Hallo! Mein Name ist Vadim Madison, ich leite die Entwicklung der Systemplattform Avito. Wie wir im Unternehmen von der monolithischen Architektur zur Microservice-Architektur übergehen, wurde mehr als einmal gesagt. Es ist Zeit zu teilen, wie wir unsere Infrastruktur verändert haben, um das Beste aus Microservices herauszuholen und uns nicht in ihnen zu verlieren. Wie PaaS uns hier hilft, wie wir die Bereitstellung vereinfacht und die Erstellung eines Microservices auf einen Klick reduziert haben - lesen Sie weiter. Nicht alles, was ich unten schreibe, ist vollständig in Avito implementiert. Ein Teil davon ist, wie wir unsere Plattform entwickeln.
(Und am Ende dieses Artikels werde ich über die Möglichkeit sprechen, ein dreitägiges Seminar von einem Experten für Mikroservice-Architektur, Chris Richardson, zu besuchen.)

Wie wir zu Microservices kamen
Avito ist eine der größten Kleinanzeigen der Welt und veröffentlicht täglich mehr als 15 Millionen neue Anzeigen. Unser Backend akzeptiert mehr als 20.000 Anfragen pro Sekunde. Jetzt haben wir mehrere hundert Microservices.
Wir bauen seit mehreren Jahren eine Microservice-Architektur. Wie genau - unsere Kollegen sprachen ausführlich in unserem Abschnitt über RIT ++ 2017. Auf dem CodeFest 2017 (siehe Video ) erklärten Sergey Orlov und Mikhail Prokopchuk ausführlich, warum wir den Übergang zu Microservices brauchten und welche Rolle Kubernetes hier spielte. Nun tun wir alles, um die Skalierungskosten zu minimieren, die einer solchen Architektur inhärent sind.
Anfangs haben wir kein Ökosystem geschaffen, das uns bei der Entwicklung und Einführung von Mikrodiensten umfassend helfen würde. Sie sammelten einfach sinnvolle Open-Source-Lösungen, starteten sie zu Hause und schlugen dem Entwickler vor, sich mit ihnen zu befassen. Infolgedessen ging er zu einem Dutzend Orten (Dashboards, interne Dienste), wonach er stärker in dem Wunsch wurde, den Code auf die alte Art und Weise in einem Monolithen zu schneiden. Die grüne Farbe in den folgenden Diagrammen zeigt an, was der Entwickler auf die eine oder andere Weise mit seinen eigenen Händen tut, die gelbe Farbe zeigt die Automatisierung an.
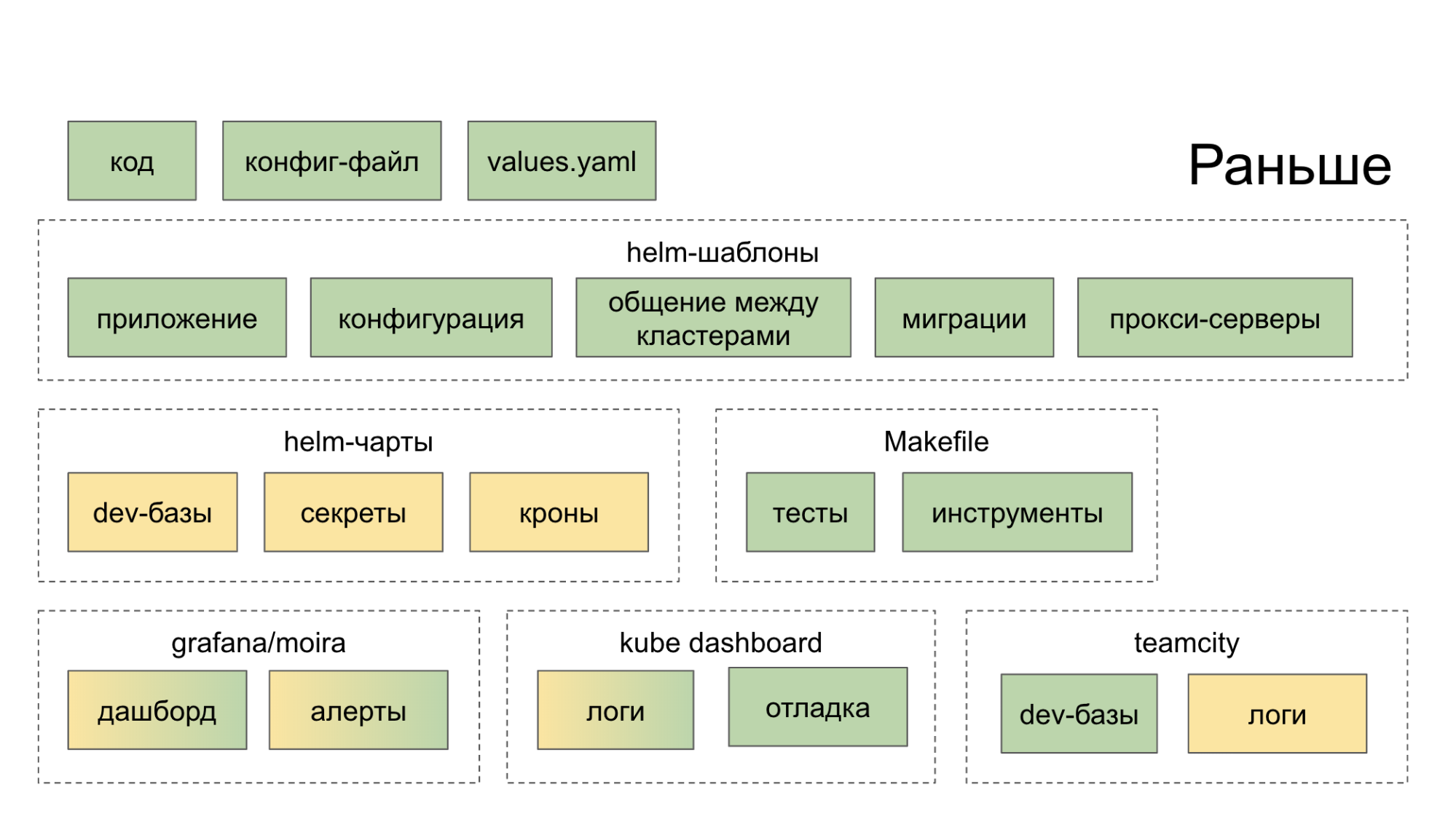
Jetzt erstellt ein Team im PaaS CLI-Dienstprogramm einen neuen Dienst, und zwei weitere fügen eine neue Datenbank hinzu und stellen sie für Stage bereit.
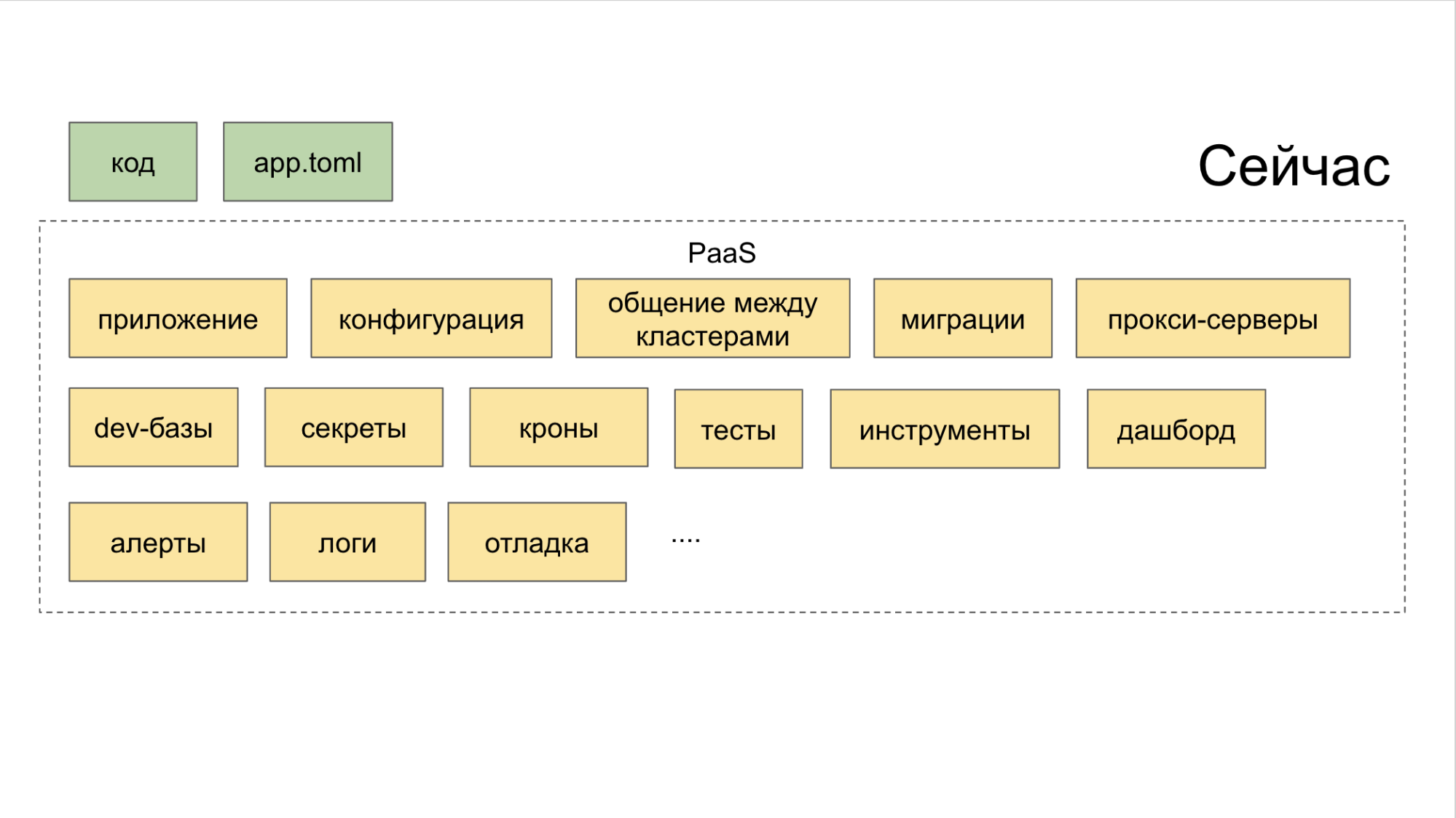
Wie man die Ära der "Microservice-Fragmentierung" überwindet
Bei einer monolithischen Architektur mussten Entwickler aus Gründen der Konsistenz der Produktänderungen herausfinden, was mit ihren Nachbarn geschah. Bei der Arbeit an der neuen Architektur hängen Servicekontexte nicht mehr voneinander ab.
Darüber hinaus müssen viele Prozesse eingerichtet werden, damit die Microservice-Architektur effektiv ist, nämlich:
• Protokollierung;
• Abfrageverfolgung (Jaeger);
• Fehleraggregation (Sentry);
• Status, Nachrichten, Ereignisse von Kubernetes (Event Stream Processing);
• Race Limit / Leistungsschalter (Sie können Hystrix verwenden);
• Kontrolle der Servicekonnektivität (wir verwenden Netramesh);
• Überwachung (Grafana);
• Montage (TeamCity);
• Kommunikation und Benachrichtigung (Slack, E-Mail);
• Aufgabenverfolgung; (Jira)
• Zusammenstellung von Dokumentationen.
Damit das System skaliert, seine Integrität nicht verliert und effektiv bleibt, haben wir die Organisation der Arbeit von Microservices in Avito überdacht.
Wie wir mit Microservices umgehen
Die Durchführung einer einheitlichen „Parteipolitik“ unter den vielen Mikrodiensten, die Avito anbietet, hilft:
- Aufteilung der Infrastruktur in Schichten;
- Platform as a Service (PaaS) -Konzept;
- Überwachung von allem, was mit Microservices passiert.
Infrastrukturabstraktionsschichten umfassen drei Schichten. Gehen wir von oben nach unten.
A. Oberes Netz. Zuerst haben wir Istio ausprobiert, aber es stellte sich heraus, dass es zu viele Ressourcen verbraucht, was für unsere Volumes zu teuer ist. Aus diesem Grund hat der leitende Ingenieur des Architekturteams Alexander Lukyanchenko seine eigene Lösung entwickelt - Netramesh (verfügbar auf Open Source), die wir jetzt in der Produktion verwenden und die um ein Vielfaches weniger Ressourcen verbraucht als Istio (aber nicht alles tut, was Istio vorweisen kann).
B. Medium - Kubernetes. Darauf setzen wir Microservices ein und betreiben sie.
C. Unteres blankes Metall. Wir verwenden keine Wolken und Dinge wie OpenStack, sondern sitzen komplett auf Bare Metal.
Alle Schichten werden von PaaS kombiniert. Und diese Plattform besteht wiederum aus drei Teilen.
I. Generatoren, die über das CLI-Dienstprogramm gesteuert werden. Sie hilft dem Entwickler, einen Microservice auf die richtige Art und Weise und mit minimalem Aufwand zu erstellen.
II. Kombinierter Kollektor mit Steuerung aller Werkzeuge über ein gemeinsames Dashboard.
III. Repository . Es stört Planer, die automatisch Auslöser für wichtige Aktionen setzen. Dank eines solchen Systems wird keine einzige Aufgabe übersehen, nur weil jemand vergessen hat, eine Aufgabe in Jira zu stellen. Wir verwenden hierfür ein internes Tool namens Atlas.

Die Implementierung von Microservices in Avito erfolgt ebenfalls nach einem einzigen Schema, das die Kontrolle über diese Services in jeder Phase der Entwicklung und Veröffentlichung vereinfacht.
Funktionsweise der Standard-Microservice-Entwicklungspipeline
Im Allgemeinen lautet die Erstellungskette für Mikroservices wie folgt:
CLI-Push → Kontinuierliche Integration → Backen → Bereitstellen → Künstliche Tests → Kanarische Tests → Quetschtests → Produktion → Service.
Wir gehen es genau in dieser Reihenfolge durch.
CLI-Push
• Erstellen eines Microservices .
Wir hatten lange Mühe, jedem Entwickler beizubringen, wie man Microservices herstellt. Einschließlich in Confluence geschriebene detaillierte Anweisungen. Aber die Regelungen haben sich geändert und ergänzt. Fazit - ein Engpass, der sich zu Beginn der Reise gebildet hat: Das Starten von Microservices dauerte viel länger als zulässig, und dennoch traten bei der Erstellung häufig Probleme auf.
Am Ende haben wir ein einfaches CLI-Dienstprogramm erstellt, das die grundlegenden Schritte beim Erstellen eines Microservices automatisiert. Tatsächlich ersetzt es den ersten Git-Push. Das macht sie.
- Erstellt einen Dienst gemäß der Vorlage - Schritt für Schritt im "Assistenten" -Modus. Wir haben Vorlagen für die wichtigsten Programmiersprachen im Avito-Backend: PHP, Golang und Python.
- Mit einem Befehl wird die Umgebung für die lokale Entwicklung auf einem bestimmten Computer bereitgestellt. - Minikube steigt, Helm-Diagramme werden automatisch generiert und in lokalen Kubernetzen gestartet.
- Verbindet die gewünschte Datenbank. Der Entwickler muss die IP-Adresse, das Login und das Passwort nicht kennen, um auf die von ihm benötigte Datenbank zugreifen zu können - zumindest lokal, zumindest in Stage, zumindest in der Produktion. Darüber hinaus wird die Datenbank sofort in einer fehlertoleranten Konfiguration und mit Ausgleich bereitgestellt.
- Es selbst führt eine Live-Montage durch. Angenommen, ein Entwickler hat über seine IDE etwas in einem Microservice behoben. Das Dienstprogramm erkennt die Änderungen im Dateisystem und setzt darauf basierend die Anwendung (für Golang) wieder zusammen und startet neu. Für PHP leiten wir einfach das Verzeichnis innerhalb des Cubes weiter und dort wird das Live-Reload "automatisch" erhalten.
- Erzeugt Autotests. In Form von Scheiben, aber durchaus einsatzbereit.
• Stellen Sie den Microservice bereit .
Es war ein bisschen trostlos, vorher einen Microservice bereitzustellen. Obligatorisch erforderlich:
I. Dockerfile.
II. Konfig.
III. Eine Helmkarte, die selbst sperrig ist und Folgendes enthält:
- die Diagramme selbst;
- Vorlagen;
- spezifische Werte unter Berücksichtigung unterschiedlicher Umgebungen.
Wir haben den Schmerz beseitigt, Kubernetes-Manifeste zu wiederholen, und jetzt werden sie automatisch generiert. Vor allem aber vereinfachten sie die Bereitstellung bis an die Grenzen. Von nun an haben wir eine Docker-Datei und der Entwickler schreibt die gesamte Konfiguration in eine einzige kurze app.toml-Datei.
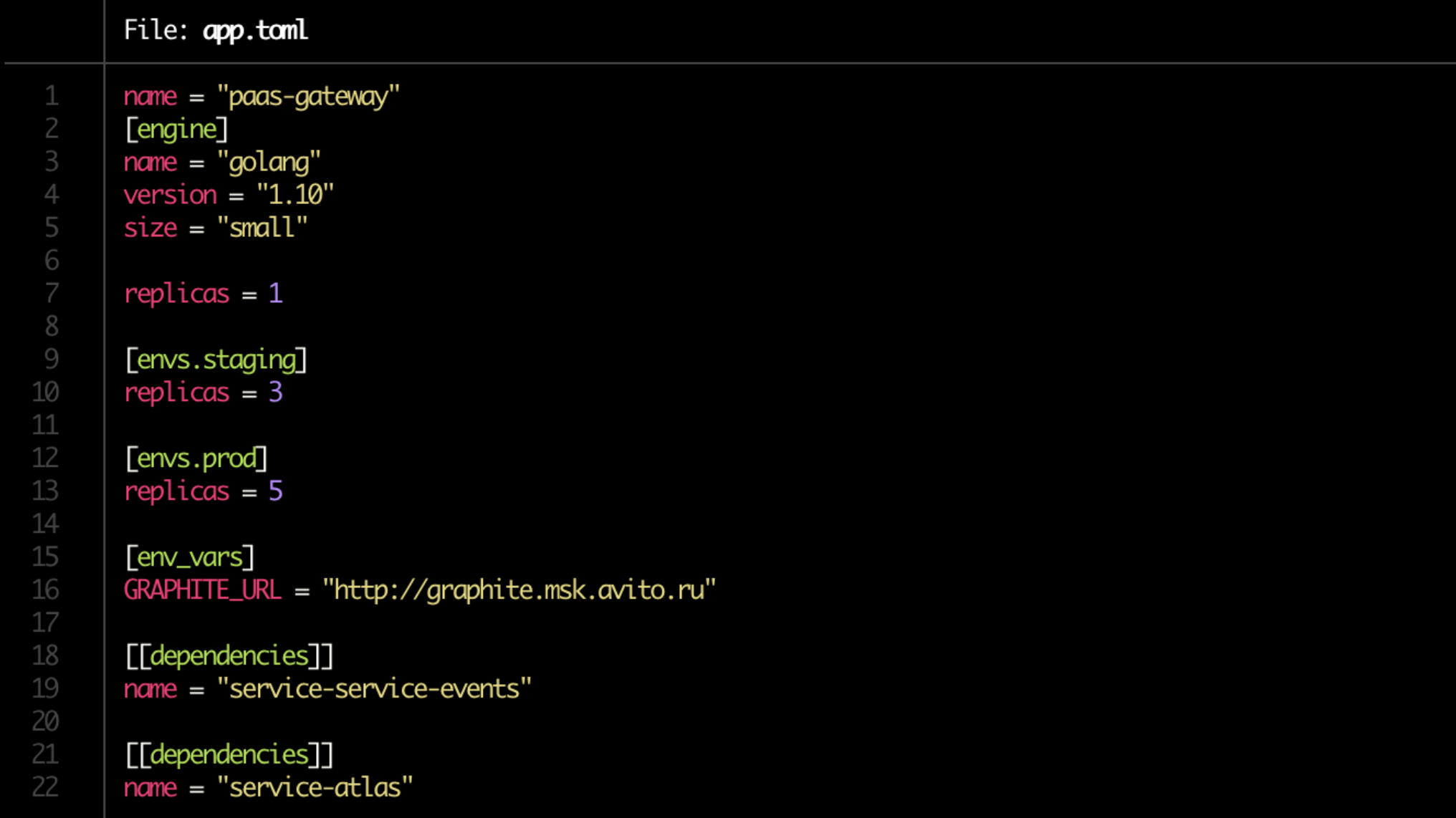
Ja, und in der App.toml selbst geht es jetzt um eine Minute. Wir schreiben auf, wo wie viele Kopien des Dienstes (auf dem Dev-Server, beim Staging, bei der Produktion) ausgelöst werden sollen, und geben seine Abhängigkeiten an. Beachten Sie die Zeilengröße = "klein" im Block [engine]. Dies ist das Limit, das dem Dienst über Kubernetes zugewiesen wird.
Weiterhin werden anhand der Konfiguration automatisch alle notwendigen Helm-Charts generiert und Verbindungen zu den Datenbanken hergestellt.
• Grundlegende Validierung. Solche Überprüfungen werden ebenfalls automatisiert.
Müssen verfolgen:
- Gibt es eine Docker-Datei?
- gibt es app.toml;
- ob es Unterlagen gibt;
- ob die Abhängigkeiten in Ordnung sind;
- sind die Regeln für Warnungen festgelegt.
Zum letzten Punkt: Der Servicebesitzer gibt selbst an, welche Produktmetriken überwacht werden sollen.
• Vorbereitung der Dokumentation.
Immer noch ein Problemort. Es scheint das offensichtlichste, aber gleichzeitig ein rekordverdächtiges „oft vergessenes“ und damit verletzliches Glied in der Kette zu sein.
Es ist erforderlich, dass sich die Dokumentation unter jedem Microservice befindet. Die folgenden Blöcke sind darin enthalten.
I. Kurze Beschreibung des Dienstes . Nur ein paar Sätze darüber, was er tut und wofür er gebraucht wird.
II. Link zum Architekturdiagramm . Es ist wichtig, dass ein kurzer Blick darauf leicht verständlich macht, ob Sie Redis zum Zwischenspeichern oder als Hauptdatenspeicher im permanenten Modus verwenden. In Avito ist dies bisher eine Verbindung zu Confluence.
III. Runbook . Eine kurze Anleitung zum Starten des Dienstes und die Feinheiten bei der Handhabung.
IV. FAQ , wo es gut ist, die Probleme zu antizipieren, auf die Ihre Kollegen bei der Arbeit mit dem Service stoßen können.
V. Beschreibung der Endpunkte für die API . Wenn Sie Ihr Ziel plötzlich nicht mehr angegeben haben, werden Sie mit ziemlicher Sicherheit von Kollegen bezahlt, deren Microservices mit Ihrem verwandt sind. Jetzt verwenden wir Swagger dafür und unsere Lösung heißt kurz.
VI. Etiketten Oder Markierungen, die anzeigen, zu welchem Produkt, welcher Funktionalität und welcher Struktureinheit des Unternehmens die Dienstleistung gehört. Sie helfen beispielsweise dabei, schnell zu verstehen, ob Sie nicht die Funktionen sehen, die Ihre Kollegen vor einer Woche für denselben Geschäftsbereich eingeführt haben.
VII. Der Eigentümer oder die Eigentümer des Dienstes . In den meisten Fällen kann es - oder sie - automatisch mithilfe von PaaS ermittelt werden. Für Versicherungen muss der Entwickler sie jedoch manuell angeben.
Schließlich empfiehlt es sich, die Dokumentation zu überprüfen, ähnlich wie bei der Codeüberprüfung.
Kontinuierliche Integration
- Repositorys vorbereiten.
- Erstellen einer Pipeline in TeamCity.
- Rechte einstellen.
- Suche nach Service-Eigentümern. Es gibt ein Hybridschema - manuelle Kennzeichnung und minimale Automatisierung von PaaS. Ein vollautomatisches Schema kann keine Dienste zur Unterstützung an ein anderes Entwicklungsteam übertragen oder beispielsweise, wenn ein Dienstentwickler beendet wird.
- Serviceregistrierung in Atlas (siehe oben). Mit all seinen Besitzern und Abhängigkeiten.
- Überprüfen Sie die Migrationen. Wir prüfen, ob sich unter ihnen potenziell gefährliche befinden. In einer von ihnen wird beispielsweise eine Änderungstabelle oder etwas anderes angezeigt, das die Kompatibilität des Datenschemas zwischen verschiedenen Versionen des Dienstes beeinträchtigen kann. Dann wird die Migration nicht durchgeführt, sondern ein Abonnement abgeschlossen. PaaS sollte dem Eigentümer des Dienstes signalisieren, wann die Verwendung sicher wird.
Backen
Die nächste Stufe ist das Packen von Diensten vor der Bereitstellung.
- Erstellen Sie die Anwendung. Nach den Klassikern - im Docker-Bild.
- Generierung von Helmdiagrammen für den Service selbst und zugehörige Ressourcen. Einschließlich für Datenbanken und Cache. Sie werden automatisch gemäß der app.toml-Konfiguration erstellt, die in der CLI-Push-Phase generiert wurde.
- Erstellen von Tickets für Administratoren zum Öffnen von Ports (falls erforderlich).
- Unit-Testlauf und Berechnung der Codeabdeckung . Wenn die Codeabdeckung unter einem bestimmten Schwellenwert liegt, schlägt der Dienst höchstwahrscheinlich weiter fehl - bei der Bereitstellung. Wenn es kurz vor dem Zulässigen steht, wird dem Service ein „Pessimierungskoeffizient“ zugewiesen. Wenn sich der Indikator im Laufe der Zeit nicht verbessert, erhält der Entwickler eine Benachrichtigung, dass seitens der Tests keine Fortschritte erzielt wurden (und diesbezüglich muss etwas unternommen werden).
- Berücksichtigung von Speicher- und CPU-Einschränkungen . Wir schreiben hauptsächlich Microservices in Golang und betreiben sie in Kubernetes. Von hier aus gibt es eine Feinheit, die mit der Besonderheit der Golang-Sprache verbunden ist: Standardmäßig werden beim Start alle Kernel auf dem Computer verwendet. Wenn Sie die Variable GOMAXPROCS nicht explizit festlegen und mehrere solcher Dienste auf demselben Computer gestartet werden, beginnen sie um Ressourcen zu konkurrieren und stören sich gegenseitig. Die folgenden Grafiken zeigen, wie sich die Laufzeit ändert, wenn Sie die Anwendung ohne Konkurrenz und im Wettlauf um Ressourcen ausführen. (Die Quelle der Grafiken ist hier ).

Vorlaufzeit, weniger ist besser. Maximum: 643 ms; Minimum: 42 ms. Das Foto ist anklickbar.
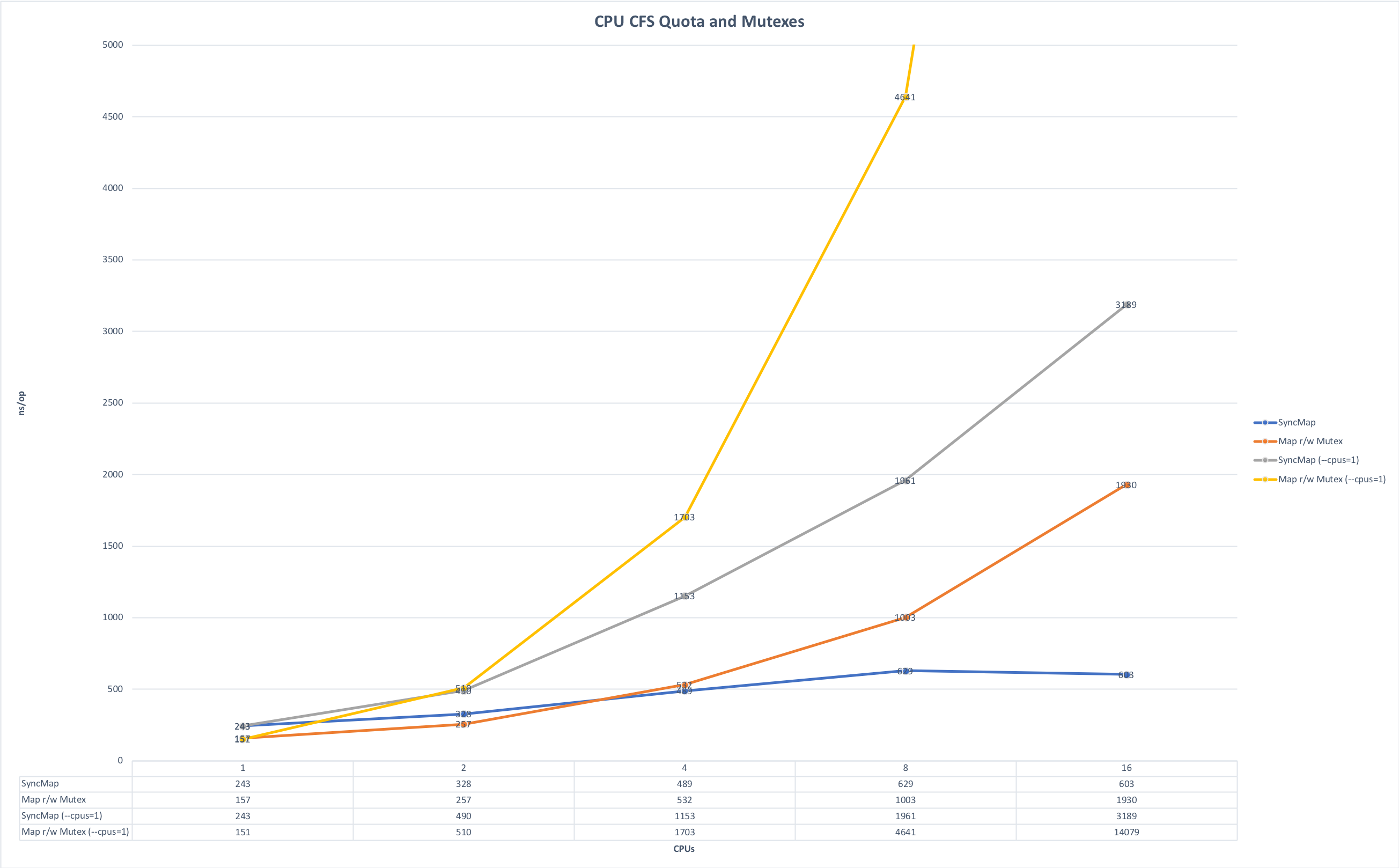
Zeit für eine Operation, weniger ist besser. Maximum: 14091 ns, Minimum: 151 ns. Das Foto ist anklickbar.
In der Phase der Vorbereitung der Baugruppe können Sie diese Variable explizit festlegen oder die automaxprocs- Bibliothek der Uber- Mitarbeiter verwenden.
Bereitstellen
• Überprüfung von Konventionen. Bevor Sie mit der Bereitstellung von Servicebaugruppen für vorgesehene Umgebungen beginnen, müssen Sie Folgendes überprüfen:
- API-Endpunkte.
- Einhaltung des Endpunktschemas für API-Antworten.
- Protokollformat.
- Header für Serviceanfragen setzen (Netramesh macht das jetzt)
- Festlegen des Besitzertokens beim Senden von Nachrichten an den Bus (Ereignisbus). Dies ist erforderlich, um die Konnektivität von Diensten über den Bus zu verfolgen. Sie können idempotente Daten an den Bus senden, die die Konnektivität von Diensten nicht erhöhen (was gut ist), sowie Geschäftsdaten, die die Konnektivität von Diensten verbessern (was sehr schlecht ist!). In dem Moment, in dem diese Konnektivität zu einem Problem wird, hilft das Verstehen, wer den Bus schreibt und liest, die Dienste richtig aufzuteilen.
Es gibt zwar nicht viele Konventionen in Avito, aber ihr Pool erweitert sich. Je mehr solche Vereinbarungen in Form eines verständlichen und bequemen Befehls vorliegen, desto einfacher ist es, die Konsistenz zwischen Microservices aufrechtzuerhalten.
Synthetische Tests
• Closed-Loop-Test. Für ihn verwenden wir jetzt die Open Source Hoverfly.io . Zuerst wird die tatsächliche Auslastung des Dienstes aufgezeichnet und dann - nur in einer geschlossenen Schleife - emuliert.
• Lasttest. Wir versuchen, alle Dienstleistungen auf optimale Leistung zu bringen. Alle Versionen jedes Dienstes sollten Stresstests unterzogen werden, damit wir die aktuelle Leistung des Dienstes und den Unterschied zu früheren Versionen desselben Dienstes verstehen können. Wenn nach einem Service-Update die Leistung um das Eineinhalbfache gesunken ist, ist dies ein klares Signal für die Eigentümer: Sie müssen sich in den Code vertiefen und die Situation beheben.
Wir bauen beispielsweise auf den gesammelten Daten auf, um die automatische Skalierung korrekt zu implementieren und letztendlich allgemein zu verstehen, wie skalierbar der Service ist.
Während des Stresstests prüfen wir, ob der Ressourcenverbrauch die festgelegten Grenzwerte erreicht. Und wir konzentrieren uns hauptsächlich auf Extreme.
a) Wir betrachten die Gesamtlast.
- Zu klein - höchstwahrscheinlich funktioniert etwas überhaupt nicht, wenn die Last plötzlich mehrmals abfällt.
- Zu groß - Optimierung ist erforderlich.
b) Wir betrachten den Cut-off von RPS.
Hier betrachten wir den Unterschied zwischen der aktuellen und der vorherigen Version und der Gesamtzahl. Wenn ein Dienst beispielsweise 100 U / min erzeugt, ist er entweder schlecht geschrieben oder es ist seine Spezifität. In jedem Fall ist dies jedoch eine Gelegenheit, den Dienst sehr genau zu betrachten.
Wenn RPS im Gegenteil zu viel ist, werden möglicherweise eine Art Fehler und einige der Endpunkte die Nutzdaten nicht mehr ausführen, aber eine Art return true; ausgelöst return true;
Kanarische Tests
Nachdem die synthetischen Tests bestanden wurden, führen wir den Microservice für eine kleine Anzahl von Benutzern aus. Wir beginnen vorsichtig mit einem winzigen Bruchteil der geschätzten Zielgruppe des Dienstes - weniger als 0,1%. In dieser Phase ist es sehr wichtig, dass die richtigen technischen und Produktmetriken in der Überwachung festgelegt werden, damit sie das Problem im Service so schnell wie möglich anzeigen. Die Mindestzeit für einen Kanarientest beträgt 5 Minuten, die Hauptzeit 2 Stunden. Für komplexe Dienste stellen wir die Zeit im manuellen Modus ein.
Wir analysieren:
- sprachspezifische Metriken, insbesondere PHP-Fpm-Mitarbeiter;
- Fehler in Sentry;
- Status der Antworten;
- Reaktionszeit (Reaktionszeit), genau und durchschnittlich;
- Latenz;
- Ausnahmen, verarbeitet und unverarbeitet;
- Lebensmittelmetriken.
Quetschtest
Squeeze Testing wird auch als Extrusionstest bezeichnet. Der Name der Technik wurde in Netflix eingeführt. Das Wesentliche ist, dass wir zunächst eine Instanz mit echtem Datenverkehr bis zum Fehlerzustand füllen und damit ihre Grenze festlegen. Fügen Sie als Nächstes eine weitere Instanz hinzu und laden Sie dieses Paar erneut auf das Maximum. Wir sehen ihre Decke und ihr Delta beim ersten "Squeeze". Und so verbinden wir eine Instanz pro Schritt und berechnen das Änderungsmuster.
Testdaten durch „Extrusion“ strömen auch zur allgemeinen metrischen Basis, wo wir sie entweder mit künstlichen Belastungsergebnissen anreichern oder sie sogar durch „Kunststoffe“ ersetzen.
Produktion
• Skalierung. Indem wir den Service auf die Produktion ausweiten, verfolgen wir, wie er skaliert. In diesem Fall ist es nach unserer Erfahrung ineffizient, nur CPU-Indikatoren zu überwachen. Die automatische Skalierung mit RPS-Benchmarking in reiner Form funktioniert jedoch nur für bestimmte Dienste, z. B. Online-Streaming. Daher betrachten wir hauptsächlich anwendungsspezifische Produktmetriken.
Als Ergebnis analysieren wir bei der Skalierung:
- CPU- und RAM-Anzeigen,
- die Anzahl der Anfragen in der Warteschlange,
- Reaktionszeit
- Prognose basierend auf historischen Daten.
Beim Skalieren eines Dienstes ist es auch wichtig, seine Abhängigkeiten zu überwachen, damit sich nicht herausstellt, dass wir der erste Dienst in der Skalierungskette sind und diejenigen, auf die er sich bezieht, unter Last fallen. Um eine akzeptable Auslastung für den gesamten Servicepool zu ermitteln, betrachten wir die historischen Daten des "nächsten" abhängigen Dienstes (basierend auf einer Kombination aus CPU und RAM und app-spezifischen Metriken) und vergleichen sie mit den historischen Daten des Initialisierungsdienstes usw. entlang der gesamten "Abhängigkeitskette". ", Von oben nach unten.
Service
Nachdem der Microservice in Betrieb genommen wurde, können wir Trigger daran hängen.
Hier sind typische Situationen, in denen Feuer ausgelöst wird.
- Potenziell gefährliche Migrationen erkannt.
- Sicherheitsupdates wurden veröffentlicht.
- Der Dienst selbst wurde lange nicht aktualisiert.
- Die Belastung des Dienstes hat erheblich abgenommen oder eine seiner Produktmetriken liegt außerhalb des normalen Bereichs.
- Der Dienst erfüllt die neuen Plattformanforderungen nicht mehr.
Einige der Auslöser sind für die Stabilität der Arbeit verantwortlich, andere als Funktion der Wartung des Systems. Einige Dienste wurden beispielsweise schon lange nicht mehr bereitgestellt, und das grundlegende Image hat die Sicherheitsüberprüfungen nicht mehr bestanden.
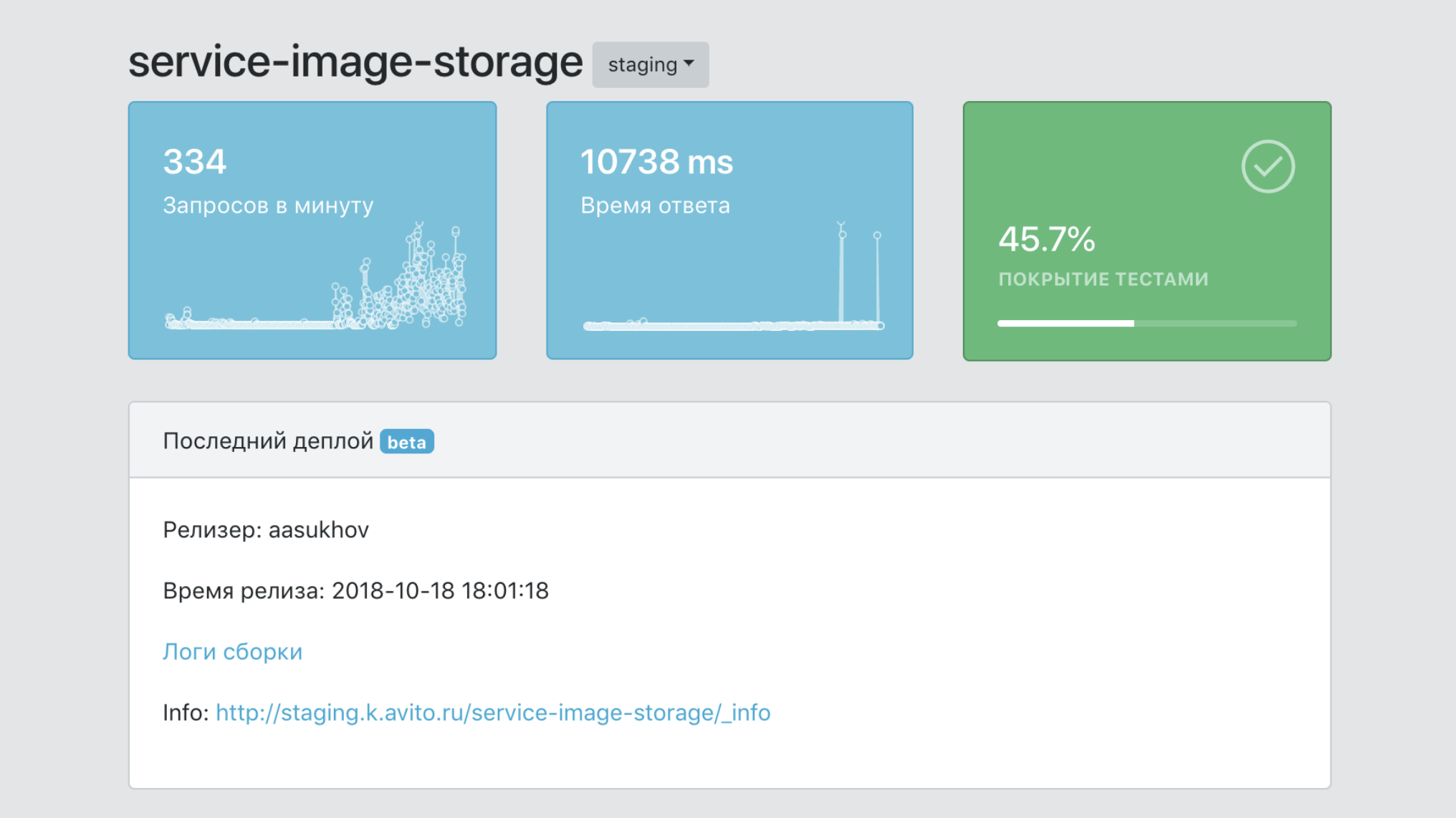
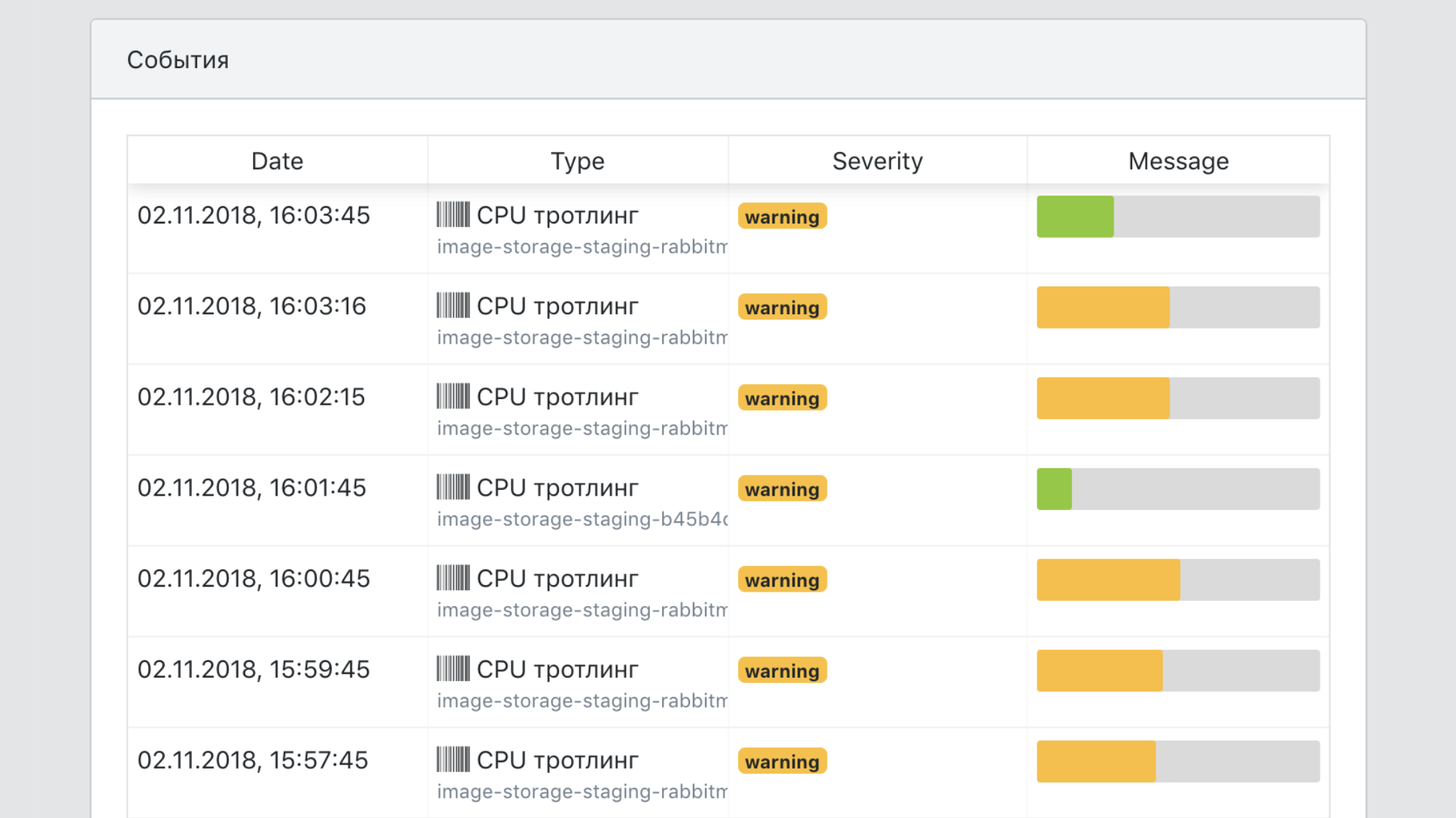
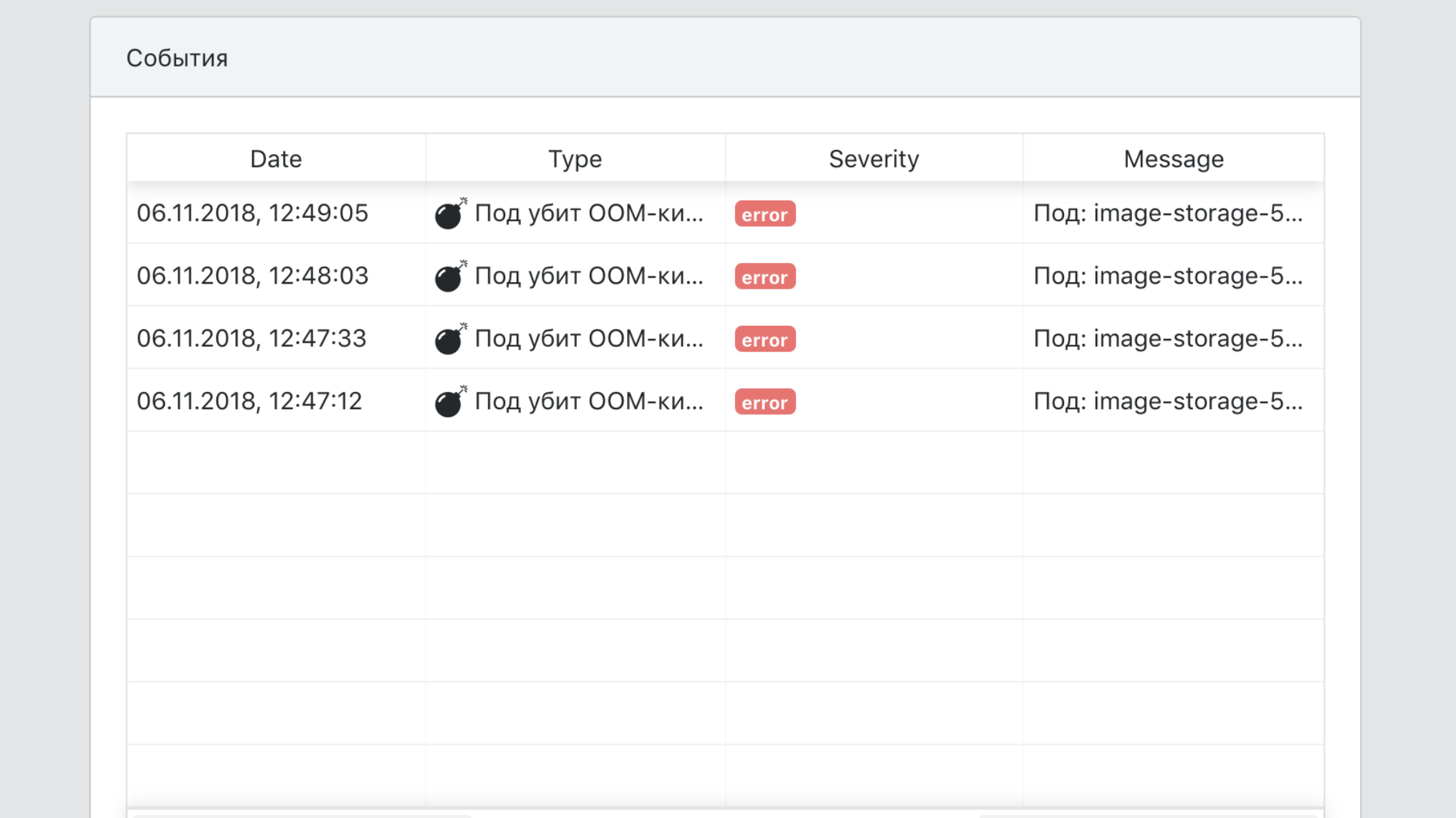
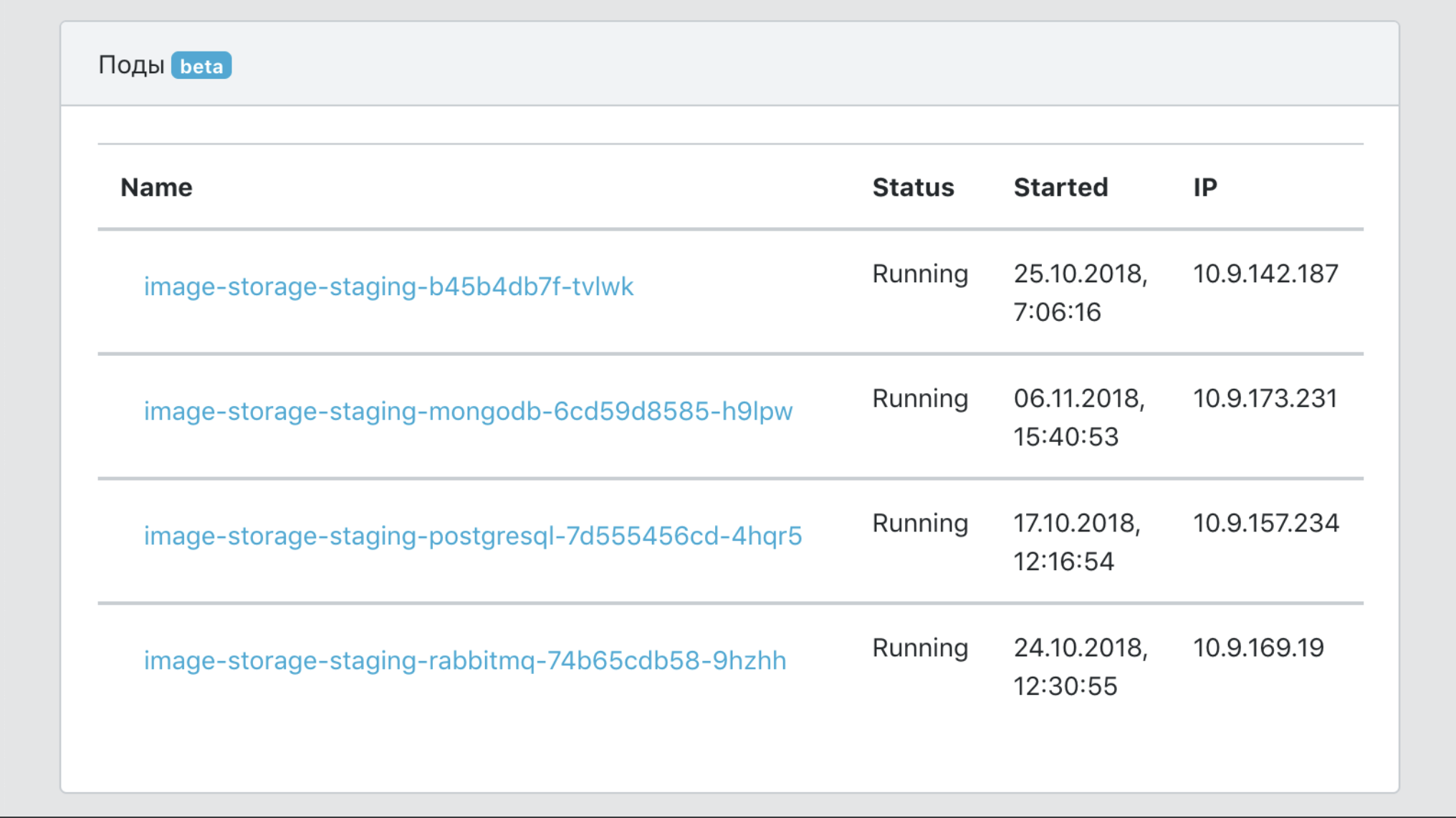
Dashboard
Kurz gesagt, das Dashboard ist das Bedienfeld unseres gesamten PaaS.
- Ein einzelner Informationspunkt über einen Dienst mit Daten zu seiner Abdeckung durch Tests, der Anzahl seiner Bilder, der Anzahl der Produktionskopien, Versionen usw.
- Ein Tool zum Filtern von Daten nach Services und Labels (Kennzeichen für die Zugehörigkeit zu Geschäftsbereichen, Produktfunktionalität usw.)
- Integrationsmittel in Infrastruktur-Tools zum Nachverfolgen, Protokollieren und Überwachen.
- Eine einzige Point-of-Service-Dokumentation.
- Eine einzige Sicht auf alle Serviceereignisse.
Insgesamt
Vor der Einführung von PaaS konnte ein neuer Entwickler mehrere Wochen damit verbringen, alle Tools zu sortieren, die zum Starten eines Microservices in der Produktion erforderlich sind: Kubernetes, Helm, unsere internen TeamCity-Funktionen, das Herstellen einer Verbindung zu Datenbanken und Caches in fehlertoleranter Form usw. Jetzt dauert es ein paar Stunden, um den Schnellstart zu lesen und den Dienst selbst zu erstellen.
Ich habe einen Bericht zu diesem Thema für HighLoad ++ 2018 erstellt. Sie können das Video und die Präsentation ansehen.
Bonustrack für diejenigen, die bis zum Ende gelesen haben
Wir in Avito organisieren eine interne dreitägige Schulung für Entwickler von Chris Richardson , einem Experten für Microservice-Architektur. Wir möchten einem der Leser dieses Beitrags die Möglichkeit geben, daran teilzunehmen. Hier ist ein Trainingsprogramm.
Das Training findet vom 5. bis 7. August in Moskau statt. Dies sind Arbeitstage, die voll belegt sind. Das Mittagessen und die Schulung finden in unserem Büro statt und der ausgewählte Teilnehmer bezahlt die Reise und die Unterkunft selbst.
Sie können die Teilnahme an diesem Google-Formular beantragen. Von Ihnen - die Antwort auf die Frage, warum genau Sie an der Schulung teilnehmen müssen, und Informationen zur Kontaktaufnahme. Antworte auf Englisch, da Chris den Teilnehmer auswählt, der zum Training kommt.
Wir werden den Namen des Schulungsteilnehmers bis spätestens 19. Juli als Update für diesen Beitrag in den sozialen Netzwerken von Avito für Entwickler (AvitoTech auf Facebook , Vkontakte , Twitter ) bekannt geben.
UPD, 19.07.: Wir haben Dutzende von Bewerbungen erhalten. Chris untersuchte sie und wählte einen Teilnehmer aus: Zusammen mit unseren Kollegen wird Andrei Igumnov studieren gehen. Glückwunsch!