Hallo Kollegen!
Vielleicht hätte der Titel der heutigen Veröffentlichung mit einem Fragezeichen besser ausgesehen - es ist schwer zu sagen. Auf jeden Fall möchten wir Ihnen heute eine kurze Tour anbieten, die Sie in die
Dask- Bibliothek einführt, mit der Aufgaben in Python parallelisiert werden sollen. Wir hoffen, dass wir in Zukunft noch ausführlicher auf dieses Thema zurückkommen können.
 Foto aufgenommen bei
Foto aufgenommen beiDask ist ohne Übertreibung das revolutionärste Datenverarbeitungswerkzeug, auf das ich gestoßen bin. Wenn Sie
Pandas und Numpy mögen , aber manchmal nicht mit Daten umgehen können, die nicht in den Arbeitsspeicher passen, ist Dask genau das, was Sie brauchen. Dask unterstützt den Pandas-Datenrahmen und Numpy-Datenstrukturen (Arrays). Dask kann entweder auf dem lokalen Computer oder skaliert ausgeführt und dann im Cluster ausgeführt werden. Im Wesentlichen schreiben Sie den Code nur einmal und wählen dann aus, ob Sie ihn auf dem lokalen Computer verwenden oder in einem Cluster mit vielen Knoten mithilfe der gängigsten Python-Syntax bereitstellen möchten. Die Funktion selbst ist großartig, aber ich habe beschlossen, diesen Artikel zu schreiben, um zu betonen: Jeder Data Scientist (zumindest mit Python) sollte Dask verwenden. Aus meiner Sicht besteht die Magie von Dask darin, dass Sie durch Minimieren des Codes ihn mithilfe der Rechenleistung parallelisieren können, die beispielsweise auf meinem Laptop bereits verfügbar ist. Bei paralleler Datenverarbeitung läuft das Programm schneller, Sie müssen weniger warten und dementsprechend bleibt mehr Zeit für die Analyse. In diesem Artikel werden wir insbesondere über das Objekt
dask.delayed sprechen und darüber, wie es in den Data Science-Aufgabenstrom passt.
Dask vorstellen
Als Einführung in Dask finden Sie hier einige Beispiele, um Ihnen einen Eindruck von der völlig unauffälligen und natürlichen Syntax zu vermitteln. Die wichtigste Schlussfolgerung, die ich in diesem Fall vorschlagen möchte, ist, dass das Wissen, über das Sie bereits verfügen, ausreicht, um zu arbeiten. Sie müssen kein neues Big-Data-Tool wie Hadoop oder Spark erlernen.
Dask bietet 3 parallele Sammlungen an, in denen Sie Daten speichern können, die die Größe des RAM überschreiten, nämlich Dataframes, Bags und Arrays. In jeder dieser Arten von Sammlungen können Sie Daten speichern, indem Sie sie zwischen RAM und Festplatte segmentieren sowie Daten auf mehrere Knoten in einem Cluster verteilen.
Ein Dask DataFrame besteht aus geschredderten Datenframes, z. B. in Pandas, sodass Sie eine Teilmenge der Funktionen der Pandas-Abfragesyntax verwenden können. Unten finden Sie einen Beispielcode, der alle CSV-Dateien für 2018 herunterlädt, ein Feld mit einem Zeitstempel analysiert und eine Pandas-Anforderung startet:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Dask Dataframe-BeispielIn Dask Bag können Sie Sammlungen von Python-Objekten speichern und verarbeiten, die nicht in den Speicher passen. Dask Bag eignet sich hervorragend für die Verarbeitung von Protokollen und Sammlungen von Dokumenten im JSON-Format. In diesem Codebeispiel werden alle JSON-Dateien für 2018 in die Dask Bag-Datenstruktur geladen, jeder JSON-Datensatz wird analysiert und Benutzerdaten werden mithilfe der Lambda-Funktion gefiltert:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
Dask Bag BeispielDie Datenstruktur von Dask Arrays unterstützt Slices im Numpy-Stil. Im folgenden Beispiel wird ein Satz von HDF5-Daten in Dimensionsblöcke (5000, 5000) aufgeteilt:
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Dask Array BeispielParallelverarbeitung in Dask
Ein weiterer ebenso genauer Titel für diesen Abschnitt wäre "Tod eines sequentiellen Zyklus". Hin und wieder stoße ich auf ein gemeinsames Muster: Durchlaufen Sie die Liste der Elemente und führen Sie dann die Python-Methode mit jedem Element aus, jedoch mit unterschiedlichen Eingabeargumenten. Zu den gängigen Datenverarbeitungsszenarien gehört das Berechnen von Feature-Aggregaten für jeden Client oder das Aggregieren von Ereignissen aus dem Protokoll für jeden Schüler. Anstatt auf jedes Argument in einer sequentiellen Schleife eine Funktion anzuwenden, können Sie mit dem Objekt Dask Delayed viele Elemente parallel verarbeiten. Bei der Arbeit mit Dask Delayed werden alle Funktionsaufrufe in die Warteschlange gestellt und in das Ausführungsdiagramm eingefügt. Danach sollen sie verarbeitet werden.
Ich war immer etwas faul, meine eigene Threading-Engine zu schreiben oder Asyncio zu verwenden, daher werde ich Ihnen nicht einmal ähnliche Beispiele zum Vergleich zeigen. Mit Dask können Sie weder die Syntax noch den Programmierstil ändern! Sie müssen nur die Methode kommentieren oder
@dask.delayed , die parallel zu
@dask.delayed und die Berechnungsmethode aufrufen, nachdem der Schleifencode ausgeführt wurde.
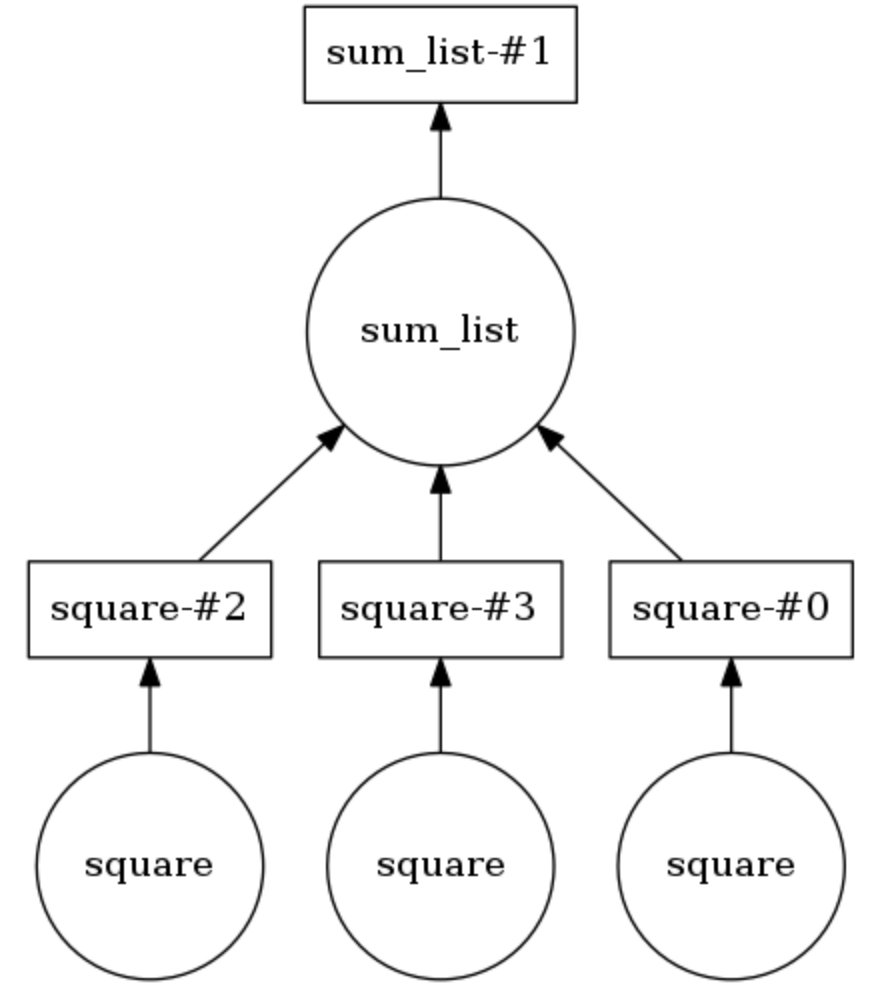
Dask Computing Graph Beispiel
Im folgenden Beispiel sind die beiden Methoden mit
@dask.delayed . Drei Zahlen werden in einer Liste gespeichert, sie müssen quadriert und dann summiert werden. Dask erstellt einen Berechnungsgraphen, der die parallele Ausführung der Quadrierungsmethode
sum_list .
sum_list das Ergebnis dieser Operation an die
sum_list Methode übergeben. Das Berechnungsdiagramm kann durch
calling .visualize() angezeigt werden.
Calling .compute() wird das Berechnungsdiagramm ausgeführt. Wie aus der
Schlussfolgerung hervorgeht , werden die Listenelemente nicht in der richtigen Reihenfolge, sondern parallel verarbeitet.
Die Anzahl der Threads kann festgelegt werden (z. B.
dask.set_options( pool=ThreadPool(10) ), und sie können auch einfach ausgetauscht werden, um Prozesse auf Ihrem Laptop oder PC zu verwenden (z. B.
dask.config.set( scheduler='processes' ). .
Daher habe ich gezeigt, wie trivial es sein wird, einem Projekt aus dem Bereich Data Science mithilfe von Dask eine parallele Verarbeitung von Aufgaben hinzuzufügen. Kurz bevor ich diesen Artikel schrieb, habe ich Dask verwendet, um die Daten über Benutzer-Klick-Streams (Besuchsverlauf) in 40-minütige Sitzungen aufzuteilen und dann die Attribute für jeden Benutzer für weitere Cluster zu aggregieren. Sagen Sie uns, wie Sie Dask verwendet haben!