
Die Ingenieure von DevOps und SRE haben wahrscheinlich mehr als einmal von Prometheus gehört .
Prometheus wurde 2012 bei SoundCloud entwickelt und ist seitdem zum Standard für Überwachungssysteme geworden . Es verfügt über vollständig Open Source-Code und bietet Dutzende verschiedener Exporteure, mit denen Sie die Überwachung der gesamten Infrastruktur in wenigen Minuten einrichten können.
Prometheus hat einen offensichtlichen Wert und wird bereits von Brancheninnovatoren wie DigitalOcean oder Docker als Teil eines vollständigen Überwachungssystems verwendet.
Was ist Prometheus?
Warum wird es benötigt?
Wie unterscheidet es sich von anderen Systemen?
Wenn Sie überhaupt nichts über Prometheus wissen oder es, sein Ökosystem und alle Interaktionen besser verstehen möchten, ist dieser Artikel nur für Sie .
Wir haben diesen Leitfaden wie bei InfluxDB in drei Teile unterteilt .
- Zunächst erhalten Sie einen vollständigen Überblick über Prometheus , sein Ökosystem und die wichtigsten Aspekte der schnelllebigen Technologie.
- Anschließend werden Erläuterungen zu den technischen Begriffen von Prometheus gegeben. Wenn Sie nicht wissen, was Metriken, Labels, Instanzen oder Exporteure sind, sind Sie hier.
- Abschließend beschreiben wir verschiedene reale Szenarien für die Verwendung von Prometheus . Hier lassen Sie sich von Beispielen erfolgreicher Unternehmen inspirieren.
Teil I. Was ist Prometheus?
Prometheus ist eine Zeitreihendatenbank. Wenn Sie nicht wissen, was eine Zeitreihendatenbank ist, lesen Sie den ersten Teil des InfluxDB-Handbuchs .
Prometheus ist jedoch nicht nur eine Zeitreihendatenbank.
Sie können ein ganzes Ökosystem von Tools daran anhängen, um die Funktionalität zu erweitern.
Prometheus überwacht eine Vielzahl von Systemen : Server, Datenbanken, einzelne virtuelle Maschinen und fast alles.
Zu diesem Zweck kratzt Prometheus regelmäßig seine Ziele .
Was ist Schaben?
Prometheus ruft Metriken über HTTP-Aufrufe an bestimmte Endpunkte ab, die in der Prometheus-Konfiguration angegeben sind.
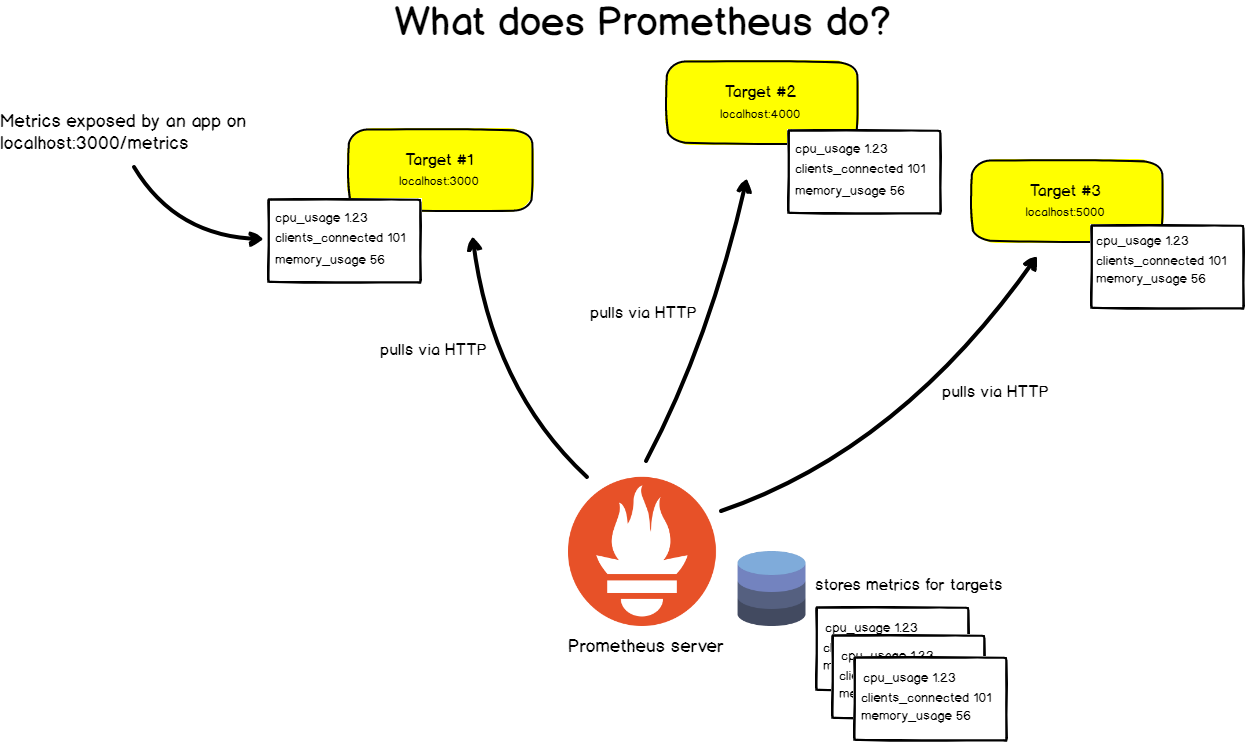
Nehmen Sie zum Beispiel die Webanwendung unter http: // localhost: 3000 . Die Anwendung überträgt Metriken im Textformat an eine URL. Sagen wir http: // localhost: 3000 /metrics .
An dieser Adresse ruft Prometheus in bestimmten Intervallen Daten vom Ziel ab.
1. Wie funktioniert Prometheus?
Wie gesagt, Prometheus besteht aus einer Vielzahl von Komponenten.
Zunächst benötigen Sie es, um Metriken aus Ihren Systemen zu extrahieren. Es gibt verschiedene Möglichkeiten:
- Instrumentierung der Anwendung, dh Ihre Anwendung stellt Prometheus-kompatible Metriken unter der angegebenen URL bereit. Prometheus identifiziert es als Ziel und verschrottet es im angegebenen Intervall.
- Verwendung von vorgefertigten Exporteuren . Prometheus verfügt über eine Sammlung von Exporteuren für vorhandene Technologien. Zum Beispiel vorgefertigte Exporteure zur Überwachung von Linux-Computern ( Node Exporter ), für gängige Datenbanken ( SQL Exporter oder MongoDB Exporter ) und sogar für HTTP-Load Balancer (z. B. HAProxy Exporter ).
- Pushgateway verwenden . Manchmal stellen Anwendungen oder Aufgaben keine Metriken direkt bereit. Sie sind möglicherweise nicht dafür ausgelegt (z. B. Stapeljobs), oder Sie haben selbst entschieden, keine Metriken direkt über die Anwendung bereitzustellen.
Wie Sie bereits verstanden haben, sammelt Prometheus Daten selbst (mit Ausnahme der seltenen Fälle, in denen wir Pushgateway verwenden).
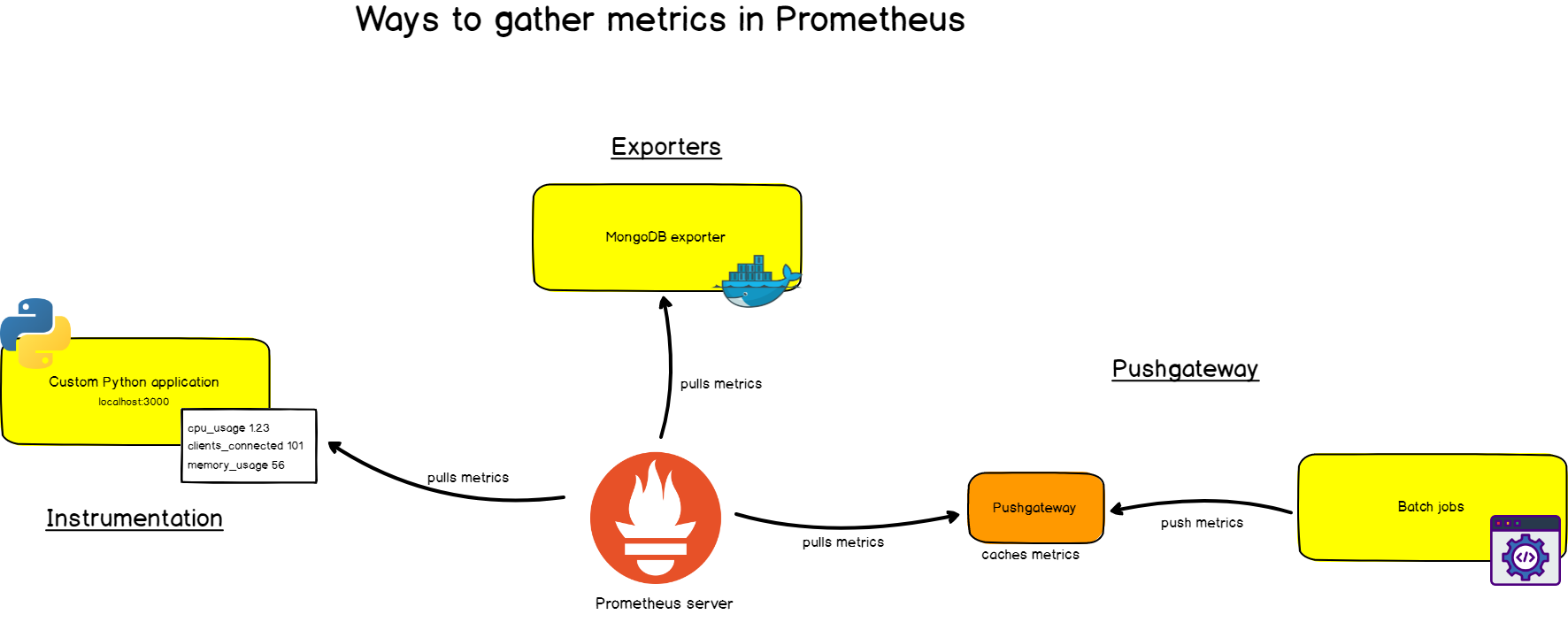
Was bedeutet das?
Warum wird das benötigt?
2. Sammlung vs. Senden
Prometheus unterscheidet sich deutlich von anderen Zeitreihendatenbanken: Es scannt Ziele aktiv, um Metriken von ihnen zu erhalten .
InfluxDB funktioniert beispielsweise anders: Sie senden Daten direkt selbst an sie .
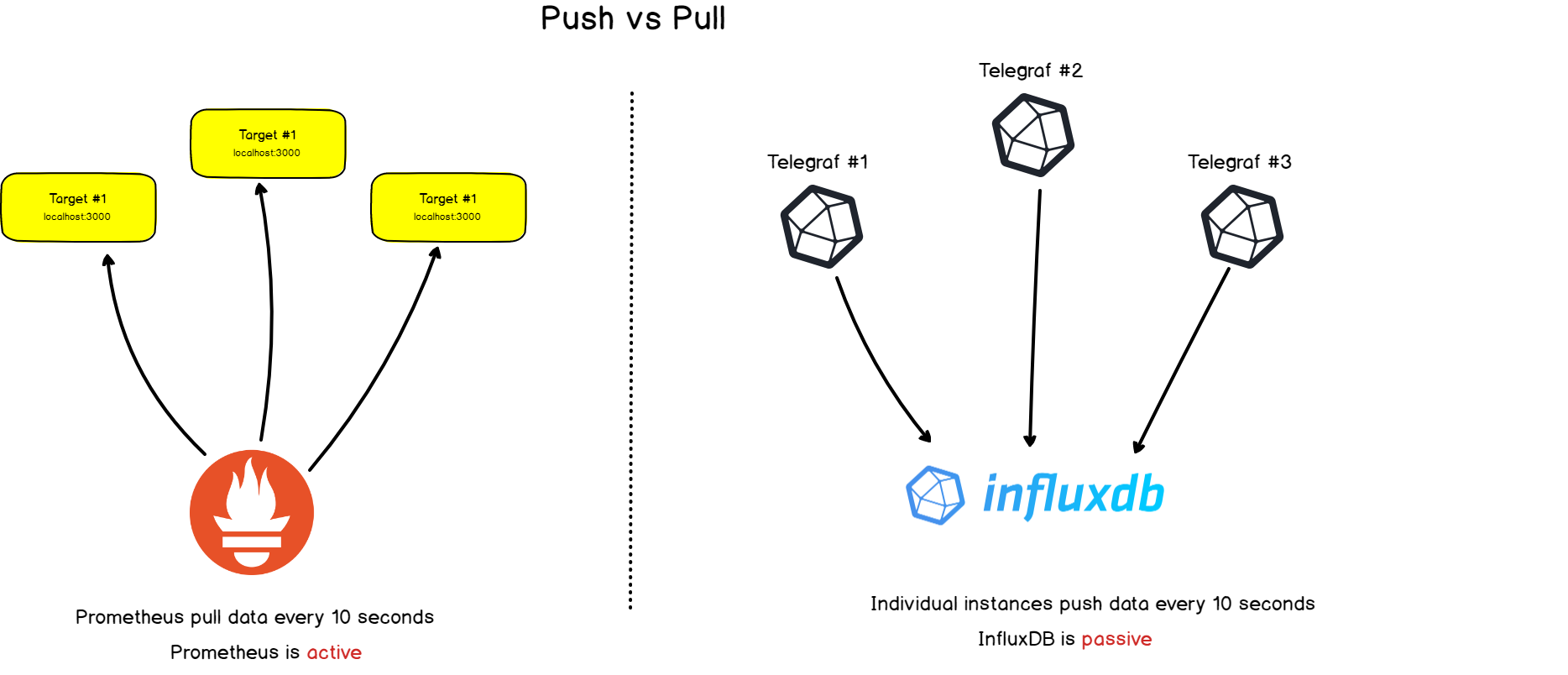
Beide Ansätze haben ihre Vor- und Nachteile. Basierend auf der verfügbaren Dokumentation haben wir eine Liste der Gründe zusammengestellt, warum sich die Macher von Prometheus für diese Architektur entschieden haben:
- Zentrale Steuerung . Wenn Prometheus Anforderungen an Ziele sendet, führen wir die gesamte Konfiguration auf der Prometheus-Seite durch, nicht auf den einzelnen Systemen.
Prometheus entscheidet, wo und wie oft er kratzen soll.
Wenn die Objekte selbst Daten senden, besteht das Risiko, dass zu viele dieser Daten vorhanden sind und der Server abstürzt. Wenn das System Daten sammelt, können Sie die Häufigkeit der Erfassung steuern und mehrere Scraping-Konfigurationen erstellen, um eine unterschiedliche Häufigkeit für verschiedene Objekte auszuwählen.
- Prometheus speichert aggregierte Metriken .
Dies ist eine Ergänzung zum ersten Teil, in dem wir die Rolle des Prometheus besprochen haben.
Prometheus ist nicht ereignisbasiert und unterscheidet sich stark von anderen Zeitreihendatenbanken. Es werden keine einzelnen Ereignisse mit Bezug auf die Zeit abgefangen (z. B. Dienstausfälle), sondern voraggregierte Metriken zu Ihren Diensten erfasst .
Insbesondere sendet der Webdienst keine 404-Fehlermeldung und keine Nachricht mit der Fehlerursache. Es wird eine Nachricht gesendet, dass der Dienst in den letzten fünf Minuten eine 404-Fehlermeldung erhalten hat.
Dies ist der Hauptunterschied zwischen Zeitreihendatenbanken, die aggregierte Metriken erfassen, und solchen, die Rohmetriken erfassen.
3. Entwickeltes Prometheus-Ökosystem
Prometheus ist im Wesentlichen eine Zeitreihendatenbank.
Wenn Sie jedoch mit solchen Datenbanken arbeiten, müssen Sie die Daten häufig visualisieren , analysieren und Warnungen für sie konfigurieren.
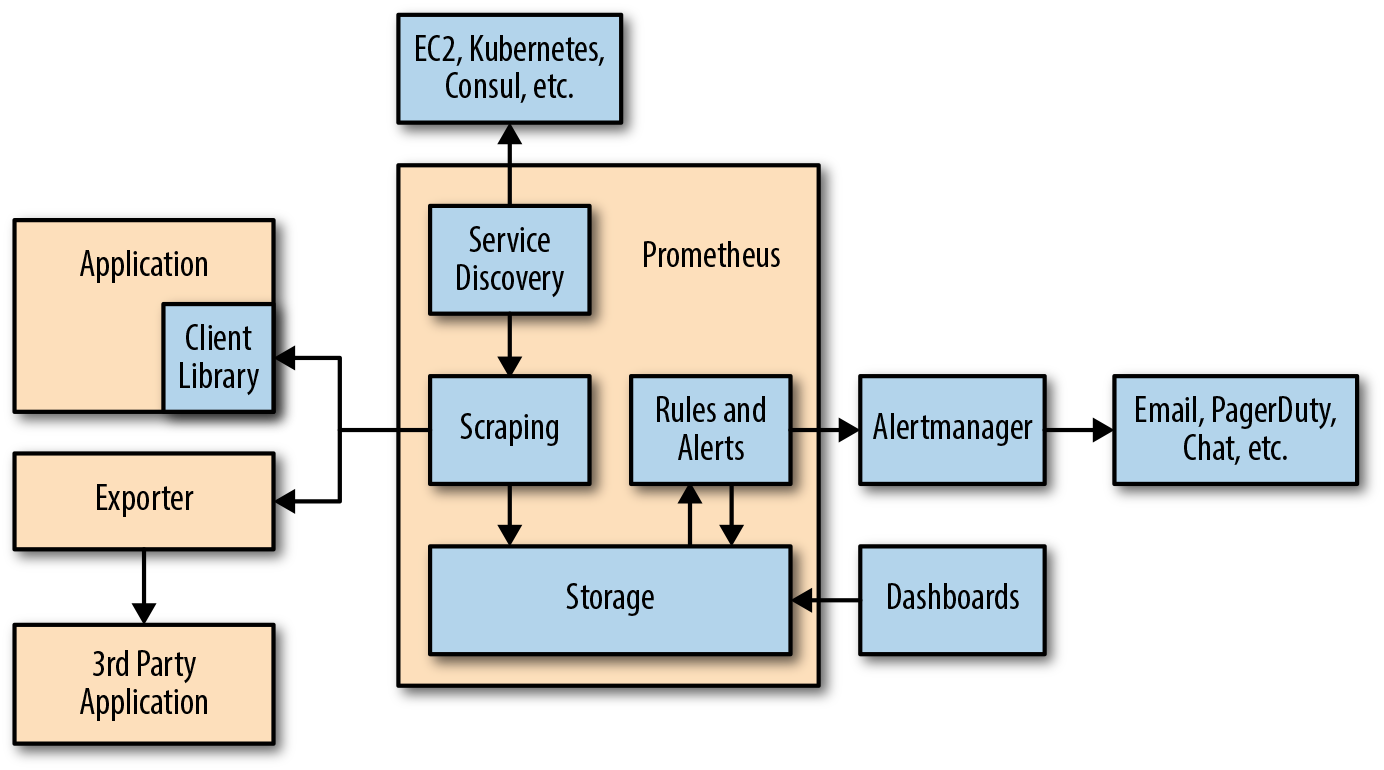
Prometheus unterstützt die folgenden Tools, die seine Funktionalität erweitern:
- Alertmanager . Prometheus sendet Warnungen an Alertmanager basierend auf benutzerdefinierten Regeln, die in Konfigurationsdateien definiert sind. Von dort können sie an verschiedene Endpunkte exportiert werden (z. B. Pagerduty oder Slack).
- Datenvisualisierung . Wie bei Grafana können Sie Zeitreihen direkt in der Prometheus-Webbenutzeroberfläche visualisieren. Sie können die Daten filtern und spezifische Überprüfungen der Vorgänge in verschiedenen Zielen erstellen.
- Serviceerkennung . Prometheus erkennt Ziele dynamisch und kratzt auf Anfrage automatisch neue Ziele. Dies ist besonders praktisch, wenn Sie mit Containern arbeiten, die Adressen je nach Bedarf dynamisch ändern.

Teil II Prometheus-Konzepte
Wie im InfluxDB-Handbuch werden wir die technischen Begriffe zu Prometheus ausführlich erläutern.
1. Schlüsselwertdatenmodell
Bevor Sie mit den Prometheus-Tools fortfahren, ist es wichtig, dieses Datenmodell vollständig zu verstehen.
Prometheus arbeitet mit Schlüssel-Wert-Paaren . Der Schlüssel beschreibt, was wir messen, und der Wert speichert den tatsächlichen Wert als Zahl.
Denken Sie daran: Prometheus ist nicht zum Speichern von Rohdaten wie einfachem Text vorgesehen. Es speichert über einen bestimmten Zeitraum aggregierte Metriken.
Der Schlüssel wird in diesem Fall als Metrik bezeichnet . Dies ist beispielsweise die Prozessorgeschwindigkeit oder die Speichernutzung.
Aber was ist, wenn Sie weitere Details zur Metrik benötigen?
Zum Beispiel hat der Prozessor 4 Kerne und wir brauchen 4 separate Metriken?
Und hier kommen Abkürzungen zur Rettung. Verknüpfungen bieten weitere Informationen zu Metriken, indem Sie zusätzliche Felder hinzufügen. Beispielsweise beschreiben Sie nicht nur die Geschwindigkeit des Prozessors, sondern auch die Geschwindigkeit eines Kerns über eine bestimmte IP.
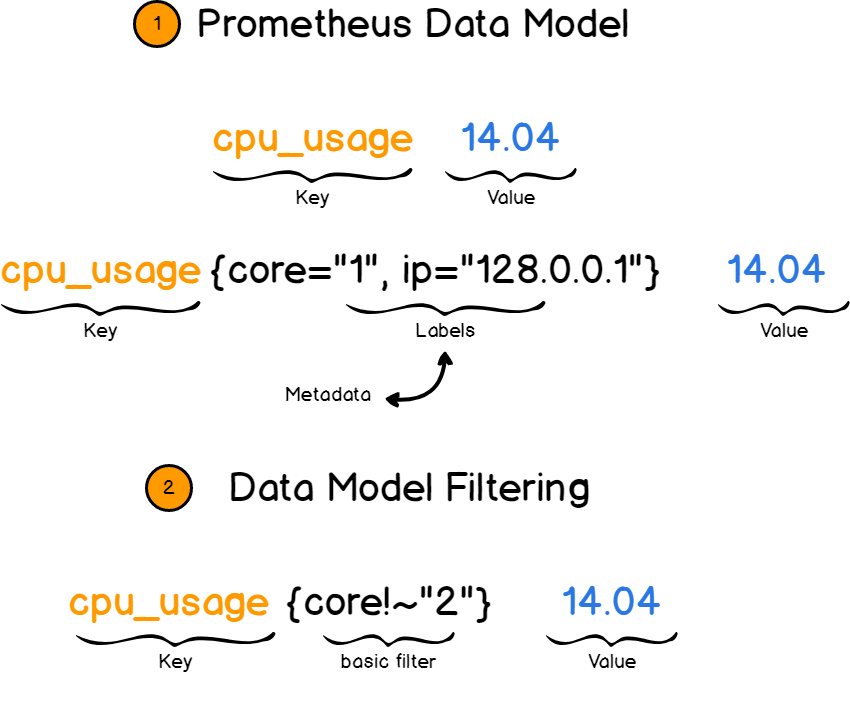
Anschließend können Sie die Metriken nach Beschriftungen filtern und nur die benötigten Informationen anzeigen.
2. Arten von Metriken
Bei der Überwachung mit Prometheus können Metriken auf vier Arten beschrieben werden. Es ist besser, es bis zum Ende zu lesen, da es hier Fallstricke gibt.
Zähler
Dies ist wahrscheinlich die einfachste Art von Metrik. Der Zähler zählt, wie der Name schon sagt, die Elemente für einen bestimmten Zeitraum .
Wenn Sie beispielsweise HTTP-Fehler auf Servern zählen oder eine Website besuchen möchten, verwenden Sie einen Zähler .
Und logischerweise kann der Zähler natürlich nur die Zahl erhöhen oder auf Null setzen , daher ist er nicht für Werte geeignet, die abnehmen können, oder für negative Werte.
Mit seiner Hilfe ist es besonders zweckmäßig, die Anzahl des Auftretens eines bestimmten Ereignisses über einen Zeitraum zu berücksichtigen, d. H. Die Änderungsrate der Metrik über die Zeit.
Und wenn Sie beispielsweise den verwendeten Speicher für einen bestimmten Zeitraum messen müssen?
Dieser Wert kann abnehmen. Wie zählt man es mit Prometheus?
Meter
Treffen Sie die Meter!
Zähler behandeln Werte, die mit der Zeit abnehmen können . Sie können mit Thermometern verglichen werden. Wenn Sie sich das Thermometer ansehen, sehen wir die aktuelle Temperatur.
Aber wenn die Zähler zunehmen und abnehmen und positive und negative Werte annehmen können, stellt sich heraus, dass sie besser sind als Zähler?
Also sind die Zähler nutzlos?
Zuerst dachte ich es mir. Da sie alles können, verwenden wir sie überall. Ist es logisch?
Aber nein.
Messgeräte sind ideal zum Messen des aktuellen Metrikwerts, der mit der Zeit abnehmen kann.
Hier liegen die Fallstricke: Der Zähler zeigt nicht die Entwicklung der Metrik über einen bestimmten Zeitraum an. Mithilfe von Messgeräten können Sie unregelmäßige Änderungen der Metrik im Laufe der Zeit verpassen .
Warum? Folgendes sagt / u / justinDavidow :
„Das Messgerät zeigt den Durchschnittswert des Zählerdeltas für eine Einheit über einen bestimmten Zeitraum an.
Der Zähler berücksichtigt jede verwendete Einheit (wenn es sich um einen Prozessor handelt, dann Operationen, Zyklen oder Ticks), und Sie können dann auswählen, welche Indikatoren für welchen Zeitraum Sie benötigen.
Wenn Sie ein Messgerät verwenden, muss die Abtastrate genau sein. Wenn sich die Frequenz um mindestens einige Mikrosekunden unterscheidet, ist der Wert unzuverlässig. "Dies macht sich unter starker Last noch deutlicher bemerkbar, wenn die Zeit zwischen den Messungen exponentiell zunimmt, da der Systemplaner keine Zeit hat, auf die Überwachungsanwendung zu achten."
Wenn das System alle 5 Sekunden Metriken sendet und Prometheus das Ziel alle 15 Sekunden abkratzt, gehen möglicherweise einige Metriken verloren. Wenn Sie mit diesen Metriken zusätzliche Berechnungen durchführen, ist die Genauigkeit der Ergebnisse sogar noch geringer.
Am Zähler wird jeder Wert aggregiert. Wenn Prometheus es sammelt, stellt er fest, dass der Wert in einem bestimmten Intervall gesendet wurde.
Jetzt nicht verwirren.
Balkendiagramm
Ein Histogramm ist eine komplexere Art von Metrik. Es bietet zusätzliche Informationen. Zum Beispiel die Summe der Messungen und ihre Anzahl.
Die Werte werden in einem Bereich mit einer benutzerdefinierten Obergrenze erfasst. Daher kann ein Histogramm:
- Berechnen Sie Durchschnittswerte , d. H. Die Summe der Werte geteilt durch die Anzahl der Werte.
- Berechnen Sie relative Wertemessungen. Dies ist sehr praktisch, wenn Sie herausfinden möchten, wie viele Werte in einem bestimmten Bereich den angegebenen Kriterien entsprechen. Dies ist besonders nützlich, wenn Sie Proportionen verfolgen oder Qualitätsindikatoren festlegen müssen.
In der realen Welt möchte ich eine Warnung erhalten, wenn 20% meiner Server in mehr als 20% der Fälle eine Antwort von mehr als 300 ms oder eine Serverantwort von mehr als 300 ms haben.
Wenn Sie mit Proportionen zu tun haben, benötigen Sie Histogramme .
Zusammenfassung
Dashboards sind erweiterte Histogramme . Sie zeigen auch die Summe und Anzahl der Messungen sowie Quantile für die Bewegungsperiode .
Quantile teilen, wenn überhaupt, die Wahrscheinlichkeitsdichte in Segmente gleicher Wahrscheinlichkeit.
Also: Balkendiagramme oder Zusammenfassungen?
Es hängt alles von der Absicht ab .
Histogramme kombinieren Werte über einen bestimmten Zeitraum und geben die Menge und Menge an, anhand derer Sie die Entwicklung einer bestimmten Metrik verfolgen können.
Die Zusammenfassungen zeigen andererseits Quantile über einen sich bewegenden Zeitraum (d. H. Kontinuierliche Entwicklung über die Zeit).
Dies ist besonders praktisch, wenn Sie einen Wert kennen müssen, der 95% der über einen Zeitraum aufgezeichneten Werte darstellt.
3. Aufgaben und Instanzen
Angesichts der jüngsten Fortschritte bei verteilten Architekturen und der Beliebtheit von Cloud-basierten Lösungen ist es unwahrscheinlich, dass Sie einen einzelnen Server verwenden, der alleine ausgeführt wird.
Server werden weltweit repliziert und verteilt.
Schauen wir uns zur Veranschaulichung die klassische Architektur von zwei HAProxy-Servern an, die die Last auf neun Backend-Webserver verteilen ( Nein, Nein, keine Stackoverflow-Stapel ).
In diesem Beispiel aus der Praxis verfolgen wir die Anzahl der von Webservern zurückgegebenen HTTP-Fehler .
In Prometheus wird ein Webserver als Instanz bezeichnet . Die Aufgabe besteht darin, dass Sie die Anzahl der HTTP-Fehler in allen Instanzen messen.
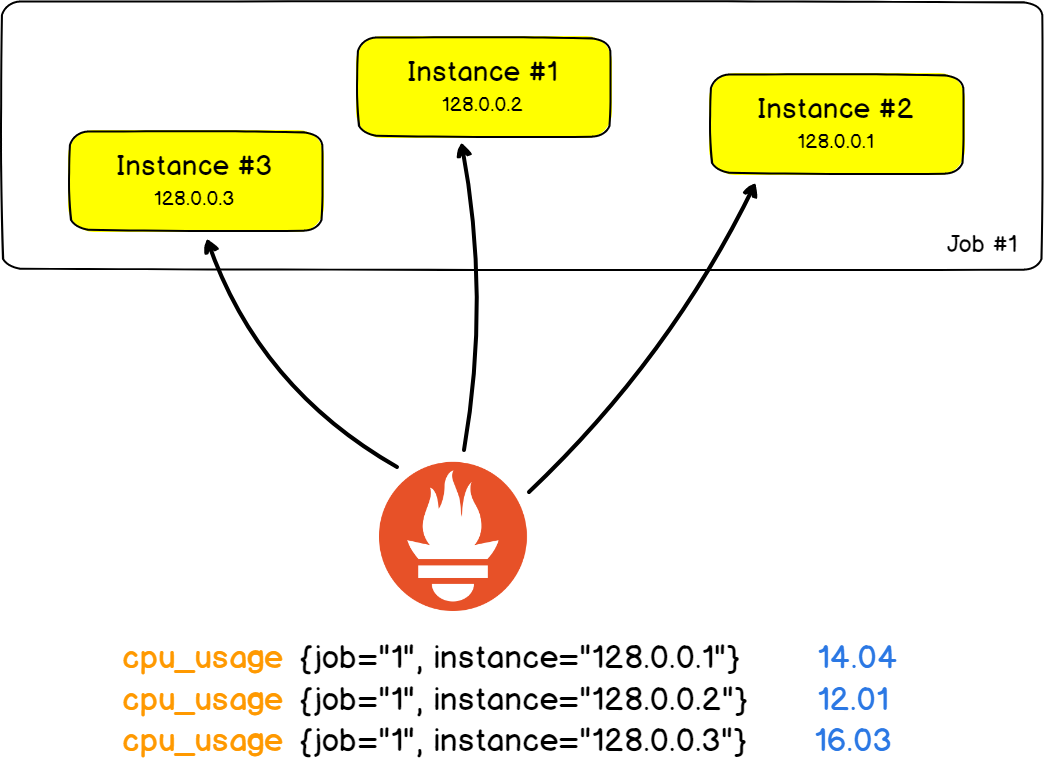
Das Schöne ist, dass Aufgaben und Instanzen Felder in Beschriftungen sind und Sie die Ergebnisse nach einer bestimmten Instanz oder Aufgabe filtern können.
Ist es bequem?
4. PromQL
Wenn Sie auf InfluxDB basierende Datenbanken verwenden, sind Sie wahrscheinlich bereits mit InfluxQL vertraut. Oder verwenden Sie SQL in TimescaleDB .
Prometheus hat auch eine eigene Sprache zum Abfragen und Abrufen von Daten von Servern: PromQL .
Wie wir bereits wissen, werden Daten in Form von Schlüssel-Wert-Paaren dargestellt. PromQL verwendet dieselbe Syntax und gibt Ergebnisse als Vektoren zurück.
Welche Art von Vektoren?
Es gibt zwei Arten von Vektoren in Prometheus und PromQL:
- Sofortvektoren , die alle Metriken nach dem letzten Zeitstempel darstellen.
- Vektoren mit einem Zeitbereich : Wenn Sie die Entwicklung einer Metrik im Zeitverlauf betrachten müssen, können Sie in einer Anfrage an Prometheus einen Zeitbereich angeben. Als Ergebnis erhalten Sie einen Vektor, der alle für den ausgewählten Zeitraum aufgezeichneten Werte kombiniert.
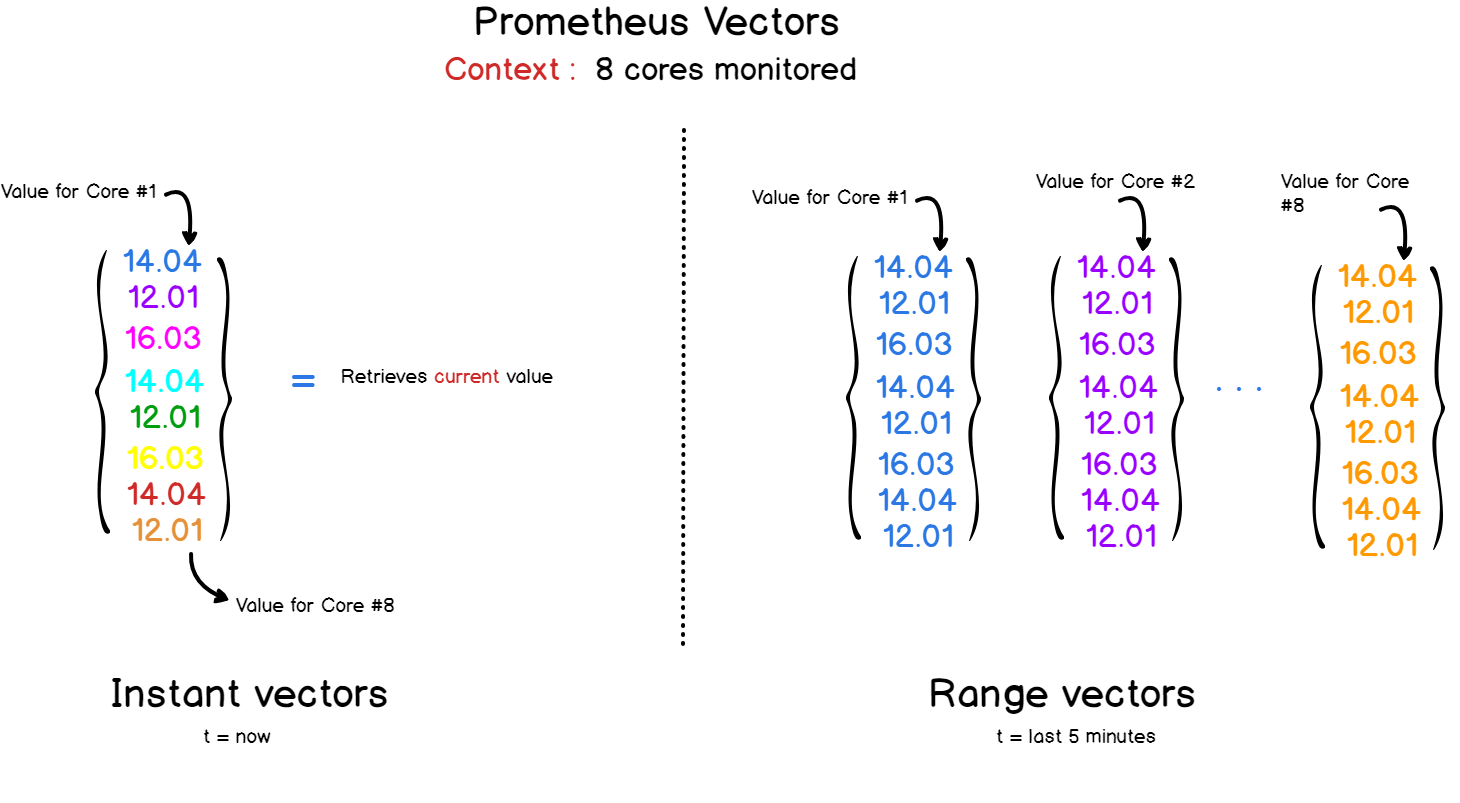
Die PromQL-API bietet eine Reihe von Funktionen für Operationen mit Daten in Abfragen.
Sie können Werte sortieren, mathematische Funktionen auf sie anwenden (z. B. Ableitungen oder Exponenten berechnen) und sogar Vorhersagen treffen (z. B. mithilfe des Holt-Winters-Modells).
5. Instrumentierung
Instrumentierung ist ein weiterer wichtiger Bestandteil von Prometheus. Sie instrumentieren Anwendungen, bevor Sie Daten daraus extrahieren.
In Prometheus bedeutet Instrumentierung das Hinzufügen von Clientbibliotheken zur Anwendung, um Prometheus-Metriken bereitzustellen.
Die Instrumentierung ist für die meisten gängigen Programmiersprachen verfügbar: z. B. Python, Java, Ruby, Go und sogar Node oder C # .
Im Wesentlichen erstellen Sie Speicherobjekte (z. B. Zähler oder Zähler), die den Wert dynamisch erhöhen oder verringern.
Anschließend wählen Sie aus, wo die Metriken bereitgestellt werden sollen. Prometheus holt sie von dort ab und speichert sie in ihrer Zeitreihendatenbank.
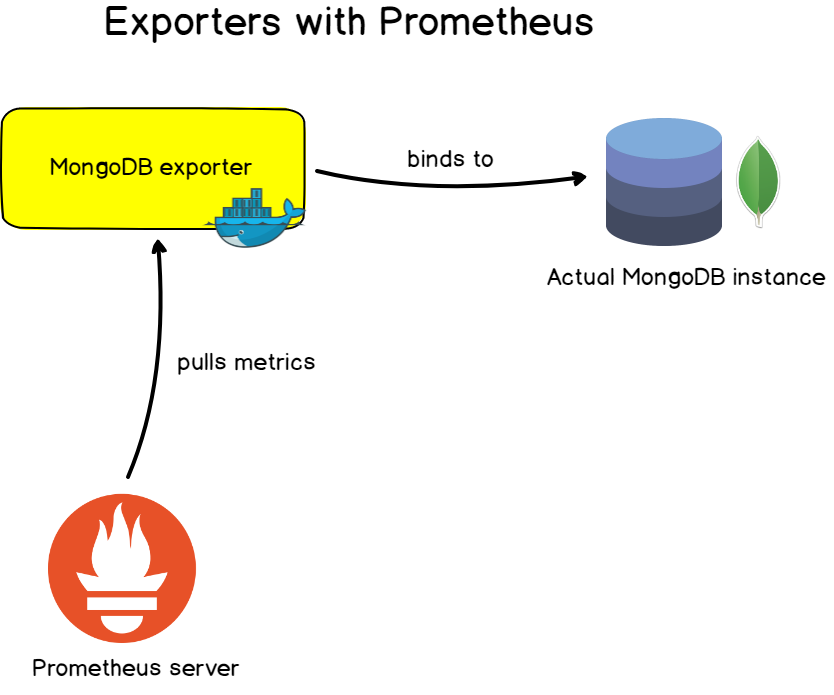
6. Exporteure
In den von Ihnen geschriebenen Anwendungen ist es sehr praktisch, die bereitgestellten Metriken anzupassen und sie mithilfe von Instrumenten im Laufe der Zeit zu ändern.
Für bekannte Anwendungen, Server und Datenbanken bietet Prometheus Exporteure, mit denen Sie Ziele überwachen können .
Diese Exporteure werden normalerweise als Docker-Images dargestellt und können einfach angepasst werden. Sie bieten einen vorgefertigten Satz von Metriken und häufig vorgefertigte Dashboards, mit denen Sie die Überwachung in wenigen Minuten konfigurieren können.
Beispiele für Exporteure:
- Datenbankexporteure : für MongoDB-Datenbanken, SQL- und MySQL-Server.
- HTTP-Exporteure : für HAProxy-, Apache- oder NGINX-Server.
- Unix-Exporteure : Die Systemleistung kann mithilfe der integrierten Knotenexporteure überwacht werden, die alle Systemmetriken ohne zusätzliche Konfiguration bereitstellen.
Ein paar Worte zur gegenseitigen Kompatibilität
Die meisten Zeitreihendatenbanken unterstützen die Interoperabilität ihrer Systeme.
Prometheus ist nicht das einzige Überwachungssystem mit seinen metrischen Anforderungen. Zum Beispiel haben InfluxDB (über Telegraf), CollectD , StatsD und Nagios auch ihre eigenen Standards.
Daher werden für das Zusammenspiel verschiedener Systeme Exporteure geschaffen. Selbst wenn Telegraf keine Metriken in dem von Prometheus akzeptierten Format sendet, kann Telegraf diese Metriken an den InfluxDB-Exporter senden, von dem Prometheus sie dann abholt.
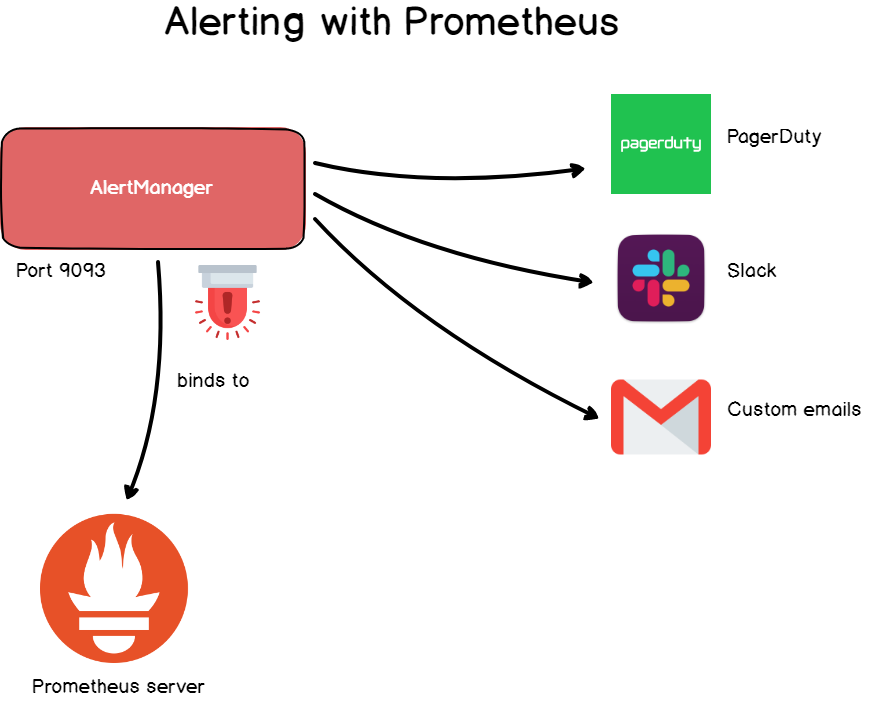
7. Warnungen
Wenn Sie mit Zeitreihendatenbanken arbeiten, benötigen Sie Feedback von den Daten, und Alert Manager sind dafür verantwortlich.
In Grafana sind Warnungen häufig, sie sind jedoch auch in Prometheus über den Warnungsmanager verfügbar.
Alert Manager ist ein separates Tool, das Prometheus beitritt und benutzerdefinierte Sirenen startet .
Warnungen werden in der Konfigurationsdatei definiert und definieren eine Reihe von Regeln für Metriken. Wenn die Regel in der Zeitreihe eingehalten wird, wird eine Warnung ausgelöst und an die angegebenen Empfänger gesendet.
Wie in Grafana können Sie die E-Mail-Adresse, den Slack-Webhook, PagerDuty und benutzerdefinierte HTTP-Objekte als Empfänger angeben.
Teil III. Prometheus Beispiele

Und natürlich sollte jeder Leitfaden praktische Beispiele haben . Wie ich gerne sagen möchte, ist Technologie kein Selbstzweck und sollte eine bestimmte Aufgabe erfüllen.
Wir werden darüber reden.
1. DevOps
Bei all diesen Exporteuren für verschiedene Systeme, Datenbanken und Server ist es offensichtlich, dass Prometheus hauptsächlich für die DevOps-Industrie bestimmt ist .
Wir wissen, dass es in diesem Bereich viele konkurrierende Lieferanten und personalisierte Lösungen gibt.
Prometheus ist perfekt für DevOps.
Das Einrichten und Ausführen von Instanzen ist nahezu mühelos und Sie können jedes Hilfstool einfach aktivieren und konfigurieren.
Durch die Erkennung von Zielen - beispielsweise über einen Dateiexporter - ist dies eine hervorragende Lösung für Stapel, in denen Container und verteilte Architekturen weit verbreitet sind.
In einer Umgebung, in der ständig Instanzen erstellt und gelöscht werden, kann kein einziger DevOps-Stack auf die Serviceerkennung verzichten .
2. Gesundheit
Überwachungslösungen werden heute nicht nur in der IT benötigt. Sie werden auch in großen Branchen eingesetzt, die flexible und skalierbare Gesundheitsarchitekturen bereitstellen.
Die Nachfrage wächst und IT-Architekturen müssen diese erfüllen. Wenn Sie nicht über ein zuverlässiges Tool zur Überwachung der gesamten Infrastruktur verfügen, besteht die Gefahr schwerwiegender Betriebsunterbrechungen . Bereits im Gesundheitsbereich muss eine solche Gefahr unbedingt minimiert werden.
Dieses Beispiel wurde im folgenden Artikel unter opensource.com erläutert .
3. Finanzdienstleistungen
Das jüngste Beispiel wurde auf der InfoQ-Konferenz gegeben, auf der die Verwendung von Prometheus in Finanzinstituten erörtert wurde.
Jamie Christian und Alan Strader zeigen, wie sie Prometheus verwenden, um ihre Infrastruktur bei Northern Trust zu überwachen. Sehr informativ, ich rate Ihnen zu schauen.
Teil X. Wie geht es weiter?

Es ist Zeit, von der Theorie zur Praxis überzugehen .
Heute haben Sie die Grundlagen von Prometheus kennengelernt, gelernt, welche Funktionen es ausführt, mit welchen Tools und Systemen es arbeitet und welche Begriffe es verwendet.
Jetzt haben Sie alles, was Sie zum Erstellen Ihrer Überwachungslösung benötigen .
Um mit Prometheus zu beginnen, studieren Sie alle verfügbaren Exporteure .
Installieren Sie dann die erforderlichen Tools, erstellen Sie Ihr erstes Dashboard - und los geht's!
Wenn Sie Inspiration benötigen, lesen Sie meinen Artikel über die Überwachung eines Linux-Computers mit Prometheus und Grafana . Es gibt Anweisungen zum Einrichten von Tools und des ersten Dashboards.
Ich hoffe du hast etwas Neues gelernt.
Wenn Sie ein Thema für meinen nächsten Artikel haben, teilen Sie es.
Gerne bleiben!