
Einführung
Es ist Zeit, über Ausnahmen oder eher Ausnahmesituationen zu sprechen. Bevor wir beginnen, schauen wir uns die Definition an. Was ist eine Ausnahmesituation?
Dies ist eine Situation, die die Ausführung des aktuellen oder nachfolgenden Codes falsch macht. Ich meine anders als es entworfen oder beabsichtigt war. Eine solche Situation beeinträchtigt die Integrität einer Anwendung oder ihres Teils, z. B. eines Objekts. Es bringt die Anwendung in einen außergewöhnlichen oder außergewöhnlichen Zustand.
Aber warum müssen wir diese Terminologie definieren? Weil es uns in einigen Grenzen halten wird. Wenn wir uns nicht an die Terminologie halten, können wir zu weit von einem entworfenen Konzept entfernt sein, was zu vielen mehrdeutigen Situationen führen kann. Sehen wir uns einige praktische Beispiele an:
struct Number { public static Number Parse(string source) { // ... if(!parsed) { throw new ParsingException(); } // ... } public static bool TryParse(string source, out Number result) { // .. return parsed; } }
Dieses Beispiel scheint ein wenig seltsam, und das hat einen Grund. Ich habe diesen Code leicht künstlich gemacht, um die Wichtigkeit der darin auftretenden Probleme zu verdeutlichen. Schauen wir uns zunächst die Parse Methode an. Warum sollte es eine Ausnahme auslösen?
- Da der akzeptierte Parameter eine Zeichenfolge ist, ist seine Ausgabe eine Zahl, die ein Werttyp ist. Diese Zahl kann nicht die Gültigkeit von Berechnungen anzeigen: Sie existiert nur. Mit anderen Worten, das Verfahren hat keine Mittel in seiner Schnittstelle, um ein potentielles Problem zu kommunizieren.
- Andererseits erwartet die Methode eine korrekte Zeichenfolge, die eine Zahl und keine redundanten Zeichen enthält. Wenn es nicht enthält, gibt es ein Problem bei den Voraussetzungen für die Methode: Der Code, der unsere Methode aufruft, hat falsche Daten übergeben.
Daher ist die Situation, in der diese Methode eine Zeichenfolge mit falschen Daten erhält, außergewöhnlich, da die Methode weder einen korrekten Wert noch irgendetwas zurückgeben kann. Der einzige Weg ist also, eine Ausnahme auszulösen.
Die zweite Variante der Methode kann auf einige Probleme mit Eingabedaten hinweisen: Der Rückgabewert ist hier boolean was auf eine erfolgreiche Ausführung der Methode hinweist. Diese Methode muss keine Ausnahmen verwenden, um Probleme anzuzeigen: Sie werden alle durch den false Rückgabewert abgedeckt.
Übersicht
Die Behandlung von Ausnahmen sieht möglicherweise so einfach aus wie ABC: Wir müssen nur try-catch Blöcke platzieren und auf entsprechende Ereignisse warten. Diese Einfachheit wurde jedoch durch die enorme Arbeit der CLR- und CoreCLR-Teams möglich, die alle Fehler, die aus allen Richtungen und Quellen in die CLR kommen, vereinheitlichten. Um zu verstehen, worüber wir als nächstes sprechen werden, schauen wir uns ein Diagramm an:
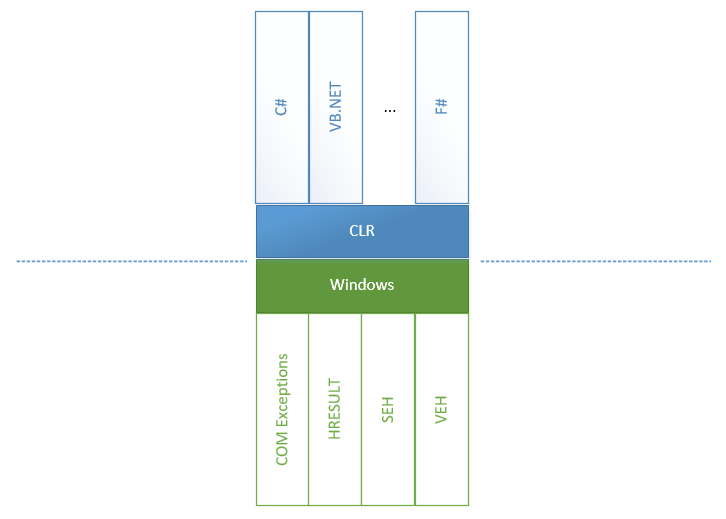
Wir können sehen, dass es in big .NET Framework zwei Welten gibt: alles, was zu CLR gehört, und alles, was nicht, einschließlich aller möglichen Fehler, die in Windows und anderen Teilen der unsicheren Welt auftreten.
- Die strukturierte Ausnahmebehandlung (SEH) ist eine Standardmethode, mit der Windows Ausnahmen behandelt. Wenn
unsafe Methoden aufgerufen und Ausnahmen ausgelöst werden, erfolgt die unsichere <-> CLR-Konvertierung von Ausnahmen in beide Richtungen: von unsicher zu CLR und rückwärts. Dies liegt daran, dass CLR eine unsichere Methode aufrufen kann, die wiederum eine CLR-Methode aufrufen kann. - Vectored Exception Handling (VEH) ist eine Wurzel von SEH und ermöglicht es Ihnen, Ihre Handler an Orten zu platzieren, an denen Ausnahmen ausgelöst werden können. Insbesondere wurde es zum Platzieren von
FirstChanceException . - COM + -Ausnahmen werden angezeigt, wenn die Ursache eines Problems eine COM-Komponente ist. In diesem Fall muss eine Ebene zwischen COM und einer .NET-Methode einen COM-Fehler in eine .NET-Ausnahme konvertieren.
- Und natürlich Wrapper für HRESULT. Sie werden eingeführt, um ein WinAPI-Modell (ein Fehlercode ist in einem Rückgabewert enthalten, während Rückgabewerte mithilfe von Methodenparametern erhalten werden) in ein Ausnahmemodell zu konvertieren, da dies eine Ausnahme ist, die für .NET Standard ist.
Andererseits gibt es Sprachen oberhalb der CLI, von denen jede mehr oder weniger Funktionen zur Behandlung von Ausnahmen hat. Beispielsweise verfügte VB.NET oder F # kürzlich über eine umfassendere Ausnahmebehandlungsfunktion, die in einer Reihe von Filtern ausgedrückt wurde, die in C # nicht vorhanden waren.
Rückkehrcodes vs. Ausnahme
Separat sollte ich ein Modell zur Behandlung von Anwendungsfehlern unter Verwendung von Rückkehrcodes erwähnen. Die Idee, einfach einen Fehler zurückzugeben, ist klar und deutlich. Wenn wir Ausnahmen als goto Operator behandeln, wird die Verwendung von Rückkehrcodes außerdem sinnvoller: In diesem Fall sieht der Benutzer einer Methode die Möglichkeit von Fehlern und kann verstehen, welche Fehler auftreten können. Lassen Sie uns jedoch nicht raten, was besser und wofür ist, sondern das Problem der Wahl anhand einer gut begründeten Theorie diskutieren.
Nehmen wir an, dass alle Methoden Schnittstellen haben, um Fehler zu behandeln. Dann würden alle Methoden so aussehen:
public bool TryParseInteger(string source, out int result); public DialogBoxResult OpenDialogBox(...); public WebServiceResult IWebService.GetClientsList(...); public class DialogBoxResult : ResultBase { ... } public class WebServiceResult : ResultBase { ... }
Und ihre Verwendung würde aussehen wie:
public ShowClientsResult ShowClients(string group) { if(!TryParseInteger(group, out var clientsGroupId)) return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed }; var webResult = _service.GetClientsList(clientsGroupId); if(!webResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult }; } var dialogResult = _dialogsService.OpenDialogBox(webResult.Result); if(!dialogResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult }; } return ShowClientsResult.Success(); }
Möglicherweise ist dieser Code mit der Fehlerbehandlung überladen. Ich möchte jedoch, dass Sie Ihre Position überdenken: Alles hier ist eine Emulation eines Mechanismus, der Ausnahmen auslöst und behandelt.
Wie kann eine Methode ein Problem melden? Dies kann mithilfe einer Schnittstelle zum Melden von Fehlern erfolgen. In der TryParseInteger Methode wird eine solche Schnittstelle beispielsweise durch einen Rückgabewert dargestellt: Wenn alles in Ordnung ist, gibt die Methode true . Wenn es nicht in Ordnung ist, wird false . Hier gibt es jedoch einen Nachteil: Der reale Wert wird über out int result . Der Nachteil ist, dass der Rückgabewert einerseits logisch ist und nach Wahrnehmung mehr "Rückgabewert" als der Parameter out . Andererseits kümmern wir uns nicht immer um Fehler. In der Tat, wenn eine Zeichenfolge für vorgesehen ist Die Analyse stammt von einem Dienst, der diese Zeichenfolge generiert hat. Wir müssen sie nicht auf Fehler überprüfen: Die Zeichenfolge ist immer korrekt und gut für die Analyse geeignet. Nehmen wir jedoch an, wir verwenden eine andere Implementierung der Methode:
public int ParseInt(string source);
Dann gibt es eine Frage: Wenn eine Zeichenfolge Fehler enthält, was sollte die Methode tun? Sollte es Null zurückgeben? Dies ist nicht korrekt: Die Zeichenfolge enthält keine Null. In diesem Fall liegt ein Interessenkonflikt vor: Die erste Variante enthält zu viel Code, während die zweite Variante keine Möglichkeit hat, Fehler zu melden. Es ist jedoch tatsächlich einfach zu entscheiden, wann Rückkehrcodes und wann Ausnahmen verwendet werden sollen.
Wenn es normal ist, einen Fehler zu erhalten, wählen Sie einen Rückkehrcode. Beispielsweise ist es normal, wenn ein Textanalyse-Algorithmus auf Fehler in einem Text stößt. Wenn jedoch ein anderer Algorithmus, der mit einer analysierten Zeichenfolge arbeitet, einen Fehler von einem Parser erhält, kann dies kritisch oder mit anderen Worten außergewöhnlich sein.
Versuchen Sie es kurz
Ein try Block deckt einen Abschnitt ab, in dem ein Programmierer eine kritische Situation erwartet, die von externem Code als Norm behandelt wird. Mit anderen Worten, wenn ein Code seinen internen Status aufgrund einiger Regeln als inkonsistent betrachtet und eine Ausnahme auslöst, kann ein externes System, das eine breitere Sicht auf dieselbe Situation hat, diese Ausnahme mithilfe eines catch Blocks catch und die Ausführung des Anwendungscodes normalisieren . Daher legalisieren Sie Ausnahmen in diesem Codeabschnitt, indem Sie sie abfangen . Ich denke, es ist eine wichtige Idee, die das Verbot rechtfertigt, alle try-catch(Exception ex){ ...} für alle Fälle zu try-catch(Exception ex){ ...} .
Es bedeutet nicht, dass das Fangen von Ausnahmen einer Ideologie widerspricht. Ich sage, dass Sie nur die Fehler abfangen sollten, die Sie von einem bestimmten Codeabschnitt erwarten. Beispielsweise können Sie nicht alle Arten von Ausnahmen erwarten, die von ArgumentException geerbt wurden, oder Sie können keine NullReferenceException , da dies häufig bedeutet, dass ein Problem eher in Ihrem Code als in einem aufgerufenen liegt. Es ist jedoch zu erwarten, dass Sie eine beabsichtigte Datei nicht öffnen können. Auch wenn Sie zu 200% sicher sind, dass Sie in der Lage sind, vergessen Sie nicht, dies zu überprüfen.
Der finally Block ist ebenfalls bekannt. Es ist für alle Fälle geeignet, die von try-catch Blöcken abgedeckt werden. Mit Ausnahme einiger seltener besonderer Situationen funktioniert dieser Block immer . Warum wurde eine solche Leistungsgarantie eingeführt? Bereinigen der Ressourcen und Gruppen von Objekten, die im try Block zugewiesen oder erfasst wurden und für die dieser Block verantwortlich ist.
Dieser Block wird häufig ohne catch Block verwendet, wenn es uns egal ist, welcher Fehler einen Algorithmus beschädigt hat, wir jedoch alle für diesen Algorithmus zugewiesenen Ressourcen bereinigen müssen. Schauen wir uns ein einfaches Beispiel an: Ein Algorithmus zum Kopieren von Dateien benötigt zwei geöffnete Dateien und einen Speicherbereich für einen Geldpuffer. Stellen Sie sich vor, wir haben Speicher zugewiesen und eine Datei geöffnet, aber keine andere. Um alles atomar in eine "Transaktion" zu packen, haben wir alle drei Operationen in einem einzigen try Block (als Variante der Implementierung) zusammengefasst, wobei die Ressourcen finally bereinigt wurden. Es mag wie ein vereinfachtes Beispiel erscheinen, aber das Wichtigste ist, das Wesentliche zu zeigen.
Was C # tatsächlich fehlt, ist ein fault , der aktiviert wird, wenn ein Fehler auftritt. Es ist wie finally auf Steroiden. Wenn wir dies hätten, könnten wir zum Beispiel einen einzelnen Einstiegspunkt erstellen, um Ausnahmesituationen zu protokollieren:
try { //... } fault exception { _logger.Warn(exception); }
Eine andere Sache, die ich in dieser Einführung ansprechen sollte, sind Ausnahmefilter. Es ist keine neue Funktion auf der .NET-Plattform, aber C # -Entwickler sind möglicherweise neu darin: Die Ausnahmefilterung wurde nur in Version 4 angezeigt. 6.0. Filter sollten eine Situation normalisieren, in der es einen einzigen Ausnahmetyp gibt, der mehrere Fehlertypen kombiniert. Es sollte uns helfen, wenn wir uns mit einem bestimmten Szenario befassen möchten, aber zuerst die gesamte Fehlergruppe erfassen und später filtern müssen. Natürlich meine ich den Code des folgenden Typs:
try { //... } catch (ParserException exception) { switch(exception.ErrorCode) { case ErrorCode.MissingModifier: // ... break; case ErrorCode.MissingBracket: // ... break; default: throw; } }
Nun können wir diesen Code jetzt richtig umschreiben:
try { //... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier) { // ... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket) { // ... }
Die Verbesserung liegt hier nicht im Fehlen eines switch . Ich glaube, dieses neue Konstrukt ist in mehreren Punkten besser:
when wir zum Filtern verwenden, fangen wir genau das, was wir wollen, und es ist ideologisch richtig.- Der Code wird in dieser neuen Form besser lesbar. Durch das Durchsuchen des Codes kann unser Gehirn Blöcke für die leichtere Behandlung von Fehlern identifizieren, da es zunächst nach dem
catch und nicht nach dem switch-case sucht. - das letzte aber nicht zuletzt: ein vorläufiger Vergleich ist VOR dem Betreten des Fangblocks. Dies bedeutet, dass dieses Konstrukt schneller funktioniert als ein
switch , wenn wir erneut eine Ausnahme auslösen, wenn wir falsche Vermutungen über mögliche Situationen anstellen.
Viele Quellen sagen, dass das Besondere an diesem Code ist, dass die Filterung vor dem Abrollen des Stapels erfolgt. Sie können dies in Situationen sehen, in denen keine anderen Anrufe als üblich zwischen dem Ort, an dem eine Ausnahme ausgelöst wird, und dem Ort, an dem die Filterprüfung erfolgt, stattfinden.
static void Main() { try { Foo(); } catch (Exception ex) when (Check(ex)) { ; } } static void Foo() { Boo(); } static void Boo() { throw new Exception("1"); } static bool Check(Exception ex) { return ex.Message == "1"; }
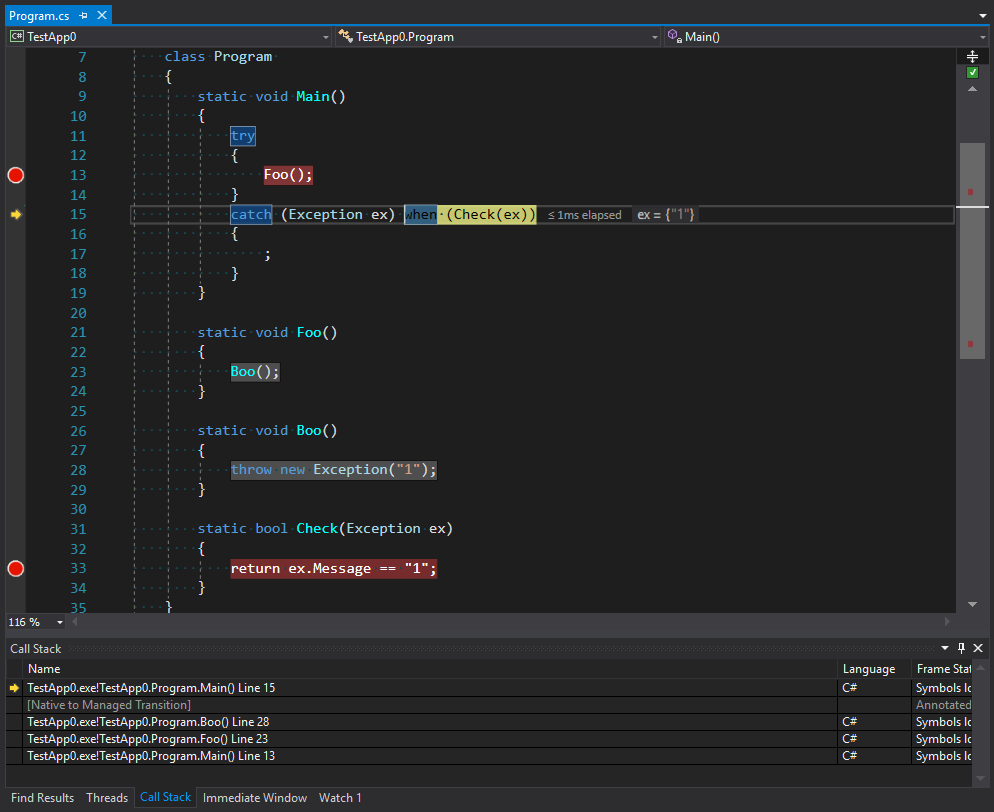
Sie können dem Bild entnehmen, dass die Stapelverfolgung nicht nur den ersten Aufruf von Main als Punkt zum Abfangen einer Ausnahme enthält, sondern den gesamten Stapel vor dem Auslösen einer Ausnahme sowie den zweiten, der über nicht verwalteten Code in Main eingeht. Wir können annehmen, dass dieser Code genau der Code zum Auslösen von Ausnahmen ist, der sich in der Phase des Filterns und Auswählens eines endgültigen Handlers befindet. Es können jedoch nicht alle Aufrufe verarbeitet werden, ohne dass der Stapel abgewickelt wird . Ich glaube, dass eine übermäßige Einheitlichkeit der Plattform zu viel Vertrauen in sie schafft. Wenn beispielsweise eine Domäne eine Methode von einer anderen Domäne aufruft, ist sie hinsichtlich des Codes absolut transparent. Die Art und Weise, wie Methoden Arbeit aufrufen, ist jedoch eine völlig andere Geschichte. Wir werden im nächsten Teil darüber sprechen.
Serialisierung
Beginnen wir mit den Ergebnissen der Ausführung des folgenden Codes (ich habe die Übertragung eines Anrufs über die Grenze zwischen zwei Anwendungsdomänen hinzugefügt).
class Program { static void Main() { try { ProxyRunner.Go(); } catch (Exception ex) when (Check(ex)) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { throw new Exception("1"); } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } } }
Wir können sehen, dass das Abrollen des Stapels erfolgt, bevor wir mit dem Filtern beginnen. Schauen wir uns Screenshots an. Die erste wird vor der Generierung einer Ausnahme erstellt:
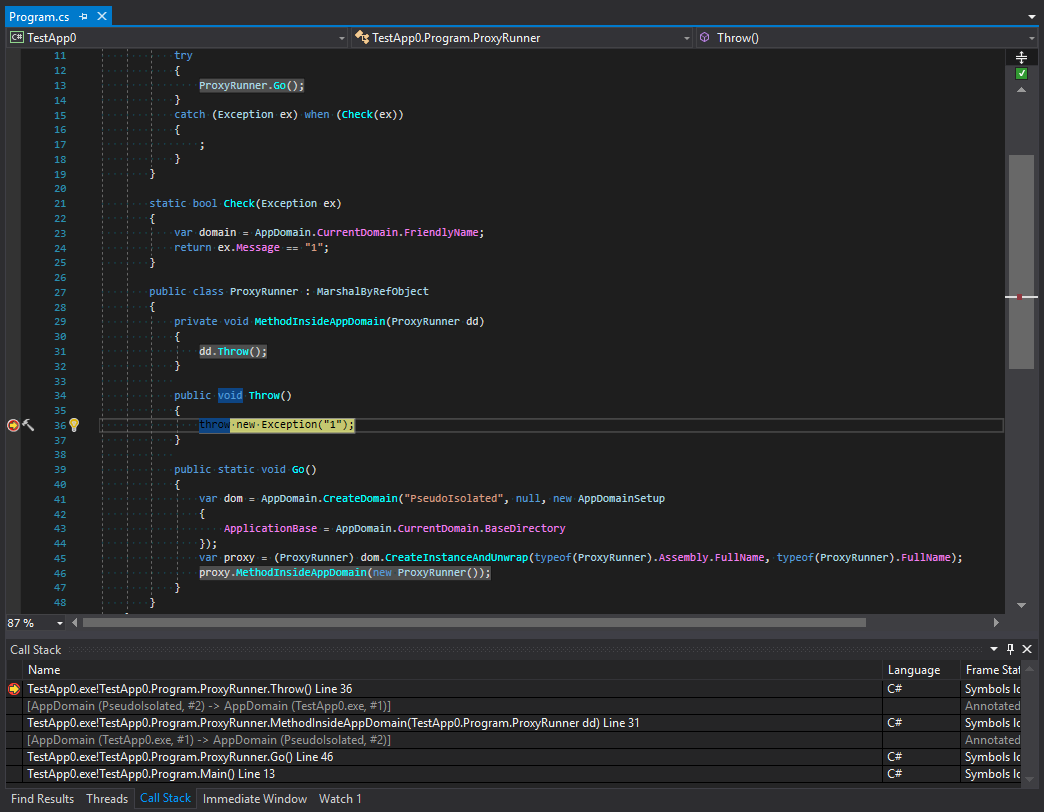
Der zweite ist danach:
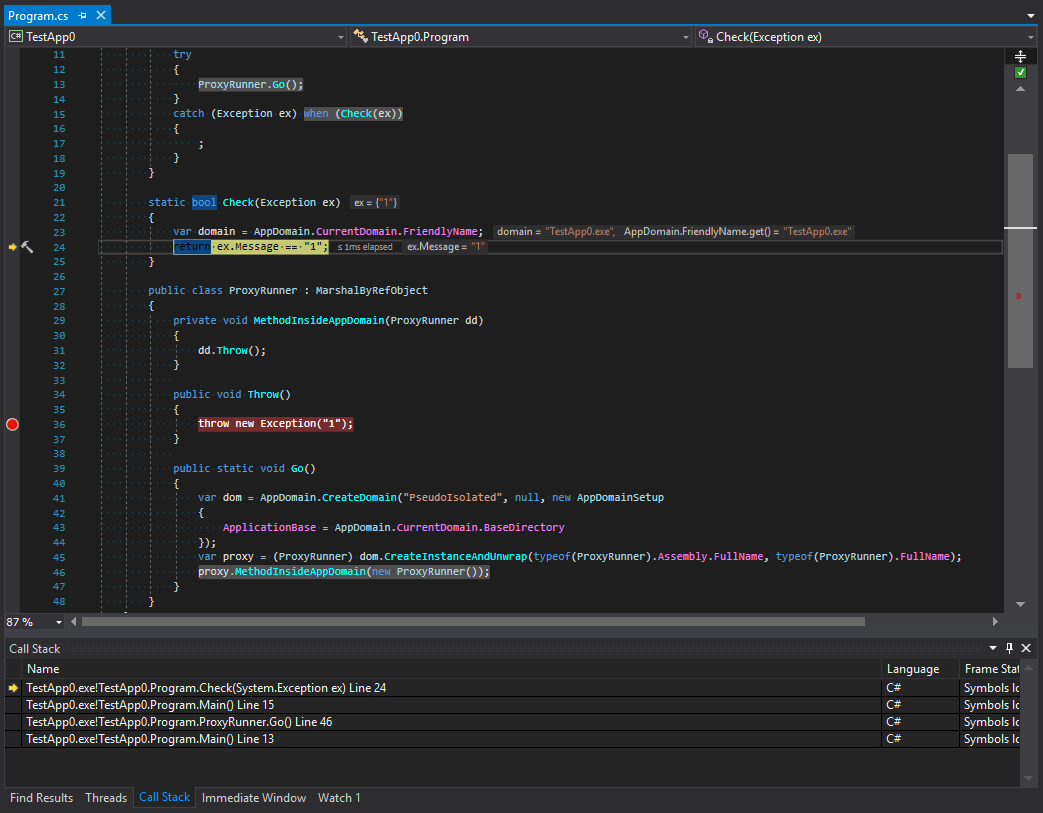
Lassen Sie uns die Anrufverfolgung untersuchen, bevor und nachdem Ausnahmen gefiltert werden. Was passiert hier? Wir können sehen, dass Plattformentwickler etwas gemacht haben, das auf den ersten Blick wie der Schutz einer Subdomain aussieht. Die Ablaufverfolgung wird nach der letzten Methode in der Aufrufkette unterbrochen, und dann erfolgt die Übertragung an eine andere Domäne. Aber ich finde das seltsam. Um zu verstehen, warum dies geschieht, erinnern wir uns an die Hauptregel für Typen, die die Interaktion zwischen Domänen organisieren. Diese Typen sollten MarshalByRefObject erben und serialisierbar sein. Trotz der Strenge von C # können Ausnahmetypen beliebiger Art sein. Was bedeutet das Dies bedeutet, dass Situationen auftreten können, in denen eine Ausnahme innerhalb einer Unterdomäne in einer übergeordneten Domäne abgefangen werden kann. Wenn ein Datenobjekt, das in eine Ausnahmesituation geraten kann, über einige Methoden verfügt, die hinsichtlich der Sicherheit gefährlich sind, können sie in einer übergeordneten Domäne aufgerufen werden. Um dies zu vermeiden, wird die Ausnahme zuerst serialisiert und überschreitet dann die Grenze zwischen Anwendungsdomänen und wird erneut mit einem neuen Stapel angezeigt. Lassen Sie uns diese Theorie überprüfen:
[StructLayout(LayoutKind.Explicit)] class Cast { [FieldOffset(0)] public Exception Exception; [FieldOffset(0)] public object obj; } static void Main() { try { ProxyRunner.Go(); Console.ReadKey(); } catch (RuntimeWrappedException ex) when (ex.WrappedException is Program) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { var x = new Cast {obj = new Program()}; throw x.Exception; } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } }
Da C # -Code eine Ausnahme von jedem Typ auslösen kann (ich möchte Sie nicht mit MSIL quälen), habe ich in diesem Beispiel einen Trick ausgeführt, bei dem ein Typ in einen nicht vergleichbaren Typ umgewandelt wurde, sodass wir eine Ausnahme von jedem Typ außer dem Übersetzer auslösen können würde denken, dass wir den Exception verwenden. Wir erstellen eine Instanz des Program , die mit Sicherheit nicht serialisierbar ist, und lösen eine Ausnahme aus, indem wir diesen Typ als Workload verwenden. Die gute Nachricht ist, dass Sie einen Wrapper für Nicht-Ausnahme-Ausnahmen von RuntimeWrappedException dem eine Instanz unseres Program Objekts RuntimeWrappedException wird und wir diese Ausnahme abfangen können. Es gibt jedoch schlechte Nachrichten, die unsere Idee unterstützen: Aufruf von proxy.MethodInsideAppDomain(); generiert eine SerializationException :
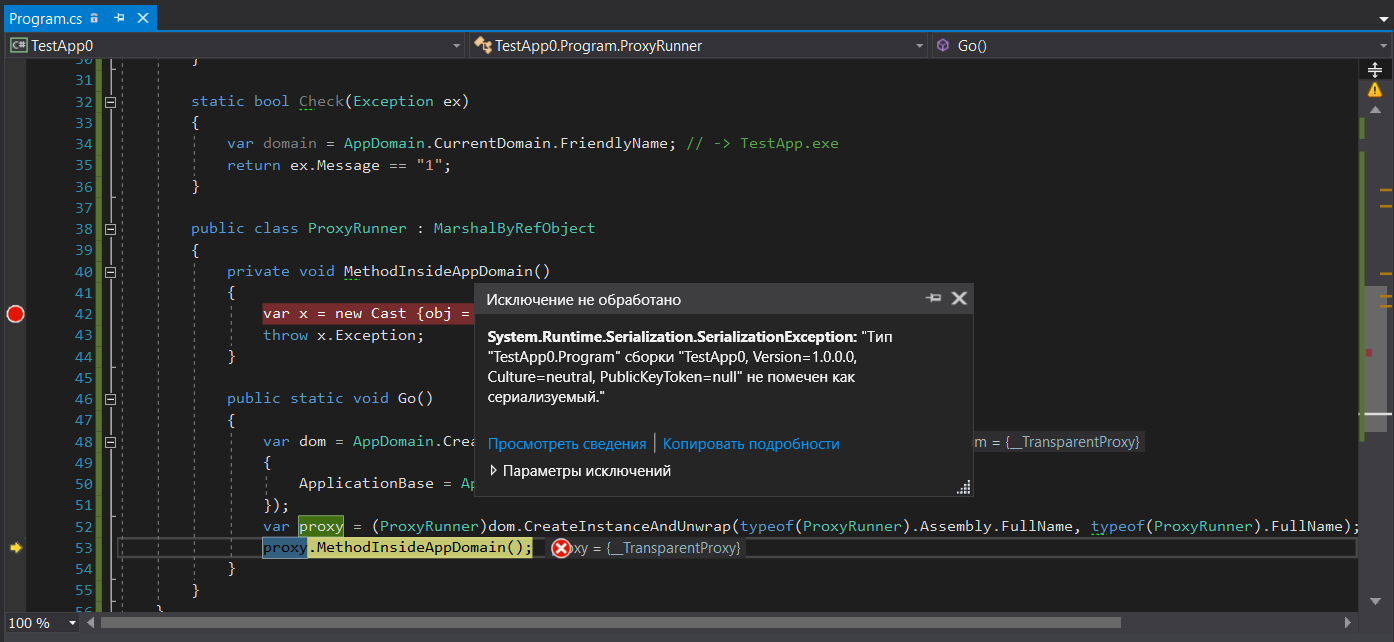
Daher können Sie eine solche Ausnahme nicht zwischen Domänen übertragen, da eine Serialisierung nicht möglich ist. Dies bedeutet wiederum, dass die Verwendung von Ausnahmefiltern zum Umschließen von Methodenaufrufen in anderen Domänen ohnehin zum Abrollen des Stapels führt, obwohl die Serialisierung mit den FullTrust Einstellungen einer Subdomäne nicht FullTrust zu sein scheint.
Wir sollten dem Grund, warum eine Serialisierung zwischen Domänen so notwendig ist, zusätzliche Aufmerksamkeit widmen. In unserem künstlichen Beispiel erstellen wir eine Subdomain, die keine Einstellungen hat. Dies bedeutet, dass es auf FullTrust-Weise funktioniert. CLR vertraut voll und ganz seinem Inhalt und führt keine zusätzlichen Überprüfungen durch. Wenn Sie jedoch mindestens eine Sicherheitseinstellung einfügen, verschwindet die volle Vertrauenswürdigkeit und CLR steuert alles, was in einer Subdomain geschieht. Wenn Sie also eine vollständig vertrauenswürdige Domain haben, benötigen Sie keine Serialisierung. Gib zu, wir müssen uns nicht schützen. Serialisierung existiert aber nicht nur zum Schutz. Jede Domäne lädt alle erforderlichen Assemblys ein zweites Mal und erstellt ihre Kopien. Auf diese Weise werden Kopien aller Typen und aller VMTs erstellt. Wenn Sie ein Objekt von Domäne zu Domäne übergeben, erhalten Sie natürlich dasselbe Objekt. Die VMTs sind jedoch keine eigenen und dieses Objekt kann nicht in einen anderen Typ umgewandelt werden. Mit anderen Worten, wenn wir eine Instanz eines Boo Typs erstellen und in einer anderen Domäne (Boo)boo , funktioniert das Casting von (Boo)boo nicht. In diesem Fall wird das Problem durch Serialisierung und Deserialisierung gelöst, da das Objekt gleichzeitig in zwei Domänen vorhanden ist. Es wird mit all seinen Daten vorhanden sein, in denen es erstellt wurde, und es wird im Verwendungsbereich als Proxy-Objekt vorhanden sein, um sicherzustellen, dass Methoden eines ursprünglichen Objekts aufgerufen werden.
Durch das Übertragen eines serialisierten Objekts zwischen Domänen erhalten Sie eine vollständige Kopie des Objekts von einer Domäne in eine andere, während Sie einige Abgrenzungen im Speicher behalten. Diese Abgrenzung ist jedoch fiktiv. Es wird nur für Typen verwendet, die nicht in Shared AppDomain . Wenn Sie also ausnahmsweise etwas nicht serialisierbares Shared AppDomain , aber von Shared AppDomain , wird kein Serialisierungsfehler Shared AppDomain (wir können versuchen, Action anstelle von Program Shared AppDomain ). In diesem Fall kommt es jedoch trotzdem zum Abrollen des Stapels: Beide Varianten sollten standardmäßig funktionieren. Damit niemand verwirrt wird.
 Dieses Kapitel wurde vom Autor und von professionellen Übersetzern gemeinsam aus dem Russischen übersetzt . Sie können uns bei der Übersetzung von Russisch oder Englisch in eine andere Sprache helfen, hauptsächlich ins Chinesische oder Deutsche.
Dieses Kapitel wurde vom Autor und von professionellen Übersetzern gemeinsam aus dem Russischen übersetzt . Sie können uns bei der Übersetzung von Russisch oder Englisch in eine andere Sprache helfen, hauptsächlich ins Chinesische oder Deutsche.
Wenn Sie sich bei uns bedanken möchten, können Sie dies am besten tun, indem Sie uns einen Stern auf Github geben oder das Repository teilen  github / sidristij / dotnetbook .
github / sidristij / dotnetbook .