Denken Sie daran, dass der Elastic Stack auf der nicht relationalen Elasticsearch-Datenbank, der Kibana-Weboberfläche und den Datensammlern (dem bekanntesten Logstash, verschiedenen Beats, APM und anderen) basiert. Eine der netten Ergänzungen zum gesamten aufgelisteten Produktstapel ist die Datenanalyse mit Algorithmen für maschinelles Lernen. In diesem Artikel verstehen wir, was diese Algorithmen sind. Wir bitten um Katze.
Maschinelles Lernen ist eine kostenpflichtige Funktion des Shareware Elastic Stack und Teil des X-Packs. Um es zu verwenden, reicht es nach der Aktivierung aus, die 30-Tage-Testversion zu aktivieren. Nach Ablauf der Testphase können Sie Support für die Verlängerung anfordern oder ein Abonnement erwerben. Die Abonnementkosten werden nicht aus der Datenmenge berechnet, sondern aus der Anzahl der verwendeten Knoten. Nein, die Datenmenge wirkt sich natürlich auf die Anzahl der erforderlichen Knoten aus, aber dieser Lizenzierungsansatz ist im Verhältnis zum Budget des Unternehmens humaner. Wenn keine hohe Leistung erforderlich ist, können Sie sparen.
ML in Elastic Stack ist in C ++ geschrieben und funktioniert außerhalb der JVM, auf der Elasticsearch selbst ausgeführt wird. Das heißt, der Prozess (der übrigens als Autodetect bezeichnet wird) verbraucht alles, was die JVM nicht verschluckt. Am Demo-Stand ist dies nicht so wichtig, aber in einer produktiven Umgebung ist es wichtig, separate Knoten für ML-Aufgaben hervorzuheben.
Algorithmen für maschinelles Lernen werden in zwei Kategorien unterteilt -
mit und
ohne Lehrer . In Elastic Stack gehört der Algorithmus zur Kategorie „kein Lehrer“.
Über diesen Link können Sie den mathematischen Apparat von Algorithmen für maschinelles Lernen sehen.
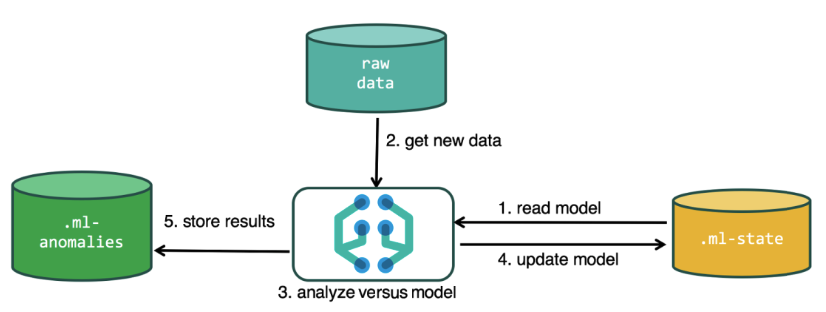
Zur Durchführung der Analyse verwendet der Algorithmus für maschinelles Lernen die in den Elasticsearch-Indizes gespeicherten Daten. Sie können Aufgaben für die Analyse sowohl über die Kibana-Oberfläche als auch über die API erstellen. Wenn Sie dies durch Kibana tun, müssen einige Dinge nicht wissen. Zum Beispiel zusätzliche Indizes, die der Algorithmus im Prozess verwendet.
Zusätzliche Indizes, die im Analyseprozess verwendet werden.ml-state - Informationen zu statistischen Modellen (Analyseeinstellungen);
.ml-Anomalien- * - Ergebnisse der Arbeit von ML-Algorithmen;
.ml-Benachrichtigungen - Benachrichtigungseinstellungen basierend auf Analyseergebnissen.
Die Datenstruktur in der Elasticsearch-Datenbank besteht aus darin gespeicherten Indizes und Dokumenten. Beim Vergleich mit einer relationalen Datenbank kann der Index mit dem Datenbankschema und einem Dokument mit einem Eintrag in der Tabelle verglichen werden. Dieser Vergleich ist bedingt und dient dazu, das Verständnis von weiterem Material für diejenigen zu vereinfachen, die nur von Elasticsearch gehört haben.
Über die API steht dieselbe Funktionalität zur Verfügung wie über die Weboberfläche. Aus Gründen der Klarheit und des Verständnisses der Konzepte wird die Konfiguration über Kibana gezeigt. Im Menü links befindet sich ein Abschnitt zum maschinellen Lernen, in dem Sie einen neuen Job erstellen können. In der Kibana-Oberfläche sieht es wie im Bild unten aus. Jetzt werden wir jeden Aufgabentyp analysieren und die Analysetypen zeigen, die hier erstellt werden können.
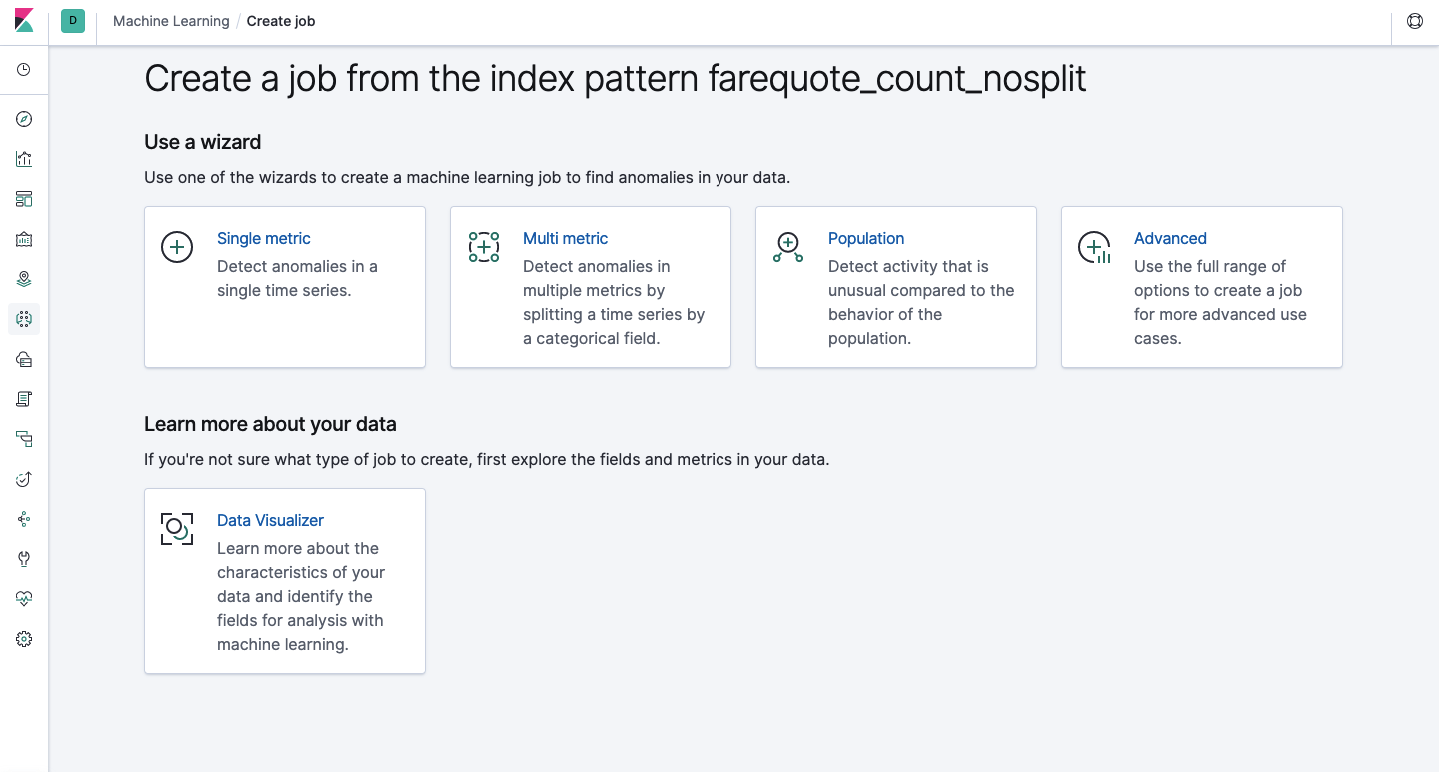
Einzelne Metrik - Analyse einer Metrik, Multi-Metrik - Analyse von zwei oder mehr Metriken. In beiden Fällen wird jede Metrik in einer isolierten Umgebung analysiert, d.h. Der Algorithmus berücksichtigt nicht das Verhalten der parallel analysierten Metriken, wie es im Fall von Multi Metric erscheinen mag. Um die Berechnung unter Berücksichtigung der Korrelation verschiedener Metriken durchzuführen, können Sie die Bevölkerungsanalyse anwenden. Und Advanced ist eine Feinabstimmung von Algorithmen mit zusätzlichen Optionen für bestimmte Aufgaben.
Einzelne Metrik
Die Analyse von Änderungen in einer einzelnen Metrik ist das Einfachste, was Sie hier tun können. Nachdem Sie auf Job erstellen geklickt haben, sucht der Algorithmus nach Anomalien.
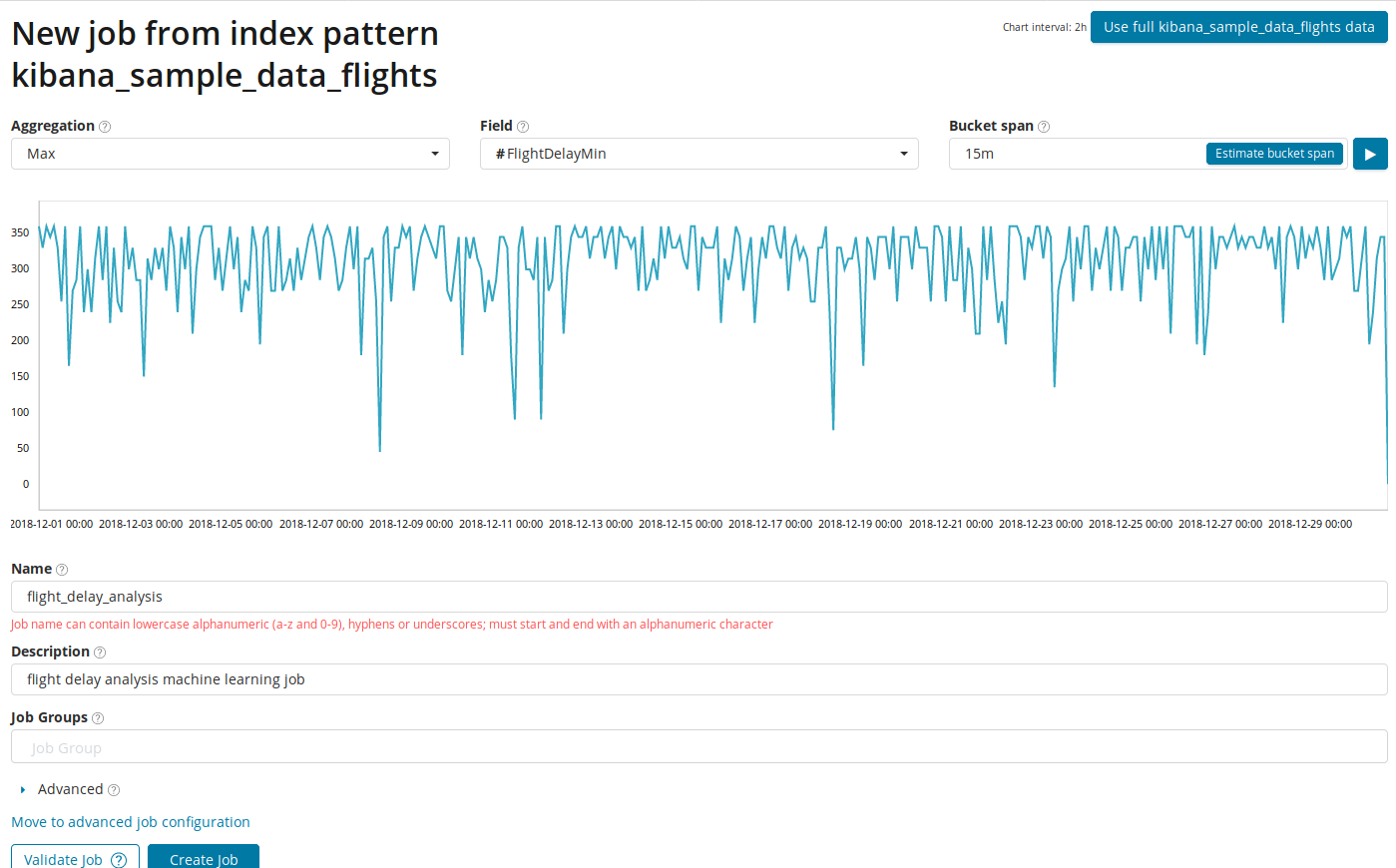
Im Feld
Aggregation können Sie einen Ansatz für die Suche nach Anomalien auswählen. Beispielsweise werden mit
Min abnormale Werte als niedriger als typisch angesehen. Es gibt
Max, Hign Mean, Low, Mean, Distinct und andere. Eine Beschreibung aller Funktionen finden Sie
hier .
Das Feld Feld gibt das numerische Feld im Dokument an, anhand dessen wir analysieren werden.
Im Feld
Bucket span die Granularität der Intervalle auf der Zeitachse, über die die Analyse durchgeführt wird. Sie können der Automatisierung vertrauen oder manuell auswählen. Das Bild unten zeigt ein Beispiel für eine zu niedrige Granularität - Sie können die Anomalie überspringen. Mit dieser Einstellung können Sie die Empfindlichkeit des Algorithmus für Anomalien ändern.

Die Dauer der gesammelten Daten ist ein Schlüsselfaktor, der die Effektivität der Analyse beeinflusst. In der Analyse ermittelt der Algorithmus die Wiederholungsintervalle, berechnet das Konfidenzintervall (Baselines) und identifiziert Anomalien - atypische Abweichungen vom üblichen Verhalten der Metrik. Nur zum Beispiel:
Baselines mit einer kleinen Datenspanne:
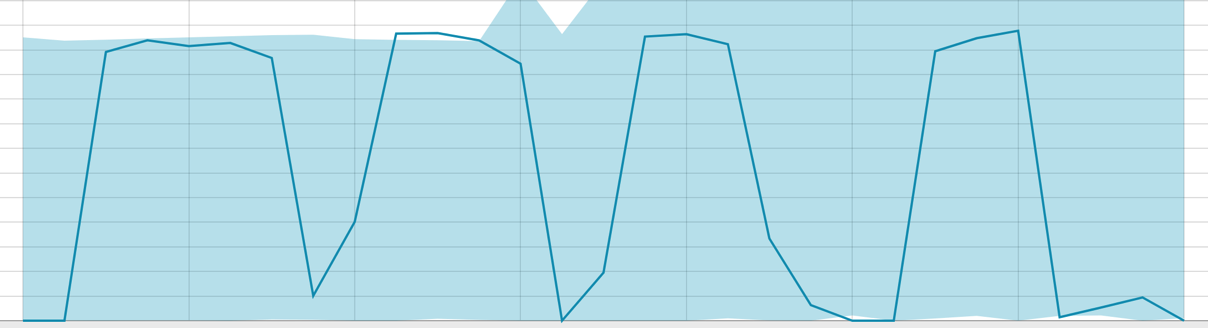
Wenn der Algorithmus etwas zu lernen hat, sieht die Basislinie folgendermaßen aus:
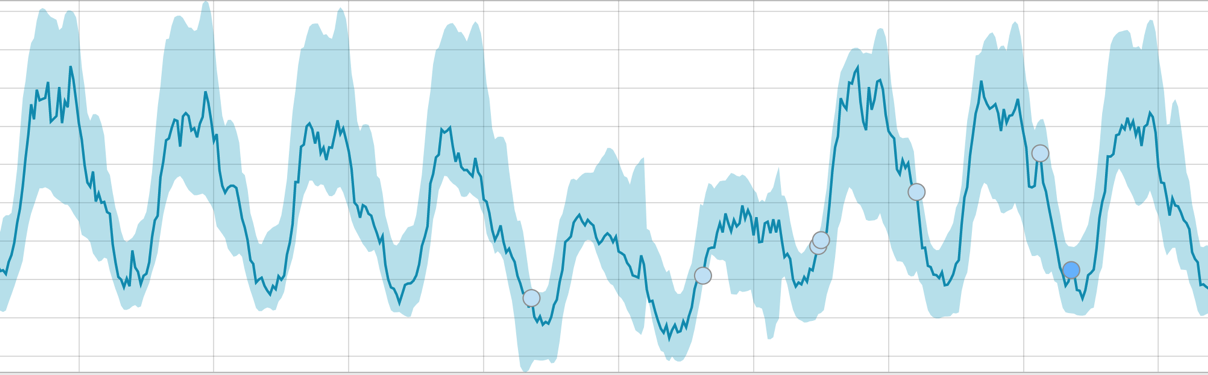
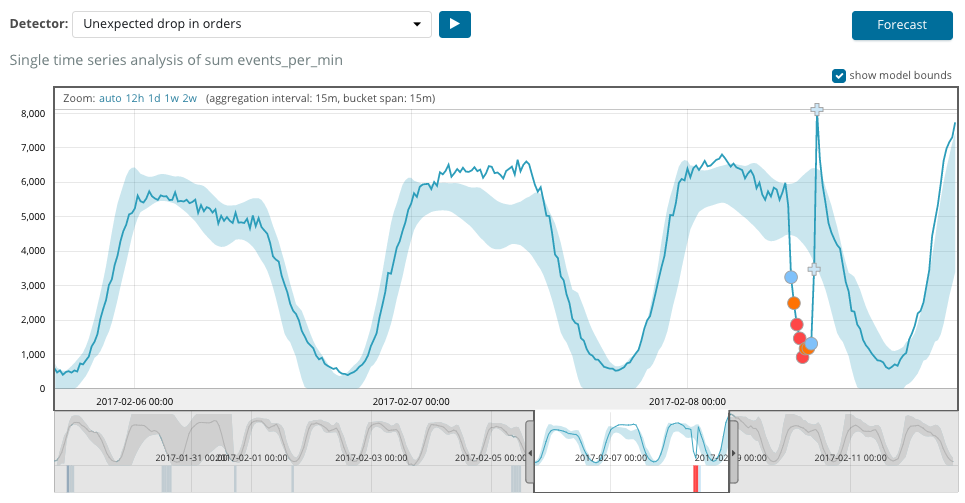
Nach dem Start der Aufgabe ermittelt der Algorithmus die anomalen Abweichungen von der Norm und ordnet sie nach der Wahrscheinlichkeit der Anomalie (die Farbe des entsprechenden Etiketts ist in Klammern angegeben):
Warnung (Cyan): weniger als 25
Klein (gelb): 25-50
Major (orange): 50-75
Kritisch (rot): 75-100
Die folgende Tabelle zeigt ein Beispiel für gefundene Anomalien.
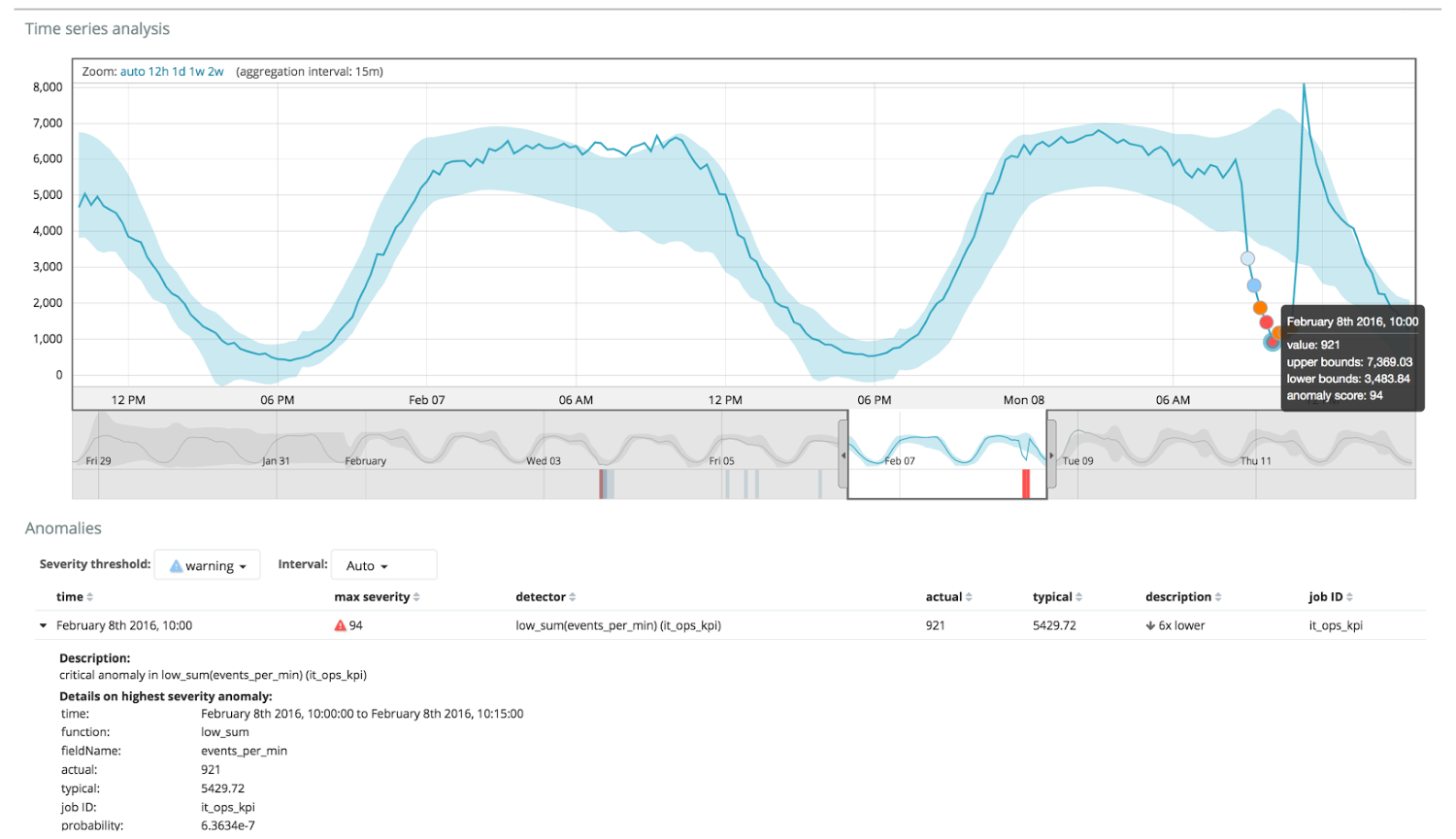
Hier sehen Sie die Zahl 94, die die Wahrscheinlichkeit einer Anomalie angibt. Es ist klar, dass der Wert nahe bei 100 liegt und eine Anomalie bedeutet. Die Spalte unter der Grafik zeigt eine abfällige Wahrscheinlichkeit von 0,000063634% des Auftretens des dortigen Metrikwerts.
Zusätzlich zur Suche nach Anomalien in Kibana können Sie Prognosen ausführen. Dies geschieht auf elementare Weise und aus derselben Sicht mit Anomalien - der Schaltfläche
Prognose in der oberen rechten Ecke.

Die Prognose basiert auf maximal 8 Wochen im Voraus. Auch wenn Sie wirklich wollen, können Sie nicht mehr mit Absicht.
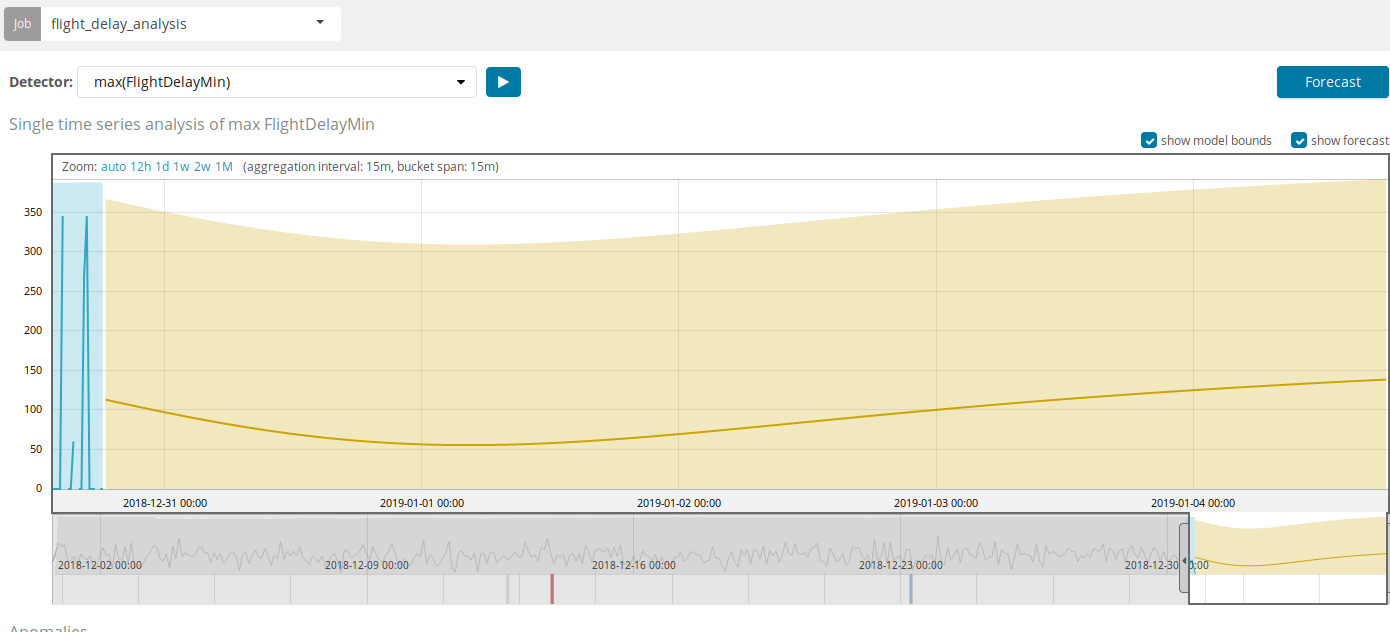
In einigen Situationen ist die Prognose sehr nützlich, beispielsweise wenn die Benutzerlast in der Infrastruktur überwacht wird.
Multi Metrik
Wir fahren mit dem nächsten ML-Feature in Elastic Stack fort - der Analyse mehrerer Metriken in einem Bundle. Dies bedeutet jedoch nicht, dass die Abhängigkeit einer Metrik von einer anderen analysiert wird. Dies ist dasselbe wie bei einer einzelnen Metrik, bei der nur viele Metriken auf einem Bildschirm angezeigt werden, um die Auswirkungen einer Metrik auf den anderen zu vergleichen. Wir werden über die Analyse der Abhängigkeit einer Metrik von einer anderen im Bevölkerungsteil sprechen.
Nachdem Sie mit Multi Metric auf das Quadrat geklickt haben, wird ein Einstellungsfenster angezeigt. Wir werden näher darauf eingehen.
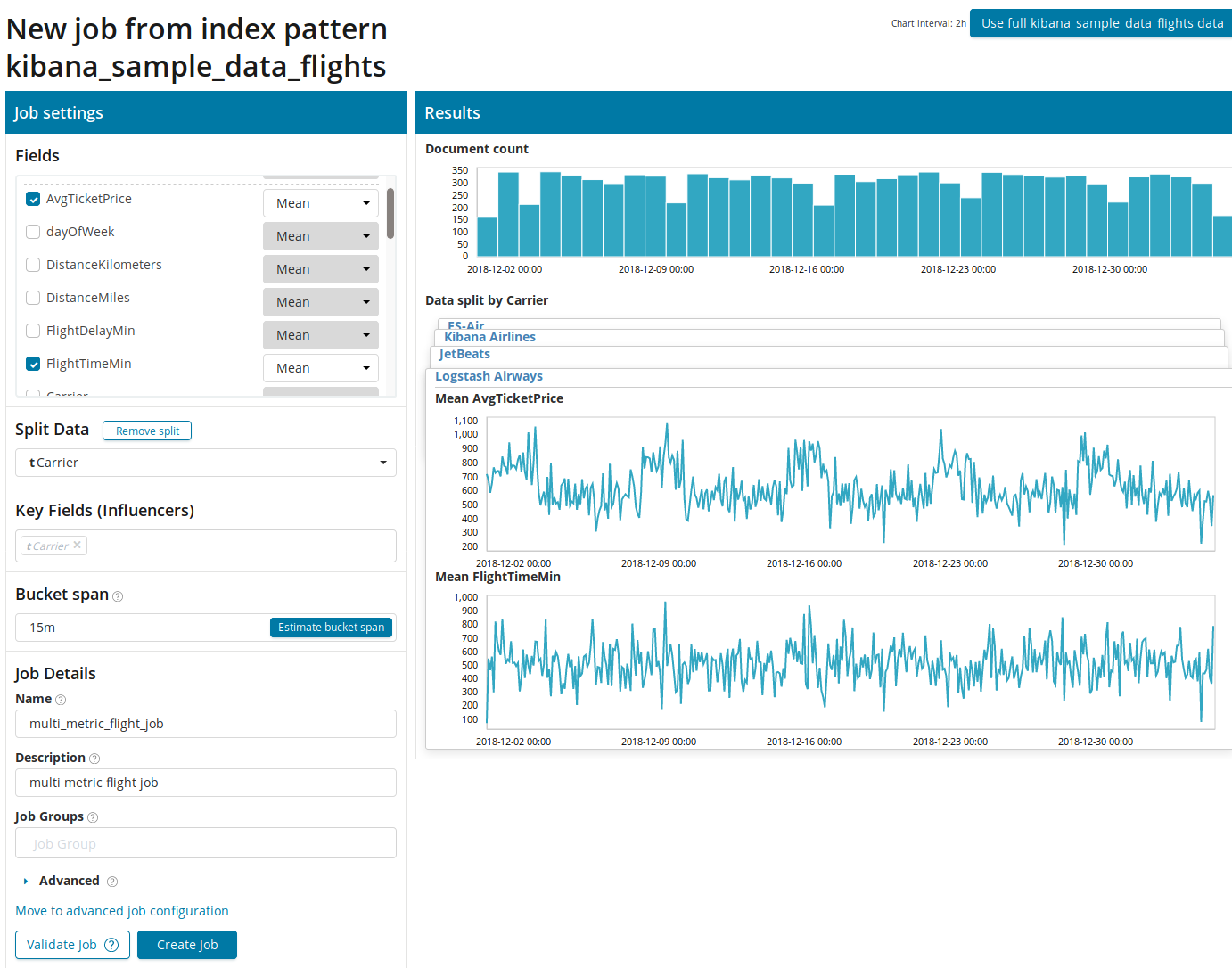
Zuerst müssen Sie die Felder für die Analyse und Aggregation der Daten auswählen. Die Aggregationsoptionen sind hier dieselben wie für einzelne
Metriken (
Max, Hign Mean, Low, Mean, Distinct und andere). Ferner werden die Daten optional in eines der Felder (Feld
Daten teilen) unterteilt. Im Beispiel haben wir dies mit dem Feld
OriginAirportID gemacht . Beachten Sie, dass das Metrikdiagramm auf der rechten Seite jetzt als mehrere Diagramme dargestellt wird.
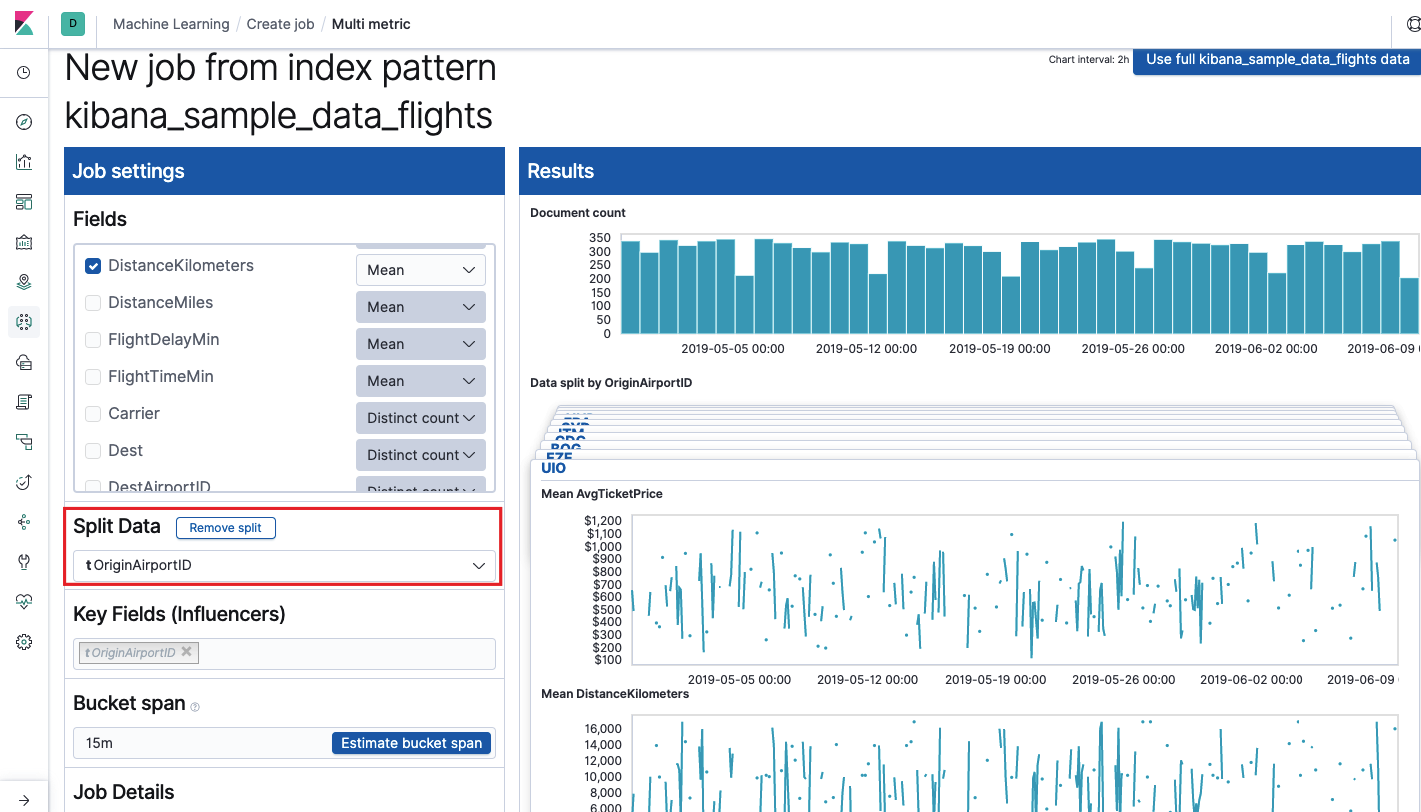
Das
Feld Schlüsselfelder (Influencer) wirkt sich direkt auf die gefundenen Anomalien aus. Standardmäßig gibt es immer mindestens einen Wert, und Sie können weitere hinzufügen. Der Algorithmus berücksichtigt den Einfluss dieser Felder in der Analyse und zeigt die „einflussreichsten“ Werte an.
Nach dem Start wird das folgende Bild in der Kibana-Oberfläche angezeigt.
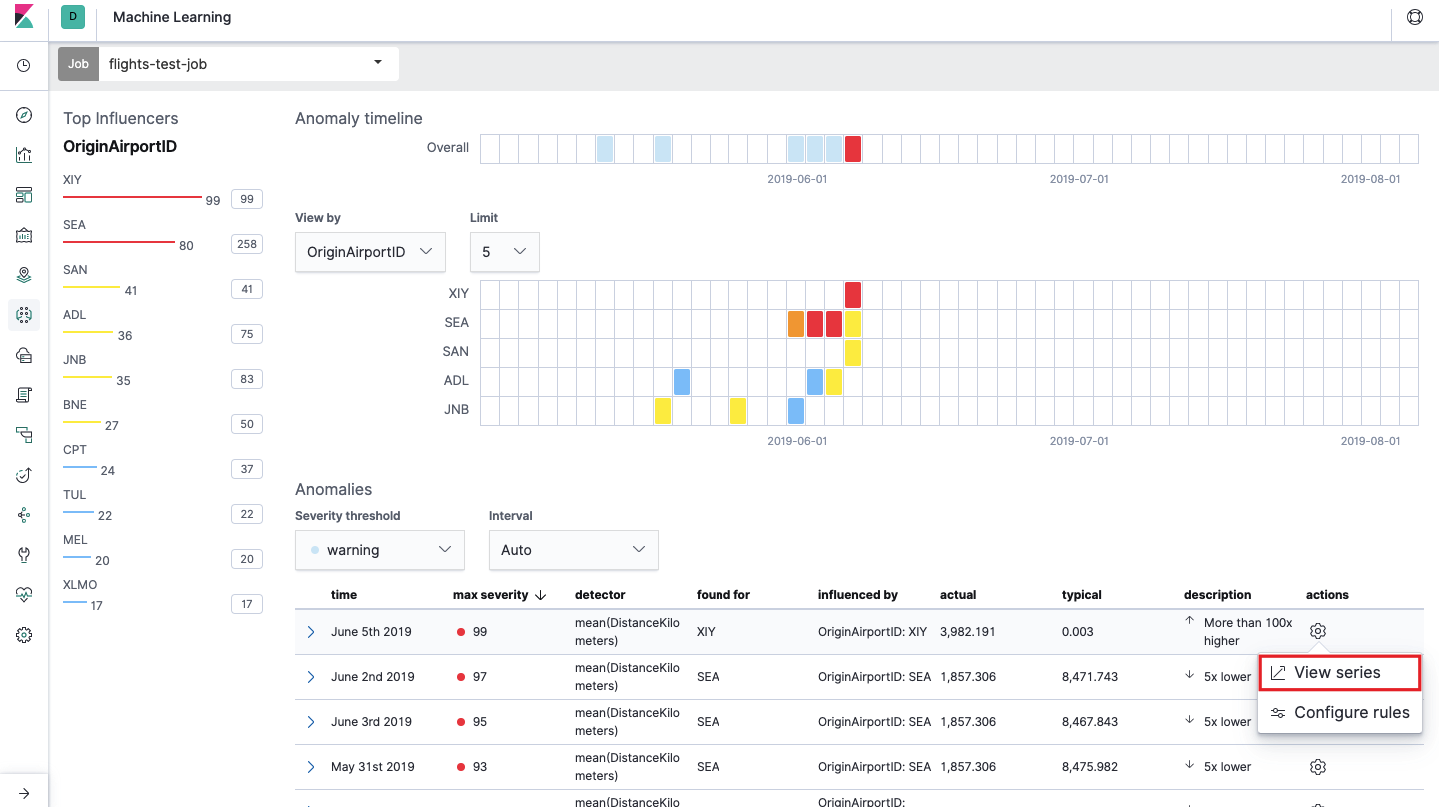
Dies ist das sogenannte Heatmap von Anomalien für jeden Wert des
OriginAirportID- Felds, den wir in den
Split Data angegeben haben . Wie bei der Einzelmetrik gibt die Farbe den Grad der abnormalen Abweichung an. Es ist zweckmäßig, eine ähnliche Analyse durchzuführen, z. B. an Arbeitsstationen, um diejenigen zu verfolgen, bei denen verdächtig viele Berechtigungen usw. vorliegen. Wir haben bereits
über verdächtige Ereignisse in EventLog Windows geschrieben , die auch hier gesammelt und analysiert werden können.
Unterhalb der Heatmap befindet sich eine Liste von Anomalien. Von jeder Anomalie können Sie zur detaillierten Analyse in die Ansicht "Einzelmetrik" wechseln.
Bevölkerung
Um nach Anomalien zwischen den Korrelationen zwischen verschiedenen Metriken zu suchen, verfügt Elastic Stack über eine spezielle Populationsanalyse. Mithilfe dieser Funktion können Sie nach anomalen Werten für die Leistung eines Servers im Vergleich zu anderen Servern suchen, z. B. indem die Anzahl der Anforderungen an das Zielsystem erhöht wird.
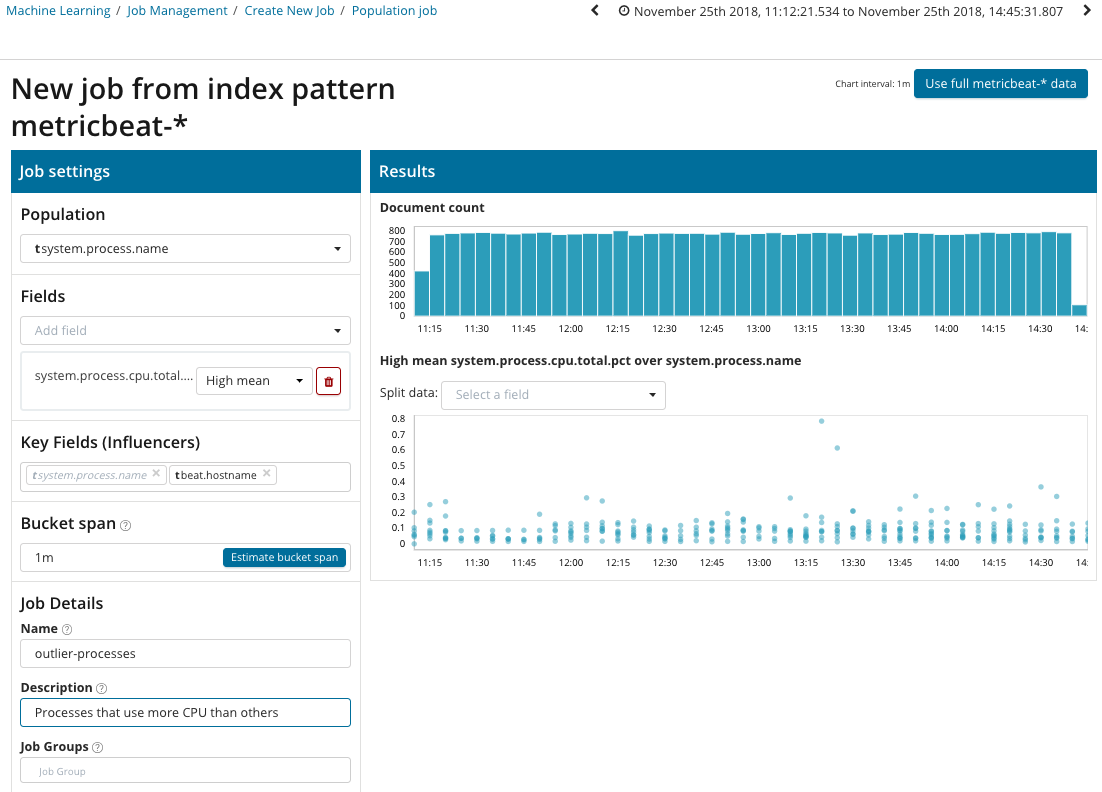
In dieser Abbildung gibt das Feld Population den Wert an, auf den sich die analysierten Metriken beziehen. Dies ist der Name des Prozesses. Als Ergebnis werden wir sehen, wie sich die Prozessorbelastung durch jeden der Prozesse gegenseitig beeinflusst.
Bitte beachten Sie, dass sich das Diagramm der analysierten Daten von den Fällen mit Single Metric und Multi Metric unterscheidet. Dies geschieht in Kibana, um die Wahrnehmung der Werteverteilung der analysierten Daten besser wahrzunehmen.

Die Grafik zeigt, dass sich der
Stressprozess (übrigens von einem speziellen Dienstprogramm generiert) auf dem
Poipu- Server
abnormal verhalten hat , was das Auftreten dieser Anomalie beeinflusst hat (oder sich als Einflussfaktor herausstellte).
Erweitert
Fein abgestimmte Analyse. Mit der erweiterten Analyse werden zusätzliche Einstellungen in Kibana angezeigt. Nachdem Sie auf der Kachel Erweitert auf das Menü Erstellen geklickt haben, wird ein solches Fenster mit Registerkarten angezeigt. Die Registerkarte Jobdetails wurde absichtlich übersprungen, da die Grundeinstellungen nicht direkt mit den Analyseeinstellungen zusammenhängen.
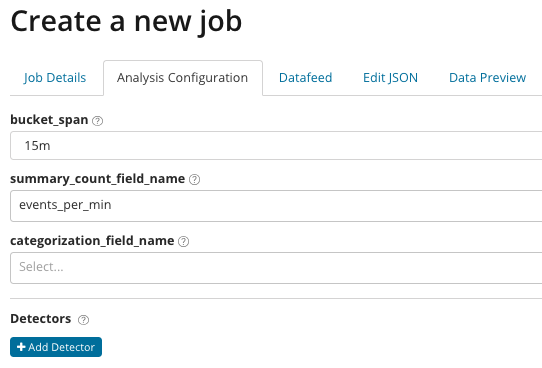
In
summary_count_field_name können Sie optional den Namen des Felds aus Dokumenten angeben, die aggregierte Werte enthalten. In diesem Beispiel die Anzahl der Ereignisse pro Minute. Der
Kategorisierungsfeldname gibt den Namen des Feldwerts aus dem Dokument an, der eine Art Variablenwert enthält. Durch Maske in diesem Feld können Sie die analysierten Daten in Teilmengen aufteilen. Achten Sie auf die Schaltfläche
Detektor hinzufügen in der vorherigen Abbildung. Unten sehen Sie das Ergebnis des Klickens auf diese Schaltfläche.

Hier ist ein zusätzlicher Einstellungsblock zum Einrichten des Anomaliedetektors für eine bestimmte Aufgabe. In den folgenden Artikeln planen wir, bestimmte Anwendungsfälle (insbesondere aus Sicherheitsgründen) zu analysieren.
Schauen Sie sich als Beispiel einen der zerlegten Fälle an. Es ist mit der Suche nach selten erscheinenden Werten verbunden und wird
von der seltenen Funktion implementiert.
Im
Funktionsfeld können Sie eine bestimmte Funktion auswählen, um nach Anomalien zu suchen. Zusätzlich zu den
seltenen gibt es einige interessante Funktionen -
time_of_day und time_of_week . Sie identifizieren Anomalien im Verhalten von Metriken während des Tages bzw. der Woche. Die restlichen Analysefunktionen
finden Sie in der Dokumentation .
Der
Feldname gibt das Feld des Dokuments an, das analysiert werden soll.
Mit By_field_name können Analyseergebnisse für jeden einzelnen Wert des hier angegebenen Dokumentfelds getrennt werden. Wenn Sie
over_field_name eingeben, erhalten Sie die Populationsanalyse, die wir oben untersucht haben. Wenn Sie in
partition_field_name einen Wert angeben, werden in diesem Dokumentfeld einzelne Basislinien für jeden Wert berechnet (z. B. kann der Name des Servers oder der Prozess auf dem Server die Rolle des Werts spielen). In
exclude_frequent können Sie
alle oder
keine auswählen. Dies
bedeutet, dass häufig vorkommende Dokumentfeldwerte ausgeschlossen (oder eingeschlossen) werden.
In dem Artikel haben wir versucht, eine möglichst präzise Vorstellung von den Möglichkeiten des maschinellen Lernens in Elastic Stack zu vermitteln. Hinter den Kulissen stecken noch viele Details. Sagen Sie uns in den Kommentaren, welche Fälle Sie mit Hilfe von Elastic Stack gelöst haben und für welche Aufgaben Sie es verwenden. Um mit uns in Kontakt zu treten, können Sie persönliche Nachrichten auf Habré oder das
Feedback-Formular auf der Website verwenden .