Bedeutende wissenschaftliche Arbeiten aus dem Jahr 2012 haben das Gebiet der Bilderkennungssoftware verändert

Heute kann ich beispielsweise Google Fotos öffnen, "Strand" schreiben und einige meiner Fotos von verschiedenen Stränden sehen, die ich im letzten Jahrzehnt besucht habe. Und ich habe meine Fotos nie signiert - Google erkennt Strände an ihnen anhand ihres Inhalts. Diese scheinbar langweilige Funktion basiert auf einer Technologie namens „Deep Convolutional Neural Network“, mit der Programme Bilder mit einer komplexen Methode verstehen können, auf die Technologien früherer Generationen nicht zugreifen können.
In den letzten Jahren haben Forscher festgestellt, dass die Softwaregenauigkeit besser wird, wenn sie tiefere neuronale Netze (NS) aufbauen und diese auf immer größeren Datenmengen trainieren. Dies führte zu einem unstillbaren Bedarf an Rechenleistung und bereicherte GPU-Hersteller wie Nvidia und AMD. Vor einigen Jahren hat Google eigene Spezialchips für die Nationalversammlung entwickelt, während andere Unternehmen versuchen, mitzuhalten.
Bei Tesla beispielsweise wurde Andrei Karpati, ein Experte für tiefes Lernen, zum Leiter des Autopilot-Projekts ernannt. Jetzt entwickelt der Autohersteller einen eigenen Chip, um die Arbeit des NS in zukünftigen Versionen des Autopiloten zu beschleunigen. Oder nehmen Sie Apple: Die A11- und A12-Chips, die für die neuesten iPhones von zentraler Bedeutung sind, verfügen über einen „
neuronalen Prozessor “ der Neural Engine, der den NS beschleunigt und es Bild- und Spracherkennungsanwendungen ermöglicht, besser zu funktionieren.
Die Experten, die ich für diesen Artikel interviewt habe, verfolgen den Beginn des Deep-Learning-Booms für einen bestimmten Job: AlexNet, benannt nach dem Hauptautor Alex Krizhevsky. "Ich glaube, dass 2012 ein Meilenstein war, als AlexNets Arbeit herauskam", sagte Sean Gerrish, Experte für Verteidigung und Autor des Buches "
How Smart Cars Think ".
Bis 2012 waren tiefe neuronale Netze (GNS) in der Welt der Region Moskau ein Rückstau. Aber dann nahmen Krizhevsky und seine Kollegen von der Universität von Toronto an dem prestigeträchtigen Wettbewerb um Bilderkennung teil, und ihr Programm übertraf in seiner Genauigkeit alles, was zuvor entwickelt wurde, dramatisch. Fast augenblicklich wurde STS zur führenden Technologie bei der Bilderkennung. Andere Forscher, die diese Technologie verwendeten, zeigten bald weitere Verbesserungen der Erkennungsgenauigkeit.
In diesem Artikel werden wir uns mit tiefem Lernen befassen. Ich werde erklären, was NS ist, wie sie geschult werden und warum sie solche Computerressourcen benötigen. Und dann werde ich erklären, warum eine bestimmte Art von NS - Deep Convolution Networks - Bilder so gut versteht. Keine Sorge, es wird viele Bilder geben.
Ein einfaches Beispiel mit einem Neuron
Das Konzept eines „neuronalen Netzwerks“ mag Ihnen vage erscheinen. Beginnen wir also mit einem einfachen Beispiel. Angenommen, Sie möchten, dass die Nationalversammlung anhand der grünen, gelben und roten Verkehrssignale entscheidet, ob Sie ein Auto fahren. NS kann dieses Problem mit einem einzelnen Neuron lösen.

Ein Neuron empfängt Eingabedaten (1 - Ein, 0 - Aus), multipliziert mit dem entsprechenden Gewicht und addiert alle Werte der Gewichte. Dann fügt das Neuron einen Offset hinzu, der den Schwellenwert für die "Aktivierung" des Neurons definiert. In diesem Fall glauben wir, dass das Neuron aktiviert wurde, wenn die Ausgabe positiv ist - und umgekehrt. Das Neuron entspricht der Ungleichung "grün - rot - 0,5> 0". Wenn sich herausstellt, dass es wahr ist - das heißt, Grün ist an und Rot ist nicht an -, sollte das Auto fahren.
In der realen NS machen künstliche Neuronen einen weiteren Schritt. Durch Addieren einer gewichteten Eingabe und Hinzufügen eines Offsets verwendet das Neuron eine nichtlineare Aktivierungsfunktion. Oft wird ein Sigmoid verwendet, eine S-förmige Funktion, die immer einen Wert von 0 bis 1 ergibt.
Die Verwendung der Aktivierungsfunktion ändert nichts am Ergebnis unseres einfachen Ampelmodells (wir müssen nur einen Schwellenwert von 0,5 verwenden, nicht 0). Die Nichtlinearität von Aktivierungsfunktionen ist jedoch erforderlich, damit NS komplexere Funktionen modellieren können. Ohne die Aktivierungsfunktion wird jeder beliebig komplexe NS auf eine lineare Kombination von Eingabedaten reduziert. Eine lineare Funktion kann komplexe Phänomene in der realen Welt nicht simulieren. Die nichtlineare Aktivierungsfunktion ermöglicht es dem NS,
jede mathematische Funktion zu approximieren.
Netzwerkbeispiel
Natürlich gibt es viele Möglichkeiten, eine Funktion zu approximieren. NS zeichnet sich dadurch aus, dass wir wissen, wie man sie mit ein wenig Algebra, einer Menge Daten und einem Meer an Rechenleistung „trainiert“. Anstatt den Programmierer anzuweisen, die NS für eine bestimmte Aufgabe zu entwickeln, können wir Software erstellen, die mit einer ziemlich allgemeinen NS beginnt, eine Reihe von markierten Beispielen untersucht und dann die NS so ändert, dass sie für so viele Beispiele wie möglich die richtige Bezeichnung gibt. Es wird erwartet, dass der endgültige NS die Daten zusammenfasst und die richtigen Bezeichnungen für Beispiele erstellt, die zuvor nicht in der Datenbank enthalten waren.
Der Prozess, der zu diesem Ziel führte, begann lange vor AlexNet. 1986 veröffentlichte ein Trio von Forschern eine
wegweisende Arbeit zur Backpropagation, eine Technologie, die dazu beitrug, das mathematische Lernen komplexer NS zu verwirklichen.
Um sich vorzustellen, wie Backpropagation funktioniert, schauen wir uns einen einfachen NS an, den Michael Nielsen in seinem hervorragenden
Online-GO-Lehrbuch beschrieben hat . Der Zweck des Netzwerks besteht darin, das Bild einer handgeschriebenen Nummer in einer Auflösung von 28 x 28 Pixel zu verarbeiten und korrekt zu bestimmen, ob die Nummer 0, 1, 2 usw. geschrieben ist.
Jedes Bild hat 28 * 28 = 784 Eingangsgrößen, von denen jede eine reelle Zahl von 0 bis 1 ist, die angibt, wie hell oder dunkel das Pixel ist. Nielsen schuf die NA dieser Art:
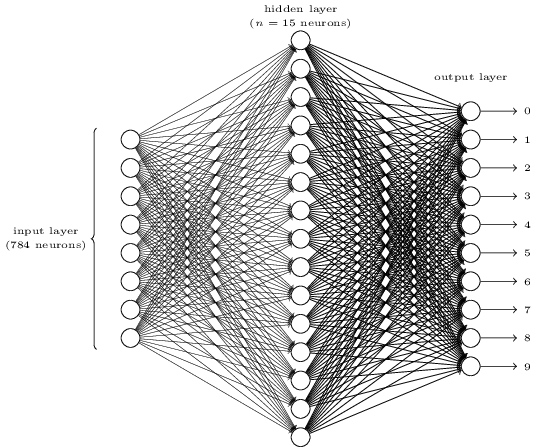
Jeder Kreis in der Mitte und in der rechten Spalte ist ein Neuron ähnlich dem, das wir im vorherigen Abschnitt untersucht haben. Jedes Neuron nimmt einen gewichteten Durchschnitt der Eingabe, fügt einen Versatz hinzu und wendet eine Aktivierungsfunktion an. Die Kreise links sind keine Neuronen, sondern repräsentieren die Eingabedaten des Netzwerks. Und obwohl das Bild nur 8 Eingabekreise zeigt, gibt es tatsächlich 784 davon - einen für jedes Pixel.
Jedes der 10 Neuronen auf der rechten Seite sollte seine eigene Nummer "auslösen": Das oberste sollte sich einschalten, wenn eine handgeschriebene 0 eingegeben wird (und nur in diesem Fall), das zweite, wenn das Netzwerk eine handgeschriebene 1 sieht (und nur diese) und so weiter.
Jedes Neuron nimmt Eingaben von jedem Neuron der vorherigen Schicht wahr. Jedes der 15 Neuronen in der Mitte erhält also 784 Eingabewerte. Jedes dieser 15 Neuronen hat einen Gewichtungsparameter für jeden der 784 Eingabewerte. Dies bedeutet, dass nur diese Schicht 15 * 784 = 11 760 Gewichtsparameter hat. In ähnlicher Weise enthält die Ausgabeschicht 10 Neuronen, von denen jede Eingabe von allen 15 Neuronen der mittleren Schicht empfängt, wodurch weitere 15 × 10 = 150 Gewichtsparameter hinzugefügt werden. Darüber hinaus verfügt das Netzwerk über 25 Verschiebungsvariablen - eine für jedes der 25 Neuronen.
Neuronales Netzwerktraining
Ziel des Trainings ist es, diese 11.935 Parameter zu optimieren, um die Wahrscheinlichkeit zu maximieren, dass das gewünschte Ausgangsneuron - und nur dieses - aktiviert wird, wenn die Netzwerke ein Bild einer handgeschriebenen Ziffer liefern. Wir können dies mit dem bekannten Satz von Bildern MNIST tun, bei dem 60.000 markierte Bilder mit einer Auflösung von 28 x 28 Pixel vorhanden sind.
 160 von 60.000 Bildern aus dem MNIST-Set
160 von 60.000 Bildern aus dem MNIST-SetNielsen zeigt, wie man ein Netzwerk mit 74 Zeilen regulären Python-Codes trainiert - ohne Bibliotheken für MO. Das Lernen beginnt mit der Auswahl von Zufallswerten für jeden dieser 11.935 Parameter, Gewichte und Offsets. Anschließend durchläuft das Programm Beispiele für Bilder und durchläuft jeweils zwei Phasen:
- Der Vorwärtsausbreitungsschritt berechnet die Netzwerkausgabe basierend auf dem Eingabebild und den aktuellen Parametern.
- Der Backpropagation-Schritt berechnet die Abweichung des Ergebnisses von den korrekten Ausgabedaten und ändert die Netzwerkparameter, um die Effizienz in diesem Bild geringfügig zu verbessern.
Ein Beispiel. Angenommen, das Netzwerk hat das folgende Bild erhalten:
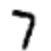
Wenn es gut kalibriert ist, sollte Pin „7“ auf 1 und die anderen neun Schlussfolgerungen auf 0 gehen. Nehmen wir jedoch an, dass das Netzwerk am Ausgang „0“ stattdessen einen Wert von 0,8 ergibt. Das ist zu viel! Der Trainingsalgorithmus ändert die Eingabegewichte des für „0“ verantwortlichen Neurons so, dass es bei der nächsten Verarbeitung dieses Bildes näher an 0 kommt.
Hierzu berechnet der Backpropagation-Algorithmus für jedes Eingabegewicht einen Fehlergradienten. Dies ist ein Maß dafür, wie sich der Ausgabefehler bei einer bestimmten Änderung des Eingabegewichts ändert. Dann verwendet der Algorithmus den Gradienten, um zu entscheiden, um wie viel jedes Eingabegewicht geändert werden soll - je größer der Gradient, desto stärker die Änderung.
Mit anderen Worten, der Trainingsprozess „trainiert“ die Neuronen der Ausgabeschicht, um den Eingaben (Neuronen in der mittleren Schicht), die sie zur falschen Antwort führen, weniger Aufmerksamkeit zu schenken, als den Eingaben, die in die richtige Richtung drücken.
Der Algorithmus wiederholt diesen Schritt für alle anderen Ausgangsneuronen. Es reduziert die Eingabegewichte für die Neuronen "1", "2", "3", "4", "5", "6", "8" und "9" (aber nicht "7"), um deren Wert zu senken Ausgangsneuronen. Je höher der Ausgabewert ist, desto größer ist der Gradient des Ausgabefehlers in Bezug auf das Eingabegewicht - und desto stärker nimmt sein Gewicht ab.
Und umgekehrt erhöht der Algorithmus das Gewicht der Eingabedaten für die Ausgabe "7", wodurch das Neuron beim nächsten Erhalt dieses Bildes einen höheren Wert erzeugt. Wiederum erhöhen Eingaben mit größeren Werten die Gewichte stärker, wodurch das Ausgangsneuron „7“ diesen Eingaben beim nächsten Mal mehr Aufmerksamkeit schenkt.
Dann sollte der Algorithmus die gleichen Berechnungen für die mittlere Schicht durchführen: Ändern Sie jedes Eingabegewicht in eine Richtung, die Netzwerkfehler reduziert - und bringen Sie die Ausgabe „7“ näher an 1 und den Rest an 0. Aber jedes mittlere Neuron hat eine Verbindung mit allen 10 freien Tagen, was die Sache in zweierlei Hinsicht kompliziert.
Erstens hängt der Fehlergradient für jedes durchschnittliche Neuron nicht nur vom Eingabewert ab, sondern auch von den Fehlergradienten in der nächsten Schicht. Der Algorithmus wird als Backpropagation bezeichnet, da sich die Fehlergradienten der späteren Schichten des Netzwerks in die entgegengesetzte Richtung ausbreiten und zur Berechnung der Gradienten in den früheren Schichten verwendet werden.
Außerdem ist jedes mittlere Neuron eine Eingabe für alle zehn freien Tage. Daher muss der Trainingsalgorithmus den Fehlergradienten berechnen, der widerspiegelt, wie sich eine Änderung eines bestimmten Eingabegewichts auf den durchschnittlichen Fehler für alle Ausgaben auswirkt.
Backpropagation ist ein Algorithmus zum Besteigen eines Hügels: Jeder Durchgang bringt die Ausgabewerte näher an die korrekten Werte für ein bestimmtes Bild, jedoch nur geringfügig. Je mehr Beispiele der Algorithmus betrachtet, desto höher steigt er den Hügel hinauf in Richtung des optimalen Parametersatzes, der die maximale Anzahl von Trainingsbeispielen korrekt klassifiziert. Um eine hohe Genauigkeit zu erreichen, sind Tausende von Beispielen erforderlich, und der Algorithmus muss möglicherweise jedes Bild in diesem Satz Dutzende Male durchlaufen, bevor seine Wirksamkeit nicht mehr zunimmt.
Nielsen zeigt, wie diese 74 Zeilen in Python implementiert werden. Überraschenderweise kann ein mit einem so einfachen Programm trainiertes Netzwerk mehr als 95% der handgeschriebenen Zahlen aus der MNIST-Datenbank erkennen. Mit zusätzlichen Verbesserungen kann ein einfaches zweischichtiges Netzwerk mehr als 98% der Zahlen erkennen.
Durchbruch AlexNet
Sie könnten denken, dass die Entwicklung des Themas Backpropagation in den 1980er Jahren stattfinden und zu raschen Fortschritten in der MO auf der Grundlage der Nationalversammlung führen sollte - aber dies geschah nicht. In den 1990er und frühen 2000er Jahren arbeiteten einige Leute an dieser Technologie, aber das Interesse an der Nationalversammlung gewann erst Anfang der 2010er Jahre an Dynamik.
Dies lässt sich auf
den ImageNet-Wettbewerb zurückführen, einen jährlichen MO-Wettbewerb, der von Stanford Fay Fay Lee, einem IT-Spezialisten, organisiert wird. Jedes Jahr erhalten die Rivalen den gleichen Satz von mehr als einer Million Bildern für das Training, von denen jedes manuell in Kategorien von mehr als 1000 gekennzeichnet ist - von „Feuerwehrauto“ und „Pilz“ bis „Gepard“. Die Software der Teilnehmer wird nach der Möglichkeit beurteilt, andere Bilder zu klassifizieren, die nicht im Set enthalten waren. Ein Programm kann einige Vermutungen anstellen, und seine Arbeit wird als erfolgreich angesehen, wenn mindestens eine der ersten fünf Vermutungen mit der von einer Person festgelegten Note übereinstimmt.
Der Wettbewerb begann im Jahr 2010 und tiefe NS spielten in den ersten zwei Jahren keine große Rolle. Die besten Teams verwendeten verschiedene MO-Techniken und erzielten ziemlich durchschnittliche Ergebnisse. Im Jahr 2010 gewann das Team mit einem Fehleranteil von 28. Im Jahr 2011 - mit einem Fehler von 25%.
Und dann kam 2012. Ein Team von der University of Toronto machte ein
Angebot - später AlexNet zu Ehren des Hauptautors Alex Krizhevsky genannt - und ließ die Rivalen weit hinter sich. Mit Deep NS erreichte das Team eine Fehlerrate von 16%. Für den engsten Konkurrenten betrug diese Zahl 26.
Die im Artikel zur Handschrifterkennung beschriebene NS hat zwei Schichten, 25 Neuronen und fast 12.000 Parameter. AlexNet war viel größer und komplexer: acht trainierte Schichten, 650.000 Neuronen und 60 Millionen Parameter.
Zum Trainieren von NS dieser Größe ist eine enorme Verarbeitungsleistung erforderlich. AlexNet wurde entwickelt, um die massive Parallelisierung moderner GPUs zu nutzen. Die Forscher fanden heraus, wie die Arbeit des Trainings des Netzwerks in zwei GPUs aufgeteilt werden kann, wodurch sich die Leistung verdoppelt. Trotz der strengen Optimierung dauerte das Netzwerktraining auf der 2012 verfügbaren Hardware (auf einem Paar Nvidia GTX 580 mit 3 GB Speicher) 5 bis 6 Tage.
Es ist nützlich, Beispiele für die Ergebnisse von AlexNet zu studieren, um zu verstehen, wie ernst dieser Durchbruch war. Hier ist ein Bild aus einer wissenschaftlichen Arbeit, das Beispiele von Bildern und die ersten fünf Vermutungen des Netzwerks nach ihrer Klassifizierung zeigt:

AlexNet konnte das Häkchen im ersten Bild erkennen, obwohl es in der Ecke nur eine kleine Form gibt. Die Software identifizierte nicht nur den Leoparden korrekt, sondern gab auch andere nahe Optionen - einen Jaguar, einen Geparden, einen Schneeleoparden und einen ägyptischen Mau. AlexNet hat das Hainbuchenfoto als "Agaric" markiert. Nur "Pilz" war die zweite Version des Netzwerks.
"Fehler" AlexNet sind ebenfalls beeindruckend. Sie markierte das Foto mit einem Dalmatiner, der hinter einem Bündel Kirschen stand, als „Dalmatiner“, obwohl das offizielle Etikett „Kirsche“ war. AlexNet erkannte, dass auf dem Foto eine Art Beere zu sehen war - unter den ersten fünf Optionen waren „Trauben“ und „Holunder“ -, erkannte die Kirsche einfach nicht. Auf einem Foto eines Madagaskar-Makis, der auf einem Baum sitzt, gab AlexNet eine Liste kleiner Säugetiere, die auf Bäumen leben. Ich denke, dass viele Leute (einschließlich ich) hier die falsche Unterschrift gesetzt hätten.
Die Qualität der Arbeit war beeindruckend und zeigte, dass die Software gewöhnliche Objekte in einer Vielzahl ihrer Ausrichtungen und Umgebungen erkennen kann. GNS wurde schnell zur beliebtesten Technik für die Bilderkennung, und seitdem hat die Welt von MO sie nicht aufgegeben.
„Nach dem Erfolg der auf GO basierenden Methode im Jahr 2012 haben die meisten Teilnehmer des Wettbewerbs 2013 auf tief gefaltete neuronale Netze umgestellt“, schreiben die Sponsoren von ImageNet. In den folgenden Jahren setzte sich dieser Trend fort, und anschließend arbeiteten die Gewinner auf der Grundlage von Basistechnologien, die zuerst vom AlexNet-Team angewendet wurden. Bis 2017 reduzierten Rivalen, die tiefere NS verwendeten, die Fehlerrate ernsthaft auf weniger als drei. Angesichts der Komplexität der Aufgabe haben Computer bis zu einem gewissen Grad gelernt, sie besser zu lösen als viele Menschen.
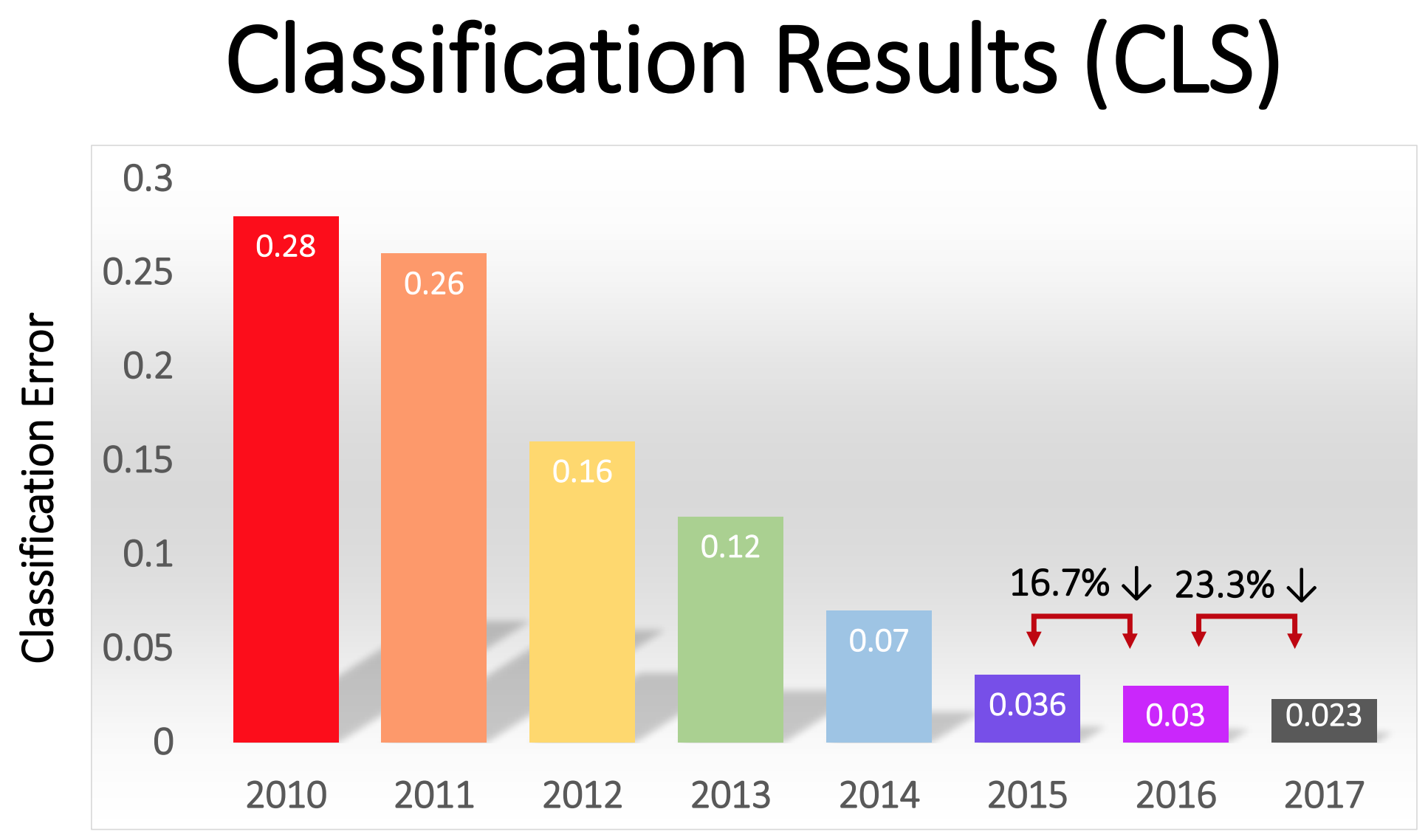 Der Prozentsatz der Fehler bei der Klassifizierung von Bildern in verschiedenen Jahren
Der Prozentsatz der Fehler bei der Klassifizierung von Bildern in verschiedenen JahrenFaltungsnetzwerke: Ein Konzept
Technisch gesehen war AlexNet ein Faltungs-NS. In diesem Abschnitt werde ich erklären, was das Convolutional Neural Network (SNA) tut und warum diese Technologie für moderne Mustererkennungsalgorithmen von entscheidender Bedeutung geworden ist.
Das zuvor diskutierte einfache Netzwerk zur Handschrifterkennung war vollständig verbunden: Jedes Neuron der ersten Schicht war eine Eingabe für jedes Neuron der zweiten Schicht. Eine solche Struktur eignet sich sehr gut für einfache Aufgaben mit Erkennung von Zahlen in Bildern mit 28 x 28 Pixeln. Aber es skaliert nicht gut.
In der handgeschriebenen MNIST-Zifferndatenbank sind alle Zeichen zentriert. Dies vereinfacht das Lernen erheblich, da beispielsweise die sieben oben und rechts immer mehrere dunkle Pixel haben und die untere linke Ecke immer weiß ist. Null hat fast immer einen weißen Fleck in der Mitte und dunkle Pixel an den Rändern. Ein einfaches und vollständig verbundenes Netzwerk kann solche Muster recht leicht erkennen.
Angenommen, Sie möchten einen NS erstellen, der Zahlen erkennt, die sich an einer beliebigen Stelle auf einem größeren Bild befinden können. Ein vollständig verbundenes Netzwerk funktioniert bei dieser Aufgabe nicht so gut, da ähnliche Funktionen in Formularen, die sich in verschiedenen Teilen des Bildes befinden, nicht effektiv erkannt werden können. Wenn sich in Ihrem Trainingsdatensatz die meisten Siebenen in der oberen linken Ecke befinden, kann Ihr Netzwerk die Siebenen in der oberen linken Ecke besser erkennen als in jedem anderen Teil des Bildes.
Theoretisch kann dieses Problem gelöst werden, indem sichergestellt wird, dass Ihr Satz viele Beispiele für jede Ziffer an jeder der möglichen Positionen enthält. In der Praxis wird dies jedoch eine enorme Verschwendung von Ressourcen sein. Mit zunehmender Bildgröße und Netzwerktiefe steigt die Anzahl der Links - und die Anzahl der Gewichtungsparameter - explosionsartig an. Sie benötigen viel mehr Trainingsbilder (und Rechenleistung), um eine angemessene Genauigkeit zu erzielen.
Wenn ein neuronales Netzwerk lernt, eine Form zu erkennen, die sich an einer Stelle eines Bildes befindet, muss es in der Lage sein, dieses Wissen anzuwenden, um dieselbe Form in anderen Teilen des Bildes zu erkennen. SNA bietet eine elegante Lösung für dieses Problem."Es ist, als würde man eine Schablone nehmen und an allen Stellen im Bild anbringen", sagte der KI-Forscher Jai Teng. - Sie haben eine Schablone mit einem Bild eines Hundes und befestigen sie zuerst an der oberen rechten Ecke des Bildes, um zu sehen, ob sich dort ein Hund befindet? Wenn nicht, verschieben Sie die Schablone etwas. Und so für das ganze Bild. Es ist egal, wo das Bild des Hundes ist. Die Schablone passt zu ihr. Sie brauchen nicht jeden Teil des Netzwerks, um seine eigene Klassifizierung von Hunden zu lernen. “Stellen Sie sich vor, wir hätten ein großes Bild aufgenommen und es in Quadrate von 28 x 28 Pixel unterteilt. Dann können wir jedes Quadrat eines vollständig verbundenen Netzwerks speisen, das die zuvor untersuchte Handschrift erkennt. Wenn die Ausgabe „7“ in mindestens einem der Quadrate ausgelöst wird, ist dies ein Zeichen dafür, dass das gesamte Bild eine Sieben enthält. Genau das tun Faltungsnetzwerke.Wie Faltungsnetzwerke in AlexNet funktionierten
In Faltungsnetzwerken sind solche "Schablonen" als Merkmalsdetektoren bekannt, und der Bereich, den sie untersuchen, ist als Empfangsfeld bekannt. Echte Merkmalsdetektoren arbeiten mit viel kleineren Feldern als ein Quadrat mit einer Seite von 28 Pixeln. In AlexNet arbeiteten Feature-Detektoren in der ersten Faltungsschicht mit einem Empfangsfeld von 11 x 11 Pixel. In nachfolgenden Schichten waren die Empfangsfelder 3 bis 5 Einheiten breit.Während des Durchlaufs erzeugt der Detektor der Zeichen des Eingabebildes eine Karte der Zeichen: ein zweidimensionales Gitter, auf dem vermerkt ist, wie stark der Detektor in verschiedenen Teilen des Bildes aktiviert wurde. Faltungsschichten haben normalerweise mehr als einen Detektor, und jeder von ihnen scannt das Bild auf der Suche nach verschiedenen Mustern. AlexNet hatte 96 Feature-Detektoren auf der ersten Ebene und gab 96 Feature-Karten aus. Um dies besser zu verstehen, sollten Sie eine visuelle Darstellung der Muster betrachten, die von jedem der 96 AlexNet-Detektoren der ersten Schicht nach dem Training des Netzwerks untersucht wurden. Es gibt Detektoren, die nach horizontalen oder vertikalen Linien, Übergängen von hell nach dunkel, Schachmustern und vielen anderen Formen suchen.Ein Farbbild wird normalerweise als Pixelkarte mit drei Zahlen für jedes Pixel dargestellt: dem Wert von Rot, Grün und Blau. Die erste Ebene von AlexNet nimmt diese Ansicht und verwandelt sie in eine Ansicht mit 96 Zahlen. Jedes „Pixel“ in diesem Bild hat 96 Werte, einen für jeden Merkmaldetektor.In diesem Beispiel gibt der erste von 96 Werten an, ob ein Punkt im Bild diesem Muster entspricht:
Um dies besser zu verstehen, sollten Sie eine visuelle Darstellung der Muster betrachten, die von jedem der 96 AlexNet-Detektoren der ersten Schicht nach dem Training des Netzwerks untersucht wurden. Es gibt Detektoren, die nach horizontalen oder vertikalen Linien, Übergängen von hell nach dunkel, Schachmustern und vielen anderen Formen suchen.Ein Farbbild wird normalerweise als Pixelkarte mit drei Zahlen für jedes Pixel dargestellt: dem Wert von Rot, Grün und Blau. Die erste Ebene von AlexNet nimmt diese Ansicht und verwandelt sie in eine Ansicht mit 96 Zahlen. Jedes „Pixel“ in diesem Bild hat 96 Werte, einen für jeden Merkmaldetektor.In diesem Beispiel gibt der erste von 96 Werten an, ob ein Punkt im Bild diesem Muster entspricht: Der zweite Wert gibt an, ob ein Bildpunkt mit einem solchen Muster übereinstimmt:
Der zweite Wert gibt an, ob ein Bildpunkt mit einem solchen Muster übereinstimmt: Der dritte Wert gibt an, ob ein Bildpunkt mit einem solchen Muster übereinstimmt:
Der dritte Wert gibt an, ob ein Bildpunkt mit einem solchen Muster übereinstimmt: usw. für 93 Merkmaldetektoren in der ersten AlexNet-Schicht. Die erste Ebene erzeugt eine neue Darstellung des Bildes, wobei jedes Pixel ein Vektor in 96 Dimensionen ist (ich werde später erklären, dass diese Darstellung um das Vierfache reduziert wird).Dies ist die erste Schicht von AlexNet. Dann gibt es vier weitere Faltungsschichten, von denen jede die Ausgabe der vorherigen als Eingabe verwendet.Wie wir gesehen haben, zeigt die erste Ebene grundlegende Muster wie horizontale und vertikale Linien, Übergänge von hell nach dunkel und Kurven. Die zweite Ebene verwendet sie als Baustein zum Erkennen etwas komplexerer Formen. Beispielsweise könnte die zweite Schicht einen Merkmalsdetektor haben, der Kreise unter Verwendung einer Kombination der Ausgaben von Merkmalsdetektoren der ersten Schicht findet, die Kurven finden. Die dritte Ebene findet noch komplexere Formen, indem Merkmale aus der zweiten Ebene kombiniert werden. Der vierte und fünfte finden noch komplexere Muster.Die Forscher Matthew Zeiler und Rob Fergus haben 2014 eine hervorragende Arbeit veröffentlicht , die sehr nützliche Möglichkeiten zur Visualisierung von Mustern bietet, die von einem fünfschichtigen neuronalen Netzwerk ähnlich wie ImageNet erkannt werden.In der nächsten Diashow aus ihrer Arbeit hat jedes Bild außer dem ersten zwei Hälften. Rechts sehen Sie Beispiele für Miniaturansichten, die einen bestimmten Feature-Detektor stark aktiviert haben. Sie werden in neun gesammelt - und jede Gruppe entspricht einem eigenen Detektor. Auf der linken Seite befindet sich eine Karte, die genau zeigt, welche Pixel in dieser Miniaturansicht am meisten für die Übereinstimmung verantwortlich sind. Dies zeigt sich insbesondere in der fünften Schicht, da es Feature-Detektoren gibt, die stark auf Hunde, Logos, Räder usw. reagieren.
usw. für 93 Merkmaldetektoren in der ersten AlexNet-Schicht. Die erste Ebene erzeugt eine neue Darstellung des Bildes, wobei jedes Pixel ein Vektor in 96 Dimensionen ist (ich werde später erklären, dass diese Darstellung um das Vierfache reduziert wird).Dies ist die erste Schicht von AlexNet. Dann gibt es vier weitere Faltungsschichten, von denen jede die Ausgabe der vorherigen als Eingabe verwendet.Wie wir gesehen haben, zeigt die erste Ebene grundlegende Muster wie horizontale und vertikale Linien, Übergänge von hell nach dunkel und Kurven. Die zweite Ebene verwendet sie als Baustein zum Erkennen etwas komplexerer Formen. Beispielsweise könnte die zweite Schicht einen Merkmalsdetektor haben, der Kreise unter Verwendung einer Kombination der Ausgaben von Merkmalsdetektoren der ersten Schicht findet, die Kurven finden. Die dritte Ebene findet noch komplexere Formen, indem Merkmale aus der zweiten Ebene kombiniert werden. Der vierte und fünfte finden noch komplexere Muster.Die Forscher Matthew Zeiler und Rob Fergus haben 2014 eine hervorragende Arbeit veröffentlicht , die sehr nützliche Möglichkeiten zur Visualisierung von Mustern bietet, die von einem fünfschichtigen neuronalen Netzwerk ähnlich wie ImageNet erkannt werden.In der nächsten Diashow aus ihrer Arbeit hat jedes Bild außer dem ersten zwei Hälften. Rechts sehen Sie Beispiele für Miniaturansichten, die einen bestimmten Feature-Detektor stark aktiviert haben. Sie werden in neun gesammelt - und jede Gruppe entspricht einem eigenen Detektor. Auf der linken Seite befindet sich eine Karte, die genau zeigt, welche Pixel in dieser Miniaturansicht am meisten für die Übereinstimmung verantwortlich sind. Dies zeigt sich insbesondere in der fünften Schicht, da es Feature-Detektoren gibt, die stark auf Hunde, Logos, Räder usw. reagieren. Die erste Schicht - einfache Muster und Formen. Die
Die erste Schicht - einfache Muster und Formen. Die zweite Schicht - kleine Strukturen erscheinen. Feature-
zweite Schicht - kleine Strukturen erscheinen. Feature- Detektoren auf der dritten Schicht können komplexere Formen wie Autoräder, Waben und sogar die Silhouetten von Menschen erkennen
Detektoren auf der dritten Schicht können komplexere Formen wie Autoräder, Waben und sogar die Silhouetten von Menschen erkennen Die vierte Schicht kann komplexe Formen wie die Gesichter von Hunden oder die Füße von Vögeln unterscheiden.
Die vierte Schicht kann komplexe Formen wie die Gesichter von Hunden oder die Füße von Vögeln unterscheiden. Die fünfte Schicht kann sehr komplexe Formen erkennen.Wenn Sie sich die Bilder ansehen, können Sie sehen, wie jede nachfolgende Schicht immer komplexere Muster erkennen kann. Die erste Ebene erkennt einfache Muster, die nichts sind. Der zweite erkennt Texturen und einfache Formen. Durch die dritte Schicht werden erkennbare Formen wie Räder und rot-orangefarbene Kugeln (Tomaten, Marienkäfer, etwas anderes) sichtbar.In der ersten Schicht beträgt die Seite des Empfangsfeldes 11 und in den späteren drei bis fünf. Denken Sie jedoch daran, dass spätere Ebenen Feature-Maps erkennen, die von früheren Ebenen generiert wurden, sodass jedes ihrer „Pixel“ mehrere Pixel des Originalbilds bezeichnet. Daher enthält das Empfangsfeld jeder Schicht einen größeren Teil des ersten Bildes als die vorherigen Schichten. Dies ist Teil des Grundes dafür, dass Miniaturansichten in späteren Ebenen komplexer aussehen als in früheren.Die fünfte, letzte Schicht des Netzwerks kann eine beeindruckend große Anzahl von Elementen erkennen. Schauen Sie sich zum Beispiel dieses Bild an, das ich aus der oberen rechten Ecke des Bildes ausgewählt habe, das der fünften Ebene entspricht:
Die fünfte Schicht kann sehr komplexe Formen erkennen.Wenn Sie sich die Bilder ansehen, können Sie sehen, wie jede nachfolgende Schicht immer komplexere Muster erkennen kann. Die erste Ebene erkennt einfache Muster, die nichts sind. Der zweite erkennt Texturen und einfache Formen. Durch die dritte Schicht werden erkennbare Formen wie Räder und rot-orangefarbene Kugeln (Tomaten, Marienkäfer, etwas anderes) sichtbar.In der ersten Schicht beträgt die Seite des Empfangsfeldes 11 und in den späteren drei bis fünf. Denken Sie jedoch daran, dass spätere Ebenen Feature-Maps erkennen, die von früheren Ebenen generiert wurden, sodass jedes ihrer „Pixel“ mehrere Pixel des Originalbilds bezeichnet. Daher enthält das Empfangsfeld jeder Schicht einen größeren Teil des ersten Bildes als die vorherigen Schichten. Dies ist Teil des Grundes dafür, dass Miniaturansichten in späteren Ebenen komplexer aussehen als in früheren.Die fünfte, letzte Schicht des Netzwerks kann eine beeindruckend große Anzahl von Elementen erkennen. Schauen Sie sich zum Beispiel dieses Bild an, das ich aus der oberen rechten Ecke des Bildes ausgewählt habe, das der fünften Ebene entspricht: Die neun Bilder rechts sind möglicherweise nicht gleich. Wenn Sie sich jedoch die neun Heatmaps auf der linken Seite ansehen, werden Sie feststellen, dass dieser Funktionsdetektor nicht auf Objekte im Vordergrund der Fotos fokussiert. Stattdessen konzentriert er sich auf das Gras im Hintergrund eines jeden von ihnen!Natürlich ist ein Grasdetektor nützlich, wenn eine der Kategorien, die Sie identifizieren möchten, „Gras“ ist, aber er kann für viele andere Kategorien nützlich sein. Nach fünf Faltungsschichten hat AlexNet drei Schichten vollständig verbunden, wie unser Netzwerk für die Handschrifterkennung. Diese Ebenen untersuchen jede der von fünf Faltungsebenen ausgegebenen Feature-Maps und versuchen, das Bild in eine der 1000 möglichen Kategorien einzuteilen.Wenn sich also Gras im Hintergrund befindet, ist mit hoher Wahrscheinlichkeit ein wildes Tier im Bild zu sehen. Wenn sich im Hintergrund Gras befindet, ist es weniger wahrscheinlich, dass Möbel im Haus abgebildet sind. Diese und andere Feature-Detektoren der fünften Schicht liefern eine Menge Informationen über den wahrscheinlichen Inhalt des Fotos. Die letzten Schichten des Netzwerks synthetisieren diese Informationen, um eine faktengestützte Vermutung darüber zu liefern, was im Allgemeinen im Bild dargestellt ist.
Die neun Bilder rechts sind möglicherweise nicht gleich. Wenn Sie sich jedoch die neun Heatmaps auf der linken Seite ansehen, werden Sie feststellen, dass dieser Funktionsdetektor nicht auf Objekte im Vordergrund der Fotos fokussiert. Stattdessen konzentriert er sich auf das Gras im Hintergrund eines jeden von ihnen!Natürlich ist ein Grasdetektor nützlich, wenn eine der Kategorien, die Sie identifizieren möchten, „Gras“ ist, aber er kann für viele andere Kategorien nützlich sein. Nach fünf Faltungsschichten hat AlexNet drei Schichten vollständig verbunden, wie unser Netzwerk für die Handschrifterkennung. Diese Ebenen untersuchen jede der von fünf Faltungsebenen ausgegebenen Feature-Maps und versuchen, das Bild in eine der 1000 möglichen Kategorien einzuteilen.Wenn sich also Gras im Hintergrund befindet, ist mit hoher Wahrscheinlichkeit ein wildes Tier im Bild zu sehen. Wenn sich im Hintergrund Gras befindet, ist es weniger wahrscheinlich, dass Möbel im Haus abgebildet sind. Diese und andere Feature-Detektoren der fünften Schicht liefern eine Menge Informationen über den wahrscheinlichen Inhalt des Fotos. Die letzten Schichten des Netzwerks synthetisieren diese Informationen, um eine faktengestützte Vermutung darüber zu liefern, was im Allgemeinen im Bild dargestellt ist.Was Faltungsschichten anders macht: gemeinsame Eingabegewichte
Wir haben gesehen, dass Feature-Detektoren auf Faltungsschichten eine beeindruckende Mustererkennung zeigen, aber bisher habe ich nicht erklärt, wie Faltungsnetzwerke tatsächlich funktionieren.Die Faltungsschicht (SS) besteht aus Neuronen. Sie nehmen wie alle Neuronen einen gewichteten Durchschnitt am Eingang und verwenden die Aktivierungsfunktion. Die Parameter werden unter Verwendung von Rückausbreitungstechniken trainiert.Im Gegensatz zu früheren NS ist die SS jedoch nicht vollständig verbunden. Jedes Neuron erhält Eingaben von einem kleinen Teil der Neuronen aus der vorherigen Schicht. Und vor allem haben Faltungsnetzwerkneuronen gemeinsame Eingabegewichte.Schauen wir uns das erste Neuron der ersten AlexNet SS genauer an. Das Empfangsfeld dieser Schicht hat eine Größe von 11 x 11 Pixel, sodass das erste Neuron ein Quadrat von 11 x 11 Pixel in einer Ecke des Bildes untersucht. Dieses Neuron empfängt Eingaben von diesen 121 Pixeln, und jedes Pixel hat drei Werte - Rot, Grün und Blau. Daher hat das Neuron im Allgemeinen 363 Eingabeparameter. Wie jedes Neuron nimmt dieses einen gewichteten Durchschnitt von 363 Parametern und wendet eine Aktivierungsfunktion auf diese an. Und da die Eingabeparameter 363 sind, benötigen die Gewichtsparameter auch 363.Das zweite Neuron der ersten Schicht ähnelt dem ersten. Er untersucht auch die Quadrate von 11 x 11 Pixel, aber sein Empfangsfeld ist gegenüber dem ersten um vier Pixel verschoben. Die beiden Felder haben eine Überlappung von 7 Pixeln, sodass das Netzwerk die interessanten Muster nicht aus den Augen verliert, die in die Verbindung zweier Quadrate gefallen sind. Das zweite Neuron nimmt auch 363 Parameter, die das 11x11-Quadrat beschreiben, multipliziert jeden von ihnen mit dem Gewicht, addiert die Aktivierungsfunktion und wendet sie an.Anstatt einen separaten Satz von 363 Gewichten zu verwenden, verwendet das zweite Neuron dieselben Gewichte wie das erste. Das obere linke Pixel des ersten Neurons verwendet die gleichen Gewichte wie das obere linke Pixel des zweiten. Daher suchen beide Neuronen nach dem gleichen Muster; Ihre Empfangsfelder werden einfach um 4 Pixel relativ zueinander verschoben.Natürlich gibt es mehr als zwei Neuronen: Im 55x55-Gitter befinden sich 3025 Neuronen. Jeder von ihnen verwendet den gleichen Satz von 363 Gewichten wie die ersten beiden. Zusammen bilden alle Neuronen einen Merkmalsdetektor, der das Bild nach dem gewünschten Muster "scannt", das sich überall befinden kann.Denken Sie daran, dass die erste AlexNet-Schicht 96 Feature-Detektoren hat. Die 3025 Neuronen, die ich gerade erwähnte, bilden einen dieser 96 Detektoren. Jede der verbleibenden 95 ist eine separate Gruppe von 3025 Neuronen. Jede Gruppe von 3025 Neuronen verwendet einen gemeinsamen Satz von 363 Gewichten - für jede der 95 Gruppen hat sie jedoch ihre eigenen.HFs werden mit derselben Backpropagation trainiert, die für vollständig verbundene Netzwerke verwendet wird, aber die Faltungsstruktur macht den Lernprozess effizienter und effektiver."Die Verwendung von Faltung hilft wirklich - die Parameter können wiederverwendet werden", sagte Sean Gerrish, Experte für Verteidigung und Autorisierung. Dies reduziert die Anzahl der Eingabegewichte, die das Netzwerk lernen muss, drastisch, wodurch es mit weniger Trainingsbeispielen bessere Ergebnisse erzielen kann.Das Lernen an einem Teil des Bildes führt zu einer verbesserten Erkennung des gleichen Musters in anderen Teilen des Bildes. Dies ermöglicht es dem Netzwerk, bei einer viel geringeren Anzahl von Trainingsbeispielen eine hohe Leistung zu erzielen.Die Menschen erkannten schnell die Kraft tiefer Faltungsnetzwerke.
Die Arbeit von AlexNet wurde in der akademischen Gemeinschaft der Region Moskau zu einer Sensation, aber ihre Bedeutung wurde in der IT-Branche schnell verstanden. Google war besonders an ihr interessiert.
Im Jahr 2013 erwarb Google ein von den Autoren AlexNet gegründetes Startup. Das Unternehmen verwendete diese Technologie, um Google Fotos eine neue Funktion zur Fotosuche hinzuzufügen. "Wir haben die fortgeschrittene Forschung etwas mehr als sechs Monate später in Betrieb genommen", schrieb Chuck Rosenberg von Google.
In der Zwischenzeit wurde 2013 beschrieben, wie Google mithilfe von GSS Adressen aus Fotos von Google Street View erkennt. "Unser System hat uns geholfen, fast 100 Millionen physische Adressen aus diesen Bildern zu extrahieren", schrieben die Autoren.
Die Forscher fanden heraus, dass die Wirksamkeit von NS mit zunehmender Tiefe zunimmt. "Wir haben festgestellt, dass die Effektivität dieses Ansatzes mit der Tiefe des SNA zunimmt und die tiefste der von uns trainierten Architekturen die besten Ergebnisse zeigt", schrieb das Google Street View-Team. "Unsere Experimente legen nahe, dass tiefere Architekturen eine höhere Genauigkeit erzielen können, jedoch mit einer Verlangsamung der Effizienz."
Nach AlexNet wurden die Netzwerke immer tiefer. Das Google-Team hat sich 2014 für den Wettbewerb beworben - nur zwei Jahre nach dem Gewinn von AlexNet im Jahr 2012. Es basierte ebenfalls auf einer tiefen SNA, aber Goolge verwendete ein viel tieferes Netzwerk von 22 Schichten, um eine Fehlerrate von zu erreichen 6,7% - dies war eine wesentliche Verbesserung gegenüber 16% bei AlexNet.
Gleichzeitig funktionierten tiefere Netzwerke nur mit größeren Trainingsdatensätzen besser. Daher sagte Gerrish, dass der ImageNet-Datensatz und der Wettbewerb eine wichtige Rolle für den Erfolg der SNA gespielt haben. Denken Sie daran, dass die Teilnehmer beim ImageNet-Wettbewerb eine Million Bilder erhalten und gebeten werden, diese in 1.000 Kategorien zu sortieren.
"Wenn Sie eine Million Bilder für das Training haben, enthält jede Klasse 1.000 Bilder", sagte Gerrish. Ohne einen so großen Datensatz sagte er: "Sie hätten zu viele Optionen, um das Netzwerk zu trainieren."
In den letzten Jahren konzentrieren sich Experten zunehmend darauf, eine große Datenmenge zu sammeln, um tiefere und genauere Netzwerke zu trainieren. Aus diesem Grund konzentrieren sich Unternehmen, die Roboterautos entwickeln, auf das Fahren auf öffentlichen Straßen. Bilder und Videos dieser Fahrten werden an die Zentrale gesendet und für die Schulung von NS-Unternehmen verwendet.
Computing Deep Learning Boom
Die Entdeckung der Tatsache, dass tiefere Netzwerke und größere Datensätze die NS-Leistung verbessern können, hat einen unstillbaren Durst nach immer größerer Rechenleistung erzeugt. Eine der Hauptkomponenten für den Erfolg von AlexNet war die Idee, dass Matrixtraining im NS-Training verwendet wird, das auf gut parallelisierbaren GPUs effizient durchgeführt werden kann.
"Die NS sind gut parallelisiert", sagte Jai Ten, ein MO-Forscher. Grafikkarten, die eine enorme Parallelverarbeitungsleistung für Videospiele bieten, haben sich für NS als nützlich erwiesen.
"Der zentrale Teil der Arbeit der GPU, die sehr schnelle Matrixmultiplikation, erwies sich als zentraler Teil der Arbeit der Nationalversammlung", sagte Ten.
All dies war für führende Hersteller von GPU, Nvidia und AMD erfolgreich. Beide Unternehmen haben neue Chips entwickelt, die speziell auf die Anforderungen der MO-Anwendung zugeschnitten sind. Jetzt sind AI-Anwendungen für einen erheblichen Teil des GPU-Umsatzes dieser Unternehmen verantwortlich.
Im Jahr 2016 kündigte Google die Schaffung eines speziellen Chips an, der Tensor Processing Unit (TPU), die für den Betrieb in der Nationalversammlung entwickelt wurde. "Obwohl Google bereits 2006 die Möglichkeit in Betracht gezogen hat, spezielle integrierte Schaltkreise (ASICs) zu schaffen, wurde diese Situation 2013 dringend",
schrieb ein Unternehmensvertreter im vergangenen Jahr. "Damals wurde uns klar, dass wir aufgrund der schnell wachsenden Anforderungen der Nationalversammlung an die Rechenleistung möglicherweise die Anzahl unserer Rechenzentren verdoppeln müssen."
Anfangs hatten nur die eigenen Dienste von Google Zugriff auf TPUs. Später erlaubte das Unternehmen jedem, diese Technologie über eine Cloud-Computing-Plattform zu nutzen.
Natürlich ist Google nicht das einzige Unternehmen, das an KI-Chips arbeitet. Nur ein paar Beispiele: In den neuesten Versionen der iPhone-Chips
gibt es einen „neuronalen Kern“, der für den Betrieb mit dem NS optimiert ist. Intel
entwickelt eine eigene Reihe von Chips, die für GO optimiert sind. Tesla
kündigte kürzlich die Ablehnung von Chips von Nvidia zugunsten seiner eigenen NS-Chips an. Es wird auch gemunkelt, dass Amazon an seinen KI-Chips arbeitet.
Warum tiefe neuronale Netze schwer zu verstehen sind
Ich habe erklärt, wie neuronale Netze funktionieren, aber ich habe nicht erklärt, warum sie so gut funktionieren. Es ist nicht klar, wie genau die immense Menge an Matrixberechnungen es einem Computersystem ermöglicht, einen Jaguar von einem Geparden und Holunder von Johannisbeeren zu unterscheiden.
Die vielleicht bemerkenswerteste Eigenschaft der Nationalversammlung ist, dass dies nicht der Fall ist. Durch die Faltung kann der NS die Silbentrennung verstehen - er kann erkennen, ob das Bild in der oberen rechten Ecke des Bildes dem Bild in der oberen linken Ecke eines anderen Bildes ähnlich ist.
Gleichzeitig hat der SNA keine Ahnung von der Geometrie. Sie können die Ähnlichkeit der beiden Bilder nicht erkennen, wenn sie um 45 Grad gedreht oder verdoppelt werden. SNA versucht nicht, die dreidimensionale Struktur von Objekten zu verstehen und kann unterschiedliche Lichtverhältnisse nicht berücksichtigen.
Gleichzeitig können NS Fotos von Hunden erkennen, die sowohl von vorne als auch von der Seite aufgenommen wurden, und es spielt keine Rolle, ob der Hund einen kleinen oder einen großen Teil des Bildes einnimmt. Wie machen sie das? Es stellt sich heraus, dass ein statistischer Ansatz mit direkter Aufzählung die Aufgabe bewältigen kann, wenn genügend Daten vorhanden sind. Der SNA ist nicht so konzipiert, dass er sich vorstellen kann, wie ein bestimmtes Bild aus einem anderen Blickwinkel oder unter anderen Bedingungen aussehen würde, aber mit einer ausreichenden Anzahl von beschrifteten Beispielen kann er durch einfache Wiederholung alle möglichen Variationen des Bildes lernen.
Es gibt Hinweise darauf, dass das visuelle System von Menschen auf ähnliche Weise funktioniert. Schauen Sie sich ein paar Bilder an - studieren Sie zuerst das erste sorgfältig und öffnen Sie dann das zweite.
 Erstes Foto
Erstes FotoDer Schöpfer des Bildes machte ein Foto von jemandem und stellte seine Augen und seinen Mund auf den Kopf. Das Bild erscheint relativ normal, wenn man es verkehrt herum betrachtet, da das menschliche visuelle System es gewohnt ist, Augen und Münder in dieser Position zu sehen. Wenn Sie das Bild jedoch in der richtigen Ausrichtung betrachten, können Sie sofort feststellen, dass das Gesicht merkwürdig verzerrt ist.
Dies legt nahe, dass das menschliche visuelle System auf denselben groben Mustererkennungstechniken wie das NS basiert. Wenn wir etwas betrachten, das fast immer in einer Ausrichtung sichtbar ist - das menschliche Auge -, können wir es in seiner normalen Ausrichtung viel besser erkennen.
NS erkennen Bilder gut anhand des gesamten auf ihnen verfügbaren Kontexts. Zum Beispiel fahren Autos normalerweise auf Straßen. Kleider werden normalerweise am Körper einer Frau getragen oder hängen in einem Schrank. Flugzeuge werden normalerweise gegen den Himmel geschossen oder sie regieren auf der Landebahn. Niemand lehrt die NS speziell diese Korrelationen, aber mit einer ausreichenden Anzahl von beschrifteten Beispielen kann das Netzwerk selbst sie lernen.
Im Jahr 2015 versuchten Forscher von Google, die NS besser zu verstehen, "indem sie sie rückwärts laufen ließen". Anstatt Bilder zum Trainieren von NS zu verwenden, verwendeten sie trainiertes NS, um Bilder zu ändern. Zum Beispiel begannen sie mit einem Bild, das zufälliges Rauschen enthielt, und änderten es dann allmählich, so dass es eines der Ausgangsneuronen des NS stark aktivierte. Tatsächlich baten sie das NS, eine der Kategorien zu „zeichnen“, deren Erkennung ihm beigebracht wurde. In einem interessanten Fall zwangen sie die NS, Bilder zu erzeugen, die die NS aktivieren und darauf trainiert sind, Hanteln zu erkennen.

"Natürlich gibt es hier Hanteln, aber kein einziges Bild von Hanteln scheint vollständig zu sein, ohne dass eine muskulöse Muskelrolle sie anhebt", schrieben Google-Forscher.
Auf den ersten Blick sieht es seltsam aus, aber in Wirklichkeit unterscheidet es sich nicht so sehr von dem, was Menschen tun. Wenn wir ein kleines oder verschwommenes Objekt auf dem Bild sehen, suchen wir nach einem Hinweis in seiner Umgebung, um zu verstehen, was dort passieren kann. Menschen sprechen offensichtlich anders über Bilder und verwenden dabei ein komplexes konzeptionelles Verständnis der Welt um sie herum. Aber am Ende erkennt das STS Bilder gut, weil sie den gesamten auf ihnen dargestellten Kontext voll ausnutzen, und dies unterscheidet sich nicht wesentlich von der Art und Weise, wie Menschen dies tun.