und dritten Platz belegten, konnten das Ensemble RNN erweitern. Und der Teilnehmer vom achten Platz schaffte es, nur mit kollaborativen Filtermodellen darauf zu klettern.
Evgeni Smirnov, der den zweiten Platz im Wettbewerb belegte, schrieb einen Artikel, in dem er über seine Entscheidung sprach.
Derzeit ist der Wettbewerb in Form einer Sandbox verfügbar , sodass jeder, der sich für Empfehlungssysteme interessiert, sich daran versuchen und nützliche Erfahrungen sammeln kann.
Fazit
Mit diesem Artikel wollte ich Ihnen zeigen, dass Empfehlungssysteme in der Produktion überhaupt nicht schwierig, aber unterhaltsam und rentabel sind. Die Hauptsache ist, über Ziele nachzudenken, nicht über die Mittel, um sie zu erreichen und ständig alles zu messen.
In zukünftigen Artikeln werden wir Ihnen noch mehr über die Okko-Innenküche erzählen. Vergessen Sie also nicht, sie zu abonnieren und zu mögen.