Webanwendungen sind mittlerweile weit verbreitet, und HTTP macht den Löwenanteil aller Transportprotokolle aus. Die meisten von ihnen untersuchen die Nuancen der Entwicklung von Webanwendungen und achten kaum auf das Betriebssystem, auf dem diese Anwendungen tatsächlich ausgeführt werden. Die Trennung von Entwicklung (Dev) und Betrieb (Ops) machte die Sache nur noch schlimmer. Mit der Verbreitung der DevOps-Kultur beginnen Entwickler jedoch, die Verantwortung für das Starten ihrer Anwendungen in der Cloud zu übernehmen. Daher ist es für sie sehr nützlich, sich gründlich mit dem Betriebssystem-Backend vertraut zu machen. Dies ist besonders nützlich, wenn Sie versuchen, ein System für Tausende oder Zehntausende gleichzeitiger Verbindungen bereitzustellen.
Einschränkungen bei Webdiensten sind Einschränkungen in anderen Anwendungen sehr ähnlich. Ob Load Balancer oder Datenbankserver, alle diese Anwendungen haben ähnliche Probleme in einer Hochleistungsumgebung. Wenn Sie diese grundlegenden Einschränkungen kennen und wissen, wie Sie sie im Allgemeinen überwinden können, können Sie die Leistung und Skalierbarkeit Ihrer Webanwendungen bewerten.
Ich schreibe diese Artikelserie als Antwort auf Fragen junger Entwickler, die gut informierte Systemarchitekten werden möchten. Es ist unmöglich, die Methoden zur Optimierung von Linux-Anwendungen klar zu verstehen, ohne auf die Grundlagen ihrer Funktionsweise auf Betriebssystemebene einzugehen. Obwohl es viele Arten von Anwendungen gibt, möchte ich in dieser Serie Netzwerkanwendungen untersuchen, nicht Desktop-Anwendungen wie einen Browser oder einen Texteditor. Dieses Material richtet sich an Entwickler und Architekten, die verstehen möchten, wie Linux- oder Unix-Programme funktionieren und wie sie für eine hohe Leistung strukturiert werden.
Linux ist ein
Server- Betriebssystem, und meistens werden Ihre Anwendungen auf diesem bestimmten Betriebssystem ausgeführt. Obwohl ich "Linux" sage, können Sie die meiste Zeit davon ausgehen, dass alle Unix-ähnlichen Betriebssysteme im Allgemeinen gemeint sind. Ich habe den zugehörigen Code jedoch nicht auf anderen Systemen getestet. Wenn Sie also an FreeBSD oder OpenBSD interessiert sind, kann das Ergebnis variieren. Wenn ich etwas Linux-spezifisches ausprobiere, weise ich darauf hin.
Obwohl Sie dieses Wissen verwenden können, um eine Anwendung von Grund auf neu zu erstellen, und sie perfekt optimiert wird, ist es besser, dies nicht zu tun. Wenn Sie einen neuen Webserver in C oder C ++ für die Geschäftsanwendung Ihres Unternehmens schreiben, ist dies möglicherweise Ihr letzter Arbeitstag. Die Kenntnis der Struktur dieser Anwendungen hilft jedoch bei der Auswahl vorhandener Programme. Sie können prozessbasierte Systeme mit threadbasierten und ereignisbasierten Systemen vergleichen. Sie werden verstehen und verstehen, warum Nginx besser funktioniert als Apache httpd, warum eine Tornado-basierte Python-Anwendung mehr Benutzer bedienen kann als eine Django-basierte Python-Anwendung.
ZeroHTTPd: Lernwerkzeug
ZeroHTTPd ist ein Webserver, den ich in C als Trainingstool von Grund auf neu geschrieben habe. Es gibt keine externen Abhängigkeiten, einschließlich des Zugriffs auf Redis. Wir führen unsere eigenen Redis-Routinen aus. Siehe unten für weitere Details.
Obwohl wir die Theorie lange diskutieren konnten, gibt es nichts Besseres, als Code zu schreiben, auszuführen und alle Serverarchitekturen miteinander zu vergleichen. Dies ist die naheliegendste Methode. Daher werden wir mit jedem Modell einen einfachen ZeroHTTPd-Webserver schreiben: basierend auf Prozessen, Threads und Ereignissen. Lassen Sie uns jeden dieser Server überprüfen und sehen, wie sie im Vergleich zueinander funktionieren. ZeroHTTPd ist in einer einzelnen C-Datei implementiert. Der ereignisbasierte Server enthält
uthash , eine hervorragende Implementierung von Hash-Tabellen, die in einer einzelnen Header-Datei
geliefert wird. In anderen Fällen gibt es keine Abhängigkeiten, um das Projekt nicht zu komplizieren.
Der Code enthält viele Kommentare, um das Problem zu lösen. ZeroHTTPd ist ein einfacher Webserver in wenigen Codezeilen und ein minimales Framework für die Webentwicklung. Es verfügt nur über eingeschränkte Funktionen, kann jedoch statische Dateien und sehr einfache „dynamische“ Seiten erstellen. Ich muss sagen, dass ZeroHTTPd gut geeignet ist, um zu lernen, wie man leistungsstarke Linux-Anwendungen erstellt. Im Großen und Ganzen warten die meisten Webdienste auf Anfragen, prüfen sie und verarbeiten sie. Genau das wird ZeroHTTPd tun. Dies ist ein Lernwerkzeug, kein Produktionswerkzeug. Er kann nicht gut mit Fehlern
strcpy und verfügt wahrscheinlich nicht über die besten Sicherheitspraktiken (oh ja, ich habe
strcpy ) oder
strcpy abstruse Tricks. Aber ich hoffe, er macht seine Arbeit gut.
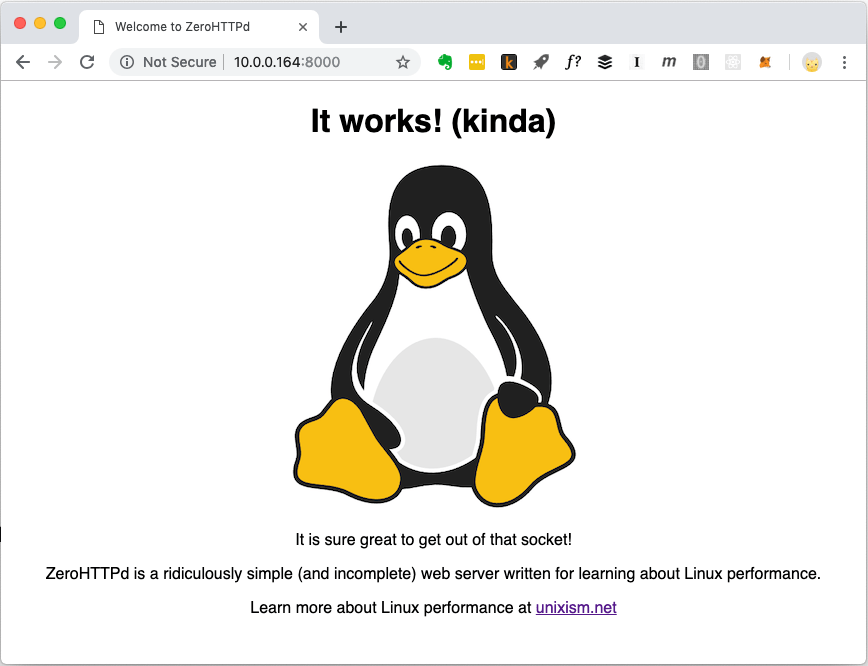 ZeroHTTPd-Homepage. Es können verschiedene Dateitypen einschließlich Bilder erstellt werden
ZeroHTTPd-Homepage. Es können verschiedene Dateitypen einschließlich Bilder erstellt werdenGästebuchanwendung
Moderne Webanwendungen sind normalerweise nicht auf statische Dateien beschränkt. Sie haben komplexe Interaktionen mit verschiedenen Datenbanken, Caches usw. Daher erstellen wir eine einfache Webanwendung namens "Gästebuch", in der Besucher Einträge unter ihrem Namen hinterlassen. Das Gästebuch speichert die zuvor verbliebenen Einträge. Es gibt auch einen Besucherschalter am Ende der Seite.
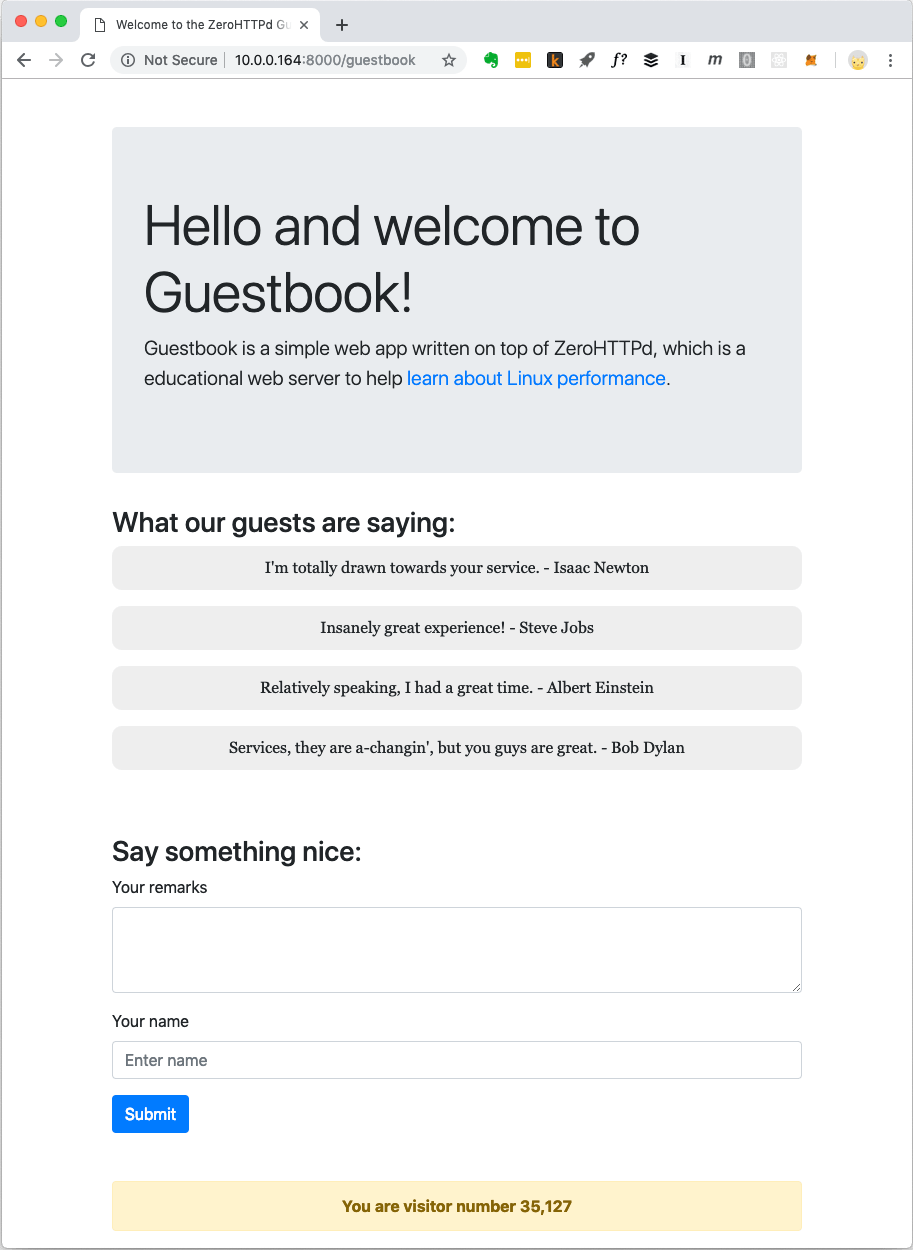 Gästebuch-Webanwendung ZeroHTTPd
Gästebuch-Webanwendung ZeroHTTPdDer Besucherschalter und die Gästebucheinträge werden in Redis gespeichert. Für die Kommunikation mit Redis werden eigene Prozeduren implementiert, die von einer externen Bibliothek unabhängig sind. Ich bin kein großer Fan von rollendem Code aus eigenem Anbau, wenn es öffentlich verfügbare und gut getestete Lösungen gibt. Das Ziel von ZeroHTTPd ist es jedoch, die Linux-Leistung und den Zugriff auf externe Dienste zu untersuchen, während die Bearbeitung von HTTP-Anforderungen die Leistung erheblich beeinträchtigt. Wir müssen die Kommunikation mit Redis in jeder unserer Serverarchitekturen vollständig steuern. In einer Architektur verwenden wir blockierende Aufrufe, in anderen verwenden wir ereignisbasierte Prozeduren. Die Verwendung einer externen Redis-Clientbibliothek gibt eine solche Kontrolle nicht. Darüber hinaus führt unser kleiner Redis-Client nur wenige Funktionen aus (Abrufen, Setzen und Erhöhen eines Schlüssels; Abrufen und Hinzufügen eines Arrays). Darüber hinaus ist das Redis-Protokoll außergewöhnlich elegant und einfach. Er muss nicht einmal speziell unterrichtet werden. Die Tatsache, dass das Protokoll die gesamte Arbeit in etwa hundert Codezeilen ausführt, zeigt an, wie gut es durchdacht ist.
Die folgende Abbildung zeigt die Anwendung, wenn der Client (Browser)
/guestbookURL anfordert.
 Der Mechanismus der Gästebuchanwendung
Der Mechanismus der GästebuchanwendungWenn Sie eine Gästebuchseite ausgeben müssen, gibt es einen Aufruf an das Dateisystem, um die Vorlage in den Speicher einzulesen, und drei Netzwerkaufrufe an Redis. Die Vorlagendatei enthält den größten Teil des HTML-Inhalts für die Seite im obigen Screenshot. Es gibt auch spezielle Platzhalter für den dynamischen Teil des Inhalts: Datensätze und Besucherzähler. Wir bekommen sie von Redis, fügen sie auf der Seite ein und geben dem Kunden vollständig gestaltete Inhalte. Ein dritter Aufruf von Redis kann vermieden werden, da Redis beim Inkrementieren einen neuen Schlüsselwert zurückgibt. Für unseren Server mit einer asynchronen ereignisbasierten Architektur sind viele Netzwerkanrufe jedoch ein guter Test für Schulungszwecke. Daher verwerfen wir den Rückgabewert von Redis über die Anzahl der Besucher und fordern ihn in einem separaten Anruf an.
ZeroHTTPd-Serverarchitekturen
Wir erstellen sieben Versionen von ZeroHTTPd mit derselben Funktionalität, aber unterschiedlichen Architekturen:
- Iterativ
- Fork-Server (ein untergeordneter Prozess pro Anforderung)
- Pre-Fork-Server (Pre-Forking-Prozesse)
- Server mit Threads (ein Thread pro Anfrage)
- Server mit Pre-Threading
poll() -basierte Architektur
- Epoll Architektur
Wir messen die Leistung jeder Architektur, indem wir den Server mit HTTP-Anforderungen laden. Beim Vergleich von Architekturen mit einem hohen Grad an Parallelität steigt jedoch die Anzahl der Anforderungen. Wir testen dreimal und berücksichtigen den Durchschnitt.
Testmethodik
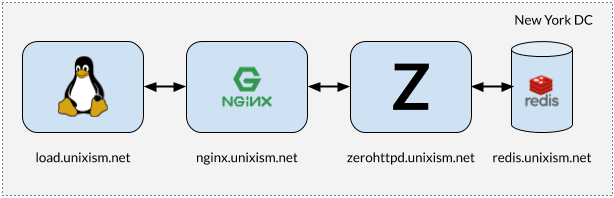 Installation zum Stresstest ZeroHTTPd
Installation zum Stresstest ZeroHTTPdEs ist wichtig, dass bei der Durchführung von Tests nicht alle Komponenten auf derselben Maschine funktionieren. In diesem Fall verursacht das Betriebssystem zusätzlichen Planungsaufwand, da die Komponenten um die CPU konkurrieren. Das Messen des Betriebssystem-Overheads von jeder der ausgewählten Serverarchitekturen ist eines der wichtigsten Ziele dieser Übung. Das Hinzufügen weiterer Variablen wirkt sich nachteilig auf den Prozess aus. Daher funktioniert die Einstellung in der obigen Abbildung am besten.
Was jeder dieser Server tut
- load.unixism.net: Hier führen wir
ab , das Dienstprogramm Apache Benchmark. Es erzeugt die Last, die zum Testen unserer Serverarchitekturen erforderlich ist.
- nginx.unixism.net: Manchmal möchten wir mehr als eine Instanz eines Serverprogramms ausführen. Hierzu fungiert der Nginx-Server mit den entsprechenden Einstellungen als Load Balancer, der von ab zu unseren Serverprozessen kommt.
- zerohttpd.unixism.net: Hier führen wir unsere Serverprogramme nacheinander auf sieben verschiedenen Architekturen aus.
- redis.unixism.net: Der Redis-Daemon wird auf diesem Server ausgeführt, auf dem Einträge im Gästebuch und im Besucherzähler gespeichert sind.
Alle Server laufen auf einem einzigen Prozessorkern. Die Idee ist, die maximale Leistung jeder Architektur zu bewerten. Da alle Serverprogramme auf derselben Hardware getestet werden, ist dies die grundlegende Ebene für den Vergleich. Mein Testaufbau besteht aus virtuellen Servern, die von Digital Ocean gemietet werden.
Was messen wir?
Sie können verschiedene Indikatoren messen. Wir bewerten die Leistung jeder Architektur in dieser Konfiguration und laden Server mit Anforderungen auf verschiedenen Ebenen der Parallelität: Die Last steigt von 20 auf 15.000 gleichzeitige Benutzer.
Testergebnisse
Das folgende Diagramm zeigt die Leistung von Servern auf verschiedenen Architekturen auf verschiedenen Ebenen der Parallelität. Die y-Achse ist die Anzahl der Anforderungen pro Sekunde, die x-Achse ist eine parallele Verbindung.
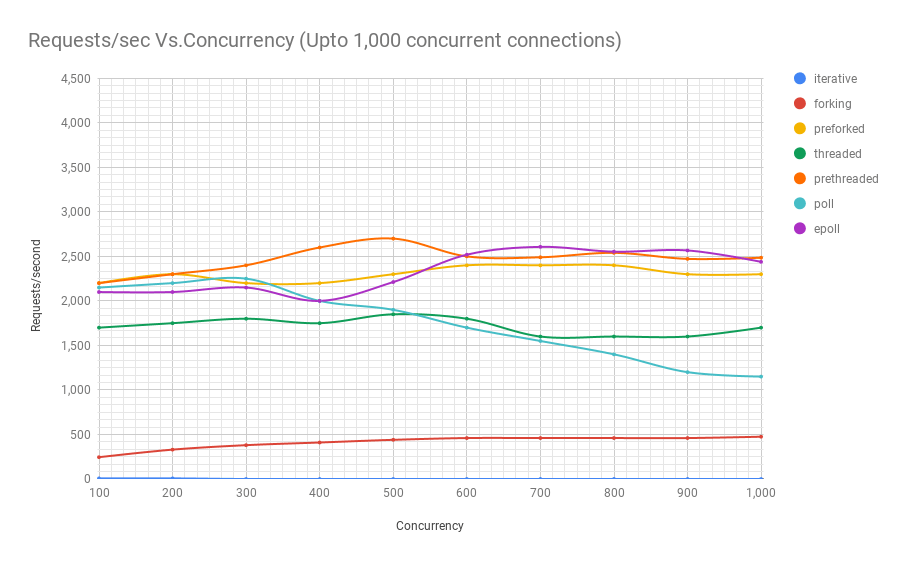
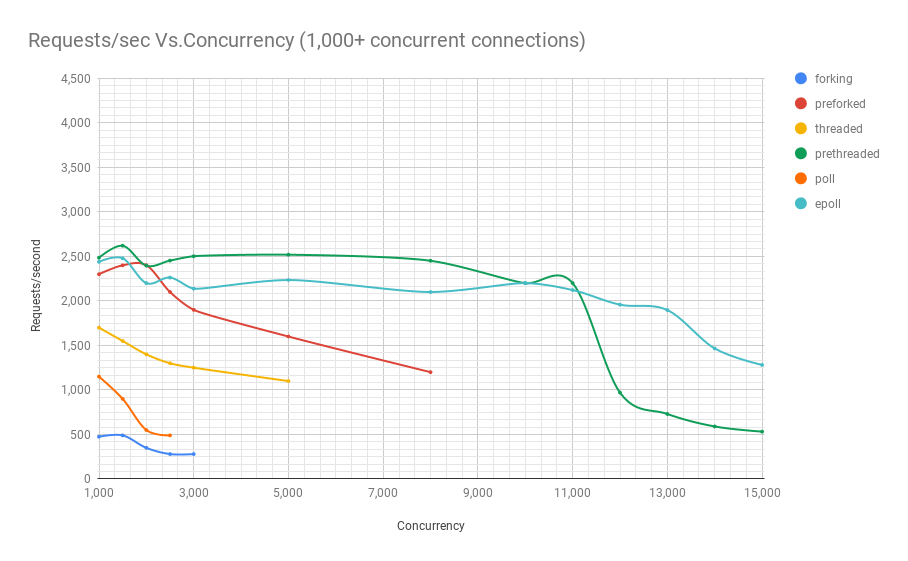
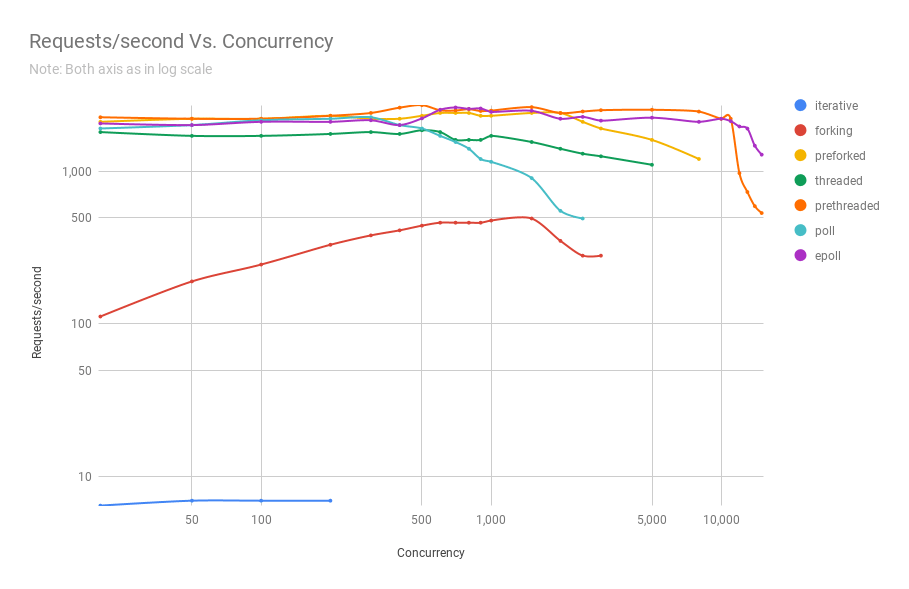
Unten finden Sie eine Tabelle mit den Ergebnissen.
Aus der Grafik und Tabelle geht hervor, dass über 8000 gleichzeitige Anfragen nur noch zwei Spieler übrig sind: Pre-Fork und Epoll. Mit zunehmender Auslastung ist der umfragebasierte Server schlechter als der Streaming-Server. Die Pre-Threading-Architektur konkurriert mit epoll: Dies ist ein Beweis dafür, wie gut der Linux-Kernel eine große Anzahl von Threads plant.
Quellcode ZeroHTTPd
Der Quellcode für ZeroHTTPd ist
hier . Jede Architektur hat ein eigenes Verzeichnis.
ZeroHTTPd
│
├── 01_iterativ
│ ├ main.c
├── 02_Gabelung
│ ├ main.c
├── 03_Vorforking
│ ├ main.c
├── 04_Threading
│ ├ main.c
├── 05_prethreading
│ ├ main.c
├── 06_poll
│ ├ main.c
├── 07_epoll
│ └ main.c
├── Makefile
├── öffentlich
│ ├ index.html
│ └ tux.png
└── Vorlagen
└── Gästebuch
└── index.html Neben sieben Verzeichnissen für alle Architekturen befinden sich zwei weitere Verzeichnisse im Verzeichnis der obersten Ebene: public und templates. Die erste enthält die Datei index.html und das Bild aus dem ersten Screenshot. Dort können andere Dateien und Ordner abgelegt werden, und ZeroHTTPd sollte diese statischen Dateien problemlos ausgeben. Wenn der Pfad im Browser mit dem Pfad im öffentlichen Ordner übereinstimmt, sucht ZeroHTTPd in diesem Verzeichnis nach der Datei index.html. Gästebuchinhalte werden dynamisch generiert. Es hat nur die Hauptseite und der Inhalt basiert auf der Datei 'templates / guestbook / index.html'. ZeroHTTPd fügt auf einfache Weise dynamische Seiten zur Erweiterung hinzu. Die Idee ist, dass Benutzer diesem Verzeichnis Vorlagen hinzufügen und ZeroHTTPd nach Bedarf erweitern können.
Um alle sieben Server zu erstellen, führen Sie
make all aus dem Verzeichnis der obersten Ebene aus. Alle Builds werden in diesem Verzeichnis angezeigt. Die ausführbaren Dateien suchen in dem Verzeichnis, in dem sie ausgeführt werden, nach den Verzeichnissen public und templates.
Linux API
Um die Informationen in dieser Artikelserie zu verstehen, müssen Sie sich nicht mit der Linux-API auskennen. Ich empfehle jedoch, mehr zu diesem Thema zu lesen. Es gibt viele Referenzressourcen im Web. Obwohl wir verschiedene Kategorien von Linux-APIs abdecken werden, konzentrieren wir uns hauptsächlich auf Prozesse, Threads, Ereignisse und den Netzwerkstapel. Neben Büchern und Artikeln über die Linux-API empfehle ich auch das Lesen von Mana für verwendete Systemaufrufe und Bibliotheksfunktionen.
Leistung und Skalierbarkeit
Ein Hinweis zu Leistung und Skalierbarkeit. Theoretisch besteht keine Verbindung zwischen ihnen. Möglicherweise haben Sie einen Webdienst, der mit einer Antwortzeit von einigen Millisekunden sehr gut funktioniert, aber überhaupt nicht skaliert. In ähnlicher Weise gibt es möglicherweise eine schlecht ausgeführte Webanwendung, deren Antwort einige Sekunden dauert, die jedoch auf Zehn skaliert wird, um Zehntausende gleichzeitiger Benutzer zu verarbeiten. Die Kombination aus hoher Leistung und Skalierbarkeit ist jedoch eine sehr leistungsstarke Kombination. Hochleistungsanwendungen nutzen Ressourcen im Allgemeinen sparsam und bedienen so effektiv mehr gleichzeitige Benutzer auf dem Server, wodurch die Kosten gesenkt werden.
CPU- und E / A-Aufgaben
Schließlich gibt es beim Rechnen immer zwei mögliche Arten von Aufgaben: für E / A und CPU. Das Empfangen von Anforderungen über das Internet (Netzwerk-E / A), die Dateiverwaltung (Netzwerk- und Festplatten-E / A) und die Kommunikation mit der Datenbank (Netzwerk- und Festplatten-E / A) sind E / A-Aktionen. Einige Datenbankabfragen können die CPU ein wenig belasten (Sortieren, Berechnen des Durchschnitts von einer Million Ergebnissen usw.). Die meisten Webanwendungen sind durch die maximal mögliche E / A begrenzt, und der Prozessor wird selten mit voller Kapazität verwendet. Wenn Sie feststellen, dass einige CPUs viele CPUs verwenden, ist dies höchstwahrscheinlich ein Zeichen für eine schlechte Anwendungsarchitektur. Dies kann bedeuten, dass CPU-Ressourcen für die Prozesssteuerung und die Kontextumschaltung aufgewendet werden - und dies ist nicht ganz nützlich. Wenn Sie beispielsweise Bildverarbeitung, Audiokonvertierung oder maschinelles Lernen ausführen, benötigt die Anwendung leistungsstarke CPU-Ressourcen. Bei den meisten Anwendungen ist dies jedoch nicht der Fall.
Mehr zu Serverarchitekturen
- Teil I. Iterative Architektur
- Teil II Gabel-Server
- Teil III. Pre-Fork-Server
- Teil IV Server mit Threads
- Teil V. Server mit Thread-Vorerstellung
- Teil VI. Umfragebasierte Architektur
- Teil VII. Epoll Architektur