
Wenn eines Ihrer Projekte die in der Azhurov-Datenbank gespeicherten Daten verwendet, haben Sie möglicherweise die Möglichkeit, die Datensuche mithilfe der Azure-Suche zu verwenden. Sie können nicht nur nach Datenbanken (Azure Cosmos DB, Azure SQL-Datenbank, in einer Azure-VM gehosteter SQL Server), sondern auch nach Blob (Azure Blob-Speicher, Azure-Tabellenspeicher) suchen.
Search hat einen kostenlosen Tarif, mit dem Sie bis zu drei Indizes mit einer Gesamtgröße von bis zu 50 MB erstellen können. Der kostenlose Tarif verfügt nicht über Lastausgleichsfunktionen, ist jedoch für die Verwendung gut geeignet.
Der Umgang mit der Suche erschien mir ziemlich einfach (obwohl dies nicht immer offensichtlich ist). Es gibt drei Arten von Objekten: Datenquelle, Index und Indexer. Das Hauptobjekt ist vielleicht der Index. Er ist dafür verantwortlich, wie man sucht und wonach man genau sucht. Die Datenquelle ist eine Datenverbindung, und der Indexer ist ein Job, der Indexdaten aktualisiert.
Über die Portal-Benutzeroberfläche können Sie Daten importieren und alle drei Objekte erstellen. Gelegenheit wird im Vorbeigehen sein und der Suche kognitive Fähigkeiten hinzufügen. Wenn sich die SQL-Datenbank im Abonnement befindet, können Sie sie beim Erstellen der Datenquelle auswählen. Obwohl das Passwort aus irgendeinem Grund, müssen Sie noch eingeben. Wenn Sie Cosmos DB verwenden möchten, müssen Sie die Verbindungszeichenfolge manuell eingeben. Vergessen Sie nicht, in der Zeile und in der Datenbank anzugeben und am Ende der Zeile Database = YOUR_BASE_NAME hinzuzufügen
Nach Auswahl einer Datenquelle werden Sie aufgefordert, die kognitiven Suchfunktionen zu verwenden. Die Standardfähigkeiten sind noch recht klein: Sie können die Sprache definieren, Namen, Namen von Organisationen, Orte und Schlüsselphrasen extrahieren. Es gibt auch eine interessante Möglichkeit, die Art des Textes für positive oder negative Emotionen mithilfe der Stimmungserkennung zu bestimmen. Diese Fähigkeit sollte für Produktbewertungen in Online-Shops geeignet sein. Mithilfe der API-Beschreibung können Sie Ihre eigenen Fähigkeiten erstellen .
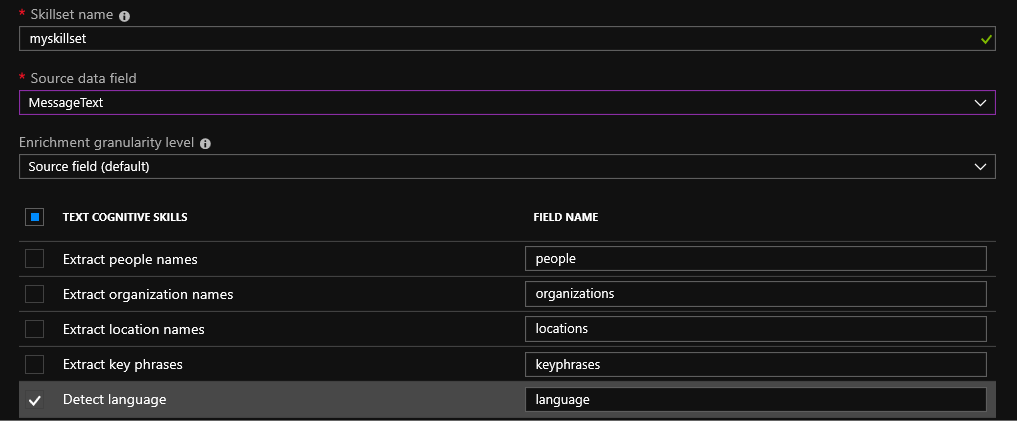
Für Dateien, die auf blob hochgeladen wurden, ist OCR (Optical Character Recognition) möglich. Die Erkennung von handschriftlichem (bisher nur englischem) und gedrucktem Text ist möglich. Mit kognitiven Diensten können verschiedene Objekte auf dem Foto identifiziert werden. Zum Beispiel berühmte Orte oder Prominente.
Der nächste Schritt ist das Erstellen eines Index. Die einzige Option für den Suchmodus an diesem Tag ist "analyseInfixMatching".
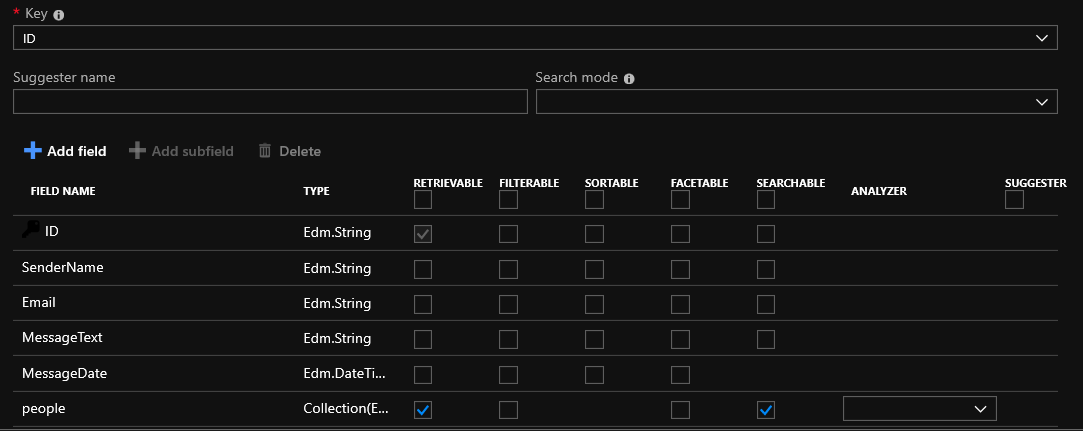
Zu diesem Zeitpunkt können Sie die Kontrollkästchen neben den Feldern in Ihrer Tabelle aktivieren oder dem Index ein neues Feld hinzufügen. Für alle Fälle werde ich die Möglichkeiten der Felder erläutern:
Abrufbar - Das Feld wird in den Suchergebnissen angezeigt
Filterbar - Der Feldwert kann gefiltert werden
Sortierbar - Sie können das Ergebnis nach diesem Feld sortieren
Facetable - eine Art Gruppierung nach bestimmten Merkmalen. Wenn Sie beispielsweise den folgenden Ausdruck facet = listPrice mit den Werten 10 | 25 | 100 | 500 | 1000 | 2500 verwenden, können Sie die folgenden Ergebnisse in Gruppen aufteilen
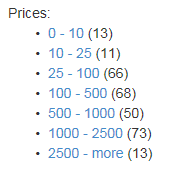
Durchsuchbar - In diesem Feld wird gesucht
Das Feld Analysator schlägt vor, einen Analysator für verschiedene Sprachen auszuwählen. Es werden 2 Versionen verwendet - Lucene und Microsoft . Um zu verstehen, was der Unterschied ist, müssen Sie verstehen, was der Unterschied zwischen den beiden folgenden Begriffen ist:
Stamming ist der Prozess, bei dem die Basis eines Wortes für ein bestimmtes Quellwort gefunden wird. Stamm (Englisch) - Stamm, Stamm, Herkunft. Stemming verwendet Algorithmen. Schneidet Wörter häufig ab, indem Suffixe und Endungen entfernt werden, um die Grundlage des Wortes zu erhalten.
Lemmatisierung ist der Prozess des Reduzierens einer Wortform auf ein Lemma - ihre normale (Vokabular-) Form. Das Lemma ist die kanonische Grundform des Wortes. Die Lemmatisierung verwendet eine Wörterbuchsuche, die verschiedene Formen von Wörtern enthält.
Der Lucene-Analysator verwendet Stemming. Microsoft Analyzer verwendet Lemmatisierung.
Wenn nichts ausgewählt ist, wird standardmäßig Lucene verwendet. Wenn Sie jedoch nach Daten in einer bestimmten Sprache suchen, ist es zweifellos besser, einen Analysator für diese Sprache zu verwenden.
Vorschlag - Mit dieser Option können Sie anhand der Anfangsbuchstaben der Suche Hinweise zu Dokumenten geben, die den eingegebenen Text enthalten.
Wenn Sie den Probester in Azure Search in der Clientanwendung verwenden, haben Sie zwei Möglichkeiten, ihn zu verwenden: den Counsester selbst oder die automatische Vervollständigung . Kurz gesagt, die Eingabeaufforderung schlägt die gesamte Zeile aus dem Tabellenfeld vollständig vor, und die automatische Vervollständigung bietet nur die Möglichkeit, ein Wort oder einen Ausdruck aus mehreren Wörtern zu vervollständigen. Der beste Artikel über die Unterschiede zwischen dem Eingabeaufforderungs- und dem Autocomplete-Modus wird im folgenden Artikel beschrieben: Autocomplete in Azure Search jetzt in der öffentlichen Vorschau Dieser Artikel enthält sehr visuelle Gifs.
In der Phase der Erstellung des Indexers müssen Sie eine Spalte mit hohem Wasserzeichen angeben. Dies ist ein Feld, das sich jedes Mal ändert, wenn ein Datensatz geändert wird. Normalerweise ist dies so etwas wie ein Feld mit dem Datum der letzten Änderung oder ein _ts-Feld in Cosmos DB. Wenn während der Indizierung der Feldwert geändert wird, ändert sich auch der Index.
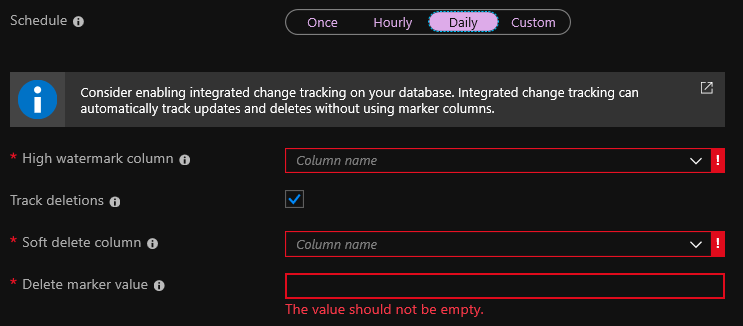
Löschungen verfolgen ist eine Option, um Einträge automatisch aus dem Index zu löschen. Dazu muss jedoch Soft Delete in Ihrer Datenbank konfiguriert sein. Wenn Sie Soft Delete verwenden, wird ein Datensatz beim Löschen nicht gelöscht, sondern einfach als gelöscht markiert. Die Standardoption besteht darin, das Feld isDeleted zur Datenbank hinzuzufügen und auf true zu setzen, wenn der Datensatz gelöscht wird.
Alternativ können Sie jedes Mal, wenn Sie einen Eintrag aus der Datenbank löschen, eine Löschanforderung aus der Suche an die Azure Search-API senden. In diesem Fall kann das Kontrollkästchen Trak-Löschungen weggelassen werden. Diese Option gefällt mir jedoch nicht wirklich, da der Datensatz im Index verbleibt, wenn die Löschanforderung nicht funktioniert. Für mich gibt es nicht genügend Möglichkeiten, den Index einmal in einem bestimmten Zeitraum vollständig neu zu erstellen.
Trotz aller Bequemlichkeit des Portals können Sie nach dem Erstellen einige neue Felder zum Index hinzufügen, die vorhandenen jedoch nicht ändern. Was tun, wenn Sie etwas ändern müssen? Sie können den Index neu erstellen. Löschen Sie die vorhandene und erstellen Sie eine neue mit den erforderlichen Änderungen. Das Portal zu benutzen, um dies zu tun, ist eine ziemlich trostlose Aufgabe. Ich benutze die API für diese Zwecke. Mit einer Anwendung wie Postman können Sie den Index JSON abrufen und damit eine Anforderung zur Indexerstellung schreiben. Es müssen nur kleine Änderungen vorgenommen werden (entfernen Sie beispielsweise die Systemfelder "@ odata.context" und "@ odata.etag").
Um mit der API arbeiten zu können, müssen Sie den Schlüssel aus dem Portal entnehmen, der dem Header jeder API-Anforderung hinzugefügt werden muss. Der Schlüssel wird hier genommen:
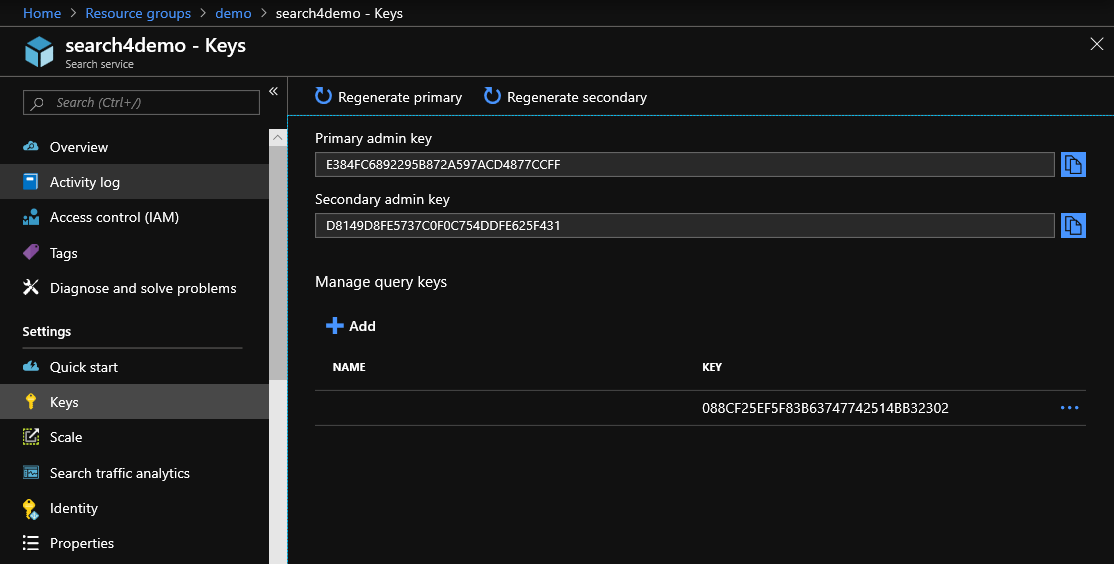
Eine Abfrage zum Abrufen von Indexdaten lautet:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
api-key: [admin key] muss zum Header hinzugefügt werden api-key: [admin key]
Das Erstellen eines Index ist mit einer der folgenden beiden Abfragen möglich:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
oder
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
In body müssen Sie JSON mit dem Inhalt des Index angeben. Die aktuellste Version ist im Moment 2019-05-06 und bevor sie für eine lange Zeit 2017-11-11 verwendet wurde
Wenn Sie die API verwenden, können Sie einige Suchfunktionen verwenden, die im Portal nicht verfügbar sind.
Um einigen Feldern bei der Suche Priorität einzuräumen, können Sie Bewertungsprofile verwenden .
Der folgende JSON, der der Anforderung hinzugefügt wurde, bietet dem Feld "Titel" einen doppelten Vorteil gegenüber dem Feld "Info":
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
Zusätzlich zur Möglichkeit, einigen Feldern mithilfe von Gewichten Priorität einzuräumen, können einige vordefinierte Funktionen verwendet werden: Frische, Größe, Abstand und Tag.
Frische wird nur mit DateTime-Feldern verwendet und ermöglicht es Ihnen, die neuesten Datensätze in der Suche aufzurufen. Die Größe wird mit int- und double-Feldern verwendet. Gut und dementsprechend ist diese Funktion gut für Felder geeignet, in denen Preise, die Anzahl der Downloads und andere numerische Informationen gespeichert sind. Die Entfernung wird nur bei Feldern wie Edm.GeographyPoint verwendet und bei einer Suche nach Entfernung von einem bestimmten Ort erhöht. Wenn Tag als Funktionstyp angegeben ist, werden Dokumente mit Tags, die in der Suchzeichenfolge angezeigt werden, bei der Suche ausgelöst.
Eine der beliebtesten Optionen ist das Abrufen der neuesten Dokumente bei einer Suche wie dieser:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Dokumente, deren documentDate-Feld das Datum der letzten sieben Tage enthält ("P7D"), werden aufgerufen.
Nachdem Sie ein Bewertungsprofil erstellt haben, können Sie dessen Namen in Anforderungen angeben. Nur in diesem Fall werden die erforderlichen Felder bei der Suche angezeigt.
Weitere Informationen finden Sie in der offiziellen Dokumentation: Hinzufügen von Bewertungsprofilen zu einem Azure Search-Index
Richtlinie zur Erkennung von Datenänderungen
Die API bietet etwas mehr Funktionen für die Datenquelle. Wie Sie oben lesen können, können Sie beim Erstellen einer Datenquelle ein Feld angeben, anhand dessen festgestellt werden kann, ob sich die Daten geändert haben. In Form von JSON sieht es so aus:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } soft delete policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Wenn Sie SQL Server verwenden und Ihre Datenbank die Änderungsverfolgung unterstützt, können gelöschte Datensätze automatisch aus dem Index gelöscht werden. Die Angabe von highWaterMarkColumnName ist in diesem Fall nicht erforderlich. Es reicht aus, SqlIntegratedChangeTrackingPolicy anstelle von HighWaterMarkChangeDetectionPolicy anzugeben
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
Es ist sehr bequem. Es gibt jedoch Nuancen, die es nicht ermöglichen, diese Funktion vollständig zu nutzen.
Erstens kann SqlIntegratedChangeTrackingPolicy nicht mit Ansichten verwendet werden. Zweitens sollte die Tabelle keine zusammengesetzten Primärschlüssel enthalten. Es versteht sich von selbst, dass die Version von SQL Server mehr oder weniger neu sein muss. Schließlich muss die Änderungsverfolgung für die Datenbank und die Tabellen aktiviert sein, die von der Suche verwendet werden. Für die Datenbank wird sie folgendermaßen aktiviert:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
Und für den Tisch so:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Das ist aber noch nicht alles. Es wird dringend empfohlen, die Snapshot-Isolation für die Basis zu aktivieren.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
Neben dem Tanzen mit einem Tamburin bei der Installation von Change Traking für die Datenbank ist für mich der Nachteil die Unfähigkeit, Ansichten zu verwenden. Daher muss ich normalerweise immer noch HighWaterMarkChangeDetectionPolicy verwenden
Datensuche
Standardmäßig verwendet die Azure-Suche eine einfache Abfragesyntax . Es mag nicht überraschend erscheinen, aber es ist ganz einfach:
wifi + luxus sucht gleichzeitig nach den Wörtern wifi und luxus
"Luxushotel" sucht nach dem Satz
wifi | Luxus sucht entweder nach dem Wort WLAN oder nach dem Wort Luxus
wifi –luxury sucht nach Texten mit dem Wort wifi, aber ohne das Wort luxus
lux sucht nach Wörtern, die mit lux beginnen
Es ist möglich, Suchregeln in Klammern zu kombinieren. Beispielsweise sucht die Motel + -Regel (WLAN | Luxus) nach dem Wort Motel und entweder nach dem Wort WLAN oder nach dem Wort Luxus
Es ist schön, dass Azure Search die Lucene- Syntax verwenden kann. Um es verwenden zu können, muss der Suchabfrage queryType = full hinzugefügt werden
Der Unterschied zwischen der Azure- und der klassischen Lucene-Syntax besteht nur in fehlender Reichweite.
In Azure Search können Sie also nicht: mod_date:[20020101 TO 20030101]
In Azure Search können Sie jedoch $ filter mit ODATA- Syntax verwenden. Hier ist ein Beispielfilter:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Filter können auch mit einfacher Abfragesyntax verwendet werden.
In Lucene wird die Logik „oder“ mit ODER oder || implementiert
Beide Werte können durch Angabe der Anweisung "und" mit: AND , && oder + ermittelt werden
Für "nicht" können Sie eine der folgenden Optionen verwenden : NICHT! oder -
Die Anweisung "nicht" hat eine gemeinsame Funktion sowohl für die einfache Syntax als auch für Lucene. Das Verhalten hängt vom Suchmodus ab, der sowohl in searchMode = all als auch in searchMode = any festgelegt werden kann (dieser Wert wird standardmäßig verwendet). In jedem Modus werden bei der Suche nach WLAN-Luxus Dokumente mit dem Wort WLAN oder Dokumente ohne das Wort Luxus gefunden. Im All-Modus werden auf dieselbe Anfrage Docks mit dem Wort WLAN und gleichzeitig ohne das Wort Luxus gefunden.
Schauen wir uns einige interessante Lucene-Funktionen an.
Mit der Fuzzy-Suche können Sie nach Wörtern suchen, die sich durch einen oder mehrere Buchstaben von der Suche unterscheiden. Das heißt, es hilft, mit Tippfehlern umzugehen. Wenn Sie beispielsweise nach "blau ~" oder "blau ~ 1" suchen, erhalten Sie "blau" und "blau" und sogar "Kleber". Gleichzeitig bedeutet eine Suche nach "Business ~ Analyst" Business oder Analyst
In der Nähe können Sie nach Wörtern suchen, die sich in der Nähe befinden. Zum Beispiel findet "Hotelflughafen" ~ 5 die Wörter "Hotel" und "Flughafen", die sich im Text nicht weiter als 5 Wörter voneinander befinden.
Mit Term Boosting können Sie die Priorität eines Wortes in der Suche festlegen. Beispiel: "rock ^ 2 electronic" sucht nach den Wörtern rock und electronic, aber Einträge mit dem Wort rock in der Suche werden oben angezeigt.
Reguläre Ausdrücke - mit regulären Ausdrücken. Alles hier entspricht der offiziellen Lucene Regex-Dokumentation. Sie finden sie unter folgendem Link . Bei der Suche müssen reguläre Ausdrücke zwischen Schrägstrichen "/" stehen. Zum Beispiel wie folgt: / [mh] otel /
Wenn Ihre Suchzeichenfolge Sonderzeichen enthält, müssen diese mit einem Backslash versehen werden. Beispielzeichen, die maskiert werden sollen: + - && ||! () {} [] ^ "~ *?: \ /
Die Suche kann mithilfe einer GET-Anforderung erfolgen. Das offizielle Beispiel lautet:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Sie können jedoch eine POST-Anforderung mit body verwenden. Wieder ein offizielles Beispiel:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Wenn Sie eine GET-Anforderung oder einen POST mit dem Datentyp application / x-www-form-urlencoded verwenden, müssen Sie unsichere und reservierte Zeichen codieren.
Symbole / ?: @ = & sind reserviert
Die Zeichen `` <> #% {} | \ ^ ~ [] sind unsicher.
Zum Beispiel wird das Symbol # zu% 23 und das Symbol? wird% 3F
Ein paar Links für Entwickler.
Wenn .NET ein Entwickler ist, können Sie das Microsoft.Azure.Search NuGet-Paket verwenden . Darüber hinaus gibt es Beispiele in NodeJS und Java .
Ein Beispiel für eine einfache Anwendung in .NET Core finden Sie hier. ASP.NET Core Azure-Suchbeispiel