Einführung
Bei der Durchführung einer CWT-Analyse mit der PyWavelets-Bibliothek (einer kostenlosen Open Source-Software, die unter der MIT-Lizenz veröffentlicht wurde) treten Probleme bei der Visualisierung des Ergebnisses auf. Das von den Entwicklern vorgeschlagene Visualisierungstestprogramm ist in der folgenden Liste aufgeführt:
Auflistungimport pywt import numpy as np import matplotlib.pyplot as plt t = np.linspace(-1, 1, 200, endpoint=False) sig = np.cos(2 * np.pi * 7 * t) + np.real(np.exp(-7*(t-0.4)**2)*np.exp(1j*2*np.pi*2*(t-0.4))) widths = np.arange(1, 31) cwtmatr, freqs = pywt.cwt(sig, widths, 'cmor1-1.5') plt.imshow(cwtmatr, extent=[-1, 1, 1, 31], cmap='PRGn', aspect='auto', vmax=abs(cwtmatr).max(), vmin=-abs(cwtmatr).max())
Bei der Arbeit mit komplexen Wavelets, beispielsweise mit 'cmor1-1.5', erzeugt das Programm einen Fehler:
File"C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\matplotlib\image.py", line 642, in set_data raise TypeError("Image data cannot be converted to float") TypeError: Image data cannot be converted to float
Dieser Fehler sowie Schwierigkeiten bei der Auswahl der Skala (Breiten) zur Bereitstellung der erforderlichen Zeitauflösung machen es insbesondere für Anfänger schwierig, die CWT-Analyse zu studieren, was mich dazu veranlasste, diesen Artikel pädagogischer Natur zu schreiben.
Der Zweck dieser Veröffentlichung ist es, die Verwendung des neuen
Skalierungsvisualisierungsmoduls für die Analyse einfacher und spezieller Signale sowie bei Verwendung von Normalisierungsmethoden, logarithmischer Skalierung und Synthese zu berücksichtigen, die zusätzliche Informationen bei der Analyse von Zeitreihen liefern.
Der Artikel verwendete Informationen aus der Veröffentlichung
„Eine sanfte Einführung in Wavelet für die Datenanalyse“ . In den Auflistungen der in der Veröffentlichung angegebenen Beispiele werden die Fehler behoben, und jede Auflistung des Beispiels wird in seine fertige Form gebracht, sodass es verwendet werden kann, ohne mit den vorherigen vertraut zu sein. Für die Wavelet-Analyse spezieller Signale wurden Daten aus der PyWavelets-Probendatenbank verwendet.
Ein Wavelet-Skalogramm ist eine zweidimensionale Darstellung eindimensionaler Daten. Die Zeit ist auf der X-Achse aufgetragen, und auf der Y-Achse ist eine Skala dargestellt - das Ergebnis der Wavelet-Transformation des Signals entsprechend der Signalamplitude zum Zeitpunkt X. Der analytische Wert einer solchen grafischen Anzeige des Signals besteht darin, dass die Zeitauflösung auf der Y-Achse angezeigt wird, die zusätzliche Informationen liefert über die dynamischen Eigenschaften des Signals.
Wavelet - Einfache Signalskalogramme
1. Kosinuswelle mit einer Gaußschen Hüllkurve (Ersetzen von Wavelets. Sie können die Abhängigkeit der Zeitauflösung von der Skala untersuchen):
Auflistung from numpy import* from pylab import* import scaleogram as scg import pywt
Wavelet-Funktion zur Signalumwandlung: cmor1-1.5 (Complex Morlet Wavelets)


Das periodische Signal erscheint nun in Form eines horizontalen kontinuierlichen Streifens am Punkt Y = p1, dessen Intensität in Abhängigkeit von der Amplitude des periodischen Signals variiert.
Die Erkennung weist eine gewisse Unschärfe auf, da die Bandbreite nicht gleich Null ist. Dies liegt an der Tatsache, dass die Wavelets nicht eine Frequenz, sondern ein Band erfassen. Dieser Effekt ist mit der Wavelet-Bandbreite verbunden.
2. Drei Impulse werden mit zunehmender Periode nacheinander addiert (Um periodische Variationen in verschiedenen Maßstäben zu berücksichtigen: Analyse mit mehreren Auflösungen):
Auflistung from numpy import* import pandas as pd from pylab import* import scaleogram as scg

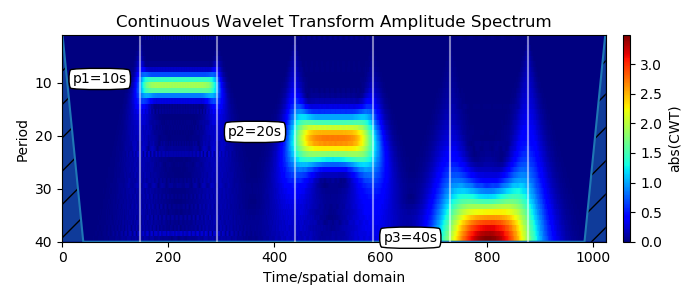
Impulse erscheinen an der erwarteten Stelle Y, entsprechend ihrer Periodizität, sie sind in Frequenz und Zeit lokalisiert. Der Anfang des Streifens und das Ende entsprechen dem Impuls.
Die Bandbreite skaliert mit der Länge des Zeitraums. Dies ist eine bekannte Eigenschaft der Wavelet-Transformation: Wenn die Skala zunimmt, nimmt die zeitliche Auflösung ab. Dies wird auch als Kompromiss zwischen Zeit und Frequenz bezeichnet. Wenn Sie sich ein Spektrogramm dieses Typs ansehen, führen Sie viele Auflösungsanalysen durch.
3. Drei periodische Schwingungen mit unterschiedlichen Frequenzen gleichzeitig (die Wavelet-Analyse kann die Komponenten des Signals nach Frequenz unterscheiden, wenn ihre Unterschiede signifikant sind):
Auflistung from numpy import* import pandas as pd from pylab import* import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')


4. Ein nicht sinusförmiges periodisches Signal (Die Differenz der Wavelet-Transformationen eines Dreieckswellensignals mit einer Periode von 30 Sekunden gegenüber den zuvor betrachteten wird berücksichtigt):
Auflistung from numpy import* from pylab import* import scipy.signal import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')

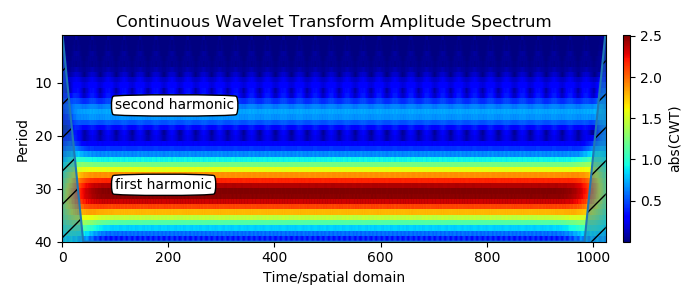
Eine große Band ist die erste Harmonische. Die zweite Harmonische ist genau zum halben Wert der Periode der ersten Harmonischen sichtbar. Dies ist das erwartete Ergebnis für periodische nicht sinusförmige Signale. Um die zweite Harmonische herum erscheinen unscharfe vertikale Elemente, die schwächer sind und für eine dreieckige Wellenform eine Amplitude von 1/4 der ersten haben.
5. Glatte Impulse (Gaußsche Impulse) ähneln realen Datenstrukturen. (Dieses Beispiel zeigt, wie mithilfe der Wavelet-Analyse lokalisierte Signaländerungen im Zeitverlauf erkannt werden.)
Eine Reihe von glatten Impulsen mit unterschiedlichen Sigma-Werten:
Pulsbreite:
Auflistung from numpy import* from pylab import* import scaleogram as scg scg.set_default_wavelet('cmor1-1.5')

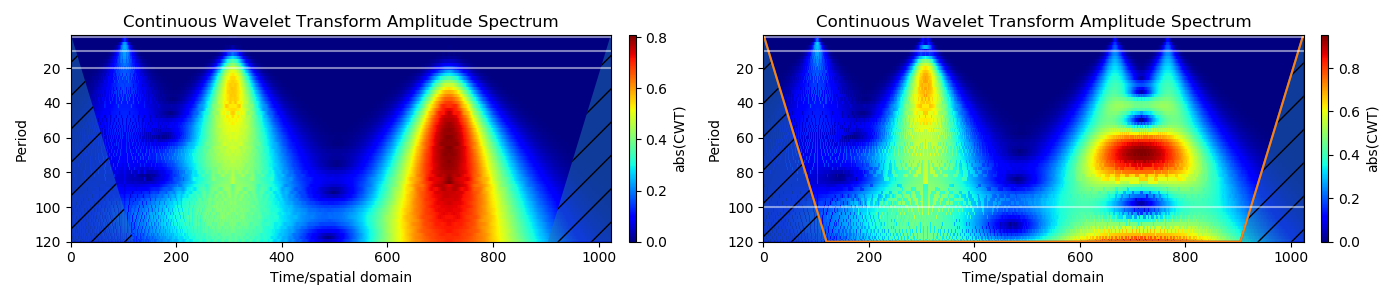
Diskrete Impulse erzeugen im Sialogramm konische Strukturen, die auch als Einflusskegel bezeichnet werden. Glatte Impulse (Gaußsche Impulse) ähneln realen Datenstrukturen und erzeugen Kegel, die sich zu großen Maßstäben ausdehnen. Die horizontalen Führungslinien entsprechen ungefähr Zeiträumen (2 s, 10 s, 20 s). Daher ähnelt der Impuls einem periodischen Signal mit einer Periode.
6. Rauschen (Rauschen im Sialogramm anzeigen):
Auflistung from numpy import* from pylab import* import scaleogram as scg import random scg.set_default_wavelet('cmor1-1.5')


Rauschen wird normalerweise als eine Reihe von Elementen angezeigt, und einige Unregelmäßigkeiten können wie Objekte realer Daten aussehen. Wenn Sie also reale Daten verwenden, müssen Sie vorsichtig sein und gegebenenfalls den Rauschpegel überprüfen. Der obere Zeitplan ist bei jedem Programmstart anders.
Wavelet-Skalogramme von Spezialsignalen
Die PyWavelets-Datenbank enthält zwanzig spezielle Wavelet-Transformationssignale, die sowohl für Studien als auch für die Entwicklung nützlich sind. Daher werde ich eine Liste geben, mit der Sie eine Wavelet-Analyse aller zwanzig Signale durchführen können:
Ich werde nur ein Ergebnis der Wavelet-Transformation des Dopplersignals geben:
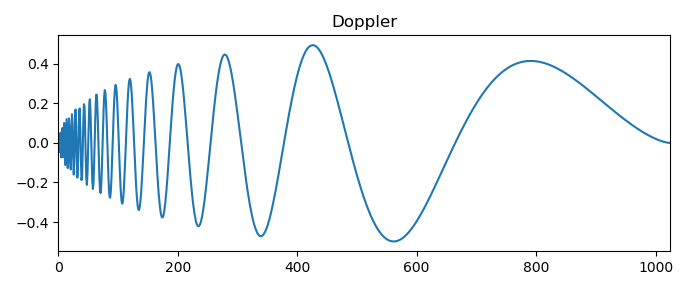

Es werden die häufigsten Arten von einfachen und speziellen Signalen betrachtet, die es uns ermöglichen, auf die Verwendung eines Skalogramms umzuschalten, um einige Probleme der Zeitreihenanalyse zu lösen.
Wavelet-Timeline-Skalogramme
1. CDC-Fertilitätsdaten in den USA 1969-2008 (Fertilitätsdaten enthalten periodische Merkmale, sowohl auf jährlicher als auch auf kleinerer Ebene):
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()


Eine horizontale Linie erscheint mit einer Häufigkeit von ungefähr 7 Tagen. Hohe Werte erscheinen in der Nähe der Grenzen der Skala, was das normale Verhalten der Wavelet-Verarbeitung ist. Diese Effekte sind als Einflusskegel bekannt, weshalb eine (optionale) Maske diesen Bereich überlagert.
2. Normalisierung (Entfernen des Durchschnittswerts -
geburts_normed = Geburten-Geburten.Mittel () ist obligatorisch, andernfalls werden die
Datengrenzen als Stufen betrachtet, die viele falsche kegelförmige Erkennungen erzeugen):
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
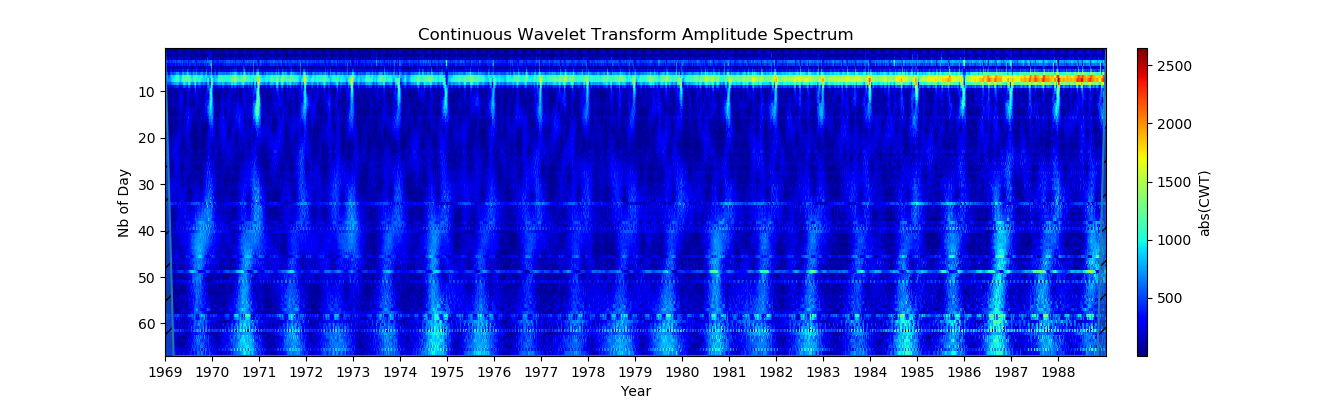
3. Änderung der Amplitudenskala (Um
Jahresobjekte mit
period2scales () anzuzeigen, wird die Skalierung entlang der Y-Achse angegeben).
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
Der Amplitudenbereich der Farbkarte (Y-Achse) wird nun durch klim = (0,2500) eingestellt. Der genaue Wert für die Amplitude der Schwingungen hängt vom Wavelet ab, bleibt jedoch nahe der Größenordnung des tatsächlichen Werts. Das ist viel besser, jetzt sehen wir sehr gut die jährliche Variation sowie ungefähr 6 Monate!
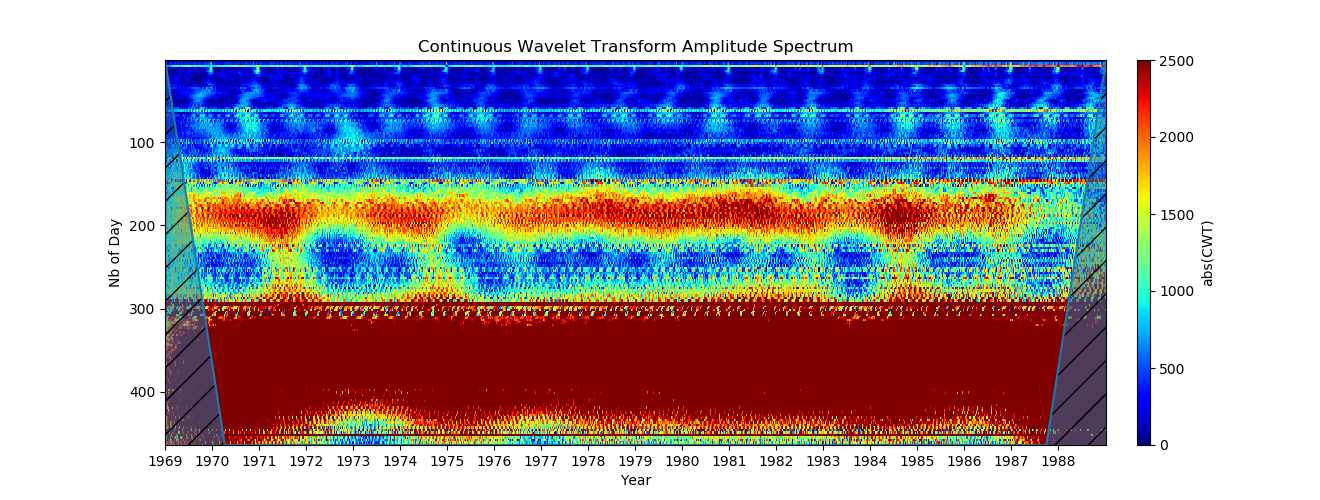
4. Verwenden der logarithmischen Skala (Um kleine und große Perioden gleichzeitig anzuzeigen, ist es besser, die logarithmische Skala auf der Y-Achse zu verwenden. Dies wird mit der Option xscale = log erreicht.)
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()

Das Ergebnis ist viel besser, aber jetzt werden Pixel mit niedrigen Periodenwerten entlang der Y-Achse verlängert.
5. Gleichmäßige Verteilung auf einer logarithmischen Skala (Um eine gleichmäßige Verteilung auf einer Skala zu erhalten, müssen die Periodenwerte gleichmäßig verteilt und dann wie unten gezeigt in Skalenwerte umgewandelt werden :):
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
Wir können Signaländerungen auf allen Skalen sehen. Das Sialogramm zeigt jedes Jahr in gleichen Zeiträumen.
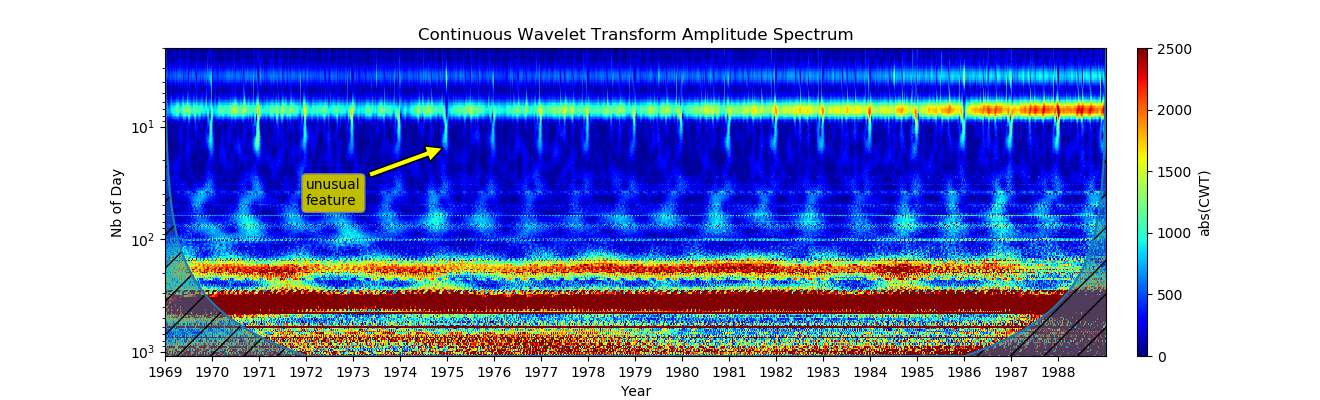
6. Hervorheben eines Teils der Zeitleiste (Suchen nach Zwischendaten zwischen den Zeitleistenmarkierungen auf der Suche nach Artefakten oder fehlenden Daten.):
Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
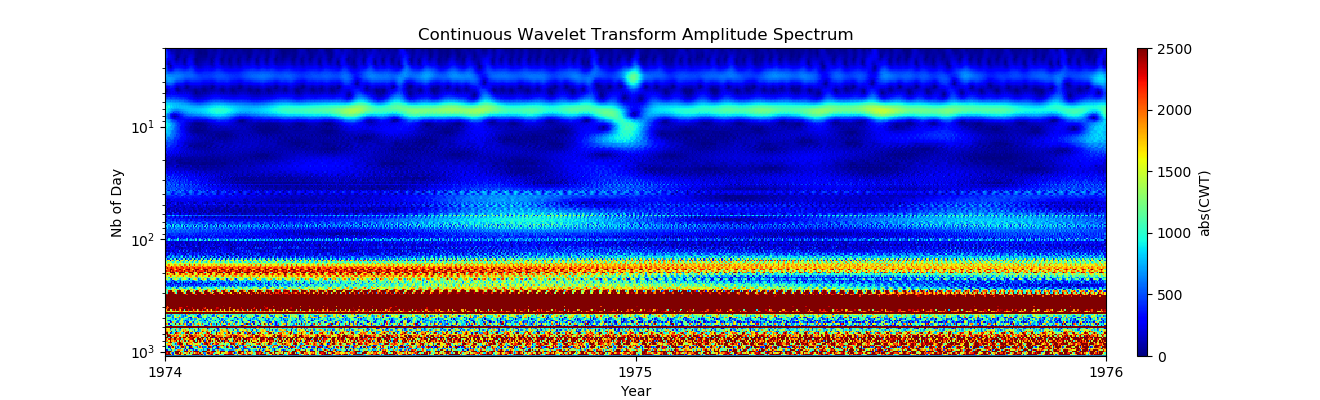 Auf den ersten Blick sehen die wöchentlichen Muster sehr gleichmäßig aus, aber am Weihnachtstag passiert etwas. Schauen wir uns diesen Zeitraum noch einmal an:
Auf den ersten Blick sehen die wöchentlichen Muster sehr gleichmäßig aus, aber am Weihnachtstag passiert etwas. Schauen wir uns diesen Zeitraum noch einmal an:Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()

 Jetzt ist klar, dass dies der Effekt des Jahresendes ist:
Jetzt ist klar, dass dies der Effekt des Jahresendes ist:- Weihnachten: Der 23./24. Dezember zeigt eine ungewöhnlich geringe Anzahl von Geburten, und diese Tage weichen heutzutage vom Wochenplan ab.
- Es gibt Daten für Dezember, die mit dem Vorhandensein eines gewissen Werts für die betroffenen Daten am 1. und 2. Januar übereinstimmen. Diese Daten sind normalerweise kleiner als persönliche Ereignisse
7. Synthese (Ein Sialogramm wird aus normalisierten Daten mit besserer Lesbarkeit für alle Skalen erstellt):Auflistung import pandas as pd import numpy as np from pylab import* import scaleogram as scg import pywt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
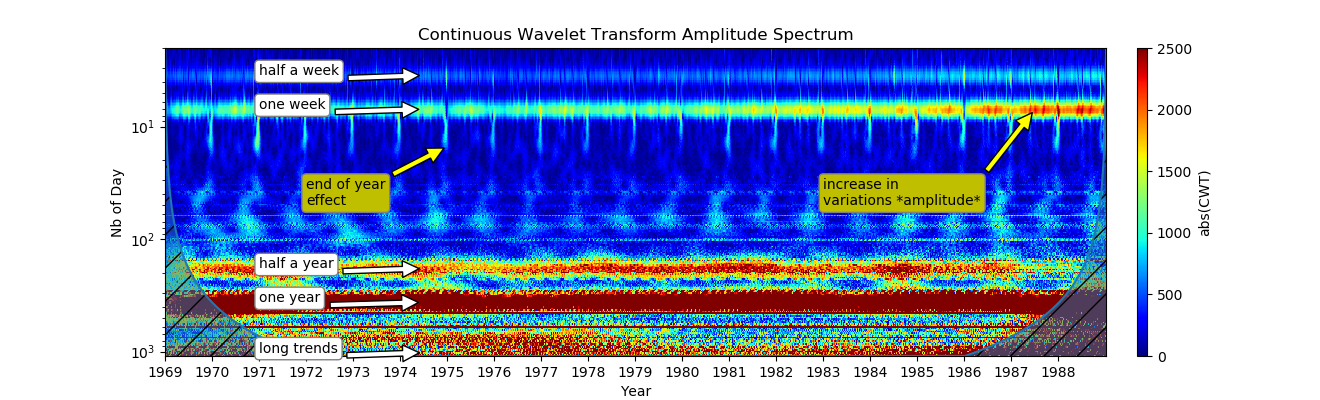 CWT enthüllt in kurzer Zeit viele Informationen:Eine wöchentliche Variation, die die Krankenhausgewohnheiten zeigt, ist seit mehreren Jahrzehnten vorhanden;In den 80er Jahren gab es einen Anstieg des wöchentlichen Indikators, der durch eine Änderung der Arbeitsgewohnheiten von Krankenhäusern, eine Änderung der Fruchtbarkeit oder eine einfache Änderung der Bevölkerung verursacht werden kann.Die zweite Halbjahresband ist eindeutig die zweite Harmonische. In der Zone von 3 bis 1 Monat treten unscharfe Muster auf, was auf die dritte Harmonische zurückzuführen sein kann, da die jährlichen Schwankungen so stark sind. Es kann auch durch die Auswirkung von Feiertagen auf die Fruchtbarkeit verursacht werden und weitere Untersuchungen erfordern;Die Auswirkungen des Jahresendes wurden an Weihnachten und am 1. Januar festgestellt. Dieser kann bei einer anderen Frequenzmethode unsichtbar geblieben sein.
CWT enthüllt in kurzer Zeit viele Informationen:Eine wöchentliche Variation, die die Krankenhausgewohnheiten zeigt, ist seit mehreren Jahrzehnten vorhanden;In den 80er Jahren gab es einen Anstieg des wöchentlichen Indikators, der durch eine Änderung der Arbeitsgewohnheiten von Krankenhäusern, eine Änderung der Fruchtbarkeit oder eine einfache Änderung der Bevölkerung verursacht werden kann.Die zweite Halbjahresband ist eindeutig die zweite Harmonische. In der Zone von 3 bis 1 Monat treten unscharfe Muster auf, was auf die dritte Harmonische zurückzuführen sein kann, da die jährlichen Schwankungen so stark sind. Es kann auch durch die Auswirkung von Feiertagen auf die Fruchtbarkeit verursacht werden und weitere Untersuchungen erfordern;Die Auswirkungen des Jahresendes wurden an Weihnachten und am 1. Januar festgestellt. Dieser kann bei einer anderen Frequenzmethode unsichtbar geblieben sein.Schlussfolgerungen:
In dieser Veröffentlichung haben wir gesehen, wie sich die Grundform von Signalvariationen in ein Skalogramm umsetzt. Ein Beispiel eines zeitlich geordneten Datensatzes wurde dann verwendet, um Schritt für Schritt zu demonstrieren, wie CWT auf Standarddaten angewendet wird.Die obige Technik kann erweitert werden, um den Netzwerkverkehr zu analysieren und ungewöhnliches Verhalten von Objekten zu erkennen. CWT ist ein leistungsstarkes Tool, das zunehmend als Eingabe für neuronale Netze verwendet wird und zur Erstellung neuer Funktionen zur Klassifizierung oder Erkennung von Anomalien verwendet werden kann.Jedes Beispiel ist als eigenständiges Programm implementiert, mit dem Sie ein Beispiel für Ihre Aufgabe auswählen können, ohne auf die vorherigen und nachfolgenden Beispiele eingehen zu müssen. Der Benutzer kann beliebige Wavelet-Funktionen aus der am Anfang jedes Programms angegebenen Liste ausprobieren, z. B. mexh oder gaus5. Zum Beispiel 1:
 PS Für die praktische Verwendung von Auflistungen werde ich die Versionen der darin verwendeten Module angeben:
PS Für die praktische Verwendung von Auflistungen werde ich die Versionen der darin verwendeten Module angeben: >>> import scaleogram; print(scaleogram .__version__) 0.9.5 >>> import pandas; print(pandas .__version__) 0.24.1 >>> import numpy; print(numpy .__version__) 1.16.1 >>> import matplotlib; print(matplotlib .__version__) 3.0.2
Für einen unabhängigen Datensatz in der * .csv-Datei bringe ich die Datenstruktur (in einer Spalte):Jahr, Monat, Tag, Geschlecht, Geburten1969,1,1, F, 40461969,1,1, M, 44401969,1,2 F, 4454,1969.1.2, M, 4548...
Für Pandas der Version 0.24.1 müssen Sie Matplotlib-Konverter explizit registrieren.So registrieren Sie Konverter: from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()