
Am 14. Mai, als Trump sich darauf vorbereitete, alle Hunde auf Huawei zu starten, saß ich friedlich in Shenzhen auf der Huawei STW 2019 - einer großen Konferenz für 1000 Teilnehmer -, die Berichte von
Philip Wong , Vizepräsident der TSMC-Forschung über die Aussichten von Nicht-von-Neumann-Computern, enthielt Architekturen und Heng Liao, Huawei Fellow, Chefwissenschaftler Huawei 2012 Lab, über die Entwicklung einer neuen Architektur von Tensorprozessoren und Neuroprozessoren. Wenn Sie wissen, stellt TSMC neuronale Beschleuniger für Apple und Huawei mithilfe der 7-nm-Technologie her (die nur
wenige Menschen besitzen ), und Huawei ist bereit, in Bezug auf Neuroprozessoren mit Google und NVIDIA zu konkurrieren.
Google in China ist verboten. Ich habe mir nicht die Mühe gemacht, ein VPN auf dem Tablet zu
installieren. Deshalb habe ich Yandex
patriotisch verwendet, um zu sehen, wie die Situation bei anderen Herstellern von ähnlichem Eisen ist und was im Allgemeinen passiert. Im Allgemeinen habe ich die Situation beobachtet, aber erst nach diesen Berichten wurde mir klar, wie groß die Revolution in den Eingeweiden der Unternehmen und in der Stille der wissenschaftlichen Räume vorbereitet wurde.
Allein im letzten Jahr wurden mehr als 3 Milliarden US-Dollar in das Thema investiert. Google hat die neuronalen Netze seit langem zu einem strategischen Bereich erklärt und baut seinen Hardware- und Software-Support aktiv auf. NVIDIA spürt, dass der Thron schwankt, und unternimmt fantastische Anstrengungen in Bibliotheken zur Beschleunigung neuronaler Netze und neuer Hardware. Intel gab 2016 0,8 Milliarden aus, um zwei Unternehmen zu kaufen, die an der Hardwarebeschleunigung neuronaler Netze beteiligt sind. Und dies trotz der Tatsache, dass die Hauptkäufe noch nicht begonnen haben und die Anzahl der Spieler fünfzig überschritten hat und schnell wächst.
TPU, VPU, IPU, DPU, NPU, RPU, NNP - was bedeutet das alles und wer wird gewinnen? Versuchen wir es herauszufinden. Wen kümmert es - Willkommen bei Katze!
Haftungsausschluss: Der Autor musste die Videoverarbeitungsalgorithmen für eine effektive Implementierung auf ASIC komplett neu schreiben, und die Kunden haben Prototypen auf FPGA erstellt, sodass eine Vorstellung von der Tiefe der Unterschiede in den Architekturen besteht. Der Autor hat jedoch in letzter Zeit nicht direkt mit Eisen gearbeitet. Aber er rechnet damit, dass er sich damit befassen muss.
Hintergrund der Probleme
Die Anzahl der erforderlichen Berechnungen wächst schnell, die Leute würden gerne mehr Ebenen und Architekturoptionen verwenden und aktiver mit Hyperparametern spielen, aber ... das hängt von der Leistung ab. Gleichzeitig zum Beispiel mit dem Produktivitätswachstum der guten alten Prozessoren - große Probleme. Alle guten Dinge gehen zu Ende: Wie Sie wissen, läuft das Moore-Gesetz aus und die Wachstumsrate der Prozessorleistung sinkt:
Berechnungen der tatsächlichen Leistung von Ganzzahloperationen auf SPECint im Vergleich zu VAX11-780 , im Folgenden häufig eine logarithmische SkalaWenn von Mitte der 80er bis Mitte der 2000er Jahre - in den gesegneten Jahren der Blütezeit der Computer - das Wachstum durchschnittlich 52% pro Jahr betrug, ist es in den letzten Jahren auf 3% pro Jahr zurückgegangen. Und dies ist ein Problem (eine Übersetzung eines kürzlich erschienenen Artikels von Patriarch John Hennessey über die Probleme und Perspektiven der modernen Architektur
war auf Habré ).
Es gibt viele Gründe, zum Beispiel, dass die Häufigkeit von Prozessoren nicht mehr wächst:
Es wurde schwieriger, die Größe von Transistoren zu reduzieren. Das letzte Unglück, das die Produktivität drastisch reduziert (einschließlich der Leistung bereits freigegebener CPUs), ist (Trommelwirbel) ... richtig, Sicherheit.
Meltdown ,
Spectre und
andere Sicherheitslücken verursachen enorme Schäden an der Wachstumsrate der CPU-Verarbeitungsleistung (
ein Beispiel für das Deaktivieren von Hyperthreading (!)). Das Thema ist populär geworden und neue Schwachstellen dieser Art werden
fast monatlich gefunden . Und das ist eine Art Albtraum, weil es in Bezug auf die Leistung weh tut.
Gleichzeitig ist die Entwicklung vieler Algorithmen fest mit dem bekannten Wachstum der Prozessorleistung verbunden. Zum Beispiel sind viele Forscher heutzutage nicht besorgt über die Geschwindigkeit von Algorithmen - sie werden sich etwas einfallen lassen. Und es wäre schön, wenn man lernt - Netzwerke werden groß und "schwierig" zu benutzen. Dies zeigt sich insbesondere im Video, für das die meisten Ansätze im Prinzip nicht mit hoher Geschwindigkeit anwendbar sind. Und sie machen oft nur in Echtzeit Sinn. Dies ist auch ein Problem.
Ebenso werden neue Komprimierungsstandards entwickelt, die eine Erhöhung der Decoderleistung implizieren. Und wenn die Prozessorleistung nicht wächst? Die ältere Generation erinnert sich, wie es in den 2000er Jahren Probleme gab, hochauflösende Videos im damals frischen
H.264 auf älteren Computern
abzuspielen . Ja, die Qualität war bei einer kleineren Größe besser, aber bei schnellen Szenen hing das Bild oder der Ton war zerrissen. Ich muss mit den Entwicklern des neuen
VVC / H.266 kommunizieren (eine Veröffentlichung ist für nächstes Jahr geplant). Sie werden sie nicht beneiden.
Was bereitet uns das kommende Jahrhundert angesichts des Rückgangs der Wachstumsrate der Prozessorleistung in Bezug auf neuronale Netze vor?
CPU
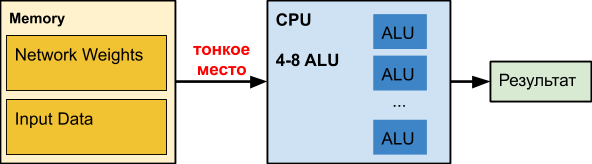
Eine normale
CPU ist ein großer Brecher, der seit Jahrzehnten perfektioniert wird. Leider für andere Aufgaben.
Wenn wir mit neuronalen Netzen arbeiten, insbesondere mit tiefen, kann unser Netzwerk selbst Hunderte von Megabyte belegen. Beispielsweise sind die Speicheranforderungen von
Objekterkennungsnetzwerken wie folgt:
Nach unserer Erfahrung können die Koeffizienten eines tiefen neuronalen Netzwerks zur Verarbeitung
durchscheinender Grenzen 150 bis 200 MB einnehmen. Kollegen im neuronalen Netzwerk bestimmen das Alter und Geschlecht der Größe der Koeffizienten in der Größenordnung von 50 MB. Und während der Optimierung für die mobile Version mit reduzierter Genauigkeit - ca. 25 MB (float32⇒float16).
Gleichzeitig wird der Verzögerungsgraph beim Zugriff auf den Speicher in Abhängigkeit von der Größe der Daten
ungefähr so verteilt (horizontale Skala ist logarithmisch):
Das heißt, Bei einer Zunahme des Datenvolumens um mehr als 16 MB erhöht sich die Verzögerung um das 50-fache oder mehr, was sich negativ auf die Leistung auswirkt. Tatsächlich wartet die CPU die meiste Zeit, wenn sie mit tiefen neuronalen Netzen arbeitet,
dumm auf Daten. Interessant sind
die Daten von
Intel zur Beschleunigung verschiedener Netzwerke, bei denen die Beschleunigung tatsächlich nur dann erfolgt, wenn das Netzwerk klein wird (z. B. aufgrund der Quantisierung von Gewichten), um zusammen mit den verarbeiteten Daten zumindest teilweise in den Cache zu gelangen. Beachten Sie, dass der Cache einer modernen CPU bis zur Hälfte der Prozessorenergie verbraucht. Im Fall von schweren neuronalen Netzen ist es unwirksam und arbeitet unangemessen teure Heizung.
Für Anhänger neuronaler Netze auf der CPULaut unseren internen Tests verliert sogar
Intel OpenVINO die Implementierung des Matrix-Multiplikations- + NNPACK-Frameworks auf vielen Netzwerkarchitekturen (insbesondere auf einfachen Architekturen, bei denen die Bandbreite für die Echtzeitdatenverarbeitung im Single-Threaded-Modus wichtig ist). Ein solches Szenario ist für verschiedene Klassifizierer von Objekten im Bild relevant (bei denen das neuronale Netzwerk mehrmals ausgeführt werden muss - 50 bis 100 in Bezug auf die Anzahl der Objekte im Bild), und der Aufwand für das Starten von OpenVINO wird unangemessen hoch.
Vorteile:- "Jeder hat es" und ist normalerweise untätig, d.h. relativ niedriger Einstiegspreis für Abrechnung und Implementierung.
- Es gibt separate Nicht-CV-Netzwerke, die gut in die CPU passen. Kollegen nennen sie beispielsweise Wide & Deep und GNMT.
Minus:- Die CPU ist ineffizient, wenn mit tiefen neuronalen Netzen gearbeitet wird (wenn die Anzahl der Netzwerkschichten und die Größe der Eingabedaten groß sind), funktioniert alles schmerzhaft langsam.
GPU

Das Thema ist bekannt, daher skizzieren wir kurz die Hauptsache. Bei neuronalen Netzen hat die
GPU bei massiv parallelen Aufgaben einen erheblichen Leistungsvorteil:
Achten Sie darauf, wie das 72-Kern-
Xeon Phi 7290 geglüht wird, während das "Blau" auch das Server-Xeon ist, d. H. Intel gibt nicht so einfach auf, was weiter unten erläutert wird. Noch wichtiger ist jedoch, dass der Speicher von Grafikkarten ursprünglich für eine etwa fünfmal höhere Leistung ausgelegt war. In neuronalen Netzen ist das Rechnen mit Daten äußerst einfach. Ein paar elementare Aktionen, und wir brauchen neue Daten. Infolgedessen ist die Datenzugriffsgeschwindigkeit für den effizienten Betrieb eines neuronalen Netzwerks entscheidend. Ein Hochgeschwindigkeitsspeicher „an Bord“ der GPU und ein flexibleres Cache-Verwaltungssystem als auf der CPU können dieses Problem lösen:
Tim Detmers unterstützt seit mehreren Jahren die interessante Rezension
„Welche GPUs für Deep Learning: Meine Erfahrungen und Ratschläge für die Verwendung von GPUs beim Deep Learning“ . Es ist klar, dass Tesla und Titans für das Training regieren, obwohl der Unterschied in den Architekturen interessante Ausbrüche verursachen kann, zum Beispiel bei wiederkehrenden neuronalen Netzen (und der Marktführer im Allgemeinen ist TPU, Hinweis für die Zukunft):
Es gibt jedoch ein äußerst nützliches Leistungsdiagramm für den Dollar, wo auf dem
RTX- Pferd (höchstwahrscheinlich aufgrund
seiner Tensorkerne ), wenn Sie genügend Speicher dafür haben, natürlich:
Natürlich sind die Rechenkosten wichtig. Der zweite Platz der ersten Bewertung und der letzte der zweiten -
Tesla V100 wird für 700.000 Rubel verkauft, wie 10 „normale“ Computer (+ der teure Infiniband-Switch, wenn Sie auf mehreren Knoten trainieren möchten). Echte V100 und funktioniert für zehn. Die Menschen sind bereit, für eine spürbare Beschleunigung des Lernens zu viel zu bezahlen.
Insgesamt zusammenfassen!
Vorteile:- Kardinal - 10-100 mal - Beschleunigung im Vergleich zur CPU.
- Extrem effektiv für das Training (und etwas weniger effektiv für den Gebrauch).
Minus:- Die Kosten für Top-End-Grafikkarten (die über genügend Speicher verfügen, um große Netzwerke zu trainieren) übersteigen die Kosten für den Rest des Computers ...
FPGA
 FPGA
FPGA ist schon interessanter. Dies ist ein Netzwerk von mehreren Millionen programmierbaren Blöcken, die wir auch programmgesteuert miteinander verbinden können. Das Netzwerk und die Blöcke
sehen ungefähr so aus (der Engpass ist der Engpass, achten Sie darauf, noch einmal vor dem Chipspeicher, aber es ist einfacher, was weiter unten beschrieben wird):
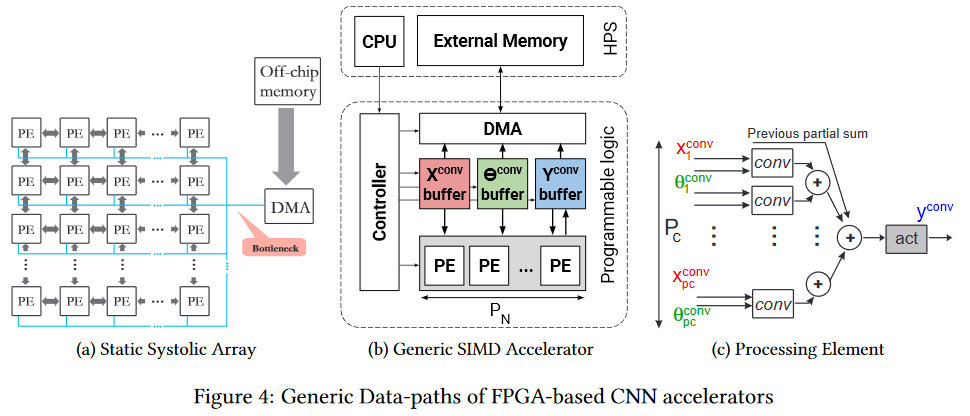
Natürlich ist es sinnvoll, FPGA bereits in der Phase der Verwendung eines neuronalen Netzwerks zu verwenden (in den meisten Fällen ist nicht genügend Speicher für das Training vorhanden). Darüber hinaus hat das Thema der Ausführung auf FPGA nun begonnen, sich aktiv zu entwickeln. Hier ist zum Beispiel das
fpgaConvNet-Framework , das die Verwendung von CNN auf FPGAs erheblich beschleunigen und den Stromverbrauch senken kann.
Das Hauptvorteil von FPGA ist, dass wir das Netzwerk direkt in den Zellen speichern können, d. H. Ein dünner Fleck in Form von Hunderten von Megabyte derselben Daten, die 25 Mal pro Sekunde (für Videos) in dieselbe Richtung übertragen werden, verschwindet auf magische Weise. Dies ermöglicht eine niedrigere Taktrate und das Fehlen von Caches anstelle einer geringeren Leistung, um eine spürbare Steigerung zu erzielen. Ja, und den Energieverbrauch für die
globale Erwärmung pro Berechnungseinheit drastisch reduzieren.
Intel beteiligte sich aktiv an dem Prozess und veröffentlichte letztes Jahr das
OpenVINO Toolkit im Open Source-
Format , das das
Deep Learning Deployment Toolkit (Teil von
OpenCV ) enthält. Darüber hinaus sieht die Leistung von FPGAs in verschiedenen Grids sehr interessant aus, und der Vorteil von FPGAs im Vergleich zu GPUs (obwohl integrierte Intel-GPUs) ist ziemlich bedeutend:
Was die Seele des Autors besonders wärmt - FPS werden verglichen, d.h. Bilder pro Sekunde ist die praktischste Metrik für Videos. Angesichts der Tatsache, dass Intel
Altera , den zweitgrößten Player auf dem FPGA-Markt, im Jahr 2015 gekauft hat, bietet die Grafik gute Denkanstöße.
Und offensichtlich ist die Eintrittsbarriere für solche Architekturen höher, so dass einige Zeit vergehen muss, bis praktische Tools erscheinen, die die grundlegend andere FPGA-Architektur effektiv berücksichtigen. Aber das Potenzial der Technologie zu unterschätzen, lohnt sich nicht. Es sind schmerzhaft viele dünne Stellen, die sie stickt.
Schließlich betonen wir, dass das
Programmieren von FPGAs eine eigenständige Kunst ist. Daher wird das Programm dort nicht ausgeführt, und alle Berechnungen werden in Bezug auf Datenströme, Stream-Verzögerungen (die die Leistung beeinträchtigen) und verwendete Gates (die immer fehlen) durchgeführt. Um effektiv programmieren zu können, müssen Sie daher
Ihre eigene Firmware (im neuronalen Netzwerk zwischen Ihren Ohren) gründlich
ändern . Bei guter Effizienz wird dies überhaupt nicht erreicht. Die neuen Frameworks werden jedoch bald den externen Unterschied vor den Forschern verbergen.
Vorteile:- Potenziell schnellere Netzwerkausführung.
- Deutlich geringerer Stromverbrauch im Vergleich zu CPU und GPU (dies ist besonders wichtig für mobile Lösungen).
Nachteile:- Meistens helfen sie dabei, die Ausführung zu beschleunigen, und das Training auf ihnen ist im Gegensatz zur GPU merklich weniger bequem.
- Komplexere Programmierung im Vergleich zu früheren Optionen.
- Deutlich weniger Spezialisten.
ASIC

Als nächstes kommt
ASIC , kurz für Application-Specific Integrated Circuit, d. H. integrierte Schaltung für unsere Aufgabe. Zum Beispiel die Realisierung eines in Eisen gelegten neuronalen Netzwerks. Die meisten Rechenknoten können jedoch parallel arbeiten. Tatsächlich können nur Datenabhängigkeiten und ungleichmäßiges Rechnen auf verschiedenen Ebenen des Netzwerks verhindern, dass wir ständig alle funktionierenden ALUs verwenden.
Vielleicht hat das Cryptocurrency Mining in den letzten Jahren die größte ASIC-Werbung in der Öffentlichkeit gemacht. Am Anfang war das Mining auf der CPU ziemlich profitabel, später musste ich eine GPU, dann ein FPGA und dann spezialisierte ASICs kaufen, da die Leute (lesen - der Markt) für Aufträge reiften, bei denen ihre Produktion rentabel wurde.
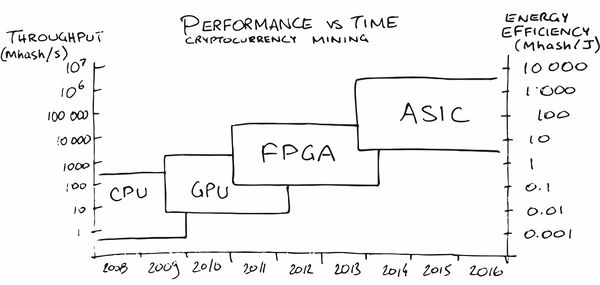
In unserer Region sind auch (natürlich!) Bereits
Dienste erschienen, die dazu beitragen, ein neuronales Netz auf Eisen mit den notwendigen Eigenschaften für Energieverbrauch, FPS und Preis zu setzen. Magisch zustimmen!
ABER! Wir verlieren die Netzwerkanpassung. Und natürlich denken die Leute auch darüber nach. Hier ist zum Beispiel ein Artikel mit dem Spruch: "
Kann eine rekonfigurierbare Architektur ASIC als CNN-Beschleuniger schlagen? " ("Kann eine konfigurierbare Architektur ASIC wie einen CNN-Beschleuniger schlagen?"). Es gibt genug Arbeit zu diesem Thema, da die Frage nicht untätig ist. Der Hauptnachteil von ASIC besteht darin, dass es für uns schwierig wird, das Netzwerk zu ändern, nachdem wir es in Hardware umgewandelt haben. Sie sind am vorteilhaftesten für Fälle, in denen wir bereits ein gut funktionierendes Netzwerk mit Millionen von Chips mit geringem Stromverbrauch und hoher Leistung benötigen. Und diese Situation entwickelt sich beispielsweise auf dem Markt für Autopilotautos allmählich. Oder in Überwachungskameras. Oder in den Kammern von Roboterstaubsaugern. Oder in den Kammern eines Haushaltskühlschranks. Oder in einer Kaffeemaschinenkammer.
Oder in der Eisenkammer. Nun, Sie verstehen die Idee,
kurz gesagt !
Es ist wichtig, dass der Chip in der Massenproduktion billig ist, schnell arbeitet und ein Minimum an Energie verbraucht.
Vorteile:- Die niedrigsten Chipkosten im Vergleich zu allen vorherigen Lösungen.
- Niedrigster Stromverbrauch pro Betriebseinheit.
- Ziemlich hohe Geschwindigkeit (auf Wunsch auch eine Aufzeichnung).
Nachteile:- Sehr eingeschränkte Fähigkeit, das Netzwerk und die Logik zu aktualisieren.
- Höchste Entwicklungskosten im Vergleich zu allen bisherigen Lösungen.
- Die Verwendung von ASIC ist vor allem bei großen Auflagen kostengünstig.
TPU
Denken Sie daran, dass es bei der Arbeit mit Netzwerken zwei Aufgaben gibt - Training und Ausführung (Inferenz). Wenn FPGA / ASICs in erster Linie darauf abzielen, die Ausführung zu beschleunigen (einschließlich einiger fester Netzwerke), ist TPU (Tensor Processing Unit oder Tensor Processors) entweder eine hardwarebasierte Lernbeschleunigung oder eine relativ universelle Beschleunigung eines beliebigen Netzwerks. Der Name ist wunderschön, stimme zu, obwohl tatsächlich
Tensoren vom Rang 2 mit einer Mixed Multiply Unit (MXU), die an einen High-Bandwidth Memory (HBM) angeschlossen ist, immer noch verwendet werden. Unten sehen Sie das Architekturdiagramm der 2. und 3. Version von TPU Google:
TPU Google
Im Allgemeinen machte Google eine Werbung für den TPU-Namen und enthüllte interne Entwicklungen im Jahr 2017:
Sie begannen 2006 mit ihren Worten mit den Vorarbeiten an spezialisierten Prozessoren für neuronale Netze, 2013 schufen sie ein Projekt mit guter Finanzierung und 2015 begannen sie mit den ersten Chips zu arbeiten, die bei neuronalen Netzen für den Google Translate Cloud-Dienst und mehr sehr hilfreich waren. Wir betonen, dass dies die Beschleunigung des Netzwerks war. Ein wichtiger Vorteil für Rechenzentren ist die um zwei Größenordnungen höhere TPU-Energieeffizienz im Vergleich zu CPUs (Grafik für TPU v1):
Außerdem ist die
Leistung des Netzwerks im Vergleich zur GPU in der Regel 10 bis 30 Mal besser:
Der Unterschied ist sogar zehnmal signifikant. Es ist klar, dass der Unterschied zur GPU in 20 bis 30-mal die Entwicklung dieser Richtung bestimmt.
Und zum Glück ist Google nicht allein.
TPU Huawei
Heute begann das langmütige Huawei vor einigen Jahren auch mit der Entwicklung von TPU unter dem Namen Huawei Ascend und in zwei Versionen gleichzeitig - für Rechenzentren (wie Google) und für mobile Geräte (mit denen Google kürzlich ebenfalls begonnen hat). Wenn Sie den Materialien von Huawei glauben, haben sie das frische Google TPU v3 2,5-mal durch FP16 und 2-mal NVIDIA V100 überholt:

Wie immer eine gute Frage: Wie wird sich dieser Chip bei realen Aufgaben verhalten? Wie Sie sehen können, wird in der Grafik die Spitzenleistung angezeigt. Darüber hinaus ist Google TPU v3 in vielerlei Hinsicht gut, da es in Clustern von 1024 Prozessoren effektiv arbeiten kann. Huawei kündigte auch Server-Cluster für das Ascend 910 an, aber es gibt keine Details. Im Allgemeinen haben sich die Ingenieure von Huawei in den letzten 10 Jahren als äußerst kompetent erwiesen, und es besteht jede Chance, dass in diesem Fall eine 2,8-mal höhere Spitzenleistung im Vergleich zu Google TPU v3 in Verbindung mit der neuesten 7-nm-Prozesstechnologie verwendet wird.
Der Speicher und der Datenbus sind für die Leistung von entscheidender Bedeutung, und die Folie zeigt, dass diesen Komponenten erhebliche Aufmerksamkeit geschenkt wurde (einschließlich der Geschwindigkeit der Kommunikation mit dem Speicher, die viel schneller ist als die der GPU):
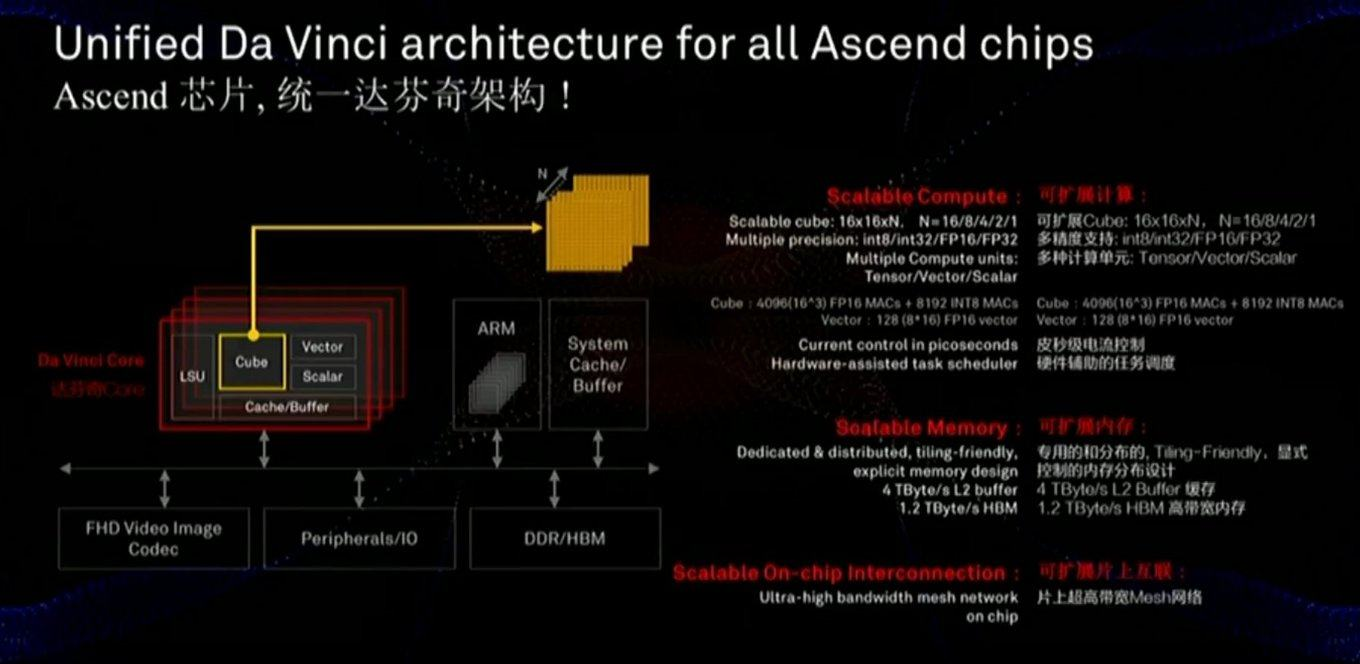
Der Chip verwendet auch einen etwas anderen Ansatz - keine zweidimensionalen MXU 128x128-Skalen, sondern Berechnungen in einem dreidimensionalen Würfel kleinerer Größe 16x16xN, wobei N = {16,8,4,2,1}. Die Schlüsselfrage ist daher, wie gut es auf der tatsächlichen Beschleunigung bestimmter Netzwerke liegt (z. B. sind Berechnungen in einem Würfel für Bilder praktisch). Eine sorgfältige Untersuchung der Folie zeigt auch, dass der Chip im Gegensatz zu Google sofort Arbeiten mit komprimiertem FullHD-Video enthält. Für den Autor klingt das
sehr ermutigend!
Wie oben erwähnt, werden in derselben Linie Prozessoren für mobile Geräte entwickelt, für die Energieeffizienz entscheidend ist und auf denen das Netzwerk hauptsächlich ausgeführt wird (d. H. Separat Prozessoren für das Cloud-Lernen und separat für die Ausführung):
 Und mit diesem Parameter sieht zumindest im Vergleich zu NVIDIA alles gut aus (beachten Sie, dass kein Vergleich mit Google durchgeführt wurde, Google jedoch keine Cloud-TPUs an die Hände gibt). Und ihre mobilen Chips werden mit Prozessoren von Apple, Google und anderen Unternehmen konkurrieren, aber es ist noch zu früh, um hier Bilanz zu ziehen.Es ist deutlich zu sehen, dass die neuen Nano-, Tiny- und Lite-Chips noch besser sein sollten. Es wird deutlich,
Und mit diesem Parameter sieht zumindest im Vergleich zu NVIDIA alles gut aus (beachten Sie, dass kein Vergleich mit Google durchgeführt wurde, Google jedoch keine Cloud-TPUs an die Hände gibt). Und ihre mobilen Chips werden mit Prozessoren von Apple, Google und anderen Unternehmen konkurrieren, aber es ist noch zu früh, um hier Bilanz zu ziehen.Es ist deutlich zu sehen, dass die neuen Nano-, Tiny- und Lite-Chips noch besser sein sollten. Es wird deutlich, warum Trump Angst hatte, warum viele Hersteller die Erfolge von Huawei (das alle Eisenhersteller in den USA, einschließlich Intel im Jahr 2018, übertraf) sorgfältig prüfen.Analoge tiefe Netzwerke
Wie Sie wissen, entwickelt sich Technologie oft spiralförmig, wenn alte und vergessene Ansätze in einer neuen Runde relevant werden.Ähnliches könnte sehr gut mit neuronalen Netzen passieren. Sie haben vielleicht gehört, dass die Multiplikations- und Additionsoperationen einmal von Elektronenröhren und Transistoren ausgeführt wurden (zum Beispiel die Umwandlung von Farbräumen - eine typische Multiplikation von Matrizen - in jedem Farbfernseher bis Mitte der 90er Jahre)? Es stellte sich eine gute Frage: Wenn unser neuronales Netzwerk relativ unempfindlich gegen ungenaue Berechnungen im Inneren ist, was ist, wenn wir diese Berechnungen in analoge Form umwandeln? Wir erhalten sofort eine spürbare Beschleunigung der Berechnungen und eine möglicherweise dramatische Reduzierung des Energieverbrauchs für einen Vorgang:Mit diesem Ansatz wird DNN (Deep Neural Network) schnell und energieeffizient berechnet. Es gibt jedoch ein Problem - dies sind DAC / ADCs (DAC / ADC) - Konverter von digital zu analog und umgekehrt, die sowohl die Energieeffizienz als auch die Prozessgenauigkeit verringern.Bereits 2017 schlug IBM Research ein analoges CMOS für RPU ( Resistive Processing Units ) vor, mit dem Sie verarbeitete Daten auch in analoger Form speichern und die Gesamteffizienz des Ansatzes erheblich steigern können:, — RPU, , . IBM , 2- ( ), 100 (!) GPU:
, :
Die mögliche Richtung des analogen Rechnens sieht jedoch
äußerst interessant aus.
Das einzige, was verwirrt, ist, dass es IBM ist,
die bereits Dutzende von Patenten zu diesem Thema angemeldet hat . Erfahrungsgemäß kooperieren sie aufgrund der Besonderheiten der Unternehmenskultur relativ schwach mit anderen Unternehmen und verlangsamen, da sie einige Technologien besitzen, ihre Entwicklung unter anderem eher, als sie effektiv zu teilen. Beispielsweise lehnte IBM es einmal ab, die arithmetische Komprimierung für JPEG an das
ISO- Komitee zu lizenzieren, obwohl der Standardentwurf eine Option mit arithmetischer Komprimierung war. Infolgedessen wurde JPEG mit Huffman-Komprimierung zum Leben erweckt und stach 10-15% schlechter als es konnte. Die gleiche Situation war bei Videokomprimierungsstandards. Und die Branche hat erst nach Ablauf von 5 IBM-Patenten 12 Jahre später massiv auf arithmetische Komprimierung in Codecs umgestellt ... Hoffen wir, dass IBM diesmal eher zur Zusammenarbeit neigt, und
wünschen dementsprechend
allen, die nicht mit IBM verbunden sind, maximalen Erfolg auf diesem Gebiet Der Nutzen
solcher Menschen und Unternehmen ist groß .
Wenn es klappt,
wird es eine Revolution in der Nutzung neuronaler Netze und eine Revolution in vielen Bereichen der Informatik sein.Verschiedenes Andere Briefe
Im Allgemeinen ist das Thema der Beschleunigung neuronaler Netze in Mode gekommen, alle großen Unternehmen und Dutzende von Startups sind daran beteiligt, und
mindestens fünf von ihnen haben bis Anfang 2018 Investitionen in Höhe von
mehr als 100 Millionen US-Dollar angezogen . Insgesamt wurden im Jahr 2017 1,5 Milliarden US-Dollar in Startups im Zusammenhang mit der Entwicklung von Chips investiert. Trotz der Tatsache, dass die Anleger die Chiphersteller seit gut 15 Jahren nicht mehr bemerkten (weil es dort vor dem Hintergrund der Giganten nichts zu fangen gab). Im Allgemeinen - jetzt gibt es eine echte Chance für eine kleine Eisenrevolution. Darüber hinaus ist es äußerst schwierig vorherzusagen, welche Architektur gewinnen wird, der Bedarf an Revolution ist gereift und die Möglichkeiten zur Steigerung der Produktivität sind groß. Die klassische revolutionäre Situation ist gereift:
Moore kann nicht mehr und
Dean ist noch nicht bereit.
Nun, da das wichtigste Marktrecht - anders sein - gibt es viele neue Buchstaben, zum Beispiel:
- Neural Processing Unit ( NPU ) - Ein Neuroprozessor, manchmal wunderschön - ein neuromorpher Chip - im Allgemeinen der allgemeine Name für einen Beschleuniger neuronaler Netze, die als Chips Samsung , Huawei und weiter auf der Liste bezeichnet werden ...
Im Folgenden werden in diesem Abschnitt hauptsächlich Folien von Unternehmenspräsentationen als Beispiele für Technologie -Selbstnamen aufgeführt
Es ist klar, dass ein direkter Vergleich problematisch ist, aber hier sind einige interessante Daten zum Vergleich von Chips mit Neuroprozessoren von Apple und Huawei, die von TSMC hergestellt wurden und von eingangs erwähnt wurden. Es zeigt sich, dass der Wettbewerb hart ist, die neue Generation eine 2-8-fache Produktivitätssteigerung und die Komplexität technologischer Prozesse aufweist:
- Neural Network Processor (NNP) - Prozessor für neuronale Netze.
Dies ist der Name seiner Chipfamilie, zum Beispiel Intel (ursprünglich war es die Firma Nervana Systems , die Intel 2016 für über 400 Millionen US-Dollar gekauft hat). In Artikeln und Büchern ist der Name NNP jedoch auch weit verbreitet.
- Intelligence Processing Unit (IPU) - ein intelligenter Prozessor - der Name der von Graphcore beworbenen Chips (die übrigens bereits eine Investition von 310 Millionen US-Dollar erhalten haben).
Es werden spezielle Karten für Computer hergestellt, die jedoch auf das Training neuronaler Netze ausgerichtet sind. Die RNN-Trainingsleistung ist 180- bis 240-mal höher als die des NVIDIA P100.
- Dataflow Processing Unit (DPU) - Datenverarbeitungsprozessor - der Name wird von WAVE Computing beworben, das bereits eine Investition von 203 Millionen US-Dollar erhalten hat. Es produziert ungefähr die gleichen Beschleuniger wie Graphcore:
Da sie 100 Millionen weniger erhalten haben, erklären sie, dass das Training nur mehr als 25 Mal schneller ist als auf der GPU (obwohl sie versprechen, dass es bald 1000 Mal sein wird). Mal sehen ...
- Vision Processing Unit ( VPU ) - Computer Vision-Prozessor:
Der Begriff wird in Produkten mehrerer Unternehmen verwendet, z. B. Myriad X VPU von Movidius (ebenfalls 2016 von Intel gekauft ).
- Einer der Konkurrenten von IBM (der, wie wir uns erinnern, den Begriff RPU verwendet ) - Mythic - bewegt Analog DNN , das auch das Netzwerk im Chip speichert und relativ schnell ausführt. Bisher haben sie nur Versprechen, wenn auch ernst :
Und dies listet nur die größten Gebiete auf, in deren Entwicklung Hunderte Millionen investiert wurden (dies ist wichtig für die Entwicklung von Eisen).
Wie wir sehen, blühen im Allgemeinen alle Blumen schnell. Allmählich werden Unternehmen Investitionen in Milliardenhöhe verdauen (normalerweise dauert die Herstellung von Chips 1,5 bis 3 Jahre), Staub wird sich absetzen, der Marktführer wird klar, die Gewinner werden wie üblich eine Geschichte schreiben und der Name der erfolgreichsten Technologie auf dem Markt wird allgemein akzeptiert. Dies ist bereits mehrmals vorgekommen („IBM PC“, „Smartphone“, „Xerox“ usw.).
Ein paar Worte zum richtigen Vergleich
Wie bereits oben erwähnt, ist es nicht einfach, die Leistung neuronaler Netze richtig zu vergleichen. Genau aus diesem Grund veröffentlicht Google ein Diagramm, in dem TPU v1 den NVIDIA V100 herstellt. NVIDIA veröffentlicht eine solche Schande und veröffentlicht einen Zeitplan, in dem Google TPU v1 die V100 verliert. (Also!) Google veröffentlicht die folgende Tabelle, in der der V100 auf Google TPU v2 & v3 verliert. Und schließlich ist Huawei der Zeitplan, in dem jeder beim Huawei Ascend verliert, aber das V100 ist besser als das TPU v3. Kurz gesagt, Zirkus. Was ist charakteristisch -
jedes Diagramm
hat seine eigene Wahrheit!
Die Hauptursachen der Situation sind klar:
- Sie können die Lerngeschwindigkeit oder die Ausführungsgeschwindigkeit messen (je nachdem, was bequemer ist).
- Es ist möglich, verschiedene neuronale Netze zu messen, da sich die Geschwindigkeit der Ausführung / des Trainings verschiedener neuronaler Netze auf bestimmten Architekturen aufgrund der Netzwerkarchitektur und der erforderlichen Datenmenge erheblich unterscheiden kann.
- Und Sie können die Spitzenleistung des Beschleunigers messen (vielleicht die abstrakteste von allen oben genannten).
Als Versuch, die Dinge in diesem Zoo in Ordnung zu bringen, erschien der
MLPerf- Test, für den jetzt Version 0.5 verfügbar ist, d. H. Derzeit entwickelt er eine Vergleichsmethode, die im
3. Quartal dieses Jahres erstmals veröffentlicht werden soll :
Da die Autoren dort einen der Hauptverantwortlichen für TensorFlow sind, besteht jede Möglichkeit herauszufinden, wie man am besten trainiert und möglicherweise verwendet (da die mobile Version von TF im Laufe der Zeit höchstwahrscheinlich auch in diesen Test einbezogen wird).
Kürzlich hat die internationale Organisation
IEEE , die den dritten Teil der weltweiten Fachliteratur zu Funkelektronik, Computern und Elektrotechnik veröffentlicht,
Huawei aus dem
Gesicht eines Kindes
verbannt und
das Verbot jedoch bald
aufgehoben . Huawei ist noch nicht im
aktuellen MLPerf-Ranking, während Huawei TPU ein ernstzunehmender Konkurrent von Google TPUs und NVIDIA-Karten ist (d. H. Neben politischen gibt es wirtschaftliche Gründe, Huawei offen zu ignorieren). Mit unverhohlenem Interesse werden wir die Entwicklung der Ereignisse verfolgen!
Alles in den Himmel! Näher an den Wolken!
Und da es um Training ging, lohnt es sich, ein paar Worte zu seinen Besonderheiten zu sagen:
- Mit der weit verbreiteten Abkehr von der Erforschung tiefer neuronaler Netze (mit Dutzenden und Hunderten von Schichten, die wirklich alle zerreißen) war es notwendig, Hunderte von Megabyte an Koeffizienten zu mahlen, was alle Prozessor-Caches früherer Generationen sofort unwirksam machte. Gleichzeitig diskutiert das klassische ImageNet eine strikte Korrelation zwischen der Größe des Netzwerks und seiner Genauigkeit (je höher desto besser, rechts, desto größer das Netzwerk, ist die horizontale Achse logarithmisch):
- Der Berechnungsprozess innerhalb des neuronalen Netzwerks folgt einem festen Schema, d.h. Wo in den allermeisten Fällen alle „Verzweigungen“ und „Übergänge“ (im Hinblick auf das letzte Jahrhundert) stattfinden werden, ist im Voraus genau bekannt, so dass die spekulative Ausführung von Anweisungen ohne Arbeit bleibt, was zuvor die Produktivität erheblich steigert:
Dies macht die angehäuften superskalaren Vorhersagemechanismen für Verzweigungen und Vorberechnungen früherer Jahrzehnte der Prozessorverbesserung unwirksam (dieser Teil des Chips trägt leider auch zur globalen Erwärmung bei, ähnlich wie DNN im DNN-Cache).
- Darüber hinaus ist das neuronale Netzwerktraining horizontal relativ schwach skaliert . Das heißt, Wir können nicht 1000 leistungsfähige Computer nehmen und 1000-mal Lernbeschleunigung erhalten. Und selbst bei 100 können wir nicht (zumindest bis das theoretische Problem der Verschlechterung der Trainingsqualität bei einer großen Größe der Charge gelöst ist). Im Allgemeinen ist es für uns ziemlich schwierig, etwas auf mehrere Computer zu verteilen, da die Geschwindigkeit des Lernens katastrophal abnimmt, sobald die Zugriffsgeschwindigkeit auf den einheitlichen Speicher, in dem sich das Netzwerk befindet, abnimmt. Wenn ein Forscher
kostenlos auf 1000 leistungsstarke Computer zugreifen kann, wird er sie sicherlich bald alle nutzen, aber höchstwahrscheinlich (wenn es kein Infiniband + RDMA gibt) wird es viele neuronale Netze mit unterschiedlichen Hyperparametern geben. Das heißt, Die gesamte Trainingszeit ist nur um ein Vielfaches kürzer als bei einem Computer. Dort ist es möglich, mit der Größe des Stapels, der Weiterbildung und anderen neuen modischen Technologien zu spielen, aber die Hauptschlussfolgerung lautet: Ja, mit zunehmender Anzahl von Computern steigen die Arbeitseffizienz und die Wahrscheinlichkeit, ein Ergebnis zu erzielen, jedoch nicht linear. Und heute ist die Zeit eines Data Science-Forschers teuer und oft, wenn Sie viele Autos ausgeben können (wenn auch unvernünftig), aber eine Beschleunigung erhalten - dies geschieht (siehe das Beispiel mit 1, 2 und 4 teuren V100 in den Wolken unten).
Genau diese Punkte erklären, warum so viele Menschen zur Entwicklung von Spezialeisen für tiefe neuronale Netze eilten. Und warum haben sie ihre Milliarden bekommen? Am Ende des Tunnels ist wirklich sichtbares Licht und nicht nur Graphcore (das, wie man sich erinnert, das 240-fache des RNN-Trainings beschleunigte).
Zum Beispiel sind die Herren von IBM Research
optimistisch, dass die Entwicklung spezieller Chips, die die Recheneffizienz in 5 Jahren um eine Größenordnung steigern (und in 10 Jahren um 2 Größenordnungen, die in diesem Diagramm eine 1000-fache Steigerung gegenüber 2016 erreichen), wahr ist , in der Effizienz pro Watt, aber die Kernleistung wird auch zunehmen):
All dies bedeutet das Auftreten von Eisenstücken, deren Training relativ schnell, aber teuer sein wird, was natürlich zu der Idee führt, die Zeit für die Verwendung dieses teuren Eisenstücks zwischen den Forschern zu teilen. Und diese Idee führt uns heute nicht weniger natürlich zum Cloud Computing. Und der Übergang des Lernens in die Wolken ist seit langem aktiv.
Beachten Sie, dass sich das Training derselben Modelle jetzt zeitlich um eine Größenordnung verschiedener Cloud-Dienste unterscheiden kann. Amazon liegt an der Spitze, und Googles kostenloses Colab steht an letzter Stelle. Bitte beachten Sie, wie sich das Ergebnis der Anzahl der V100 unter den Führenden ändert - eine Erhöhung der Anzahl der Karten um das Vierfache (!) Erhöht die Produktivität um weniger als ein Drittel (!!!) von Blau auf Lila, und Google hat noch weniger:
Es scheint, dass der Unterschied in den kommenden Jahren auf zwei Größenordnungen anwachsen wird. Herr! Geld kochen! Wir werden den erfolgreichsten Investoren einvernehmlich mehrere Milliarden Investitionen zurückgeben ...
Kurz gesagt
Versuchen wir, die wichtigsten Punkte des Tablets zusammenzufassen:
Ein paar Worte zur Softwarebeschleunigung
Fairerweise erwähnen wir, dass heute das große Thema die Softwarebeschleunigung der Ausführung und des Trainings tiefer neuronaler Netze ist. Die Ausführung kann vor allem durch die sogenannte Quantisierung des Netzwerks erheblich beschleunigt werden. Vielleicht liegt dies zum einen daran, dass der Bereich der verwendeten Gewichte nicht so groß ist und es häufig möglich ist, Gewichte von einem 4-Byte-Gleitkommawert auf eine 1-Byte-Ganzzahl zu vergröbern (und, wenn man sich an die Erfolge von IBM erinnert, noch stärker). Zweitens ist das trainierte Netzwerk insgesamt ziemlich widerstandsfähig gegen
Rechenrauschen und die Genauigkeit des Übergangs zu
int8 sinkt leicht. Gleichzeitig erhöht die Tatsache, dass das Netzwerk um das Vierfache verkleinert wird und als schnelle Vektoroperationen betrachtet werden kann, die Gesamtausführungsgeschwindigkeit erheblich, obwohl die Anzahl der Operationen (aufgrund der Skalierung bei der Berechnung) sogar zunehmen kann. Dies ist besonders wichtig für mobile Anwendungen, funktioniert aber auch in den Clouds (ein Beispiel für eine beschleunigte Ausführung in Amazon Clouds):
Es gibt andere Möglichkeiten,
die Netzwerkausführung algorithmisch zu
beschleunigen, und noch mehr Möglichkeiten,
das Lernen zu
beschleunigen . Dies sind jedoch separate große Themen, über die diesmal nicht gesprochen wird.
Anstelle einer Schlussfolgerung
In seinen Vorträgen gibt der Investor und Autor
Tony Ceba ein großartiges Beispiel: Im Jahr 2000 nahm der Supercomputer Nr. 1 mit einer Kapazität von 1 Teraflops 150 Quadratmeter ein, kostete 46 Millionen US-Dollar und verbrauchte 850 kW:
15 Jahre später passte die NVIDIA-GPU mit einer Leistung von 2,3 Teraflops (2-mal mehr) in eine Hand, kostete 59 USD (eine Verbesserung um das Millionenfache) und verbrauchte 15 Watt (eine Verbesserung um das 56.000-fache):
Im März dieses Jahres stellte
Google TPU-Pods vor , bei denen es sich tatsächlich um flüssigkeitsgekühlte Supercomputer handelt, die auf TPU v3 basieren. Das Hauptmerkmal besteht darin, dass sie in Systemen mit 1024 TPU zusammenarbeiten können. Sie sehen ziemlich beeindruckend aus:
Die genauen Daten werden nicht angegeben, aber es wird gesagt, dass das System mit den Top-5-Supercomputern der Welt vergleichbar ist. TPU Pod kann die Geschwindigkeit des Lernens neuronaler Netze drastisch erhöhen. Um die Interaktionsgeschwindigkeit zu erhöhen, werden TPUs durch Hochgeschwindigkeitsleitungen zu einer Ringstruktur verbunden:

Es scheint, dass dieser doppelt so leistungsstarke Neuroprozessor nach 15 Jahren auch in Ihre Hand passen wird, wie der
Skynet-Prozessor (Sie
müssen zugeben, es ist etwas Ähnliches):
Aufnahme aus der Regieversion des Films "Terminator 2"Angesichts der aktuellen Verbesserungsrate von Hardwarebeschleunigern in tiefen neuronalen Netzen und des obigen Beispiels ist dies völlig real. In ein paar Jahren gibt es jede Chance, einen Chip mit einer Leistung wie dem heutigen TPU Pod zu kaufen.
Übrigens ist es lustig, dass die Chiphersteller im Film (anscheinend vorstellend, wohin das Selbsttrainingsnetzwerk führen könnte) die Umschulung standardmäßig deaktiviert haben. Charakteristischerweise konnte der
T-800 selbst den Trainingsmodus nicht aktivieren und arbeitete im Inferenzmodus (siehe die längere
Regieversion ). Darüber hinaus wurde der
neuronale Netzprozessor weiterentwickelt und konnte beim Einschalten der Umschulung die zuvor gesammelten Daten zur Aktualisierung des Modells verwenden. Nicht schlecht für 1991.
Dieser Text wurde im heißen 13-millionsten Shenzhen begonnen. Ich saß in einem der 27.000 elektrischen Taxis der Stadt und schaute mit großem Interesse auf die 4 Flüssigkristallschirme des Autos. Ein kleines - unter den Geräten vor dem Fahrer, zwei - in der Mitte im Armaturenbrett und das letzte - durchscheinend - im Rückspiegel, kombiniert mit einem DVR, einer Videoüberwachungskamera und einem Android an Bord (gemessen an der obersten Zeile mit dem Ladezustand und der Kommunikation mit dem Netzwerk). Es wurden Fahrerdaten (über die man sich beschweren sollte, wenn dies der Fall war), eine frische Wettervorhersage angezeigt, und es schien eine Verbindung zur Taxiflotte zu bestehen. Der Fahrer konnte kein Englisch und konnte ihn nicht nach seinen Eindrücken von der elektrischen Maschine fragen. Deshalb trat er träge aufs Pedal und bewegte das Auto leicht im Stau. Und ich beobachtete das Fenster mit einem futuristischen Blick mit Interesse - die Chinesen in ihren Jacken fuhren von der Arbeit an Elektrorollern und Monorädern ... und fragten mich, wie das alles in 15 Jahren aussehen würde ...
Tatsächlich kann der Rückspiegel bereits heute mithilfe der Daten der Kamera des DVR und der
Hardwarebeschleunigung der neuronalen Netze das Auto im Verkehr steuern und die Route festlegen. Zumindest nachmittags). Nach 15 Jahren wird das System eindeutig nicht nur in der Lage sein, ein Auto zu fahren, sondern wird mich auch gerne mit den Eigenschaften frischer chinesischer Elektrofahrzeuge versorgen. Natürlich auf Russisch (optional: Englisch, Chinesisch ... endlich Albanisch). Der Fahrer hier ist überflüssig, schlecht ausgebildet, eine Verbindung.
Herr!
EXTREM INTERESSANT 15 Jahre warten auf uns!
Bleib dran!
Ich komme wieder! )))
 UPD:
UPD: Die interessantesten Kommentare:
Über die Quantisierung und Beschleunigung von Berechnungen auf FPGA
Kommentare @Mirn
Auf dem FPGA steht nicht nur eine Arithmetik mit beliebiger Genauigkeit zur Verfügung, sondern auch die verdammt wichtige Fähigkeit, Daten beliebiger Bits zu speichern und zu verarbeiten. Zum Beispiel enthält das nervige MobileNetV2 W und B zu viele Koeffizienten, und Sie können sie ohne großen Genauigkeitsverlust auf nur 16 Bit quantisieren, oder Sie müssen neu trainieren. Wenn Sie jedoch nach innen schauen und Statistiken über Kanäle und Ebenen sammeln, können Sie sehen, dass alle 16 Bits nur am Eingang der ersten 1000-W-Koeffizienten verwendet werden. Der Rest hat punktuell 8 bis 11 Bits, von denen nur 2-3 höchstwertige Bits und Vorzeichen wirklich wichtig sind. und Statistiken über die Verwendung von Kanälen, so dass es viele Kanäle gibt, in denen im Allgemeinen Nullen oder kleine Werte vorhanden sind, oder Kanäle, in denen fast alle Werte 8 bis 11 Bit sind, d.h. Es ist möglich, den Aussteller in der Kompilierungszeit in Nägel zu nageln und nicht zu lagern, d.h. Tatsächlich ist es möglich, nicht 16-Bit-, sondern 4-Bit-Werte im ROM-Speicher zu speichern, und Sie können sogar das gesamte neuronale Netzwerk auf billigen FPGAs ohne großen Genauigkeitsverlust (weniger als 1%) speichern und mit einer Latenz von bis zu Zehntausenden von FPS verarbeiten, sodass wir sofort eine Antwort auf das neuronale Netzwerk erhalten Wie endet der Empfang des Frames?
Über die Quantisierung: Meine Idee ist, dass, wenn sich in einer Reihe von Berechnungsstufen W die Koeffizienten für Kanal Nr. 0 nur von +50 auf -50 ändern, es sinnvoll ist, die Bitterkeit auf 7 zu komprimieren, und wenn beispielsweise von -123 auf +124, dann auf 8 (einschließlich des Vorzeichens) ) FPGA , 7, 8 ROM . , .
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! weil dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
GPU, FPGA, ASIC
@BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
FPGA, FPGA Microsoft
@Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . Das heißt, - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
FPGA ASIC
@Mirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !