Hallo an alle. Mein Team bei Tinkoff baut Empfehlungssysteme. Wenn Sie mit Ihrem monatlichen Cashback zufrieden sind, ist dies unser Geschäft. Wir haben auch ein Empfehlungssystem mit Sonderangeboten von Partnern aufgebaut und beschäftigen uns mit einzelnen Sammlungen von Geschichten in der Tinkoff-Anwendung. Und wir lieben es, an Wettbewerben für maschinelles Lernen teilzunehmen, um uns in Form zu halten.
Zwei Monate lang, vom 18. Februar bis 18. April, fand bei Boosters.pro ein Wettbewerb statt , um ein Empfehlungssystem für reale Daten aus einem der größten russischen Online-Kinos Okko aufzubauen. Die Organisatoren wollten das bestehende Empfehlungssystem verbessern. Derzeit ist der Wettbewerb im Sandbox-Modus verfügbar , in dem Sie Ihre Ansätze testen und Ihre Fähigkeiten beim Aufbau von Empfehlungssystemen verbessern können.
Datenbeschreibung
Der Zugriff auf Inhalte in Okko erfolgt über die Anwendung auf dem Fernseher oder Smartphone oder über die Weboberfläche. Inhalte können gemietet, gekauft (P) oder im Abonnement (S) angezeigt werden. Der Veranstalter des Wettbewerbs stellte Daten zu Ansichten für N Tage (N> 60) zur Verfügung. Außerdem standen Informationen zu den hinzugefügten Bewertungen und Lesezeichen zur Verfügung. Beachten Sie ein wichtiges Detail: Wenn der Benutzer einen Film mehrmals oder mehrere Folgen der Serie gesehen hat, werden nur das Datum der letzten Transaktion und die Gesamtzeit pro Inhaltseinheit auf dem Tablet aufgezeichnet.
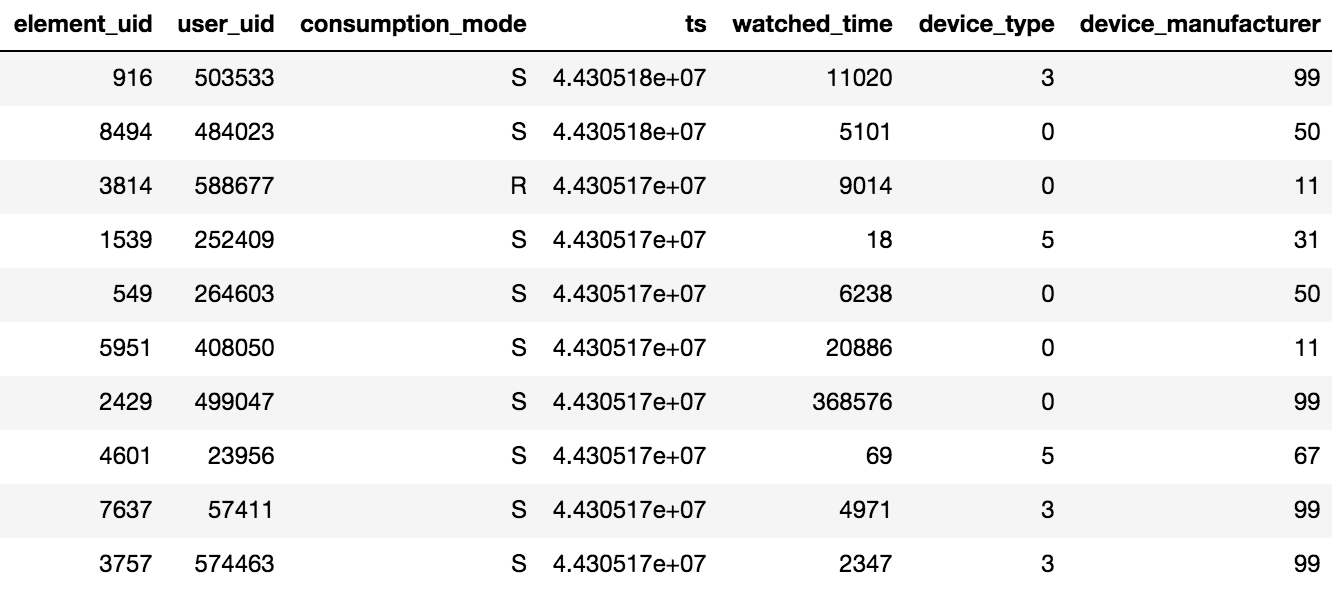
Es wurden ungefähr 10 Millionen Transaktionen, 450.000 Bewertungen und 950.000 Lesezeichen für 500.000 Benutzer bereitgestellt.
Das Beispiel enthält nicht nur aktive Benutzer, sondern auch Benutzer, die während des gesamten Zeitraums einige Filme angesehen haben.
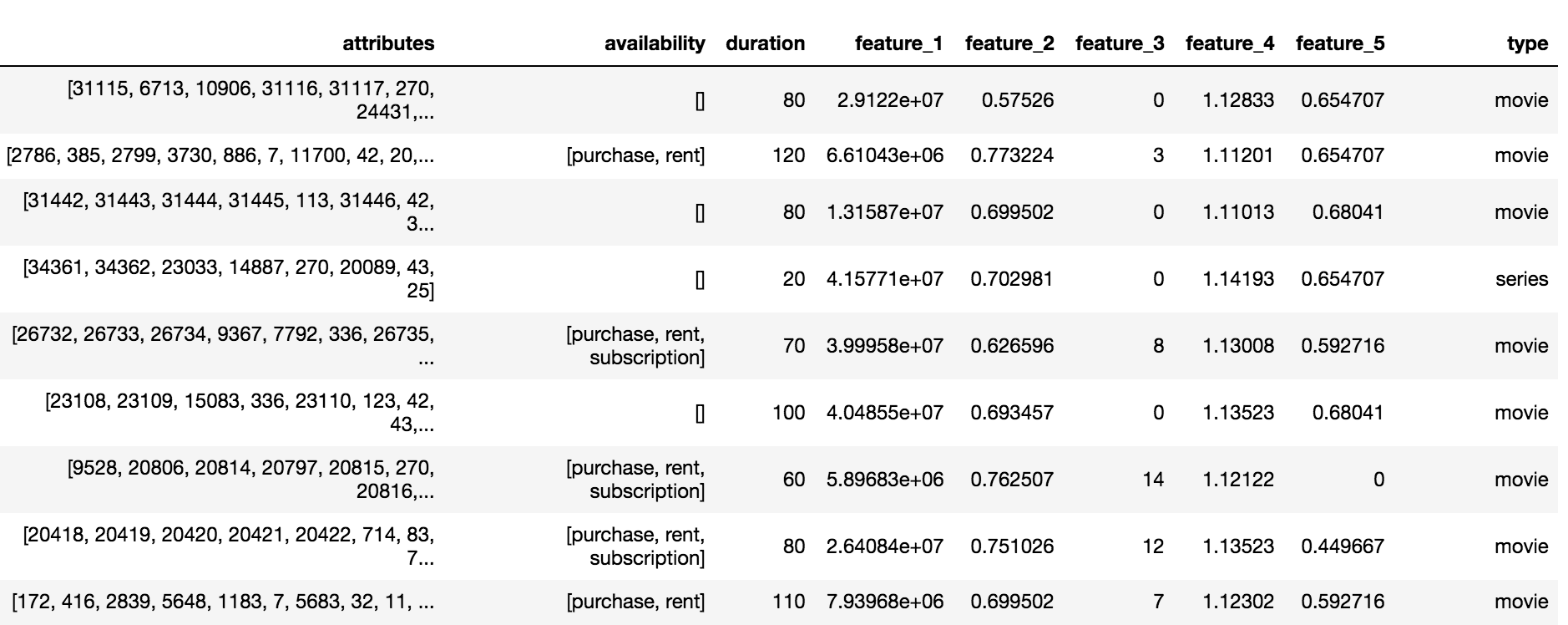
Der Okko-Katalog enthält drei Arten von Inhalten: Filme (Film), Serien (Serien) und Serienfilme (multipart_movie), insgesamt 10.200 Objekte. Für jedes Objekt standen eine Reihe anonymisierter Attribute und Attribute (feature_1, ..., feature_5), Abonnement-, Miet- oder Kaufverfügbarkeit und -dauer zur Verfügung.
Zielvariable und Metrik
Die Aufgabe, die erforderlich ist, um viele Inhalte vorherzusagen, die der Benutzer in den nächsten 60 Tagen verbrauchen würde. Es wird angenommen, dass ein Benutzer Inhalte konsumiert, wenn er:
- Kaufen oder mieten
- Sehen Sie sich mehr als die Hälfte des Films im Abonnement an
- Sehen Sie sich mehr als ein Drittel der Serie im Abonnement an
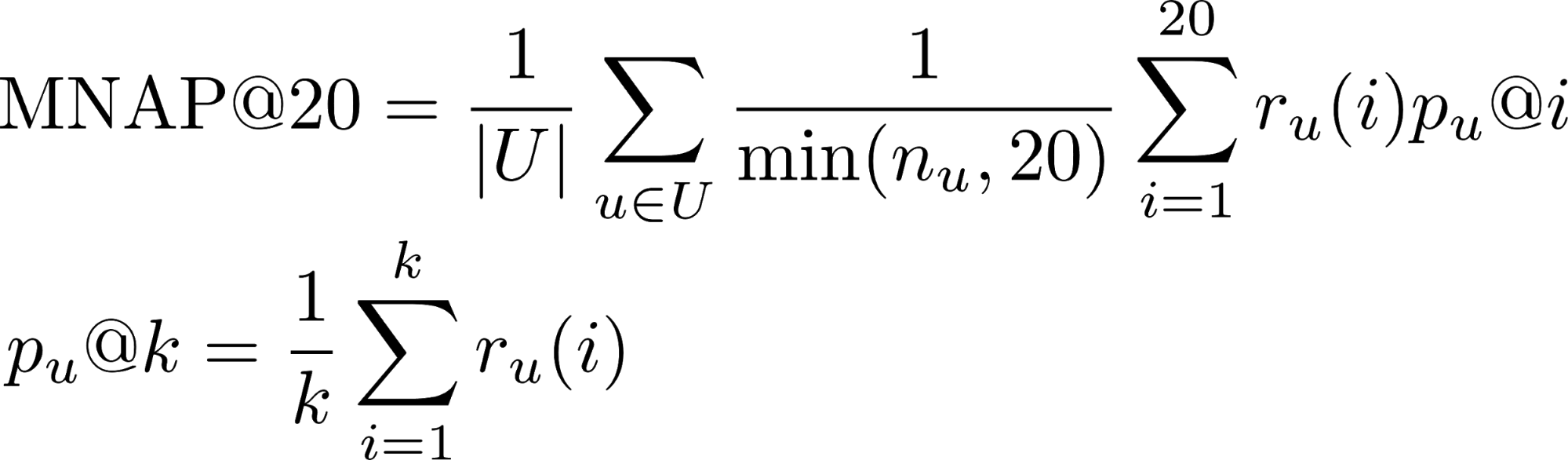
- r_u (i) - ob der Benutzer u den ihm vorhergesagten Inhalt an Stelle i (1 oder 0) konsumiert hat
- n_u - Die Anzahl der Elemente, die der Benutzer während des Testzeitraums verbraucht hat
- U - viele Testbenutzer
In diesem Beitrag erfahren Sie mehr über Metriken für die Ranking-Aufgabe.
Die meisten Benutzer schauen sich Filme bis zum Ende an, sodass der Anteil der positiven Klasse an Transaktionen 65% beträgt. Die Qualität des Algorithmus wurde anhand einer Teilmenge von 50.000 Benutzern aus der vorgestellten Stichprobe bewertet.
Gesamtbewertung
Die Wettbewerbsentscheidung begann mit der Zusammenfassung aller Benutzerinteraktionen mit Inhalten in einer einzigen Bewertungsskala. Es wurde angenommen, dass wenn der Benutzer den Inhalt gekauft hat, dies maximales Interesse bedeutet. Der Film ist kürzer als die Serie. Um die gesamte Serie zu betrachten, müssen Sie mehr Punkte vergeben. Als Ergebnis wurde das aggregierte Rating nach folgenden Regeln gebildet:
- Filmfreigabe * 5
- TV-Show teilen * 10
- [Lesezeichen für den Film] * 0.5
- [Lesezeichen für die Serie] * 1.5
- [Kauf / Verleih von Inhalten] * 15
- Bewertung + 2
Modell der ersten Ebene
Die Organisatoren stellten eine grundlegende Lösung zur Verfügung, die auf der kollaborativen Filterung mit Tf-IDF-Skalen basiert. Hinzufügen aller Arten von Interaktionen zur aggregierten Bewertung, Erhöhen der Anzahl der nächsten Nachbarn von 20 auf 150 und Ersetzen von Tf-IDF durch BM25-Gewichte, die in LB (Leader Board) um etwa 0,03 geschlagen wurden.
Inspiriert von dem Posten des Teams, das bei der RecSys Challenge 2018 den 3. Platz belegte , entschied ich mich für das LightFM- Modell mit WARP- Verlust als zweitem Basismodell. LightFM mit ausgewählten Hyperparametern: learning_rate, no_components, item_alpha, user_alpha, max_sampled ergab 0,033 auf LB.

Die Validierung des Modells erfolgte pünktlich: Die ersten 80% der Interaktionen fielen in den Zug, die restlichen 20% in die Validierung. Für eine Einreichung bei LB wurde ein Modell für den gesamten Datensatz mit zur Validierung ausgewählten Parametern trainiert.
Modellmischung
In der vorherigen Phase stellte sich heraus, dass zwei starke Basislinien erstellt wurden. Darüber hinaus überschnitten sich ihre Empfehlungen im Durchschnitt für 60 Prozent des empfohlenen Inhalts. Wenn es zwei starke und gleichzeitig schwach korrelierte Modelle gibt, ist ihre Überblendung ein vernünftiger Schritt.
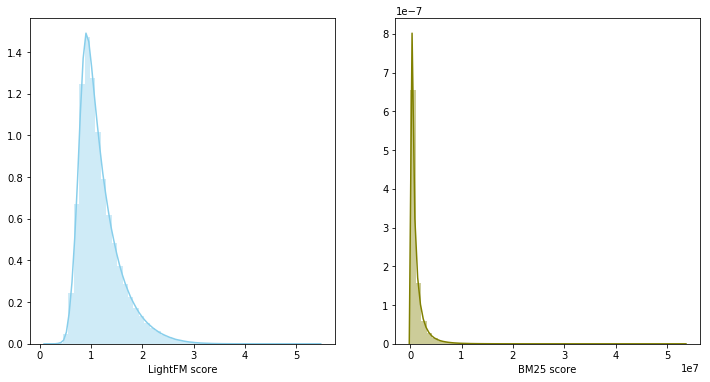
In diesem Fall gehören die Modellbewertungen zu unterschiedlichen Verteilungen und haben unterschiedliche Skalen. Daher wurde beschlossen, die Summe der Ränge zu verwenden, um die beiden Modelle zu kombinieren. Das Modellmischen ergab 0,0347 auf LB.

Modell der zweiten Ebene
Empfehlungssysteme verwenden häufig einen zweistufigen Ansatz zum Erstellen von Modellen: Zuerst werden Spitzenkandidaten durch ein einfaches Modell der ersten Ebene ausgewählt, dann wird die ausgewählte Spitze durch ein komplexeres Modell mit einer großen Anzahl von Merkmalen neu eingestuft.

Der Datensatz wurde zeitlich in die Trainings- und Validierungsteile unterteilt. Für den Validierungsteil wurde für jeden Benutzer eine Auswahl von Empfehlungen gesammelt, die aus der Kombination von Top200-Vorhersagen von Modellen der ersten Ebene mit Ausnahme der bereits angesehenen Filme bestehen. Außerdem musste das Modell lernen, das resultierende Oberteil für jeden Benutzer neu anzuordnen. Das Problem wurde in Bezug auf die binäre Klassifizierung formuliert. Ein Paar (Benutzer, Inhalt) gehörte nur dann zur positiven Klasse, wenn der Benutzer den Inhalt während des Validierungszeitraums konsumierte. Als Modell der zweiten Ebene wurde die Gradientenverstärkung verwendet, nämlich das LightGBM-Paket.
Zeichen
Modelle der ersten Ebene für Paare (Benutzer, Inhalt) bewerten die Relevanz in Form einer Geschwindigkeit und sortieren diese, wobei Sie in absteigender Reihenfolge einen Rang erhalten können. Das Modell, das auf den Zeichen von Rang und Geschwindigkeit trainiert wurde, schlug zusammen mit den Zeichen aus dem Inhaltskatalog 0,0359 auf LB aus.
Aus der Verteilungsform des ersten der anonymisierten Features wurde geschlossen, dass es sich um das Datum handelt, an dem der Film im Katalog erscheint. Daher wurde das Modell für dieses Feature mit dem ausgewählten Validierungsschema stark umgeschult. Das Entfernen eines Merkmals aus der Probe ergab einen Anstieg der LB auf 0,0367
Das LightFM-Modell gibt neben der Vorhersage der Relevanz von Inhalten für den Benutzer zwei Vektoren zurück: Item Bias und User Bias, die mit dem Bekanntheitsgrad des Inhalts und der Anzahl der vom Benutzer angesehenen Filme korrelieren. Das Hinzufügen von Zeichen erhöhte die Geschwindigkeit auf LB auf 0,0388 .
Sie können einem Paar (Benutzer, Inhalt) entweder vor oder nach dem Löschen bereits angesehener Filme einen Rang zuweisen. Änderungen in der Methode zu letzterer führten zu einer Erhöhung der LB auf 0,0395 .
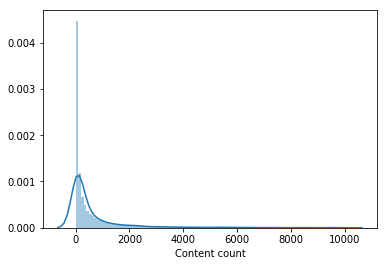
Fast niemand hat einen wesentlichen Teil des Filmkatalogs gesehen. Inhalte, die von weniger als 100 Benutzern angesehen wurden, wurden aus der Stichprobe entfernt, um ein Modell der zweiten Ebene zu trainieren, wodurch der Katalog um die Hälfte reduziert wurde. Das Entfernen von unbeliebtem Inhalt machte die Auswahl aus den Modellen der ersten Ebene relevanter und erst danach verbesserte der Vektor der Benutzer von LightFM die Validierungsgeschwindigkeit und erhöhte die LB auf 0,0429 .
Außerdem wurde ein Schild hinzugefügt - der Benutzer fügte das Lesezeichen zum Buch hinzu, sah sich jedoch nicht die Zugperiode an , wodurch die Geschwindigkeit auf LB auf 0,0447 erhöht wurde . Außerdem wurden Zeichen zum Datum der ersten und letzten Transaktion hinzugefügt, die die Geschwindigkeit auf LB auf 0,0457 erhöhten.

Wir werden dieses Modell als endgültig betrachten. Am bedeutendsten waren Zeichen aus Modellen der ersten Ebene und anonymisierte Zeichen aus dem Inhaltskatalog.
Die folgenden Funktionen wurden nicht auf das endgültige Modell erweitert:
- Anzahl der Lesezeichen + Anteil der angezeigten Inhalte von Lesezeichen - 0,0453 LB
- die Anzahl der gekauften Filme 0,0451 LB
Aber als sie sich mit dem endgültigen Modell mischten , schlugen sie 0,0465 auf LB aus. Inspiriert vom Ergebnis der Mischung wurden die folgenden Modelle separat trainiert:
- mit verschiedenen Brüchen der Trainingsstichprobe für das First-Level-Modell. Die Aufteilung von 90% / 10% ergab einen Anstieg im Gegensatz zur Aufteilung von 95% / 5% und 70% / 30%.
- mit einer modifizierten Rating-Aggregationsmethode.
- mit dem Hinzufügen unbeliebter Filme zum Trainingsset für ein Modell der zweiten Ebene. Für jede Inhaltseinheit wurde eine Zusammenstellung von 1000 Benutzern zusammengestellt.
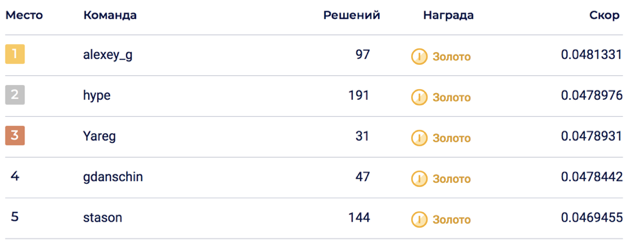
Die endgültige Mischung von 6 Modellen ermöglichte es, 0,0469678 auf LB zu erreichen, was dem 5. Platz entsprach.

Auf der privaten Seite kam es zu einer Erschütterung, die die Lösung auf den 2. Platz warf. Ich denke, dass sich die Lösung dank der Mischung einer großen Anzahl von Modellen als nachhaltig erwiesen hat.
Nicht eingegeben
Bei der Lösung des Wettbewerbs wurden viele Zeichen generiert, die definitiv zu stimmen schienen, aber leider. Zeichen und Ansätze, denen am meisten vertraut wurde:
- Anonyme Inhaltsattribute. Es war nicht sicher bekannt, was sie enthielten, aber alle Teilnehmer des Wettbewerbs glaubten, dass sie Informationen über Schauspieler, Regisseure, Komponisten enthielten ... Bei meiner Entscheidung habe ich versucht, sie in verschiedenen Formaten hinzuzufügen: Als Binärzeichen am beliebtesten, legen Sie die Inhaltsmatrix an Attribute mit LightFM und BigARTM, ziehen Sie dann die Vektoren heraus und fügen Sie sie dem Modell der zweiten Ebene hinzu.
- Inhaltsvektoren aus dem LigthFM-Modell im Modell der zweiten Ebene.
- Attribute der Geräte, von denen aus der Benutzer den Inhalt angezeigt hat.
- Verringern des Gewichts beliebter Inhalte für ein Modell der zweiten Ebene.
- Der Anteil der Filme / Fernsehsendungen an der Gesamtzahl der angezeigten Inhalte.
- Ranking-Metriken von CatBoost.
Interessante Fakten zum Wettbewerb
- Die Top1-Lösung erwies sich als schlechter als das Okko-Produktmodell 0.048 gegenüber 0.062. Es ist zu beachten, dass das Produktmodell bereits zum Zeitpunkt der Probenahme eingeführt wurde.
- Ungefähr eine Woche nach dem Start des Wettbewerbs wurde der Datensatz geändert. Für diejenigen, die von Anfang an teilnahmen, fügten sie 30 Einreichungen hinzu, die nach dem Zusammenschluss der Teams unerwartet ausgebrannt waren.
- Die Validierung korrelierte nicht immer mit der LB, was auf eine mögliche Erschütterung hinwies.
Entscheidungscode
Die Lösung ist auf Github in Form von zwei Jupyter-Laptops verfügbar: Bewertungsaggregation, Trainingsmodelle der ersten und zweiten Ebene.
Eine Lösung für den 3. Platz ist auch auf Github verfügbar.
Die Entscheidung der Veranstalter
Anstelle von tausend Wörtern füge ich die Top-Features der Organisatoren hinzu.
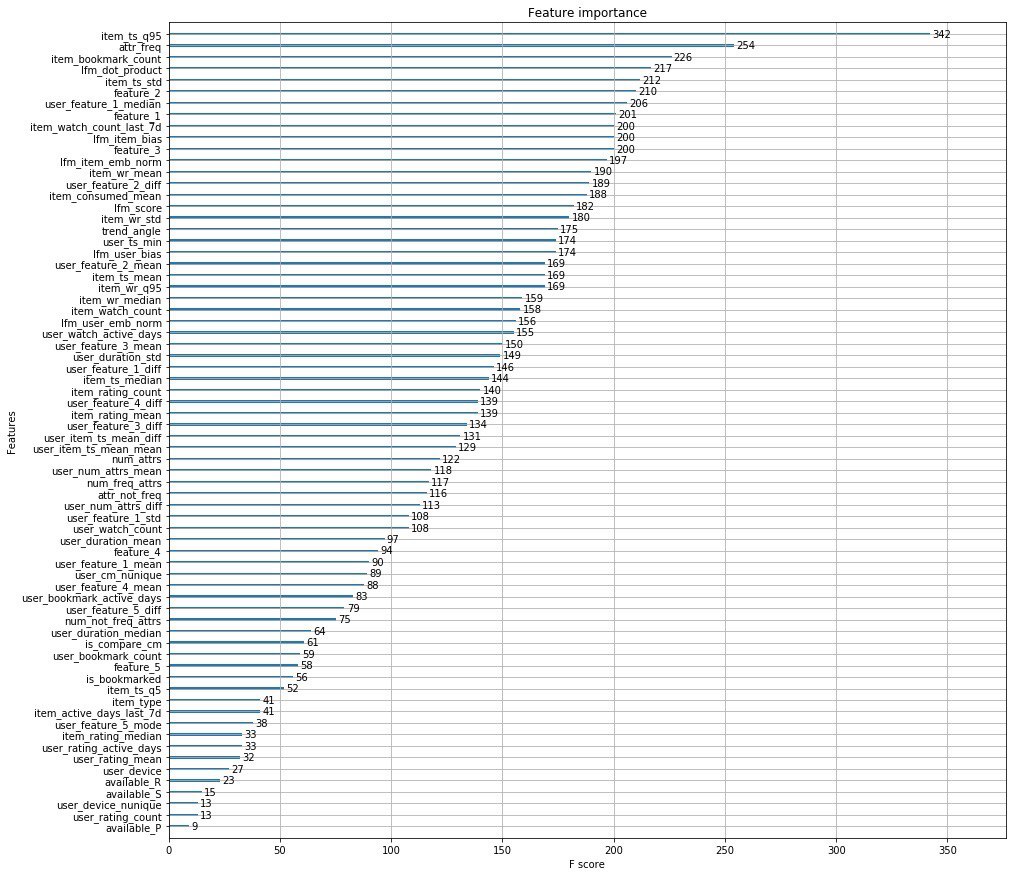
Außerdem haben die Jungs von Okko einen Artikel veröffentlicht, in dem sie über die Entwicklungsstadien ihrer Empfehlungs-Engine sprechen.
PS hier können Sie die Leistung bei Data Fest 6 über diese Lösung des Problems sehen.