Ich mache Sie auf eine Übersetzung des Berichts von Alexander Kuzmenko (seit April dieses Jahres arbeitet er offiziell als Entwickler des Haxe-Compilers) über Änderungen in der Haxe-Sprache aufmerksam, die seit der Veröffentlichung von Haxe 3.4 aufgetreten sind.

Mehr als zweieinhalb Jahre sind seit der Veröffentlichung von Haxe 3.4 vergangen. In dieser Zeit wurden 7 Patch-Releases, 5 Preview-Releases von Haxe 4 und 2 Release-Kandidaten von Haxe 4 veröffentlicht. Die neue Version war weit entfernt und fast fertig ( etwa 20 Probleme müssen noch gelöst werden).

Alexander dankte der Haxe-Community für die Meldung von Fehlern und für ihren Wunsch, an der Entwicklung der Sprache teilzunehmen. Dank des Haxe-Evolution-Projekts werden in Haxe 4 folgende Dinge angezeigt:
- Inline-Markup
- Inlining-Funktionen am Anrufort
- Pfeilfunktionen

Im Rahmen dieses Projekts werden auch mögliche Innovationen diskutiert, wie z. B.: Versprechen , polymorphes dies und Standardtypen (Standardtypparameter).
Als nächstes sprach Alexander über die Änderungen in der Syntax der Sprache .

Die erste ist die neue Syntax zur Beschreibung der Syntax von Funktionstypen. Die alte Syntax war etwas seltsam.
Haxe ist eine Multi-Paradigma-Programmiersprache, die immer erstklassige Funktionen unterstützt, aber die Syntax zur Beschreibung von Funktionstypen wurde von einer funktionalen Sprache geerbt (und unterscheidet sich von der in anderen Paradigmen verwendeten). Programmierer, die mit der funktionalen Programmierung vertraut sind, erwarten, dass Funktionen mit dieser Syntax das automatische Currying unterstützen. Aber in Haxe ist das nicht so.
Der Hauptnachteil der alten Syntax ist laut Alexander die Unfähigkeit, die Namen der Argumente zu bestimmen, weshalb Sie lange Annotationskommentare mit einer Beschreibung der Argumente schreiben müssen.
Aber jetzt haben wir eine neue Syntax zur Beschreibung von Funktionstypen (die übrigens im Rahmen der Haxe-Evolution-Initiative zur Sprache hinzugefügt wurden), bei der eine solche Möglichkeit besteht (obwohl dies optional, aber empfohlen ist). Die neue Syntax ist einfacher zu lesen und kann sogar als Teil der Dokumentation für den Code betrachtet werden.
Ein weiterer Nachteil der alten Syntax zur Beschreibung von Funktionstypen war ihre Inkonsistenz - die Notwendigkeit, den Typ der Funktionsargumente anzugeben, auch wenn die Funktion keine Argumente akzeptiert: Void->Void (diese Funktion akzeptiert keine Argumente und gibt nichts zurück).
In der neuen Syntax wird dies eleganter implementiert: ()->Void

Das zweite sind Pfeilfunktionen oder Lambda-Ausdrücke - eine Kurzform zur Beschreibung anonymer Funktionen. Die Community hat lange darum gebeten, sie der Sprache hinzuzufügen, und schließlich ist es passiert!
In solchen Funktionen wird anstelle des Schlüsselworts return die Zeichenfolge -> (daher lautet der Syntaxname "Pfeilfunktion").
In der neuen Syntax bleibt es möglich, die Argumenttypen festzulegen (da das automatische Typinferenzsystem dies nicht immer so tun kann, wie es der Programmierer wünscht, kann der Compiler beispielsweise Float anstelle von Int ).
Die einzige Einschränkung der neuen Syntax besteht darin, dass der Rückgabetyp nicht explizit festgelegt werden kann. Bei Bedarf haben Sie die Wahl, entweder die alte Syntax oder die Check-Type-Syntax im Hauptteil der Funktion zu verwenden, die dem Compiler den Rückgabetyp mitteilt.

Pfeilfunktionen haben keine spezielle Darstellung im Syntaxbaum, sondern werden wie normale anonyme Funktionen verarbeitet. Die Sequenz -> wird durch das Schlüsselwort return .

Die dritte Änderung - final nun zu einem Schlüsselwort (in Haxe 3 war final eines der im Compiler integrierten Meta-Tags).
Wenn Sie es auf eine Klasse anwenden, wird die Vererbung von dieser Klasse verboten. Gleiches gilt für Schnittstellen. Durch Anwenden des final Qualifikationsmerkmals auf eine Klassenmethode wird verhindert, dass es in untergeordneten Klassen überschrieben wird.
In Haxe gab es jedoch eine Möglichkeit, die durch das final Schlüsselwort auferlegten Einschränkungen zu umgehen. Sie können hierfür das Meta-Tag @:hack (dies sollte jedoch nur erfolgen, wenn dies unbedingt erforderlich ist).
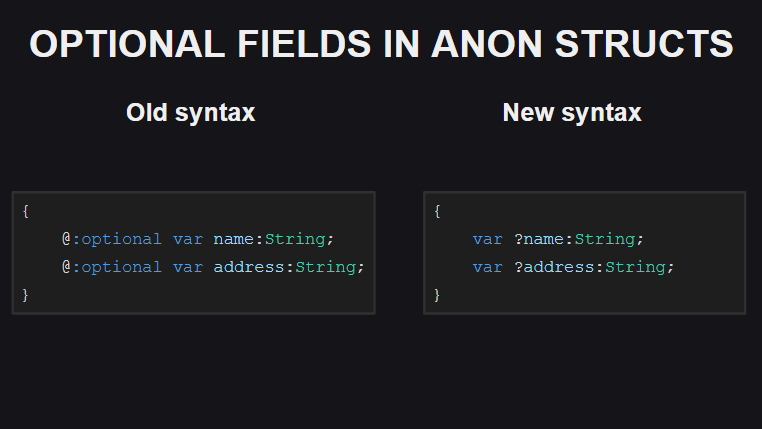
Die vierte Änderung ist eine Möglichkeit, optionale Felder in anonymen Strukturen zu deklarieren. Bisher wurde hierfür das @:optional Meta-Tag @:optional jetzt einfach ein Fragezeichen vor dem Feldnamen ein.

Fünftens sind abstrakte Aufzählungen zu einem vollständigen Mitglied der Haxe-Typfamilie geworden, und anstelle des Meta-Tags @:enum Schlüsselwort @:enum jetzt verwendet, um sie zu deklarieren.
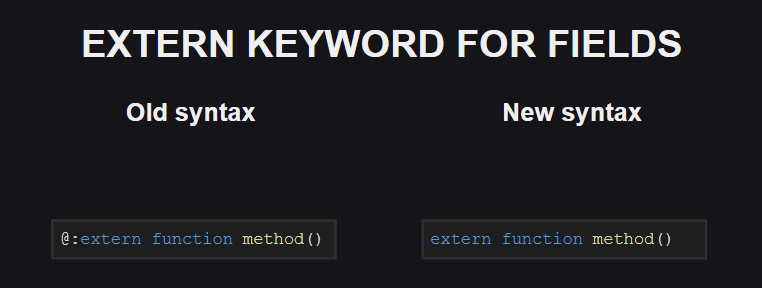
Eine ähnliche Änderung betraf das Meta-Tag @:extern .

Seventh ist eine neue Typ-Schnittpunktsyntax, die die Essenz expandierender Strukturen besser widerspiegelt.
Dieselbe neue Syntax wird verwendet, um Einschränkungen für Typparameter zu begrenzen. Sie vermittelt die Einschränkungen, die einem Typ auferlegt wurden, genauer. Für eine Person, die mit Haxe nicht vertraut ist, könnte die alte Syntax MyClass<T:(Type1, Type2)> als Voraussetzung dafür angesehen werden, dass der Typ des Parameters T entweder Type1 oder Type2 . Die neue Syntax besagt ausdrücklich, dass T gleichzeitig Type1 und Type2 muss.
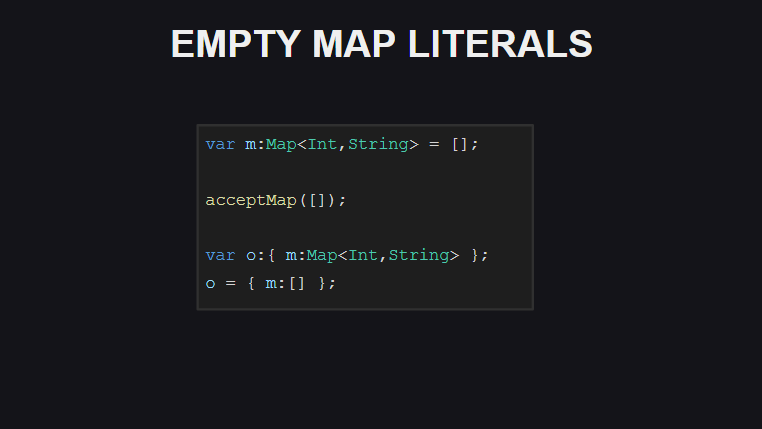
Das achte ist die Möglichkeit, mit [] einen leeren Map Container zu deklarieren (wenn Sie jedoch den Typ der Variablen nicht explizit angeben, gibt der Compiler den Typ für diesen Fall als Array aus).
Nachdem wir über die Änderungen in der Syntax gesprochen haben, fahren wir mit der Beschreibung neuer Funktionen in der Sprache fort .
Beginnen wir mit den neuen Schlüsselwert-Iteratoren
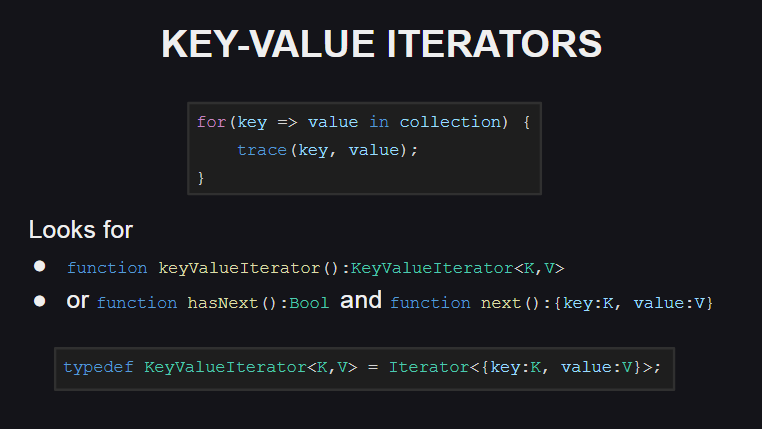
Für ihre Verwendung wurde eine neue Syntax hinzugefügt.
Um solche Iteratoren zu unterstützen, muss der Typ entweder die keyValueIterator():KeyValueIterator<K, V> -Methode implementieren keyValueIterator():KeyValueIterator<K, V> oder die hasNext():Bool -Methoden hasNext():Bool und next():{key:K, value:V} . Gleichzeitig ist der Typ KeyValueIterator<K, V> ein Synonym für einen regulären Iterator in der anonymen Struktur Iterator<{key:K, value:V}> .
Schlüsselwert-Iteratoren werden für einige Typen aus der Haxe-Standardbibliothek ( String , Map , DynamicAccess ) DynamicAccess , und es wird auch daran gearbeitet, sie für Arrays zu implementieren.
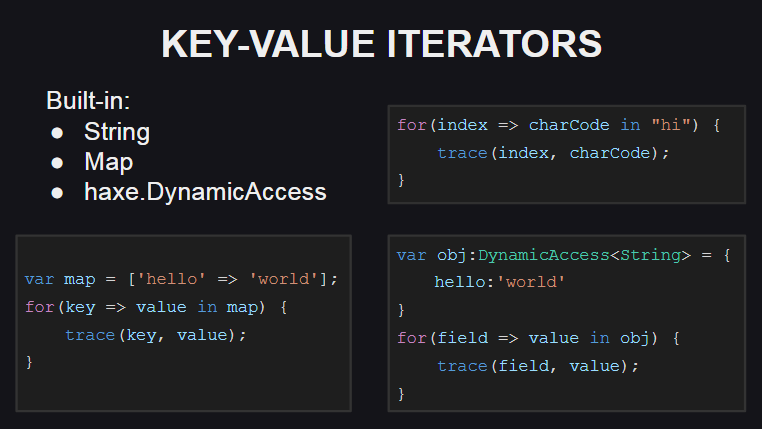
Bei Zeichenfolgen wird der Zeichenindex in der Zeichenfolge als Schlüssel verwendet, und der Zeichencode am angegebenen Index wird als Wert verwendet (wenn das Zeichen selbst benötigt wird, kann die Methode String.fromCharCode() verwendet werden).
Für den Map Container funktioniert der neue Iterator genauso wie die alte Iterationsmethode, dh er empfängt ein Array von Schlüsseln im Container und durchläuft diesen, wobei Werte für jeden der Schlüssel angefordert werden.
Bei DynamicAccess (einem Wrapper für anonyme Objekte) arbeitet der Iterator mit Reflection (um eine Liste der Felder eines Objekts mit der Reflect.fields() -Methode Reflect.fields() und um Feldwerte anhand ihrer Namen mit der Reflect.field() -Methode Reflect.field() ).

Haxe 4 verwendet einen völlig neuen Makrointerpreter, "eval". Simon Krajewski, der Autor des Dolmetschers, hat dies im offiziellen Blog von Haxe sowie in seinem letztjährigen Fortschrittsbericht ausführlich beschrieben .
Die wichtigsten Änderungen in der Arbeit des Dolmetschers:
- es ist um ein Vielfaches schneller als der alte Makrointerpreter (durchschnittlich viermal)
- unterstützt interaktives Debuggen (bisher konnte für Makros nur die Konsolenausgabe verwendet werden)
- es wird verwendet, um den Compiler im Interpreter-Modus auszuführen (zuvor wurde dafür neko verwendet. Übrigens übertrifft eval auch neko in der Geschwindigkeit).

Die Unicode-Unterstützung für alle Plattformen (mit Ausnahme von Neko) ist eine der größten Änderungen in Haxe 4. Simon hat letztes Jahr ausführlich darüber gesprochen. Hier ein kurzer Überblick über den aktuellen Stand der Unterstützung von Unicode-Zeichenfolgen in Haxe:
- Für Lua, PHP, Python und eval (Makrointerpreter) ist die vollständige Unicode-Unterstützung implementiert (UTF8-Codierung).
- Für andere Plattformen (JavaScript, C #, Java, Flash, HashLink und C ++) wird die UTF16-Codierung verwendet.
Daher funktionieren die Zeilen in Haxe für Zeichen, die in der mehrsprachigen Hauptebene enthalten sind , auf dieselbe Weise. Bei Zeichen außerhalb dieser Ebene (z. B. für Emoji) kann der Code für die Arbeit mit Zeilen je nach Plattform zu unterschiedlichen Ergebnissen führen (dies ist jedoch immer noch besser). als die Situation, die wir in Haxe 3 haben, als jede Plattform ihr eigenes Verhalten hatte).

Für Unicode-codierte Zeichenfolgen (sowohl in UTF8 als auch in UTF16) wurden der Haxe-Standardbibliothek spezielle Iteratoren hinzugefügt, die auf ALLEN Plattformen für alle Zeichen (sowohl innerhalb der mehrsprachigen Hauptebene als auch darüber hinaus) gleichermaßen funktionieren:
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

Aufgrund der Tatsache, dass die Implementierung von Zeichenfolgen von Plattform zu Plattform unterschiedlich ist, müssen einige Nuancen ihrer Arbeit berücksichtigt werden. In UTF16 benötigt jedes Zeichen 2 Bytes, sodass der Zugriff auf ein Zeichen in einer Zeichenfolge nach Index schnell erfolgt, jedoch nur innerhalb der mehrsprachigen Hauptebene. Auf der anderen Seite werden in UTF8 alle Zeichen unterstützt, dies wird jedoch auf Kosten einer langsamen Suche nach einem Zeichen in einer Zeichenfolge erreicht (da Zeichen eine unterschiedliche Anzahl von Bytes im Speicher belegen können, muss für den Zugriff auf ein Zeichen per Index jedes Mal von Anfang an durch die Zeile iteriert werden). Wenn Sie mit großen Zeichenfolgen in Lua und PHP arbeiten, müssen Sie daher berücksichtigen, dass der Zugriff auf ein beliebiges Zeichen sehr langsam funktioniert (auch auf diesen Plattformen wird die Zeichenfolgenlänge jedes Mal neu berechnet).
Obwohl für Python die vollständige Unicode-Unterstützung deklariert ist, gilt diese Einschränkung nicht für Python, da die darin enthaltenen Zeilen etwas anders implementiert sind: Für Zeichen in der mehrsprachigen Hauptebene wird die UTF16-Codierung verwendet, und für breitere Zeichen (3 und mehr Bytes) Python verwendet UTF32.
Für den eval-Makrointerpreter sind zusätzliche Optimierungen implementiert: Die Zeichenfolge „weiß“, ob sie Unicode-Zeichen enthält. Falls es keine solchen Zeichen enthält, wird die Zeichenfolge so interpretiert, dass sie aus ASCII-Zeichen besteht (wobei jedes Zeichen 1 Byte benötigt). Der sequentielle Zugriff per Index in eval wird ebenfalls optimiert: Die Position des zuletzt aufgerufenen Zeichens wird in der Zeile zwischengespeichert. Wenn Sie sich also zuerst dem 10. Zeichen in der Zeichenfolge zuwenden, wird eval beim nächsten Umdrehen des 20. Zeichens nicht vom Anfang der Zeile an, sondern ab dem 10. Zeichen danach suchen. Außerdem wird die Zeichenfolgenlänge in eval zwischengespeichert, dh sie wird nur bei der ersten Anforderung berechnet.
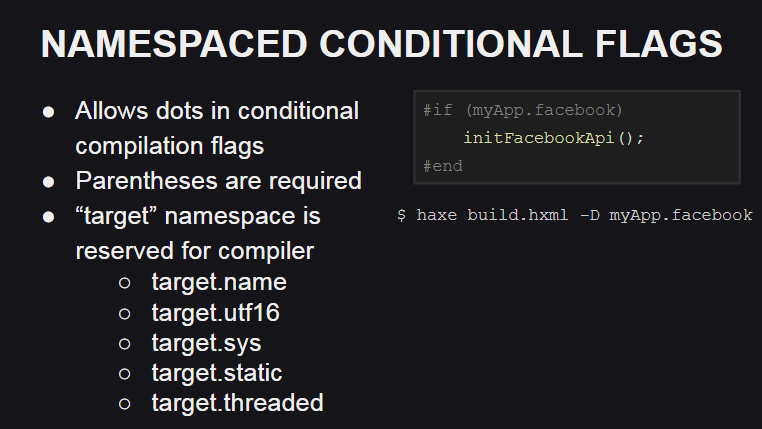
In Haxe 4 werden Namespaces für Kompilierungsflags unterstützt, die beispielsweise zum Organisieren von Code beim Schreiben benutzerdefinierter Bibliotheken hilfreich sein können.
Außerdem wurde ein reservierter Namespace für Kompilierungsflags angezeigt - target , der vom Compiler verwendet wird, um die Zielplattform und ihr Verhalten zu beschreiben:
target.name - Plattformname (js, cpp, php usw.)target.utf16 - sagt, dass die Unicode-Unterstützung mit target.utf16 implementiert wirdtarget.sys - target.sys an, ob Klassen aus dem sys-Paket verfügbar sind (z. B. um mit dem Dateisystem zu arbeiten).target.static - target.static an, ob die Plattform statisch ist (auf statischen Plattformen dürfen die Basistypen Int , Float und Bool nicht null als Wert haben).target.threaded - target.threaded an, ob die Plattform Multithreading unterstützt
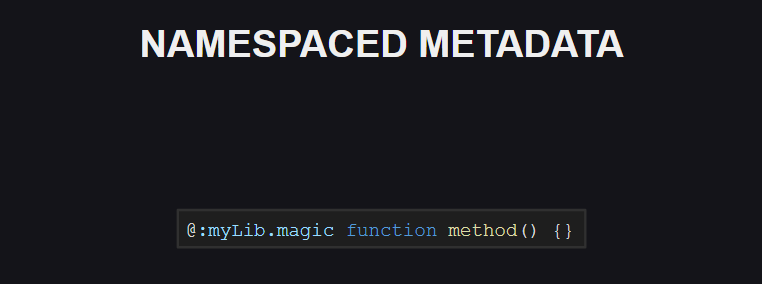
In ähnlicher Weise wurde die Namespace-Unterstützung für Meta-Tags angezeigt. Bisher gibt es keine reservierten Namespaces für Meta-Tags in der Sprache, aber die Situation kann sich in Zukunft ändern.

Der ReadOnlyArray Typ ReadOnlyArray der Haxe-Standardbibliothek hinzugefügt - eine Abstraktion über ein reguläres Array, in der nur Methoden zum Lesen von Daten aus dem Array verfügbar sind.

Eine weitere Neuerung in der Sprache sind Endfelder und lokale Variablen.
Wenn beim Deklarieren eines Klassenfelds oder einer lokalen Variablen final anstelle des Schlüsselworts var wird, bedeutet dies, dass das angegebene Feld oder die angegebene Variable nicht neu zugewiesen werden kann (wenn der Compiler dies versucht, wird ein Fehler ausgegeben). Gleichzeitig kann der Status geändert werden, sodass das endgültige Feld oder die endgültige Variable keine Konstante ist.
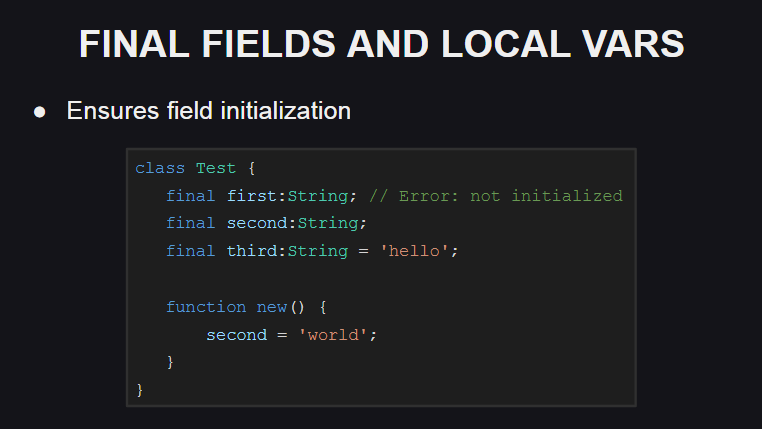
Die Werte der endgültigen Felder müssen entweder beim Deklarieren oder im Konstruktor initialisiert werden, da sonst der Compiler einen Fehler auslöst.

HashLink ist eine neue Plattform mit einer eigenen virtuellen Maschine, die speziell für Haxe entwickelt wurde. HashLink unterstützt die sogenannte „Dual Compilation“ - der Code kann entweder in Bytecode (der sehr schnell ist, den Debugging-Prozess entwickelter Anwendungen beschleunigt) oder in C-Code (der sich durch eine höhere Leistung auszeichnet) kompiliert werden. Nicholas widmete HashLink mehreren Haxe-Blog-Posts und sprach auf der letztjährigen Konferenz in Seattle über ihn. Die HashLink-Technologie wird in beliebten Spielen wie Dead Cells und Northgard verwendet.

Ein weiteres neues interessantes Merkmal von Haxe 4 ist die Null-Sicherheit, die sich noch im Versuchsstadium befindet (aufgrund von Fehlalarmen und unzureichenden Codesicherheitsprüfungen).
Was ist Nullsicherheit? Wenn Ihre Funktion nicht explizit deklariert, dass sie null als Parameterwerte akzeptieren kann, gibt der Compiler den entsprechenden Fehler aus, wenn Sie versuchen, null an sie zu übergeben. Darüber hinaus müssen Sie für Funktionsparameter, deren Wert null kann, vom Compiler zusätzlichen Code schreiben, um solche Fälle zu überprüfen und zu behandeln.
Diese Funktion ist standardmäßig deaktiviert, hat jedoch keinen Einfluss auf die Geschwindigkeit der Codeausführung (sofern Sie sie dennoch aktivieren), da die beschriebenen Überprüfungen nur in der Kompilierungsphase durchgeführt werden. Es kann für den gesamten Code sowie schrittweise für einzelne Felder, Klassen und Pakete aktiviert werden (wodurch ein schrittweiser Übergang zu einem sichereren Code ermöglicht wird). Hierfür können Sie spezielle Meta-Tags und Makros verwenden.
Die Modi, in denen Null-Sicherheit funktionieren kann, sind: Strict (am strengsten), Loose (der Standardmodus) und Off (zum Deaktivieren von Überprüfungen für einzelne Pakete und Typen).

Für die auf der Folie gezeigte Funktion ist die Null-Sicherheitsprüfung aktiviert. Wir sehen, dass diese Funktion einen optionalen Parameter s , dh wir können null als Parameterwert übergeben. Beim Versuch, Code mit einer solchen Funktion zu kompilieren, erzeugt der Compiler eine Reihe von Fehlern:
- beim Versuch, auf ein Feld des Objekts
s zuzugreifen (da es möglicherweise null ) - beim Versuch, eine Variable str zuzuweisen, die, wie wir sehen, nicht
null (andernfalls hätten wir sie nicht als String , sondern als Null<String> deklarieren sollen) - beim Versuch, ein Objekt
s von einer Funktion zurückzugeben (da die Funktion nicht null )
Wie können diese Fehler behoben werden?
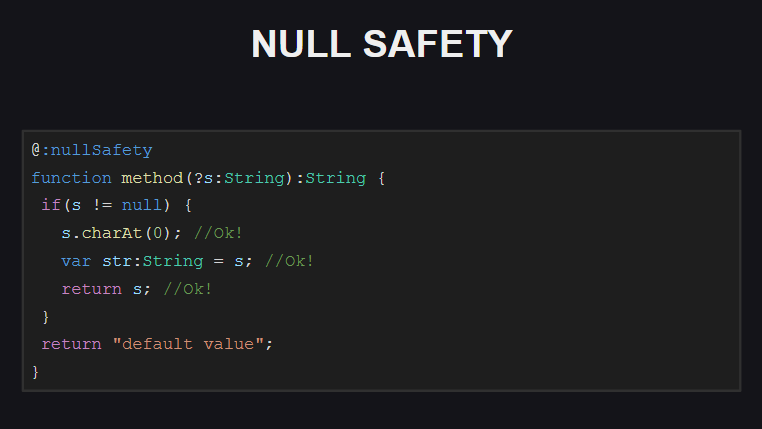
Wir müssen dem Code nur eine Nullprüfung hinzufügen (innerhalb des Blocks mit null „weiß“ der Compiler, dass s nicht null kann und sicher damit verwendet werden kann) und außerdem sicherstellen, dass die Funktion keine null !

Darüber hinaus berücksichtigt der Compiler bei der Überprüfung der Nullsicherheit die Reihenfolge, in der Programme ausgeführt werden. Wenn der Compiler beispielsweise nach dem Überprüfen des Werts des Parameters s auf null, um die Funktion zu beenden (oder eine Ausnahme auszulösen), „weiß“, dass der Parameter s nach einer solchen Überprüfung nicht mehr null kann und sicher verwendet werden kann.

Wenn der Compiler den strengen Überprüfungsmodus für die Nullsicherheit aktiviert, sind zusätzliche Überprüfungen für null erforderlich, wenn zwischen der ersten Überprüfung des Werts für null und dem Versuch, auf das Feld des Objekts zuzugreifen, ein Code ausgeführt wurde, der ihn auf null .
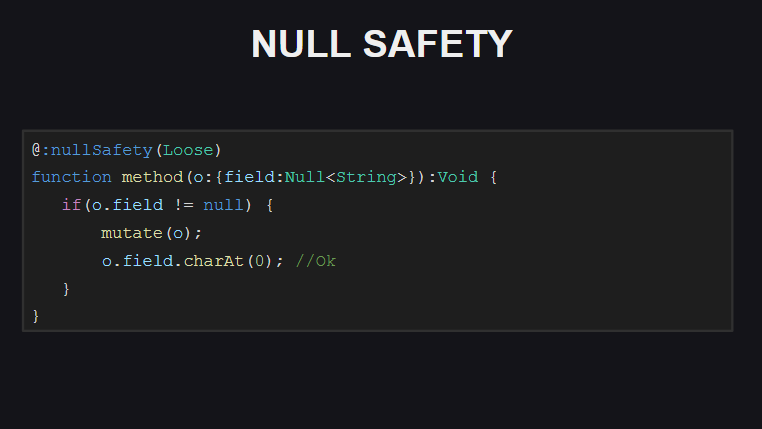
Im Loose-Modus (standardmäßig verwendet) benötigt der Compiler keine solchen Überprüfungen (dieses Verhalten wird übrigens auch standardmäßig in TypeScript verwendet).

Wenn die Prüfung auf Nullsicherheit aktiviert ist, prüft der Compiler außerdem, ob die Felder in den Klassen initialisiert sind (direkt bei der Deklaration oder im Konstruktor). Andernfalls gibt der Compiler beim Versuch, ein Objekt einer solchen Klasse zu übergeben, sowie beim Versuch, Methoden für solche Objekte aufzurufen, Fehler aus, bis alle Felder des Objekts initialisiert sind. Solche Überprüfungen können für einzelne Felder der Klasse @:nullSafety(Off) indem sie mit dem Meta-Tag @:nullSafety(Off) markiert werden.
Alexander hat letzten Oktober in Haxe mehr über Null-Sicherheit gesprochen .

In Haxe 4 wurde die Möglichkeit eingeführt, ES6-Klassen für JavaScript zu generieren. Die js-es=6 erfolgt über das Kompilierungsflag js-es=6 .
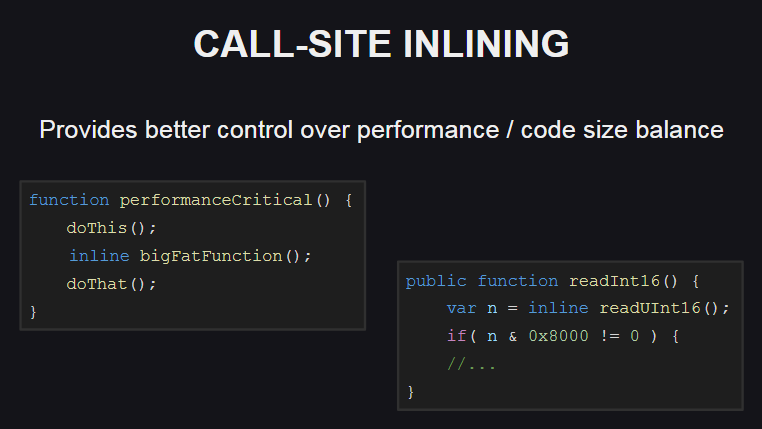
Das Einbetten von Funktionen am Ort eines Anrufs (Call-Site-Inlining) bietet mehr Optionen zum Steuern des Gleichgewichts zwischen Codeleistung und -größe. Diese Funktionalität wird auch in der Haxe-Standardbibliothek verwendet.
Wie ist sie Sie können den Funktionskörper (mit dem inline ) nur an den Stellen einbetten, an denen eine hohe Leistung gewährleistet werden muss (z. B. bei Bedarf eine ausreichend umfangreiche Methode in der Schleife aufrufen), während der Funktionskörper an anderen Stellen nicht eingebettet ist. Infolgedessen wird die Größe des generierten Codes geringfügig erhöht.
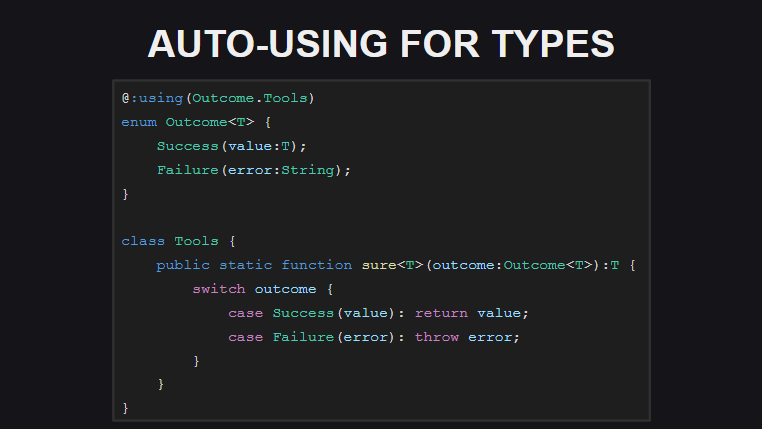
Automatische Verwendung (automatische Erweiterungen für Typen) bedeutet, dass Sie jetzt für Typen statische Erweiterungen an der Stelle der Typdeklaration deklarieren können. Dadurch entfällt die Notwendigkeit, jedes Mal das using type; Typkonstrukt zu verwenden using type; in jedem Modul, in dem Typ- und Erweiterungsmethoden verwendet werden. Momentan wird diese Art der Erweiterung nur für Übertragungen implementiert, aber in der endgültigen Version (und in nächtlichen Builds) kann sie nicht nur für Übertragungen verwendet werden.

In Haxe 4 kann der Operator für den Zugriff auf Felder eines Objekts für abstrakte Typen neu definiert werden (nur für Felder, die im Typ nicht vorhanden sind). Verwenden Sie dazu Methoden, die mit dem Meta-Tag @:op(ab) .

Das integrierte Markup ist ein weiteres experimentelles Feature in Haxe. Der integrierte Markup-Code wird vom Compiler nicht als XML-Dokument verarbeitet - der Compiler sieht ihn als Zeichenfolge, die in das Meta-Tag @:markup . .
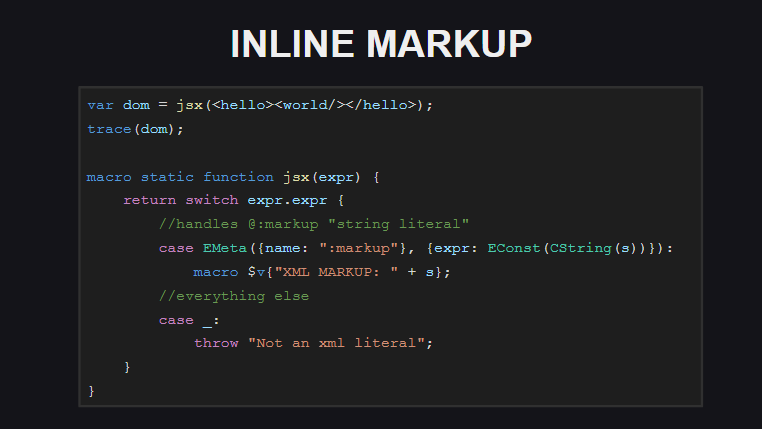
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
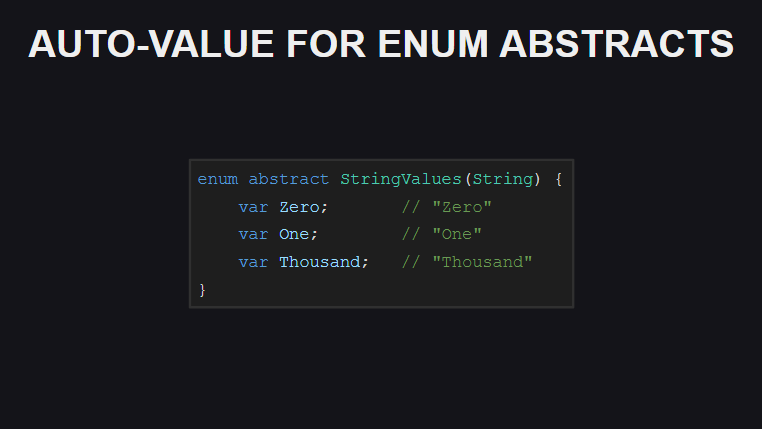
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !