Einführung
Achtung, dies ist kein weiterer "Hallo Welt" -Artikel darüber, wie man eine LED blinkt oder in ihren ersten Interrupt auf STM32 gerät. Ich habe jedoch versucht, umfassende Erklärungen zu allen aufgeworfenen Fragen zu geben, so dass der Artikel nicht nur für viele Fachleute nützlich sein wird und davon träumt, solche Entwickler zu werden (wie ich hoffe), sondern auch für unerfahrene Mikrocontroller-Programmierer, da dieses Thema aus irgendeinem Grund auf unzähligen Websites / herumkommt. Blogs "MK Programmierlehrer."
Warum habe ich beschlossen, dies zu schreiben?
Obwohl ich übertrieben habe, nachdem ich zuvor gesagt habe, dass das Hardware-Bit-Banding der Cortex-M-Familie nicht auf speziellen Ressourcen beschrieben wird, gibt es immer noch Stellen, an denen diese Funktion behandelt wird (und hier sogar einen Artikel erfüllt), aber dieses Thema muss eindeutig ergänzt und modernisiert werden. Ich stelle fest, dass dies auch für englischsprachige Ressourcen gilt. Im nächsten Abschnitt werde ich erklären, warum diese Kernelfunktion extrem wichtig sein kann.
Theorie
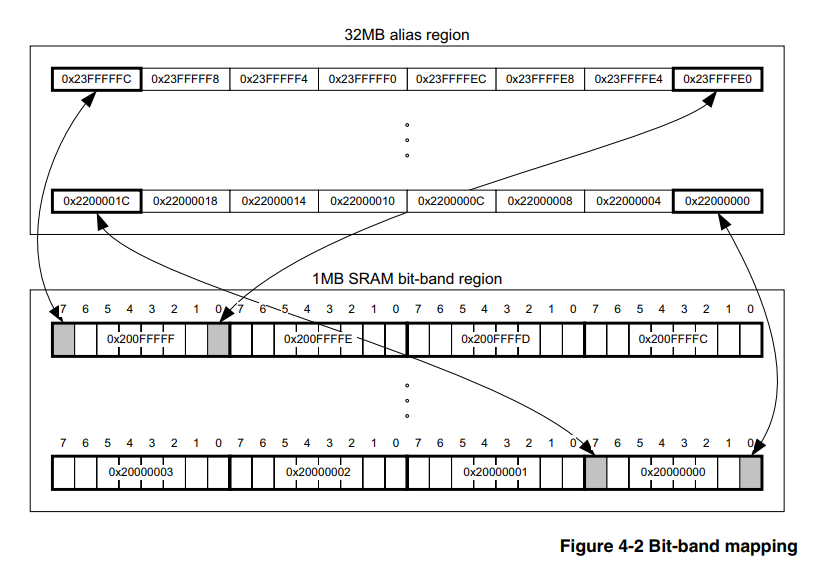
(und diejenigen, die sie kennen, können sofort in die Praxis einsteigen)Hardware-Bit-Banding ist ein Merkmal des Kerns selbst und hängt daher nicht von der Familie und dem Unternehmen des Mikrocontroller-Herstellers ab. Hauptsache, der Kern ist geeignet. In unserem Fall sei es Cortex-M3. Daher sollten Informationen zu diesem Thema in einem offiziellen Dokument über den Kern selbst eingeholt werden. Es gibt ein solches Dokument.
Hier wird in Abschnitt 4.2 ausführlich beschrieben, wie dieses Tool verwendet wird.
Hier möchte ich einen kleinen technischen Exkurs für Programmierer machen, die mit Assembler nicht vertraut sind, von denen die Mehrheit jetzt aufgrund der propagierten Komplexität und Nutzlosigkeit von Assembler für so "ernsthafte" 32-Bit-Mikrocontroller wie STM32, LPC usw. ist. Außerdem kann man häufig auf Versuche stoßen Kritik für den Einsatz von Assembler in diesem Bereich, auch auf dem Habr. In diesem Abschnitt möchte ich kurz den Mechanismus des Schreibens in den MK-Speicher beschreiben, der die Vorteile der Bitbandierung verdeutlichen soll.
Ich werde ein spezielles einfaches Beispiel für die meisten STM32 erklären. Angenommen, ich muss PB0 in einen Allzweckausgang verwandeln. Eine typische Lösung würde folgendermaßen aussehen:
GPIOB->MODER |= GPIO_MODER_MODER0_0;
Offensichtlich verwenden wir das bitweise "ODER", um die verbleibenden Bits des Registers nicht zu überschreiben.
Für den Compiler bedeutet dies den folgenden Satz von 4 Anweisungen:
- Laden Sie GPIOB-> MODER in das Allzweckregister (RON) herunter.
- Laden Sie die Werte von p1 auf die in der ROZ angegebene Adresse auf die andere ROZ hoch.
- Machen Sie mit GPIO_MODER_MODER0_0 ein bitweises ODER aus diesem Wert.
- Laden Sie das Ergebnis zurück auf GPIOB-> MODER.
Außerdem sollte man nicht vergessen, dass dieser Kernel den Befehlssatz thumb2 verwendet, was bedeutet, dass die Lautstärke unterschiedlich sein kann. Ich stelle auch fest, dass wir überall über den Grad der Optimierung von O3 sprechen.
In der Assemblersprache sieht es so aus:

Es ist ersichtlich, dass der allererste Befehl nichts anderes als ein Pseudobefehl mit einem Versatz ist. Wir finden die Adresse des Registers an der PC-Adresse (angesichts des Förderbandes) + 0x58.
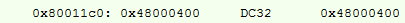
Es stellt sich heraus, dass wir 4 Schritte (und mehr Taktzyklen) und 14 Bytes belegten Speicher pro Operation haben.
Wenn Sie mehr darüber wissen wollen, dann empfehle ich das Buch [2], das es übrigens auch auf Russisch gibt.
Wir gehen zur bit_banding-Methode über.
Das Wesentliche ist laut dem Bauern, dass der Prozessor einen speziell zugewiesenen Speicherbereich hat, der die Werte schreibt, in die wir keine anderen Bits des Peripherieregisters oder des RAM ändern. Das heißt, wir müssen die oben beschriebenen Punkte 2) und 3) nicht erfüllen, und dazu reicht es aus, nur die Adresse gemäß den Formeln aus [1] wiederzugeben.

Wir versuchen, eine ähnliche Operation durchzuführen, ihren Assembler:

Neu berechnete Adresse:

Hier haben wir eine Schreibanweisung Nr. 1 in den ROZ eingefügt, aber das Ergebnis sind 10 Bytes anstelle von 14 und ein paar Taktzyklen weniger.
Aber was ist, wenn der Unterschied lächerlich ist?
Einerseits sind die Einsparungen nicht signifikant, insbesondere in Zyklen, in denen es bereits üblich ist, den Controller auf 168 MHz zu übertakten. In einem durchschnittlichen Projekt liegen die Momente, in denen Sie diese Methode anwenden können, zwischen 40 und 80. In Byte können die Einsparungen 250 Byte erreichen, wenn sich die Adressen unterscheiden. Und wenn wir bedenken, dass das Programmieren von MK direkt in Registern jetzt als "zashkvar" angesehen wird und es "cool" ist, alle Arten von Würfelwürfeln zu verwenden, können die Einsparungen viel höher sein.
Die Zahl von 250 Bytes wird auch durch die Tatsache verzerrt, dass Bibliotheken auf hoher Ebene aktiv in der Community verwendet werden und die Firmware auf unanständige Größen aufgeblasen wird. Bei niedriger Programmierung sind dies mindestens 2 - 5% des Softwarevolumens für ein durchschnittliches Projekt mit kompetenter Architektur und O3-Optimierung.
Auch hier möchte ich nicht sagen, dass dies eine Art Super-Duper-Mega-Cool-Tool ist, das jeder MK-Programmierer mit Selbstachtung verwenden sollte. Aber wenn ich die Kosten auch nur um einen so kleinen Teil senken kann, warum dann nicht?Implementierung
Alle Optionen werden nur zur Konfiguration der Peripheriegeräte angegeben, da ich nicht auf eine Situation gestoßen bin, in der RAM erforderlich wäre. Genau genommen ist die Formel für RAM ähnlich. Ändern Sie einfach die Basisadressen für die Berechnung. Wie setzen Sie das um?
Assembler
Lass uns von unten gehen, von meinem geliebten Assembler.
Bei Assembler-Projekten ordne ich normalerweise ein paar 2-Byte-ROZ (gemäß den Anweisungen, die mit ihnen funktionieren) RON unter # 0 und # 1 für das gesamte Projekt zu und verwende sie auch in Makros, wodurch ich kontinuierlich weitere 2 Bytes reduziere. Bemerkung, ich habe CMSIS in Assembler für STM nicht gefunden, weil ich die Bitnummer sofort in das Makro eingefügt habe und nicht den Registerwert.
Implementierung für GNU Assembler @ . MOVW R0, 0x0000 MOVW R1, 0x0001 @ .macro PeriphBitSet PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4)) STR R1, [R3] .endm @ .macro PeriphBitReset PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4)) STR R0, [R3] .endm
Beispiele:
Assembler-Beispiele PeriphSet TIM2_CCR2, 0 PeriphBitReset USART1_SR, 5
Der zweifelsfreie Vorteil dieser Option besteht darin, dass wir die volle Kontrolle haben, was über weitere Optionen nicht gesagt werden kann. Und wie der letzte Abschnitt des Artikels zeigen wird, ist dieser
sehr bedeutsam.
Es benötigt jedoch niemand Projekte für MK in Assembler, etwa ab dem Ende der Null, was bedeutet, dass Sie zu SI wechseln müssen.
Ebene c
Ehrlich gesagt, habe ich am Anfang des Pfades irgendwo im riesigen Netzwerk eine einfache Sishny-Option gefunden. Zu diesem Zeitpunkt habe ich bereits Bit-Banding in Assembler implementiert und bin versehentlich auf eine C-Datei gestoßen. Es hat sofort funktioniert und ich habe beschlossen, nichts zu erfinden.
Implementierung für einfaches C. #define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0 #define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A) #define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A) #define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A) #define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A) #define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A) #define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A) #define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A) #define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A) #define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A) #define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A) #define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A) #define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A) #define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A) #define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A) #define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A) #define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A) #define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A) #define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A) #define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A) #define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A) #define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A) #define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A) #define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A) #define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A) #define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A) #define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A) #define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A) #define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A) #define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A) #define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A) #define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A) #define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
Wie Sie sehen können, handelt es sich um einen sehr einfachen und unkomplizierten Code, der in der Sprache des Prozessors geschrieben ist. Die Hauptarbeit hier ist die Übersetzung von CMSIS-Werten in eine Bitnummer, die als Notwendigkeit für eine Assembler-Version fehlte.
Oh ja, benutze diese Option wie folgt:
Beispiele für einfaches C. BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0;
Moderne Trends (nach meinen Beobachtungen massiv, ungefähr ab 2015) sprechen jedoch dafür, C auch für MK durch C ++ zu ersetzen. Und Makros sind nicht das zuverlässigste Werkzeug, daher sollte die nächste Version geboren werden.
Cpp03
Hier, einem sehr interessanten und diskutierten, aber angesichts seiner Komplexität wenig genutzten, mit einem abgedroschenen Beispiel einer Fakultät, taucht das Tool Metaprogrammierung auf.
Schließlich ist die Aufgabe, den Wert einer Variablen in eine Bitzahl zu übersetzen, ideal (es gibt bereits Werte in CMSIS), und in diesem Fall ist es praktisch für die Kompilierungszeit.
Ich habe dies mithilfe von Vorlagen wie folgt implementiert:
Implementierung für C ++ 03 template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value { enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num }; }; template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)> { enum { bit_num = 31 }; }; #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
Sie können es auf die gleiche Weise verwenden:
Beispiele für C ++ 03 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false;
Und warum wurde das Makro verlassen? Tatsache ist, dass ich keinen anderen Weg kenne, um diesen Vorgang garantiert einzufügen, ohne in einen anderen Bereich des Programmcodes zu wechseln. Ich würde mich sehr freuen, wenn sie mich in den Kommentaren dazu auffordern würden. Weder Vorlagen noch Inline-Funktionen bieten eine solche Garantie. Ja, und das Makro hier kommt mit seiner Aufgabe perfekt zurecht. Es macht keinen Sinn, es zu ändern, nur weil der
Konformist dies für „nicht sicher“ hält.
Überraschenderweise stand die Zeit immer noch nicht still, Compiler unterstützten zunehmend C ++ 14 / C ++ 17, warum nicht die Innovationen nutzen und den Code verständlicher machen?
Cpp14 / cpp17
Implementierung für C ++ 14 constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num) { return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1); } #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
Wie Sie sehen, habe ich gerade die Vorlagen durch eine rekursive constexpr-Funktion ersetzt, die meiner Meinung nach für das menschliche Auge klarer ist.
Verwenden Sie den gleichen Weg. Übrigens können Sie in C ++ 17 im Prinzip die rekursive Lambda-Constexpr-Funktion verwenden, aber ich bin nicht sicher, ob dies zu zumindest einigen Vereinfachungen führt und auch die Assembler-Reihenfolge nicht kompliziert.
Zusammenfassend geben alle drei C / Cpp-Implementierungen gemäß dem Abschnitt Theorie einen gleichermaßen korrekten Befehlssatz. Ich habe lange mit allen Implementierungen auf IAR ARM 8.30 und gcc 7.2.0 gearbeitet.Übung ist eine Schlampe
Das ist alles, wie es scheint, passiert. Die Speichereinsparungen wurden berechnet, die Implementierung ausgewählt und bereit, die Leistung zu verbessern. Nicht hier, es handelte sich nur um eine Divergenz von Theorie und Praxis. Und wann war es anders?
Ich hätte es nie veröffentlicht, wenn ich es nicht getestet hätte, aber wie viel realistisch ist das belegte Volumen bei Projekten reduziert. Ich habe dieses Makro speziell bei einigen alten Projekten durch eine reguläre Implementierung ohne Maske ersetzt und mir den Unterschied angesehen. Das Ergebnis überraschte unangenehm.
Wie sich herausstellte, bleibt die Lautstärke praktisch unverändert. Ich habe speziell Projekte ausgewählt, bei denen genau 40-50 solcher Anweisungen verwendet wurden. Nach der Theorie musste ich mindestens 100 Bytes und höchstens 200 Bytes gut einsparen. In der Praxis stellte sich heraus, dass der Unterschied 24 - 32 Bytes betrug. Aber warum?
Normalerweise richten Sie beim Einrichten von Peripheriegeräten fast hintereinander 5-10 Register ein. Und bei einem hohen Grad an Optimierung ordnet der Compiler die Anweisungen nicht genau in der Reihenfolge der Register an, sondern ordnet die Anweisungen so an, wie es richtig erscheint, und stört sie manchmal an scheinbar untrennbaren Stellen.
Ich sehe zwei Möglichkeiten (hier sind meine Spekulationen):
- Oder der Compiler ist so schlau, dass er für Sie weiß, wie es besser ist, den Befehlssatz zu optimieren
- Oder der Compiler ist immer noch nicht schlauer als eine Person und verwirrt sich, wenn er auf solche Konstruktionen stößt
Das heißt, es stellt sich heraus, dass diese Methode in „Hochsprachen“ mit einem hohen Optimierungsgrad nur dann korrekt funktioniert, wenn sich keine ähnlichen Operationen in der Nähe einer solchen Operation befinden.
Auf der O0-Ebene laufen Theorie und Praxis übrigens auf jeden Fall zusammen, aber diese Optimierung interessiert mich nicht.
Ich fasse zusammen
Ein negatives Ergebnis ist auch ein Ergebnis. Ich denke, jeder wird Schlussfolgerungen für sich ziehen. Persönlich werde ich diese Technik weiterhin anwenden, es wird sicherlich nicht schlimmer sein.
Ich hoffe, es war interessant und ich möchte denjenigen, die bis zum Ende gelesen haben, großen Respekt aussprechen.
Literaturliste
- "Technisches Referenzhandbuch für Cortex-M3", Abschnitt 4.2, ARM 2005.
- Der endgültige Leitfaden zum ARM Cortex-M3, Joseph Yiu.
PS Ich habe eine kleine Berichterstattung über Themen im Zusammenhang mit der Entwicklung eingebetteter Elektronik in meiner Tasche. Lassen Sie mich wissen, wenn Sie interessiert sind, werde ich sie langsam bekommen.
PPS Irgendwie stellte sich heraus, dass es schief war, Abschnitte des Codes einzufügen. Bitte sagen Sie mir, wie ich mich verbessern kann, wenn möglich. Im Allgemeinen können Sie einen Code von Interesse in den Notizblock kopieren und unangenehme Emotionen in der Analyse vermeiden.
UPD:
Auf Wunsch der Leser weise ich darauf hin, dass die Bitbanding-Operation selbst atomar ist, was uns eine gewisse Sicherheit bei der Arbeit mit Registern gibt. Dies ist eines der wichtigsten Merkmale dieser Methode.