Eintrag
Guten Tag. Seit einem halben Jahr führen wir ein Skript (genauer gesagt eine Reihe von Skripten) aus, das Berichte über den Status virtueller Maschinen (und nicht nur) generiert. Ich beschloss, die Erstellungserfahrung und den Code selbst zu teilen. Ich zähle auf Kritik und die Tatsache, dass dieses Material für jemanden nützlich sein kann.
Wir haben viele virtuelle Maschinen (ungefähr 1500 VMs, die über das 3. vCenter verteilt sind). Neue werden erstellt und alte werden ziemlich oft gelöscht. Um die Reihenfolge zu erhalten, wurden vCenter mehrere benutzerdefinierte Felder hinzugefügt, um VMs in Subsysteme zu unterteilen und anzugeben, ob und von wem und wann sie getestet werden. Der menschliche Faktor hat dazu geführt, dass mehr als die Hälfte der Autos leere Felder hatten, was die Arbeit erschwerte. Alle sechs Monate flippte jemand aus und begann mit der Aktualisierung dieser Daten, aber das Ergebnis war anderthalb Wochen lang nicht mehr relevant.
Ich werde sofort klarstellen, dass jeder versteht, dass es Anwendungen zum Erstellen von Maschinen, einen Prozess zum Erstellen dieser Maschinen usw. geben sollte. usw. Und während all dieser Prozess streng und in Ordnung ist. Leider ist dies bei uns nicht der Fall, aber dies ist nicht das Thema des Artikels :)
Im Allgemeinen wurde beschlossen, die Überprüfung der Richtigkeit des Ausfüllens der Felder zu automatisieren.
Wir haben beschlossen, dass ein täglicher Brief mit einer Liste falsch gefüllter Maschinen für alle verantwortlichen Ingenieure und ihre Vorgesetzten ein guter Anfang ist.
Zu diesem Zeitpunkt hatte einer der Kollegen bereits ein PowerShell-Skript implementiert, das jeden Tag nach einem Zeitplan Informationen auf allen Computern aller vCenter-s sammelte und 3 CSV-Dokumente (jeweils in einem eigenen vCenter) erstellte, die auf einer gemeinsam genutzten Festplatte angeordnet waren. Es wurde beschlossen, dieses Skript als Grundlage zu verwenden und es durch Überprüfungen in der R-Sprache zu ergänzen, mit denen ich einige Erfahrung hatte.
Während des Finalisierungsprozesses wurde die Lösung mit Informationen per E-Mail, einer Datenbank mit den Haupt- und Verlaufstabellen (dazu später mehr) sowie der Analyse von vSphere-Protokollen überwachsen, um die tatsächlichen Ersteller von vm und den Zeitpunkt ihrer Erstellung zu ermitteln.
Für die Entwicklung wurden IDE RStudio Desktop und PowerShell ISE verwendet.
Das Skript wird von einer normalen virtuellen Windows-Maschine gestartet.
Beschreibung der allgemeinen Logik.
Die allgemeine Logik der Skripte lautet wie folgt.
- Wir sammeln Daten auf virtuellen Maschinen mithilfe des PowerShell-Skripts, das über R aufgerufen wird. Das Ergebnis wird zu einer CSV zusammengefasst. Die umgekehrte Interaktion zwischen Sprachen erfolgt ähnlich. (Es war möglich, Daten in Form von Variablen direkt von R nach PowerShell zu übertragen, aber es ist schwierig, und selbst mit Zwischen-CSV ist es einfacher, Zwischenergebnisse zu debuggen und mit jemandem zu teilen.)
- Mit R bilden wir gültige Parameter für die Felder, deren Werte wir überprüfen. - Wir bilden ein Word-Dokument, das die Werte dieser Felder zum Einfügen in einen Informationsbrief enthält und eine Antwort auf Fragen von Kollegen enthält. "Nicht gut, aber wie soll ich das ausfüllen?"
- Wir laden Daten auf allen VMs von CSV mit R, bilden einen Datenrahmen, entfernen unnötige Felder und erstellen ein Informations-XLSX-Dokument, das zusammenfassende Informationen zu allen VMs enthält, die wir in eine gemeinsam genutzte Ressource hochladen.
- Für den Datenrahmen für alle VMs wenden wir alle Überprüfungen auf die Richtigkeit des Ausfüllens der Felder an und bilden eine Tabelle, die nur VMs mit falsch ausgefüllten Feldern (und nur diese Felder) enthält.
- Die resultierende Liste der VMs wird an ein anderes PowerShell-Skript gesendet, das die vCenter-Protokolle auf VM-Erstellungsereignisse überprüft. Auf diese Weise können Sie den geschätzten Erstellungszeitpunkt der VM und den beabsichtigten Ersteller angeben. Dies ist der Fall, wenn niemand gesteht, wessen Auto. Dieses Skript funktioniert nicht schnell, insbesondere wenn viele Protokolle vorhanden sind. Wir betrachten daher nur die letzten zwei Wochen und verwenden auch den Workflow, mit dem Sie gleichzeitig nach Informationen auf mehreren VMs suchen können. Im Beispielskript gibt es detaillierte Kommentare zu diesem Mechanismus. Das Ergebnis wird zu csv hinzugefügt, das erneut in R geladen wird.
- Wir bilden ein wunderschön formatiertes xlsx-Dokument, in dem falsch ausgefüllte Felder rot hervorgehoben werden, Filter auf einige Spalten angewendet werden und zusätzliche Spalten mit den mutmaßlichen Erstellern und dem Zeitpunkt der VM-Erstellung angezeigt werden.
- Wir bilden eine E-Mail, in der wir ein Dokument mit den gültigen Feldwerten sowie eine Tabelle mit falsch ausgefüllten Daten ablegen. Im Text geben wir die Gesamtzahl der falsch erstellten VMs, einen Link zu einer gemeinsam genutzten Ressource und ein Motivationsimage an. Wenn es keine falsch bestückten VMs gibt, senden wir einen weiteren Brief mit einem freudigeren Motivationsbild.
- Wir zeichnen Daten auf allen VMs in der SQL Server-Datenbank unter Berücksichtigung des implementierten Mechanismus historischer Tabellen auf (ein sehr interessanter Mechanismus - über den detaillierter berichtet wird).
Skripte
Die Hauptdatei mit dem Code für R. Skript zum Abrufen der VM-Liste in PowerShell PowerShell-Skript zum Abrufen der Protokolle der Ersteller virtueller Maschinen und ihrer Erstellungsdaten Die xlsx- Bibliothek verdient besondere Aufmerksamkeit, wodurch es möglich wurde, den Anhang zum Brief klar zu formatieren (wie es das Handbuch mag) und nicht nur eine CSV-Tabelle.
Erstellen eines schönen XLSX-Dokuments mit einer Liste falsch ausgefüllter Maschinen Die Ausgabe ist ungefähr so:
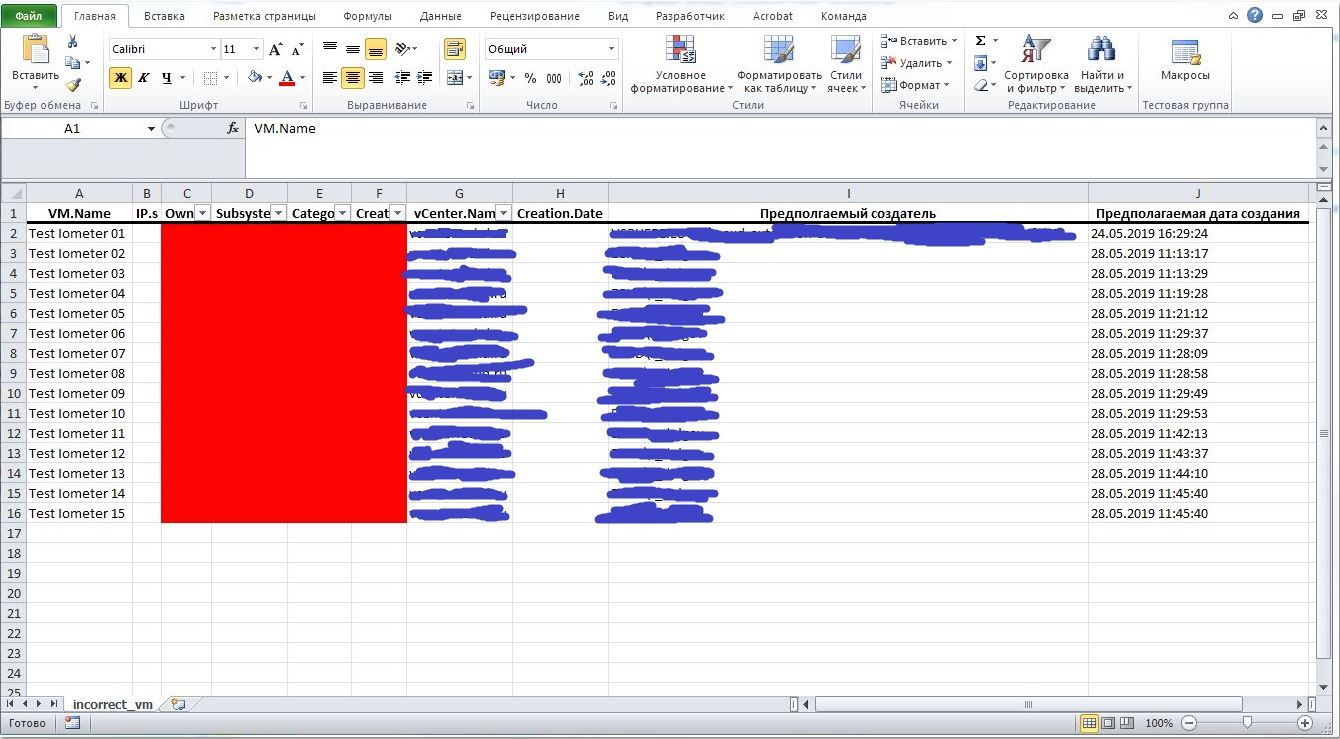
Es gab auch eine interessante Nuance beim Einrichten von Windows Scheduller. Es hat nicht geklappt, die richtigen Rechte- und Einstellungsparameter zu ermitteln, damit alles so beginnt, wie es sollte. Als Ergebnis wurde die R-Bibliothek gefunden, die selbst eine Aufgabe zum Ausführen des R-Skripts erstellt und die Protokolldatei nicht einmal vergisst. Dann können Sie die Aufgabe mit Stiften korrigieren.
Ein Teil des R-Codes mit zwei Beispielen, der eine Aufgabe im Windows Scheduler erstellt library(taskscheduleR) myscript <- file.path(getwd(), "all_vm.R")
Separat über die Datenbank
Nach dem Einrichten des Skripts tauchten weitere Fragen auf. Ich wollte beispielsweise das Datum ermitteln, an dem die VM gelöscht wurde und die Protokolle in vCenter bereits abgenutzt waren. Da das Skript die Dateien jeden Tag in den Ordner legt und sie nicht bereinigt (wir bereinigen sie mit unseren Händen, wenn wir uns erinnern), können Sie sich die alten Dateien ansehen und die erste Datei finden, in der diese VM nicht vorhanden ist. Das ist aber nicht cool.
Ich wollte eine historische Datenbank erstellen.
Die MS SQL SERVER-Funktionalität kam zu Hilfe - eine systemversionierte Zeittabelle. Es wird normalerweise als temporäre (nicht temporäre) Tabellen übersetzt.
Sie können ausführlich in der offiziellen Microsoft-Dokumentation lesen.
Kurz gesagt, wir erstellen eine Tabelle, wir sagen, dass wir sie mit einer Version haben werden, und SQL Server erstellt zwei zusätzliche Datums- / Uhrzeitspalten in dieser Tabelle (das Erstellungsdatum des Datensatzes und das Enddatum des Datensatzes) und eine zusätzliche Tabelle, in die die Änderungen geschrieben werden. Als Ergebnis erhalten wir relevante Informationen und können durch einfache Abfragen, von denen Beispiele in der Dokumentation angegeben sind, entweder den Lebenszyklus einer bestimmten virtuellen Maschine oder den Status aller VMs zu einem bestimmten Zeitpunkt anzeigen.
In Bezug auf die Leistung wird die Schreibtransaktion in die Haupttabelle erst abgeschlossen, wenn die Schreibtransaktion in die temporäre Tabelle abgeschlossen ist. Das heißt, Bei Tabellen mit einer großen Anzahl von Schreibvorgängen sollte diese Funktionalität mit Vorsicht implementiert werden. In unserem Fall ist dies jedoch eine sehr coole Sache.
Damit der Mechanismus ordnungsgemäß funktioniert, musste ein kleiner Code auf R hinzugefügt werden, der die neue Tabelle mit den Daten aller VMs mit der in der Datenbank gespeicherten vergleicht und nur geänderte Zeilen in diese schreibt. Der Code ist nicht sehr knifflig, er verwendet die compareDF-Bibliothek, aber ich werde ihn auch unten geben.
R-Code zum Schreiben von Daten in die Datenbank Insgesamt
Infolge der Einführung des Skripts wurde die Reihenfolge mehrere Monate lang aufrechterhalten. Manchmal werden falsch bestückte VMs angezeigt, aber das Skript dient als gute Erinnerung und eine seltene VM wird 2 Tage hintereinander in die Liste aufgenommen.
Es wurde auch eine Reserve für die Analyse historischer Daten gebildet.
Es ist klar, dass vieles davon nicht „am Knie“, sondern mit spezieller Software realisiert werden kann, aber die Aufgabe war interessant und, könnte man sagen, optional.
R erwies sich erneut als eine wunderbare universelle Sprache, die sich nicht nur perfekt zur Lösung statistischer Probleme eignet, sondern auch als hervorragende "Verlegung" zwischen anderen Datenquellen dient.