Automatische Moderationssysteme werden in Webdiensten und Anwendungen implementiert, in denen eine große Anzahl von Benutzernachrichten verarbeitet werden muss. Solche Systeme können die Kosten für die manuelle Moderation senken, beschleunigen und alle Benutzernachrichten in Echtzeit verarbeiten. In dem Artikel werden wir über den Aufbau eines automatischen Moderationssystems für die Verarbeitung von Englisch unter Verwendung von Algorithmen für maschinelles Lernen sprechen. Wir werden die gesamte Pipeline-Arbeit von Forschungsaufgaben und der Auswahl von ML-Algorithmen bis zur Einführung in die Produktion diskutieren. Lassen Sie uns sehen, wo Sie nach vorgefertigten Datensätzen suchen und wie Sie selbst Daten für die Aufgabe sammeln können.
Vorbereitet mit Ira Stepanyuk ( id_step ), Data Scientist bei Poteha LabsAufgabenbeschreibung
Wir arbeiten mit aktiven Chats für mehrere Benutzer, bei denen jede Minute Kurznachrichten von Dutzenden von Benutzern in einem Chat eingehen können. Die Aufgabe besteht darin, toxische Nachrichten und Nachrichten mit obszönen Bemerkungen in Dialogen aus solchen Chats hervorzuheben. Aus Sicht des maschinellen Lernens handelt es sich um eine binäre Klassifizierungsaufgabe, bei der jede Nachricht einer der Klassen zugeordnet werden muss.
Um dieses Problem zu lösen, musste zunächst verstanden werden, was toxische Botschaften sind und was sie genau toxisch macht. Zu diesem Zweck haben wir uns eine große Anzahl typischer Benutzernachrichten im Internet angesehen. Hier sind einige Beispiele, die wir bereits in toxische und normale Nachrichten unterteilt haben.
Es ist ersichtlich, dass giftige Botschaften oft obszöne Wörter enthalten, dies ist jedoch keine Voraussetzung. Die Nachricht enthält möglicherweise keine unangemessenen Wörter, ist jedoch für jemanden anstößig (Beispiel (1)). Darüber hinaus enthalten toxische und normale Nachrichten manchmal dieselben Wörter, die in unterschiedlichen Kontexten verwendet werden - anstößig oder nicht (Beispiel (2)). Solche Nachrichten müssen auch unterscheiden können.
Nachdem wir verschiedene Botschaften studiert hatten, nannten wir für unser Moderationssystem solche Botschaften
giftig , die Aussagen mit obszönen, beleidigenden Ausdrücken oder Hass auf jemanden enthalten.
Daten
Daten öffnen
Einer der bekanntesten Moderationsdatensätze ist der Datensatz der Kaggle
Toxic Comment Classification Challenge . Ein Teil des Markups im Datensatz ist falsch: Beispielsweise können Nachrichten mit obszönen Wörtern als normal markiert werden. Aus diesem Grund können Sie nicht einfach an Kernel-Wettbewerben teilnehmen und einen gut funktionierenden Klassifizierungsalgorithmus erhalten. Sie müssen mehr mit den Daten arbeiten, herausfinden, welche Beispiele nicht ausreichen, und mit solchen Beispielen zusätzliche Daten hinzufügen.
Neben Wettbewerben gibt es mehrere wissenschaftliche Veröffentlichungen mit Links zu geeigneten Datensätzen (
Beispiel ), aber nicht alle können in kommerziellen Projekten verwendet werden. Meistens enthalten diese Datensätze Nachrichten aus dem sozialen Netzwerk Twitter, in dem Sie viele giftige Tweets finden. Darüber hinaus werden Daten von Twitter gesammelt, da bestimmte Hashtags zum Suchen und Markieren toxischer Benutzernachrichten verwendet werden können.
Manuelle Daten
Nachdem wir den Datensatz aus offenen Quellen gesammelt und das Grundmodell darauf trainiert hatten, wurde klar, dass offene Daten nicht ausreichen: Die Qualität des Modells ist nicht zufriedenstellend. Zusätzlich zu den offenen Daten zur Lösung des Problems stand uns eine nicht zugewiesene Auswahl von Nachrichten von einem Game Messenger mit einer großen Anzahl toxischer Nachrichten zur Verfügung.

Um diese Daten für ihre Aufgabe zu verwenden, mussten sie irgendwie beschriftet werden. Zu diesem Zeitpunkt gab es bereits einen ausgebildeten Basisklassifikator, den wir für die halbautomatische Markierung verwendeten. Nachdem wir alle Nachrichten durch das Modell geführt haben, haben wir die Toxizitätswahrscheinlichkeiten jeder Nachricht ermittelt und in absteigender Reihenfolge sortiert. Am Anfang dieser Liste wurden Nachrichten mit obszönen und beleidigenden Worten gesammelt. Am Ende gibt es im Gegenteil normale Benutzernachrichten. Daher konnten die meisten Daten (mit sehr großen und sehr kleinen Wahrscheinlichkeitswerten) nicht markiert, sondern sofort einer bestimmten Klasse zugeordnet werden. Es bleiben die Nachrichten zu markieren, die in die Mitte der Liste fielen, was manuell gemacht wurde.
Datenerweiterung
Oft sehen Sie in Datensätzen geänderte Nachrichten, bei denen der Klassifikator falsch ist, und die Person versteht ihre Bedeutung richtig.
Dies liegt daran, dass Benutzer Moderationssysteme anpassen und lernen, sie zu betrügen, sodass die Algorithmen Fehler bei toxischen Nachrichten machen und die Bedeutung für die Person klar bleibt. Was Benutzer jetzt tun:
- Tippfehler erzeugen: Sie sind dumm Arschloch, ficken Sie ,
- Ersetzen Sie alphabetische Zeichen durch Zahlen, die in der Beschreibung ähnlich sind: n1gga, b0ll0cks ,
- zusätzliche Leerzeichen einfügen: Idiot ,
- Leerzeichen zwischen Wörtern entfernen: dieyoustupid .
Um einen Klassifikator zu trainieren, der gegen solche Ersetzungen resistent ist, müssen Sie das tun, was Benutzer tun: Generieren Sie dieselben Änderungen in Nachrichten und fügen Sie sie dem Trainingssatz zu den Hauptdaten hinzu.
Im Allgemeinen ist dieser Kampf unvermeidlich: Benutzer werden immer versuchen, Schwachstellen und Hacks zu finden, und Moderatoren werden neue Algorithmen implementieren.
Beschreibung der Unteraufgaben
Wir standen vor Unteraufgaben zur Analyse von Nachrichten in zwei verschiedenen Modi:
- Online-Modus - Echtzeitanalyse von Nachrichten mit maximaler Antwortgeschwindigkeit;
- Offline-Modus - Analyse von Nachrichtenprotokollen und Zuordnung toxischer Dialoge.
Im Online-Modus verarbeiten wir jede Benutzernachricht und führen sie durch das Modell. Wenn die Nachricht giftig ist, verstecken Sie sie in der Chat-Oberfläche. Wenn sie normal ist, zeigen Sie sie an. In diesem Modus sollten alle Nachrichten sehr schnell verarbeitet werden: Das Modell sollte so schnell eine Antwort geben, dass die Struktur des Dialogs zwischen Benutzern nicht gestört wird.
Im Offline-Modus gibt es keine zeitlichen Beschränkungen für die Arbeit, und deshalb wollte ich das Modell mit der höchsten Qualität implementieren.
Online-Modus. Wörterbuchsuche
Unabhängig davon, welches Modell als nächstes ausgewählt wird, müssen wir Nachrichten mit obszönen Wörtern finden und filtern. Um dieses Teilproblem zu lösen, ist es am einfachsten, ein Wörterbuch mit ungültigen Wörtern und Ausdrücken zu erstellen, die nicht übersprungen werden können, und in jeder Nachricht nach solchen Wörtern zu suchen. Die Suche sollte schnell sein, daher passt der Suchalgorithmus für naive Teilzeichenfolgen für diese Zeit nicht. Ein geeigneter Algorithmus zum Finden einer Reihe von Wörtern in einer Zeichenfolge ist
der Aho-Korasik-Algorithmus . Aufgrund dieses Ansatzes ist es möglich, einige toxische Beispiele schnell zu identifizieren und Nachrichten zu blockieren, bevor sie an den Hauptalgorithmus übertragen werden. Mit dem ML-Algorithmus können Sie die Bedeutung von Nachrichten "verstehen" und die Qualität der Klassifizierung verbessern.
Online-Modus. Grundlegendes Modell des maschinellen Lernens
Für das Basismodell haben wir uns für einen Standardansatz für die Textklassifizierung entschieden: TF-IDF + klassischer Klassifizierungsalgorithmus. Wieder aus Geschwindigkeits- und Leistungsgründen.
TF-IDF ist ein statistisches Maß, mit dem Sie die wichtigsten Wörter für Text im Textkörper anhand von zwei Parametern bestimmen können: der Häufigkeit der Wörter in jedem Dokument und der Anzahl der Dokumente, die ein bestimmtes Wort enthalten (
hier ausführlicher). Nachdem wir für jedes Wort in der TF-IDF-Nachricht berechnet haben, erhalten wir eine Vektordarstellung dieser Nachricht.
TF-IDF kann sowohl für Wörter im Text als auch für n-Gramm-Wörter und -Zeichen berechnet werden. Eine solche Erweiterung funktioniert besser, da sie häufig vorkommende Phrasen und Wörter verarbeiten kann, die nicht im Trainingssatz enthalten sind (außerhalb des Wortschatzes).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
Beispiel für die Verwendung von TF-IDF für n-Gramm Wörter und ZeichenNach dem Konvertieren von Nachrichten in Vektoren können Sie eine beliebige klassische Methode zur Klassifizierung verwenden:
logistische Regression, SVM ,
zufällige Gesamtstruktur, Boosten .
Wir haben uns für die Verwendung der logistischen Regression für unsere Aufgabe entschieden, da dieses Modell im Vergleich zu anderen klassischen ML-Klassifikatoren eine höhere Geschwindigkeit bietet und Klassenwahrscheinlichkeiten vorhersagt, sodass Sie einen Klassifizierungsschwellenwert in der Produktion flexibel auswählen können.
Der mit TF-IDF und logistischer Regression erhaltene Algorithmus funktioniert schnell und definiert Nachrichten mit obszönen Wörtern und Ausdrücken gut, versteht jedoch nicht immer die Bedeutung. Beispielsweise fielen Nachrichten mit den Wörtern "
schwarz " und "
feministisch " häufig in die toxische Klasse. Ich wollte dieses Problem beheben und lernen, die Bedeutung von Nachrichten mit der nächsten Version des Klassifikators besser zu verstehen.
Offline-Modus
Um die Bedeutung von Nachrichten besser zu verstehen, können Sie neuronale Netzwerkalgorithmen verwenden:
- Einbettungen (Word2Vec, FastText)
- Neuronale Netze (CNN, RNN, LSTM)
- Neue vorgefertigte Modelle (ELMo, ULMFiT, BERT)
Wir werden einige dieser Algorithmen diskutieren und wie sie detaillierter verwendet werden können.
Word2Vec und FastText
Durch das Einbetten von Modellen können Sie Vektordarstellungen von Wörtern aus Texten abrufen. Es gibt
zwei Arten von Word2Vec : Skip-Gramm und CBOW (Continuous Bag of Words). In Skip-Gramm wird der Kontext durch das Wort vorhergesagt, in CBOW umgekehrt: Das Wort wird durch den Kontext vorhergesagt.
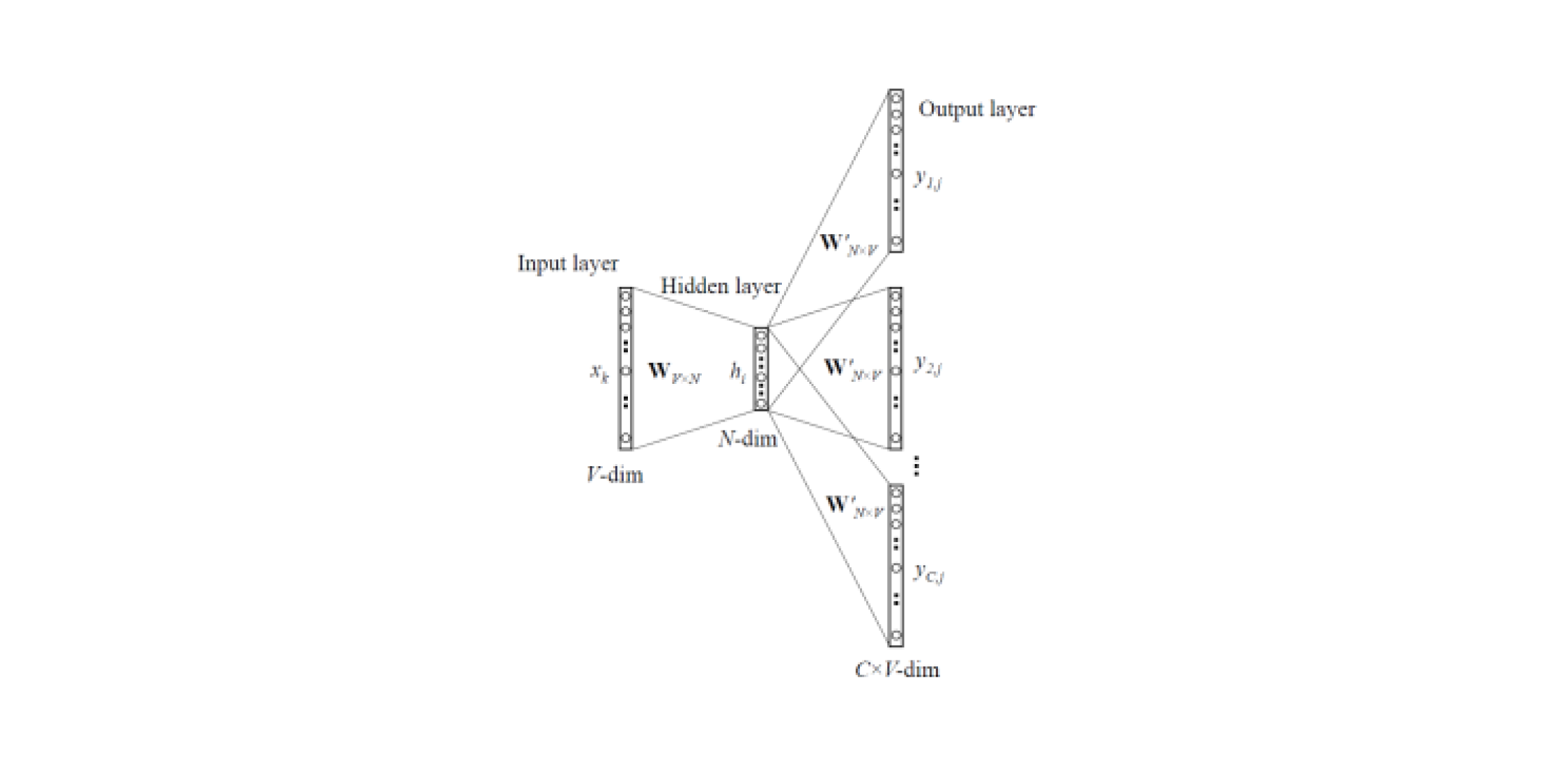
Solche Modelle werden auf großen Textkorps trainiert und ermöglichen es Ihnen, Vektordarstellungen von Wörtern aus einer verborgenen Schicht eines trainierten neuronalen Netzwerks zu erhalten. Der Nachteil dieser Architektur besteht darin, dass das Modell aus einer begrenzten Anzahl von Wörtern lernt, die im Korpus enthalten sind. Dies bedeutet, dass für alle Wörter, die sich in der Trainingsphase nicht im Textkörper befanden, keine Einbettungen vorgenommen werden. Und diese Situation tritt häufig auf, wenn vorab trainierte Modelle für ihre Aufgaben verwendet werden: Bei einigen Wörtern gibt es keine Einbettungen, dementsprechend geht eine große Menge nützlicher Informationen verloren.
Um das Problem mit Wörtern zu lösen, die nicht im Wörterbuch enthalten sind (OOV, außerhalb des Wortschatzes), gibt es ein verbessertes Einbettungsmodell -
FastText . Anstatt einzelne Wörter zum Trainieren des neuronalen Netzwerks zu verwenden, zerlegt FastText die Wörter in n-Gramm (Unterwörter) und lernt daraus. Um eine Vektordarstellung eines Wortes zu erhalten, müssen Sie Vektordarstellungen des n-Gramms dieses Wortes erhalten und diese hinzufügen.
Somit können vorab trainierte Word2Vec- und FastText-Modelle verwendet werden, um Merkmalsvektoren aus Nachrichten zu erhalten. Die erhaltenen Eigenschaften können unter Verwendung klassischer ML-Klassifikatoren oder eines vollständig verbundenen neuronalen Netzwerks klassifiziert werden.
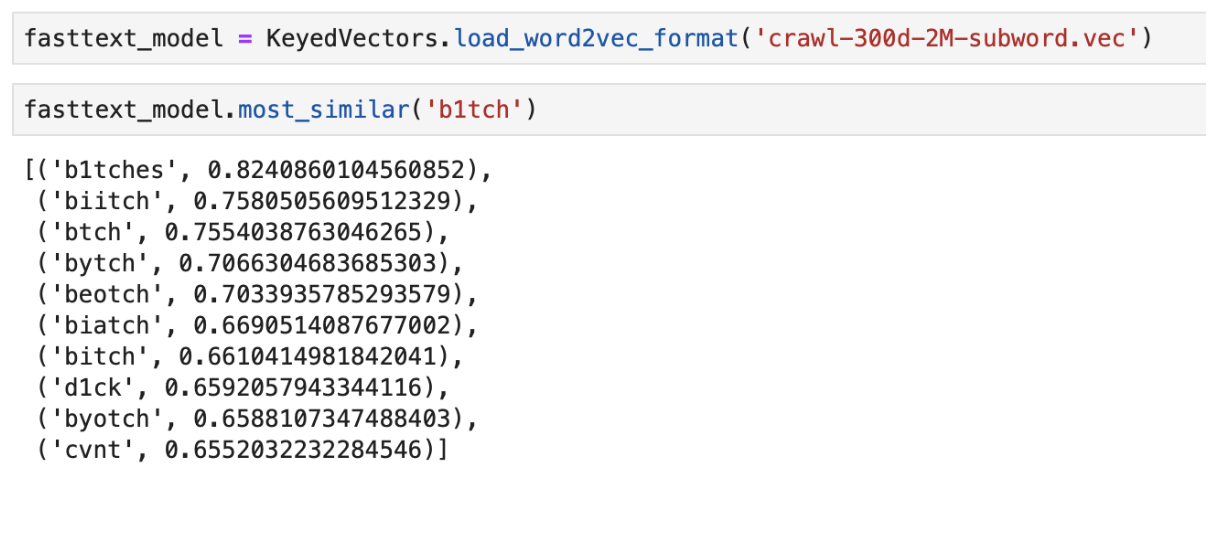 Ein Beispiel für die Ausgabe der Wörter "am nächsten" in der Bedeutung mit vorab trainiertem FastText
Ein Beispiel für die Ausgabe der Wörter "am nächsten" in der Bedeutung mit vorab trainiertem FastTextCNN-Klassifikator
Zur Verarbeitung und Klassifizierung von Texten aus neuronalen Netzwerkalgorithmen werden häufiger wiederkehrende Netzwerke (LSTM, GRU) verwendet, da sie gut mit Sequenzen funktionieren. Faltungsnetzwerke (CNNs) werden am häufigsten für die Bildverarbeitung verwendet,
können jedoch auch
für die Textklassifizierungsaufgabe verwendet werden. Überlegen Sie, wie dies getan werden kann.
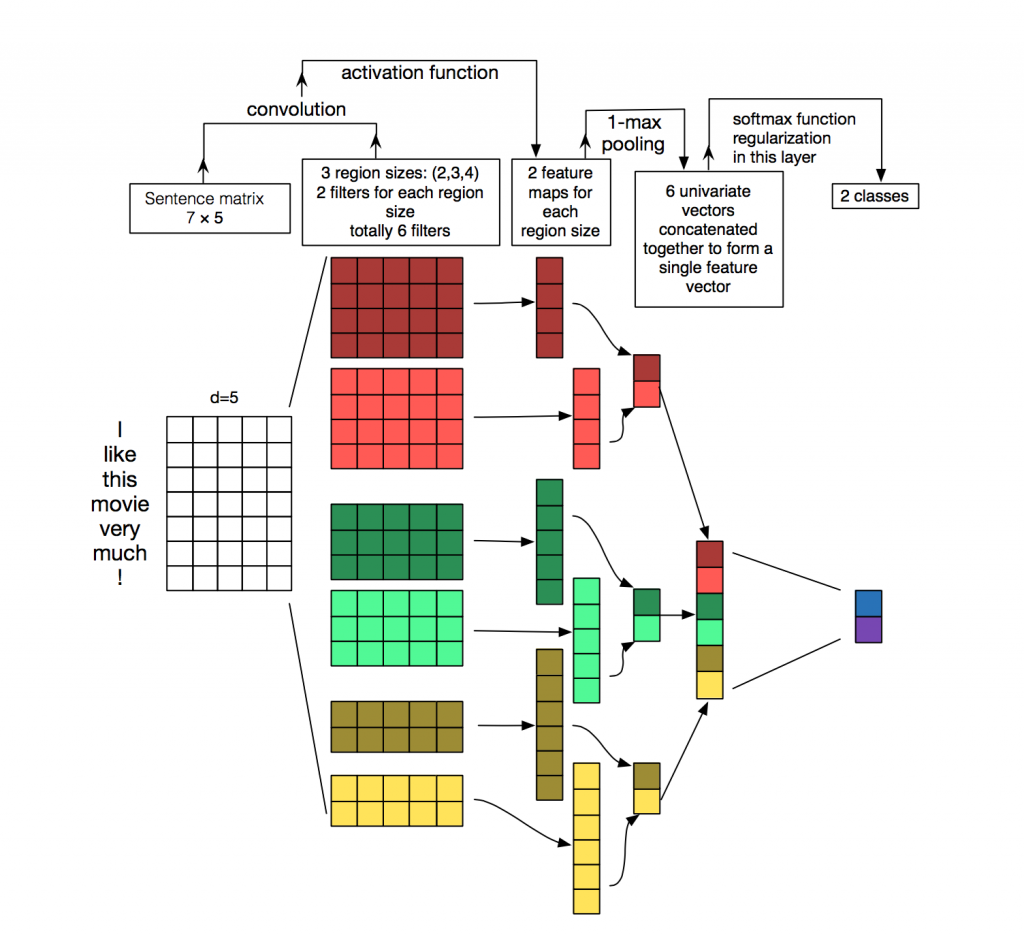
Jede Nachricht ist eine Matrix, in die in jede Zeile für das Token (Wort) seine Vektordarstellung geschrieben ist. Die Faltung wird auf eine bestimmte Weise auf eine solche Matrix angewendet: Der Faltungsfilter „gleitet“ über ganze Zeilen der Matrix (Wortvektoren), erfasst jedoch mehrere Wörter gleichzeitig (normalerweise 2 bis 5 Wörter) und verarbeitet so die Wörter im Kontext benachbarter Wörter. Details dazu finden Sie auf dem
Bild .
Warum Faltungsnetzwerke für die Textverarbeitung verwenden, wenn Sie wiederkehrende verwenden können? Tatsache ist, dass Windungen viel schneller arbeiten. Wenn Sie sie für die Klassifizierung von Nachrichten verwenden, können Sie beim Training erheblich Zeit sparen.
ELMo
ELMo (Einbettungen aus Sprachmodellen) ist ein Einbettungsmodell, das auf einem
kürzlich eingeführten Sprachmodell basiert. Das neue Einbettungsmodell unterscheidet sich von den Modellen Word2Vec und FastText. ELMo-Wortvektoren haben bestimmte Vorteile:
- Die Darstellung jedes Wortes hängt vom gesamten Kontext ab, in dem es verwendet wird.
- Die Darstellung basiert auf Symbolen, die die Bildung zuverlässiger Darstellungen für OOV-Wörter (außerhalb des Wortschatzes) ermöglichen.
ELMo kann für verschiedene Aufgaben in NLP verwendet werden. Für unsere Aufgabe können beispielsweise mit ELMo empfangene Nachrichtenvektoren an den klassischen ML-Klassifizierer gesendet werden oder ein Faltungsnetzwerk oder ein vollständig verbundenes Netzwerk verwenden.
Vorgefertigte Einbettungen von ELMo sind für Ihre Aufgabe recht einfach zu verwenden. Ein Beispiel für die Verwendung finden Sie
hier .
Implementierungsfunktionen
Kolben-API
Die Prototyp-API wurde in Flask geschrieben, da sie einfach zu verwenden ist.
Zwei Docker-Bilder
Für die Bereitstellung haben wir zwei Docker-Images verwendet: das Basis-Image, in dem alle Abhängigkeiten installiert wurden, und das Haupt-Image zum Starten der Anwendung. Dies spart erheblich Montagezeit, da das erste Image selten neu erstellt wird, und dies spart Zeit während der Bereitstellung. Es wird ziemlich viel Zeit für das Erstellen und Herunterladen von Bibliotheken für maschinelles Lernen aufgewendet, was nicht bei jedem Commit erforderlich ist.
Testen
Die Besonderheit der Implementierung einer relativ großen Anzahl von Algorithmen für maschinelles Lernen besteht darin, dass selbst bei hohen Metriken im Validierungsdatensatz die tatsächliche Qualität des Algorithmus in der Produktion gering sein kann. Um die Funktionsweise des Algorithmus zu testen, verwendete das gesamte Team den Bot in Slack. Dies ist sehr praktisch, da jedes Mitglied des Teams überprüfen kann, welche Antwort die Algorithmen auf eine bestimmte Nachricht geben. Mit dieser Testmethode können Sie sofort sehen, wie die Algorithmen mit Live-Daten funktionieren.
Eine gute Alternative ist die Einführung der Lösung auf öffentlichen Websites wie Yandex Toloka und AWS Mechanical Turk.
Fazit
Wir haben verschiedene Ansätze zur Lösung des Problems der automatischen Nachrichtenmoderation untersucht und die Merkmale unserer Implementierung beschrieben.
Die wichtigsten Beobachtungen während der Arbeit:
- Der Algorithmus für Wörterbuchsuche und maschinelles Lernen basierend auf TF-IDF und logistischer Regression ermöglichte die schnelle Klassifizierung von Nachrichten, jedoch nicht immer korrekt.
- Neuronale Netzwerkalgorithmen und vorab trainierte Einbettungsmodelle bewältigen diese Aufgabe besser und können die Toxizität im Sinne der Nachricht bestimmen.
Natürlich haben wir die offene Demo zur
Erkennung toxischer Kommentare von Poteha auf dem
Facebook- Bot veröffentlicht. Helfen Sie uns, den Bot besser zu machen!
Gerne beantworte ich Fragen in den Kommentaren.