
Heute werde ich darüber sprechen, wie die Idee, ein neues internes Netzwerk für unser Unternehmen zu schaffen, entstanden und umgesetzt wurde. Führungsposition - für sich selbst müssen Sie das gleiche vollwertige Projekt wie für den Kunden erstellen. Wenn wir es für uns selbst gut machen, können wir den Kunden einladen und zeigen, wie gut arrangiert und funktioniert, was wir ihm anbieten. Daher haben wir uns sehr gründlich mit der Entwicklung des Konzepts des neuen Netzwerks für das Moskauer Büro befasst und dabei den gesamten Produktionszyklus genutzt: Analyse der Anforderungen der Abteilungen → Auswahl der technischen Lösung → Design → Implementierung → Testen. Also los geht's.
Wahl der technischen Lösung: Reserve von Mutanten
Das Verfahren für die Arbeit an einem komplexen automatisierten System ist bisher am besten in GOST 34.601-90 „Automatisierte Systeme. Die Stadien der Schöpfung “, also haben wir daran gearbeitet. Und bereits in der Phase der Anforderungenstellung und der Entwicklung eines Konzepts stießen wir auf die ersten Schwierigkeiten. Organisationen verschiedener Profile - Banken, Versicherungsunternehmen, Softwareentwickler usw. - benötigen für ihre Aufgaben und Standards bestimmte Arten von Netzwerken, deren Einzelheiten klar und standardisiert sind. Dies wird jedoch bei uns nicht funktionieren.
Warum?
Jet Infosystems ist ein großes multidisziplinäres IT-Unternehmen. Gleichzeitig ist unsere interne Supportabteilung klein (aber stolz) und stellt die Verfügbarkeit grundlegender Dienste und Systeme sicher. Das Unternehmen umfasst viele Abteilungen, die unterschiedliche Funktionen ausführen: Es umfasst mehrere leistungsstarke Outsourcing-Teams, eigene Entwickler von Geschäftssystemen und Informationssicherheit sowie Architekten von Computerkomplexen - im Allgemeinen, wer auch immer nicht. Dementsprechend unterscheiden sich auch ihre Aufgaben, Systeme und Sicherheitsrichtlinien. Was erwartungsgemäß zu Schwierigkeiten bei der Bedarfsanalyse und deren Standardisierung führte.
Zum Beispiel die Entwicklungsabteilung: Ihre Mitarbeiter schreiben und testen Code für eine große Anzahl von Kunden. Oft besteht die Notwendigkeit, Testumgebungen schnell zu organisieren, und ehrlich gesagt ist es nicht immer möglich, dass jedes Projekt Anforderungen formuliert, Ressourcen anfordert und eine separate Testumgebung gemäß allen internen Vorschriften erstellt. Dies führt zu merkwürdigen Situationen: Sobald Ihr bescheidener Diener in den Entwicklerraum schaute und unter dem Tisch einen gut funktionierenden Hadoop-Cluster mit 20 Desktops fand, der unerklärlicherweise mit einem gemeinsamen Netzwerk verbunden war. Ich denke, es lohnt sich nicht anzugeben, dass die IT-Abteilung des Unternehmens nichts von seiner Existenz wusste. Dieser Umstand wurde, wie viele andere, zum Schuldigen der Tatsache, dass während der Entwicklung des Projekts der Begriff „Mutantenreserve“ geboren wurde, der den Zustand der leidenden Büroinfrastruktur beschreibt.
Oder hier ist ein anderes Beispiel. In regelmäßigen Abständen wird ein Prüfstand in einer Einheit aufgestellt. Dies war bei Jira und Confluence der Fall, die vom Software Development Center in einigen Projekten nur begrenzt verwendet wurden. Nach einiger Zeit wurden diese nützlichen Ressourcen in anderen Abteilungen herausgefunden, bewertet und Ende 2018 wechselten Jira und Confluence vom Status "lokaler Spielzeugprogrammierer" zum Status "Unternehmensressourcen". Nun sollte der Eigentümer diesen Systemen zugewiesen werden, SLAs, Zugriffs- / Sicherheitsrichtlinien, Sicherungsrichtlinien, Überwachungsrichtlinien und Routingregeln für die Fehlerbehebung bei Anwendungen sollten definiert werden. Im Allgemeinen sollten alle Attribute eines vollständigen Informationssystems vorhanden sein.
Jede unserer Einheiten ist auch ein Inkubator, der seine eigenen Produkte anbaut. Einige von ihnen sterben in der Entwicklungsphase, von denen wir einige während der Projektarbeit verwenden, während andere Wurzeln schlagen und zu replizierten Lösungen werden, die wir selbst anwenden und an Kunden verkaufen. Für jedes dieser Systeme ist es wünschenswert, eine eigene Netzwerkumgebung zu haben, in der es sich entwickelt, ohne andere Systeme zu stören, und irgendwann kann es in die Infrastruktur des Unternehmens integriert werden.
Neben der Entwicklung verfügen wir über ein sehr großes
Service-Center mit mehr als 500 Mitarbeitern, die für jeden Kunden zu Teams zusammengefasst sind. Sie befassen sich mit der Wartung von Netzwerken und anderen Systemen, der Fernüberwachung, der Abwicklung von Anwendungen usw. Das heißt, die Infrastruktur des
SC ist in der Tat die Infrastruktur des Kunden, mit dem er gerade arbeitet. Die Besonderheit bei der Arbeit mit diesem Teil des Netzwerks besteht darin, dass die Arbeitsplätze für unser Unternehmen teilweise extern und teilweise intern sind. Daher haben wir für SC den folgenden Ansatz implementiert: Das Unternehmen stellt der entsprechenden Einheit Netzwerk- und andere Ressourcen zur Verfügung, wobei die Workstations dieser Einheiten als externe Verbindungen betrachtet werden (ähnlich wie bei Zweigstellen und Remotebenutzern).
Autobahngestaltung: Wir sind der Betreiber (Überraschung)
Nachdem wir alle Fallstricke bewertet hatten, stellten wir fest, dass wir das Netzwerk eines Telekommunikationsbetreibers innerhalb eines Büros hatten, und begannen, entsprechend zu handeln.
Wir haben ein Backbone-Netzwerk erstellt, mit dessen Hilfe jeder interne und langfristig externe Verbraucher den erforderlichen Service erhält: L2 VPN, L3 VPN oder herkömmliches L3-Routing. Einige Abteilungen benötigen einen sicheren Internetzugang, während andere einen sauberen Zugang ohne Firewalls benötigen, jedoch mit dem Schutz unserer Unternehmensressourcen und des Kernnetzwerks vor ihrem Datenverkehr.
Mit jeder Abteilung haben wir informell „eine SLA abgeschlossen“. Dementsprechend sollten alle aufgetretenen Vorfälle in einem bestimmten, zuvor vereinbarten Zeitraum beseitigt werden. Die Anforderungen des Unternehmens an sein Netzwerk erwiesen sich als schwierig. Die maximale Reaktionszeit für Vorfälle bei Telefon- und E-Mail-Fehlern betrug 5 Minuten. Die Wiederherstellungszeit des Netzwerks bei typischen Ausfällen beträgt nicht mehr als eine Minute.
Da wir ein Carrier-Class-Netzwerk haben, können Sie nur in strikter Übereinstimmung mit den Regeln eine Verbindung herstellen. Serviceabteilungen legen Richtlinien fest und bieten Services an. Sie benötigen nicht einmal Informationen über die Verbindungen bestimmter Server, virtueller Maschinen und Workstations. Gleichzeitig sind jedoch Schutzmechanismen erforderlich, da keine Verbindung das Netzwerk deaktivieren sollte. Wenn andere Benutzer versehentlich eine Schleife erstellen, sollten sie dies nicht bemerken, dh eine angemessene Netzwerkantwort ist erforderlich. Jeder Telekommunikationsbetreiber löst ständig solche scheinbar komplexen Aufgaben in seinem Kernnetz. Es bietet Service für viele Kunden mit unterschiedlichen Anforderungen und Verkehr. Gleichzeitig sollten verschiedene Teilnehmer keine Unannehmlichkeiten durch den Verkehr anderer haben.
Zu Hause haben wir dieses Problem wie folgt gelöst: Wir haben ein einfaches L3-Netzwerk mit vollständiger Redundanz unter Verwendung des
IS-IS-Protokolls aufgebaut . Auf dem Backbone wurde mithilfe des
MP-BGP- Routing-
Protokolls ein Overlay-Netzwerk auf Basis der
EVPN /
VXLAN- Technologie aufgebaut. Um die Konvergenz der Routing-Protokolle zu beschleunigen, wurde die
BFD- Technologie verwendet.
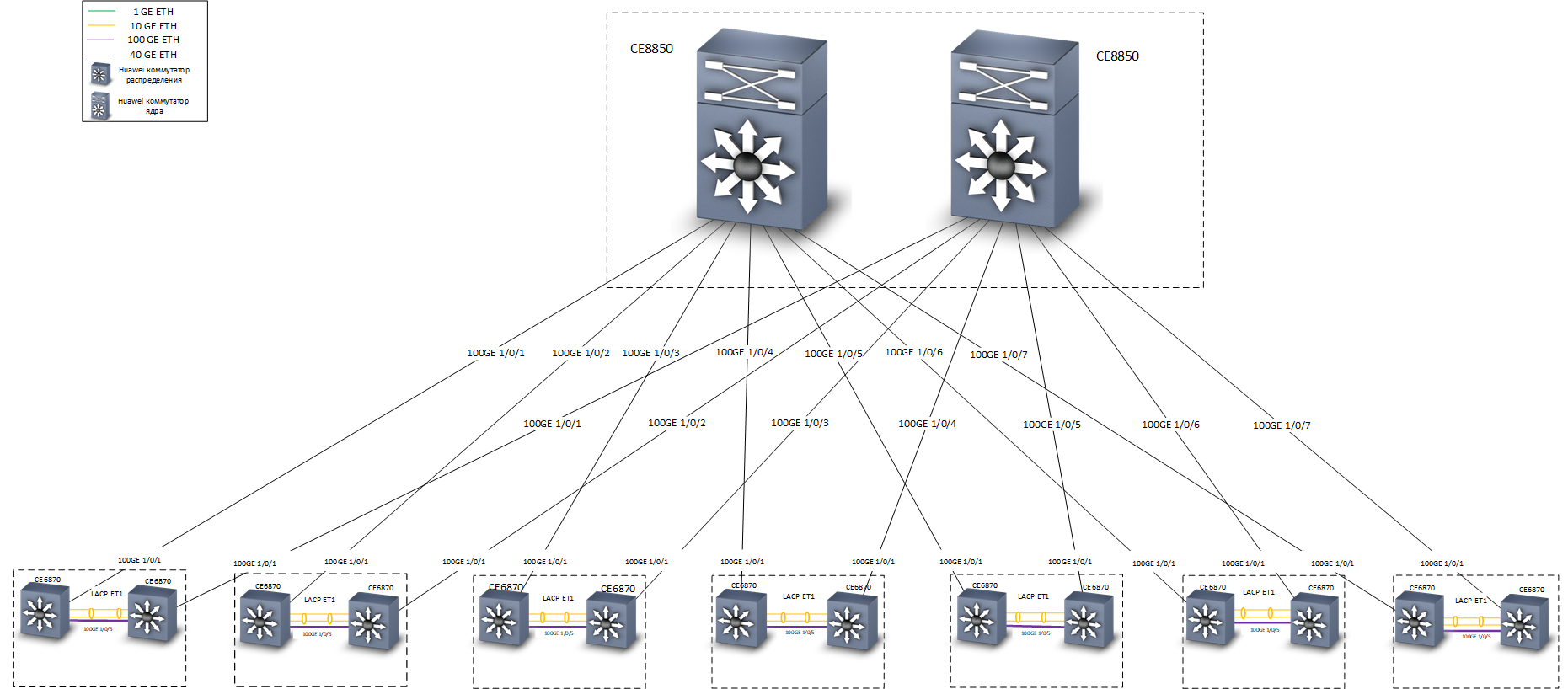 Netzwerkstruktur
NetzwerkstrukturIn Tests hat sich ein solches Schema als ausgezeichnet erwiesen - wenn ein Kanal oder ein Schalter ausgeschaltet ist, beträgt die Konvergenzzeit nicht mehr als 0,1 bis 0,2 s, ein Minimum an Paketen (oft keine) geht verloren, TCP-Sitzungen werden nicht unterbrochen, Telefongespräche werden nicht unterbrochen.
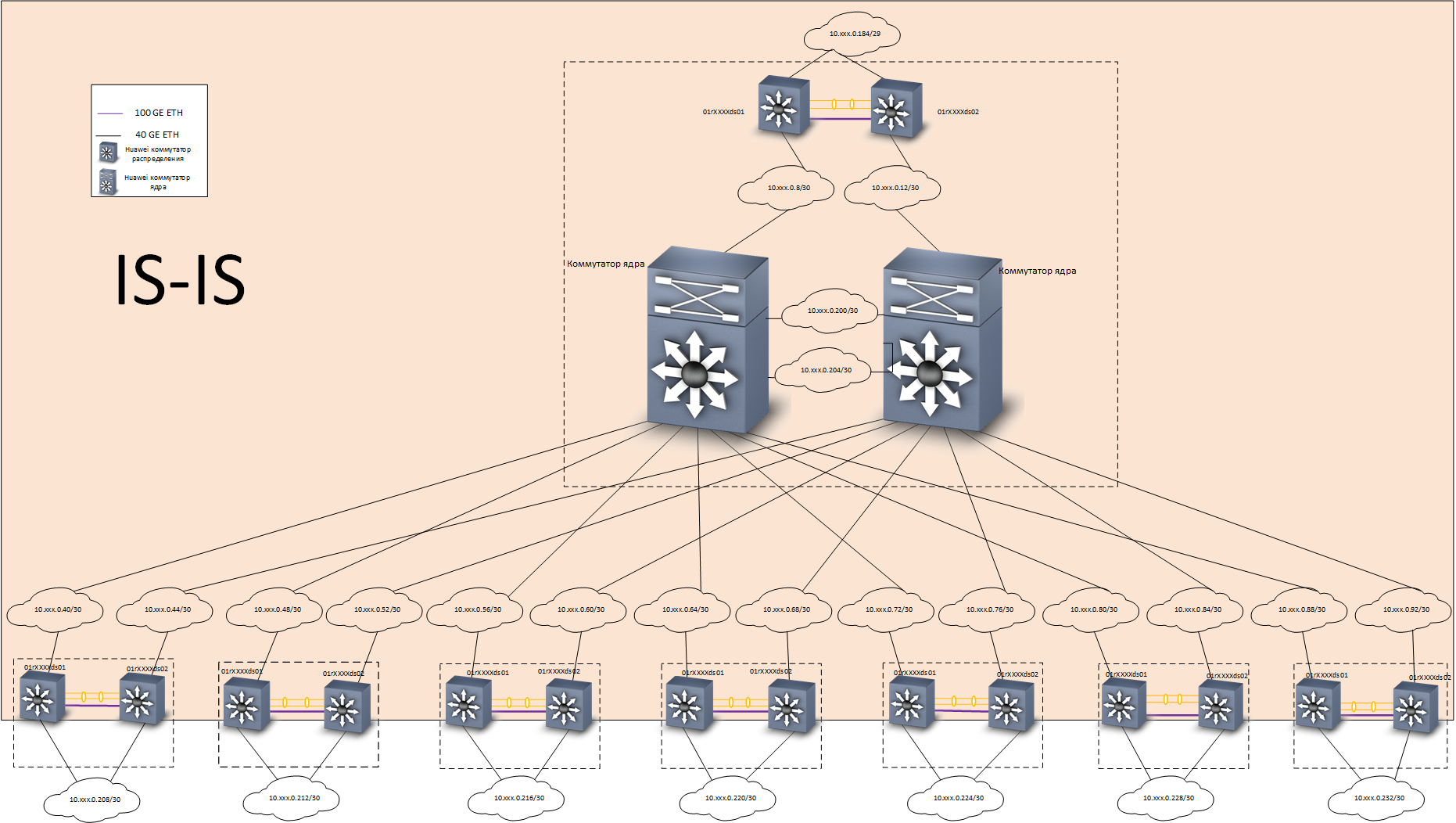 Unterlageebene - Routing
Unterlageebene - Routing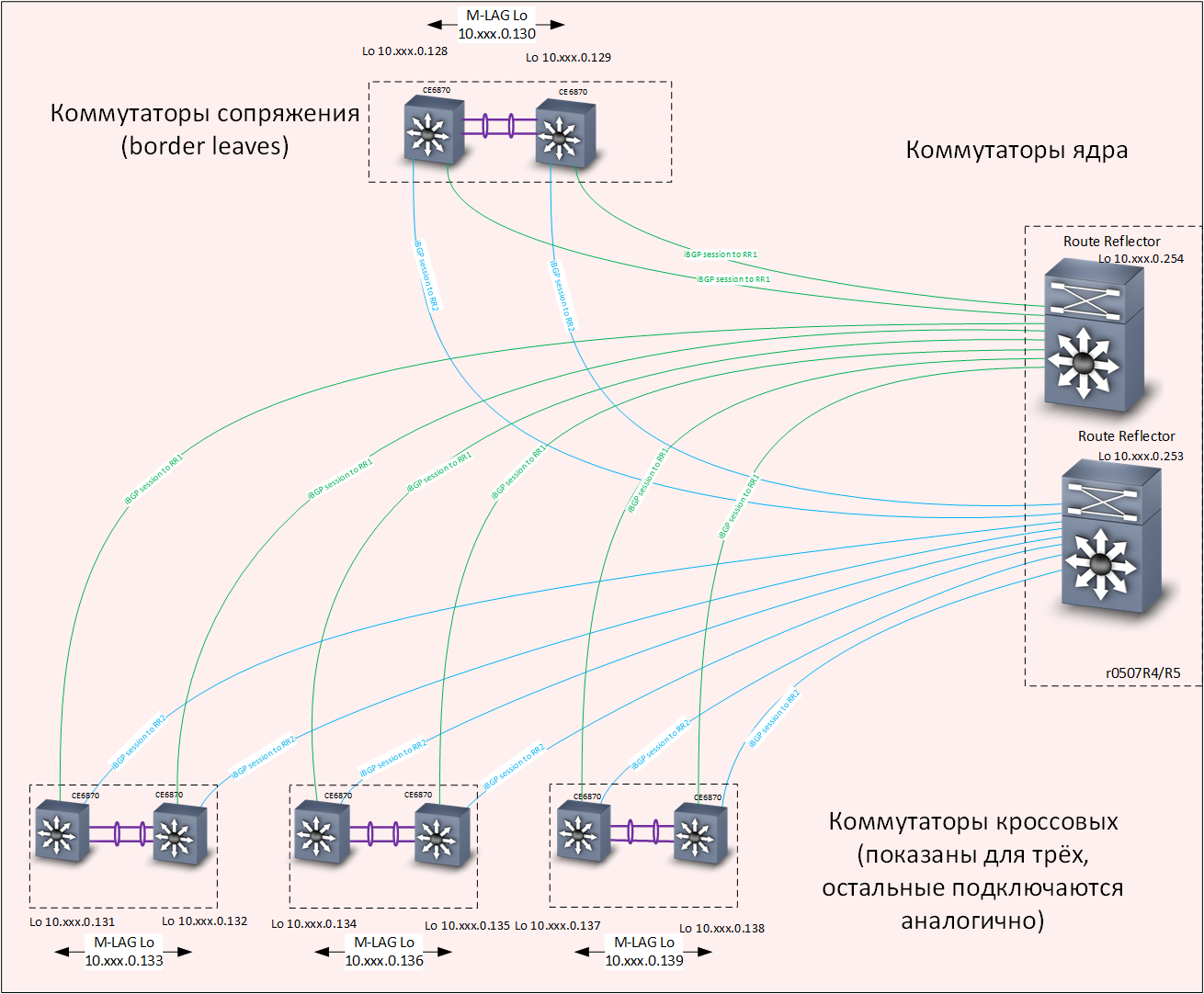 Ebenenüberlagerung - Routing
Ebenenüberlagerung - RoutingAls Distributions-Switches wurden Huawei CE6870-Switches mit VXLAN-Lizenzen verwendet. Dieses Gerät bietet eine optimale Kombination aus Preis und Qualität, ermöglicht es Ihnen, Teilnehmer mit einer Geschwindigkeit von 10 Gbit / s zu verbinden und abhängig von den verwendeten Transceivern eine Verbindung zum Trunk mit einer Geschwindigkeit von 40-100 Gbit / s herzustellen.
 Huawei CE6870 Schalter
Huawei CE6870 SchalterAls Kernschalter wurden Huawei CE8850-Schalter verwendet. Von der Aufgabe - schnell und zuverlässig Verkehr zu übertragen. Es sind keine Geräte mit ihnen verbunden, außer Verteilungs-Switches. Sie wissen nichts über VXLAN. Daher wurde ein Modell mit 32 40/100-Gbit / s-Ports ausgewählt, das über eine Basislizenz verfügt, die L3-Routing und Unterstützung für IS-IS- und MP-BGP-Protokolle bietet .
 Der niedrigste ist der Huawei CE8850 Core Switch
Der niedrigste ist der Huawei CE8850 Core SwitchIn der Entwurfsphase kam es im Team zu einer Diskussion über Technologien, mit denen Sie eine ausfallsichere Verbindung zu den Knoten des Kernnetzwerks implementieren können. Unser Moskauer Büro befindet sich in drei Gebäuden. Wir haben 7 Querräume, in denen jeweils zwei Huawei CE6870-Verteilungsschalter installiert waren (nur wenige Zugangsschalter wurden in mehreren Querräumen installiert). Bei der Entwicklung des Netzwerkkonzepts wurden zwei Sicherungsoptionen berücksichtigt:
- Das Kombinieren von Verteilungsschaltern zu einem ausfallsicheren Stapel in jedem Querraum. Vorteile: Einfachheit und einfache Einrichtung. Nachteile: Es besteht eine höhere Ausfallwahrscheinlichkeit des gesamten Stapels, wenn Fehler in der Firmware von Netzwerkgeräten auftreten ("Speicherlecks" und dergleichen).
- Wenden Sie M-LAG- und Anycast-Gateway-Technologien an, um Geräte mit Verteilungs-Switches zu verbinden.
Infolgedessen haben wir uns für die zweite Option entschieden. Es ist etwas schwieriger zu konfigurieren, aber in der Praxis hat es seine Leistung und hohe Zuverlässigkeit gezeigt.
Ziehen Sie in Betracht, zuerst Endgeräte an Verteilungsschalter anzuschließen:
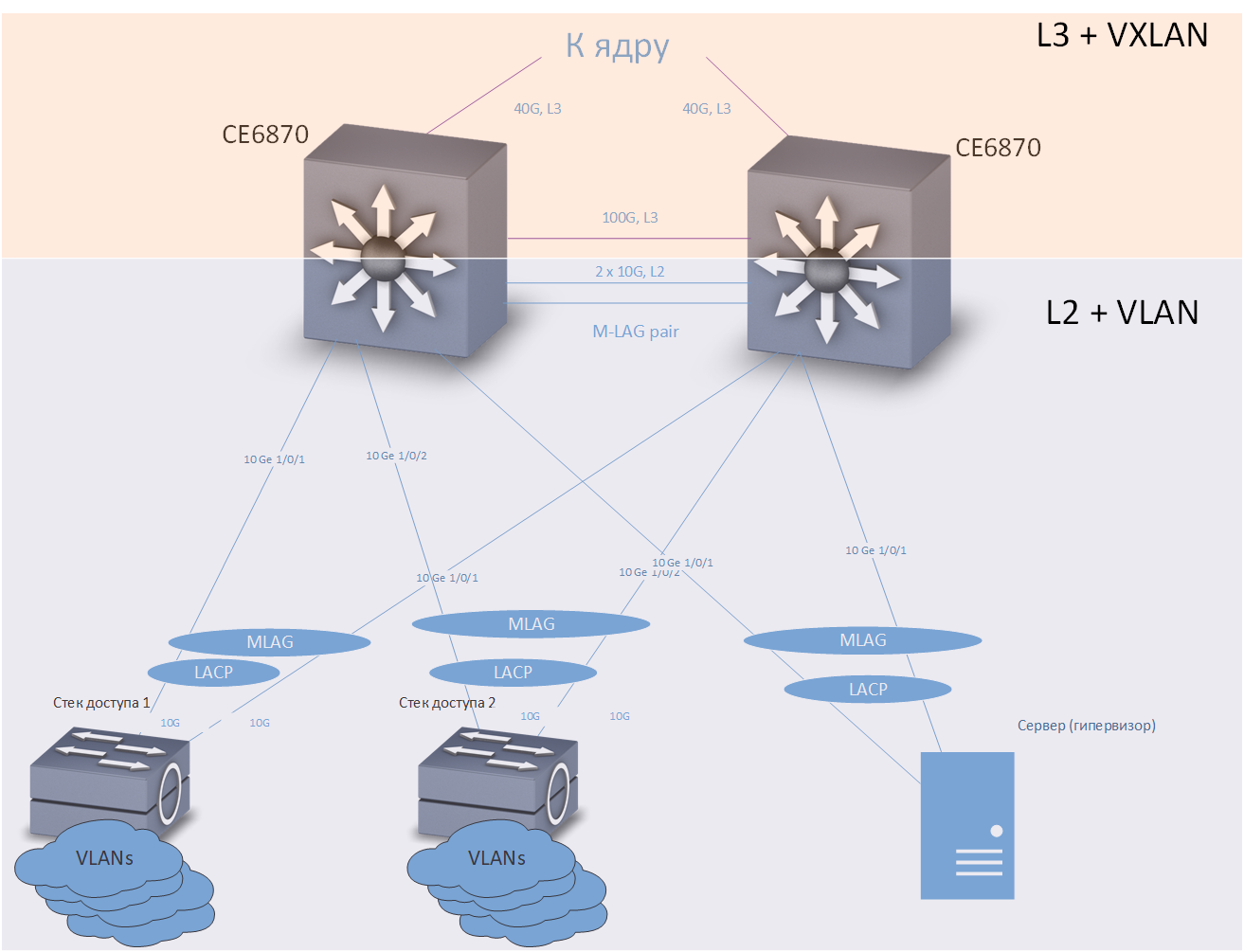 Kreuz
KreuzEin Zugriffsschalter, ein Server oder ein anderes Gerät, für das eine Failover-Verbindung erforderlich ist, ist in zwei Verteilungsschaltern enthalten. Die M-LAG-Technologie bietet Verbindungsredundanz. Es wird angenommen, dass zwei Verteilungsschalter für die angeschlossenen Geräte wie ein Gerät aussehen. Redundanz und Lastausgleich werden mithilfe des LACP-Protokolls durchgeführt.
Die Anycast-Gateway-Technologie bietet Redundanz auf Netzwerkebene. Jeder Verteilungsschalter ist mit einer ausreichend großen Anzahl von VRFs konfiguriert (jeder VRF ist für seine eigenen Zwecke konzipiert - separat für „normale“ Benutzer, separat für Telefonie, separat für verschiedene Test- und Entwicklungsumgebungen usw.) und in jedem VRF hat mehrere VLANs konfiguriert. In unserem Netzwerk sind Verteilungsschalter die Standardgateways für alle mit ihnen verbundenen Geräte. Die den VLANs entsprechenden IP-Adressen sind für beide Verteilungs-Switches gleich. Der Verkehr wird über die nächste Vermittlungsstelle geleitet.
Ziehen Sie nun in Betracht, die Verteilungsschalter mit dem Kernel zu verbinden:
Die Fehlertoleranz wird auf Netzwerkebene gemäß dem IS-IS-Protokoll bereitgestellt. Bitte beachten Sie, dass zwischen den Schaltern eine separate L3-Kommunikationsleitung mit einer Geschwindigkeit von 100 G vorgesehen ist. Bei dieser Kommunikationsleitung handelt es sich physisch um ein Direktzugriffskabel. Sie ist rechts auf dem Foto der Huawei CE6870-Switches zu sehen.
Eine Alternative wäre, eine „ehrliche“, vollständig verbundene Doppelsterntopologie zu organisieren. Wie oben erwähnt, haben wir jedoch 7 Querräume in drei Gebäuden. Wenn wir uns also für die Doppelstern-Topologie entscheiden würden, würden wir genau doppelt so viele 40G-Langstrecken-Transceiver benötigen. Die Einsparungen sind hier sehr erheblich.
Ich muss ein paar Worte darüber sagen, wie VXLAN- und Anycast-Gateway-Technologien zusammenarbeiten. VXLAN ist ein Tunnel zum Transportieren von Ethernet-Frames innerhalb von UDP-Paketen, wenn nicht auf Details eingegangen wird. Die Loopback-Schnittstellen der Verteilungs-Switches werden als Ziel-IP-Adresse des VXLAN-Tunnels verwendet. Jeder Switch verfügt über zwei Switches mit jeweils denselben Loopback-Schnittstellenadressen. Ein Paket kann zu jedem von ihnen kommen, und ein Ethernet-Frame kann daraus extrahiert werden.
Wenn der Switch die Ziel-MAC-Adresse des extrahierten Frames kennt, wird der Frame korrekt an sein Ziel geliefert. Der M-LAG-Mechanismus, der die Synchronisation von MAC-Adresstabellen (sowie ARP-Tabellen) auf beiden ermöglicht, ist dafür verantwortlich, dass beide in einem Kreuz installierten Verteilungs-Switches über aktuelle Informationen zu allen MAC-Adressen verfügen, die von Access-Switches ankommen. M-LAG-Paarschalter.
Der Verkehrsausgleich wird durch das Vorhandensein mehrerer Routen zu den Loopback-Schnittstellen von Verteilungsschaltern im Unterlagennetz erreicht.
Anstelle einer Schlussfolgerung
Wie oben erwähnt, zeigte das Netzwerk während des Testens und im Betrieb eine hohe Zuverlässigkeit (Wiederherstellungszeit für typische Ausfälle nicht mehr als Hunderte von Millisekunden) und eine gute Leistung - jeder über zwei Kanäle mit 40 Gbit / s mit dem Kern vernetzt. Zugangsschalter in unserem Netzwerk sind gestapelt und über LACP / M-LAG mit zwei 10-Gbit / s-Kanälen mit den Verteilungsschaltern verbunden. Der Stack verfügt normalerweise über 5 Switches mit jeweils 48 Ports. In jedem Cross sind bis zu 10 Access Stacks mit der Distribution verbunden. Somit liefert das Backbone selbst bei maximaler theoretischer Belastung etwa 30 Mbit / s pro Benutzer, was zum Zeitpunkt des Schreibens für alle unsere praktischen Anwendungen ausreicht.
Das Netzwerk ermöglicht es Ihnen, das Pairing beliebig verbundener Geräte sowohl über L2 als auch über L3 einfach zu organisieren und so eine vollständige Isolierung des Datenverkehrs (der dem Informationssicherheitsdienst gefällt) und der Fehlerdomänen (der dem Betriebsdienst gefällt) bereitzustellen.
Im
nächsten Teil werden wir beschreiben, wie wir in ein neues Netzwerk migriert sind. Bleib dran!
Maxim Klochkov
Senior Consultant, Netzwerkaudit und integrierte Projekte
Network Solution Center
Jet Infosystems