HighLoad ++ gibt es schon lange und wir sprechen über die regelmäßige Arbeit mit PostgreSQL. Aber Entwickler haben immer noch die gleichen Probleme von Monat zu Monat, von Jahr zu Jahr. Wenn in kleinen Unternehmen ohne DBA im Bundesstaat Fehler bei der Arbeit mit Datenbanken auftreten, ist dies nicht überraschend. Große Unternehmen benötigen auch Datenbanken, und selbst bei debuggten Prozessen treten immer noch Fehler auf und die Datenbanken fallen. Es spielt keine Rolle, wie groß das Unternehmen ist - es treten immer noch Fehler auf, Datenbanken stürzen regelmäßig ab, stürzen ab.

Natürlich wird Ihnen das nie passieren, aber das Überprüfen der Checkliste ist nicht schwierig, und es kann sehr anständig sein, zukünftige Nerven zu retten. Unter der Katze werden die wichtigsten typischen Fehler aufgelistet, die Entwickler bei der Arbeit mit PostgreSQL machen, herausfinden, warum wir dies nicht tun müssen, und herausfinden, wie.
Über den Sprecher: Alexey Lesovsky begann als Linux-Systemadministrator. Von Aufgaben der Virtualisierungs- und Überwachungssysteme kam PostgreSQL nach und nach. Jetzt PostgreSQL DBA in
Data Egret , einem Beratungsunternehmen, das mit vielen verschiedenen Projekten arbeitet und viele Beispiele für wiederkehrende Probleme sieht. Dies ist ein
Link zur Präsentation des Berichts auf HighLoad ++ 2018.
Woher kommen die Probleme?
Zum Aufwärmen ein paar Geschichten darüber, wie Fehler auftreten.
Verlauf 1. Funktionen
Eines der Probleme ist, welche Funktionen das Unternehmen bei der Arbeit mit PostgreSQL verwendet. Alles beginnt einfach: PostgreSQL, Datasets, einfache Abfragen mit JOIN. Wir nehmen die Daten, machen SELECT - alles ist einfach.
Dann beginnen wir, die zusätzlichen Funktionen von PostgreSQL zu nutzen, neue Funktionen und Erweiterungen hinzuzufügen. Die Funktion wird immer größer. Wir verbinden Streaming-Replikation, Sharding. Verschiedene Dienstprogramme und Bodykits erscheinen in der Umgebung - pgbouncer, pgpool, patroni. Ungefähr so.

Jedes Schlüsselwort ist ein Grund für das Auftreten eines Fehlers.
Verlauf 2. Datenspeicherung
Die Art und Weise, wie wir Daten speichern, ist auch eine Fehlerquelle.
Als das Projekt zum ersten Mal erschien, waren einige Daten und Tabellen darin enthalten. Einfache Abfragen reichen aus, um Daten zu empfangen und aufzuzeichnen. Aber dann gibt es immer mehr Tabellen. Daten werden an verschiedenen Stellen ausgewählt, JOINs werden angezeigt. Abfragen sind kompliziert und umfassen CTE-Konstrukte, SUBQUERY, IN-Listen und LATERAL. Einen Fehler zu machen und eine Kurvenabfrage zu schreiben wird viel einfacher.
Und dies ist nur die Spitze des Eisbergs - irgendwo an der Seite können sich weitere 400 Tabellen, Partitionen befinden, aus denen gelegentlich auch Daten gelesen werden.
Geschichte 3. Lebenszyklus
Die Geschichte, wie das Produkt verfolgt wird. Daten müssen immer irgendwo gespeichert werden, daher gibt es immer eine Datenbank. Wie entwickelt sich eine Datenbank, wenn sich ein Produkt entwickelt?
Einerseits gibt es
Entwickler , die mit Programmiersprachen beschäftigt sind. Sie schreiben ihre Anwendungen und entwickeln Fähigkeiten im Bereich der Softwareentwicklung, ohne auf Dienstleistungen zu achten. Oft interessieren sie sich nicht für die Funktionsweise von Kafka oder PostgreSQL - sie entwickeln neue Funktionen in ihrer Anwendung und kümmern sich nicht um den Rest.
 Admins
Admins dagegen. Sie rufen neue Amazon-Instanzen auf Bare-Metal auf und sind mit der Automatisierung beschäftigt: Sie richten eine Bereitstellung ein, damit das Layout gut funktioniert, und konfigurieren, dass die Dienste gut miteinander interagieren.

Es gibt eine Situation, in der keine Zeit oder kein Wunsch nach einer dünnen Abstimmung der Komponenten und der Datenbank besteht. Die Datenbanken arbeiten mit Standardkonfigurationen und vergessen sie dann vollständig - "es funktioniert, berühren Sie es nicht".
Infolgedessen sind Rechen an verschiedenen Stellen verstreut, die ab und zu in die Stirn der Entwickler fliegen. In diesem Artikel werden wir versuchen, alle diese Rechen in einem Schuppen zu sammeln, damit Sie über sie Bescheid wissen und bei der Arbeit mit PostgreSQL nicht darauf treten.
Planung und Überwachung
Stellen Sie sich zunächst vor, wir haben ein neues Projekt - es ist immer eine aktive Entwicklung, das Testen von Hypothesen und die Implementierung neuer Funktionen. In dem Moment, in dem die Anwendung gerade erschienen ist und sich entwickelt, hat sie wenig Verkehr, Benutzer und Kunden, und alle generieren kleine Datenmengen. Die Datenbank verfügt über einfache Abfragen, die schnell verarbeitet werden. Sie müssen keine großen Datenmengen ziehen, es gibt keine Probleme.
Aber es gibt mehr Benutzer, der Datenverkehr kommt: Neue Daten werden angezeigt, Datenbanken wachsen und alte Abfragen funktionieren nicht mehr. Es ist notwendig, Indizes zu vervollständigen, Abfragen neu zu schreiben und zu optimieren. Es gibt Leistungsprobleme. All dies führt zu Warnungen um 4 Uhr morgens, Stress für Administratoren und Unzufriedenheit des Managements.
Was ist los?
Nach meiner Erfahrung gibt es meistens nicht genügend Festplatten.
Das erste Beispiel . Wir öffnen den Zeitplan für die Überwachung der Festplattenauslastung und stellen fest, dass der
freie Speicherplatz auf der Festplatte knapp wird .
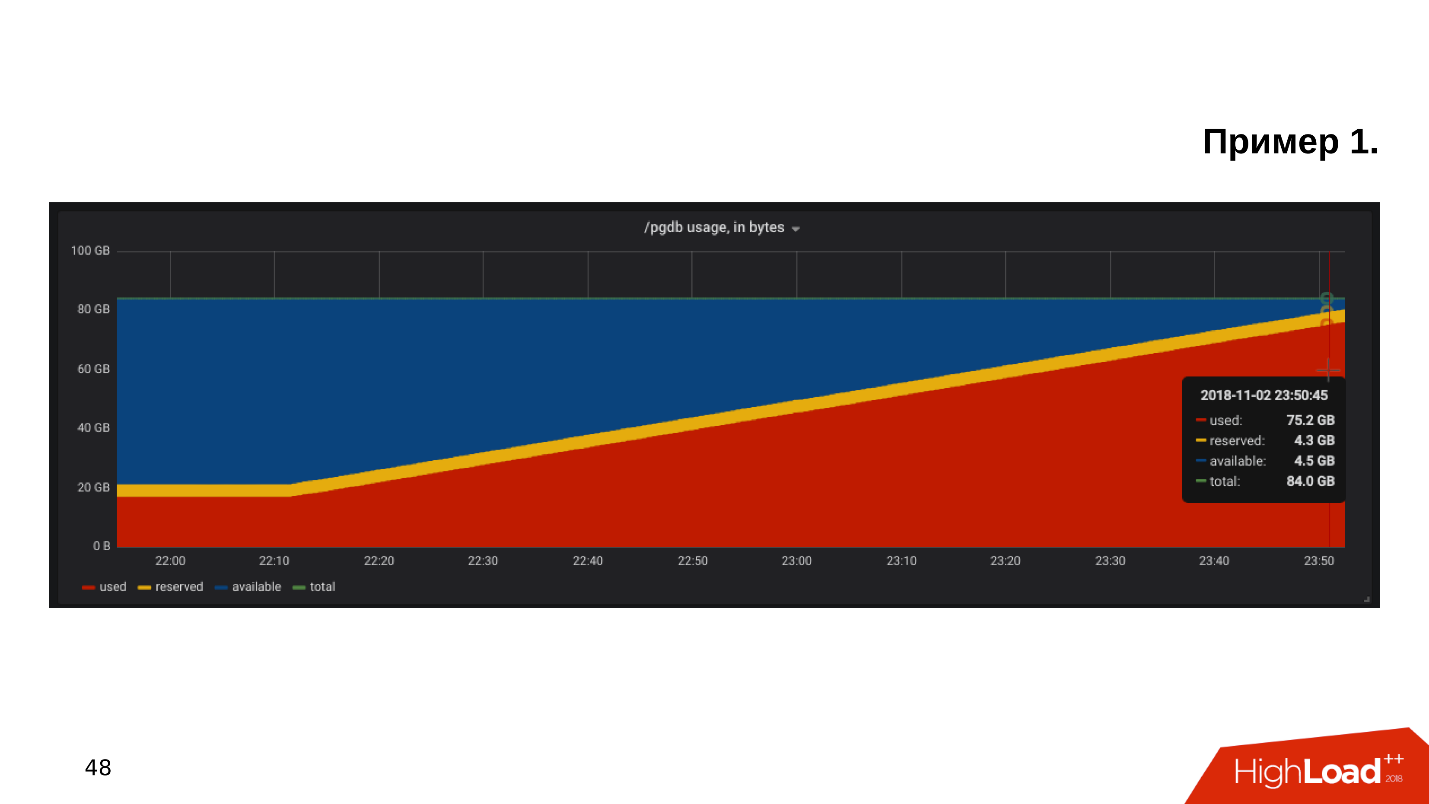
Wir schauen uns an, wie viel Speicherplatz und was verbraucht wird - es stellt sich heraus, dass es ein pg_xlog-Verzeichnis gibt:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
Datenbankadministratoren wissen normalerweise, was dieses Verzeichnis ist, und sie berühren es nicht - es existiert und existiert. Aber der Entwickler, besonders wenn er sich die Inszenierung ansieht, kratzt sich am Kopf und denkt:
- Eine Art von Protokollen ... Löschen wir pg_xlog!Löscht das Verzeichnis, die Datenbank funktioniert nicht mehr . Sofort müssen Sie googeln, wie die Datenbank nach dem Löschen der Transaktionsprotokolle ausgelöst wird.
 Zweites Beispiel
Zweites Beispiel . Wieder öffnen wir die Überwachung und stellen fest, dass nicht genügend Platz vorhanden ist. Diesmal ist der Ort von einer Art Basis besetzt.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
Wir suchen, welche Datenbank am meisten Speicherplatz beansprucht, welche Tabellen und Indizes.

Es stellt sich heraus, dass dies eine Tabelle mit historischen Protokollen ist. Wir brauchten nie historische Protokolle. Sie sind nur für den Fall geschrieben, und wenn es nicht das Problem mit dem Ort gäbe, würde niemand sie bis zum zweiten Mal ansehen:
- Lass uns alles aufräumen, was mm ... älter als Oktober ist!Machen Sie eine Update-Anfrage, führen Sie sie aus, es wird funktionieren und einige der Zeilen löschen.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
Die Abfrage wird 10 Minuten lang ausgeführt, die Tabelle belegt jedoch immer noch den gleichen Speicherplatz.
PostgreSQL entfernt Zeilen aus der Tabelle - alles ist korrekt, aber es gibt den Ort nicht an das Betriebssystem zurück. Dieses Verhalten von PostgreSQL ist den meisten Entwicklern unbekannt und kann sehr überraschend sein.
Das dritte Beispiel . Zum Beispiel hat ORM eine interessante Anfrage gestellt. Normalerweise beschuldigt jeder ORM, "schlechte" Abfragen zu machen, die einige Tabellen vorlesen.
Angenommen, es gibt mehrere JOIN-Operationen, die Tabellen in mehreren Threads parallel lesen. PostgreSQL kann Datenoperationen parallelisieren und Tabellen in mehreren Threads lesen. Da wir jedoch mehrere Anwendungsserver haben, liest diese Abfrage alle Tabellen mehrere tausend Mal pro Sekunde. Es stellt sich heraus, dass der Datenbankserver überlastet ist, die Festplatten nicht zurechtkommen und dies alles zu einem
502 Bad Gateway- Fehler im Backend führt - die Datenbank ist nicht verfügbar.
Das ist aber noch nicht alles. Sie können andere Funktionen von PostgerSQL aufrufen.
- Bremsen von DBMS-Hintergrundprozessen - PostgreSQL verfügt über alle Arten von Checkpoints, Vakuums und Replikationen.
- Virtualisierungsaufwand . Wenn die Datenbank auf einer virtuellen Maschine ausgeführt wird, befinden sich auf demselben Eisenstück auch virtuelle Maschinen an der Seite, die Konflikte um Ressourcen verursachen können.
- Der Speicher stammt vom chinesischen Hersteller NoName , dessen Leistung vom Mond im Steinbock oder der Position des Saturn abhängt, und es gibt keine Möglichkeit herauszufinden, warum dies so funktioniert. Die Basis leidet.
- Die Standardkonfiguration . Dies ist mein Lieblingsthema: Der Kunde sagt, dass seine Datenbank langsamer wird - Sie sehen, und er hat eine Standardkonfiguration. Tatsache ist, dass die Standard-PostgreSQL-Konfiguration für die Ausführung auf der schwächsten Teekanne ausgelegt ist . Die Basis wird gestartet, es funktioniert, aber wenn es bereits auf Hardware mittlerer Ebene funktioniert, reicht diese Konfiguration nicht aus, sie muss optimiert werden.
In den meisten Fällen fehlt PostgreSQL entweder der Speicherplatz oder die Festplattenleistung. Glücklicherweise ist mit Prozessoren, Speicher und einem Netzwerk in der Regel mehr oder weniger alles in Ordnung.
Wie man ist Brauchen Sie Überwachung und Planung! Es scheint offensichtlich, aber aus irgendeinem Grund plant in den meisten Fällen niemand eine Basis, und die Überwachung deckt nicht alles ab, was während des Betriebs von PostgreSQL überwacht werden muss. Es gibt eine Reihe klarer Regeln, mit denen alles gut und nicht "zufällig" funktioniert.
Planung
Hosten Sie die Datenbank ohne zu zögern auf einer SSD . SSDs sind seit langem zuverlässig, stabil und produktiv. Enterprise-SSD-Modelle gibt es schon seit Jahren.
Planen Sie immer ein Datenschema . Schreiben Sie nicht in die Datenbank, dass Sie Zweifel daran haben, was benötigt wird - garantiert nicht benötigt. Ein einfaches Beispiel ist eine leicht modifizierte Tabelle eines unserer Kunden.

Dies ist eine Protokolltabelle, in der sich eine Datenspalte vom Typ json befindet. Relativ gesehen können Sie alles in diese Spalte schreiben. Aus dem letzten Datensatz dieser Tabelle ist ersichtlich, dass die Protokolle 8 MB belegen. PostgreSQL hat kein Problem damit, Datensätze dieser Länge zu speichern. PostgreSQL hat einen sehr guten Speicher, der auf solchen Datensätzen kaut.
Das Problem ist jedoch, dass Anwendungsserver beim Lesen von Daten aus dieser Tabelle leicht die gesamte Netzwerkbandbreite verstopfen und andere Anforderungen darunter leiden. Dies ist das Problem bei der Planung eines Datenschemas.
Verwenden Sie die Partitionierung für jeden Hinweis auf eine Story, die länger als zwei Jahre gespeichert werden muss . Die Partitionierung scheint manchmal kompliziert zu sein - Sie müssen sich mit Triggern beschäftigen, mit Funktionen, die Partitionen erstellen. In neuen Versionen von PostgreSQL ist die Situation besser und jetzt ist das Einrichten der Partitionierung viel einfacher - sobald dies erledigt ist und funktioniert.
In dem betrachteten Beispiel zum Löschen von Daten in 10 Minuten kann
DELETE durch
DROP TABLE - ein solcher Vorgang dauert unter ähnlichen Umständen nur wenige Millisekunden.
Wenn die Daten nach Partitionen sortiert sind, wird die Partition buchstäblich in wenigen Millisekunden gelöscht und das Betriebssystem übernimmt sofort. Die Verwaltung historischer Daten ist einfacher, einfacher und sicherer.
Überwachung
Überwachung ist ein separates großes Thema, aber aus Sicht der Datenbank gibt es Empfehlungen, die in einen Abschnitt des Artikels passen.
Standardmäßig bieten viele Überwachungssysteme die Überwachung von Prozessoren, Speicher, Netzwerk und Speicherplatz. In der Regel
werden jedoch keine Festplattengeräte entsorgt . Informationen darüber, wie stark die Festplatten ausgelastet sind, welche Bandbreite derzeit auf den Festplatten vorhanden ist und welcher Latenzwert immer zur Überwachung hinzugefügt werden sollte. Auf diese Weise können Sie schnell beurteilen, wie Laufwerke geladen sind.
Es gibt viele PostgreSQL-Überwachungsoptionen für jeden Geschmack. Hier sind einige Punkte, die vorhanden sein müssen.
- Verbundene Clients . Es ist notwendig zu überwachen, mit welchen Status sie arbeiten, schnell die "schädlichen" Kunden zu finden, die der Datenbank schaden, und sie auszuschalten.
- Fehler Es ist notwendig, Fehler zu überwachen, um zu verfolgen, wie gut die Datenbank funktioniert: Keine Fehler - großartig, Fehler sind aufgetreten - ein Grund, sich die Protokolle anzusehen und zu verstehen, was falsch läuft.
- Anfragen (Aussagen) . Wir überwachen die quantitativen und qualitativen Merkmale von Anfragen, um grob zu beurteilen, ob wir langsame, lange oder ressourcenintensive Anfragen haben.
Weitere Informationen finden Sie im Bericht
„Grundlagen der
PostgreSQL-Überwachung“ mit HighLoad ++ Siberia und auf der Seite
„Überwachung“ im PostgreSQL-Wiki.
Wenn wir alles geplant und uns mit der Überwachung „bedeckt“ haben, können wir immer noch auf einige Probleme stoßen.
Skalieren
Normalerweise sieht der Entwickler die Datenbankzeile in der Konfiguration. Er ist nicht besonders daran interessiert, wie es intern angeordnet ist - wie Checkpoint, Replikation, Scheduler funktionieren. Der Entwickler hat bereits etwas zu tun - in todo gibt es viele interessante Dinge, die er ausprobieren möchte.
"Gib mir die Adresse der Basis, dann ich selbst." © Anonymer Entwickler.
Die Unwissenheit über das Thema führt zu interessanten Konsequenzen, wenn der Entwickler beginnt, Abfragen zu schreiben, die in dieser Datenbank funktionieren. Fantasien beim Schreiben von Abfragen führen manchmal zu atemberaubenden Effekten.
Es gibt zwei Arten von Transaktionen.
OLTP-Transaktionen sind schnell, kurz und leicht und dauern Bruchteile einer Millisekunde. Sie arbeiten sehr schnell und es gibt viele von ihnen.
OLAP - analytische Abfragen - langsam, lang, schwer, große Tabellenfelder lesen und Statistiken lesen.
In den letzten 2-3 Jahren klingt die Abkürzung
HTAP häufig - Hybrid Transaction / Analytical Processing oder
Hybrid Transactional-Analytical Processing . Wenn Sie keine Zeit haben, über Skalierung und Vielfalt von OLAP- und OLTP-Anforderungen nachzudenken, können Sie sagen: „Wir haben HTAP!“ Die Erfahrung und der Schmerz von Fehlern zeigen jedoch, dass verschiedene Arten von Anforderungen getrennt voneinander leben müssen, da lange OLAP-Anforderungen leichte OLTP-Anforderungen blockieren.
Wir kommen also zu der Frage, wie PostgreSQL skaliert werden kann, um die Last zu verteilen, und alle waren zufrieden.
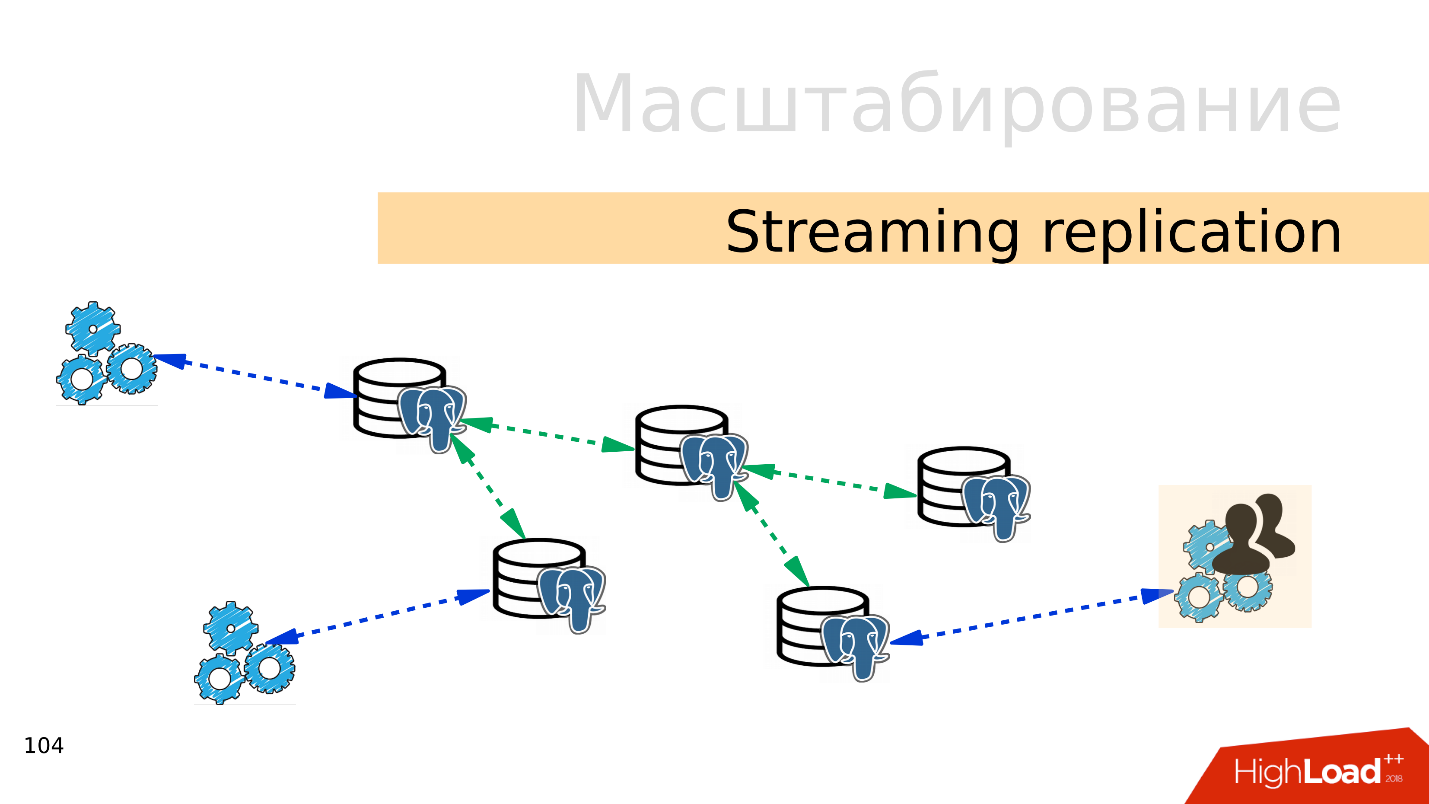
Streaming-Replikation . Die einfachste Option ist das
Streaming der Replikation . Wenn die Anwendung mit der Datenbank arbeitet, verbinden wir mehrere Replikate mit dieser Datenbank und verteilen die Last. Die Aufnahme geht immer noch zur Master-Basis und das Lesen zu Replikaten. Mit dieser Methode können Sie sehr weit skalieren.
Außerdem können Sie mehr Replikate mit einzelnen Replikaten verbinden und eine
kaskadierte Replikation erhalten . Separate Benutzergruppen oder Anwendungen, die beispielsweise Analysen lesen, können in ein separates Replikat verschoben werden.
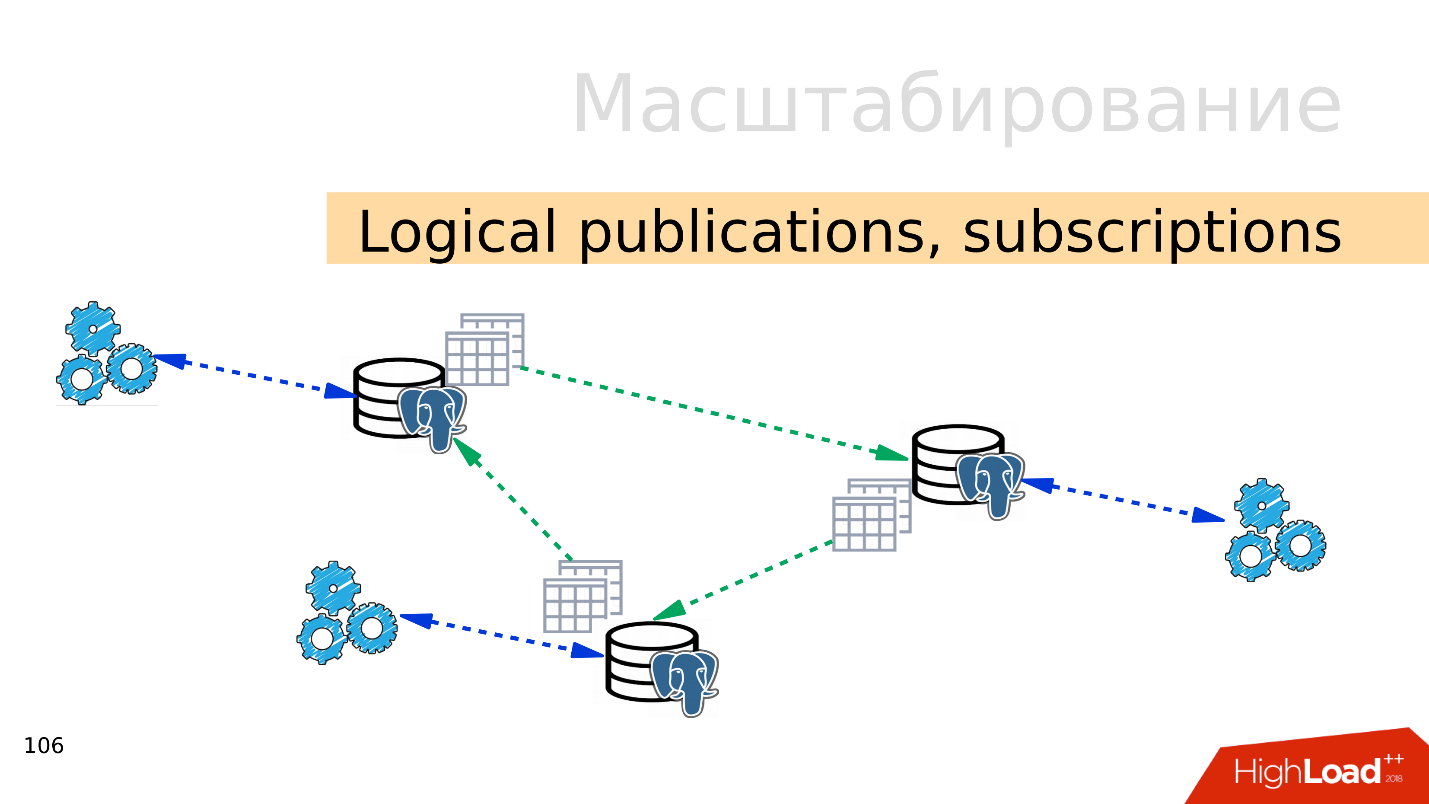
 Logische Veröffentlichungen, Abonnements
Logische Veröffentlichungen, Abonnements - Der Mechanismus logischer Veröffentlichungen und Abonnements impliziert das Vorhandensein mehrerer unabhängiger PostgreSQL-Server mit separaten Datenbanken und Tabellensätzen. Diese Tabellensätze können mit benachbarten Datenbanken verbunden werden. Sie sind für Anwendungen sichtbar, die sie normal verwenden können. Das heißt, alle Änderungen, die in der Quelle auftreten, werden auf die Zielbasis repliziert und sind dort sichtbar. Funktioniert hervorragend mit PostgreSQL 10.
 Fremdtabellen, deklarative Partitionierung - deklarative Partitionierung und externe Tabellen
Fremdtabellen, deklarative Partitionierung - deklarative Partitionierung und externe Tabellen . Sie können mehrere PostgreSQL-Dateien verwenden und dort mehrere Tabellensätze erstellen, in denen die gewünschten Datenbereiche gespeichert werden. Dies können Daten für ein bestimmtes Jahr oder Daten sein, die über einen beliebigen Bereich gesammelt wurden.
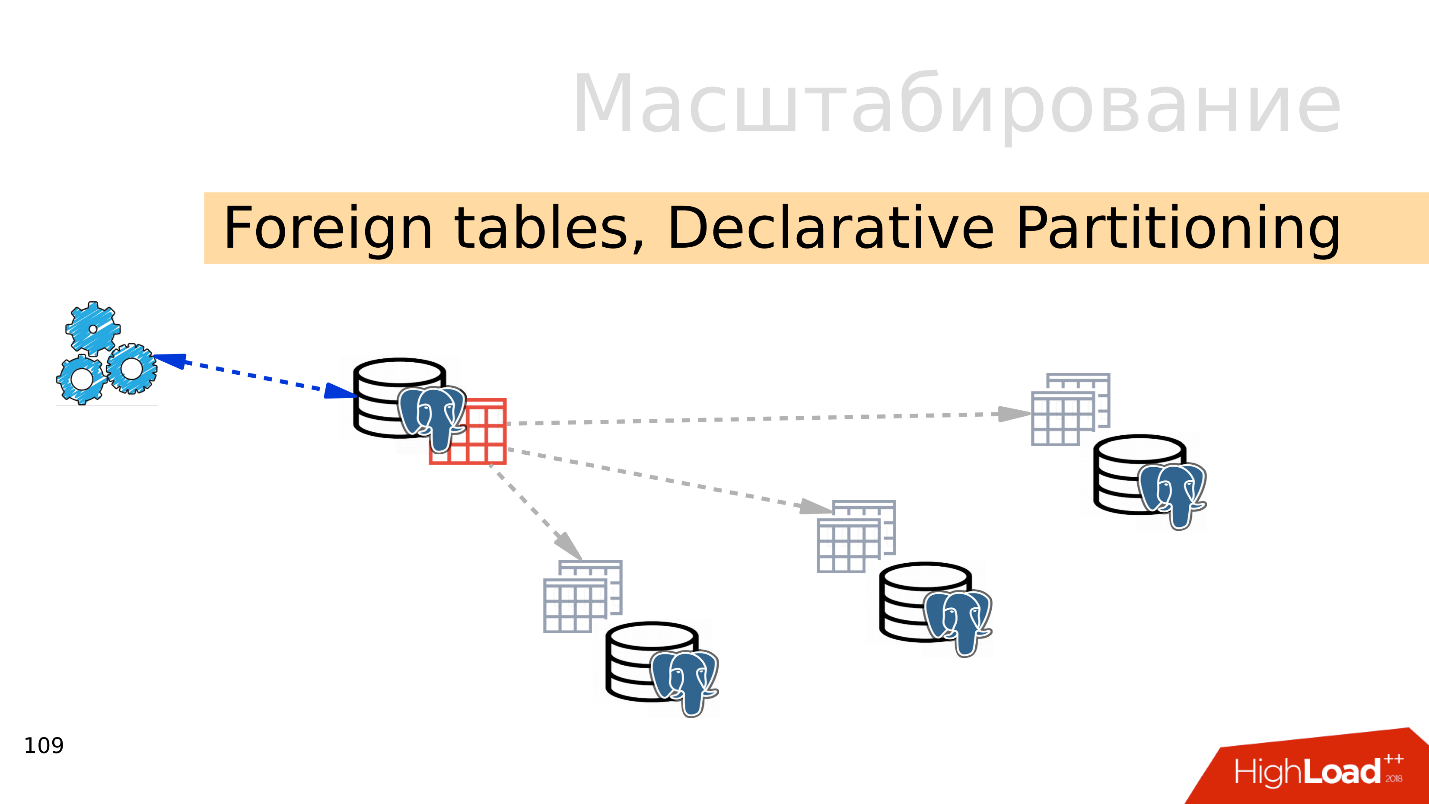
Mithilfe des Mechanismus externer Tabellen können Sie alle diese Datenbanken in Form einer partitionierten Tabelle in einem separaten PostgreSQL kombinieren. Eine Anwendung arbeitet möglicherweise bereits mit dieser partitionierten Tabelle, liest jedoch tatsächlich Daten von Remote-Partitionen. Wenn Datenmengen mehr als die Fähigkeiten eines einzelnen Servers sind, ist dies ein Sharding.

All dies kann zu verteilten Konfigurationen kombiniert werden, um verschiedene PostgreSQL-Replikationstopologien zu erstellen. Wie dies alles funktioniert und wie es verwaltet wird, ist das Thema eines separaten Berichts.
Wo soll ich anfangen?
Die einfachste Option ist die
Replikation . Der erste Schritt besteht darin, das Lesen und Schreiben zu verteilen. Schreiben Sie also an den Master und lesen Sie aus Replikaten. Also skalieren wir die Last und führen das Lesen vom Assistenten aus. Vergessen Sie außerdem nicht die Analysten. Analytische Abfragen funktionieren lange. Sie benötigen ein separates Replikat mit separaten Einstellungen, damit lange analytische Abfragen den Rest nicht beeinträchtigen können.
Der nächste Schritt ist das
Balancieren . Wir haben immer noch die gleiche Zeile in der Konfiguration, mit der der Entwickler arbeitet. Er braucht einen Ort, an dem er schreiben und lesen kann. Hier gibt es mehrere Möglichkeiten.
Ideal ist die Implementierung des Ausgleichs
auf Anwendungsebene , wenn die Anwendung selbst weiß, woher die Daten gelesen werden sollen, und weiß, wie ein Replikat ausgewählt wird. Angenommen, ein Kontostand wird immer auf dem neuesten Stand benötigt und muss vom Master gelesen werden, und das Produktbild oder die Informationen dazu können mit einiger Verzögerung gelesen und von einem Replikat erstellt werden.
- DNS Round Robin ist meiner Meinung nach keine sehr praktische Implementierung, da es manchmal lange funktioniert und nicht die erforderliche Zeit für den Wechsel der Assistentenrollen zwischen Servern im Falle eines Failovers bietet.
- Eine interessantere Option ist die Verwendung von Keepalived und HAProxy . Virtuelle Adressen für den Master und eine Reihe von Replikaten werden zwischen HAProxy-Servern geworfen, und HAProxy gleicht bereits den Datenverkehr aus.
- Patroni, DCS in Verbindung mit so etwas wie ZooKeeper, etcd, Consul - meiner Meinung nach die interessanteste Option. Das heißt, die Serviceerkennung ist für die Informationen verantwortlich, wer jetzt der Master und wer das Replikat ist. Patroni verwaltet einen Cluster von PostgreSQLs und führt das Umschalten durch. Wenn sich die Topologie geändert hat, werden diese Informationen in der Diensterkennung angezeigt, und Anwendungen können die aktuelle Topologie schnell ermitteln.
Und es gibt Nuancen bei der Replikation, von denen die häufigste die
Replikationsverzögerung ist . Sie können es wie GitLab tun, und wenn sich die Verzögerung ansammelt, lassen Sie einfach die Basis fallen. Aber wir haben eine umfassende Überwachung - wir schauen uns das an und sehen lange Transaktionen.
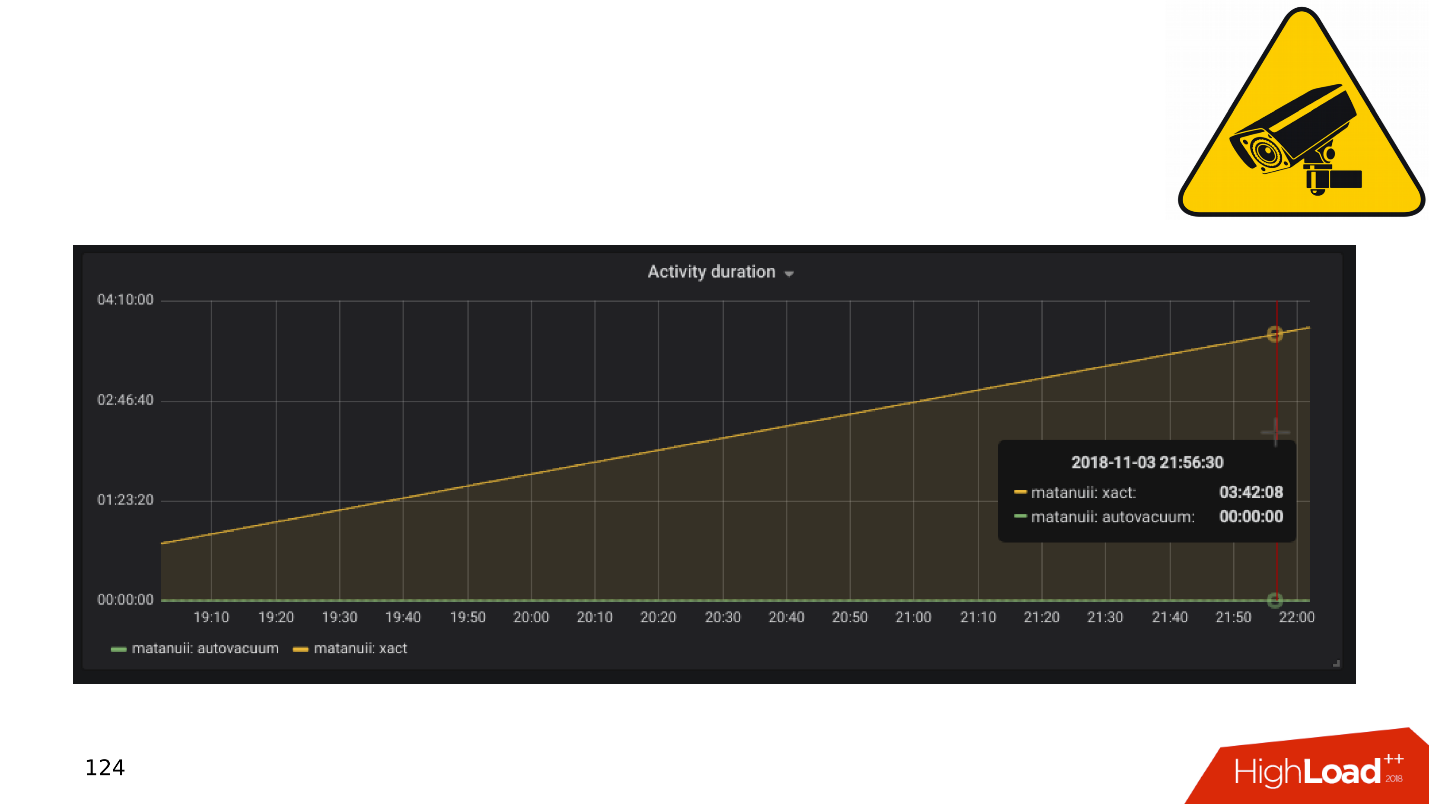
Anwendungen und DBMS-Transaktionen
Im Allgemeinen führen langsame und inaktive Transaktionen zu:
- Produktivitätsabfall - nicht zu einem scharfen Krampf, sondern zu einem glatten;
- Sperren und Deadlocks , da lange Transaktionen Sperren für Zeilen enthalten und verhindern, dass andere Transaktionen funktionieren.
- 50 * HTTP-Fehler im Backend , Schnittstellenfehler oder anderswo.
Schauen wir uns eine kleine Theorie darüber an, wie diese Probleme auftreten und warum der Mechanismus langer und inaktiver Transaktionen schädlich ist.
PostgreSQL hat MVCC - relativ gesehen eine Datenbank-Engine. Kunden können damit wettbewerbsfähig mit Daten arbeiten, ohne sich gegenseitig zu stören: Leser stören Leser nicht, und Schriftsteller stören Schriftsteller nicht. Natürlich gibt es einige Ausnahmen, aber in diesem Fall sind sie nicht wichtig.
Es stellt sich heraus, dass es in der Datenbank für eine Zeile mehrere Versionen für verschiedene Transaktionen geben kann. Clients stellen eine Verbindung her, die Datenbank gibt ihnen Snapshots von Daten, und innerhalb dieser Snapshots können verschiedene Versionen derselben Zeile vorhanden sein. Dementsprechend werden im Lebenszyklus der Datenbank Transaktionen verschoben, ersetzt und es werden Versionen von Zeilen angezeigt, die niemand benötigt.
Es besteht also ein
Bedarf an einem Müllsammler - automatischem Vakuum . Es bestehen lange Transaktionen, die verhindern, dass durch automatisches Vakuum unnötige Zeilenversionen entfernt werden. Diese Junk-Daten wandern von Speicher zu Datenträger, von Datenträger zu Speicher. Um diesen Müll zu speichern, werden CPU- und Speicherressourcen verschwendet.
Je länger die Transaktion dauert, desto mehr Junk und geringere Leistung.
Unter dem Gesichtspunkt von „Wer ist schuld?“ Ist die App für das Auftreten langer Transaktionen verantwortlich. Wenn die Datenbank für sich allein existiert, werden lange Nichtstun-Transaktionen von nirgendwoher ausgeführt. In der Praxis gibt es die folgenden Optionen für das Auftreten von Transaktionen im Leerlauf.
"Gehen wir zu einer externen Quelle .
" Die Anwendung öffnet eine Transaktion, führt etwas in der Datenbank aus und entscheidet sich dann für eine externe Quelle, z. B. Memcached oder Redis, in der Hoffnung, dass sie dann zur Datenbank zurückkehrt, weiterarbeitet und die Transaktion schließt. Wenn jedoch ein Fehler in der externen Quelle auftritt, stürzt die Anwendung ab und die Transaktion bleibt geschlossen, bis jemand sie bemerkt und beendet.
Keine Fehlerbehandlung . Andererseits kann es zu Problemen bei der Fehlerbehandlung kommen. Als die Anwendung erneut eine Transaktion öffnete, ein Problem in der Datenbank löste, zur Codeausführung zurückkehrte, einige Funktionen und Berechnungen ausführte, um die Arbeit in der Transaktion fortzusetzen und sie zu schließen. Wenn bei diesen Berechnungen der Anwendungsvorgang mit einem Fehler unterbrochen wurde, kehrte der Code zum Beginn des Zyklus zurück und die Transaktion blieb erneut geschlossen.
Der menschliche Faktor . Zum Beispiel arbeitet ein Administrator, Entwickler, Analyst in einem pgAdmin oder in DBeaver - hat eine Transaktion geöffnet und tut etwas darin. Dann wurde die Person abgelenkt, er wechselte zu einer anderen Aufgabe, dann zur dritten, vergaß die Transaktion, ging für das Wochenende und die Transaktion hängt weiter. Die Basisleistung leidet.
Mal sehen, was in diesen Fällen zu tun ist.
- Wir haben Überwachung, dementsprechend benötigen wir Warnungen bei der Überwachung . Jede Transaktion, die länger als eine Stunde dauert und nichts tut, ist eine Gelegenheit, um zu sehen, woher sie stammt, und um zu verstehen, was falsch ist.
- Der nächste Schritt besteht darin , solche Transaktionen über die Aufgabe in der Krone (pg_terminate_backend (pid)) oder in der PostgreSQL-Konfiguration zu konfigurieren. Schwellenwerte von 10 bis 30 Minuten sind erforderlich. Danach werden die Transaktionen automatisch abgeschlossen.
- Anwendungs-Refactoring . Natürlich müssen Sie herausfinden, woher die inaktiven Transaktionen kommen, warum sie auftreten, und solche Orte beseitigen.
Vermeiden Sie um jeden Preis lange Transaktionen, da diese die Datenbankleistung stark beeinträchtigen.
Alles wird noch interessanter, wenn anstehende Aufgaben angezeigt werden. Beispielsweise müssen Sie die Einheiten sorgfältig berechnen. Und wir kommen zum Thema Fahrradbau.
Fahrradbau
Wund Thema. Unternehmen auf der Anwendungsseite müssen die Hintergrundverarbeitung von Ereignissen durchführen. Zum Beispiel, um Aggregate zu berechnen: Minimum, Maximum, Durchschnittswert, Benachrichtigungen an Benutzer senden, Kunden in Rechnung stellen, nach der Registrierung ein Benutzerkonto einrichten oder sich bei benachbarten Diensten registrieren - verzögerte Verarbeitung.
Das Wesentliche solcher Aufgaben ist das gleiche - sie werden auf später verschoben. In der Datenbank werden Tabellen angezeigt, die nur die Warteschlangen ausführen.

Hier ist die Kennung der Aufgabe, der Zeitpunkt, zu dem die Aufgabe erstellt wurde, die Aktualisierung, der Handler, der sie ausgeführt hat, die Anzahl der zu erledigenden Versuche. Wenn Sie eine Tabelle haben, die dieser auch nur annähernd ähnelt, haben Sie
selbst geschriebene Warteschlangen .
All dies funktioniert einwandfrei, bis lange Transaktionen angezeigt werden. Danach nehmen
Tabellen, die mit Warteschlangen arbeiten, an Größe zu . Es werden ständig neue Jobs hinzugefügt, alte gelöscht, Aktualisierungen vorgenommen - eine Tabelle mit intensiver Aufzeichnung wird erhalten. Es sollte regelmäßig von veralteten Versionen von Zeichenfolgen gereinigt werden, damit die Leistung nicht beeinträchtigt wird.
Die Verarbeitungszeit nimmt zu - eine lange Transaktion blockiert veraltete Versionen von Zeilen oder verhindert, dass Vakuum sie bereinigt. Wenn die Tabelle größer wird, erhöht sich auch die Verarbeitungszeit, da Sie viele Seiten mit Müll lesen müssen. Die Zeit nimmt zu und die
Warteschlange funktioniert irgendwann überhaupt nicht mehr .
Unten sehen Sie ein Beispiel für die Spitze eines unserer Kunden, der eine Warteschlange hatte. Alle Anfragen beziehen sich nur auf die Warteschlange.

Achten Sie auf die Ausführungszeit dieser Anforderungen - alle bis auf eine arbeiten länger als zwanzig Sekunden.
Um diese Probleme zu lösen, wurde
Skytools PgQ , ein Warteschlangenmanager für PostgreSQL, vor langer Zeit erfunden. Erfinden Sie Ihr Fahrrad nicht neu - nehmen Sie PgQ, richten Sie es einmal ein und vergessen Sie die Linien.
Es stimmt, er hat auch Funktionen. Skytools PgQ hat
wenig Dokumentation . Nach dem Lesen der offiziellen Seite hat man das Gefühl, nichts verstanden zu haben. Das Gefühl wächst, wenn Sie versuchen, etwas zu tun. Alles funktioniert, aber
wie es funktioniert, ist nicht klar . Eine Art Jedi-Magie. Viele Informationen finden Sie jedoch in
Mailinglisten . Dies ist kein sehr praktisches Format, aber es gibt viele interessante Dinge, und Sie müssen diese Blätter lesen.
Trotz der Nachteile arbeitet Skytools PgQ nach dem Prinzip "Einrichten und Vergessen". , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
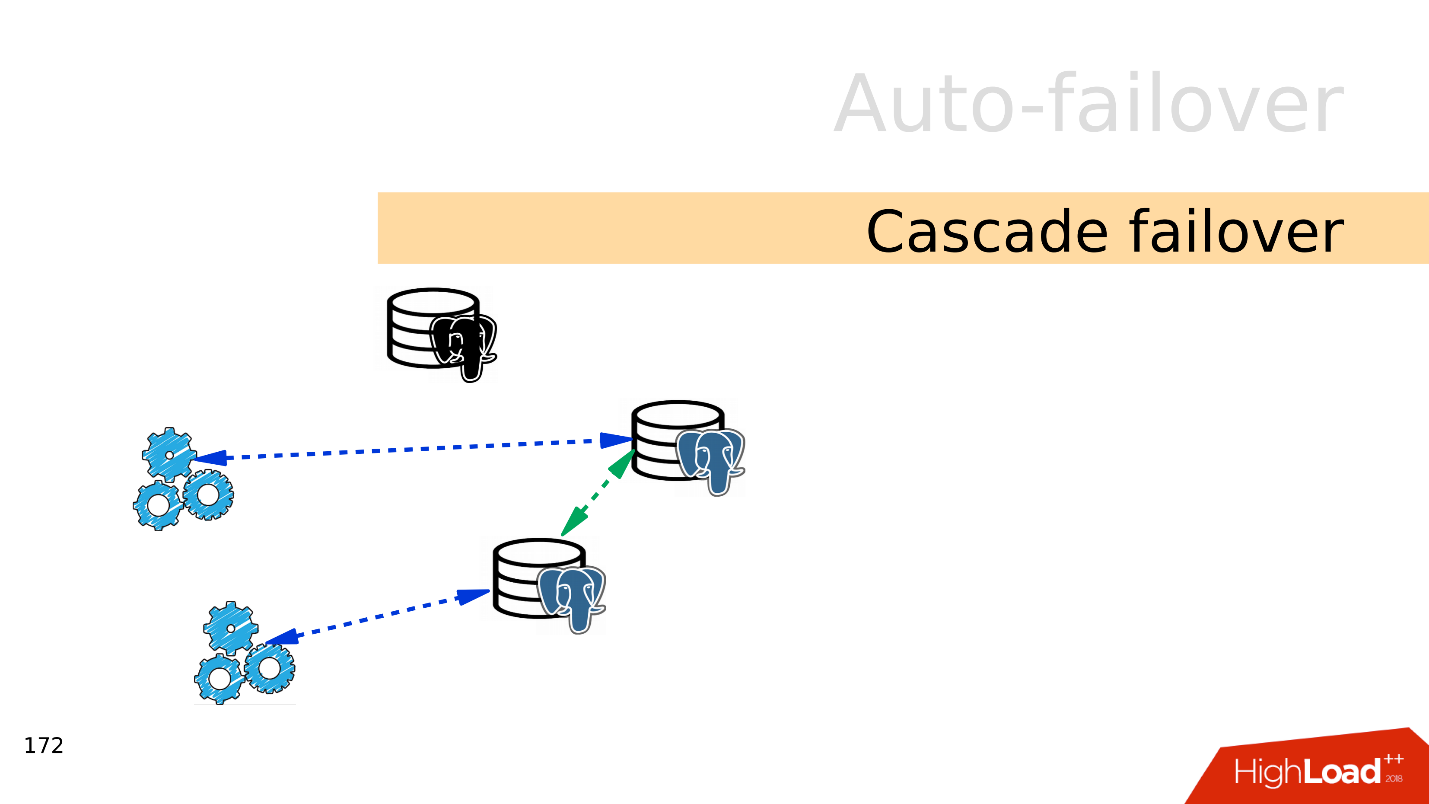
, . , .
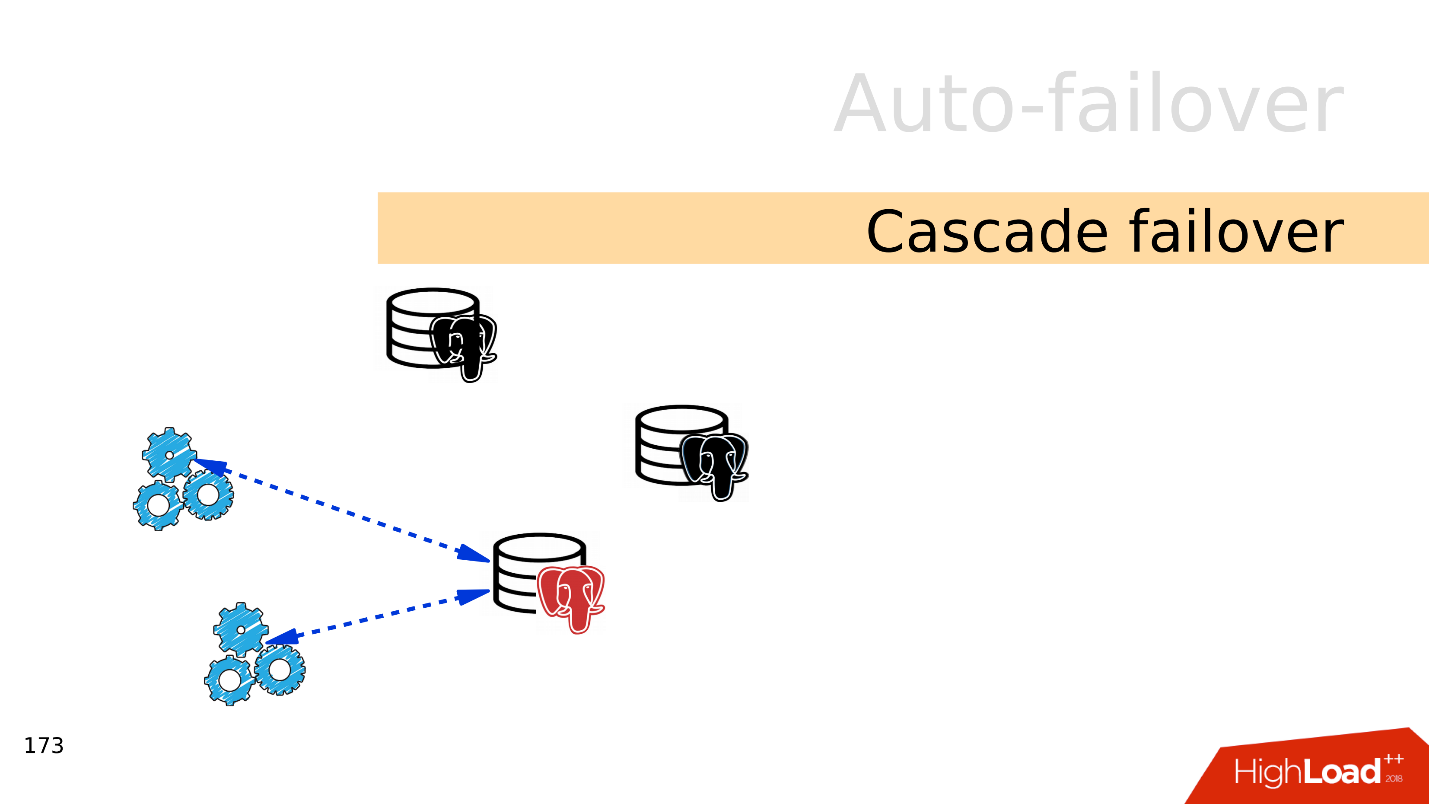
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
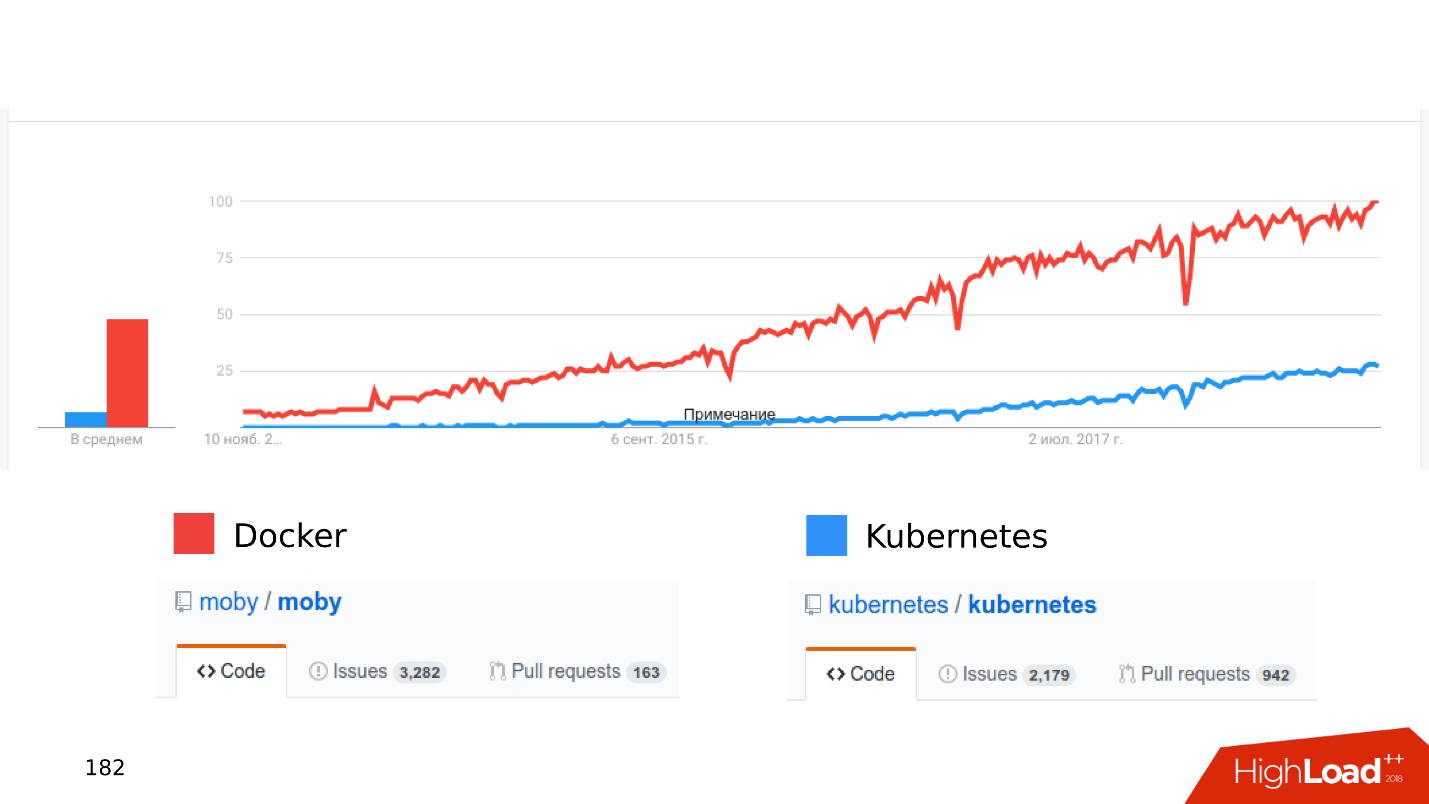
, .
« Kubernetes...» .
— stateful , - . Wo? . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !