
Hallo Habr! Ich präsentiere Ihnen die angepasste Übersetzung des ersten Kapitels von "
Node.js Best Practices " von Yoni Goldberg. Eine Auswahl von Empfehlungen auf Node.js ist auf github veröffentlicht, hat fast 30 Tonnen Sterne, wurde aber bisher auf Habré nicht erwähnt. Ich nehme an, dass diese Informationen zumindest für Anfänger nützlich sein werden.
1. Tipps zur Projektstruktur
1.1 Strukturieren Sie Ihr Projekt nach Komponenten
Der schlimmste Fehler großer Anwendungen ist die Monolith-Architektur in Form einer riesigen Codebasis mit einer großen Anzahl von Abhängigkeiten (Spaghetti-Code). Diese Struktur verlangsamt die Entwicklung erheblich, insbesondere die Einführung neuer Funktionen. Tipp - Trennen Sie Ihren Code in separate Komponenten. Wählen Sie für jede Komponente Ihren eigenen Ordner für die Komponentenmodule aus. Es ist wichtig, dass jedes Modul klein und einfach bleibt. Im Abschnitt "Details" sehen Sie Beispiele für die korrekte Struktur von Projekten.
Andernfalls ist es für Entwickler schwierig, das Produkt zu entwickeln. Das Hinzufügen neuer Funktionen und das Vornehmen von Änderungen am Code ist langsam und es besteht eine hohe Wahrscheinlichkeit, dass andere abhängige Komponenten beschädigt werden. Es wird angenommen, dass Probleme bei der Skalierung der Anwendung auftreten können, wenn die Geschäftsbereiche nicht aufgeteilt sind.
DetailsEin Absatz ErklärungFür Anwendungen mittlerer Größe und höher sind Monolithen wirklich schlecht - ein großes Programm mit vielen Abhängigkeiten ist einfach schwer zu verstehen und führt häufig zu Spaghetti-Code. Selbst erfahrene Programmierer, die wissen, wie man Module richtig „vorbereitet“, investieren viel Aufwand in die architektonische Gestaltung und versuchen, die Konsequenzen jeder Änderung der Beziehungen zwischen Objekten sorgfältig zu bewerten. Die beste Option ist eine Architektur, die auf einer Reihe kleiner Komponentenprogramme basiert: Teilen Sie das Programm in separate Komponenten auf, die ihre Dateien nicht für Dritte freigeben. Jede Komponente sollte aus einer kleinen Anzahl von Modulen bestehen (z. B. Module: API, Service, Datenbankzugriff, Testen usw.), so dass die Struktur und Zusammensetzung des Bauteils offensichtlich sind. Einige nennen diese Architektur möglicherweise "Microservice", aber es ist wichtig zu verstehen, dass Microservices keine Spezifikation sind, die Sie befolgen sollten, sondern eine Reihe einiger Prinzipien. Auf Ihren Wunsch können Sie sowohl einzelne dieser Prinzipien als auch alle Prinzipien der Microservice-Architektur übernehmen. Beide Methoden sind gut, wenn Sie die Codekomplexität gering halten.
Das Mindeste, was Sie tun müssen, ist, die Grenzen zwischen den Komponenten zu definieren: Weisen Sie jeder Komponente einen Ordner im Stammverzeichnis Ihres Projekts zu und machen Sie sie eigenständig. Der Zugriff auf die Komponentenfunktionalität sollte nur über eine öffentliche Schnittstelle oder API implementiert werden. Dies ist die Grundlage, um die Einfachheit Ihrer Komponenten zu erhalten, die „Hölle der Abhängigkeiten“ zu vermeiden und Ihre Anwendung zu einem vollwertigen Mikroservice werden zu lassen.
Zitat aus dem Blog: „Für die Skalierung muss die gesamte Anwendung skaliert werden.“Aus dem MartinFowler.com Blog
Monolithische Anwendungen können erfolgreich sein, aber die Leute sind zunehmend frustriert, insbesondere wenn sie über eine Bereitstellung in der Cloud nachdenken. Alle, auch kleinen Änderungen in der Anwendung erfordern die Montage und Neuverteilung des gesamten Monolithen. Es ist oft schwierig, ständig einen guten modularen Aufbau aufrechtzuerhalten, bei dem Änderungen in einem Modul andere nicht beeinflussen. Das Skalieren erfordert das Skalieren der gesamten Anwendung und nicht nur der einzelnen Teile. Dieser Ansatz erfordert natürlich mehr Aufwand.
Zitat aus dem Blog: "Worüber spricht die Architektur Ihrer Anwendung?"Aus dem
Onkel-Bob- Blog
... wenn Sie in der Bibliothek waren, dann repräsentieren Sie deren Architektur: den Haupteingang, Rezeptionstische, Lesesäle, Konferenzräume und viele Säle mit Bücherregalen. Die Architektur selbst wird sagen: Dieses Gebäude ist eine Bibliothek.
Worüber spricht die Architektur Ihrer Anwendung? Wenn Sie sich die Verzeichnisstruktur der obersten Ebene und die darin enthaltenen Moduldateien ansehen, heißt es: Ich bin ein Online-Shop, ich bin ein Buchhalter, ich bin ein Produktionsmanagementsystem? Oder schreien sie: Ich bin Rails, ich bin Spring / Hibernate, ich bin ASP?
(Anmerkung des Übersetzers, Rails, Spring / Hibernate, ASP sind Frameworks und Webtechnologien).
Richtige Projektstruktur mit autonomen Komponenten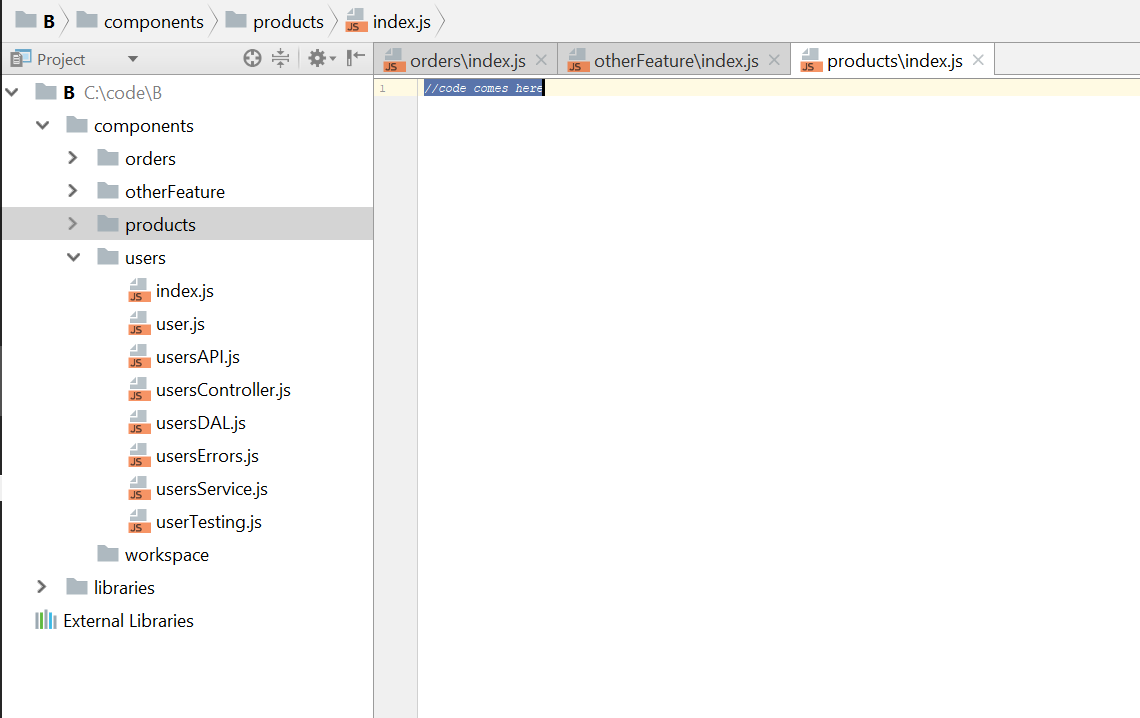 Falsche Projektstruktur mit Gruppierung von Dateien nach Zweck
Falsche Projektstruktur mit Gruppierung von Dateien nach Zweck
1.2 Trennen Sie die Ebenen Ihrer Komponenten und mischen Sie sie nicht mit der Express-Datenstruktur
Jede Ihrer Komponenten muss über „Ebenen“ verfügen, um beispielsweise mit dem Web, der Geschäftslogik und dem Zugriff auf die Datenbank arbeiten zu können. Diese Ebenen müssen über ein eigenes Datenformat verfügen, das nicht mit dem Datenformat von Bibliotheken von Drittanbietern gemischt ist. Dies trennt nicht nur die Probleme klar voneinander, sondern erleichtert auch die Überprüfung und Prüfung des Systems erheblich. Oft mischen API-Entwickler Ebenen, indem sie Express-Web-Layer-Objekte (wie z. B. req, res) an die Geschäftslogik- und Datenschicht übergeben. Dies macht Ihre Anwendung abhängig und in hohem Maße mit Express verbunden.
Andernfalls: Für eine Anwendung, in der Layer-Objekte gemischt werden, ist es schwieriger, Codetests, die Organisation von CRON-Aufgaben und andere Nicht-Express-Aufrufe bereitzustellen.
DetailsTeilen Sie den Komponentencode in Ebenen ein: Web, Services und DALDie Kehrseite mischt Ebenen in einer GIF-Animation
1.3 Wickeln Sie Ihre grundlegenden Dienstprogramme in npm-Pakete ein
In einer großen Anwendung, die aus verschiedenen Diensten mit eigenen Repositorys besteht, sollten universelle Dienstprogramme wie Logger, Verschlüsselung usw. mit Ihrem eigenen Code verpackt und als private npm-Pakete dargestellt werden. Auf diese Weise können Sie sie für mehrere Codebasen und Projekte freigeben.
Andernfalls: Sie müssen Ihr eigenes Fahrrad erfinden, um diesen Code zwischen verschiedenen Codebasen zu teilen.
DetailsEin Absatz ErklärungSobald das Projekt wächst und Sie verschiedene Komponenten auf verschiedenen Servern mit denselben Dienstprogrammen haben, sollten Sie mit der Verwaltung von Abhängigkeiten beginnen. Wie kann ich zulassen, dass mehrere Komponenten es verwenden, ohne den Code Ihres Dienstprogramms zwischen Repositorys zu duplizieren? Hierfür gibt es ein spezielles Tool, das npm heißt .... Beginnen Sie damit, Dienstprogrammpakete von Drittanbietern mit Ihrem eigenen Code zu versehen, damit Sie ihn in Zukunft problemlos ersetzen können, und veröffentlichen Sie diesen Code als privates npm-Paket. Jetzt kann Ihre gesamte Codebasis den Dienstprogrammcode importieren und alle Funktionen zur Verwaltung von npm-Abhängigkeiten verwenden. Beachten Sie, dass es folgende Möglichkeiten gibt, npm-Pakete für den persönlichen Gebrauch zu veröffentlichen, ohne sie für den öffentlichen Zugriff zu öffnen:
private Module , eine
private Registrierung oder
lokale npm-Pakete .
Freigeben Ihrer eigenen freigegebenen Dienstprogramme in verschiedenen Umgebungen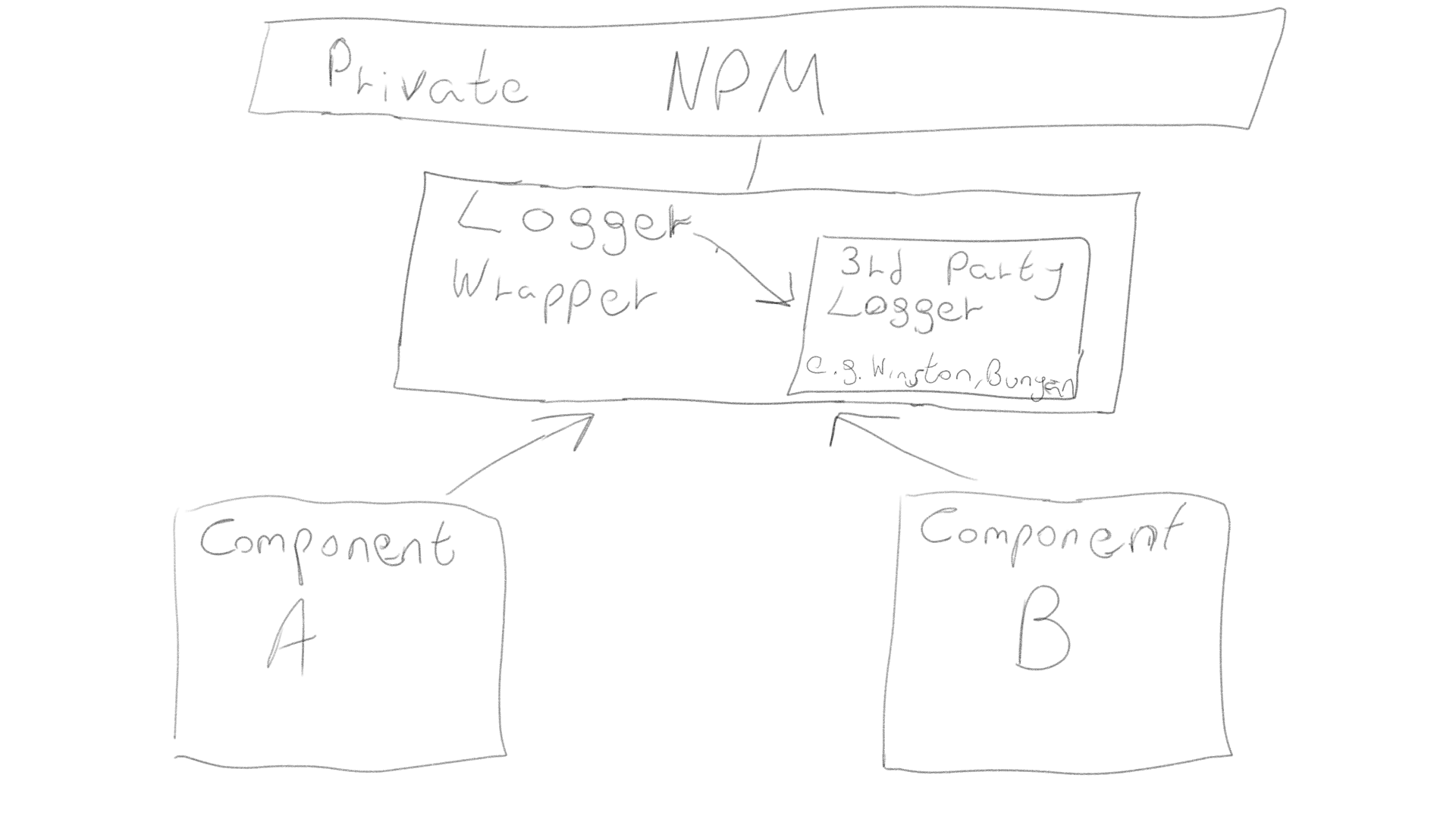
1.4 Trennen Sie Express in "Anwendung" und "Server"
Vermeiden Sie die unangenehme Angewohnheit, eine gesamte Express-Anwendung in einer großen Datei zu definieren, und teilen Sie Ihren Express-Code in mindestens zwei Dateien auf: eine API-Deklaration (app.js) und einen WWW-Servercode. Platzieren Sie für eine noch bessere Struktur eine API-Deklaration in den Komponentenmodulen.
Andernfalls: Ihre API steht nur zum Testen über HTTP-Aufrufe zur Verfügung (was langsamer und viel schwieriger zu erstellen ist, um Abdeckungsberichte zu erstellen). Trotzdem macht es nicht allzu viel Spaß, mit Hunderten von Codezeilen in einer Datei zu arbeiten.
DetailsEin Absatz ErklärungWir empfehlen die Verwendung des Express-Anwendungsgenerators und seines Ansatzes zum Erstellen der Anwendungsdatenbank: Die API-Deklaration ist von der Serverkonfiguration (Portdaten, Protokoll usw.) getrennt. Auf diese Weise können Sie die API testen, ohne Netzwerkaufrufe zu tätigen. Dies beschleunigt das Testen und erleichtert das Abrufen von Kennzahlen zur Codeabdeckung. Außerdem können Sie dieselbe API flexibel für verschiedene Servernetzwerkeinstellungen bereitstellen. Als Bonus erhalten Sie auch eine bessere Aufgabentrennung und einen saubereren Code.
Beispielcode: API-Deklaration, muss in app.js enthalten seinvar app = express(); app.use(bodyParser.json()); app.use("/api/events", events.API); app.use("/api/forms", forms);
Codebeispiel: Server-Netzwerkparameter sollten sich in / bin / www befinden var app = require('../app'); var http = require('http'); var port = normalizePort(process.env.PORT || '3000'); app.set('port', port); var server = http.createServer(app);
Beispiel: Testen unserer API mit Supertest (ein beliebtes Testpaket) const app = express(); app.get('/user', function(req, res) { res.status(200).json({ name: 'tobi' }); }); request(app) .get('/user') .expect('Content-Type', /json/) .expect('Content-Length', '15') .expect(200) .end(function(err, res) { if (err) throw err; });
1.5 Verwenden Sie eine sichere hierarchische Konfiguration basierend auf Umgebungsvariablen
Eine ideale Konfigurationseinstellung sollte Folgendes bieten:
(1) Lesen von Schlüsseln sowohl aus der Konfigurationsdatei als auch aus Umgebungsvariablen;
(2) Geheimhaltung außerhalb des Repository-Codes,
(3) hierarchische (statt flache) Datenstruktur der Konfigurationsdatei, um die Arbeit mit Einstellungen zu erleichtern.
Es gibt verschiedene Pakete, die bei der Implementierung dieser Punkte helfen können, z. B.: Rc, nconf und config.
Andernfalls: Die Nichteinhaltung dieser Konfigurationsanforderungen führt zu einer Unterbrechung der Arbeit eines einzelnen Entwicklers und des gesamten Teams.
DetailsEin Absatz ErklärungWenn Sie mit Konfigurationseinstellungen arbeiten, können viele Dinge ärgerlich sein und sich verlangsamen:
1. Das Festlegen aller Parameter mithilfe von Umgebungsvariablen wird sehr mühsam, wenn Sie mehr als 100 Schlüssel eingeben müssen (anstatt sie nur in der Konfigurationsdatei zu korrigieren). Wenn die Konfiguration jedoch nur in den Einstellungsdateien angegeben wird, kann dies für DevOps unpraktisch sein. Eine zuverlässige Konfigurationslösung sollte beide Methoden kombinieren: Sowohl Konfigurationsdateien als auch Parameterüberschreibungen von Umgebungsvariablen.
2. Wenn die Konfigurationsdatei "flach" JSON ist (dh alle Schlüssel werden als einzelne Liste geschrieben), ist es mit zunehmender Anzahl von Einstellungen schwierig, damit zu arbeiten. Dieses Problem kann gelöst werden, indem verschachtelte Strukturen gebildet werden, die Gruppen von Schlüsseln gemäß Einstellungsabschnitten enthalten, d.h. Organisieren Sie eine hierarchische JSON-Datenstruktur (siehe Beispiel unten). Es gibt Bibliotheken, mit denen Sie diese Konfiguration in mehreren Dateien speichern und die Daten zur Laufzeit daraus kombinieren können.
3. Es wird nicht empfohlen, vertrauliche Informationen (z. B. ein Datenbankkennwort) in Konfigurationsdateien zu speichern, aber es gibt keine eindeutige Lösung, wo und wie solche Informationen gespeichert werden sollen. In einigen Konfigurationsbibliotheken können Sie Konfigurationsdateien verschlüsseln, andere verschlüsseln diese Einträge bei Git-Commits oder Sie können geheime Parameter in Dateien speichern und deren Werte während der Bereitstellung über Umgebungsvariablen festlegen.
4. In einigen erweiterten Konfigurationsszenarien müssen Sie Schlüssel über die Befehlszeile (vargs) eingeben oder Konfigurationsdaten über einen zentralen Cache wie Redis synchronisieren, damit mehrere Server dieselben Daten verwenden.
Es gibt npm-Bibliotheken, die Ihnen bei der Umsetzung der meisten dieser Empfehlungen helfen. Wir empfehlen Ihnen, sich die folgenden Bibliotheken anzusehen:
rc ,
nconf und
config .
Codebeispiel: Die hierarchische Struktur hilft beim Auffinden von Datensätzen und beim Arbeiten mit umfangreichen Konfigurationsdateien
{ // Customer module configs "Customer": { "dbConfig": { "host": "localhost", "port": 5984, "dbName": "customers" }, "credit": { "initialLimit": 100, // Set low for development "initialDays": 1 } } }
(Anmerkung des Übersetzers: Kommentare können in der klassischen JSON-Datei nicht verwendet werden. Das obige Beispiel stammt aus der Dokumentation der Konfigurationsbibliothek, die Funktionen zum Vorab-Löschen von JSON-Dateien aus Kommentaren hinzufügt. Daher funktioniert das Beispiel recht gut, jedoch können Linters wie ESLint mit Standardeinstellungen verwendet werden "Schwöre" auf ein ähnliches Format).
Nachwort des Übersetzers:
- Die Beschreibung des Projekts besagt, dass die Übersetzung ins Russische bereits gestartet wurde, aber ich habe diese Übersetzung dort nicht gefunden, also habe ich den Artikel aufgegriffen.
- Wenn Ihnen die Übersetzung sehr kurz erscheint, versuchen Sie, die detaillierten Informationen in den einzelnen Abschnitten zu erweitern.
- Entschuldigung, dass die Abbildungen nicht übersetzt wurden.