Bis heute hat der Bitrix24-Dienst nicht Hunderte von Gigabit Verkehr, es gibt keine riesige Flotte von Servern (obwohl es natürlich viele gibt). Für viele Kunden ist es jedoch das Hauptwerkzeug für die Arbeit im Unternehmen. Es ist eine echte geschäftskritische Anwendung. Deshalb fallen - na ja, auf keinen Fall. Aber was ist, wenn der Sturz passiert ist, aber der Dienst so schnell „rebelliert“ hat, dass niemand etwas bemerkt hat? Und wie schaffen Sie es, ein Failover zu implementieren, ohne die Arbeitsqualität und die Anzahl der Kunden zu verlieren? Alexander Demidov, Director von Bitrix24 Cloud Services, berichtete in unserem Blog über die Entwicklung des Backup-Systems in den sieben Jahren seines Bestehens.

„Mit SaaS haben wir Bitrix24 vor 7 Jahren eingeführt. Die Hauptschwierigkeit war wahrscheinlich die folgende: Vor dem öffentlichen Start in Form von SaaS existierte dieses Produkt einfach im Format einer Box-Lösung. Kunden haben es bei uns gekauft, auf ihren Servern platziert, ein Unternehmensportal eingerichtet - eine gängige Lösung für Mitarbeiterkommunikation, Dateispeicherung, Aufgabenverwaltung, CRM - das ist alles. Und bis 2012 haben wir beschlossen, es als SaaS zu starten, es selbst zu verwalten und Fehlertoleranz und Zuverlässigkeit zu gewährleisten. Wir haben dabei Erfahrungen gesammelt, weil wir sie bis dahin einfach nicht hatten - wir waren nur Softwarehersteller, keine Dienstleister.
Beim Starten des Dienstes haben wir verstanden, dass das Wichtigste darin besteht, die Fehlertoleranz, Zuverlässigkeit und ständige Verfügbarkeit des Dienstes sicherzustellen, denn wenn Sie eine einfache reguläre Website haben, zum Beispiel ein Geschäft, das von Ihnen gefallen ist und eine Stunde liegt - nur Sie selbst leiden, verlieren Sie Aufträge Sie verlieren Kunden, aber für Ihren Kunden selbst - für ihn ist dies nicht sehr kritisch. Er war natürlich verärgert, ging aber und kaufte auf einer anderen Seite. Und wenn dies eine Anwendung ist, an die alle Arbeiten innerhalb des Unternehmens, der Kommunikation und der Lösungen gebunden sind, ist es das Wichtigste, das Vertrauen der Benutzer zu gewinnen, dh sie nicht im Stich zu lassen und nicht zu fallen. Weil die ganze Arbeit aufstehen kann, wenn etwas im Inneren nicht funktioniert.
Bitrix. 24 als SaaS
Der erste Prototyp, den wir ein Jahr vor dem öffentlichen Start im Jahr 2011 zusammengebaut haben. In ungefähr einer Woche versammelt, geschaut, verdreht - er arbeitete sogar. Das heißt, es war möglich, in das Formular zu gehen, dort den Namen des Portals einzugeben, ein neues Portal wurde entfaltet, eine Benutzerbasis wurde eingerichtet. Wir haben es uns angesehen, das Produkt im Prinzip bewertet, ausgeschaltet und ein Jahr später fertiggestellt. Weil wir eine große Aufgabe hatten: Wir wollten nicht zwei verschiedene Codebasen erstellen, wir wollten kein separates Box-Produkt, keine separaten Cloud-Lösungen unterstützen - wir wollten dies alles innerhalb desselben Codes tun.

Eine typische Webanwendung zu dieser Zeit ist ein Server, auf dem PHP-Code ausgeführt wird, die MySQL-Basis, Dateien werden heruntergeladen, Dokumente und Bilder werden in den Upload-Daddy gestellt - nun, alles funktioniert. Leider ist es unmöglich, einen kritisch nachhaltigen Webdienst zu betreiben. Der verteilte Cache wird dort nicht unterstützt, die Datenbankreplikation wird nicht unterstützt.
Wir haben die Anforderungen formuliert: Diese Fähigkeit, sich an verschiedenen Standorten zu befinden, die Replikation zu unterstützen, idealerweise in verschiedenen geografisch verteilten Rechenzentren. Trennen Sie die Logik des Produkts und in der Tat die Speicherung von Daten. Dynamisch in der Lage sein, entsprechend der Last zu skalieren, machen in der Regel die Statik. Aufgrund dieser Überlegungen gab es tatsächlich Anforderungen an das Produkt, das wir gerade im Laufe des Jahres entwickelt haben. Während dieser Zeit haben wir auf einer Plattform, die sich als einheitlich herausstellte - für Boxed-Lösungen, für unseren eigenen Service - Unterstützung für die Dinge geleistet, die wir brauchten. Unterstützung für die MySQL-Replikation auf der Ebene des Produkts selbst: Das heißt, der Entwickler, der den Code schreibt, denkt nicht darüber nach, wie seine Anforderungen verteilt werden, er verwendet unsere API, und wir können Schreib- und Leseanforderungen korrekt zwischen Mastern und Slaves verteilen.
Wir haben Unterstützung auf Produktebene für verschiedene Cloud-Objektspeicher bereitgestellt: Google Storage, Amazon S3, - Plus, Unterstützung für Open Stack Swift. Daher war es sowohl für uns als Service als auch für Entwickler, die mit einer Boxed-Lösung arbeiten, praktisch: Wenn sie nur unsere API für die Arbeit verwenden, denken sie nicht, wo die Datei gespeichert wird, weder lokal im Dateisystem noch im Objektdateispeicher .
Infolgedessen haben wir sofort beschlossen, auf der Ebene eines gesamten Rechenzentrums zu reservieren. 2012 haben wir vollständig in Amazon AWS gestartet, da wir bereits Erfahrung mit dieser Plattform hatten - unsere eigene Website wurde dort gehostet. Wir waren von der Tatsache angezogen, dass es in jeder Region in Amazon mehrere Zugangszonen gibt - tatsächlich (in ihrer Terminologie) mehrere Rechenzentren, die mehr oder weniger unabhängig voneinander sind und es uns ermöglichen, auf der Ebene eines gesamten Rechenzentrums zu reservieren: if es schlägt plötzlich fehl, die Master-Master-Datenbanken werden repliziert, die Webanwendungsserver werden reserviert und die statische Daten werden in den s3-Objektspeicher verschoben. Die Last ist ausgeglichen - zu dieser Zeit der Amazonas-Elb, aber wenig später kamen wir zu unseren eigenen Balancern, weil wir eine komplexere Logik brauchten.
Was sie wollten, haben sie bekommen ...
Alle grundlegenden Dinge, die wir bereitstellen wollten - die Fehlertoleranz der Server selbst, Webanwendungen, Datenbanken - alles hat gut funktioniert. Das einfachste Szenario: Wenn einige der Webanwendungen fehlschlagen, ist alles einfach - sie werden aus dem Gleichgewicht genommen.

Der Maschinenausgleicher (damals war es ein Amazonas-Elb), der die Maschine selbst als ungesund eingestuft hat, hat die Lastverteilung auf ihnen ausgeschaltet. Die automatische Skalierung im Amazonasgebiet funktionierte: Als die Last zunahm, wurden der Autoskalierungsgruppe neue Autos hinzugefügt, die Ladung wurde auf neue Autos verteilt - alles war in Ordnung. Bei unseren Balancern ist die Logik ungefähr dieselbe: Wenn dem Anwendungsserver etwas passiert, entfernen wir Anforderungen von ihm, werfen diese Computer aus, starten neue und arbeiten weiter. Das Schema für all diese Jahre hat sich ein wenig geändert, funktioniert aber weiterhin: Es ist einfach, verständlich und es gibt keine Schwierigkeiten damit.
Wir arbeiten auf der ganzen Welt, die Spitzenlast der Kunden ist völlig anders, und wir sollten in der Lage sein, jederzeit bestimmte Wartungsarbeiten mit allen Komponenten unseres Systems durchzuführen - unsichtbar für die Kunden. Daher haben wir die Möglichkeit, die Datenbank von der Arbeit herunterzufahren und die Last im zweiten Rechenzentrum neu zu verteilen.
Wie funktioniert das alles? - Wir schalten den Datenverkehr auf ein funktionierendes Rechenzentrum um. Wenn es sich um einen Unfall in einem Rechenzentrum handelt. Wenn es sich um unsere geplante Arbeit mit einer Basis handelt, werden wir Teil des Datenverkehrs, der diese Clients bedient, in ein zweites Rechenzentrum umschalten Replikation. Wenn Sie neue Maschinen für Webanwendungen benötigen, werden diese automatisch gestartet, da die Belastung des zweiten Rechenzentrums gestiegen ist. Wir beenden die Arbeit, die Replikation wird wiederhergestellt und wir geben die gesamte Last zurück. Wenn wir einige Arbeiten im zweiten Domänencontroller spiegeln müssen, z. B. Systemaktualisierungen installieren oder die Einstellungen in der zweiten Datenbank ändern müssen, wiederholen wir im Allgemeinen dasselbe, nur in die andere Richtung. Und wenn dies ein Unfall ist, dann machen wir alles auf einfache Weise: Im Überwachungssystem verwenden wir den Event-Handler-Mechanismus. Wenn mehrere Überprüfungen für uns funktionieren und der Status kritisch wird, wird dieser Handler gestartet, ein Handler, der diese oder jene Logik ausführen kann. Für jede Datenbank haben wir registriert, welcher Server für sie ein Failover ist und wo Sie den Datenverkehr wechseln müssen, wenn er nicht verfügbar ist. Wir - wie es sich historisch entwickelt hat - verwenden in der einen oder anderen Form Nagios oder eine seiner Gabeln. Im Prinzip gibt es ähnliche Mechanismen in fast jedem Überwachungssystem. Wir verwenden noch nichts Komplizierteres, aber vielleicht werden wir es eines Tages tun. Jetzt wird die Überwachung durch Unzugänglichkeit ausgelöst und kann etwas umschalten.
Haben wir alles reserviert?
Wir haben viele Kunden aus den USA, viele Kunden aus Europa, viele Kunden, die näher am Osten liegen - Japan, Singapur und so weiter. Natürlich ein großer Teil der Kunden in Russland. Das heißt, Arbeit ist weit davon entfernt, in einer Region zu sein. Benutzer möchten eine schnelle Antwort, es gibt Anforderungen für die Einhaltung verschiedener lokaler Gesetze, und innerhalb jeder Region reservieren wir zwei Rechenzentren. Außerdem gibt es einige zusätzliche Dienste, die wiederum bequem in einer Region platziert werden können - für Kunden, die sich in dieser Region befinden Region Arbeit. REST-Handler, Autorisierungsserver, sie sind für den gesamten Client weniger kritisch. Sie können mit einer kleinen akzeptablen Verzögerung zwischen ihnen wechseln, möchten jedoch keine Fahrräder erfinden, wie sie überwacht werden und was mit ihnen zu tun ist. Daher versuchen wir maximal, vorhandene Lösungen zu nutzen und keine Kompetenz für zusätzliche Produkte zu entwickeln. Und irgendwo verwenden wir trivialerweise das Umschalten auf DNS-Ebene und bestimmen die Lebendigkeit des Dienstes mit denselben DNS. Amazon verfügt über einen Route 53-Dienst, der jedoch nicht nur DNS-Daten enthält, sondern auch viel flexibler und bequemer ist. Mithilfe dieser Funktion können Sie geoverteilte Dienste mit Geolokalisierung erstellen, wenn Sie damit bestimmen, woher der Client stammt, und ihnen bestimmte Datensätze geben. Mit ihm können Sie Failover-Architekturen erstellen. Dieselben Integritätsprüfungen werden in Route 53 selbst konfiguriert. Sie geben überwachte Endpunkte an, legen Metriken fest und geben an, welche Protokolle die Lebensdauer des Dienstes bestimmen - tcp, http, https; Legen Sie die Häufigkeit der Überprüfungen fest, mit denen festgestellt wird, ob der Dienst aktiv ist oder nicht. Und in der DNS selbst schreiben Sie vor, was primär sein soll, was sekundär sein soll, wo gewechselt werden soll, wenn die Integritätsprüfung innerhalb der Route 53 ausgelöst wird. All dies kann mit einigen anderen Tools durchgeführt werden, aber was ist bequemer - wir haben es einmal eingerichtet und denken dann nicht darüber nach wie wir prüfen, wie wir wechseln: alles funktioniert von selbst.
Das erste „aber“ : Wie und wie reserviert man die Route 53 selbst? Passiert es, wenn ihm etwas passiert? Glücklicherweise sind wir noch nie auf diesen Rechen getreten, aber wieder werde ich vor mir eine Geschichte haben, warum wir dachten, dass wir noch reservieren müssen. Hier legen wir den Strohhalm im Voraus. Mehrmals am Tag entladen wir alle Zonen auf Route 53 vollständig. Mit der Amazon-API können sie sicher an JSON gesendet werden. Wir haben mehrere redundante Server eingerichtet, auf denen wir sie konvertieren, in Form von Konfigurationen hochladen und grob gesagt eine Sicherungskonfiguration haben. In diesem Fall können wir es schnell manuell bereitstellen, ohne dass die DNS-Einstellungsdaten verloren gehen.
Das zweite "aber" : Was ist auf diesem Bild nicht reserviert? Der Balancer selbst! Wir haben die Verteilung der Kunden nach Regionen sehr einfach gemacht. Wir haben die Domänen bitrix24.ru, bitrix24.com und .de - jetzt gibt es 13 verschiedene Domänen, die in sehr unterschiedlichen Zonen funktionieren. Wir sind zu Folgendem gekommen: Jede Region hat ihre eigenen Balancer. Die Verteilung nach Regionen ist bequemer, je nachdem, wo sich die Spitzenlast im Netzwerk befindet. Wenn dies ein Fehler auf der Ebene eines Balancers ist, wird er einfach außer Betrieb genommen und aus DNS entfernt. Wenn bei einer Gruppe von Balancern ein Problem auftritt, sind diese an anderen Standorten reserviert, und das Umschalten zwischen ihnen erfolgt auf derselben Route53, da aufgrund eines kurzen ttl das Umschalten maximal 2, 3, 5 Minuten dauert.
Das dritte "aber" : Was wurde noch nicht reserviert? S3, richtig. Wir haben die Dateien, die von Benutzern in s3 gespeichert werden, platziert und aufrichtig geglaubt, dass sie panzerbrechend sind und dass dort nichts reserviert werden muss. Aber die Geschichte zeigt, was anders passiert. Im Allgemeinen beschreibt Amazon S3 als einen grundlegenden Dienst, da Amazon selbst S3 zum Speichern von Bildern von Maschinen, Konfigurationen, AMI-Bildern, Schnappschüssen ... verwendet. Und wenn s3 abstürzt, wie es in diesen 7 Jahren einmal passiert ist, wie viel bitrix24 wir verwendet haben, folgt ein Fan zieht eine Menge von allem - Unzugänglichkeit beim Starten von virtuellen Maschinen, Fehlfunktionen der API und so weiter.
Und S3 kann fallen - es ist einmal passiert. Daher kamen wir zu folgendem Schema: Vor einigen Jahren gab es in Russland keine ernsthaften öffentlichen Lager für Objekte, und wir überlegten, ob wir etwas Eigenes tun könnten ... Glücklicherweise haben wir damit nicht begonnen, weil wir uns mit dieser Prüfung befassen würden, die wir nicht durchgeführt haben besitzen, und hätte es wahrscheinlich getan. Jetzt hat Mail.ru s3-kompatible Speicher, Yandex hat es und eine Reihe von Anbietern haben es noch. Als Ergebnis kamen wir zu dem Schluss, dass wir erstens ein Backup und zweitens die Möglichkeit haben möchten, mit lokalen Kopien zu arbeiten. Für eine bestimmte russische Region verwenden wir den Mail.ru Hotbox-Dienst, der mit s3 kompatibel ist. Wir brauchten keine ernsthaften Änderungen am Code in der Anwendung und haben den folgenden Mechanismus vorgenommen: In s3 gibt es Trigger, die beim Erstellen / Löschen von Objekten funktionieren. Amazon hat einen Dienst wie Lambda - dies ist serverloser laufender Code, der nur ausgeführt wird wenn bestimmte Trigger ausgelöst werden.
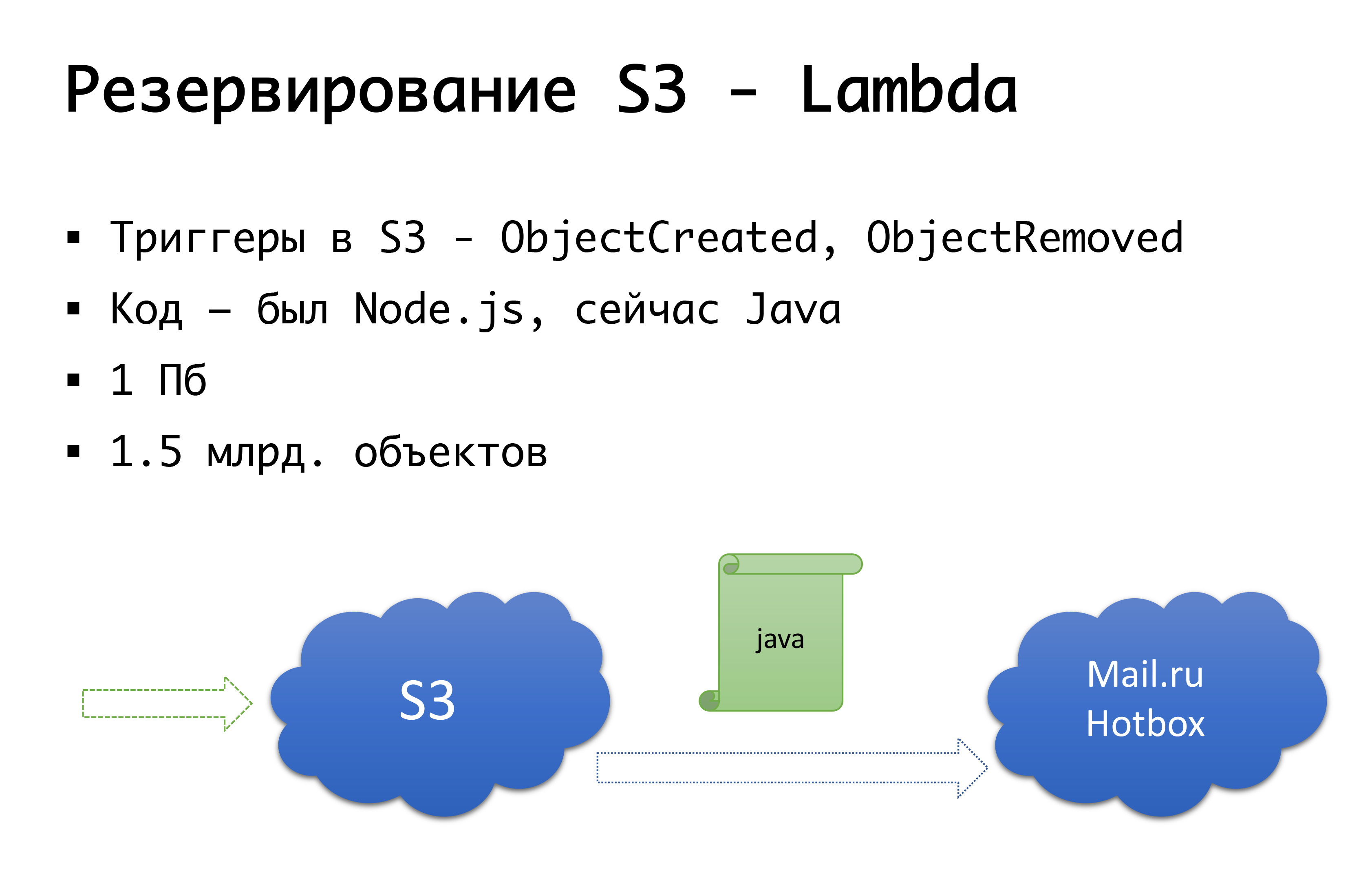
Wir haben es ganz einfach gemacht: Wenn unser Trigger ausgelöst wird, führen wir den Code aus, der das Objekt in das Mail.ru-Repository kopiert. Um vollständig mit lokalen Kopien von Daten arbeiten zu können, benötigen wir auch eine umgekehrte Synchronisierung, damit Clients im russischen Segment mit einem Speicher arbeiten können, der näher an ihnen liegt. Mail ist dabei, die Trigger in seinem Repository zu vervollständigen - es wird möglich sein, eine umgekehrte Synchronisation bereits auf Infrastrukturebene durchzuführen, aber im Moment tun wir dies auf der Ebene unseres eigenen Codes. Wenn wir sehen, dass der Client eine Art Datei abgelegt hat, stellen wir das Ereignis auf Codeebene in die Warteschlange, verarbeiten es und führen die umgekehrte Replikation durch. Warum ist es so schlimm: Wenn wir mit unseren Objekten außerhalb unseres Produkts arbeiten, dh auf externe Weise, werden wir dies nicht berücksichtigen. Daher warten wir bis zum Ende, wenn Trigger auf Speicherebene angezeigt werden, sodass das zu uns gekommene Objekt unabhängig davon, von wo aus wir den Code ausführen, in die andere Richtung kopiert wird.
Auf Codeebene werden für jeden Client beide Repositorys registriert: eines wird als Hauptrepository betrachtet, das andere als Backup. Wenn alles in Ordnung ist, arbeiten wir mit dem Speicher, der näher bei uns liegt: Das heißt, unsere Kunden bei Amazon arbeiten mit S3, und diejenigen, die in Russland arbeiten, arbeiten mit Hotbox. Wenn das Kontrollkästchen funktioniert, sollte das Failover eine Verbindung zu uns herstellen, und wir werden die Clients auf einen anderen Speicher umstellen. Wir können dieses Flag unabhängig nach Region setzen und es hin und her schalten. In der Praxis haben wir dies noch nicht verwendet, aber wir haben uns diesen Mechanismus vorgestellt und wir denken, dass wir eines Tages genau diesen Schalter brauchen und verwenden werden. Sobald es schon passiert ist.
Oh, und dein Amazon ist entkommen ...
Dieser April ist der Jahrestag des Starts der Telegrammsperren in Russland. Der am stärksten betroffene Anbieter, der darunter fiel, ist Amazon. Und leider litten russische Unternehmen, die auf der ganzen Welt tätig waren, mehr.
Wenn das Unternehmen global ist und Russland ein sehr kleines Segment ist, 3-5% - auf die eine oder andere Weise können Sie sie spenden.
Wenn es sich um ein rein russisches Unternehmen handelt - ich bin sicher, dass Sie es vor Ort suchen müssen -, ist es nur so, dass die Benutzer selbst bequem und komfortabel sind und weniger Risiken bestehen.
Und wenn dies ein Unternehmen ist, das global arbeitet und ungefähr den gleichen Anteil an Kunden aus Russland und irgendwo auf der Welt hat? Die Konnektivität der Segmente ist wichtig und sie müssen trotzdem miteinander arbeiten.
Ende März 2018 sandte Roskomnadzor einen Brief an die größten Betreiber, in dem er erklärte, dass sie planen, mehrere Millionen IP-Amazon zu blockieren, um ... den Zello-Messenger zu blockieren. Dank dieser Anbieter haben sie den Brief erfolgreich an alle weitergegeben, und es bestand Einigkeit darüber, dass die Konnektivität mit Amazon auseinanderfallen könnte. Es war Freitag, wir rannten panisch zu den Kollegen von servers.ru mit den Worten: „Freunde, wir brauchen mehrere Server, die nicht in Russland, nicht in Amazon, sondern zum Beispiel irgendwo in Amsterdam sein werden.“ Um zumindest irgendwie unseren eigenen VPN und Proxy für einige Endpunkte dort zu platzieren, die wir überhaupt nicht beeinflussen können, zum Beispiel Endponts desselben S3 - wir können nicht versuchen, einen neuen Dienst zu eröffnen und eine andere IP zu erhalten Sie müssen noch dorthin gelangen. In wenigen Tagen haben wir diese Server eingerichtet, erhöht und im Allgemeinen auf den Start der Sperren vorbereitet. Es ist merkwürdig, dass der ILV angesichts des Hype und der erhöhten Panik sagte: "Nein, wir werden jetzt nichts blockieren." (Dies ist jedoch genau bis zu dem Moment, als sie begannen, Telegramme zu blockieren.) Nachdem wir die Bypass-Optionen eingerichtet und festgestellt hatten, dass sie das Schloss nicht betreten hatten, haben wir das Ganze dennoch nicht abgebaut. Also nur für den Fall.

Und im Jahr 2019 leben wir immer noch unter den Bedingungen von Schlössern. Ich habe letzte Nacht nachgesehen: Ungefähr eine Million IP sind weiterhin blockiert. Zwar hat Amazon fast vollständig entsperrt, in der Spitze wurden 20 Millionen Adressen erreicht ... Im Allgemeinen ist die Realität, dass Konnektivität, gute Konnektivität - möglicherweise nicht. Auf einmal. Es kann nicht aus technischen Gründen sein - Brände, Bagger, all das. Oder, wie wir gesehen haben, nicht ganz technisch. Daher kann jemand, der groß und groß ist, mit seinem eigenen AS-Kami es wahrscheinlich auf andere Weise steuern - direkte Verbindung und andere Dinge befinden sich bereits auf der l2-Ebene. Aber in einer einfachen Version, genau wie wir oder noch kleiner, können Sie für alle Fälle Redundanz auf der Ebene von Servern haben, die an anderer Stelle angehoben wurden, im Voraus vpn, Proxy konfiguriert, mit der Möglichkeit, Konfigurationen in den Segmenten, in denen Sie über kritische Konnektivität verfügen, schnell zu wechseln . Dies war für uns mehr als einmal nützlich, als Amazon-Sperren gestartet wurden, haben wir im schlimmsten Fall den S3-Verkehr durchgelassen, aber nach und nach ging alles schief.
Und wie reserviert man ... den ganzen Anbieter?
Jetzt haben wir kein Szenario für den Fall eines Ausfalls des gesamten Amazonas. Wir haben ein ähnliches Szenario für Russland. Wir in Russland wurden von einem Anbieter gehostet, von dem wir uns für mehrere Standorte entschieden haben. Und vor einem Jahr sind wir auf ein Problem gestoßen: Obwohl es sich um zwei Rechenzentren handelt, kann es bereits Probleme auf der Ebene der Netzwerkkonfiguration des Anbieters geben, die beide Rechenzentren ohnehin betreffen. Und wir können an beiden Standorten unzugänglich werden. Das ist natürlich passiert. Wir haben schließlich die Architektur im Inneren neu definiert. Es hat sich nicht viel geändert, aber für Russland haben wir jetzt zwei Standorte, die nicht ein Anbieter, sondern zwei verschiedene sind. Wenn einer von ihnen ausfällt, können wir zu einem anderen wechseln.
Hypothetisch erwägen wir, dass Amazon auf der Ebene eines anderen Anbieters reserviert. Vielleicht Google, vielleicht jemand anderes ... Aber bisher haben wir in der Praxis beobachtet, dass Abstürze auf der Ebene einer ganzen Region ziemlich selten sind, wenn Amazon auf derselben Ebene der Verfügbarkeitszone abstürzt. Daher haben wir theoretisch die Idee, dass wir vielleicht eine Reservierung machen werden "Amazon ist nicht Amazon", aber in der Praxis existiert dies noch nicht.
Ein paar Worte zur Automatisierung
Benötigen Sie immer Automatisierung? Es ist angebracht, an den Mahn-Krüger-Effekt zu erinnern. Auf der x-Achse unser Wissen und unsere Erfahrung, die wir gewinnen, und auf der y-Achse das Vertrauen in unser Handeln. Zuerst wissen wir nichts und sind uns überhaupt nicht sicher. Dann wissen wir ein wenig und werden mega-selbstbewusst - dies ist der sogenannte "Höhepunkt der Dummheit", der durch das Bild "Demenz und Mut" gut veranschaulicht wird. Weiter haben wir schon ein wenig gelernt und sind bereit, in die Schlacht zu ziehen. Dann treten wir auf einen mega-ernsten Rechen und fallen in ein Tal der Verzweiflung, wenn wir etwas zu wissen scheinen, aber tatsächlich wissen wir nicht viel. Wenn Sie dann Erfahrungen sammeln, werden wir selbstbewusster.
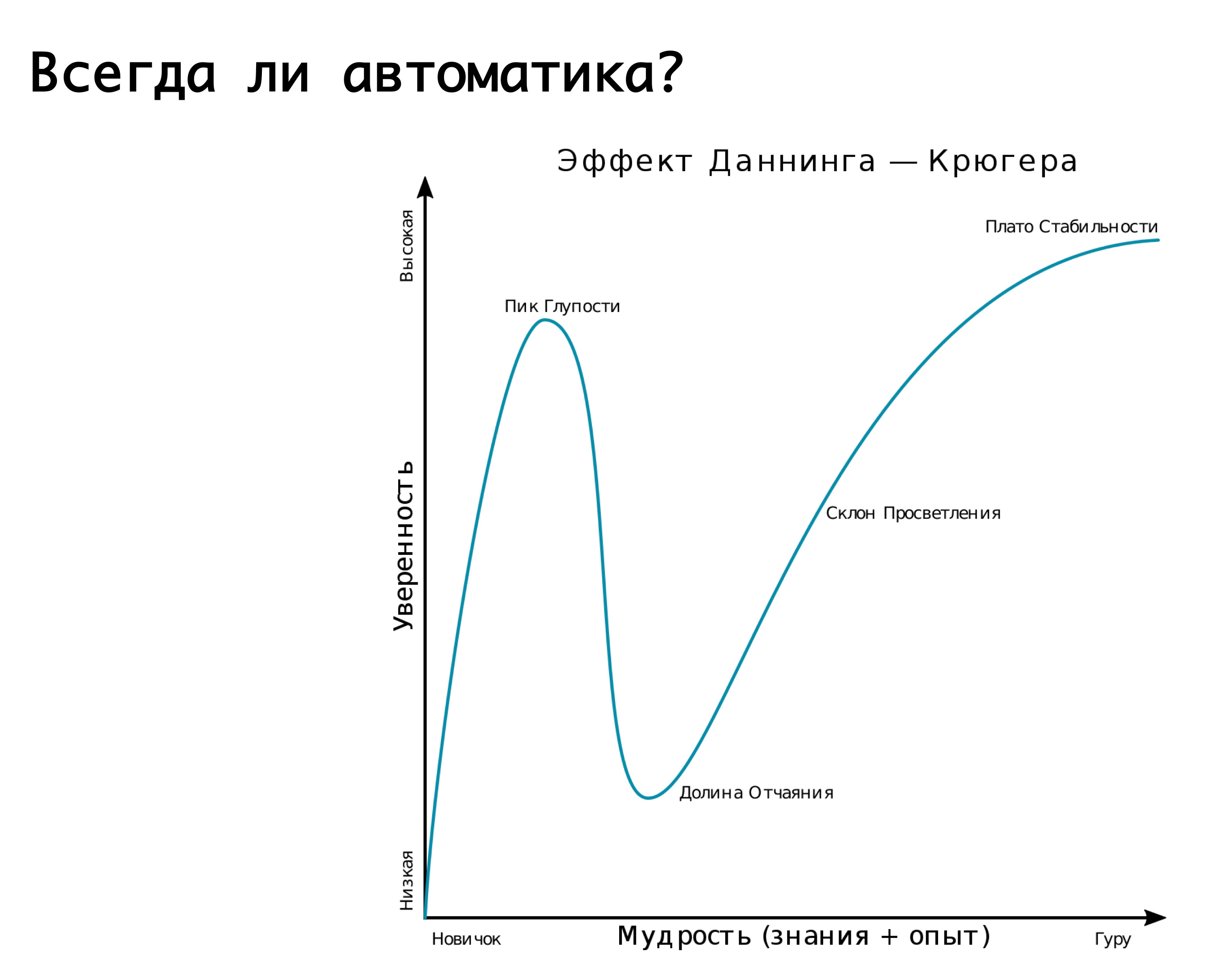
Unsere Logik über verschiedene automatische Umschaltungen auf den einen oder anderen Unfall wird in dieser Grafik sehr gut beschrieben. — , . , , , . -: false positive, - , , -, . , - — . , . , . Aber! , , , , , , …
Fazit
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
Ein vernünftiger Kompromiss zwischen Perfektionismus und realen Kräften, Zeit und Geld, die Sie für das Programm ausgeben können, das Sie letztendlich haben werden.Dieser Text ist eine ergänzende und erweiterte Version des Berichts von Alexander Demidov auf der Konferenz Uptime Day 4 .