Gefühl des Todes, Einsamkeit, gleichzeitig ein verrückter Durst nach Leben ... Sie könnten denken, wir haben beschlossen, einen Vortrag über Expressionismus zu halten und Sie in Munchs Arbeit einzutauchen. Aber nein. Sie durchlaufen all diese Phasen in dem Moment, in dem Sie sehen, dass Ihre technischen Schulden Ihr Unternehmen bald in den Abgrund der Krise treiben werden.

Seit 8 Jahren ist das IT-Team von Dodo Pizza von 2 Entwicklern in einem Land auf 80 Mitarbeiter in 12 Ländern angewachsen. Vor drei Jahren kam ich als Chief Agile Officer zu Dodo Pizza und begann, Teams bei der Erstellung von Prozessen und der Implementierung von Engineering-Praktiken zu unterstützen. Oft waren diese Implementierungen zu langsam. Darüber hinaus wurde festgestellt, dass es schwierig ist, mehrere Teams, die an demselben Produkt arbeiten, dazu zu bringen, qualitativ hochwertigen Code beizubehalten.
Wir haben die Entwicklung von Geschäftsfunktionen vorangetrieben und die technische Perfektion des Codes auf später verschoben. Also waren wir gefangen. Eine riesige technische Verschuldung hat eine Faust über uns gebracht, sie aber nicht niedergeschlagen, sondern nur mit einem Fingerschnipp unser Unternehmen in den Abgrund der Krise geworfen. Im Jahr 2018 startete das Marketing-Team eine massive Werbekampagne, wir konnten die Last nicht tragen und fielen. Schande, Schande und Schande. Während der Krise haben wir jedoch festgestellt, dass wir um ein Vielfaches effizienter arbeiten können. Die Krise zwang uns, die bekanntesten Ingenieurspraktiken schnell umzusetzen und Prozesse zu revolutionieren.
Hintergrund
Dodo Pizza ist eine Cyborg-Firma, die Pizza verkauft . Unser Geschäft basiert auf der Dodo IS-Plattform, die alle Geschäftsprozesse verwaltet: Auftragseingang, Pizzazubereitung, Bestandsverwaltung, Personalverwaltung (Management) und vieles mehr. In nur 8 Jahren sind wir von 2 Entwicklern, die eine Pizzeria bedienen, auf über 80 Entwickler gewachsen, die 498 Pizzerien in 12 Ländern bedienen.
Vor drei Jahren war Dodo IS ein Monolith mit 1 Million Codezeilen. Es gab eine kleine Abdeckung mit Unit-Tests, es gab überhaupt keine API / UI-Tests. Die Qualität des Codes selbst war enttäuschend. Jeder wusste davon oder vermutete es zumindest. In Träumen von einer besseren Zukunft haben wir den Monolithen in ein Dutzend Dienste aufgeteilt und die ekelhaftesten Teile des Systems neu geschrieben. Wir haben sogar ein Diagramm der „zukünftigen“ Architektur gezeichnet, aber ehrlich gesagt nichts unternommen, um näher daran heranzukommen.
Je mehr das Team wuchs, desto mehr litten wir unter dem Fehlen klarer Prozess- und Konstruktionspraktiken. Die Veröffentlichungen wurden immer häufiger, da alle sechs Entwicklungsteams gleichzeitig Änderungen in verschiedenen Branchen vornahmen. Wenn Teams ihre Änderungen in einem Zweig zusammengeführt haben, haben wir manchmal bis zu 4 Stunden verloren, um Zusammenführungskonflikte zu lösen. Es gab keine automatischen Regressionstests, und mit jeder Version haben wir mehr und mehr Zeit für die manuelle Regression aufgewendet.
Scheiße passiert
2018 startete das Marketing-Team unsere erste TV-Werbekampagne des Bundes mit einem Budget von 100 Millionen Rubel. Es war eine großartige Veranstaltung für Dodo Pizza. Das IT-Team war auch gut auf die Kampagne vorbereitet. Wir haben unsere Bereitstellung automatisiert und vereinfacht - jetzt können wir mit einem einzigen Knopf in TeamCity einen Monolithen in 12 Ländern bereitstellen. Mithilfe von Leistungstests haben wir eine Schwachstellenanalyse durchgeführt. Wir haben unser Bestes gegeben, aber trotzdem vermasselt.
Die Werbekampagne war unglaublich. Wir haben 100 bis 300 Bestellungen pro Minute erhalten. Das waren gute Nachrichten. Die schlechte Nachricht: Dodo IS konnte einer solchen Belastung nicht standhalten und starb. Wir haben die Grenze der vertikalen Skalierung erreicht und konnten keine Bestellungen mehr bearbeiten. Das System wurde alle 3 Stunden neu gestartet. Jede Minute Ausfallzeit kostete uns Zehntausende Rubel, ohne den Respektverlust verärgerter Kunden zu berücksichtigen.
Als ich vor drei Jahren bei Dodo Pizza ankam, begann ich sofort, technische Praktiken umzusetzen. Die meisten Teams haben die Paarprogrammierung, Unit-Tests und DDD ziemlich schnell übernommen. Aber nicht alles war so einfach. Ich musste den Widerstand der Entwickler, Produkte und des Supportteams überwinden.
Im Gegensatz zu den Ideen der Ingenieurspraktiken unterstützten zunächst nicht alle die Idee der Feature-Teams. Entwickler sind es gewohnt zu denken, dass ein Team, das sich auf eine Komponente konzentriert, den besten Code schreibt. Es war unklar, wie die rasche Entwicklung von Geschäftsfunktionen mit dem längst überfälligen massiven Refactoring eines komplexen Systems kombiniert werden sollte. Außerdem erforderte dieser endlose Strom von Fehlern ständig Aufmerksamkeit ... Wir haben das Produkt nicht mehr als einmal pro Woche veröffentlicht, und jede Veröffentlichung hat ziemlich viel Zeit in Anspruch genommen. Es erforderte eine enorme Menge an manueller Regression und Unterstützung für UI-Tests. Ich habe versucht, das Problem zu beheben, aber die Prozessänderung war zu langsam und fragmentiert.
Die Geschichte von Fall und Aufstieg
Ausgangszustand: monolithische Architektur
Um die Geschwindigkeit der Entwicklung von Geschäftsfunktionen zu erreichen, haben wir technische Lösungen nicht immer gut durchdacht. Betroffen von mangelnder Erfahrung. Wir hatten eine monolithische Anwendung mit einer einzigen Datenbank, die alle Daten aller Komponenten an einem Ort enthielt. Tracker, Buchhaltung, Website, API für Zielseiten - alle Komponenten des Systems arbeiteten mit einer Datenbank, was ein Engpass war.
Wahre Geschichte
Monolithische Architektur ist zunächst einmal gut, weil sie einfach ist. Es kann jedoch einer hohen Belastung nicht standhalten und ist der einzige Fehlerpunkt. Einmal haben alle unsere Restaurants in Russland aufgrund eines Blogposts keine Bestellungen mehr angenommen. Wie konnte das passieren?
Unser CEO Fedor hat einen Beitrag in seinem Blog veröffentlicht. Dieser Beitrag gewann schnell an Popularität. Auf der Blog-Site von Fedor gibt es einen Zähler, der die Anzahl der Pizzerien in unserem Netzwerk und das Gesamteinkommen aller Pizzerien anzeigt. Jedes Mal, wenn jemand Fedors Blog las, schickte der Webserver eine Anfrage an die Master-Datenbank, um die Einnahmen zu berechnen. Diese Anfragen überlasteten die Datenbank so sehr, dass keine Anfragen mehr an der Kasse des Restaurants bearbeitet wurden. Wir haben das Problem schnell behoben, aber dies war eines von vielen Anzeichen dafür, dass unsere Architektur die Anforderungen des Unternehmens nicht erfüllen konnte und neu gestaltet werden sollte. Wir haben diese Anzeichen jedoch weiterhin ignoriert.
Früher Absturz im Jahr 2017
14. Februar. Für Glückwunschliebhaber am 14. Februar machen wir eine besondere Pizza - Pepperoni in Form eines Herzens. Ich werde mich immer an den 14. Februar 2017 erinnern, denn an diesem Tag, als alle Pizzerien unter Volllast arbeiteten, begann Dodo IS zu fallen. Jede Pizzeria hat 4-5 Tabletten für das Produktionsmanagement: In welcher Reihenfolge rollt der Pizzabäcker den Teig, legt die Zutaten ab, backt oder schickt ihn zur Lieferung. Zu diesem Zeitpunkt erreichte die Anzahl der Pizzerien 150+, jede Tablette wurde mehrmals pro Minute aktualisiert. All diese Abfragen haben die Datenbank so stark belastet, dass sie nicht mehr standhält und fehlschlägt. Dodo IS starb während der Spitzenverkäufe. Aber es stand eine arbeitsreiche Ferienzeit bevor: 23. Februar, 8. März, 1. und 9. Mai. In diesen Ferien erwarteten wir ein noch stärkeres Auftragswachstum.
Der Tag, an dem du stirbst . In Kenntnis unserer Wachstumspläne und der Belastungsgrenze, die wir aushalten können, haben wir herausgefunden, wie lange wir am Leben bleiben können. Das geschätzte Datum von Harmagedon wurde in ungefähr sechs Monaten erwartet: von August bis September 2017. Wie ist es zu leben, wenn man das Datum Ihres Todes kennt?
Stoppen Sie die Entwicklung von Funktionen für ein Jahr. Zusammen mit CEO Fedor mussten wir eine schwierige Entscheidung treffen. Vielleicht eine der schwierigsten Entscheidungen in der Geschichte des Unternehmens. Im nächsten Jahr haben wir nur ein Geschäftsfeature erstellt. Den Rest der Zeit zahlten die Teams technische Schulden ab. Diese Schulden haben uns viel gekostet - mehr als 100 Millionen Rubel nur für die Gehälter der Entwickler.
Einige Verbesserungen nach einem Jahr
Im Laufe des Jahres sind wir deutlich gewachsen:
- Wir haben den Bereitstellungsprozess automatisiert und auf 4-5 Stunden beschleunigt
- Schließlich sahen wir den Monolithen: Der Tracker und die TV-Karten wurden in einen separaten Dienst mit eigener Datenbank verschoben
- Wir begannen, die Kasse der Lieferung zu trennen - die zweite Komponente, die eine hohe Last verursachte
- Benutzer- und Geräteauthentifizierungssystem neu geschrieben
Es scheint, dass wir stolz auf uns sein könnten. Aber vor uns lag eine große Enttäuschung.
Misserfolg während der Bundeswerbekampagne. Zweite Vertrauenskrise
Technische Schulden sind leicht zu akkumulieren, aber sehr schwer zurückzuzahlen. Es ist unwahrscheinlich, dass Sie im Voraus verstehen, wie viel es Sie kosten wird.
Trotz der Tatsache, dass wir ein ganzes Jahr lang mit einem technischen Rückstand zu kämpfen hatten, waren wir nicht bereit für eine Massenmarketingkampagne und haben es wieder vor unser Geschäft gebracht. Das Vertrauen, das wir uns Tropfen für Tropfen verdient haben, ist verschwunden.
Unter der Last der Bundesmarketingkampagne legen wir uns wieder hin. Das System stürzte erneut ab und startete alle 3 Stunden neu. Unser Geschäft verlor zig Millionen Rubel.

Dank der Krise haben wir gelernt, dass wir unter extremen Bedingungen um ein Vielfaches effizienter arbeiten können. Wir werden 20 Mal am Tag freigelassen. Alle arbeiteten als ein Team und konzentrierten sich auf ein Ziel. Während der zwei Krisenwochen haben wir das getan, wovor wir Angst hatten, noch früher zu beginnen, weil wir glaubten, dass es Monate dauern würde. Asynchroner Empfang von Bestellungen, Deaktivieren von Bestellungen, Stresstests, saubere Protokolle - dies ist nur ein kleiner Teil unserer Arbeit. Wir wollten genauso effizient weiterarbeiten, aber ohne Überstunden und Stress.
Lektionen gelernt
Nach der Retrospektive haben wir unsere Prozesse komplett neu organisiert. Wir haben LeSS als Grundlage genommen und es durch technische Praktiken ergänzt. In den nächsten Monaten haben wir einen Durchbruch bei der Einführung von Konstruktionspraktiken erzielt. Basierend auf LeSS haben wir Folgendes implementiert und verwenden es weiterhin:
- Einzelprodukt-Backlog
- Voll funktions- und komponentenübergreifende Befehle
- Pair- und Mob-Programmierung
- True Continuous Integration (CI) - Integration von Code mit 12 Teams in einem Zweig
- Vereinfachte Arbeit mit Filialen (stammbasierte Entwicklung)
- Häufige Releases: Kontinuierliche Bereitstellung für Microservices, tägliche Releases für Monolithen
- QA-Experten lehnen ein separates QA-Team ab und sind Teil des Entwicklungsteams
6 Praktiken, die wir nach der Krise gewählt haben:
1. Die Kraft des Fokus. Vor der Krise arbeitete jedes Team an seinen eigenen Schulden und spezialisierte sich auf sein Gebiet. Während der Krise hatten die Teams keine spezifischen Aufgaben, sie hatten ein großes schwieriges Ziel. Beispielsweise müssen eine mobile Anwendung und eine API 300 Bestellungen pro Minute verarbeiten, egal was passiert. Das Team nimmt das Ziel und überlegt selbständig, wie es erreicht werden kann. Das Team selbst formuliert die Hypothesen und testet sie schnell auf dem Produkt. Teams wollen keine einfachen Programmierer sein, sie wollen Probleme lösen.
Die Kraft des Fokus manifestiert sich in komplexen Aufgaben. Zum Beispiel haben wir während der Krise Stresstests erstellt, obwohl wir keine Erfahrung hatten. Wir haben auch die Logik für den Empfang der Bestellung asynchron gemacht. Wir haben lange darüber nachgedacht und uns unterhalten, und es schien uns, dass dies eine sehr schwierige Aufgabe ist, die viel Zeit in Anspruch nehmen kann. Es stellte sich jedoch heraus, dass das Team in 2 Wochen durchaus in der Lage ist, dies zu tun, wenn es nicht abgelenkt ist und sich vollständig auf das Problem konzentriert.
2. Interne Hackathons. Wir haben den 500 Errors Hackathon durchgeführt. Alle Teams zusammen haben die Protokolle gelöscht und die Ursachen für 500 Fehler auf der Site und in der API beseitigt. Ziel war es, die Protokolle sauber zu halten. Wenn die Protokolle sauber sind und neue Fehler deutlich sichtbar sind, können Sie problemlos Schwellenwerte für Warnungen festlegen.
Ein weiteres Beispiel für einen Hackathon sind Bugs. Zuvor hatten wir einen vollständigen Rückstand an Fehlern, von denen einige viele Jahre lang dort rumhingen. Sie schienen nie zu enden. Und jeden Tag tauchten neue auf. Wir haben die Arbeit an Fehlern und den üblichen Backlog-Elementen kombiniert.
#Zerobugspolicy Politik.- Wenn der Fehler länger als 3 Monate im Backlog ist, löschen Sie ihn einfach. Er hatte ewig dort gelegen, und niemand starb.
- Bewerten Sie den Schmerz, den die verbleibenden Fehler den Kunden verursachen. Lassen Sie nur die Fehler, die einer großen Gruppe von Benutzern das Leben schwer machen.
- Vereinbaren Sie einen internen Hackathon für Fehler. Wir haben es in ein paar Sprints geschafft. Jeder Sprint, jedes Team nahm mehrere Fehler und korrigierte sie. Nach 2-3 Sprints hatten wir einen sauberen Rückstand. Jetzt können Sie #zerobugspolicy eingeben.
- #zerobugspolicy. Wenn der Fehler in den Rückstand gerät, wird er definitiv behoben. Jeder Fehler im Backlog hat eine höhere Priorität als jedes andere Backlog-Element. Aber um in den Rückstand zu gelangen, muss der Fehler schwerwiegend sein. Entweder schadet es irreparabel oder es betrifft eine große Anzahl von Benutzern.
3. Vom Projektteam zum stabilen Team. Es gab eine lustige Geschichte mit Projektteams. Während der Krise haben wir Expertenteams gebildet, die für die Aufgabe am besten qualifiziert waren. Nach dem Ende der Krise beschlossen die Teams, diese Praxis fortzusetzen. Trotz der Tatsache, dass mir diese Idee überhaupt nicht gefallen hat, haben wir es versucht. In nur 2 Wochen (ein Sprint), in der nächsten Retrospektive, gaben die Teams dieses Training auf (diese Entscheidung machte mich glücklich). Wenn einem Team einige Fähigkeiten fehlen, können sie nach und nach lernen. Teamgeist, Unterstützung und gegenseitige Unterstützung dauern jedoch sehr lange, es dauert Monate. Kurzfristige Projektteams befinden sich ständig in der Phase der Bildung und des Sturms. Sie können dies mehrere Wochen lang tolerieren, aber Sie werden nicht immer auf diese Weise arbeiten können.
4. Keine manuelle Regression. Wir haben uns zum Ziel gesetzt, manuelle Regressionen loszuwerden. Wir haben 1,5 Jahre gebraucht, um es zu erreichen. Wenn Sie jedoch ein langfristig ehrgeiziges Ziel haben, denken Sie über die Schritte nach, die zum Ziel führen.
Wir haben es in 3 Schritten gemacht.- Automatisierung kritischer Pfade.
Im Juni 2017 haben wir ein QS-Team gebildet. Die Aufgabe des Teams bestand darin, die Regression der wichtigsten Funktionen von Dodo IS zu automatisieren - den Eingang und die Produktion von Bestellungen. In den nächsten 6 Monaten deckte ein neues 4-köpfiges QS-Team alle kritischen Systemfunktionen mit automatischen Tests ab. Entwickler von Feature-Teams halfen dem QA-Team aktiv. Gemeinsam haben wir eine schöne und verständliche Domain-Sprache (DSL) geschrieben, die auch von Kunden verstanden wurde. Parallel zu End-to-End-Tests gewichteten die Entwickler den Code mit Komponententests. Einige neue Komponenten wurden mit TDD neu gestaltet. Danach haben wir das QA-Team aufgelöst. Ehemalige Mitglieder des QA-Teams schlossen sich den Teams an, die an Geschäftsfunktionen arbeiteten, um die Erfahrung bei der Entwicklung und Unterstützung von Autotests auf Teams zu übertragen. - Schattenmodus.
Mit Autotests haben wir in 5 Releases eine manuelle Regression im Schattenmodus durchgeführt. Die Teams verließen sich nur auf automatische Tests, aber als das Team entschied, dass es zur Veröffentlichung bereit war, starteten wir eine manuelle Regression, um zu überprüfen, ob unsere Autotests Fehler übersehen hatten. Wir haben nachverfolgt, wie viele Fehler manuell und nicht durch automatische Tests abgefangen wurden. Nach 5 Releases haben wir die Daten analysiert und festgestellt, dass wir unseren automatischen Tests vertrauen können. Es wurden keine größeren Fehler übersehen. - Ablehnung der manuellen Regression.
Als wir genug Tests hatten, um ihnen zu vertrauen, haben wir die manuellen Tests vollständig aufgegeben. Je mehr Tests wir schreiben, desto mehr vertrauen wir ihnen. Dies geschah jedoch erst 1,5 Jahre, nachdem wir begonnen hatten, Regressionstests zu automatisieren.
5. Stresstests sind Teil der Regression. Während der Krise haben wir Stresstests geschrieben. Dies war eine völlig neue Erfahrung für uns. In nur zwei Wochen konnten wir jedoch mit Visual Studio-Tools etwas erstellen. Wir haben sie verwendet, um künstliche Last auf dem Server zu erzeugen, um Leistungsgrenzen zu finden. Wenn beispielsweise die organische Belastung des Produkts 100 Bestellungen / min beträgt, haben wir mithilfe unserer Tests weitere 50 Bestellungen / min hinzugefügt, um festzustellen, ob das System die erhöhte Belastung bewältigen kann.
Im folgenden Jahr haben wir Stresstests mit einem erfahrenen PerformanceLab-Team neu geschrieben. Heute werden diese Tests wöchentlich durchgeführt und geben den Entwicklungsteams schnelles Feedback.
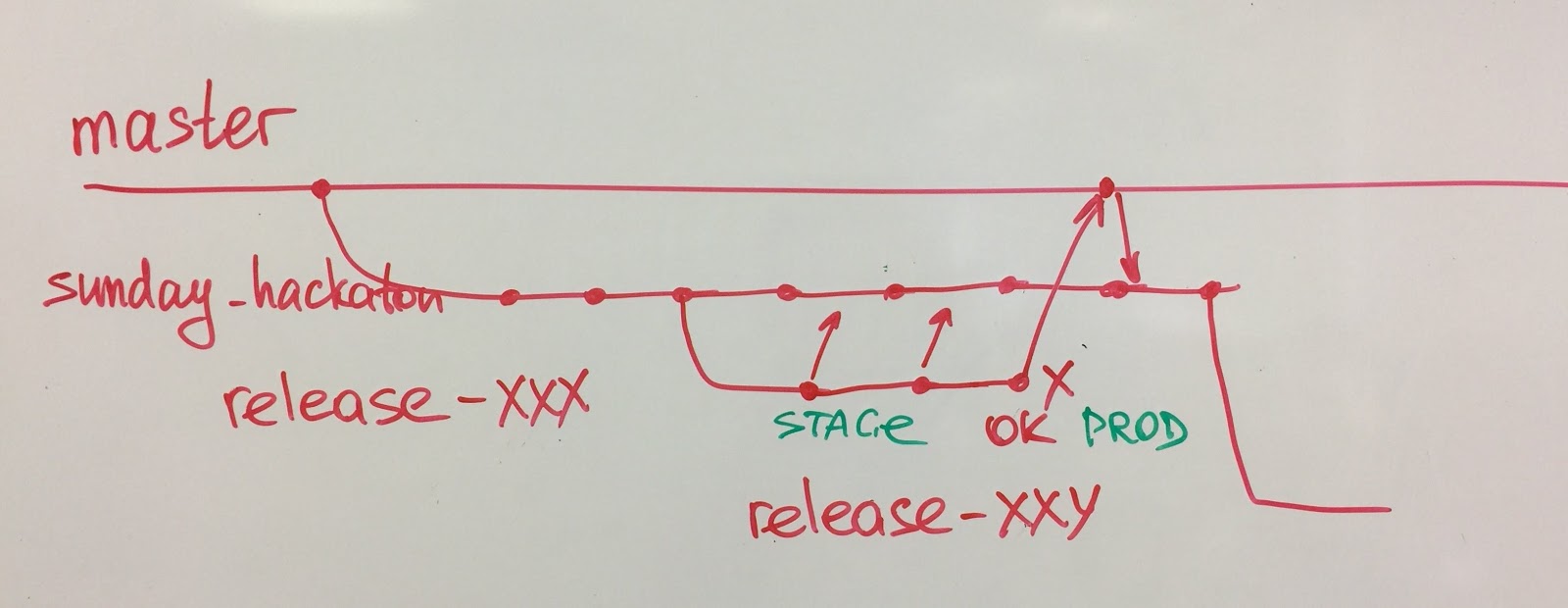 6. Ingenieurspraktiken.
6. Ingenieurspraktiken. Alle unsere Teams verwenden Paarprogrammierung. Ich betrachte die Paarprogrammierung als eine der einfachsten, aber leistungsfähigsten Methoden. Wenn Sie nicht wissen, mit welcher technischen Praxis Sie beginnen sollen, empfehle ich die Paarprogrammierung.
Ergebnisse
Das Hauptergebnis für uns war eine Erschütterung. Wir sind aufgewacht und haben angefangen zu schauspielern. Die Krise hat uns geholfen, unser maximales Potenzial auszuschöpfen. Wir haben gesehen, dass wir um ein Vielfaches effizienter arbeiten und unsere Ziele schnell erreichen können. Dafür ist es jedoch notwendig, die übliche Arbeitsweise zu ändern. Wir haben keine Angst mehr vor kühnen Experimenten.
Als Ergebnis dieser Experimente im letzten Jahr haben wir die Qualität und Stabilität des Dodo IS erheblich verbessert. Wenn unsere Pizzerien in der Frühjahrspause 2018 aufgrund von Dodo IS nicht funktionieren konnten, funktioniert Dodo IS 2019 mit einem Anstieg von 300 auf 498 Pizzerien einwandfrei. Während der zweiten Marketingkampagne und der Frühlingsferien haben wir den Umsatzspitzenwert im neuen Jahr ruhig überstanden.
Zum ersten Mal seit langer Zeit sind wir von der Qualität des Systems überzeugt und können es uns leisten, nachts tief und fest zu schlafen. Dies ist das Ergebnis des fortgesetzten Einsatzes technischer Methoden und des Fokus auf technische Exzellenz.
Geschäftsergebnisse
Engineering-Praktiken sind für sich genommen nicht erforderlich, wenn sie Ihrem Unternehmen nicht zugute kommen. Durch die Fokussierung auf technische Exzellenz verbessern wir die Qualität des Codes und entwickeln Geschäftsfunktionen mit vorhersehbarer Geschwindigkeit. Veröffentlichungen sind für uns zu einem alltäglichen Ereignis geworden.
Ergebnisse für Teams
Heute verwenden wir eine breite Palette von technischen Methoden:
- Voll funktions- und komponentenübergreifende Befehle
- Pair / Mob-Programmierung
- Kontinuierliche Integration - Kontinuierliche Integration von 12 Befehlen in einen Zweig
- Fachexperte als Team
- Es gibt kein separates QA-Team, QA-Experten sind Teil der Entwicklungsteams
- Manuelle Regression durch Autotests ersetzen
- Keine Fehlerrichtlinie (#Zerobugspolicy)
- Stoppen Sie die Leitung als Treiber, um die Bereitstellung zu beschleunigen
Was haben wir gelernt?
Ich möchte, dass die Krise nicht passiert. Als Entwickler fühlte ich mich persönlich dafür verantwortlich, zu viele technische Schulden zu akkumulieren und die Konsequenzen nicht vorhersehen zu können.
- Ingenieurspraktiken schützen Unternehmen vor Krisen
- Sammeln Sie keine technischen Schulden. Es kann zu spät werden und zu viel kosten
- Evolutionäre Veränderungen dauern um ein Vielfaches länger als revolutionäre
- Eine Krise ist nicht immer eine schlechte Sache. Nutzen Sie die Krise, um Prozesse zu revolutionieren
- Im Voraus ist jedoch ein langwieriges Evolutionstraining erforderlich.
- Wenden Sie nicht blind alle Methoden an, die Sie mögen. Einige Methoden warten in den Startlöchern, und wenn er ankommt, werden die Teams sie ohne Widerstand einsetzen. Warten Sie auf den richtigen Moment
- Im Laufe der Zeit beginnen die Teams selbst, wichtige Entscheidungen zu treffen und umzusetzen. Geben Sie ihnen eine Umgebung, in der sie es versuchen, scheitern lassen und aus Fehlern lernen können
Die technische Verschuldung hat uns zu einer schrecklichen Krise geführt. Ich bin sehr froh, dass unser Team die Kraft gefunden hat, diese Pattsituation als Wachstumspunkt zu nutzen. In unserer eigenen Haut haben wir erkannt, dass die Zeit der Krise für massive organisatorische und prozessuale Veränderungen genutzt werden kann und sollte. Geben Sie also niemals auf, denn selbst in den schwierigsten Situationen gibt es Raum für eine Leistung.
Danksagung
Ich möchte mich ganz herzlich bei allen Menschen bedanken, die mir auf meinem Weg von der Krise zur LeSS-Transformation geholfen haben. Ich fühle ständig Ihre Unterstützung.Vielen Dank an unseren CEO Fedor Ovchinnikov für sein Vertrauen. Sie sind ein wahrer Marktführer in einem Unternehmen mit einer echten, flexiblen Kultur.Vielen Dank an Dmitry Pavlov, unseren Product Owner, meinen alten Freund und Co-Trainer.Vielen Dank an Alexander Andronov und Andrey Morevsky für ihre Unterstützung.Vielen Dank an Dasha Bayanova, unsere erste hauptberufliche Scrum-Meisterin, die mir bei all unserer Initiative immer hilft und mich unterstützt. Ihre Hilfe ist schwer zu überschätzen.Besonderer Dank geht an Joanna Rothman, die mir geholfen hat, diesen Bericht unter allen Bedingungen zu schreiben: im Urlaub, nach einer Krankheit. Joanna, es war mir eine Freude, mit Ihnen zusammenzuarbeiten. Ihr Rat, Ihre Liebe zum Detail und Ihre harte Arbeit haben mir sehr geholfen.