
Suchmaschinen haben nicht viel Logik, das ist eine Tatsache. Aber sie versuchen es. Und SEO-Spezialisten versuchen zu reagieren - sie versuchen, die maximale Relevanz der Seiten zu erreichen, basierend auf Vermutungen und Experimenten.
Google hat kürzlich einen neuen Ranking-Faktor veröffentlicht - Neural Matching. Wir haben gelesen, dass Experten darüber schreiben, und einige Tricks gesammelt, mit denen Sie relevantere Texte für Anfragen schreiben können.
Übrigens ist NM kein LSI für Sie, es ist etwas komplizierter.
Im September 2018 twitterte Danny Sullivan , dass Google in den letzten Monaten die AI Neural Matching-Methode verwendet habe, um Wörter besser mit Konzepten zu verknüpfen. Dieser Algorithmus beeinflusste die Ergebnisse von 30% der Anfragen weltweit.

Wir hatten es nicht eilig, über den neuen Algorithmus zu schreiben, wir warteten auf Klarstellungen von Google und Forschung in diesem Bereich. Aber die Dinge sind immer noch da - meistens zeigen Kommentatoren dieselben Screenshots und sprechen über den Übergang von der Suche nach Wörtern zur Suche nach Absicht. Sie beziehen sich auch auf das Deep Relevance Matching Model (DRMM) .
Versuchen wir herauszufinden, um welche Art von Tier es sich bei diesem neuronalen Matching handelt und wie der Inhalt der Website dafür angepasst werden kann.
Beispiele für neuronales Matching
Danny Sullivan skizziert, was Neural Matching ist. Er gab ein Beispiel für die Abfrage „Warum sieht mein Fernseher seltsam aus?“. Der Benutzer gibt eine solche Abfrage ein, wenn er den Seifenoper-Effekt noch nicht kennt. Dank des neuen Algorithmus weiß Google jedoch genau, was Sie benötigen:

Auf Russisch eine ähnliche Geschichte:

Ein weiteres Beispiel. Sie haben in der Wohnung ein „schönes“ Insekt getroffen und wissen nicht, wie es heißt:

Wir gehen zu Google, geben eine Reihe von Funktionen ein und an erster Stelle erhalten wir die entsprechende Antwort:

Die Implementierung von Neural Matching beruht auf der Tatsache, dass Benutzer nicht immer wissen, wonach sie suchen, und Anforderungen nicht immer richtig formulieren. Danny Sullivan zeigte mehrere solcher "falschen" Fragen:

Die Aufgabe von Neural Matching besteht darin, die wahre Suchabsicht (Intention) zu bestimmen und die richtigen Ergebnisse zu erzielen.

Um die Absicht zu bestimmen, werden keine getrennten Wörter verwendet, sondern Essenzen und Beziehungen zwischen ihnen. Sehen Sie, wie es funktioniert - am Beispiel der Abfragen „Betrunken, was zu tun ist“ und „Betrunken in der Nacht“.
Jede Anfrage enthält dieselbe Entität - "betrunken". Die Kombination mit der Essenz von "über Nacht" signalisiert der Suchmaschine jedoch, dass der Benutzer übermäßiges Essen bedeutet. Und die Essenz von "was zu tun ist" ist höchstwahrscheinlich mit einer Vergiftung verbunden.

Wie definiert Google Intent - ist die Semantik ähnlich? Die Suchmaschine vergleicht, wie oft die in der Anfrage kombinierten Entitäten nebeneinander auf den Seiten gefunden werden. Darüber hinaus werden Statistiken zu Anfragen berücksichtigt (Benutzer, die die Anfrage "Nachts betrunken" eingeben, klicken häufiger auf Artikel, die sich speziell mit übermäßigem Essen befassen).
Ein weiteres Beispiel. Der Benutzer gibt den Ausdruck "Fenster setzen" ein. Dies ist nur die „falsche“ Anfrage, von der Danny Sullivan spricht. Google versteht, dass eine Person mit "Put" etwas anderes als eine einfache Installation von Fenstern bedeutet, und zeigt im TOP die Ergebnisse an, die aus seiner Sicht korrekt sind:
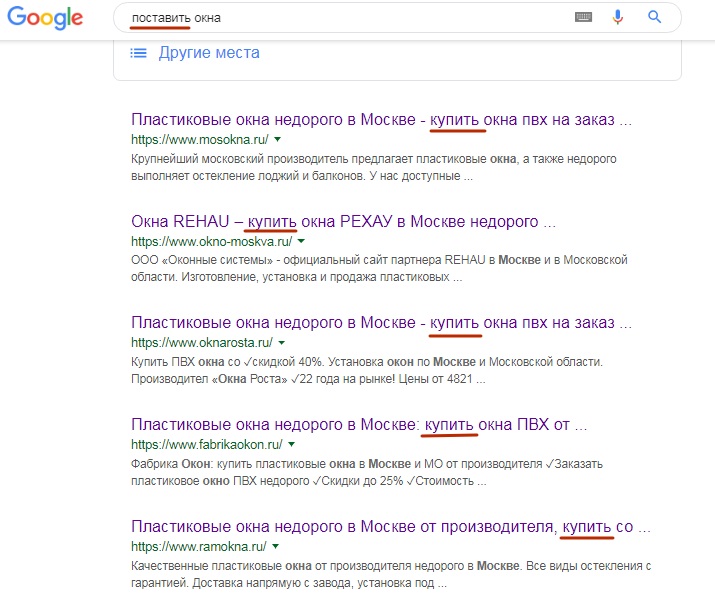
In diesem Fall enthält nur eine Seite des TOP-6 das Wort "Zustellen" (im Sinne von "Fensteranbieter" und nicht "Windows selbst installieren"). Auf den verbleibenden Seiten des TOP-6 gibt es weder ein Wort "put" noch Wurzelwörter. Obwohl Ergebnisse wie "So installieren Sie Windows selbst" usw. bereits unten gemischt sind.
Dies führt zu einer scheinbar paradoxen Schlussfolgerung: Um in vielen Worten hohe Positionen einzunehmen, ist es nicht erforderlich, Texte mit einer Semantik zu sättigen, die einer Suchabfrage ähnelt. Die Relevanz des Inhalts wird durch eine Reihe von Entitäten (Markierungsphrasen) bewertet, die mit hoher Wahrscheinlichkeit die Suchabsicht erfüllen.
Dies ändert den Ansatz beim Schreiben von SEO-Texten: Früher waren die Schlüssel der Bezugspunkt, jetzt braucht das Publikum sie.
Dokumentrelevanz-Ranking und neuronales Matching - Wie wirkt sich dies auf SEO aus?
Roger Montti schlug in einem Artikel für das Search Engine Journal vor, dass der Neural Matching-Algorithmus auf der DRR-Methode (Document Relevance Ranking) basieren könnte. Die Methode wird in dem auf Google AI veröffentlichten Artikel „ Deep Relevance Ranking mit erweiterten Interaktionen zwischen Dokumenten und Abfragen “ beschrieben.
Das Wesentliche der DRR-Methode ist, dass bei der Bestimmung der Relevanz eines Dokuments ausschließlich dessen Text verwendet wird. Andere Faktoren - Links, Anker, Erwähnungen, On-Page-SEO - spielen keine Rolle.
Was, Links werden überhaupt nicht mehr benötigt? Nicht wirklich so. Das Ranking nach dem beschriebenen DRR-Verfahren ist Teil des allgemeinen Ranking-Algorithmus. In der ersten Phase wird die Emission unter Berücksichtigung aller Ranking-Faktoren (Links, Schlüssel, „Mobilität“, Geolokalisierung usw.) gebildet. Die Suchmaschine eliminiert also Basisinhalte und identifiziert seriöse Websites. In der zweiten Phase tritt DRR in die Arbeit ein - unter den besten Ergebnissen wählt er die relevantesten aus (berücksichtigt jedoch nur den Text).
In der Praxis kann es so aussehen. Es gibt zwei Standorte: einen sehr seriösen und jungen. Die junge Seite enthält super Inhalte, die keine Analoga in der Nische haben, voller Details und Besonderheiten. Da es jedoch mehr Links zu einer maßgeblichen Site gibt, nimmt ihre Seite den ersten Platz ein und die Seite einer jungen Site den zehnten. Und hier kommt DRR zum Einsatz - die Suchmaschine scannt die Texte und stellt fest, dass der Inhalt der jungen Site aussagekräftiger ist als der einer maßgeblichen. Die Folge ist der Umzug des jungen Standortes in eine höhere Position.
So erstellen Sie Inhalte unter Neural Matching
Ob Neural Matching auf DRR basiert oder nicht, ist nicht so wichtig. Es ist wichtig, dass die Suchabsicht hier "fährt". Nicht lange "Fußtücher", nicht die Dichte der Schlüsselwörter, nicht synonymisierend.

Entscheiden Sie vor dem Erstellen von Inhalten:
- für wen ist er (es ist am besten, Nachforschungen anzustellen, Benutzerporträts zu machen und für sie zu schreiben);
- warum wird es benötigt (welche Aufgabe schließt es);
- Was ist drin, was die Wettbewerber nicht haben (welchen Wert es bringt).
Verwenden Sie eng verwandte Entitäten, um die Relevanz von Texten zusätzlich zu grundlegenden Abfragen zu erhöhen. Wenn der Text von einem Experten verfasst wurde, befinden sich solche Entitäten höchstwahrscheinlich im Text. Es ist eine andere Sache, wenn der Texter TK erhält - in diesem Fall ist es notwendig, die Entitäten zu bestimmen und sie in der Aufgabe anzugeben.
Betrachten wir die Methoden zum Sammeln von Entitäten am Beispiel einer Kategorie des Online-Shops „Benzingeneratoren“.
1. Suchen Sie nach Fragen / Antworten
Sie können Benutzeranforderungen mithilfe von Foren, Kommentaren zu Blog-Artikeln und Diskussionen in sozialen Netzwerken identifizieren. Es funktioniert alles. Es ist jedoch einfacher, zu Answers@Mail.ru (oder dem westlichen Gegenstück - Quora ) zu gehen, eine Suchabfrage einzugeben, die Fragen durchzugehen und die mit den Hauptschlüsseln verknüpften Entitäten hervorzuheben.
Auf Wunsch von "Benzingeneratoren" stellt mail.ru 1624 Fragen. Wir gehen die Liste durch und wählen die Entitäten aus, die die Bedürfnisse der Zielgruppe charakterisieren.


Nach Auswahl der Entitäten überlegen wir, welcher Inhalt für sie geeignet ist. Beispielsweise sollten der Benzinverbrauch pro Stunde und die Verwendungsmethoden des Generators (zum Schweißen, für einen Kessel, zur Beleuchtung usw.) in der Beschreibung bestimmter Waren angegeben werden. In der Beschreibung der Rubrik „Benzingeneratoren“ können Sie kurz beschreiben, wie sich Benzingeneratoren von Gas, Wechselrichtern usw. unterscheiden. Ein Problem mit dem Betrieb von Generatoren wird im Artikel für den Blog beschrieben.
Die Bearbeitung von Fragen in QS-Diensten ist mühsam, ermöglicht es Ihnen jedoch, die tatsächlichen Bedürfnisse des Publikums hervorzuheben, die Sie möglicherweise nicht erraten haben.
Sie können versuchen, die Arbeit mit dem Dienst Answer The Public zu vereinfachen. Er sammelt Fragen, Vergleiche und verschiedene Formulierungen, die im Netzwerk mit dem Auftreten einer bestimmten Phrase auftreten.

Der einzige Nachteil ist der englischsprachige Service. Die Übersetzung der gewünschten Phrase löst das Problem teilweise. Aber im kommerziellen Bereich lohnt es sich, sich an die Besonderheiten der Märkte zu erinnern (was die Indianer beunruhigt, kann für die Russen nutzlos sein).
2. Analysieren von Assoziationsphrasen
Unter den Suchergebnissen wird der Block „Zusammen mit ... häufig gesucht“ angezeigt - hier werden Phrasen gesammelt, die die Suchmaschine selbst mit der ursprünglichen Phrase verknüpft („Benzingeneratoren“).

Durch die Analyse von Assoziationsphrasen können Sie verwandte Einheiten identifizieren: 5 kW, 3 kW, 10 kW, Wechselrichter, 1 kW.
Es bleibt abzuwarten, wie sie in den Inhalt aufgenommen werden sollen. In der Beschreibung der Spalte "benzinbetriebene Generatoren" ist beispielsweise anzugeben, für welche Zwecke Generatoren mit unterschiedlicher Leistung (1, 3, 5, 10 kW) und Typ (Wechselrichter, konventionell usw.) geeignet sind.
Wenn Sie viele anfängliche Anfragen haben, sammeln Sie Assoziationen für eine lange Zeit manuell - verwenden Sie den Parser .
3. Analysieren von Suchhinweisen
Hinweise sind eine weitere Quelle für den Abgleich verwandter Entitäten.

Wir ergänzen die Liste der Entitäten, die von Verbänden gesammelt wurden: mit Autorun, Diesel, 380 Volt, lautlos. Dies sind Wörter, die Benutzerprobleme gut charakterisieren.
Es gibt auch einen Parser zum Sammeln von Hinweisen.
Grundsätzlich reichen die besprochenen Methoden aus, um sich ein Bild von den Bedürfnissen des Publikums zu machen. Wenn Sie die Semantik jedoch noch vertiefen möchten, haben Sie zwei Möglichkeiten.
4. Auswahl von Quasi-Synonymen
Quasi-Synonyme (semantische Assoziationen) sind Wörter, deren Bedeutung nahe beieinander liegt, die jedoch in verschiedenen Kontexten nicht austauschbar sind. Zum Beispiel sind die Wörter "Generator" und "Auto-Generator" Synonyme im Text über Autoersatzteile, aber sie werden im Text über Generatortypen nicht so sein.
Quasi-Synonyme werden anhand der Häufigkeit ihres Auftretens in den Texten bestimmt. Um dieses Problem zu lösen, gibt es einen RusVectōrēs- Dienst (Abschnitt „Ähnliche Wörter“). Geben Sie das gewünschte Wort ein, markieren Sie alle verfügbaren Modelle und Wortarten und starten Sie die Suche.

Als Ergebnis erhalten Sie die 10 wichtigsten Mitarbeiter für jedes Suchmodell. Es lohnt sich nicht, sie blind bei der Bildung von TK zu verwenden - es wird hier viel „Müll“ geben (Parsing-Assoziationen, die auf Daten von Suchmaschinen basieren, sind immer noch vorzuziehen). Trotzdem können Sie interessante Wörter identifizieren. Zum Beispiel sehen wir, dass die Wörter "Gasgenerator", "Wechselrichter", "Gasgenerator", "Schütz" usw. mit dem Wort "Generator" verbunden sind.
5. Analysieren von Wettbewerbertexten
Um die Bedürfnisse des Publikums zu identifizieren, ist diese Methode nicht die beste. Erstens ist nicht bekannt, wann Inhalte auf den Websites der Wettbewerber erstellt wurden (während dieser Zeit können sich die Sucheinstellungen ändern). Zweitens gibt es keine Garantie dafür, dass die Wettbewerber die Probleme des Publikums sorgfältig analysiert und darauf basierende Texte erstellt haben.
Wenn Sie diese Methode jedoch als Hilfsmittel verwenden, besteht die Möglichkeit, Entitäten zu identifizieren, die Sie möglicherweise übersehen.
Also geben wir bei der Suche die Hauptabfrage „Benzingeneratoren“ ein, kopieren die relevanten Texte von den Sites in die TOP-10 und wählen die Semantik mit Advego aus :

Wir ergänzen die Liste der relevanten Einheiten: 4-Takt, Notfall, autonom, ununterbrochen, für Sommerhäuschen, für die Natur usw.
Alles zusammenfügen und eine für Neural Matching optimierte TK erhalten.
TK für Texte: mache Neural Matching, nicht LSI
Nachdem die relevanten Entitäten gesammelt wurden, müssen Sie den Text schreiben. Es reicht jedoch nicht aus, nur die Schlüssel und eine Liste von Synonymen und verwandten Wörtern im TOR anzugeben, wie dies normalerweise bei der Bestellung von LSI-Texten der Fall ist.

Beispiel für TK für LSI-Text
Auf der Grundlage einer solchen TK - einfach mit einer Liste von Wörtern - werden manchmal ziemlich seltsame Texte erhalten.
Unter Textern ist es üblich, einen Text zu schreiben und erst dann die angegebenen Wörter einzugeben. Dies ist einfacher, da Sie die Auswahl und Einfügung von Wörtern beim Verfassen des Textes nicht unterbrechen müssen. Aber solche Einfügungen können rückwirkend die Logik und den Stil des Textes brechen - und oft brechen.
Der Text unter Neural Matching handelt von Benutzern und ihren Bedürfnissen, nicht von Schlüsseln und Pluswörtern. Daher erscheinen in TK rein Marketingmerkmale: Verbraucherbeschreibungen und deren Motive. Schlüssel und Pluswörter treten in den Hintergrund - sie werden als Markierungen und nicht als obligatorische Elemente verwendet. Ihr Platz wird von den Informationsbedürfnissen des Publikums eingenommen.

Beispiel TK unter Neural Matching
Eine solche TK ermöglicht es dem Autor, klar zu verstehen, für wen der Text ist, warum und unter welchen Umständen er gelesen wird. Eine solche TK buchstabiert nicht nur die zu verwendenden Wörter, sondern gibt auch Anweisungen - worüber man schreiben muss, um diese Wörter zu verwenden.
Neural Matching verlagert bei der Optimierung von Suchseiten den Schwerpunkt von der reinen SEO-Mechanik auf das Marketing. Tatsächlich ist dieser Trend seit mehreren Jahren zu beobachten. Neural Matching ist nur ein weiterer Schritt zur Suchmaschinenoptimierung mit menschlichem Gesicht.
Die Optimierung von Inhalten für Neural Matching erfordert Zeit und Kopfarbeit. Es ist viel einfacher, Schlüssel von der AX in TK abzulegen, plus Wörter zu analysieren und dem Texter zu sagen: "Schreiben für Menschen." Mit der Entwicklung der KI-Suche wird dieser Ansatz jedoch immer weniger effektiv sein.